La web está llena de información y, seamos realistas, nadie quiere pasarse horas copiando y pegando miles de productos o vacantes de empleo a mano. Por eso el web scraping se ha vuelto una habilidad clave para quienes trabajan en ventas, operaciones, ecommerce y muchos otros rubros. Python, con su sintaxis sencilla y librerías poderosas, es el lenguaje favorito para crear un raspador web. De hecho, más del usan Python, muy por encima de cualquier otro lenguaje.
Pero aquí está el detalle: aunque Python es súper potente para scraping, puede asustar a quienes recién empiezan, y hasta los que ya tienen experiencia se topan con trabas como webs dinámicas, bloqueos anti-bots o datos desordenados. Por eso armé esta guía paso a paso. Vamos a arrancar desde cero, ver un ejemplo raspador web Python y explorar cómo combinar Python con herramientas de IA como para raspar de forma más inteligente y eficiente. Ya sea que quieras automatizar la generación de leads, monitorear precios de la competencia o simplemente organizar datos web en una hoja de cálculo, acá vas a encontrar pasos claros y consejos útiles basados en experiencia real.
Introducción al Web Scraping con Python: Configuración Inicial
Arranquemos por lo básico. El web scraping es simplemente automatizar la recolección de datos de páginas web. En vez de copiar info a mano, un raspador visita la página, lee el HTML y saca los datos que te interesan: precios, contactos, reseñas, etc. Para los negocios, esto significa tener datos frescos para leads, monitoreo de precios o estudios de mercado, todo al alcance de un clic ().
Paso 1: Instala Python
Primero necesitás Python 3. Bajá la última versión desde la . En Windows, ejecutá el instalador y marcá la opción “Add Python to PATH”. En Mac, podés usar con brew install python o bajarlo directo. Después de instalar, abrí la terminal (o el símbolo del sistema) y ejecutá:
1python --versiono
1python3 --versionSi ves algo como Python 3.11.0, ¡ya está todo listo!
Paso 2: Crea un Entorno Virtual
Un entorno virtual te ayuda a mantener las dependencias de tu proyecto ordenadas y evita líos con otros proyectos en Python. En la carpeta de tu proyecto, ejecutá:
1# En macOS/Linux
2python3 -m venv .venv
3# En Windows
4py -m venv .venvActivá el entorno con:
- macOS/Linux:
source .venv/bin/activate - Windows:
.venv\Scripts\activate
Así, cualquier paquete que instales queda aislado en este proyecto ().
Paso 3: Instala las Librerías Clave
Vas a necesitar algunos paquetes básicos:
- Requests: Para descargar páginas web.
- BeautifulSoup (bs4): Para analizar el HTML.
- Scrapy: Para scraping avanzado y a gran escala.
Instalalos con:
1pip install requests beautifulsoup4 scrapy- Requests hace fácil pedir páginas por HTTP.
- BeautifulSoup te ayuda a encontrar y extraer datos del HTML.
- Scrapy es un framework completo para rastrear muchas páginas, manejar errores y exportar datos.
Si recién empezás, Requests + BeautifulSoup es ideal. Scrapy es útil cuando necesitás escalar.
Paso 4: Organiza tu Carpeta de Proyecto
¡Mantené tus archivos ordenados! Creá una carpeta para tu proyecto y ahí guardá tus scripts, archivos de datos y el entorno virtual. Tu “yo” del futuro te lo va a agradecer.
Ejemplo raspador web Python: Estructura Básica del Código
Vamos a armar un raspador sencillo. Bajamos una página, la analizamos y sacamos algunos datos. Acá va un ejemplo comentado usando :
1import requests
2from bs4 import BeautifulSoup
3URL = "https://example.com"
4response = requests.get(URL)
5response.raise_for_status() # Lanza error si no es 200 OK
6soup = BeautifulSoup(response.text, "html.parser")
7# Buscar todas las etiquetas de párrafo
8paragraphs = soup.find_all('p')
9for idx, p in enumerate(paragraphs, start=1):
10 print(f"Párrafo {idx}: {p.get_text()}")¿Qué pasa acá?
- Importamos las librerías.
- Bajamos la página con
requests.get. - Analizamos el HTML con BeautifulSoup.
- Buscamos todas las etiquetas
<p>y mostramos su texto.
Errores comunes:
- No chequear
response.status_code(siempre fijate que sea 200 OK). - Intentar usar
.get_text()en un objetoNone(si el elemento no existe). - Olvidar activar el entorno virtual (pueden fallar los imports).
Esta estructura—importar, descargar, analizar, extraer y mostrar—es la base de la mayoría de los raspadores en Python.
Usando Python para Raspar Páginas Web: Paso a Paso
Desglosemos el paso a paso para una tarea real de scraping.
1. Inspeccioná el Sitio Web
Abrí tu navegador, hacé clic derecho sobre el dato que te interesa y elegí “Inspeccionar”. Se abren las herramientas de desarrollador y ves la estructura HTML. Buscá etiquetas, clases o IDs únicos que identifiquen los datos que querés ().
2. Descargá la Página
Usá Requests para obtener el HTML:
1headers = {"User-Agent": "Mozilla/5.0"}
2response = requests.get(URL, headers=headers)
3response.raise_for_status()Agregar un User-Agent ayuda a evitar bloqueos básicos de bots.
3. Analizá el HTML
1soup = BeautifulSoup(response.text, "html.parser")4. Localizá y Extraé los Datos
Supongamos que querés raspar ofertas de empleo, cada una en un <div class="job-card">:
1job_cards = soup.find_all('div', class_='job-card')
2for card in job_cards:
3 title = card.find('h2', class_='title').get_text(strip=True)
4 company = card.find('h3', class_='company').get_text(strip=True)
5 print(title, company)Podés usar .find(), .find_all() o .select() con selectores CSS para búsquedas más complejas.
5. Manejá Múltiples Elementos (Listas)
Recorré la lista de contenedores (productos, empleos, etc.), extrayendo los campos que necesitás. Guardá los resultados en una lista de diccionarios para exportarlos fácil.
6. Solución de Problemas
- Si obtenés resultados vacíos, revisá tus selectores: puede que la clase haya cambiado o el contenido se cargue con JavaScript.
- Imprimí
response.text[:500]para ver si recibís el HTML esperado.
Ejemplo raspador web Python: Almacenamiento y Exportación de Datos
Una vez que tenés los datos, vas a querer guardarlos. Estas son las opciones más comunes:
Imprimir en Consola
Sirve para pruebas rápidas, pero no para proyectos reales.
Guardar en CSV
1import csv
2data = [
3 {"Name": "Alice", "Age": 25},
4 {"Name": "Bob", "Age": 30},
5]
6with open("output.csv", "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=["Name", "Age"])
8 writer.writeheader()
9 writer.writerows(data)Exportar a Excel
Si tenés instalados pandas y openpyxl:
1import pandas as pd
2df = pd.DataFrame(data)
3df.to_excel("output.xlsx", index=False)Guardar en una Base de Datos
Para necesidades simples, SQLite viene integrado en Python:
1import sqlite3
2conn = sqlite3.connect("scraped_data.db")
3cursor = conn.cursor()
4cursor.execute("CREATE TABLE IF NOT EXISTS people (name TEXT, age INTEGER)")
5for row in data:
6 cursor.execute("INSERT INTO people VALUES (?, ?)", (row["Name"], row["Age"]))
7conn.commit()
8conn.close()¿Cuándo usar cada opción?
- CSV: Ideal para hojas de cálculo y compartir datos.
- Excel: Para reportes formateados o varias hojas.
- Base de datos: Para proyectos grandes o continuos.
Usá siempre encoding="utf-8" para evitar problemas de caracteres ().
Thunderbit y Python: Potenciá tu Flujo de Trabajo de Scraping
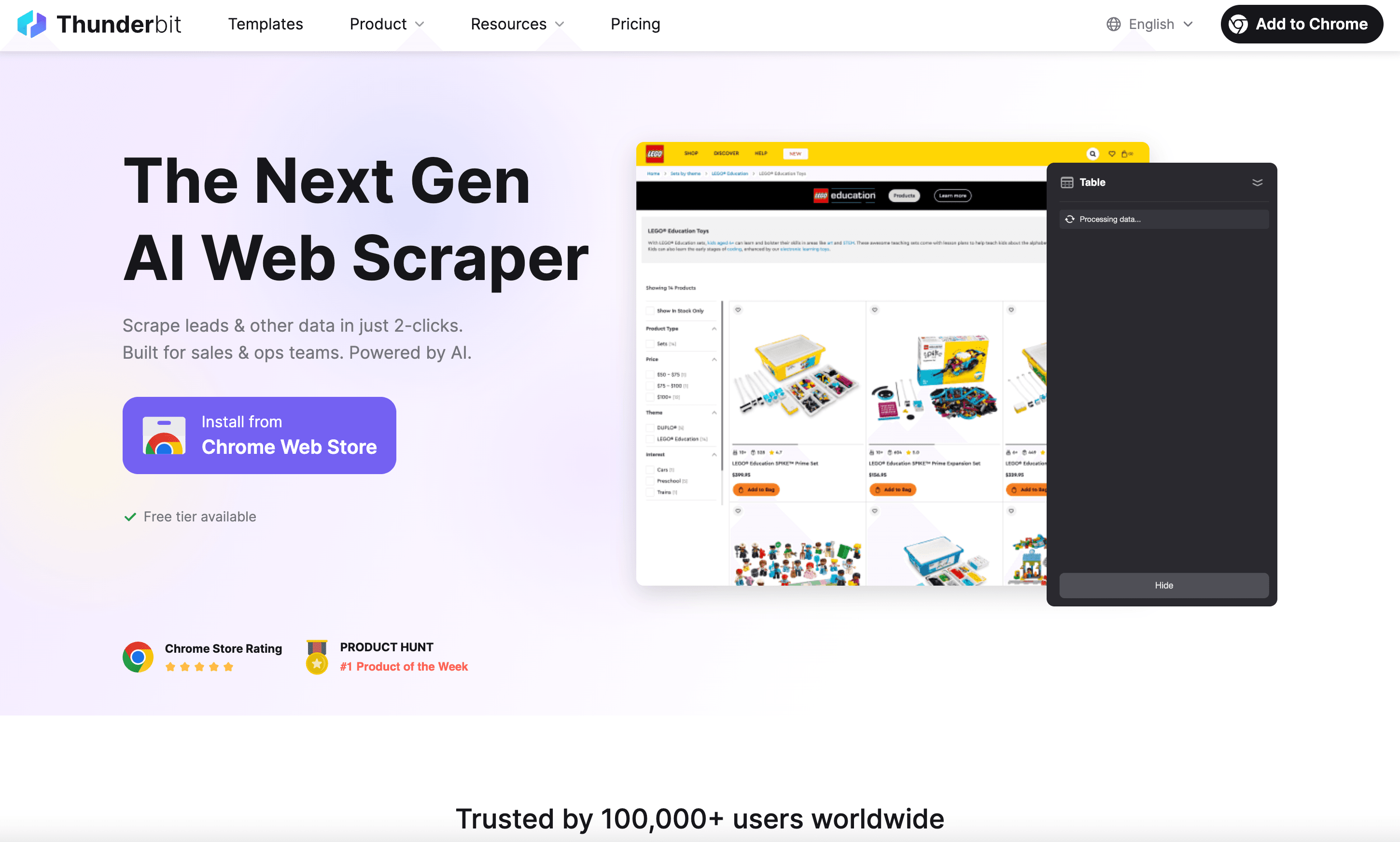 Ahora hablemos de , la extensión de Chrome para raspado web IA que está cambiando la forma de extraer datos para empresas.
Ahora hablemos de , la extensión de Chrome para raspado web IA que está cambiando la forma de extraer datos para empresas.
¿Qué hace diferente a Thunderbit?
- Sugerencia de campos con IA: Thunderbit analiza la página y te recomienda qué columnas de datos extraer—sin tener que inspeccionar HTML ni escribir selectores.
- Flujo visual e intuitivo: Solo abrí la extensión, dejá que la IA sugiera los campos, hacé clic en “Raspar” y listo.
- Raspado de subpáginas: Thunderbit puede visitar automáticamente páginas de detalle (como fichas de productos o perfiles) y enriquecer tu dataset con más info.
- Exportá donde quieras: Bajá tus datos en CSV, Excel o expórtalos directo a Google Sheets, Notion o Airtable ().
¿Cómo complementa Thunderbit a Python?
Supongamos que necesitás raspar un ecommerce complicado, con mucho JavaScript y login. Los scripts tradicionales en Python pueden tener problemas, pero Thunderbit—al correr en el navegador—puede manejar estos casos sin drama. Una vez que tenés los datos, los exportás y usás Python para analizarlos, hacer reportes o automatizar tareas.
Ejemplo de uso:
- Usá Thunderbit para raspar listados de productos (incluyendo imágenes, precios y reseñas) de un sitio dinámico.
- Exportá a CSV.
- Usá Python para analizar tendencias, combinar con otros datos o automatizar alertas.
Esta combinación te permite encarar hasta los desafíos de scraping más complejos, sin importar tu nivel de programación.
Cómo asegurar la precisión y estabilidad de tu raspador web Python
El web scraping no es solo extraer datos, sino conseguir la información correcta y de forma confiable. Acá van algunos consejos para que tus raspadores siempre funcionen:
1. Adaptate a los cambios en los sitios
Las webs cambian su HTML todo el tiempo. Escribí tus selectores para que sean lo más robustos posible—preferí IDs únicos o clases estables en vez de posiciones de etiquetas.
2. Usá manejo de errores
Poné tus peticiones y análisis dentro de bloques try/except:
1import time
2for attempt in range(3):
3 try:
4 response = requests.get(url, timeout=10)
5 response.raise_for_status()
6 break
7 except Exception as e:
8 if attempt < 2:
9 time.sleep(5)
10 else:
11 print(f"Falló tras 3 intentos: {e}")3. Rotá el User-Agent y usá proxies
Muchos sitios bloquean scripts que parecen bots. Cambiá tu User-Agent y, si hacés scraping masivo, usá proxies para evitar bloqueos de IP ().
4. Respetá robots.txt y sé ético
Revisá siempre el archivo robots.txt y los términos de uso del sitio. Solo raspá datos públicos, evitá info personal y no sobrecargues los servidores ().
5. Registrá y monitoreá
Usá el módulo logging de Python para registrar errores y éxitos. Si tu raspador corre de forma programada, configurá alertas para fallos o días sin resultados.
Cómo las funciones de IA de Thunderbit mejoran el scraping con Python
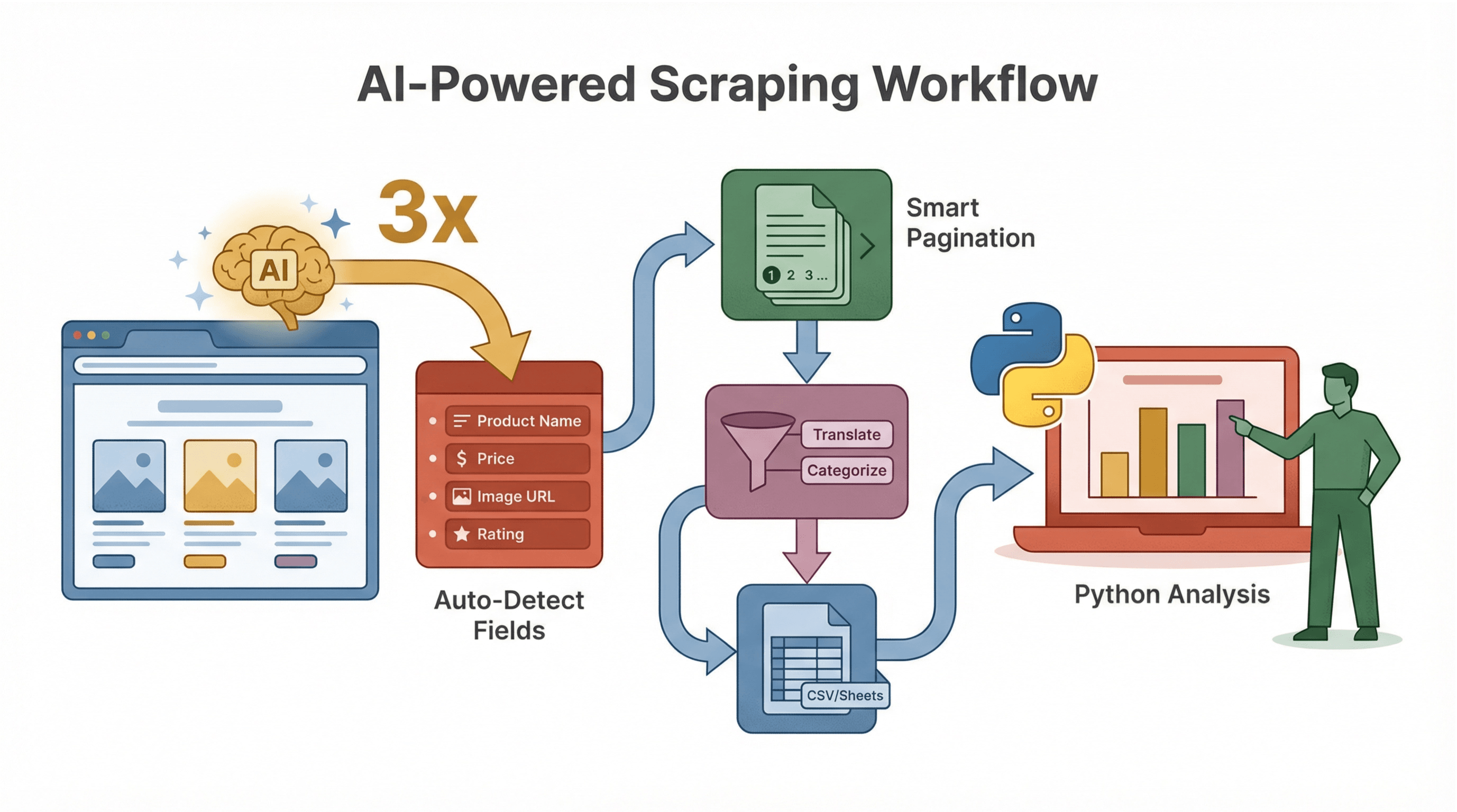 Thunderbit no solo raspa datos, sino que hace que todo el proceso sea más inteligente y rápido.
Thunderbit no solo raspa datos, sino que hace que todo el proceso sea más inteligente y rápido.
Esquema de datos sugerido por IA
La IA de Thunderbit puede sugerir al instante qué campos extraer, ahorrándote el trabajo de inspeccionar HTML y escribir selectores. Por ejemplo, en una página de producto, puede detectar automáticamente “Nombre del producto”, “Precio”, “URL de imagen” y más.
Manejo de subpáginas y paginación
La IA de Thunderbit detecta si hay páginas de detalle o varias páginas de resultados, y puede rasparlas todas—sin que tengas que programar nada extra. Esto es ideal para ecommerce, inmobiliarias o generación de leads.
Limpieza y enriquecimiento de datos con IA
¿Querés traducir, resumir o categorizar datos mientras los raspás? Thunderbit te deja agregar prompts de IA a cada campo, para, por ejemplo, etiquetar reseñas como “Positivas” o “Negativas”, o extraer solo el número de un precio.
Ejemplo de flujo de trabajo
- Usá Thunderbit para raspar y estructurar tus datos (con campos sugeridos por IA).
- Exportá a CSV o Google Sheets.
- Usá Python para analizar, visualizar o automatizar acciones posteriores.
Este flujo es ideal para equipos donde no todos programan—Thunderbit se encarga del scraping y Python del análisis avanzado.
Ejemplo raspador web Python: Consejos avanzados y problemas comunes
¿Listo para ir un paso más allá? Acá van algunos trucos de experto:
Scraping de contenido dinámico
Muchos sitios modernos usan JavaScript para cargar datos. Si Requests + BeautifulSoup no te devuelven la info que esperás, probá:
- Selenium o Playwright: Automatizá un navegador real para renderizar la página y después extraer el HTML.
- Buscá APIs: A veces los datos se cargan mediante llamadas API en segundo plano (normalmente en formato JSON). Usá la pestaña Network de tu navegador para encontrar estos endpoints—¡son mucho más fáciles de raspar!
Manejo de paginación
Recorré las páginas cambiando el parámetro de la URL (por ejemplo, ?page=2). O usá BeautifulSoup para encontrar el enlace “Siguiente” y seguí hasta que no haya más páginas.
Programá raspados
Usá la librería schedule de Python o un cron job para ejecutar tu raspador automáticamente. O usá la función de programación de Thunderbit para una solución sin código.
Problemas frecuentes
- CAPTCHAs: Bajá la velocidad de tus peticiones, usá proxies o considerá soluciones con intervención humana.
- Problemas de codificación: Especificá siempre
encoding="utf-8"al guardar archivos. - Bloqueos de IP: Rotá proxies, cambiá el User-Agent y respetá los límites de velocidad.
Conclusión y puntos clave
Dominar el web scraping con Python no tiene por qué ser complicado. Empezá por lo esencial:
- Configurá tu entorno y las librerías clave.
- Inspeccioná el sitio objetivo y planificá tus selectores.
- Escribí un script sencillo para descargar, analizar y extraer datos.
- Exportá los resultados en el formato que mejor se adapte a tu negocio.
A medida que avances, combiná Python con herramientas de IA como para encarar tareas complejas, sitios dinámicos o scraping a gran escala. Las funciones de IA de Thunderbit—como sugerencias de campos, raspado de subpáginas y exportaciones instantáneas—pueden ahorrarte horas de trabajo manual y permitir que cualquiera, incluso sin conocimientos técnicos, aproveche el scraping.
Recordá: los mejores raspadores son confiables, éticos y están pensados para el objetivo final. Seas profesional de ventas, gestor de ecommerce o fan de los datos, el web scraping puede abrirte un mundo de oportunidades—empezá de a poco, mejorá con la práctica y seguí aprendiendo.
¿Querés profundizar más? Visitá el para más guías, o probá la para ver el scraping con IA en acción.
Preguntas frecuentes
1. ¿Cuál es la forma más fácil de empezar con el web scraping en Python?
Instalá Python 3 y usá las librerías Requests y BeautifulSoup para descargar y analizar páginas web. Arrancá con sitios simples y avanzá a otros más complejos a medida que ganes experiencia.
2. ¿Cómo manejo sitios que usan JavaScript para cargar datos?
Para páginas con mucho JavaScript, usá herramientas de automatización de navegador como Selenium o Playwright, o buscá llamadas API en la pestaña Network de tu navegador que devuelvan datos estructurados (como JSON).
3. ¿Cuál es la mejor forma de exportar los datos raspados para uso empresarial?
El formato CSV es el más universal (compatible con Excel, Google Sheets, etc.), pero también podés exportar a Excel, JSON o bases de datos como SQLite. Thunderbit permite exportar directo a Google Sheets, Notion y Airtable.
4. ¿Cómo evito ser bloqueado al hacer scraping?
Cambiá tu User-Agent, usá proxies para scraping a gran escala, respetá los límites de velocidad y revisá siempre el robots.txt del sitio. Evitá raspar datos personales o sensibles.
5. ¿Cómo facilita Thunderbit el web scraping a quienes no programan?
Thunderbit usa IA para sugerir campos de datos, manejar subpáginas y paginación, y exportar datos estructurados en pocos clics—sin necesidad de programar. Es ideal para usuarios de negocio que buscan resultados rápidos y confiables sin complicaciones técnicas.
¿Listo para automatizar la recolección de datos? Probá gratis y llevá tu scraping al siguiente nivel con IA.
Más información