Déjame contarte cómo fueron mis primeros pasos en el mundo SaaS y la automatización, cuando escuchar “raspador web” me sonaba a algo que haría una araña en su tiempo libre. Hoy, el crawling web es la base de todo, desde Google Search hasta cualquier comparador de precios que usas a diario. La web es un ecosistema que nunca para de moverse, y todo el mundo—desde desarrolladores hasta equipos de ventas—quiere meterle mano a esos datos. Pero aquí va la verdad: aunque Python ha hecho mucho más fácil crear un raspador web, la mayoría solo quiere los datos, no un máster en cabeceras HTTP o renderizado de JavaScript.
Aquí es donde la cosa se pone buena. Como cofundador de , he visto de cerca cómo la demanda de datos web se ha disparado en todos los sectores. Los equipos de ventas buscan leads frescos, los de ecommerce quieren saber los precios de la competencia y los marketers necesitan insights de contenido. Pero no todos tienen el tiempo (ni las ganas) de volverse expertos en Python. Así que vamos a ver qué es realmente un raspador web python, por qué es clave y cómo herramientas con IA como Thunderbit están cambiando el juego tanto para usuarios de negocio como para desarrolladores.
Raspador Web Python: ¿Qué es y por qué es importante?
Vamos a aclarar un error común: raspadores web y scrapers web no son lo mismo. Aunque mucha gente los usa como si fueran iguales, son tan distintos como un Roomba y una Dyson (ambos limpian, pero de formas muy diferentes).
- Raspadores Web son como exploradores digitales. Su trabajo es descubrir e indexar páginas web de manera sistemática, saltando de un enlace a otro—como Googlebot recorriendo toda la web.
- Scrapers Web, en cambio, son recolectores expertos. Se enfocan en extraer datos específicos de páginas web, como precios, contactos o el contenido de un artículo.

Cuando hablamos de “raspador web python”, normalmente nos referimos a usar Python para crear estos bots automáticos que recorren y, a veces, extraen datos de la web. Python es el favorito porque es fácil de aprender, tiene un montón de librerías útiles y—seamos sinceros—nadie quiere programar un raspador web en Assembly.
El Valor de Negocio del Raspado y Scraping Web
¿Por qué tantos equipos se obsesionan con el raspado y scraping web? Porque los datos web son el nuevo oro—pero aquí no hay que excavar, solo programar (o, como verás, hacer unos clics).
Aquí tienes algunos de los usos más comunes en empresas:
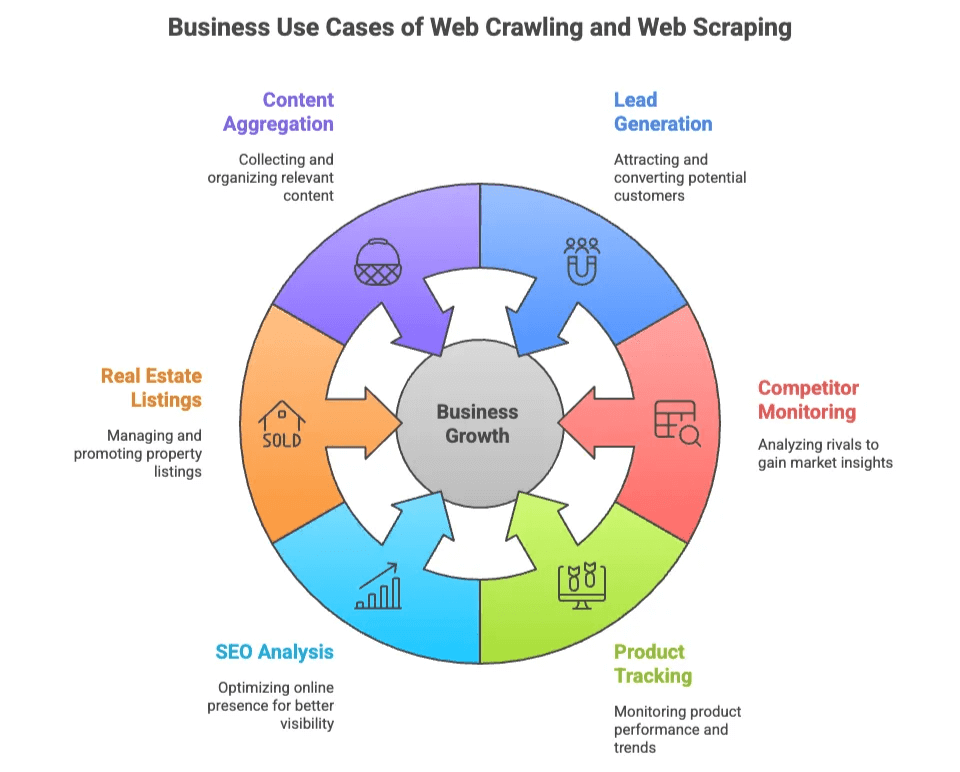
| Caso de Uso | Quién lo necesita | Valor que aporta |
|---|---|---|
| Generación de Leads | Ventas, Marketing | Crear listas de prospectos desde directorios, redes sociales |
| Monitoreo de Competencia | Ecommerce, Operaciones | Seguir precios, stock y nuevos productos de la competencia |
| Seguimiento de Productos | Ecommerce, Retail | Vigilar cambios de catálogo, reseñas y valoraciones |
| Análisis SEO | Marketing, Contenido | Analizar palabras clave, meta tags y backlinks para optimización |
| Listados Inmobiliarios | Agentes, Inversores | Unificar datos de propiedades y contactos de dueños de varias fuentes |
| Agregación de Contenido | Investigación, Medios | Recopilar artículos, noticias o foros para análisis |
Lo mejor es que tanto los equipos técnicos como los que no lo son pueden sacarle provecho. Los desarrolladores pueden crear raspadores a medida para proyectos complejos, mientras que los usuarios de negocio solo quieren datos rápidos y precisos—idealmente sin tener que aprender qué es un selector CSS.
Las Librerías Python Más Usadas para Raspado Web: Scrapy, BeautifulSoup y Selenium
La fama de Python en el raspado web no es casualidad—se apoya en tres librerías que tienen sus propios fans (y manías).
| Librería | Facilidad de uso | Velocidad | Soporte de contenido dinámico | Escalabilidad | Ideal para |
|---|---|---|---|---|---|
| Scrapy | Media | Rápida | Limitado | Alta | Raspados grandes y automatizados |
| BeautifulSoup | Fácil | Media | Ninguno | Baja | Parsing sencillo, proyectos pequeños |
| Selenium | Más difícil | Lenta | Excelente | Baja-Media | Páginas con mucho JavaScript, interactivas |
Vamos a ver qué hace especial a cada una.
Scrapy: El Framework Todo-en-Uno para Raspado Web Python
Scrapy es la navaja suiza del raspado web python. Es un framework completo pensado para grandes volúmenes y automatización—perfecto para rastrear miles de páginas, manejar solicitudes concurrentes y exportar datos a pipelines.
Por qué los desarrolladores lo aman:
- Gestiona el rastreo, parsing y exportación de datos en un solo lugar.
- Soporte integrado para concurrencia, programación y pipelines.
- Perfecto para proyectos donde necesitas escalar el raspado y scraping.
Pero… Scrapy tiene su curva de aprendizaje. Como dijo un desarrollador, es “demasiado complejo si solo necesitas extraer unas pocas páginas” (). Hay que entender selectores, procesamiento asíncrono y, a veces, hasta proxies y técnicas anti-bots.
Flujo básico de Scrapy:
- Definir un Spider (la lógica del crawler).
- Configurar los pipelines de Items (para procesar los datos).
- Ejecutar el rastreo y exportar los datos.
Si quieres rastrear la web como Google, Scrapy es tu mejor amigo. Si solo buscas una lista de emails, probablemente sea demasiado.
BeautifulSoup: Raspado Web Simple y Ligero
BeautifulSoup es el “hola mundo” del parsing web. Es una librería ligera enfocada en analizar HTML y XML, perfecta para quienes están empezando o para proyectos pequeños.
Por qué gusta tanto:
- Súper fácil de aprender y usar.
- Ideal para extraer datos de páginas estáticas.
- Flexible para scripts rápidos y sencillos.
Pero… BeautifulSoup no rastrea, solo analiza. Hay que combinarlo con requests para obtener las páginas, y tendrás que programar la lógica para seguir enlaces o manejar varias páginas ().
Si solo quieres probar el raspado web, BeautifulSoup es una buena puerta de entrada. Pero no esperes que maneje JavaScript ni escale a proyectos grandes.
Selenium: Para Páginas Dinámicas y con JavaScript
Selenium es el rey de la automatización de navegadores. Puede controlar Chrome, Firefox o Edge, interactuar con botones, rellenar formularios y—lo más importante—renderizar páginas cargadas con JavaScript.

Por qué es tan potente:
- Puede “ver” e interactuar con las páginas como un usuario real.
- Soporta contenido dinámico y datos cargados por AJAX.
- Esencial para sitios que requieren login o simulan acciones de usuario.
Pero… Selenium es lento y consume muchos recursos. Lanza un navegador completo por cada página, lo que puede saturar tu sistema si raspas a gran escala (). Además, mantenerlo puede ser un dolor de cabeza—hay que gestionar drivers y esperar a que cargue el contenido dinámico.
Selenium es tu opción cuando necesitas acceder a sitios que parecen imposibles para un scraper tradicional.
Los Retos de Construir y Ejecutar un Raspador Web Python
Ahora, hablemos del lado menos glamuroso del raspado web python. He pasado más horas de las que quisiera depurando selectores y peleando con medidas anti-bots. Estos son los principales desafíos:
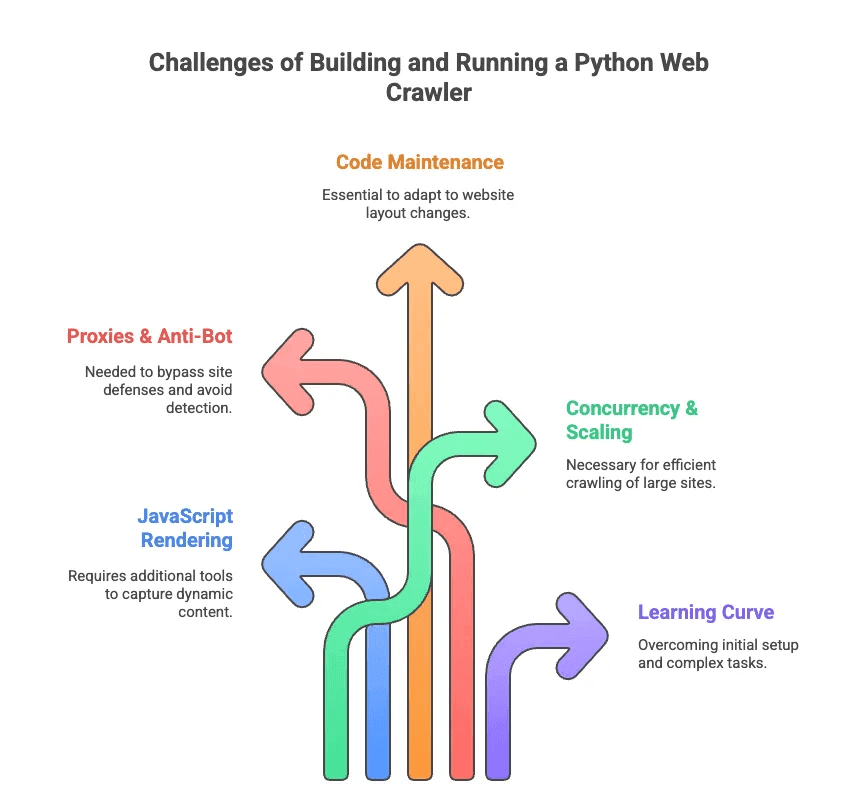
- Renderizado de JavaScript: La mayoría de los sitios modernos cargan contenido de forma dinámica. Scrapy y BeautifulSoup no pueden ver estos datos sin herramientas extra.
- Proxies y Anti-Bot: A los sitios no les gusta ser rastreados. Hay que rotar proxies, falsear agentes de usuario y, a veces, resolver CAPTCHAs.
- Mantenimiento del Código: Las webs cambian de diseño constantemente. Tu scraper puede romperse de la noche a la mañana y tendrás que actualizar selectores o lógica.
- Concurrencia y Escalabilidad: ¿Vas a rastrear miles de páginas? Hay que gestionar solicitudes asíncronas, manejo de errores y pipelines de datos.
- Curva de Aprendizaje: Para los no desarrolladores, solo instalar Python y las dependencias ya es complicado. Olvídate de manejar paginación o logins sin ayuda.
Como dijo un ingeniero, programar scrapers personalizados a veces parece que necesitas “un doctorado en configuración de selectores”—no es lo que busca un profesional de ventas o marketing promedio ().
Raspador Web IA vs. Raspador Web Python: Un Nuevo Camino para Usuarios de Negocio
¿Y si solo quieres los datos sin complicaciones? Aquí entran los raspadores web ia. Estas herramientas—como —están pensadas para usuarios de negocio, no para programadores. Usan IA para leer páginas web, sugerir qué datos extraer y se encargan de todo lo complicado (paginación, subpáginas, anti-bot) en segundo plano.
Aquí tienes una comparación rápida:
| Funcionalidad | Raspador Web en Python | Raspador Web IA (Thunderbit) |
|---|---|---|
| Configuración | Código, librerías, ajustes | Extensión de Chrome en 2 clics |
| Mantenimiento | Actualizaciones manuales, depuración | La IA se adapta a los cambios del sitio |
| Contenido Dinámico | Necesita Selenium o plugins | Renderizado integrado en navegador/nube |
| Anti-Bot | Proxies, agentes de usuario | IA y bypass en la nube |
| Escalabilidad | Alta (con esfuerzo) | Alta (nube, scraping en paralelo) |
| Facilidad de uso | Para desarrolladores | Para todos |
| Exportación de datos | Código o scripts | 1 clic a Sheets, Airtable, Notion |
Con Thunderbit, olvídate de solicitudes HTTP, JavaScript o proxies. Solo haz clic en “Sugerir campos con IA”, deja que la IA detecte lo importante y pulsa “Extraer”. Es como tener un mayordomo de datos—sin esmoquin.
Thunderbit: El Raspador Web IA de Nueva Generación para Todos
Vamos al grano. Thunderbit es una pensada para que extraer datos de la web sea tan fácil como pedir comida a domicilio. ¿Por qué destaca?
- Detección de Campos con IA: La IA de Thunderbit lee la página y sugiere qué campos (columnas) extraer—olvídate de adivinar selectores CSS ().
- Soporte para Páginas Dinámicas: Funciona tanto en páginas estáticas como en sitios cargados con JavaScript, gracias a los modos de scraping en navegador y en la nube.
- Subpáginas y Paginación: ¿Necesitas detalles de cada producto o perfil? Thunderbit puede entrar en cada subpágina y recopilar la información automáticamente ().
- Plantillas Adaptables: Una sola plantilla de raspado puede adaptarse a diferentes estructuras de página—no hace falta rehacer todo si el sitio cambia.
- Bypass Anti-Bot: La IA y la infraestructura en la nube ayudan a saltar las defensas anti-scraping más comunes.
- Exportación de Datos: Envía tus datos directamente a Google Sheets, Airtable, Notion o descárgalos como CSV/Excel—sin muros de pago, incluso en el plan gratuito ().
- Limpieza de Datos con IA: Resume, categoriza o traduce datos al instante—adiós a las hojas de cálculo desordenadas.
Ejemplos reales:
- Equipos de ventas extraen listas de prospectos de directorios o LinkedIn en minutos.
- Responsables de ecommerce monitorizan precios y cambios de productos de la competencia sin esfuerzo manual.
- Agentes inmobiliarios unifican listados y contactos de propietarios de varios portales.
- Equipos de marketing analizan contenido, palabras clave y backlinks para SEO—todo sin escribir una sola línea de código.
El flujo de trabajo de Thunderbit es tan sencillo que hasta mis amigos que no son techies lo usan—y les funciona. Solo instala la extensión, abre el sitio objetivo, haz clic en “Sugerir campos con IA” y listo. Para sitios populares como Amazon o LinkedIn, incluso hay plantillas instantáneas—un clic y ya tienes los datos ().
¿Cuándo usar un Raspador Web Python y cuándo un Raspador Web IA?
Entonces, ¿deberías crear un raspador web python o usar Thunderbit? Aquí va mi opinión honesta:
| Escenario | Raspador Web en Python | Raspador Web IA (Thunderbit) |
|---|---|---|
| Necesitas lógica personalizada o gran escala | ✔️ | Quizá (modo nube) |
| Integración profunda con otros sistemas | ✔️ (con código) | Limitado (vía exportaciones) |
| Usuario no técnico, necesitas resultados rápidos | ❌ | ✔️ |
| Cambios frecuentes en el diseño del sitio | ❌ (actualizaciones manuales) | ✔️ (la IA se adapta) |
| Sitios dinámicos/con mucho JS | ✔️ (con Selenium) | ✔️ (integrado) |
| Presupuesto ajustado, proyectos pequeños | Quizá (gratis, pero requiere tiempo) | ✔️ (plan gratuito, sin muros de pago) |
Elige raspadores web python si:
- Eres desarrollador y quieres control total.
- Vas a rastrear millones de páginas o necesitas pipelines de datos personalizados.
- No te importa el mantenimiento y la depuración constante.
Elige Thunderbit si:
- Quieres los datos ya, sin semanas de programación.
- Trabajas en ventas, ecommerce, marketing o inmobiliaria y solo necesitas resultados.
- No quieres lidiar con proxies, selectores o problemas anti-bot.
¿Aún tienes dudas? Aquí tienes una lista rápida:
- ¿Te manejas bien con Python y tecnologías web? Si es así, prueba Scrapy o Selenium.
- ¿Solo quieres los datos, rápido y limpio? Thunderbit es tu aliado.
Conclusión: Libera el Poder de los Datos Web—La Herramienta Justa para Cada Usuario
El raspado y crawling web se han vuelto habilidades clave en el mundo actual orientado a los datos. Pero seamos sinceros: no todos quieren ser expertos en scraping. Herramientas como Scrapy, BeautifulSoup y Selenium son potentes, pero requieren tiempo y mantenimiento.
Por eso me emociona tanto la llegada de los raspadores web ia como . Creamos Thunderbit para poner el poder de los datos web al alcance de todos—no solo de los desarrolladores. Con detección de campos por IA, soporte para páginas dinámicas y flujos sin código, cualquiera puede extraer los datos que necesita en minutos.
Así que, tanto si eres desarrollador y te gusta programar, como si solo quieres los datos para tu negocio, hay una herramienta para ti. Evalúa tus necesidades, tu nivel técnico y tu plazo. Y si quieres ver lo fácil que puede ser extraer datos web, —tu yo del futuro (y tu hoja de cálculo) te lo agradecerán.
¿Quieres profundizar más? Descubre más guías en el , como o . ¡Feliz crawling y feliz scraping!
Preguntas Frecuentes
1. ¿Cuál es la diferencia entre un Raspador Web Python y un Web Scraper?
Un raspador web python está diseñado para explorar e indexar páginas web siguiendo enlaces—ideal para descubrir la estructura de los sitios. Un web scraper, en cambio, extrae datos concretos de esas páginas, como precios o emails. Los crawlers mapean internet; los scrapers recogen lo que te interesa. A menudo se usan juntos en flujos de extracción de datos con Python.
2. ¿Qué librerías de Python son mejores para crear un Raspador Web?
Las más populares son Scrapy, BeautifulSoup y Selenium. Scrapy es rápida y escalable para grandes proyectos; BeautifulSoup es ideal para principiantes y páginas estáticas; Selenium destaca en sitios con mucho JavaScript, aunque es más lenta. La mejor opción depende de tus habilidades técnicas, el tipo de contenido y el tamaño del proyecto.
3. ¿Hay una forma más fácil de obtener datos web sin programar un Raspador Web Python?
Sí—Thunderbit es una extensión de Chrome con IA que permite a cualquiera extraer datos web en solo dos clics. Sin código, sin configuración. Detecta campos automáticamente, gestiona paginación y subpáginas, y exporta los datos a Sheets, Airtable o Notion. Perfecto para equipos de ventas, marketing, ecommerce o inmobiliaria que solo quieren datos limpios—y rápido.
Más información: