

Seamos sinceros: nadie se levanta por la mañana con ganas de copiar y pegar 500 filas de precios de productos en una hoja de cálculo. (Si eres de esos, te admiro la resistencia y te recomiendo una buena férula para la muñeca). Tanto si trabajas en ventas, operaciones o simplemente intentas que tu negocio vaya un paso por delante de la competencia, seguro que has sufrido la pesadilla de recopilar datos de sitios web. El mundo ya se mueve con datos web, y la demanda de extracción automatizada no para de crecer: se proyecta que el mercado de software de web scraping alcance más de 11 mil millones de dólares para 2032.
Llevo años en las trincheras del SaaS y la automatización, y he visto de todo: desde macros heroicas de Excel hasta scripts de Python parcheados a las 2 de la mañana. En esta guía te explicaré cómo usar un analizador HTML de Python para extraer datos reales de la web (sí, vamos a sacar juntos las valoraciones de películas de IMDb), y también te mostraré por qué, en 2026, hay una forma mejor: herramientas impulsadas por IA como Thunderbit, que te permiten saltarte el código y llegar directo a la información.
¿Qué es un analizador HTML y por qué usar uno en Python?
Empecemos por el principio: ¿qué hace realmente un analizador HTML? Piénsalo como tu bibliotecario personal para la web. Lee el código HTML desordenado que hay detrás de una página y lo organiza en una estructura ordenada, parecida a un árbol. Así puedes extraer solo los datos que necesitas —títulos, precios, enlaces— sin perderte entre una selva de corchetes angulares y divs.
Python es el lenguaje preferido para esta tarea, y con razón. Es legible, fácil para principiantes y cuenta con un ecosistema enorme de bibliotecas para web scraping y análisis. De hecho, Python es, con mucha diferencia, el lenguaje más popular para web scraping, gracias a su curva de aprendizaje suave y a su sólida comunidad.
El catálogo de analizadores HTML en Python
Estos son los principales nombres que verás al analizar HTML en Python:
- BeautifulSoup: la opción clásica y apta para principiantes. Sigue manteniéndose activamente:
beautifulsoup44.14.3 se publicó en PyPI a finales de 2025, así que lo que ves aquí no apunta a una biblioteca obsoleta. - lxml: rápida y potente, con consultas avanzadas.
- html5lib: súper tolerante con el HTML desordenado, igual que tu navegador.
- PyQuery: te permite usar selectores al estilo jQuery en Python.
- HTMLParser: el analizador integrado de Python; siempre está ahí, aunque es algo básico.
Cada una tiene sus particularidades, pero todas te ayudan a convertir HTML en bruto en datos estructurados.
Casos de uso clave: cómo se benefician las empresas de los analizadores HTML en Python
La extracción de datos web no es solo cosa de técnicos o científicos de datos. Se ha convertido en una actividad empresarial esencial, especialmente en ventas y operaciones. He aquí por qué:
| Caso de uso (sector) | Datos que suelen extraerse | Resultado para el negocio |
|---|---|---|
| Monitoreo de precios (retail) | Precios de la competencia, niveles de stock | Precios dinámicos, mejores márgenes (fuente) |
| Inteligencia de productos de la competencia | Anuncios, reseñas, disponibilidad | Identificar vacíos, generar leads (fuente) |
| Generación de leads (ventas B2B) | Nombres de empresas, emails, contactos | Prospección automatizada, crecimiento del pipeline (fuente) |
| Sentimiento de mercado (marketing) | Publicaciones en redes, reseñas, valoraciones | Feedback en tiempo real, detección de tendencias (fuente) |
| Agregación inmobiliaria | Anuncios, precios, información de agentes | Análisis de mercado, estrategia de precios (fuente) |
| Inteligencia de reclutamiento | Perfiles de candidatos, salarios | Captación de talento, comparación salarial (fuente) |
En resumen: si sigues copiando datos a mano, estás dejando tiempo y dinero sobre la mesa.
Conoce el kit de herramientas del analizador HTML en Python: comparación de bibliotecas populares
Vamos a ponernos prácticos. Aquí tienes una comparación rápida de las bibliotecas más populares para analizar HTML en Python, para que elijas la herramienta adecuada para tu trabajo:
| Biblioteca | Facilidad de uso | Velocidad | Flexibilidad | Necesidades de mantenimiento | Ideal para |
|---|---|---|---|---|---|
| BeautifulSoup | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ | Moderadas | Principiantes, HTML desordenado |
| lxml | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Moderadas | Velocidad, XPath, documentos grandes |
| html5lib | ⭐⭐⭐ | ⭐ | ⭐⭐⭐⭐⭐ | Bajas | Análisis tipo navegador, HTML roto |
| PyQuery | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | Moderadas | Fans de jQuery, selectores CSS |
| HTMLParser | ⭐⭐⭐ | ⭐⭐⭐ | ⭐ | Bajas | Tareas simples, integrado |
BeautifulSoup: la opción amigable para principiantes
BeautifulSoup es el “hello world” del análisis HTML. Su sintaxis es intuitiva, la documentación es excelente y perdona bastante el HTML feo o mal formado (ver más). ¿La desventaja? No es la más rápida, especialmente en páginas grandes o complejas, y no admite selectores avanzados como XPath de forma nativa.
lxml: rápida y potente
Si necesitas velocidad o quieres usar consultas XPath, lxml es tu aliada (detalles). Está construida sobre bibliotecas C, así que vuela, pero puede ser más complicada de instalar y tiene una curva de aprendizaje algo más pronunciada.
Otras opciones: html5lib, PyQuery y HTMLParser
- html5lib: analiza HTML igual que tu navegador: estupenda para marcado roto o raro, pero es lenta (comparación).
- PyQuery: te deja usar selectores al estilo jQuery en Python, lo que resulta muy práctico si vienes del front-end (ver documentación).
- HTMLParser: la opción integrada de Python: rápida y siempre disponible, aunque menos completa.
Paso 1: configurar tu entorno de analizador HTML en Python
Antes de analizar nada, necesitas preparar tu entorno de Python. Así es como se hace:
-
Instala Python: descárgalo de python.org si aún no lo tienes.
-
Instala pip: normalmente viene con Python 3.4 o superior, pero puedes comprobarlo ejecutando
pip --versionen la terminal. -
Instala las bibliotecas (vamos a usar BeautifulSoup y requests para este tutorial):
pip install beautifulsoup4 requests lxmlbeautifulsoup4es el analizador.requestste permite obtener páginas web.lxmles un analizador rápido que BeautifulSoup puede usar por debajo.
-
Comprueba la instalación:
python -c "import bs4, requests, lxml; print('All good!')"
Consejos para solucionar problemas:
- Si recibes errores de permisos, prueba
pip install --user ... - En Mac/Linux, quizá necesites usar
python3ypip3en su lugar. - Si ves “ModuleNotFoundError”, revisa la ortografía y tu entorno de Python.
Paso 2: analizar tu primera página web con Python
Vamos a ponernos manos a la obra y extraer las 250 mejores películas de IMDb. Obtendremos los títulos, los años y las valoraciones.
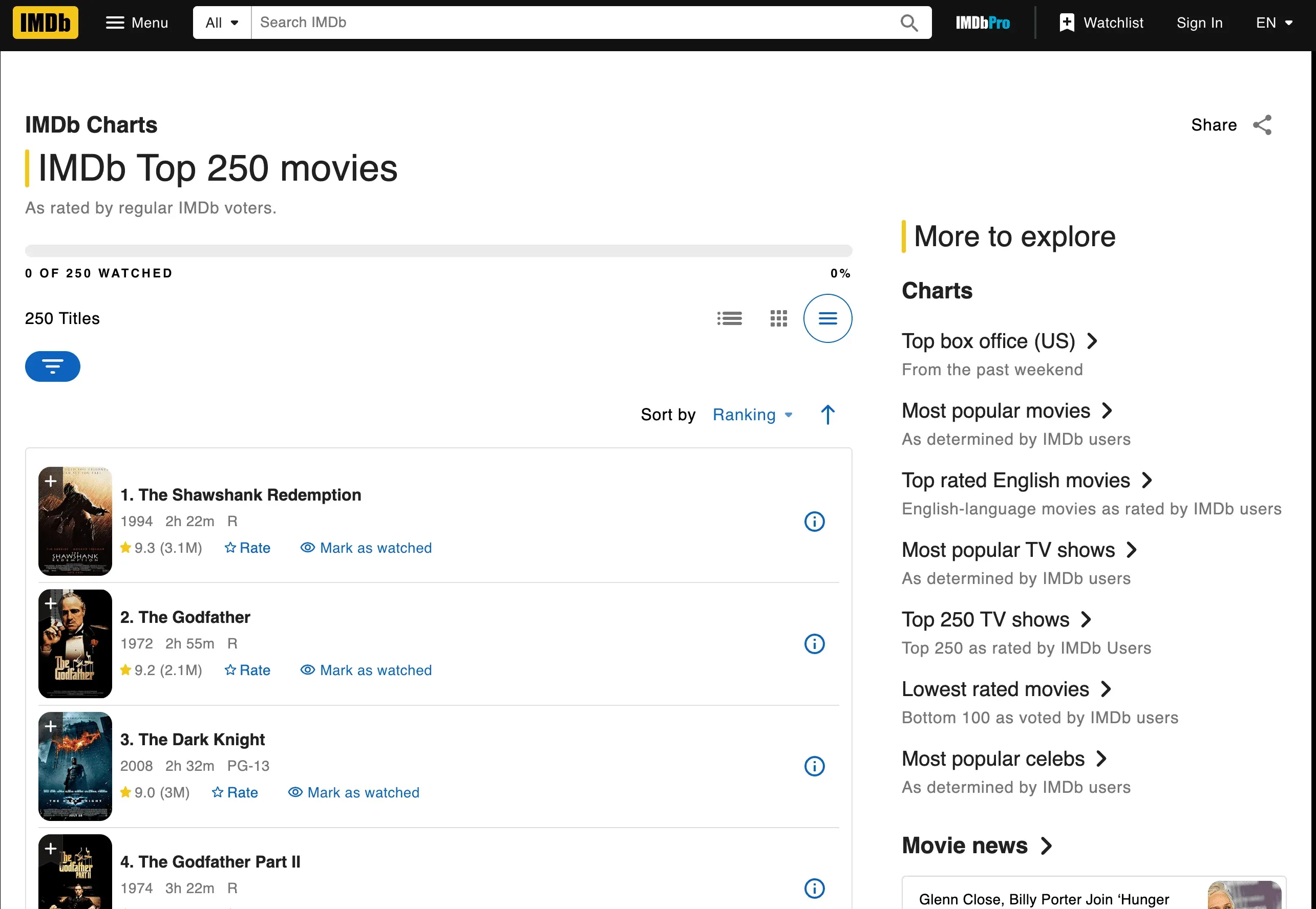
Obtener y analizar la página
Aquí tienes un script paso a paso. Antes de copiarlo, un aviso rápido: IMDb rediseñó la página Top 250 en junio de 2023, así que los viejos selectores td.titleColumn / td.ratingColumn que todavía verás en tutoriales antiguos ya no coinciden con nada. El marcado actual usa clases con prefijo ipc- generadas por su sistema de componentes, y IMDb ha reestructurado la página varias veces desde entonces (incluida una actualización a mediados de 2025), así que conviene volver a inspeccionarla con DevTools cada vez que regreses a este ejemplo.
import requests
from bs4 import BeautifulSoup
url = "https://www.imdb.com/chart/top/"
headers = {"User-Agent": "Mozilla/5.0"} # IMDb devuelve un marcado mínimo sin un UA real
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, "html.parser")
# Cada fila es un elemento de lista dentro del contenedor del ranking
rows = soup.select("li.ipc-metadata-list-summary-item")
for i, row in enumerate(rows[:3], start=1):
title_el = row.select_one("h3.ipc-title__text")
year_el = row.select_one("span.cli-title-metadata-item")
rating_el = row.select_one("span.ipc-rating-star--rating")
title = title_el.get_text(strip=True) if title_el else None
# El texto del h3 aparece como "1. The Shawshank Redemption" — eliminamos el prefijo del puesto
if title and ". " in title:
title = title.split(". ", 1)[1]
year = year_el.get_text(strip=True) if year_el else None
rating = rating_el.get_text(strip=True) if rating_el else None
print(f"{i}. {title} ({year}) -- Valoración: {rating}")
¿Qué está pasando aquí?
- Usamos
requests.get()para obtener la página (con unUser-Agentque parezca real: IMDb a veces entrega una versión recortada a clientespython-requestssin él). BeautifulSoupanaliza el HTML.- Obtenemos cada fila de película mediante
li.ipc-metadata-list-summary-itemy luego sacamos el título (h3.ipc-title__text), el año (span.cli-title-metadata-item) y la valoración (span.ipc-rating-star--rating) conselect_one(). - Extraemos el texto del título, el año y la valoración, eliminando el número de ranking inicial (
"1. ") que IMDb incrusta en el texto del título.
Si quieres algo más resistente que ir persiguiendo cambios de nombres de clases cada pocos meses, IMDb también incluye en la misma página un bloque <script type="application/ld+json"> con los mismos datos en formato estructurado — puedes analizarlo con json.loads(soup.find("script", type="application/ld+json").string) y recorrer el array itemListElement. Esa es la opción que usaría en producción; la versión con selectores CSS es más fácil de enseñar, pero también más frágil.
Salida:
1. The Shawshank Redemption (1994) -- Rating: 9.3
2. The Godfather (1972) -- Rating: 9.2
3. The Dark Knight (2008) -- Rating: 9.0
Extraer datos: encontrar títulos, valoraciones y más
¿Cómo supe qué etiquetas y clases usar? Inspeccioné el HTML de la página de IMDb (clic derecho > Inspeccionar elemento en tu navegador). Busca patrones: aquí, cada fila de película está dentro de <li class="ipc-metadata-list-summary-item">, con el título bajo <h3 class="ipc-title__text"> y la valoración bajo <span class="ipc-rating-star--rating">. Hay una advertencia importante que conviene interiorizar: IMDb ha cambiado este marcado más de una vez (el diseño td.titleColumn que todavía aparece en tutoriales antiguos no funciona desde su rediseño de junio de 2023), así que trata siempre las cadenas exactas de clases como algo orientativo y vuelve a inspeccionar antes de ejecutar el script.
Consejo profesional: si estás extrayendo datos de otro sitio, empieza siempre inspeccionando la estructura HTML e identificando clases o etiquetas únicas.
Guardar y exportar tus resultados
Vamos a guardar nuestros datos en un archivo CSV:
import csv
movies = []
for i in range(len(title_cells)):
title_cell = title_cells[i]
rating_cell = rating_cells[i]
title = title_cell.a.text
year = title_cell.span.text.strip("()")
rating = rating_cell.strong.text if rating_cell.strong else rating_cell.text
movies.append([title, year, rating])
with open('imdb_top250.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['Title', 'Year', 'Rating'])
writer.writerows(movies)
Consejos de limpieza:
- Usa
.strip()para eliminar espacios en blanco. - Maneja los datos faltantes con comprobaciones
if. - Para exportar a Excel, puedes abrir el CSV en Excel o usar
pandaspara escribir archivos.xlsx.
Paso 3: gestionar los cambios de HTML y los retos de mantenimiento
Aquí es donde la cosa se pone seria. A los sitios web les encanta cambiar su diseño, a veces solo para poner a prueba a los scrapers (o al menos así lo parece). Si IMDb cambia class="titleColumn" por class="movieTitle", tu script de repente devolverá resultados vacíos. Me ha pasado; también lo he depurado.
Cuando los scripts fallan: problemas reales
Problemas comunes:
- Selectores no encontrados: tu código no puede localizar la etiqueta o clase que especificaste.
- Resultados vacíos: la estructura de la página cambió, o el contenido ahora se carga con JavaScript.
- Errores HTTP: el sitio añadió medidas anti-bot.
Pasos para solucionarlo:
- Comprueba si el HTML que estás analizando coincide con lo que ves en el navegador.
- Actualiza tus selectores para que coincidan con la nueva estructura.
- Si el contenido se carga de forma dinámica, quizá necesites pasar a una herramienta de automatización del navegador (como Selenium) o encontrar un endpoint de API.
¿El verdadero dolor de cabeza? Si extraes datos de 10, 50 o 500 sitios distintos, puedes acabar dedicando más tiempo a reparar scripts que a analizar datos de verdad (ver historias de desarrolladores).
Paso 4: escalar: los costes ocultos del análisis HTML manual en Python
Imagina que quieres extraer no solo IMDb, sino también Amazon, Zillow, LinkedIn y una docena de sitios más. Cada uno necesita su propio script. Y cada vez que un sitio cambia, vuelves al editor de código.
Los costes ocultos:
- Trabajo de mantenimiento: algunos estiman que el mantenimiento cuesta 10 veces la construcción inicial.
- Infraestructura: necesitarás proxies, gestión de errores y supervisión.
- Rendimiento: escalar implica manejar concurrencia, límites de velocidad y más.
- Control de calidad: más scripts = más puntos donde algo puede romperse.
Para equipos no técnicos, esto se vuelve insostenible muy rápido. Es como contratar a un equipo de becarios para copiar y pegar datos todo el día, solo que los becarios son scripts de Python y se dan de baja cada vez que cambia una página web.
Una nota rápida sobre los agentes de programación con IA
Antes de pasar a las herramientas sin código, vale la pena mencionar un punto intermedio que realmente no existía cuando se escribieron la mayoría de los tutoriales de “aprende BeautifulSoup”: los agentes de programación con IA. Herramientas como Claude Code o Cursor aceptarán encantados una descripción en inglés (“obtén el Top 250 de IMDb, extrae título / año / valoración en un CSV”) y te generarán en un solo paso un script funcional de requests + BeautifulSoup, incluyendo la limpieza de selectores que acabamos de hacer a mano. Para flujos de navegador en lenguaje natural —iniciar sesión, paginar, lidiar con banners de cookies— una biblioteca como Browser Use puede controlar un navegador sin interfaz directamente desde un prompt.
Aun así, no hacen desaparecer las partes difíciles. Los límites de tasa, robots.txt, los muros de inicio de sesión y las defensas anti-bot siguen siendo tu problema, y cuando un selector falla en silencio (como ocurrió con IMDb) todavía necesitas reconocer lo que generó el agente y corregirlo. Así que incluso con un agente en el circuito, entender el flujo de trabajo del analizador HTML de este tutorial es lo que te permite depurar el resultado en lugar de quedarte mirando listas vacías.
Más allá de los analizadores HTML en Python: conoce Thunderbit, la alternativa impulsada por IA
Ahora viene la parte emocionante. ¿Y si pudieras saltarte el código, saltarte el mantenimiento y simplemente obtener los datos que necesitas, sin importar cómo cambie el sitio web?
Eso es exactamente lo que construimos con Thunderbit. Es una extensión de Chrome de raspador web con IA que te permite extraer datos estructurados de cualquier sitio web en dos clics. Sin Python, sin scripts, sin dolores de cabeza.
Analizadores HTML de Python vs. Thunderbit: comparación directa
| Aspecto | Analizadores HTML en Python | Thunderbit (ver precios) |
|---|---|---|
| Tiempo de configuración | Alto (instalar, programar, depurar) | Bajo (instalar extensión, hacer clic) |
| Facilidad de uso | Requiere programación | Sin código: apunta y haz clic |
| Mantenimiento | Alto (los scripts fallan con frecuencia) | Bajo (la IA se adapta automáticamente) |
| Escalabilidad | Compleja (scripts, proxies, infraestructura) | Integrada (scraping en la nube, tareas por lotes) |
| Enriquecimiento de datos | Manual (escribir más código) | Integrado (etiquetado, limpieza, traducción, subpáginas) |
¿Para qué construir algo si puedes resolver el problema con IA?
¿Por qué elegir IA para la extracción de datos web?
El agente de IA de Thunderbit lee la página, entiende la estructura y se adapta cuando algo cambia. Es como tener un superbecario que nunca duerme y nunca se queja de que cambien los nombres de las clases.
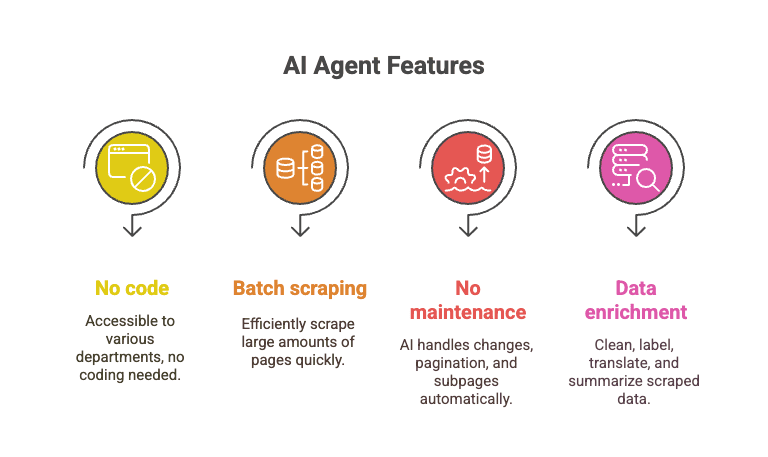
- No requiere código: cualquiera puede usarlo: ventas, operaciones, marketing, lo que sea.
- Scraping por lotes: extrae más de 10.000 páginas en el tiempo que te llevaría depurar un solo script de Python.
- Sin mantenimiento: la IA se encarga de los cambios de diseño, la paginación, las subpáginas y más.
- Enriquecimiento de datos: limpia, etiqueta, traduce y resume los datos mientras los extraes.
La cara opuesta del flujo de trabajo con BeautifulSoup que acabamos de ver es precisamente la fragilidad que encontramos con los selectores de IMDb arriba: cuando la página se reorganiza, el script devuelve resultados vacíos en silencio, y terminas pasando la tarde en DevTools en lugar de analizar datos. Un raspador de IA sin código oculta ese paso detrás de su propia capa de inferencia; es una compensación real (estás confiando en que la extracción de otra persona sea correcta), no una solución mágica.
Paso a paso: extraer las valoraciones de películas de IMDb con Thunderbit
Veamos cómo Thunderbit resuelve la misma tarea de IMDb:
- Instala la extensión de Chrome de Thunderbit.
- Navega a la página Top 250 de IMDb.
- Haz clic en el icono de Thunderbit.
- Haz clic en “AI Suggest Fields”. Thunderbit leerá la página y recomendará columnas (título, año, valoración).
- Revisa o ajusta las columnas si hace falta.
- Haz clic en “Scrape”. Thunderbit extraerá las 250 filas al instante.
- Exporta a Excel, Google Sheets, Notion o CSV: tú eliges.
Y ya está. Sin código, sin depuración, sin momentos de “¿por qué esta lista está vacía?”.
¿Quieres verlo en acción? Echa un vistazo al canal de YouTube de Thunderbit para ver demostraciones, o lee nuestra guía paso a paso para extraer datos de Amazon para otro ejemplo real.
Conclusión: elegir la herramienta adecuada para tus necesidades de datos web
Los analizadores HTML de Python como BeautifulSoup y lxml son potentes, flexibles y gratuitos. Son ideales para desarrolladores que quieren control total y no les importa arremangarse. Pero vienen con una curva de aprendizaje pronunciada, mantenimiento continuo y costes ocultos, especialmente a medida que crecen tus necesidades de scraping.
Para usuarios de negocio, equipos de ventas y cualquiera que solo quiera los datos, no el código, herramientas impulsadas por IA como Thunderbit son un soplo de aire fresco. Te permiten extraer, limpiar y enriquecer datos web a escala, sin programar y sin mantenimiento.
Mi consejo: usa Python si te encanta programar scripts y necesitas una personalización total. Pero si valoras tu tiempo (y tu cordura), prueba Thunderbit. ¿Por qué construir y cuidar scripts cuando puedes dejar que la IA haga el trabajo pesado?
¿Quieres aprender más sobre web scraping, extracción de datos y automatización con IA? Explora más tutoriales en el blog de Thunderbit, como Cómo extraer datos de un sitio web a Excel usando IA o Las mejores herramientas y software de web scraping en 2025.




