

Hace unos años, si me hubieras preguntado cómo automatizar tareas en la web—como sacar los precios de productos de la página de un competidor o hacer pruebas de interfaz de usuario—seguramente te habría recomendado Selenium o Puppeteer, te habría pasado un par de ejemplos de código y te habría deseado buena suerte. Pero hoy la cosa es muy diferente. La demanda de automatizar navegadores y sacar datos de la web se ha disparado, sobre todo en áreas como ventas, marketing, ecommerce y el sector inmobiliario. Todo el mundo quiere datos web, pero no todos quieren convertirse en programadores para conseguirlos.
La verdad es que, aunque herramientas como Puppeteer, Selenium y Playwright siguen siendo la base para los equipos técnicos, la gente de negocio busca otra cosa: soluciones sin código, que no se rompan cada vez que una web cambia y que no dependan del equipo de desarrollo. Aquí es donde las herramientas sin código con IA, como Thunderbit, están ganando terreno. Pero antes de mirar hacia adelante, vamos a repasar los clásicos y por qué está cambiando el panorama.
¿Qué es Puppeteer? Una intro rápida
Arranquemos con Puppeteer. Si alguna vez quisiste controlar Chrome o Chromium con código—abrir páginas, hacer clic en botones, sacar capturas de pantalla o extraer datos—Puppeteer es la librería Node.js perfecta. Es como tener un control remoto para tu navegador, pero en vez de botones, usas JavaScript.
¿Para qué se usa Puppeteer?
- Pruebas automatizadas de apps web (por ejemplo: “¿Sigue funcionando mi checkout?”)
- Raspado web—sacar datos de sitios que no tienen API
- Generar capturas de pantalla o PDFs de páginas web (ideal para informes o archivar)
- Simular interacciones de usuario para auditorías de rendimiento o SEO
La gran ventaja de Puppeteer es lo bien que se integra con Chrome. Habla directamente con el navegador, es rápido, confiable y soporta todas las funciones modernas—apps de una sola página, contenido dinámico, etc. Pero ojo, está pensado casi solo para Chrome. Si necesitas automatizar Firefox o Safari, no es la mejor opción.
¿Qué es Selenium? El clásico de la automatización web
Selenium es el abuelo de la automatización de navegadores. Existe desde la época en que “Web 2.0” era lo más top. Selenium no es solo una librería—es todo un ecosistema, compatible con varios lenguajes de programación (Python, Java, C#, JavaScript, Ruby, entre otros) y prácticamente todos los navegadores importantes (Chrome, Firefox, Safari, Edge e incluso Internet Explorer para los nostálgicos).
¿Por qué destaca Selenium?
- Soporte para varios lenguajes: Usa el que más te guste—no tienes que aprender JavaScript si prefieres Python.
- Compatibilidad con muchos navegadores: Automatiza Chrome, Firefox, Safari, Edge y más.
- Comunidad gigante: Hay montones de tutoriales, plugins e integraciones.
- Pruebas de interfaz a gran escala: Es la base de la automatización de pruebas para muchos equipos de QA.
Pero hay un detalle: la arquitectura de Selenium es algo viejita. Usa un modelo de “driver + API”, lo que implica lidiar con drivers, versiones de navegador y, a veces, bastantes dolores de cabeza. Es potente, pero puede sentirse como manejar un coche manual en la era de los eléctricos.
puppeteer vs selenium: Diferencias clave
Entonces, ¿en qué se diferencian Puppeteer y Selenium? Vamos al grano.
| Característica | Puppeteer | Selenium |
|---|---|---|
| Soporte de Lenguaje | Solo JavaScript/Node.js | Varios (Python, Java, C#, JS, Ruby, etc.) |
| Soporte de Navegador | Chrome/Chromium (Firefox experimental) | Chrome, Firefox, Safari, Edge, IE |
| Rendimiento | Rápido, optimizado para Chrome | Bueno, pero puede ser más lento por la abstracción |
| Facilidad de Uso | API sencilla, sintaxis moderna | Más complejo, curva de aprendizaje mayor |
| Comunidad/Ecosistema | En crecimiento, menor que Selenium | Enorme, madura, muchos recursos |
| Casos de Uso | Pruebas, scraping, capturas, PDFs | Pruebas, scraping, automatización |
A nivel técnico:
- Ambos usan el modelo de “driver + API”.
- Puppeteer está enfocado en Chrome y usa el protocolo DevTools.
- Selenium es independiente del navegador, usando WebDriver para soportar varios navegadores.
En resumen:
Si solo usas Chrome y te gusta JavaScript, Puppeteer es rápido y fácil. Si necesitas flexibilidad—diferentes navegadores y lenguajes—Selenium es tu mejor amigo. Pero ambos requieren escribir y mantener scripts, y ninguno “entiende” realmente la web más allá del DOM.
Playwright: La alternativa moderna a Puppeteer
Aquí entra Playwright, la respuesta de Microsoft a las necesidades actuales de automatización web. Si Puppeteer es un deportivo para Chrome, Playwright es un SUV que va por todo.
¿Por qué Playwright está de moda?
- Soporte real multiplataforma: Chrome, Firefox, Safari, Edge—todo desde una sola API.
- Ejecución en paralelo: Permite varios contextos de navegador a la vez, ideal para CI/CD.
- Autoespera inteligente: Olvídate de escribir “wait for element” una y otra vez—Playwright espera automáticamente a que los elementos estén listos.
- Selectores avanzados: Puedes seleccionar elementos por texto, rol o atributos ARIA.
- Funciones modernas: Soporte nativo para descargas, subidas, geolocalización, permisos y más.
He visto equipos pasarse a Playwright cuando necesitan pruebas confiables, rápidas y fáciles de mantener—sobre todo en entornos de integración y despliegue continuo (CI/CD). También sirve para scraping, pero, igual que Puppeteer y Selenium, sigue siendo una herramienta para programadores. Si no te llevas bien con los scripts, te va a costar.
alternativas a playwright: ¿Qué más hay?
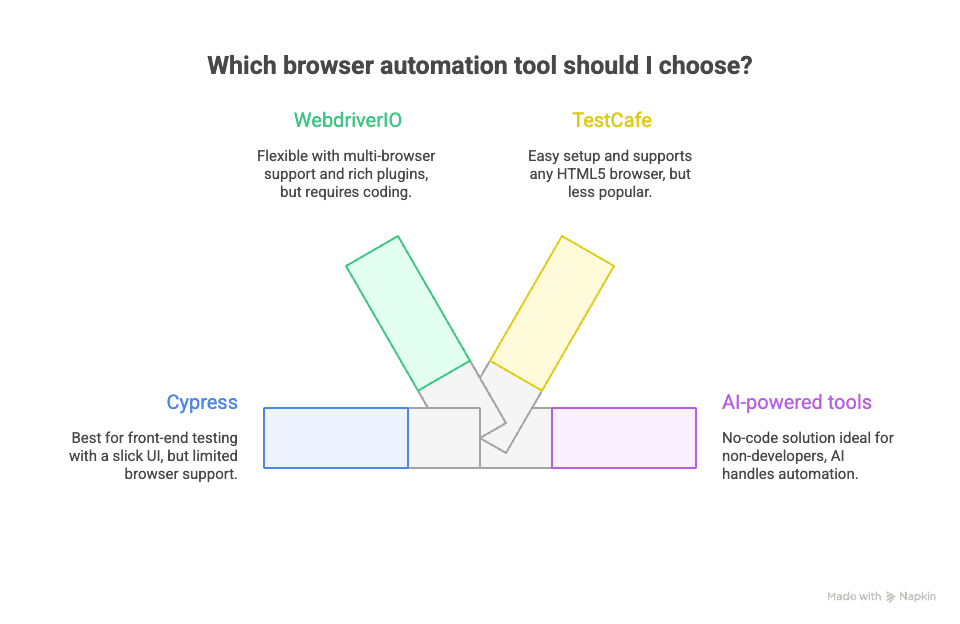
Seamos sinceros: el mundo de la automatización de navegadores está lleno de opciones. Aquí tienes otros nombres que seguro escucharás y cómo se comparan:
-
Cypress:
Pensado para pruebas de frontend, Cypress tiene una interfaz muy amigable y una gran experiencia para desarrolladores, pero solo funciona con navegadores basados en Chrome y no se lleva bien con múltiples pestañas o dominios. Es genial para testing, menos para scraping o automatización fuera de pruebas. Más sobre Cypress.
-
WebdriverIO:
Implementación en Node.js del protocolo WebDriver, WebdriverIO es flexible, soporta varios navegadores y tiene un ecosistema de plugins muy completo. Se usa tanto para testing como para scraping, pero, otra vez, hay que programar. Sitio oficial de WebdriverIO.
-
TestCafe:
Otra herramienta basada en JavaScript, TestCafe es fácil de instalar y corre pruebas en cualquier navegador compatible con HTML5. Es menos popular que Cypress o Playwright, pero vale la pena para automatizaciones sencillas. Sitio oficial de TestCafe.
-
Herramientas con IA como Thunderbit:
Aquí es donde la cosa se pone interesante para los equipos de negocio. Thunderbit va por otro camino: sin código, sin scripts, solo selecciona lo que quieres y deja que la IA haga el trabajo duro. Ahora te cuento cómo funciona, pero si no eres desarrollador, este es el camino a seguir.
Tabla resumen: Herramientas con código vs sin código
| Herramienta | Soporte de Navegador | Lenguaje(s) | Requiere Código | Ideal para |
|---|---|---|---|---|
| Puppeteer | Chrome/Chromium | JavaScript | Sí | Devs, automatización en Chrome |
| Selenium | Todos los principales | Varios | Sí | Devs, pruebas multiplataforma |
| Playwright | Todos los principales | JavaScript, etc. | Sí | Automatización moderna, CI/CD |
| Cypress | Familia Chrome | JavaScript | Sí | Pruebas frontend |
| WebdriverIO | Todos los principales | JavaScript | Sí | Automatización flexible |
| TestCafe | Todos los principales | JavaScript | Sí | Automatización sencilla |
| Thunderbit | Todos los principales* | N/A (Sin código) | No | Usuarios de negocio, scraping |
- Thunderbit funciona en tu navegador, así que es compatible donde funcione Chrome.
De la “automatización de navegadores” al “scraping inteligente”: el enfoque Thunderbit
Extrae datos de cualquier web usando IA Get Started Free
Aquí es donde el fan de la automatización que llevo dentro se emociona. Los frameworks clásicos como Puppeteer, Selenium y Playwright manipulan el DOM—usan selectores para encontrar elementos, hacer clic y extraer texto. Pero no “entienden” realmente la página. Si cambias una clase, mueves un botón o el contenido se carga de forma dinámica, tu script puede romperse en segundos.
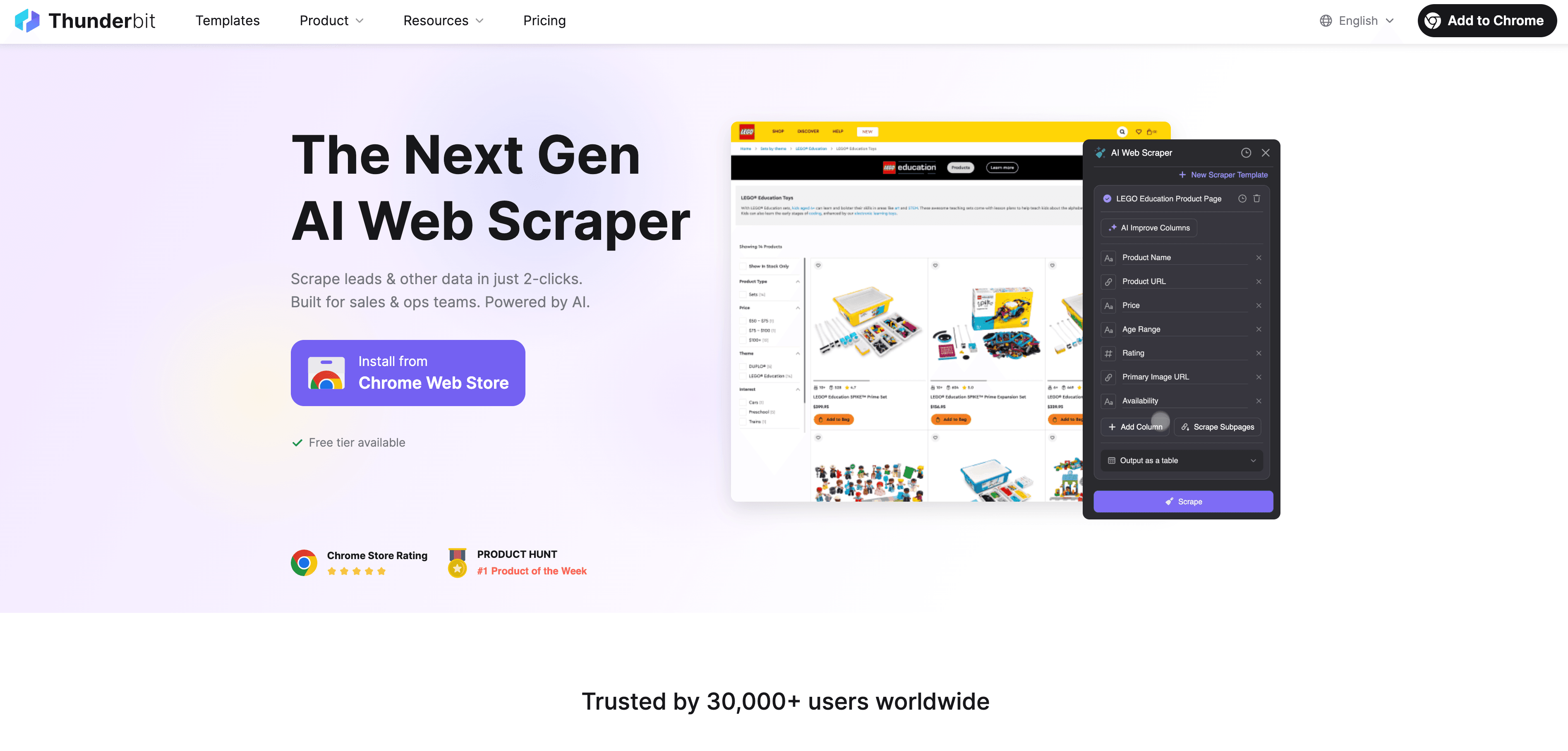
Thunderbit cambia las reglas. En vez de interactuar solo con el DOM, la IA de Thunderbit lee la página como lo haría una persona. Primero convierte la web en un formato estructurado tipo Markdown y luego lo analiza con IA para entender el contexto. Así, la IA distingue entre el nombre de un producto, un precio o una reseña, aunque el HTML sea un caos.
¿Qué significa esto en la práctica?
- Scraping estable en páginas complejas o dinámicas: ¿Páginas con scroll infinito, pop-ups o contenido generado por usuarios? Sin problema.
- Olvídate de los selectores: La IA se adapta a los cambios de diseño, así que no tienes que reescribir scripts cada vez que la web se actualiza.
- Extracción semántica: Thunderbit puede sacar datos estructurados (tablas, listas, información anidada) incluso de páginas caóticas para un raspador tradicional.
He visto a Thunderbit enfrentarse a Facebook Marketplace, secciones de comentarios larguísimas y tiendas online con contenido dinámico—escenarios donde la mayoría de los raspadores basados en código se rinden. Y todo con un par de clics.
Por qué los equipos de negocio necesitan scraping web semántico y sin código
Qué es el scraping de datos y cómo hacerlo en 2025 Get Started Free
Seamos realistas: la mayoría de los equipos de ventas, marketing, ecommerce e inmobiliarias no tienen un desarrollador a mano. Y si lo tienen, seguro que está ocupado con otras cosas “más urgentes”. Esto es lo que suele pasar con las herramientas basadas en código:
- Mantenimiento constante de scripts: Cada vez que cambia una web, alguien tiene que actualizar selectores o reescribir scripts.
- Dependencia del desarrollador: Los usuarios no técnicos dependen del equipo de ingeniería.
- Curva de aprendizaje alta: Incluso los frameworks “fáciles” requieren tiempo para aprender y depurar.
- Procesos frágiles: Un pequeño cambio en la web objetivo y todo el flujo se rompe.
Thunderbit nació para resolver estos problemas. Así lo hace:
- Scraping en 2 clics: Solo haz clic en “Sugerir campos con IA” y luego en “Extraer”. La IA detecta qué datos extraer.
- Sugerencia de campos con IA: Thunderbit analiza la página y recomienda las columnas y tipos de datos adecuados.
- Scraping de subpáginas: ¿Necesitas datos de páginas enlazadas (como detalles de productos o reseñas)? Thunderbit puede visitar cada subpágina y enriquecer tu tabla automáticamente.
- Sin código, sin scripts: Cualquier persona puede usarlo—no necesitas conocimientos técnicos.
Tabla comparativa para usuarios de negocio
| Funcionalidad | Puppeteer/Selenium/Playwright | Thunderbit |
|---|---|---|
| ¿Requiere código? | Sí | No |
| Mantenimiento de scripts | Frecuente | Ninguno (la IA se adapta) |
| Manejo de contenido dinámico | Scripting manual | Comprensión semántica por IA |
| Datos de subpáginas/enlaces | Código personalizado | Scraping de subpáginas con 1 clic |
| Exportación de datos (Excel, Sheets) | Procesamiento manual | Exportación integrada y gratuita |
| Curva de aprendizaje | Alta | Mínima |
| Ideal para | Desarrolladores, QA | Ventas, Marketing, Operaciones, Inmobiliarias |
¿Cuándo usar Puppeteer, Selenium, Playwright o Thunderbit? (Guía de decisión)
Entonces, ¿qué herramienta deberías usar? Aquí va mi consejo, después de años creando automatizaciones para equipos técnicos y de negocio:
Usa Puppeteer, Selenium o Playwright si:
- Tienes desarrolladores o ingenieros de QA dedicados.
- Necesitas flujos de trabajo muy personalizados (por ejemplo, pruebas complejas, interacciones avanzadas con el navegador).
- Requieres integración con pipelines de CI/CD o frameworks de testing automatizado.
- Tu equipo está cómodo manteniendo código y resolviendo errores en scripts.
Usa Thunderbit si:
- Quieres sacar datos de webs rápido, sin programar.
- Tu equipo es de ventas, marketing, ecommerce o inmobiliaria y necesitas datos ya, no después de un sprint.
- Estás cansado de que los scripts se rompan cada vez que cambia una web.
- Necesitas manejar páginas complejas, dinámicas o que cambian con frecuencia.
- Quieres exportar datos directamente a Excel, Google Sheets, Airtable o Notion.
Matriz de decisión
| Escenario | Mejor herramienta(s) |
|---|---|
| Automatización personalizada de navegador | Playwright, Puppeteer |
| Pruebas de interfaz multiplataforma | Selenium, Playwright |
| Scraping web sin código | Thunderbit |
| Páginas web dinámicas o cambiantes | Thunderbit |
| Equipo de negocio, sin desarrolladores | Thunderbit |
| Integración profunda con CI/CD | Playwright, Selenium |
Prueba Thunderbit AI Web Scraper gratis
El futuro: combinando frameworks de automatización con scraping impulsado por IA
Aquí es donde la cosa se pone interesante. El mundo clásico de la “automatización de navegadores” se está mezclando con el nuevo mundo del “scraping inteligente”. Veo un futuro donde los equipos técnicos y de negocio no tienen que elegir entre código y no-código—pueden tener ambos.
Los flujos de trabajo híbridos están en auge:
- Los desarrolladores pueden usar frameworks como Playwright para automatizaciones personalizadas, pero integrar módulos de IA para extracción semántica de datos.
- Los usuarios de negocio pueden empezar con herramientas sin código como Thunderbit y, si necesitan personalización avanzada, pasar a soluciones con código.
- Los modelos de IA cada vez entienden mejor la estructura, el contexto e incluso la intención de las páginas web—haciendo el scraping más confiable y menos frágil.
Las organizaciones que se preparen para este cambio—creando flujos de trabajo programables y accesibles para usuarios no técnicos—serán más ágiles, orientadas a datos y mucho menos frustradas.
Conclusión: elige la herramienta adecuada para tu negocio
En resumen:
- Puppeteer es rápido, enfocado en Chrome, ideal para desarrolladores JavaScript.
- Selenium es el veterano multiplataforma y multilenguaje—potente pero algo anticuado.
- Playwright es la alternativa moderna, compatible con varios navegadores y perfecta para CI/CD y automatización avanzada.
- Thunderbit es la solución sin código, impulsada por IA, para usuarios de negocio que buscan scraping web confiable y semántico sin complicaciones.
La verdadera pregunta no es cuál es la “mejor” herramienta, sino cuál se adapta a las habilidades, necesidades y recursos de tu equipo. Si eres desarrollador y necesitas flujos personalizados, los frameworks clásicos siguen siendo útiles. Pero si eres usuario de negocio y solo quieres datos—rápido, preciso y sin dolores de cabeza—Thunderbit merece tu atención.
Y si te interesa el futuro del scraping y la automatización web, mantente atento a cómo la IA está revolucionando el sector. Estamos pasando de scripts de “haz clic aquí, espera allá” a herramientas que realmente comprenden la web—haciendo la extracción de datos más inteligente, rápida y, sobre todo, más entretenida.
¿Quieres ver más sobre cómo la IA está revolucionando el scraping web? Descubre otras guías en el Blog de Thunderbit, como Qué es el scraping de datos y cómo hacerlo en 2025 o Cómo extraer datos de cualquier web usando IA.
Y si quieres probar el scraping sin código y con IA, instala la extensión de Chrome de Thunderbit y experimenta la automatización inteligente. Tu yo del futuro (y tu equipo hambriento de datos) te lo agradecerán.
Empieza con Thunderbit AI Web Scraper
Preguntas frecuentes
1. ¿Cuáles son las principales diferencias entre Puppeteer y Selenium?
Puppeteer es una librería de Node.js pensada sobre todo para automatizar Chrome y Chromium, con una API moderna y sencilla para tareas como pruebas de interfaz, scraping y generación de capturas o PDFs. Selenium, en cambio, es un framework más veterano, compatible con varios lenguajes y todos los navegadores principales. Mientras que Puppeteer es más rápido y fácil de usar para tareas específicas de Chrome, Selenium ofrece mayor flexibilidad para pruebas multiplataforma y tiene una comunidad y ecosistema más grande.
2. ¿Cómo mejora Playwright respecto a Puppeteer y Selenium?
Playwright, desarrollado por Microsoft, parte de las ventajas de Puppeteer y suma soporte real para varios navegadores (Chrome, Firefox, Safari, Edge) desde una sola API. Incorpora funciones como ejecución en paralelo, autoespera robusta y selectores avanzados. Playwright es especialmente popular para pruebas modernas de aplicaciones web y automatización en pipelines CI/CD, ofreciendo una experiencia más confiable y fácil de mantener que sus predecesores.
3. ¿Qué ventajas tienen las herramientas sin código y con IA como Thunderbit para el scraping web?
Las herramientas sin código y con IA como Thunderbit están pensadas para usuarios de negocio que necesitan datos web rápido y sin barreras técnicas. Thunderbit usa IA para entender semánticamente las páginas, lo que la hace resistente a cambios de diseño y contenido dinámico. Los usuarios pueden extraer datos estructurados con solo unos clics, sin escribir ni mantener scripts. Este enfoque elimina problemas típicos como scripts rotos, dependencia de desarrolladores y curvas de aprendizaje complicadas.
4. ¿Cuándo elegir una herramienta basada en código (como Puppeteer, Selenium o Playwright) en vez de una solución sin código como Thunderbit?
Las herramientas basadas en código son ideales para equipos con desarrolladores o ingenieros de QA que necesitan flujos de trabajo muy personalizados, integración profunda con pipelines CI/CD o automatización avanzada de navegadores. Si tu proyecto requiere pruebas complejas, interacciones personalizadas o soporte para varios lenguajes y navegadores, estos frameworks son la mejor opción. Las soluciones sin código como Thunderbit son preferibles cuando usuarios no técnicos necesitan extraer datos de forma rápida y confiable, especialmente en entornos de negocio.
5. ¿Qué depara el futuro para la automatización de navegadores y las herramientas de scraping web?
El futuro de la automatización de navegadores va hacia un modelo híbrido que combina la programabilidad de los frameworks clásicos con la inteligencia y accesibilidad de las herramientas sin código impulsadas por IA. A medida que los modelos de IA mejoran en la comprensión de la estructura y el contexto de las páginas web, tanto usuarios técnicos como de negocio se beneficiarán de flujos de trabajo más robustos y menos frágiles. Las organizaciones que adopten tanto soluciones con código como sin código serán más ágiles y orientadas a los datos.
Más información:
- Cómo extraer datos de cualquier web usando IA
- Convertir imágenes a Excel: guía de JPG a Word y texto
- Control de precios MAP: guía completa de monitoreo
- puppeteer vs selenium: cuál elegir
Prueba Raspador Web IA Get Started Free




