
Jamás se me va a borrar de la cabeza la primera vez que vi a alguien pasar horas copiando y pegando datos de una web a una hoja de cálculo. Era como ver a alguien intentar vaciar el Han River con una cuchara de postre. Hoy en día, la automatización de procesos ha cambiado por completo este panorama, sobre todo en el mundo del web scraping. Pero a medida que más equipos buscan automatizar tareas repetitivas, surge la gran pregunta: ¿Deberías seguir con el RPA tradicional (Automatización Robótica de Procesos) o dar el salto a los agentes de IA y los raspadores web IA?
Si trabajas en ventas, ecommerce u operaciones, seguro que te has topado con este dilema. Los números lo dejan claro: , y otro 19% planea sumarse pronto. Mientras tanto, los agentes de IA y los raspadores web IA avanzan a toda velocidad, prometiendo extraer datos hasta de los sitios más enredados con solo unos clics. Entonces, ¿cómo decidir? Vamos a desmenuzar qué significa realmente la automatización de procesos, en qué se diferencian RPA y los agentes de IA, y por qué el futuro del web scraping se parece cada vez más al enfoque con IA de .
Desmitificando la Automatización de Procesos: ¿Qué Significa Realmente?
Vamos a lo básico: automatización de procesos es dejar que el software haga el trabajo aburrido por ti. Es como tener un túnel de lavado automático en el mundo de la oficina: las máquinas se encargan de lo repetitivo y monótono, y tú puedes dedicarte a lo que de verdad importa (o al menos, a tomarte un café tranquilo).
En el mundo de los negocios, la automatización de procesos busca agilizar el día a día, reducir errores y liberar tiempo del equipo. En el web scraping, significa usar herramientas para recolectar datos de sitios web—como precios, contactos o reseñas—sin tener que ir página por página. En vez de pasar horas copiando y pegando, configuras un “robot” digital o agente que lo hace por ti. Es como tener un contestador automático, pero para todo internet.
Las ventajas saltan a la vista: . Y después de años desarrollando productos SaaS y de automatización, te lo digo claro: una vez que automatizas el web scraping, no hay vuelta atrás al trabajo manual.
RPA al Detalle: ¿Qué es la Automatización Robótica de Procesos?
La Automatización Robótica de Procesos (RPA) es la pionera de la automatización. RPA utiliza “robots” de software que imitan lo que haría una persona en el ordenador: hacer clic, navegar por webs, copiar y pegar datos entre aplicaciones. Estos bots siguen instrucciones estrictas y basadas en reglas, y son perfectos para tareas repetitivas y bien estructuradas.
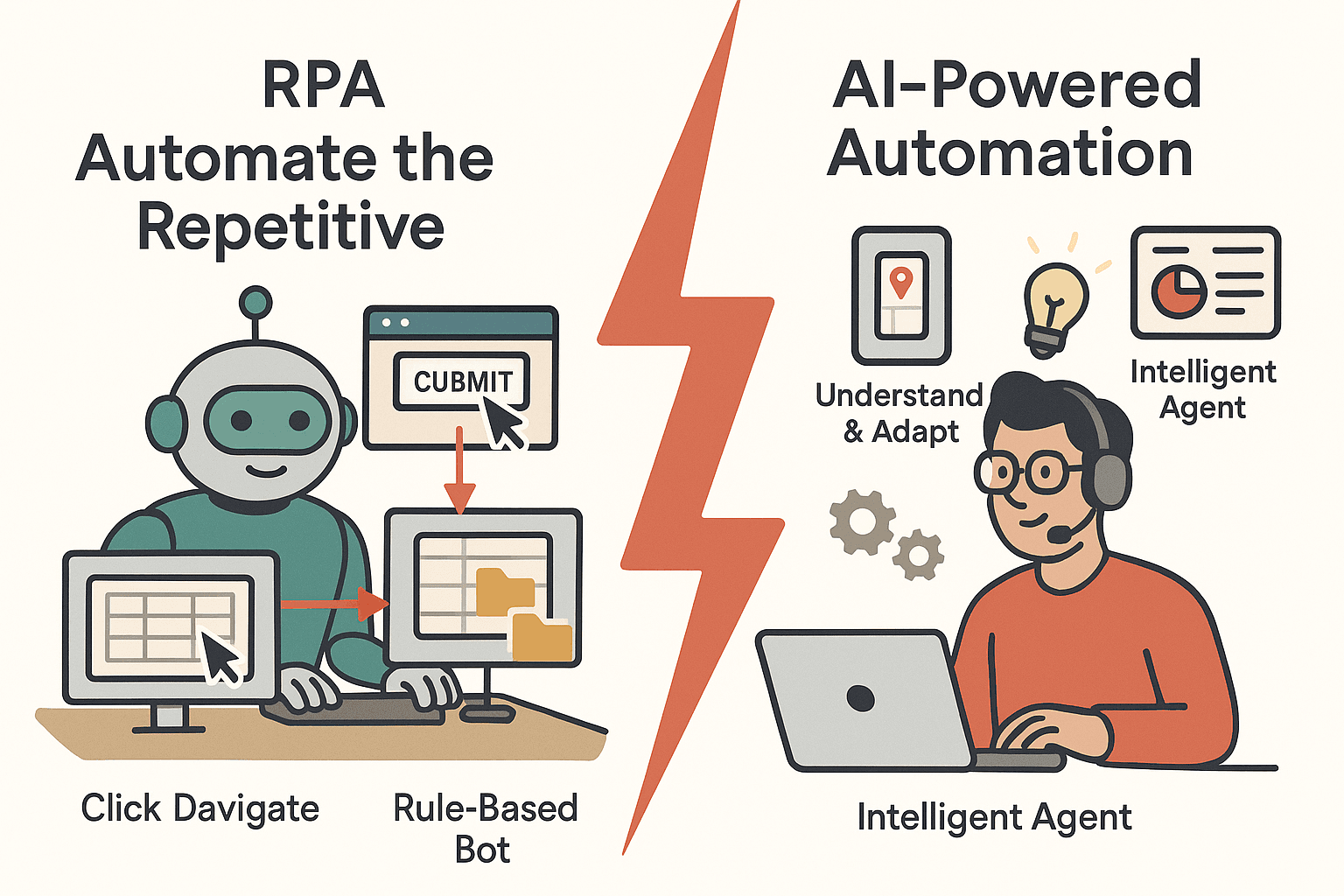
Casos Comunes de Uso de RPA en Web Scraping
- Iniciar sesión en una web y extraer datos de campos específicos
- Copiar datos de formularios web a bases de datos internas
- Descargar informes de portales web de forma programada
RPA ha sido clave en sectores como finanzas, ecommerce y operaciones. Por ejemplo, un minorista puede usar RPA para extraer precios de la competencia cada noche, o un equipo financiero para actualizar hojas de cálculo con cotizaciones bursátiles.
Ventajas de RPA
- Fiabilidad: Los bots no se cansan ni cometen errores de tipeo. Pueden trabajar 24/7 y son .
- Cumplimiento: Cada paso queda documentado, lo que facilita las auditorías.
- Implementación rápida: Para tareas simples y repetitivas, RPA se configura rápido—sin necesidad de integraciones complejas.
Limitaciones de RPA
Pero aquí está el tema: RPA es muy rígido. Si una web cambia su diseño o estructura, el bot puede fallar. Es como enseñarle a alguien a conducir memorizando cada giro; si la carretera cambia, se pierde. RPA también tiene problemas con:
- Contenido dinámico: Scroll infinito, pop-ups o cambios de diseño requieren lógica y mantenimiento extra.
- Datos no estructurados: Si los datos no están siempre en el mismo sitio, RPA se confunde.
- Mantenimiento: .
Así que, aunque RPA es ideal para tareas rutinarias y bien definidas, no es la herramienta más flexible.
El Nuevo Jugador: ¿Qué es un Agente de IA?
Aquí entran los agentes de IA—una nueva generación de automatización que aporta adaptabilidad e inteligencia. En web scraping, un agente de IA es un programa autónomo al que le das un objetivo (“consígueme todos los nombres y precios de productos de este sitio”) y él mismo decide cómo lograrlo.
¿En Qué se Diferencian los Agentes de IA de RPA?
- Aprendizaje y Adaptación: Los agentes de IA usan machine learning y procesamiento de lenguaje natural para entender, decidir y actuar. Pueden manejar datos no estructurados, aprender de nuevos patrones y ajustar sus acciones.
- Comprensión contextual: En vez de seguir reglas rígidas, interpretan el contenido de la página—reconocen patrones, entienden el contexto e incluso pueden analizar imágenes o texto libre.
- Instrucciones en lenguaje natural: Muchas veces basta con decirle al agente de IA lo que quieres en español, y él se encarga del resto.
Piensa en RPA como un empleado meticuloso que sigue instrucciones al pie de la letra, mientras que un agente de IA es como un asistente autónomo capaz de improvisar y adaptarse.
El Raspador Web IA: La Siguiente Evolución
Los raspadores web IA van un paso más allá. Utilizan modelos avanzados para detectar automáticamente campos de datos, gestionar paginación y scroll infinito, e incluso extraer datos de subpáginas—todo con una configuración mínima. Aquí es donde herramientas como marcan la diferencia, acercando la automatización a cualquier usuario, no solo a desarrolladores.
Automatización de Procesos para Web Scraping: ¿Por Qué es Importante?
¿Por qué molestarse en automatizar el web scraping? Porque recolectar datos manualmente es lento, propenso a errores y no escala. La automatización ofrece:
- Ahorro de tiempo: Los bots pueden extraer cientos de páginas en minutos—lo que antes llevaba días o semanas.
- Reducción de costes: al reemplazar la entrada manual de datos.
- Precisión: La automatización genera datos más consistentes y sin errores.
- Escalabilidad: Los raspadores automáticos pueden manejar miles de productos o millones de registros.
- Ventaja competitiva: Datos más rápidos y actualizados permiten mejores decisiones y respuestas ágiles.
Aquí tienes una tabla rápida de casos comunes de web scraping y los beneficios de automatizarlos:
| Caso de Uso de Web Scraping | Qué se Extrae y Por Qué | Beneficio de la Automatización |
|---|---|---|
| Monitoreo de Precios de la Competencia | Precios de productos, stock | Inteligencia de precios en tiempo real, ahorra horas de revisión manual |
| Generación de Leads | Nombres, emails, teléfonos | Llena el embudo de ventas 24/7, libera tiempo para vender |
| Investigación de Mercado | Reseñas, valoraciones | Agrega opiniones rápidamente, detecta tendencias |
| Agregación de Catálogos de Productos | Detalles de productos | Mantiene bases de datos actualizadas, acelera el lanzamiento al mercado |
| Listados Inmobiliarios | Precios, ubicaciones | Información diaria del mercado, permite informes completos |
| Extracción de Datos Financieros | Precios de acciones, informes | Actualizaciones en tiempo real, escala a miles de datos |
| Monitoreo de Cumplimiento | Uso de marca, políticas | Aplicación constante, alertas instantáneas, trazabilidad para auditoría |
En resumen: .
RPA vs Agente de IA: ¿Cómo Automatizan el Web Scraping?
Vamos a lo práctico. ¿Cómo abordan el web scraping RPA y los agentes de IA? Aquí tienes una comparación directa:
| Paso | Enfoque RPA | Enfoque Agente de IA |
|---|---|---|
| Configuración Inicial | El usuario graba cada acción, define cada campo | El usuario da la URL y describe los datos; la IA detecta los campos automáticamente |
| Flexibilidad | Frágil—falla si el sitio cambia | Adaptable—gestiona cambios de diseño y nuevos patrones |
| Datos Estructurados | Funciona bien | Funciona bien |
| Datos No Estructurados | Tiene dificultades | Destaca—puede analizar texto, imágenes y contexto |
| Paginación/Scroll | Requiere scripts explícitos | Lo detecta y gestiona automáticamente |
| Mantenimiento | Alto—requiere actualizaciones frecuentes | Bajo—la IA se adapta a cambios menores |
| Nivel Técnico Necesario | Medio—requiere configuración | Bajo—sin código, instrucciones en lenguaje natural |
| Escalabilidad | Limitada por licencias de bots | Nativo en la nube, escala fácilmente |
¿Cuándo Destaca Cada Uno?
- RPA es ideal cuando el sitio es estable y los datos están bien estructurados—por ejemplo, portales internos o sistemas antiguos.
- Los agentes de IA brillan cuando necesitas manejar webs dinámicas, desordenadas o que cambian a menudo, o si tu equipo no es técnico.
RPA para Web Scraping: El Camino Tradicional
Veamos un ejemplo real. Usando RPA (como UiPath o Automation Anywhere), harías:
- Grabar tu navegación: abrir el navegador, iniciar sesión, recorrer páginas, copiar datos.
- El bot repite estas acciones, recorriendo páginas y copiando datos a tu hoja de cálculo o base de datos.
Desafíos comunes:
- Cambios en la web: Un nuevo banner o botón renombrado puede romper el bot.
- Paginación: Scroll infinito o botones “Cargar más” requieren scripts adicionales.
- Contenido dinámico: Los bots necesitan esperas explícitas para cargar contenido.
- Medidas anti-bots: CAPTCHAs y bloqueos de IP pueden detener el RPA.
- Escalabilidad: Ejecutar muchos bots en paralelo puede ser costoso y complejo.
RPA es excelente para sitios internos y predecibles, pero para la web pública puede ser un dolor de cabeza en mantenimiento.
Raspador Web IA: La Nueva Generación de Automatización
Ahora, veamos cómo lo haría un raspador web IA:
- Abre la web, haz clic en “Sugerir Campos IA” y deja que la IA analice la página.
- La IA propone una tabla con los datos que puede extraer—nombres de productos, precios, valoraciones, etc.
- Ajustas o aceptas las sugerencias y haces clic en “Extraer”.
- El agente de IA gestiona automáticamente la paginación, sigue enlaces a subpáginas y exporta los datos a Excel, Google Sheets, Airtable o Notion.
Ventajas clave:
- Configuración mínima: Sin código ni etiquetado manual—solo describe lo que necesitas.
- Gestiona subpáginas y paginación: La IA detecta y sigue enlaces automáticamente.
- Análisis inteligente de datos: La IA puede limpiar, formatear e incluso categorizar los datos mientras los extrae.
- Exportaciones sencillas: Exporta con un clic a tus herramientas favoritas.
Para usuarios no técnicos (y también para los técnicos que valoran su tiempo), esto es un antes y un después. Es como pasar de un móvil plegable a un smartphone de última generación de un día para otro.
Thunderbit en Acción: Raspador Web IA como Agente de IA
Te cuento dónde he puesto mi energía (y más de una noche sin dormir): . Thunderbit es una extensión de Chrome para web scraping con IA que está evolucionando hacia un agente de IA completo para automatización web. ¿Nuestro objetivo? Que el web scraping sea tan fácil que hasta tu halmeoni pueda hacerlo (¡y hasta le guste!).
¿Qué Hace Diferente a Thunderbit?
- Sugerencia de Campos IA: Un solo clic y la IA lee la página y sugiere las mejores columnas para extraer.
- Extracción en Subpáginas: Thunderbit puede visitar cada subpágina (como fichas de producto) y enriquecer tu tabla de datos—sin configuración extra.
- Detección de Paginación: Ya sea un botón “Siguiente” o scroll infinito, la IA de Thunderbit lo detecta y sigue extrayendo.
- Exportación Instantánea: Exporta tus datos a Excel, Google Sheets, Airtable o Notion con un clic—sin costes adicionales.
- Sin Necesidad de Programar: Todo está pensado para usuarios de negocio, no solo para desarrolladores.
- Extracción en la Nube o en el Navegador: Elige extraer en la nube (rápido, en paralelo) o en tu navegador (ideal para sitios con login).
- Utilidades IA Gratis: Extrae emails, teléfonos o imágenes de cualquier web con un solo clic.
- Raspador Programado: Programa extracciones recurrentes con lenguaje natural—“cada día a las 9am”—y Thunderbit se encarga del resto.
Thunderbit está pensado para ser tu “asistente de datos web IA” en el navegador. No se trata solo de extraer datos, sino de automatizar todo el proceso, desde la extracción hasta la exportación, con la menor fricción posible. Y sí, esto es solo el principio. El futuro son agentes de IA capaces no solo de leer la web, sino de actuar sobre ella.
¿Quieres probarlo? .
Eligiendo la Herramienta Adecuada: ¿Cuándo Usar RPA, Agente de IA o Ambos?
Entonces, ¿cómo decidir entre RPA y agentes de IA (como Thunderbit) para automatizar tu web scraping? Aquí tienes una guía rápida:
| Factor de Decisión | RPA | Agente de IA / Raspador Web IA |
|---|---|---|
| Datos muy estructurados y sitio estable | ✅ | |
| Datos desordenados, no estructurados o sitio cambia a menudo | ✅ | |
| Necesidad de manejar contenido dinámico (scroll infinito, pop-ups) | ✅ | |
| El equipo tiene habilidades técnicas | ✅ | ✅ |
| El equipo no es técnico | ✅ | |
| Cumplimiento/auditoría requiere pasos estrictos y repetibles | ✅ | |
| Necesidad de escalar rápido o extraer de muchos sitios | ✅ | |
| Extracción puntual o ad-hoc | ✅ | |
| Proceso repetitivo y continuo | ✅ | ✅ |
| Quiero combinar fortalezas | Híbrido posible | Híbrido posible |
Tip: Muchas empresas ya combinan ambos enfoques—RPA para flujos internos y estructurados, y agentes de IA para datos web externos y cambiantes. El futuro es híbrido.
Superando Retos Comunes en la Automatización de Web Scraping
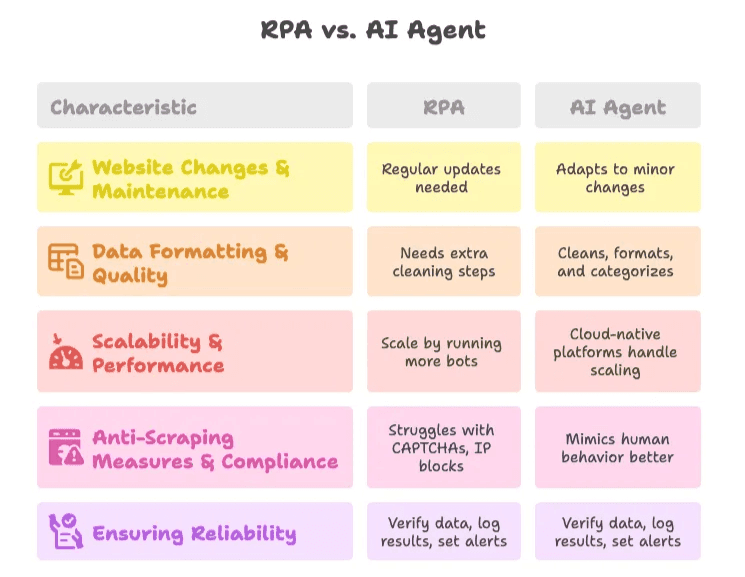
1. Cambios en la Web y Mantenimiento
- RPA: Requiere actualizaciones frecuentes cuando los sitios cambian. Usa scripts modulares y monitorización para detectar problemas a tiempo.
- Agente de IA: Más resistente—la IA se adapta a cambios menores, pero revisa los resultados periódicamente.
2. Formato y Calidad de los Datos
- RPA: Añade pasos extra para limpiar datos o integra scripts/Excel.
- Agente de IA: La IA puede limpiar, formatear y categorizar datos al extraerlos. Usa prompts específicos para mejores resultados.
3. Escalabilidad y Rendimiento
- RPA: Escala ejecutando más bots, pero cuidado con los límites y costes de infraestructura.
- Agente de IA: Plataformas en la nube como Thunderbit gestionan la escalabilidad por ti.
4. Medidas Anti-Scraping y Cumplimiento
- RPA: Puede tener problemas con CAPTCHAs y bloqueos de IP. Limítate a sitios donde tengas permiso.
- Agente de IA: Algunos agentes de IA imitan mejor el comportamiento humano, pero siempre respeta las políticas y la privacidad de datos.
5. Garantizar Fiabilidad
- Mejor Práctica: Verifica siempre los datos extraídos, registra resultados y configura alertas para anomalías. Haz revisiones manuales periódicas, sobre todo en procesos críticos.
El Futuro de la Automatización de Procesos: Agentes de IA a la Cabeza
Aquí es donde la cosa se pone interesante. El mundo está pasando de la automatización a la autonomía. Los agentes de IA ya no solo siguen instrucciones: empiezan a tomar decisiones, adaptarse a nuevos escenarios e incluso sugerir acciones según los datos que recogen.
- .
- Para 2028, .
- Las plataformas no-code y low-code están haciendo que el desarrollo de agentes de IA sea accesible para todos, no solo para IT.
En Thunderbit, trabajamos para ese futuro. Nuestra visión es que la automatización de procesos sea tan intuitiva que cualquiera pueda automatizar web scraping, recolección de datos e incluso flujos de trabajo con unos clics y una instrucción en lenguaje natural. No solo extraemos datos: estamos creando los agentes de IA que impulsarán la próxima ola de automatización empresarial.
¿Quieres ver hacia dónde va el futuro? Descubre más en el , o explora temas como y .
Reflexión Final
La automatización de procesos ya no es solo reemplazar trabajo manual: es empoderar a los equipos para hacer más, más rápido y con menos complicaciones. RPA y los agentes de IA tienen su lugar, pero la tendencia es clara: los raspadores web IA como Thunderbit hacen la automatización más inteligente, resistente y accesible para todos.
Si todavía sigues copiando y pegando datos a mano, es hora de dejar la cucharita y dejar que los robots hagan el trabajo pesado. Y si quieres descubrir lo que los agentes de IA pueden hacer por tu negocio, . Tu yo del futuro (y tu equipo) te lo agradecerán.
Preguntas Frecuentes
1. ¿Cuál es la diferencia entre RPA y los agentes de IA en la automatización de procesos?
RPA (Automatización Robótica de Procesos) sigue instrucciones estrictas y basadas en reglas para automatizar tareas repetitivas, ideal para entornos estables y estructurados. Los agentes de IA, en cambio, interpretan el contexto, se adaptan a cambios y gestionan datos no estructurados usando machine learning y procesamiento de lenguaje natural—perfectos para tareas de web scraping dinámicas y complejas.
2. ¿Por qué es importante la automatización de procesos para el web scraping?
El web scraping manual es lento, propenso a errores y no escala. Automatizar el web scraping ahorra tiempo, reduce costes, mejora la precisión y permite tomar decisiones en tiempo real al recolectar datos frescos de la web sin intervención manual.
3. ¿Cuándo debería usar RPA en vez de un raspador web IA como Thunderbit?
RPA es más adecuado para webs predecibles con datos estructurados y cuando se requiere documentación estricta de cumplimiento. Si tu equipo tiene habilidades técnicas y los sitios objetivo no cambian a menudo, RPA puede ser una opción fiable.
4. ¿Qué diferencia a Thunderbit de otras herramientas de scraping tradicionales?
Thunderbit utiliza IA para detectar campos automáticamente, gestionar paginación, extraer de subpáginas y exportar datos con un clic—sin necesidad de programar. Está pensado para usuarios de negocio y permite extracción en navegador o en la nube, haciendo la automatización accesible a quienes no son desarrolladores.
5. ¿Se pueden usar juntos RPA y agentes de IA?
Sí. Muchas empresas usan RPA para procesos internos y estables, y agentes de IA como Thunderbit para webs externas y dinámicas. Este enfoque híbrido aprovecha lo mejor de ambas tecnologías para una automatización más amplia y robusta.
Lecturas recomendadas: