

Algunas personas coleccionan sellos. Otras, zapatillas. Pero si trabajas en ventas, marketing, e-commerce u operaciones en 2026, lo más probable es que estés coleccionando algo un poco más… digital: datos web. Y no solo un poco. Las empresas ya están gastando una media de 5 millones de dólares al año en recopilación de datos web, y el web scraping ya es una herramienta estándar en todos los departamentos, desde estrategia hasta atención al cliente (fuente).
Con esta explosión de la demanda, dos nombres aparecen una y otra vez en cualquier tutorial de scraping con Python y en cualquier proyecto de datos empresariales: Playwright y Selenium. Ambos empezaron como herramientas de automatización de navegadores para pruebas, pero ahora son los frameworks de referencia para cualquiera que quiera convertir la web en datos estructurados y accionables. Pero aquí está el detalle: elegir entre ellos no es solo una decisión técnica; también implica escoger la herramienta adecuada para tus necesidades reales de scraping. Y si no eres desarrollador, o simplemente quieres resultados rápidos, hay un camino aún más sencillo (pista: no hace falta escribir ni una sola línea de Python). Vamos al grano.
De herramientas de prueba a potencias del web scraping: qué son Playwright y Selenium
Pongámonos en contexto. Selenium existe desde 2004 y es el veterano de confianza en automatización de navegadores. Creado originalmente para testers de QA, te permite controlar navegadores como Chrome, Firefox e incluso Internet Explorer (para quienes disfrutan vivir al límite). Playwright, por otro lado, irrumpió en 2020 respaldado por Microsoft, con una visión moderna de la automatización de navegadores: piensa en él como el hermano menor de Selenium, más rápido y más actual.
Ambas herramientas te permiten escribir scripts, a menudo en Python, que abren un navegador, navegan a un sitio web, hacen clic en botones, rellenan formularios y, lo más importante para nosotros, extraen datos. Aunque nacieron en el mundo de las pruebas automatizadas, se han convertido en la base del web scraping para todo, desde el seguimiento de precios hasta la generación de leads (fuente). Su popularidad no se limita a los desarrolladores: cada vez más usuarios de negocio se arremangan para crear sus propios scrapers, o al menos lo intentan.
Pero aquí está el giro: cuando haces scraping de datos, tus prioridades cambian. Te importa menos la cobertura de pruebas y más obtener los datos de forma fiable, evitar bloqueos y no pasar el fin de semana depurando errores de Python. Ahí es donde entran las diferencias reales entre Playwright y Selenium.
Diferencias clave: Playwright vs. Selenium para web scraping

Vamos al grano: Playwright y Selenium pueden hacer scraping de sitios web, pero brillan en escenarios distintos.
- Selenium es el veterano. Funciona con casi cualquier navegador y lenguaje, tiene una comunidad enorme y encaja muy bien con el scraping de sitios antiguos y estáticos con diseños predecibles.
- Playwright es el recién llegado con funciones modernas. Está pensado para los sitios dinámicos de hoy, cargados de JavaScript, con herramientas integradas para manejar inicios de sesión, pop-ups, scroll infinito y más. Además, es más rápido y más fácil de configurar, especialmente para usuarios de Python.
Pero no te quedes solo con mi palabra; vamos a analizarlo función por función.
Tabla comparativa de funciones: Playwright vs. Selenium
| Función | Selenium | Playwright |
|---|---|---|
| Compatibilidad con lenguajes | Python, Java, C#, JS, Ruby, más | Python, JS/TS, Java, C# |
| Compatibilidad con navegadores | Chrome, Firefox, Edge, Safari, IE, Opera | Chromium (Chrome/Edge), Firefox, WebKit |
| Complejidad de configuración | Necesita driver del navegador y configuración manual | Un solo comando instala todo |
| Velocidad/rendimiento | Más lento, consume más recursos | Por lo general, más rápido en páginas con mucho JavaScript; diseñado para trabajo asíncrono y concurrente |
| Manejo de contenido dinámico | Esperas manuales, requiere más código | Autoespera; maneja con facilidad sitios cargados de JavaScript |
| Evasión anti-bots | Más propenso a la detección; necesita complementos | Stealth integrado; mejor imitando usuarios |
| Herramientas de depuración | Básicas (Selenium IDE, capturas de pantalla) | Inspector, grabación de vídeo, codegen |
| Soporte de la comunidad | Enorme, maduro, con muchísimos tutoriales | Crece rápido, documentación moderna, desarrolladores activos |
| Flujo de trabajo de scraper en Python | Más configuración, más código repetitivo | Más fluido, menos código, más fácil para principiantes |
Cómo elegir la herramienta adecuada: cuándo usar Playwright o Selenium para web scraping
Entonces, ¿cuál deberías elegir para tu próximo proyecto de scraping? Esta es mi opinión, después de años creando herramientas de automatización y ayudando a equipos a sacar datos del salvaje oeste de la web.
- Selenium te conviene si:
- El sitio que vas a scrapear es clásico: HTML estático, poco JavaScript y sin pop-ups sofisticados.
- Necesitas compatibilidad con navegadores raros (hola, Internet Explorer) o integrarte con sistemas heredados.
- Quieres la tranquilidad de una comunidad enorme y respuestas interminables en StackOverflow.
- Ya conoces Selenium de proyectos de pruebas.
- Playwright es la mejor opción si:
- El sitio es moderno, dinámico y está lleno de JavaScript (piensa en e-commerce, redes sociales o cualquier cosa que haga girar el ventilador de tu portátil).
- Necesitas iniciar sesión, navegar por pestañas, manejar scroll infinito o lidiar con pop-ups.
- Quieres empezar rápido, con menos configuración y menos código.
- Estás cansado de escribir
time.sleep(5)por todas partes y quieres que la herramienta gestione los tiempos por ti.
Una regla sencilla: si tu primer intento de scrapear un sitio con Selenium termina en muchos momentos de “¿por qué no carga esto?”, probablemente ya sea hora de probar Playwright.
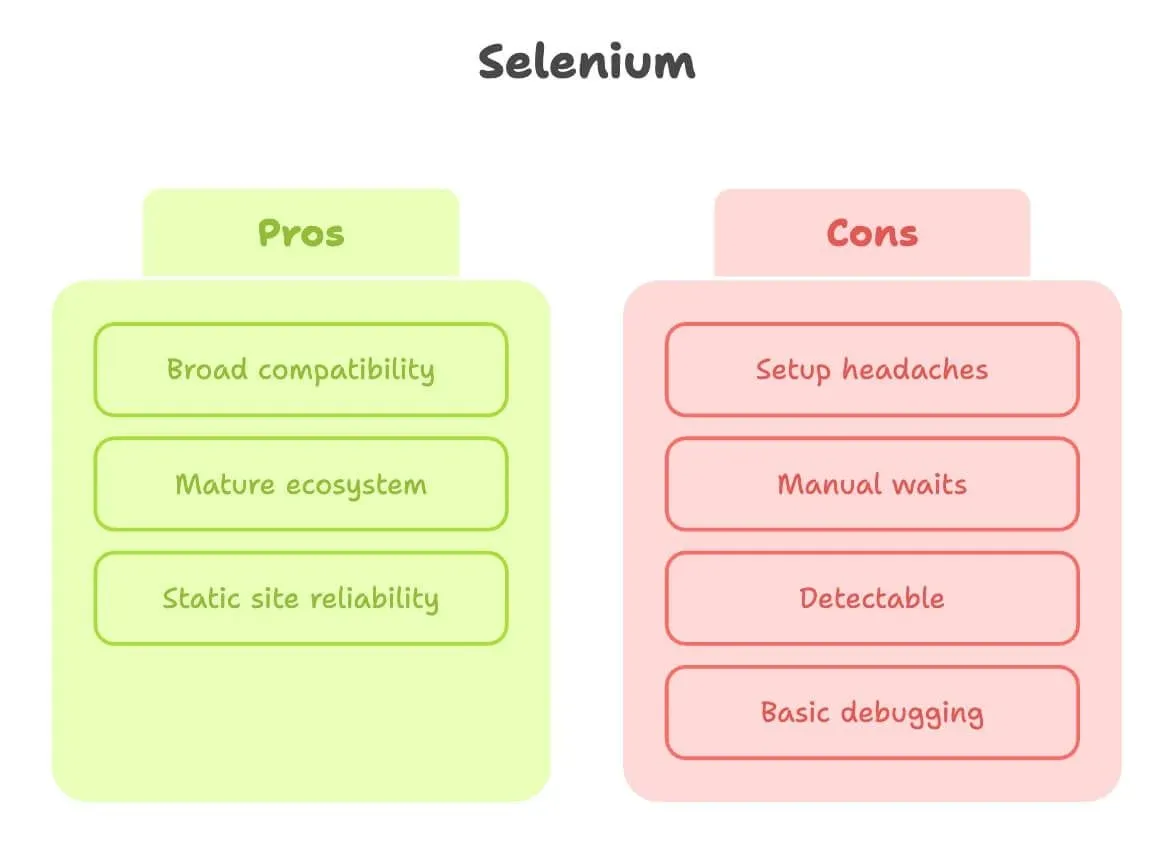
Selenium para web scraping: ventajas y limitaciones
Démosle a Selenium lo que merece. Es el abuelo de la automatización de navegadores y, para muchas tareas de scraping, simplemente funciona.
Ventajas:
- Amplia compatibilidad: funciona con casi cualquier navegador y lenguaje.
- Ecosistema maduro: montones de tutoriales, Q&A y plugins.
- Ideal para sitios estáticos: si la página no cambia mucho, Selenium es muy sólido.
Limitaciones:
- Dolores de cabeza en la configuración: tienes que descargar y configurar un driver del navegador, como ChromeDriver, y mantenerlo actualizado. Los principiantes suelen atascarse aquí (fuente).
- Esperas manuales: ¿contenido dinámico? Vas a escribir muchas esperas explícitas o, peor aún, sentencias
sleepaleatorias. - Más fácil de detectar: muchos sitios pueden identificar navegadores controlados por Selenium y bloquearlos, especialmente si ejecutas el scraping en un servidor en la nube.
- La depuración es básica: no incluye grabación de vídeo ni inspector interactivo integrados.
En resumen, Selenium es perfecto para sitios simples y estables, pero puede sentirse como empujar una roca cuesta arriba en páginas modernas e interactivas.
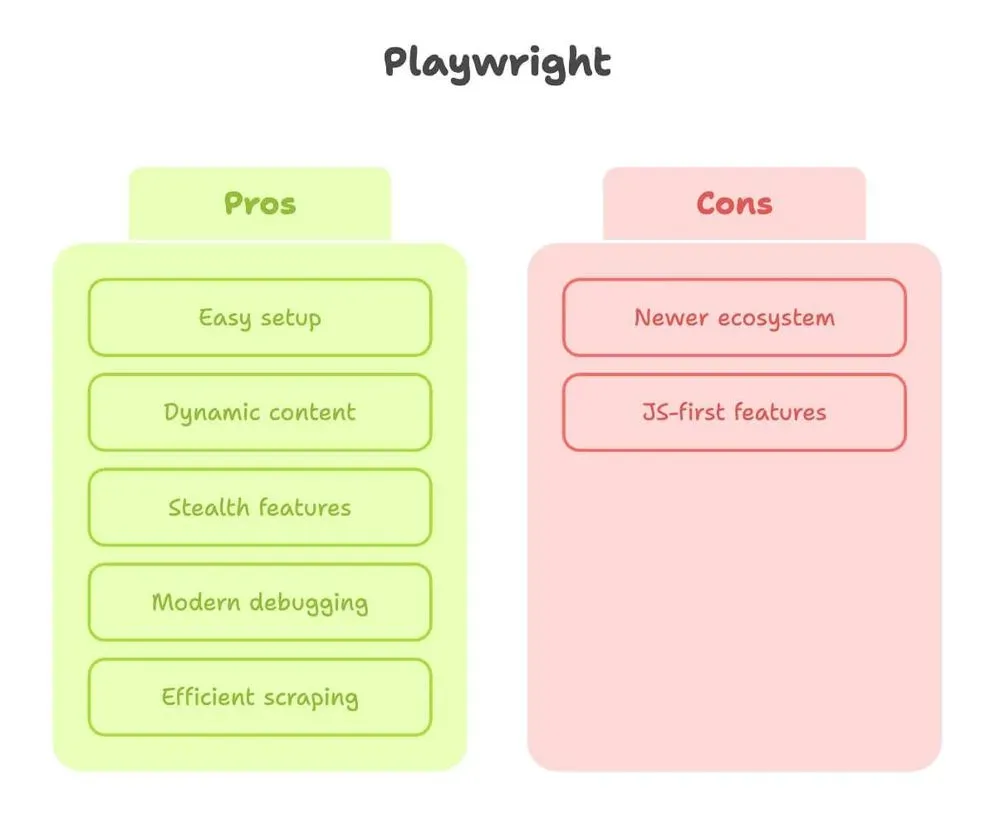
Playwright para web scraping: ventajas y limitaciones
Ahora hablemos de Playwright. Como alguien que ha pasado mucho tiempo peleándose con ambas herramientas, puedo decir que Playwright parece construido por gente que de verdad ha sufrido haciendo scraping.
Ventajas:
- Configuración sencilla: un
pip install, un comando y listo. Sin dramas con drivers. - Maneja contenido dinámico: espera automáticamente a que los elementos carguen, así que no tienes que adivinar cuándo la página está lista (fuente).
- Funciones de stealth: imita mejor a usuarios reales, con modo sigiloso integrado y soporte para múltiples contextos (ideal para scrapear como varios “usuarios” a la vez).
- Depuración moderna: inspector, grabación de vídeo e incluso generación de código a partir de tus clics manuales.
- Más rápido y eficiente: sobre todo para scrapear muchas páginas o ejecutar procesos en paralelo.
Limitaciones:
- Ecosistema más reciente: hay algo menos de tutoriales, aunque la diferencia se está reduciendo rápido.
- Algunas funciones son más “first JavaScript”: la mayoría funciona en Python, pero a veces encontrarás alguna característica mejor documentada en JS.
En pocas palabras: Playwright es mi opción preferida para cualquier sitio que sea aunque sea un poco dinámico, o cuando quiero resultados rápidos sin pelearme con la configuración.
Evasión anti-bots: ¿qué scraper en Python maneja mejor los sitios modernos?
Hablemos del elefante en la habitación: que te bloqueen. En web scraping, la parte más difícil no es escribir código, sino asegurarte de que el sitio no te cierre la puerta en las narices.
- Selenium: de entrada, es más fácil de detectar. Los sitios pueden ver la bandera
webdriver, los user agents en modo headless y otras señales evidentes. Hay soluciones alternativas (como undetected-chromedriver), pero requieren configuración extra y siempre van a la zaga de la tecnología anti-bots (fuente). - Playwright: incluye funciones de stealth integradas, como ocultar automáticamente huellas de automatización, admitir múltiples contextos de navegador y esperar interacciones que se parezcan más a las de un usuario real. No es magia, pero es menos probable que te bloqueen al primer intento.
Pero esta es la verdad: ninguna herramienta es completamente inmune a las medidas anti-bot. Para scraping de alto riesgo (como lanzamientos de zapatillas o sitios de venta de entradas), seguirás necesitando proxies, rotación de IPs e incluso resolver CAPTCHAs. Playwright solo hace que duela un poco menos.
Experiencia del desarrollador: configuración, curva de aprendizaje y depuración
Hablemos de la experiencia real de empezar, especialmente si eres principiante o solo quieres terminar el trabajo sin un doctorado en Python.
- Selenium:
- Configuración: instala Python, instala Selenium, descarga el driver correcto del navegador, ponlo en tu PATH y reza para haber acertado con las versiones. (He visto a más personas atascadas en el paso del driver que en el scraping propiamente dicho.)
- Curva de aprendizaje: muchos recursos, pero también mucho código heredado y tutoriales desactualizados.
- Depuración: sobre todo
printy capturas de pantalla. Selenium IDE existe, pero es básico.
- Playwright:
- Configuración:
pip install playwrighty luegoplaywright install. Hecho. - Curva de aprendizaje: documentación moderna, muchos ejemplos y una API que se siente más “humana”: puedes seleccionar elementos por texto, rol o incluso placeholder.
- Depuración: el inspector te permite avanzar paso a paso por tu script, ver el navegador e incluso grabar vídeos de tus ejecuciones de scraping (fuente).
- Configuración:
Si quieres ver resultados rápido y dedicar menos tiempo a la configuración y a resolver problemas, Playwright es el ganador claro. Selenium es genial si ya estás cómodo con sus peculiaridades o necesitas su amplia compatibilidad.
Paso a paso: construir tu primer scraper web en Python con Playwright o Selenium
Veamos cómo se construye realmente un scraper con cada herramienta, sin código, solo los pasos.
Playwright (Python):
- Instala Playwright y los navegadores:
pip install playwright+playwright install - Abre el navegador: inicia Chromium, Firefox o WebKit (con o sin interfaz).
- Ve a la página: usa
page.goto("<https://example.com>") - Espera el contenido: Playwright espera automáticamente a que los elementos carguen.
- Extrae los datos: usa selectores fáciles de leer, como
get_by_textolocator("span.price"). - Gestiona la paginación o las subpáginas: recorre páginas o haz clic en enlaces; Playwright facilita ejecutar varias páginas en paralelo.
- Exporta los datos: guárdalos en CSV, Excel o una base de datos.
- Depura: usa el inspector o la grabación de vídeo si algo sale mal.
Selenium (Python):
- Instala Selenium:
pip install selenium - Descarga el driver del navegador: por ejemplo, ChromeDriver para Chrome, y añádelo a tu PATH.
- Abre el navegador: inicia Chrome, Firefox u otro navegador.
- Ve a la página:
driver.get("<https://example.com>") - Espera el contenido: añade manualmente esperas explícitas (
WebDriverWait) o, si te sientes con suerte,time.sleep. - Extrae los datos: usa
find_elementofind_elements(selectores CSS/XPath). - Gestiona la paginación o las subpáginas: recorre URLs o haz clic en botones, pero tendrás que controlar tú mismo los tiempos y la navegación.
- Exporta los datos: guárdalos en CSV, Excel o una base de datos.
- Depura: en gran parte manual: observa el navegador, imprime HTML o toma capturas de pantalla.
¿Notas la diferencia? Playwright es un poco más “enchufar y usar” para los sitios modernos.
Más allá del código: web scraping sin código con Thunderbit AI Web Scraper
Extrae datos de cualquier sitio web usando IA Get Started Free
Seamos sinceros. No todo el mundo quiere convertirse en gurú de Python solo para obtener una tabla de precios de productos o una lista de leads. Quizá trabajas en ventas, marketing, inmobiliaria u operaciones, y lo único que quieres son los datos—ahora. Ahí es donde entra Thunderbit.
Como cofundador de Thunderbit, he visto de primera mano cuántos usuarios de negocio solo quieren saltarse la programación y llegar a lo importante. Por eso creamos una extensión de Chrome con IA que te permite extraer datos de cualquier sitio web en dos clics: sin Python, sin drivers, sin depuración.
Cómo funciona Thunderbit
- Ve al sitio web que quieres scrapear.
- Haz clic en “Sugerir campos con IA”. La IA de Thunderbit analiza la página y recomienda los campos de datos (como nombre del producto, precio, imagen o valoración).
- Haz clic en “Extraer”. Al instante obtienes una tabla estructurada de datos.
- Exporta a Excel, Google Sheets, Airtable, Notion, CSV o JSON. Y listo.
Sin pelearte con selectores, sin pruebas y errores, sin código. Es tan fácil como pedir comida para llevar (y, seamos honestos, probablemente más rápido que esperar a que llegue).
Prueba Thunderbit AI Web Scraper gratis
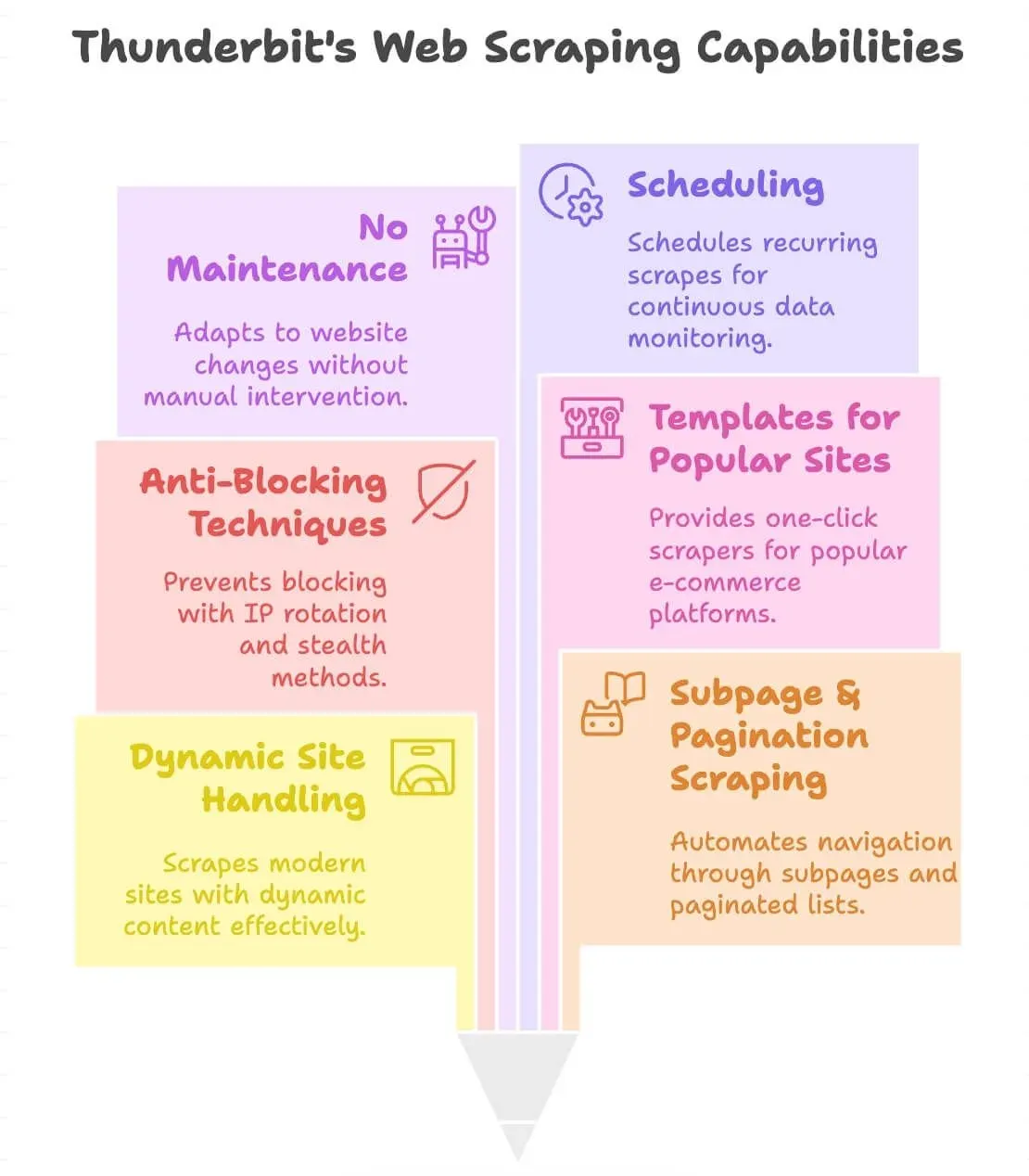
¿Qué hace diferente a Thunderbit?
- Maneja sitios dinámicos: extrae datos de e-commerce moderno, directorios e incluso sitios con scroll infinito o pop-ups.
- Scraping de subpáginas y paginación: hace clic automáticamente en páginas de productos o listas paginadas para obtener todos los datos que necesitas.
- Antibloqueo integrado: usa rotación de IPs en el backend y técnicas de stealth, para que sea menos probable que te bloqueen.
- Plantillas para sitios populares: scrapers con un clic para Amazon, eBay, Shopify, Zillow y más (consulta nuestro blog para más detalles).
- Menor mantenimiento: cuando cambia el diseño de un sitio, el paso de “Sugerir campos con IA” suele volver a detectar los campos, así que normalmente basta con repetir ese paso en lugar de reconstruir un script de selectores desde cero.
- Programación: configura extracciones recurrentes para monitorización continua (por ejemplo, revisiones diarias de precios).
- Compatible con 55 idiomas: extrae y traduce datos desde prácticamente cualquier lugar.
¿Y lo mejor? No necesitas saber nada de HTML, CSS ni Python. Si sabes usar un navegador, puedes usar Thunderbit.
¿Qué solución de web scraping es la adecuada para ti?
Cerramos con una guía rápida de decisión:
| Tu situación | Mejor herramienta |
|---|---|
| Scraping de un sitio estático y sencillo; no te importa la configuración | Selenium |
| Scraping de un sitio moderno y dinámico; quieres resultados rápidos | Playwright |
| Necesitas compatibilidad con navegadores o lenguajes heredados | Selenium |
| Quieres configuración fácil, depuración moderna y menos código | Playwright |
| No eres desarrollador; quieres datos ya, sin código ni configuración | Thunderbit |
| Necesitas scrapear varias páginas, subpáginas o programar tareas | Thunderbit |
| Quieres exportar directamente a Excel, Sheets, Notion o Airtable | Thunderbit |
| Odias depurar errores de Python | Thunderbit |
Si eres desarrollador o te encanta trastear con código, Playwright y Selenium son opciones potentes. Pero si tu objetivo es llevar datos a una hoja de cálculo lo más rápido posible, Thunderbit te ahorrará horas, quizá incluso días, de trabajo.
Empieza con Thunderbit AI Web Scraper
Conclusión: web scraping rápido y fiable, a tu manera
El web scraping se ha vuelto algo común, y con razón: las empresas necesitan datos para competir, y los necesitan ya. Playwright y Selenium han pasado de ser humildes herramientas de pruebas a frameworks esenciales de scraping, cada uno con sus propias fortalezas. Selenium sigue siendo el veterano fiable para sitios estáticos y configuraciones heredadas; Playwright es la opción moderna y rápida para páginas dinámicas e interactivas.
Pero aquí va mi consejo honesto, después de años en SaaS, automatización e IA: si no estás en esto por la programación, no pierdas el tiempo peleándote con drivers, selectores y trucos anti-bot. Con AI Web Scraper de Thunderbit, puedes pasar de “necesito estos datos” a “aquí está mi archivo de Excel” en minutos, no en días.
Así que, tanto si eres un profesional de Python como si eres un usuario de negocio que solo quiere resultados, hay una solución de scraping que encaja con tus necesidades y con tu paciencia. Pruébalas, comprueba cuál funciona mejor para tu flujo de trabajo y recuerda: el mejor scraper es el que te da los datos que necesitas con el menor esfuerzo posible.
Y si alguna vez te encuentras a las 2 de la mañana depurando un error de Selenium driver, que sepas que Thunderbit seguirá aquí, listo para scrapear en dos clics. Feliz scraping.
¿Quieres aprender más sobre scraping sin código, extracción de datos con IA y cómo Thunderbit puede ayudar a tu equipo? Echa un vistazo a nuestro blog o empieza hoy mismo con la extensión de Chrome de Thunderbit.
P.D. Si todavía no sabes qué herramienta usar, o quieres ver Thunderbit en acción, pásate por nuestro canal de YouTube para ver demos, consejos y algún que otro chiste sobre web scraping. (Sí, también tenemos de esos.)
Lecturas recomendadas:
- Qué es la extracción de datos y cómo hacerlo en 2025
- Cómo extraer productos y reseñas de Amazon en 2025 usando IA
- Las mejores herramientas y software de web scraping en 2025
Prueba AI Web Scraper Get Started Free




