

La primera vez que muchos se animan a probar el raspado web suele ser por pura curiosidad y con una meta sencilla, como sacar información de productos de la web de un competidor. BeautifulSoup aparece enseguida en Google, pero al principio puede parecer un poco enredado. Después de varios intentos, conseguir que funcione el comando pip install beautifulsoup4 y extraer un elemento HTML básico—como un titular—es ese momento “¡eureka!” que engancha a quienes empiezan con Python.
Si apenas estás dando tus primeros pasos en el mundo del raspado web, seguramente BeautifulSoup será la primera herramienta que escucharás nombrar. Y no es casualidad: es fácil de usar, potente y lleva más de diez años siendo la biblioteca de referencia para scraping en Python. En esta guía te explico paso a paso cómo instalar BeautifulSoup usando pip, te muestro ejemplos prácticos y te cuento por qué sigue siendo la favorita de muchos desarrolladores y analistas de datos. Pero también te hablaré con sinceridad sobre sus limitaciones—y por qué cada vez más equipos (sobre todo quienes no programan) prefieren soluciones con IA como Thunderbit.
¿Qué es BeautifulSoup y por qué sigue siendo tan popular?
BeautifulSoup vs. AI Web Scraper: Comparativa completa Get Started Free
Vamos a lo básico: ¿qué es exactamente BeautifulSoup? Imagínala como una “lupa” para HTML en Python. Le das un trozo de HTML o XML y te lo transforma en una estructura de árbol fácil de recorrer, buscar y analizar con código Python. Es como tener visión de rayos X para páginas web: de repente, todo ese código desordenado se convierte en datos que puedes manipular.
¿Por qué BeautifulSoup sigue siendo tan usada?
Aunque han salido frameworks más modernos, BeautifulSoup sigue siendo la puerta de entrada para la mayoría de quienes empiezan con Python. De hecho, se descarga más de 150 millones de veces al mes desde PyPI. Y no es solo fama: en Stack Overflow hay más de 32,000 preguntas etiquetadas como “beautifulsoup”, lo que significa que hay una comunidad enorme y mucho apoyo para quienes empiezan.
Usos más comunes:
- Extraer información de productos de tiendas online (nombres, precios, valoraciones)
- Obtener titulares de noticias o contenido de blogs para análisis o agregadores
- Parsear tablas o directorios para conseguir datos estructurados (como listados de empresas)
- Generar leads sacando emails o teléfonos de directorios
- Monitorear cambios (precios, nuevas ofertas de empleo, etc.)
BeautifulSoup es especialmente útil para páginas web estáticas—sitios donde los datos están directamente en el HTML. Es flexible, tolerante (incluso con HTML mal hecho) y no te obliga a seguir una estructura rígida. Por eso, incluso en 2025, sigue siendo la “primera opción” para quienes empiezan a hacer scraping con Python (más sobre su popularidad).
Instalar BeautifulSoup con pip: la forma más fácil de empezar
¿Qué es pip y por qué usarlo?
Si eres nuevo en Python, pip es el gestor de paquetes que te permite instalar librerías desde el Python Package Index (PyPI). Es como la Play Store, pero para código Python. Instalar BeautifulSoup con pip es la manera más rápida y segura de empezar.
Consejo: El nombre correcto del paquete es beautifulsoup4 (no solo beautifulsoup). Asegúrate de poner el “4” para tener la versión más actual.
Paso a paso: cómo instalar BeautifulSoup
1. Verifica tu versión de Python
BeautifulSoup necesita Python 3.7 o superior. Puedes comprobar tu versión en la terminal:
python --version
o
python3 --version
2. Instala BeautifulSoup4 con pip
Abre la terminal o el símbolo del sistema y ejecuta:
pip install beautifulsoup4
Si tienes varias versiones de Python, puede que necesites:
pip3 install beautifulsoup4
En Windows, también puedes usar:
py -m pip install beautifulsoup4
3. (Opcional, pero recomendable) Instala un parser
BeautifulSoup funciona de serie con el parser integrado de Python ("html.parser"), pero para mayor velocidad y precisión, instala lxml y html5lib:
pip install lxml html5lib
4. (Opcional) Instala Requests
BeautifulSoup no descarga páginas web, solo analiza HTML. La mayoría usa la librería Requests para obtener el contenido:
pip install requests
5. Verifica la instalación
Haz una prueba en Python:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
Si ves <title>Example Domain</title>, todo está funcionando.
Instalar BeautifulSoup en un entorno virtual
Siempre recomiendo usar un entorno virtual para tus proyectos en Python. Así mantienes tus dependencias ordenadas y evitas líos.
Cómo crearlo:
python -m venv venv
# En Windows:
venv\Scripts\activate
# En macOS/Linux:
source venv/bin/activate
pip install beautifulsoup4 requests lxml html5lib
Todo lo que instales quedará dentro de la carpeta del proyecto. Olvídate de los típicos problemas de “¿por qué no encuentro el paquete?”.
Métodos alternativos de instalación (Conda, etc.)
Si usas Anaconda, puedes instalar BeautifulSoup con:
conda install beautifulsoup4
Y para el parser:
conda install lxml
Asegúrate de tener activado tu entorno conda antes de instalar.
BeautifulSoup en Python: primeros pasos con ejemplos de código
Vamos a la práctica. Así se usa BeautifulSoup en un script real de Python.
Ejemplo 1: Descargar una página y extraer el título
from bs4 import BeautifulSoup
import requests
url = "https://en.wikipedia.org/wiki/Python_(programming_language)"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# Obtener el título de la página
title_text = soup.title.string
print("Título de la página:", title_text)
Este script descarga la página de Wikipedia sobre Python, analiza el HTML y muestra el título. Fácil, ¿no?
Ejemplo 2: Extraer todos los enlaces
links = soup.find_all('a')
for link in links[:10]: # Muestra los primeros 10 enlaces
href = link.get('href')
text = link.get_text()
print(f"{text}: {href}")
Esto imprime el texto y la URL de los primeros 10 enlaces de la página.
Ejemplo 3: Extraer titulares
headings = soup.find_all('h2')
for h in headings:
print(h.get_text().strip())
¿Quieres sacar todos los titulares <h2>? Así de sencillo.
Ejemplo 4: Usar selectores CSS
items = soup.select("ul.menu > li")
for item in items:
print(item.get_text())
El método select() te permite usar selectores CSS como los de siempre.
Ejemplo 5: Obtener atributos y etiquetas anidadas
first_link = soup.find('a')
print(first_link['href']) # Acceso directo (lanza error si no existe)
print(first_link.get('href')) # Acceso seguro (devuelve None si no existe)
Ejemplo 6: Extraer todo el texto
text_content = soup.get_text()
print(text_content)
Esto saca todo el texto de la página—ideal para análisis rápidos.
Tareas comunes con BeautifulSoup para principiantes
Estas son algunas de las tareas más habituales con BeautifulSoup:
-
Buscar un solo elemento:
soup.find('div', class_='price') -
Buscar todos los elementos:
soup.find_all('p', class_='description') -
Obtener el texto de un elemento:
element.get_text() -
Obtener el valor de un atributo:
element.get('href') -
Usar selectores CSS:
soup.select('table.data > tr') -
Manejar elementos que pueden faltar:
price = soup.find('span', class_='price') if price: print(price.get_text())
La sintaxis es clara, fácil de leer y tolerante, incluso si el HTML está desordenado (ver documentación).
Las limitaciones de BeautifulSoup para el raspado web moderno
Ahora, hablemos de los puntos flojos. BeautifulSoup es ideal para páginas estáticas y proyectos pequeños, pero no todo es color de rosa.
Principales inconvenientes:
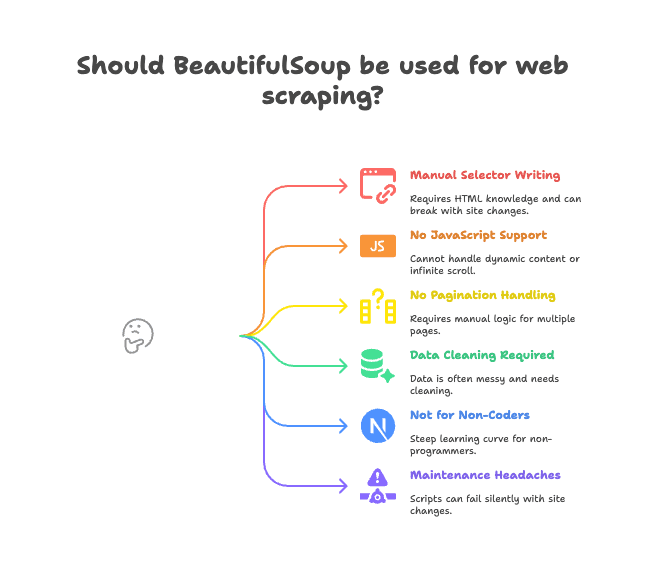
- Selectores manuales: Tienes que leer el HTML y escribir las rutas correctas de etiquetas o clases. Si el sitio cambia, tu script deja de funcionar.
- Sin soporte para JavaScript: BeautifulSoup solo ve el HTML que manda el servidor. Si la web carga datos con JavaScript (scroll infinito, contenido dinámico), no podrás acceder a ellos (más información).
- No gestiona paginación ni subpáginas: Si quieres sacar datos de varias páginas o entrar en detalles de productos, tienes que programar toda la lógica.
- Requiere limpieza de datos: Los datos suelen venir con espacios de más, caracteres raros o formatos inconsistentes.
- No apto para quienes no programan: Si trabajas en ventas, marketing u operaciones y no sabes programar, BeautifulSoup puede ser complicado.
- Mantenimiento constante: Si la web cambia su estructura, tu script puede fallar sin avisar o dejar de extraer datos.
Para muchos equipos, estos “pequeños” problemas terminan siendo verdaderos cuellos de botella. He visto proyectos que se frenan porque el script de scraping necesita arreglos todo el tiempo.
Por qué los equipos están migrando a Thunderbit para extraer datos web
Prueba Thunderbit AI Web Scraper Extrae datos de cualquier web con IA. Sin programar. Get Started Free
¿La alternativa? Aquí es donde entra Thunderbit. Thunderbit no es solo otra librería de Python—es una extensión de Chrome que funciona como un asistente inteligente para extraer datos web.
¿Cómo funciona?
- Abres la web de la que quieres extraer datos.
- Haces clic en “AI Sugerir Campos”—la IA de Thunderbit analiza la página y te sugiere las columnas adecuadas (como “Nombre del producto”, “Precio”, “Ubicación”).
- Puedes ajustar los nombres y tipos de columnas si lo deseas.
- Haces clic en “Extraer” y Thunderbit recopila, limpia y estructura los datos por ti.
- Exporta a Excel, Google Sheets, Notion, Airtable o tu herramienta favorita con un solo clic.
Sin código. Sin selectores. Sin dolores de cabeza por mantenimiento.
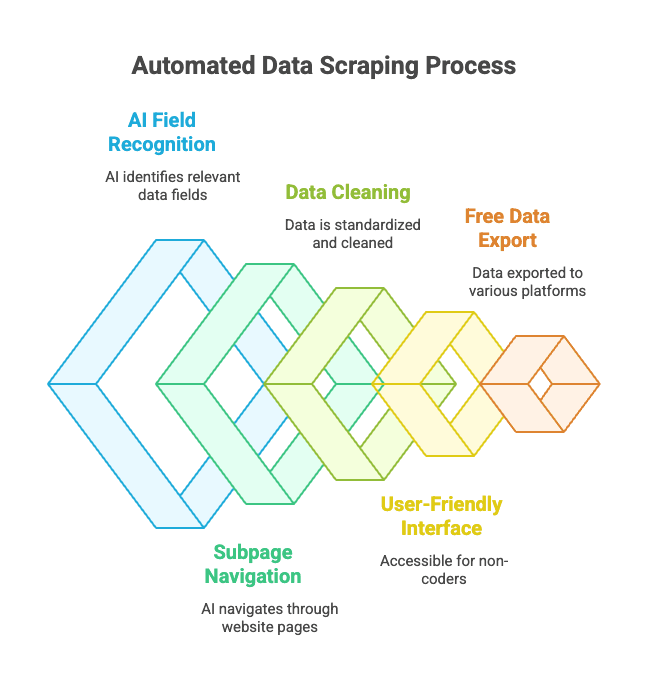
Ventajas clave de Thunderbit:
- Reconocimiento de campos con IA: La IA identifica los datos relevantes, incluso si el HTML está desordenado.
- Extracción de subpáginas y paginación: Puede entrar en páginas de productos o manejar enlaces de “siguiente página” automáticamente.
- Limpieza y formato de datos: Thunderbit estandariza teléfonos, emails, imágenes y más.
- Fácil para quienes no programan: Si sabes usar un navegador, puedes usar Thunderbit.
- Exportación gratuita de datos: Exporta a Excel, Google Sheets, Airtable, Notion—sin coste para exportaciones básicas.
- Scraping programado: Puedes programar extracciones automáticas y olvidarte del proceso.
Para usuarios de negocio, esto cambia por completo la forma de extraer datos web. En vez de pelear con scripts de Python, solo apuntas, haces clic y obtienes tus datos.
Prueba Thunderbit AI Web Scraper gratis
Thunderbit vs. BeautifulSoup: ¿cuál te conviene?
Veamos la comparación:
| Funcionalidad | BeautifulSoup (Código Python) | Thunderbit (IA sin código) |
|---|---|---|
| Instalación | Requiere Python, pip, código | Extensión de Chrome, instalación en 2 clics |
| Velocidad para obtener datos | Horas para el primer script | Minutos por sitio |
| Soporta JavaScript | No (requiere herramientas extra) | Sí (funciona en el navegador) |
| Paginación/Subpáginas | Requiere código manual | Integrado, opción con un clic |
| Limpieza de datos | Manual, con código | Automática, con IA |
| Opciones de exportación | Debes programar tu propio CSV/Excel | Un clic a Sheets, Notion, etc. |
| Ideal para | Desarrolladores, entusiastas | Usuarios de negocio, sin experiencia técnica |
| Costo | Gratis (pero consume tiempo) | Freemium (gratis para tareas pequeñas) |
Cuándo usar BeautifulSoup:
- Si te manejas bien con Python y quieres control total.
- Si vas a extraer datos de sitios estáticos o necesitas lógica personalizada.
- Si integras el scraping en un flujo de trabajo más grande en Python.
Cuándo usar Thunderbit:
- Si necesitas resultados rápidos y sin programar.
- Si tienes que extraer datos de sitios dinámicos (con JavaScript).
- Si trabajas en ventas, marketing, operaciones o simplemente no quieres lidiar con código.
- Si quieres exportar datos directamente a tus herramientas de negocio.
La verdad, incluso como desarrollador, a veces uso Thunderbit cuando quiero extraer datos rápido sin montar un proyecto en Python. Es como tener un superpoder en el navegador.
Buenas prácticas para instalar y usar BeautifulSoup
Si decides seguir con BeautifulSoup, aquí tienes algunos consejos para evitar problemas:
- Usa siempre un entorno virtual: Mantén tus dependencias organizadas y evita el clásico “en mi máquina sí funciona”.
- Mantén pip y los paquetes actualizados: Ejecuta
pip install --upgrade pipypip list --outdatedcon frecuencia. - Instala los parsers recomendados:
pip install lxml html5libpara mejor rendimiento y robustez. - Escribe código modular: Separa la lógica de descarga y análisis para facilitar el mantenimiento.
- Respeta robots.txt y limita la frecuencia de peticiones: No satures los sitios—usa
time.sleep()entre solicitudes. - Usa selectores descriptivos pero estables: Evita rutas demasiado específicas que se rompen fácilmente.
- Prueba el análisis con HTML guardado: Descarga una página y prueba tu código offline para no hacer peticiones repetidas.
- Aprovecha la comunidad: Stack Overflow es tu mejor aliado para resolver dudas.
Solución de problemas al instalar BeautifulSoup
¿Tienes problemas? Aquí tienes una lista rápida de comprobación:
- “ModuleNotFoundError: No module named bs4”
- ¿Instalaste
beautifulsoup4en el entorno correcto? Prueba conpython -m pip install beautifulsoup4.
- ¿Instalaste
- Instalaste el paquete incorrecto (
beautifulsoupen vez debeautifulsoup4)- Desinstala el antiguo:
pip uninstall beautifulsoup - Instala el correcto:
pip install beautifulsoup4
- Desinstala el antiguo:
- Avisos del parser o errores Unicode
- Instala
lxmlyhtml5lib, y especifica el parser:BeautifulSoup(html, "lxml")
- Instala
- No encuentra elementos
- ¿Los datos se cargan con JavaScript? BeautifulSoup no los verá. Revisa el código fuente de la página, no el DOM renderizado.
- Errores de pip o permisos
- Usa un entorno virtual, o prueba con
pip install --user beautifulsoup4 - Actualiza pip:
pip install --upgrade pip
- Usa un entorno virtual, o prueba con
- Problemas con conda
- Prueba
conda install beautifulsoup4o usa pip dentro de tu entorno conda.
- Prueba
¿Sigues atascado? La documentación de BeautifulSoup y Stack Overflow cubren casi cualquier escenario.
Conclusión: puntos clave para instalar y usar BeautifulSoup
-
BeautifulSoup es la biblioteca de scraping más popular en Python—es sencilla, flexible y perfecta para quienes empiezan.
-
Instálala con pip:
pip install beautifulsoup4 lxml html5lib requests -
Usa un entorno virtual para mantener tu entorno limpio.
-
BeautifulSoup es ideal para páginas estáticas y proyectos pequeños, pero tiene limitaciones con JavaScript, paginación y mantenimiento.
-
Thunderbit es la alternativa moderna con IA para usuarios de negocio y quienes no programan—sin código, sin complicaciones, solo datos.
-
Elige la herramienta adecuada para tus necesidades:
- Desarrolladores y entusiastas: BeautifulSoup te da control total.
- Usuarios de negocio y equipos: Thunderbit te da resultados rápidos.
Prueba ambos enfoques—muchas veces, la mejor solución es la que te permite avanzar sin complicaciones.
Prueba Thunderbit AI Web Scraper gratis Get Started Free
Preguntas frecuentes: pip install BeautifulSoup y más allá
P: ¿Cuál es la diferencia entre beautifulsoup y beautifulsoup4?
R: Siempre instala beautifulsoup4—es la versión más reciente y compatible. El paquete antiguo beautifulsoup está obsoleto y no funciona con Python 3. Se importa como from bs4 import BeautifulSoup (más detalles aquí).
P: ¿Debo instalar lxml o html5lib junto con BeautifulSoup?
R: No es obligatorio, pero sí muy recomendable. Mejoran la velocidad y robustez del análisis. Instálalos con pip install lxml html5lib (por qué es importante).
P: ¿BeautifulSoup puede manejar sitios web con mucho JavaScript?
R: No—BeautifulSoup solo ve el HTML estático. Para contenido generado por JavaScript, usa herramientas como Selenium o prueba una solución con IA en el navegador como Thunderbit (más información).
P: ¿Cómo desinstalo BeautifulSoup?
R: Ejecuta pip uninstall beautifulsoup4 en la terminal (paso a paso).
P: ¿Thunderbit es gratis?
R: Thunderbit tiene un modelo freemium—gratis para tareas pequeñas, con planes de pago para mayor volumen o funciones avanzadas. Puedes probarlo gratis directamente desde el navegador (ver precios).
Si quieres ver una comparativa real entre Thunderbit y BeautifulSoup, revisa nuestra comparativa detallada. Y si quieres aprender más sobre raspado web, no te pierdas nuestras guías sobre qué es el data scraping y cómo extraer productos y reseñas de Amazon.
¡Feliz scraping! Recuerda: tanto si eres experto en Python como si solo quieres tus datos en una hoja de cálculo, hay una herramienta (y una comunidad) lista para ayudarte a conseguirlo.




