Te lo digo: si me dieran un dólar por cada vez que alguien me envió un PDF lleno de “datos importantes” y esperaba que, por arte de magia, lo convirtiera en una hoja de cálculo, probablemente tendría suficiente para comprar café para toda la vida (y quizá unas cuantas extensiones de Chrome más). Los PDF están por todas partes: contratos de ventas, catálogos de productos, trabajos de investigación, facturas, lo que quieras. Pero cuando toca usar de verdad los datos dentro de esos archivos, ahí es donde empieza lo divertido (léase: los quebraderos de cabeza).
He estado en la trinchera: copiando, pegando, reformateando y, a veces, simplemente tirando la toalla cuando el formato se descontrola o las imágenes y los enlaces desaparecen sin dejar rastro. Pero aquí viene la buena noticia: el mundo del scraping de PDF ha cambiado muchísimo, sobre todo con el auge de las herramientas impulsadas por IA. Si estás cansado de pasar horas reescribiendo números o de volverte loco con tablas rotas, estás en el sitio adecuado. Vamos a meternos de lleno en el scraping de PDF, por qué importa y cómo herramientas como están haciendo que, por fin, no sea un suplicio.
¿Qué es el scraping de PDF? Entendiendo los conceptos básicos de la extracción de datos de PDF
Empecemos por lo básico: scraping de PDF no es más que una forma elegante de decir “extraer datos estructurados de archivos PDF, automáticamente”. Un Raspador Web de PDF es una herramienta (software, extensión o servicio) que saca lo que te interesa —texto, tablas, imágenes, enlaces, lo que sea— y lo convierte en un formato que realmente puedes usar, como Excel, Google Sheets o una base de datos.
Pero aquí está el truco: los PDF no son como las páginas web ni como los archivos de Excel. Se parecen más a impresiones digitales, pensadas para verse igual en todas partes, no para que una computadora las desmonte sin esfuerzo. Algunos PDF tienen texto seleccionable; otros son solo imágenes escaneadas (que necesitan OCR, reconocimiento óptico de caracteres), y el formato puede ser totalmente irregular. Así que extraer datos de un PDF no consiste solo en copiar texto: se trata de descifrar un rompecabezas de diseños, tipografías y, a veces, incluso metadatos ocultos.
¿Qué puedes extraer de un PDF?
- Texto plano (párrafos, títulos, etc.)
- Tablas (piensa en: finanzas, especificaciones de productos, datos de encuestas)
- Imágenes y gráficos (gráficas, logotipos, firmas escaneadas)
- Hipervínculos y referencias (URL incrustadas, citas)
- Datos de formularios (campos de formularios rellenables)
- Metadatos (autor, título, fecha de creación, etiquetas)
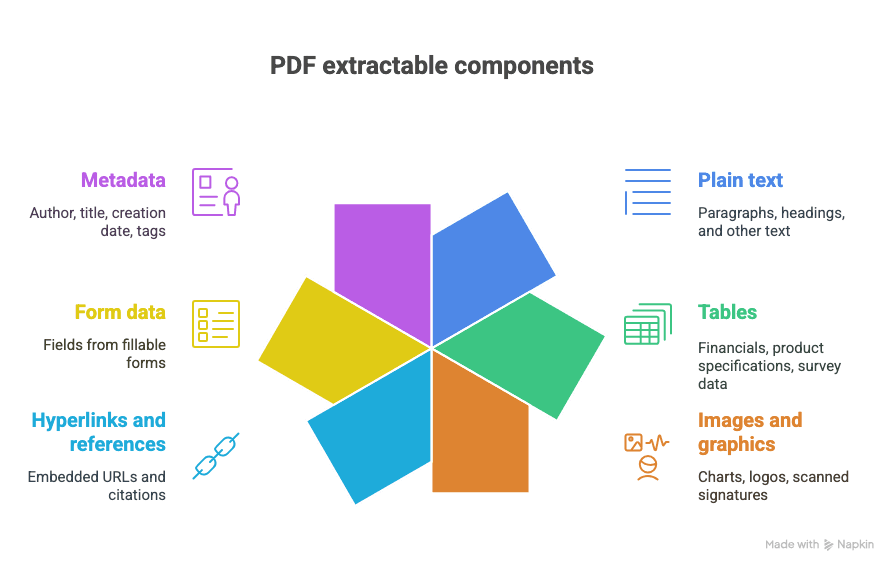
Y sí, a veces todo eso acaba mezclado en un solo documento gloriosamente caótico.
Por qué importa el scraping de PDF: casos de uso reales y beneficios para el negocio
Entonces, ¿por qué molestarse en extraer datos de PDF? Porque todo el mundo los usa, y los datos que contienen suelen ser críticos para el negocio. Aquí es donde el scraping de PDF realmente brilla:
| Caso de uso | Esfuerzo manual | Con un raspador de PDF | Ahorro de tiempo y errores |
|---|---|---|---|
| Extracción de leads de ventas | Horas copiando contactos de propuestas o PDFs de eventos, con riesgo de perder leads | Inserta todos los leads al instante en una hoja de cálculo | 80–90% más rápido, menos errores |
| Datos de productos para e-commerce | Días introduciendo especificaciones de productos desde PDFs de proveedores, con problemas de formato | Extracción masiva a CSV o Sheets | Más del 95% de tiempo ahorrado, datos consistentes |
| Análisis de datos de investigación | Semanas transcribiendo tablas de artículos académicos, con alto riesgo de erratas | Extrae tablas, referencias e incluso texto escaneado | 80% de tiempo ahorrado, mayor precisión |
Pongamos algunos números sobre la mesa:
- Se crean cada año.
- El usa el PDF como formato principal para compartir información.
- La administración digital manual, como la introducción de datos desde PDF, se come .
- Las herramientas automatizadas pueden reducir las tasas de error de .
Si trabajas en ventas, e-commerce o investigación, automatizar la extracción de datos de PDF no es solo algo “deseable”: es una ventaja competitiva.
Métodos tradicionales de scraping de PDF: desafíos y limitaciones
Seamos sinceros: las formas de antes de sacar datos de un PDF no son… geniales. Esto es lo que la mayoría hemos probado (y por qué resulta tan frustrante):

1. Copiar y pegar manualmente
- Puntos de dolor: El formato se destroza, las tablas quedan hechas un desastre, las imágenes y los enlaces desaparecen y tú te quedas con un dolor de cabeza.
- Costo laboral: Alto. Si tienes 5.000 PDF, incluso a 1 minuto cada uno, eso son más de 80 horas de tu vida que nunca recuperarás.
- Tasa de error: 5–10%. Erratas, filas omitidas, borrados accidentales… sí, ya lo he vivido.
2. Convertir a Word/Excel y luego limpiar
- Puntos de dolor: A veces funciona con documentos simples, pero los diseños complejos o las tablas quedan desordenados. Luego igual tienes que limpiar el desastre.
- Imágenes/enlaces: Normalmente se pierden por el camino.
- Extracción específica: Olvídalo: obtienes todo el documento, no solo lo que necesitas.
3. Scripts personalizados (Python, etc.)
- Puntos de dolor: Necesitas saber programar (o tener a alguien a mano). Cada nuevo formato de PDF obliga a retocar el script. ¿PDF escaneados? Buena suerte.
- Mantenimiento: Alto. Cada vez que un proveedor cambia su plantilla de factura, tu script se rompe.
- Escalabilidad: No apto para corazones sensibles (ni para perfiles no técnicos).
4. Convertidores online
- Puntos de dolor: Son fáciles para trabajos puntuales, pero tienes que subir documentos sensibles a un servidor de terceros (hola, problemas de cumplimiento). Además, control limitado sobre lo que se extrae.
- Formato: Inconsistente. Puede que pases más tiempo limpiando que ahorrando.
En resumen: los métodos tradicionales son lentos, propensos a errores y no escalan. Por eso tantos equipos simplemente “conviven” con el problema, pero a un coste enorme de productividad.
Soluciones modernas para el scraping de PDF: de código a herramientas sin código
Por suerte, ya no estamos atrapados en la Edad Oscura. El panorama se ha llenado de opciones de scraping de PDF más inteligentes, rápidas y fáciles de usar.
1. Librerías de programación (para desarrolladores)
- Ejemplos: , , .
- Ventajas: Muy flexibles, automatizables para lotes grandes, gratuitas (código abierto).
- Desventajas: Mucho tiempo de configuración, requieren habilidades de programación, son frágiles (se rompen con nuevos formatos) y tienen soporte limitado para OCR/imágenes.
2. Convertidores online de PDF
- Ejemplos: , , .
- Ventajas: Sin configuración, fáciles para quienes no son técnicos, rápidos para trabajos pequeños.
- Desventajas: Personalización limitada, preocupaciones de privacidad, errores de formato, límites de tamaño y páginas.
3. Raspadores de PDF con IA
- Ejemplos: , Nanonets, Docparser.
- Ventajas: No hace falta programar, gestiona texto/tablas/imágenes/enlaces, la IA sugiere qué extraer, admite trabajos por lotes, se integra con Sheets/Notion/Airtable.
- Desventajas: Algunos tienen límites de créditos o páginas, puede requerir conexión a internet y, a veces, hay una curva de aprendizaje con documentos complejos.
Comparando herramientas de scraping de PDF: ¿qué enfoque encaja con tus necesidades?
| Herramienta/Método | Configuración | Ideal para | Extrae | ¿Personalizable? | Costo |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | Moderada (interfaz/código) | Tablas en PDF | Tablas | Algo | Gratis |
| PDFMiner | Requiere código | PDF con mucho texto | Texto | Sí (código) | Gratis |
| PyPDF2 | Requiere código | Texto/metadatos simples | Texto, metadatos | Sí (código) | Gratis |
| Smallpdf/convertidores online | Ninguna (basado en web) | Conversiones rápidas | Documento completo (Word/Excel) | No | Freemium |
| Thunderbit | Instalación en 2 clics | Usuarios de negocio, equipos | Texto, tablas, imágenes, enlaces | Sí (prompts de IA) | Freemium ($16.5/mes para Pro) |
Conoce Thunderbit: la extensión de Chrome con IA para scraping de PDF
Ahora sí, hablemos de la herramienta que me ha hecho la vida —y la de muchos usuarios de negocio— muchísimo más fácil: .
¿Qué hace diferente a Thunderbit?
- Extracción en 2 clics: abre un PDF en Chrome, haz clic en la extensión de Thunderbit y deja que la IA haga el resto.
- Sugerencias de campos impulsadas por IA: la función “AI Suggest Fields” de Thunderbit lee tu PDF y recomienda las columnas que probablemente quieras (como “Nombre”, “Correo electrónico”, “Precio”, etc.).
- Gestiona imágenes, enlaces y tablas: no solo texto plano: Thunderbit puede extraer imágenes, hipervínculos e incluso ejecutar OCR en documentos escaneados.
- Prompts personalizados: ¿Solo necesitas números de teléfono o especificaciones de productos? Añade una instrucción personalizada y Thunderbit se centrará justo en eso.
- Exporta a todas partes: envía tus datos directamente a Excel, Google Sheets, Airtable o Notion. Se acabó pelearte con CSV.
- Scraping por lotes y de subpáginas: ¿Tienes una lista de PDF o enlaces? Thunderbit puede procesarlos todos de una vez.
- Fiabilidad de nivel empresarial: diseñado para ofrecer precisión, privacidad y flujos de trabajo reales.
En resumen, es como tener un becario digital al que de verdad le encanta introducir datos (y nunca se cansa).
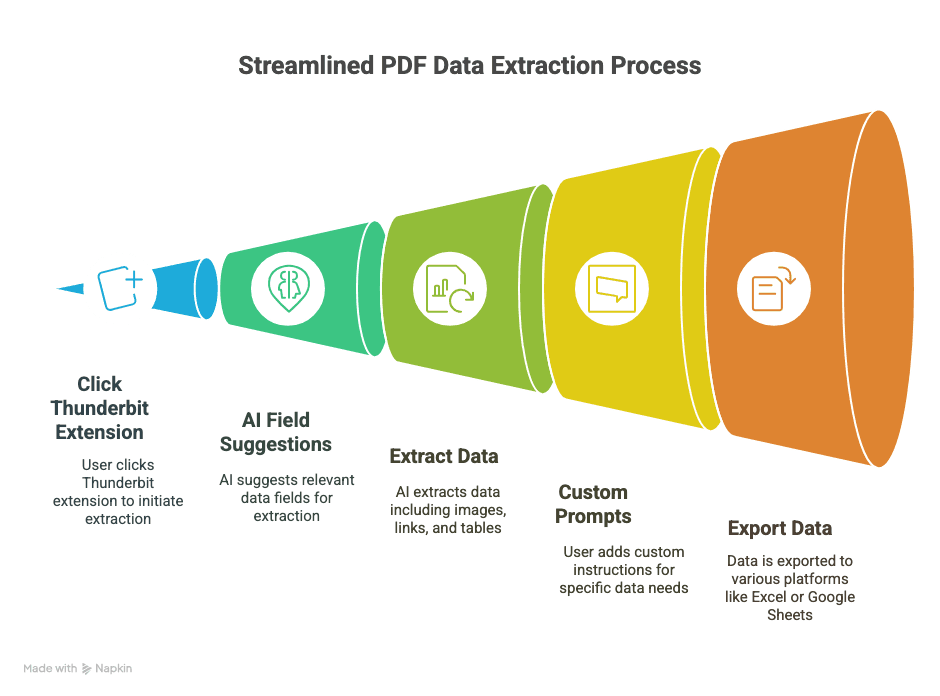
Cómo extraer datos de un PDF usando Thunderbit: guía paso a paso
¿Listo para ver lo fácil que puede ser? Así es como uso Thunderbit para convertir PDFs en datos estructurados y útiles:
1. Instala Thunderbit
- Descarga la .
- Regístrate (con cuenta de Google o correo electrónico: tardas segundos).
2. Abre tu PDF en Chrome
- Puedes abrir un PDF desde un enlace web o arrastrar un PDF local a una pestaña de Chrome.
3. Lanza Thunderbit sobre el PDF
- Haz clic en el icono de Thunderbit en la barra de herramientas del navegador.
- Selecciona “AI Web Scraper”: Thunderbit detectará el PDF y se preparará para trabajar.
4. Deja que la IA sugiera los campos
- Haz clic en “AI Suggest Columns”.
- La IA de Thunderbit escanea el PDF y recomienda columnas (como “Fecha”, “Importe”, “Nombre del contacto”, etc.).
- Previsualiza los datos extraídos en una tabla dentro de la propia extensión.
5. Personaliza si hace falta
- Cambia el nombre de las columnas, elimina las que sobren o añade las tuyas (por ejemplo, “Plazo de garantía” o “URL del producto”).
- Para datos complicados, selecciona texto en el PDF para entrenar a la IA sobre lo que quieres.
6. Elige el formato de exportación
- Elige entre CSV, Google Sheets, Airtable o Notion.
- Autoriza a Thunderbit para conectarse (configuración única).
7. Extrae y exporta
- Pulsa “Scrape” o “Export”.
- Thunderbit procesa el PDF y envía los datos donde tú quieras, normalmente en segundos.
Y listo. Sin código, sin copiar y pegar, sin dramas.
Consejos para una extracción precisa de datos de PDF con Thunderbit
- Revisa los campos sugeridos por la IA: la IA es inteligente, pero una mirada rápida te asegura que obtienes exactamente lo que necesitas.
- Gestiona tablas complejas: para tablas de varias páginas o con formatos extraños, usa la vista previa para detectar problemas y ajustar las columnas según sea necesario.
- Extrae imágenes/enlaces: asegúrate de incluir estos campos si tu PDF los contiene; Thunderbit también puede capturarlos.
- PDF escaneados: el OCR integrado de Thunderbit funciona muy bien, pero cuanto más limpio sea el escaneo, mejores serán los resultados.
- Prompts personalizados: ¿Solo quieres correos electrónicos o números de teléfono? Añade un prompt como “Extrae todas las direcciones de correo electrónico” y Thunderbit se centrará en ellas.
Scraping avanzado de PDF: extracción de imágenes, enlaces y datos personalizados
Thunderbit no trata solo del texto plano. Así puedes sacar aún más provecho de tus PDF:
- Imágenes: extrae logotipos, gráficas o cualquier imagen incrustada. Thunderbit incluso puede aplicar OCR al texto dentro de imágenes.
- Hipervínculos: extrae todas las URL o referencias: ideal para trabajos de investigación o currículums.
- Tipos de datos personalizados: usa prompts de IA para extraer justo lo que necesitas (por ejemplo, “Encuentra todos los SKU de producto y sus precios”).
- Resúmenes y categorización: añade una columna y pide a Thunderbit que resuma una sección o clasifique datos al vuelo.
Analizar datos de PDF para necesidades empresariales específicas
- Ventas: extrae solo la información de contacto de un lote de propuestas.
- E-commerce: extrae especificaciones, precios e imágenes de catálogos de proveedores.
- Investigación: recupera tablas, referencias e incluso genera resúmenes de artículos académicos.
Y una vez tengas los datos, estructúralos para analizarlos fácilmente en Excel, Google Sheets o Notion: Thunderbit hace el trabajo pesado y tú solo aprovechas el resultado.
Exportar y usar los datos de tus PDF: de la extracción a la acción
Sacar los datos es solo el principio. Aquí tienes cómo hacer que trabajen para ti:
- Opciones de exportación: CSV, Excel, Google Sheets, Airtable, Notion: elige la que prefieras.
- Consejos de formato: usa la configuración de tipo de columna de Thunderbit (número, fecha, texto) para obtener datos limpios y listos para analizar.
- Integración en flujos de trabajo: conecta los datos exportados a CRM, sistemas de inventario o paneles de analítica.
- Colaboración: comparte hojas de Google Sheets o bases de Airtable con tu equipo: todos trabajan con los mismos datos actualizados.
¿La mejor parte? Nada de mandar hojas de cálculo por correo una y otra vez ni de preguntarte si se te pasó una fila.
Errores comunes en el scraping de PDF y cómo evitarlos
Incluso con las mejores herramientas, pueden aparecer algunos tropiezos. Esto es lo que he aprendido, a veces por las malas:
- Errores de OCR: los escaneos borrosos o las tipografías raras pueden confundir incluso al mejor OCR. Intenta usar los PDF más limpios posibles y revisa los campos críticos.
- Diseños complejos: las tablas multinivel o con varias columnas pueden necesitar algo de guía manual: usa la selección manual de Thunderbit o los prompts.
- Tipos de datos: ¿números con comas o fechas en formatos extraños? Define el tipo de columna antes de exportar o límpialo en Excel/Sheets.
- Límites de tamaño/páginas: ¿PDF enormes? Divídelos en fragmentos más pequeños o usa el modo en la nube de Thunderbit para trabajos por lotes.
- “Alucinación” de la IA: es raro, pero a veces la IA puede adivinar un nombre de columna o completar datos faltantes. Revisa siempre la salida, especialmente si son números importantes.
- Revisión manual: para datos críticos, haz una validación rápida: las herramientas automáticas son precisas, pero una mirada humana nunca está de más.
Y si te encuentras con una pared, el soporte y la comunidad de Thunderbit están para ayudarte.
Conclusión y conclusiones clave: cómo hacer que el scraping de PDF funcione para tu negocio
Vamos cerrando. Extraer datos de PDF antes era una pesadilla: lento, propenso a errores y simplemente agotador. Pero con herramientas modernas como , ahora es rápido, preciso y, me atrevo a decir, casi agradable.
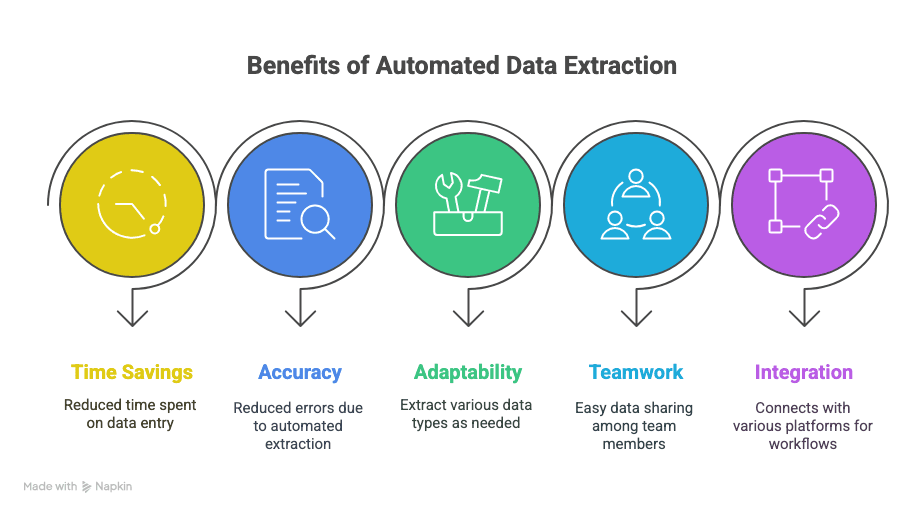
Esto es lo que consigues:
- Recuperar tiempo: horas —o incluso semanas— ahorradas en la introducción manual de datos.
- Menos errores: la extracción automatizada significa menos erratas y menos filas perdidas.
- Flexibilidad: extrae exactamente lo que necesitas: texto, tablas, imágenes, enlaces, lo que sea.
- Colaboración: comparte datos al instante con tu equipo, esté donde esté.
- Flujos de trabajo más inteligentes: integración con Sheets, Notion, Airtable y más.
¿Listo para probarlo? Descarga la , ejecútala en tu próximo PDF y descubre cuánto más fácil puede ser la vida. Tu yo del futuro (y tu túnel carpiano) te lo agradecerán.
Para más consejos y guías, visita el o profundiza con .
Convirtamos esos dolores de cabeza con PDF en victorias de productividad, un clic a la vez.
Shuai Guan, cofundador y CEO de Thunderbit