
Optimizar las consultas de listas de apollo en apollo no es solo un tema técnico: es una habilidad clave para cualquiera que viva de datos de noticias en tiempo real, de la extracción automatizada de noticias o de flujos de ventas y operaciones a toda pastilla. Lo he visto en carne propia: una consulta lenta puede convertir un dashboard bien montado en un tapón monumental. El equipo comercial se queda mirando loaders eternos y el equipo de ops acaba resolviendo “a la rápida” en hojas de cálculo. En un mundo donde , cada milisegundo cuenta.

Entonces, ¿cómo haces que las consultas de listas con Apollo Client vayan como un tiro, sean confiables y escalen sin drama, sobre todo si estás recopilando noticias, siguiendo leads o alimentando dashboards críticos? En esta guía te voy a condensar las mejores prácticas que he ido aprendiendo (y otras que aprendí a golpes), desde cómo plantear la consulta hasta caché, paginación e incluso cómo integrar herramientas no-code como para automatizar el trabajo pesado de la extracción de noticias. Seas dev, product manager o la persona a la que todos miran cuando el dashboard se arrastra, aquí tienes tu manual para mejorar el rendimiento de listas en Apollo GraphQL (sí, incluso si por ahí alguien anda probando apollp ai o viene de las misiones apollo con mentalidad de “esto tiene que funcionar sí o sí”).
Por qué optimizar las consultas de listas en Apollo (rendimiento de listas en apollo client, optimizar consultas de listas en apollo)
Hablemos sin rodeos: nadie quiere esperar a que carguen titulares o leads. En entornos de negocio —sobre todo los que dependen de la o de datos en tiempo real— las consultas lentas no solo fastidian: cuestan dinero, frenan decisiones y empujan a la gente a volver al modo manual. El dice que los trabajadores de oficina se pasan aproximadamente un tercio del día en tareas de bajo valor, muchas veces porque las herramientas van lentas o están hechas un rompecabezas.
Esto es lo que suele pasar cuando las consultas de listas no están bien afinadas:
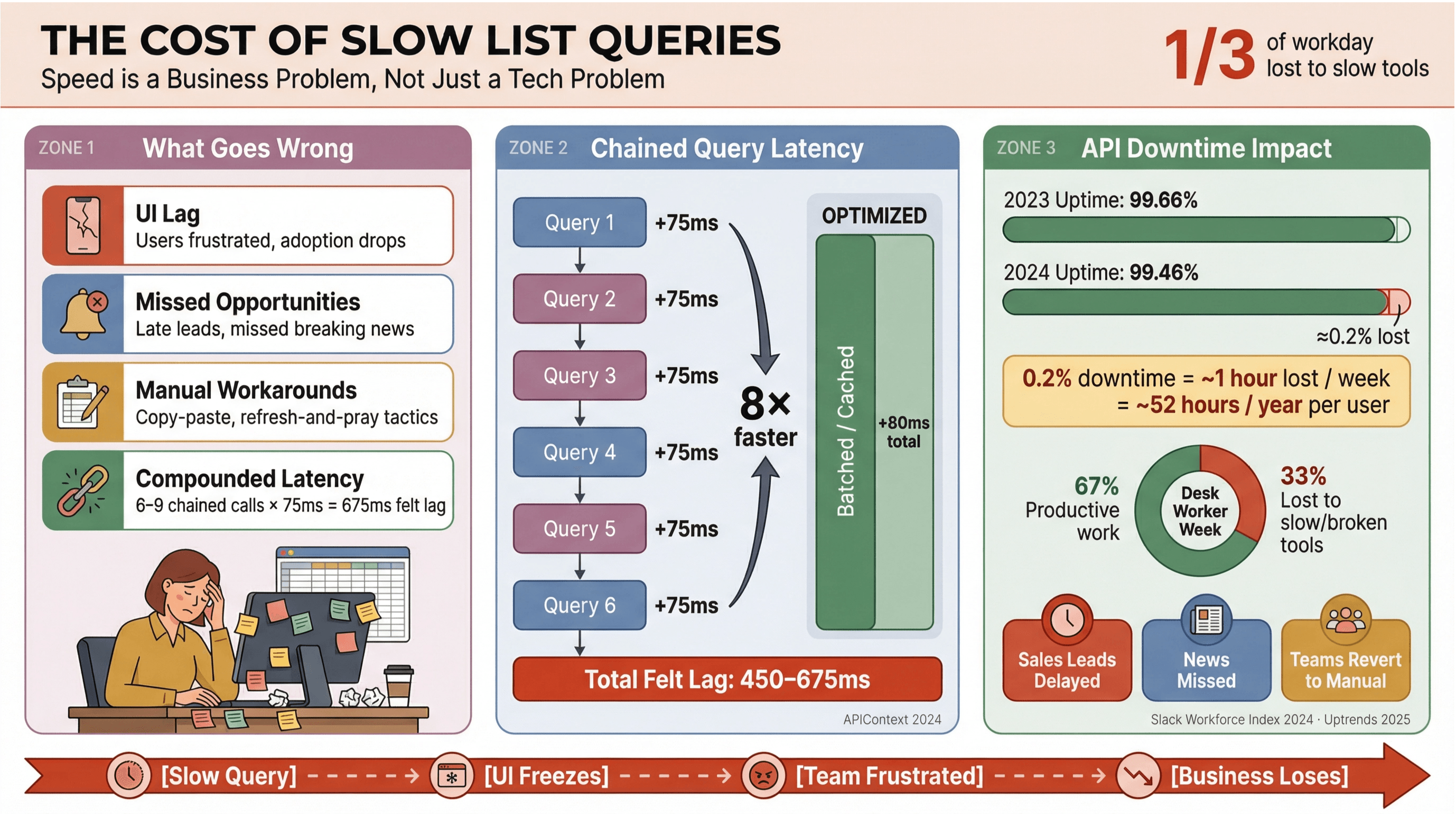
- Lentitud en la interfaz: el usuario nota el retraso, se desespera y baja la adopción.
- Oportunidades perdidas: en ventas o en monitorización de noticias, unos segundos pueden ser la diferencia entre pillar un lead caliente o perder una primicia.
- Atajos manuales: el equipo vuelve al copiar/pegar, a las hojas de cálculo o al clásico “actualiza y reza”.
- Latencia acumulada: cada llamada lenta a la API suma; si tu flujo dispara 6–9 consultas dependientes, un retraso moderado de 75 ms por llamada puede convertirse en 450–675 ms de lag percibido ().
Y ojo, no es solo velocidad. El : la disponibilidad media bajó de 99,66% a 99,46% en solo un año. Traducido: casi una hora de productividad perdida por semana en apps que dependen fuerte de listas. Si tu negocio vive de datos de noticias en tiempo real, ese riesgo no te lo puedes permitir.
Elegir la estructura de datos y los campos adecuados (mejores prácticas de listas en apollo graphql)
Uno de los fallos más típicos que veo (y sí, yo también caí ahí) es tratar cada consulta de lista como si fuera una consulta de detalle. En GraphQL puedes pedir exactamente lo que necesitas: úsalo a tu favor. El overfetching es el enemigo número uno del rendimiento, especialmente en herramientas de scraping de noticias y dashboards en tiempo real.
Ajustar los campos para la extracción automatizada de noticias
Ponte en situación: estás armando un feed de noticias. ¿De verdad necesitas el cuerpo completo del artículo, todas las etiquetas, comentarios y biografías de autores en la consulta de lista? Casi seguro que no. Mira la diferencia:
Consulta de lista eficiente:
1query NewsFeed($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 cursor
5 node {
6 id
7 title
8 url
9 sourceName
10 publishedAt
11 }
12 }
13 pageInfo { endCursor hasNextPage }
14 }
15}Consulta de lista ineficiente (evítala):
1query NewsFeedTooHeavy($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 node {
5 id title url publishedAt
6 fullText
7 summary
8 entities { ... }
9 relatedArticles { ... }
10 }
11 }
12 }
13}La primera es liviana y al grano: perfecta para ordenar, filtrar y renderizar filas. ¿La segunda? Es una consulta de detalle disfrazada, que se trae cargas enormes y te ralentiza todo (, ).
Consejo pro: aplica un enfoque de dos niveles: en la lista, solo campos ligeros; y los detalles pesados (texto completo o enriquecimiento NLP) solo cuando el usuario abre un elemento o pasa el cursor.
Aprovechar la caché de Apollo Client para consultas más rápidas (rendimiento de listas en apollo client)
La caché de Apollo Client es tu as bajo la manga para que las listas se sientan instantáneas. Bien configurada, te permite:
- Responder al instante a consultas repetidas (sin ir a la red)
- Bajar carga del servidor y costes de API
- Navegación suave al volver atrás/adelante y al cambiar filtros
Pero la caché no es magia: necesita configuración y un poco de disciplina.
Definir políticas de caché efectivas
Apollo soporta varias :
| Política | Qué hace | Mejor caso de uso en listas de noticias |
|---|---|---|
| cache-first | Lee de caché; si falta, consulta la red | Volver a listas, cambiar filtros, navegación atrás/adelante |
| network-only | Siempre consulta la red | Actualización manual, “últimos titulares” |
| cache-and-network | Devuelve caché primero y luego actualiza con la red | Pintado inicial rápido + actualización en segundo plano (ideal) |
| no-cache | Siempre consulta y no guarda en caché | Consultas puntuales sensibles (raro en listas) |
Para datos de noticias en tiempo real, a mí me encanta cache-and-network: te da resultados al toque y luego refresca en segundo plano. Solo cuidado con el parpadeo de la UI si el orden cambia al actualizar ().
Consejos de configuración de caché:
- Usa IDs estables (
ido_id) para normalizar (). - Ajusta el tamaño de la caché y la recolección de basura para listas grandes ().
- Evita guardar blobs enormes sin normalizar bajo
ROOT_QUERY: te puede congelar la app ().
Implementar paginación y limitar el número de elementos (mejores prácticas de listas en apollo graphql)
Si intentas cargar cientos o miles de artículos o leads de una sola, estás pidiendo problemas. La paginación no es solo UX: es una necesidad de rendimiento.
Apollo soporta paginación y . Comparación rápida:
| Tipo de paginación | Ventajas | Desventajas | Mejor para |
|---|---|---|---|
| Por offset | Simple, fácil de implementar | Puede saltar/duplicar si cambian los datos | Listas pequeñas o inmutables |
| Por cursor | Estable, maneja bien cambios de datos | Algo más compleja | Feeds de noticias, listas grandes |
Para la mayoría de listas de noticias o leads en tiempo real, la paginación por cursor es la jugada correcta. Mantiene consistencia aunque entren nuevos elementos o se borren otros ().
Tips de paginación en Apollo:
- Configura
keyArgspara controlar las claves de caché en campos paginados (). - Implementa una función
mergepara combinar páginas en la caché. - Usa
fetchMorepara traer páginas extra sin pisar resultados anteriores.
Patrones prácticos de paginación para herramientas de scraping de noticias
Una UI típica de scraping de noticias suele:
- Mostrar los últimos 20–50 titulares (solo campos ligeros)
- Cargar más al hacer scroll o al pulsar “siguiente”
- Traer detalles solo cuando haga falta
Así mantienes la interfaz ágil, la API tranquila y a la gente enfocada.
Integrar Thunderbit para la extracción automatizada de noticias
Ahora sí, hablemos de lo evidente: ¿de dónde sale toda esa info de noticias ya estructurada? Ahí entra .
Thunderbit es una extensión de Chrome de Raspador Web IA no-code que puede extraer titulares, URLs, fuentes, autores, fechas de publicación, resúmenes e imágenes de prácticamente cualquier web, sin necesidad de programar. He visto equipos usar Thunderbit para automatizar todo el proceso de extracción de noticias, convirtiendo páginas caóticas en datos limpios y estructurados que puedes mandar directo a una base de datos o a una API GraphQL.
Combinar Thunderbit con Apollo para datos de noticias en tiempo real
Este flujo me parece una joya para equipos de ventas y operaciones que necesitan noticias al día:
- Capa de extracción: usa la de Thunderbit para sacar datos estructurados de sitios objetivo de forma programada.
- Capa de almacenamiento: guarda lo extraído en una base de datos optimizada para lecturas rápidas.
- Capa GraphQL: expón un campo de lista
newsFeedy un campo de detallenewsArticle(id)en tu API. - Capa cliente: con Apollo Client, consulta la lista (campos ligeros, paginada) y pide detalles solo cuando haga falta.
Este pipeline “extraer → almacenar → consultar” hace que tus consultas de Apollo trabajen siempre con datos frescos y ordenados, sin copiar/pegar manual ni scripts frágiles.
Extra: Thunderbit también puede enriquecer tus listas con campos adicionales (como sentimiento o categoría) gracias a sus sugerencias de campos con IA, haciendo tu feed todavía más inteligente.
Guía paso a paso: optimizar consultas de listas en Apollo
¿Listo para ponerlo en práctica? Este es mi checklist de siempre para optimizar listas en Apollo:
-
Haz tus consultas más ligeras
- Pide solo lo necesario para renderizar la lista (título, URL, fecha/hora, etc.).
- Lleva los campos pesados (texto completo, imágenes, enriquecimiento) a consultas de detalle.
-
Implementa paginación
- Usa paginación por cursor en listas grandes o dinámicas.
- Configura
keyArgsy funcionesmergepara que la caché quede bien.
-
Aprovecha la caché de Apollo
- Normaliza entidades con IDs estables.
- Elige la fetch policy adecuada (
cache-and-networkva de lujo para noticias). - Ajusta tamaño de caché y garbage collection según tu volumen.
-
Integra extracción automatizada
- Usa Thunderbit para automatizar el scraping de noticias y mantener los datos al día.
- Exporta datos estructurados directo a tu base de datos o a una hoja de cálculo.
-
Monitorea y depura
- Usa para inspeccionar consultas, caché y rendimiento.
- Vigila escrituras grandes en caché, watched queries excesivas y tirones en la UI.
- Controla latencia p95/p99 y tasas de error (, ).
Monitorización y resolución de problemas de rendimiento
Las Devtools de Apollo son un salvavidas. Te dejan:
- Revisar consultas activas y el estado de la caché
- Cazar consultas duplicadas o demasiados watchers
- Identificar blobs grandes en caché o fallos de normalización
Si notas lag en la UI o actualizaciones lentas, revisa:
- Consultas de lista demasiado pesadas (hazlas más ligeras)
- Normalización floja (arregla los IDs)
- Problemas al combinar páginas (audita
keyArgsymerge)
Y no te quedes con promedios: mide la tail latency. Ahí es donde se esconde el dolor real del usuario.
Comparativa: scraping tradicional vs. extracción de noticias con IA
Seamos honestos: antes, extraer noticias era escribir scripts a medida, pelearte con navegadores headless y rezar para que el sitio no cambiara el layout de un día para otro. Hoy, con herramientas basadas en IA como Thunderbit, puedes automatizarlo todo: sin código y sin líos.
| Enfoque | Puntos fuertes | Limitaciones para usuarios de negocio |
|---|---|---|
| Scraping con scripts | Totalmente personalizable, barato a escala | Alto mantenimiento, requiere tiempo de ingeniería |
| Plataformas gestionadas | Arranque rápido, gestionan anti-bot | Aún requiere configuración, el coste crece con el uso |
| Extracción con IA (Thunderbit) | Se adapta a layouts complejos, sin código | Requiere QA del resultado, integración con tu esquema |
| Scrapers visuales no-code | Accesible para no ingenieros | Puede romperse con cambios de UI, escala limitada |
| Infra de proxies/unlockers | Evita bloqueos, alto rendimiento | Aún necesitas lógica de extracción, riesgos de cumplimiento |
Nota legal: por lo general, extraer datos públicos es legal, pero respeta siempre los términos de servicio y los límites de tasa ().
Ideas clave: mejores prácticas para listas en Apollo GraphQL
Lo esencial, en corto:
- Prioriza velocidad y claridad: listas ligeras, paginación y caché bien usada.
- La estructura manda: pide solo lo necesario; lo pesado, a consultas de detalle.
- La caché es tu compa: normalización y fetch policies para servir datos al instante.
- Automatiza la extracción: herramientas como hacen que el scraping y el enriquecimiento estén al alcance de cualquiera.
- Mide y mejora: Devtools y observabilidad para detectar cuellos de botella temprano.
Para equipos de ventas, operaciones y noticias, esto se traduce en menos tiempo esperando, más tiempo actuando y muchos menos mensajes de Slack tipo “¿por qué va tan lento?”.
Conclusión: próximos pasos para optimizar tus listas en Apollo
Si todavía estás usando consultas de lista pesadas, sin paginación o poco amigas de la caché, ya toca darles una vuelta. Empieza por lo básico: recorta campos, mete paginación y ajusta la caché. Luego sube de nivel integrando herramientas de extracción automatizada como [Thunderbit](https://chromewebstore.googleOptimizar las consultas de listas de apollo en apollo no es solo un tema técnico: es una habilidad clave para cualquiera que viva de datos de noticias en tiempo real, de la extracción automatizada de noticias o de flujos de ventas y operaciones a toda pastilla. Lo he visto en carne propia: una consulta lenta puede convertir un panel bien montado en un tapón enorme. El equipo comercial se queda mirando loaders eternos y el equipo de operaciones acaba resolviendo “a la coreana”: rápido, improvisado y en Google Sheets. En un mundo donde , cada milisegundo cuenta.
Entonces, ¿cómo haces que las consultas de listas con Apollo Client vayan 빨리빨리 (rápido-rápido), sean fiables y escalen sin drama, sobre todo si estás recopilando noticias, siguiendo leads o alimentando dashboards críticos? En esta guía te dejo las mejores prácticas que he ido aprendiendo (y otras a base de 삽질, o sea, “cavar y equivocarse”), desde el diseño de la consulta hasta la caché, la paginación e incluso cómo encajar herramientas no-code como para automatizar el trabajo pesado de la extracción de noticias. Seas dev, PM o la persona a la que todos miran cuando el dashboard va lento, aquí tienes tu manual para mejorar el rendimiento de listas en Apollo GraphQL.
Por qué optimizar las consultas de listas en Apollo (rendimiento de listas en apollo client, optimizar consultas de listas en apollo)
Vamos al grano: nadie quiere esperar a que carguen titulares o leads. En entornos de negocio —sobre todo los que dependen de la o de datos en tiempo real— las consultas lentas no solo fastidian: cuestan dinero, frenan decisiones y empujan a la gente a volver al curro manual. El dice que los trabajadores de oficina se pasan aproximadamente un tercio del día en tareas de bajo valor, muchas veces por culpa de herramientas lentas o todo “a trocitos”.
Esto es lo que suele pasar cuando las consultas de listas no están optimizadas:
- Lentitud en la interfaz: el usuario nota el retraso, se frustra y baja la adopción.
- Oportunidades perdidas: en ventas o monitorización de noticias, unos segundos pueden ser perder un lead caliente o una primicia.
- Atajos manuales: el equipo vuelve al copiar/pegar, a las hojas de cálculo o al “actualiza y reza”.
- Latencia acumulada: cada llamada lenta a la API se suma; si tu flujo dispara 6–9 consultas dependientes, un retraso moderado de 75 ms por llamada puede convertirse en 450–675 ms de lag percibido ().
Y no es solo velocidad. El : la disponibilidad media bajó de 99,66% a 99,46% en solo un año, lo que se traduce en casi una hora de productividad perdida por semana en apps que dependen mucho de listas. Si tu negocio vive de datos de noticias en tiempo real, es un riesgo que no te puedes permitir.
Elegir la estructura de datos y los campos adecuados (mejores prácticas de listas en apollo graphql)
Uno de los fallos más típicos que veo (y sí, yo también he caído) es tratar cada consulta de lista como si fuera una consulta de detalle. En GraphQL puedes pedir exactamente lo que necesitas: úsalo a tu favor. El exceso de datos (overfetching) es el enemigo del rendimiento, especialmente en herramientas de scraping de noticias y dashboards en tiempo real.
Ajustar los campos para la extracción automatizada de noticias
Imagina que estás montando un feed de noticias. ¿De verdad necesitas el cuerpo completo del artículo, todas las etiquetas, comentarios y biografías de autores en la consulta de lista? Casi seguro que no. Mira la diferencia:
Consulta de lista eficiente:
1query NewsFeed($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 cursor
5 node {
6 id
7 title
8 url
9 sourceName
10 publishedAt
11 }
12 }
13 pageInfo { endCursor hasNextPage }
14 }
15}Consulta de lista ineficiente (evítala):
1query NewsFeedTooHeavy($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 node {
5 id title url publishedAt
6 fullText
7 summary
8 entities { ... }
9 relatedArticles { ... }
10 }
11 }
12 }
13}La primera es ligera y directa: perfecta para ordenar, filtrar y pintar filas. ¿La segunda? Es una consulta de detalle disfrazada, que se trae un 짐 (carga) enorme y lo ralentiza todo (, ).
Consejo pro: usa un enfoque en dos niveles: en la lista, solo campos livianos; y los detalles pesados (texto completo o enriquecimiento NLP) solo cuando el usuario abre un elemento o pasa el cursor.
Aprovechar la caché de Apollo Client para consultas más rápidas (rendimiento de listas en apollo client)
La caché de Apollo Client es tu carta ganadora para que las listas se sientan instantáneas. Bien afinada, te permite:
- Responder al instante a consultas repetidas (sin viajes a la red)
- Reducir carga del servidor y costes de API
- Navegación fluida al volver atrás/adelante y al cambiar filtros
Pero la caché no hace magia por sí sola: necesita configuración y un poco de disciplina (sí, ese “modo 정리”, de tenerlo todo ordenado).
Definir políticas de caché efectivas
Apollo admite varias :
| Política | Qué hace | Mejor caso de uso en listas de noticias |
|---|---|---|
| cache-first | Lee de caché; si falta, consulta la red | Volver a listas, cambiar filtros, navegación atrás/adelante |
| network-only | Siempre consulta la red | Actualización manual, “últimos titulares” |
| cache-and-network | Devuelve caché primero y luego actualiza con la red | Pintado inicial rápido + actualización en segundo plano (ideal) |
| no-cache | Siempre consulta y no guarda en caché | Consultas puntuales sensibles (raro en listas) |
Para datos de noticias en tiempo real, me gusta cache-and-network: te da resultados al momento y luego refresca en segundo plano. Solo ojo con el “parpadeo” de la UI si el orden cambia al actualizar ().
Consejos de configuración de caché:
- Usa IDs estables (
ido_id) para normalizar (). - Ajusta el tamaño de la caché y la recolección de basura para listas grandes ().
- Evita guardar blobs enormes sin normalizar bajo
ROOT_QUERY: puede dejar la app tiesa ().
Implementar paginación y limitar el número de elementos (mejores prácticas de listas en apollo graphql)
Si intentas cargar cientos o miles de artículos o leads de golpe, estás pidiendo problemas. La paginación no es solo UX: es supervivencia de rendimiento.
Apollo soporta paginación y . Comparación rápida:
| Tipo de paginación | Ventajas | Desventajas | Mejor para |
|---|---|---|---|
| Por offset | Simple, fácil de implementar | Puede saltar/duplicar si cambian los datos | Listas pequeñas o inmutables |
| Por cursor | Estable, maneja bien cambios de datos | Algo más compleja | Feeds de noticias, listas grandes |
Para la mayoría de listas de noticias o leads en tiempo real, la paginación por cursor es la mejor opción. Mantiene la consistencia aunque entren nuevos elementos o se eliminen otros ().
Tips de paginación en Apollo:
- Configura
keyArgspara controlar las claves de caché en campos paginados (). - Implementa una función
mergepara combinar páginas en la caché. - Usa
fetchMorepara cargar páginas adicionales sin sobrescribir resultados previos.
Patrones prácticos de paginación para herramientas de scraping de noticias
Una UI típica de scraping de noticias suele:
- Mostrar los últimos 20–50 titulares (solo campos ligeros)
- Cargar más al hacer scroll o al pulsar “siguiente”
- Traer detalles solo cuando haga falta
Así mantienes la interfaz ágil, la API tranquila y a la gente en modo 집중 (concentración).
Integrar Thunderbit para la extracción automatizada de noticias
Ahora, hablemos de lo obvio: ¿de dónde sale toda esa info de noticias ya estructurada? Ahí entra .
Thunderbit es una extensión de Chrome de Raspador Web IA no-code que puede extraer titulares, URLs, fuentes, autores, fechas de publicación, resúmenes e imágenes de prácticamente cualquier sitio web, sin necesidad de programar. He visto equipos usar Thunderbit para automatizar todo el proceso de extracción de noticias, convirtiendo páginas desordenadas en datos limpios y estructurados que se pueden enviar directamente a una base de datos o a una API GraphQL.
Combinar Thunderbit con Apollo para datos de noticias en tiempo real
Este flujo me encanta para equipos de ventas y operaciones que necesitan noticias al día, en plan 실시간 (tiempo real):
- Capa de extracción: usa la de Thunderbit para obtener datos estructurados de sitios objetivo de forma programada.
- Capa de almacenamiento: guarda los datos extraídos en una base de datos optimizada para lecturas rápidas.
- Capa GraphQL: expón un campo de lista
newsFeedy un campo de detallenewsArticle(id)en tu API. - Capa cliente: con Apollo Client, consulta la lista (campos ligeros, paginada) y pide detalles solo cuando sea necesario.
Este pipeline “extraer → almacenar → consultar” hace que tus consultas de Apollo trabajen siempre con datos frescos y estructurados, sin copiar/pegar manual ni scripts frágiles.
Extra: Thunderbit también puede enriquecer tus listas con campos adicionales (como sentimiento o categoría) gracias a sus sugerencias de campos con IA, haciendo tu feed aún más inteligente.
Guía paso a paso: optimizar consultas de listas en Apollo
¿Listo para ponerte manos a la obra? Este es mi checklist de siempre para optimizar listas en Apollo:
-
Haz tus consultas más ligeras
- Pide solo lo necesario para renderizar la lista (título, URL, fecha/hora, etc.).
- Lleva los campos pesados (texto completo, imágenes, enriquecimiento) a consultas de detalle.
-
Implementa paginación
- Usa paginación por cursor en listas grandes o dinámicas.
- Configura
keyArgsy funcionesmergepara que la caché sea correcta.
-
Aprovecha la caché de Apollo
- Normaliza entidades con IDs estables.
- Elige la fetch policy adecuada (
cache-and-networkva genial para noticias). - Ajusta tamaño de caché y garbage collection según tu volumen.
-
Integra extracción automatizada
- Usa Thunderbit para automatizar el scraping de noticias y mantener los datos actualizados.
- Exporta datos estructurados directamente a tu base de datos o a una hoja de cálculo.
-
Monitorea y depura
- Usa para inspeccionar consultas, caché y rendimiento.
- Vigila escrituras grandes en caché, watched queries excesivas y tirones en la UI.
- Controla latencia p95/p99 y tasas de error (, ).
Monitorización y resolución de problemas de rendimiento
Las Devtools de Apollo son un salvavidas. Te dejan:
- Revisar consultas activas y el estado de la caché
- Detectar consultas duplicadas o demasiados watchers
- Identificar blobs grandes en caché o problemas de normalización
Si notas lag en la UI o actualizaciones lentas, revisa:
- Consultas de lista demasiado grandes (hazlas más ligeras)
- Normalización deficiente (corrige los IDs)
- Problemas al combinar páginas (audita
keyArgsymerge)
Y no te quedes solo con promedios: mide la latencia de cola (tail latency). Ahí es donde se esconde el dolor real del usuario.
Comparativa: scraping tradicional vs. extracción de noticias con IA
Seamos honestos: antes, extraer noticias era escribir scripts a medida, pelearte con navegadores headless y rezar para que el layout no cambiara de un día para otro. Hoy, con herramientas basadas en IA como Thunderbit, puedes automatizarlo todo: sin código y sin líos.
| Enfoque | Puntos fuertes | Limitaciones para usuarios de negocio |
|---|---|---|
| Scraping con scripts | Totalmente personalizable, barato a escala | Alto mantenimiento, requiere tiempo de ingeniería |
| Plataformas gestionadas | Arranque rápido, gestionan anti-bot | Aún requiere configuración, el coste crece con el uso |
| Extracción con IA (Thunderbit) | Se adapta a layouts complejos, sin código | Requiere QA del resultado, integración con tu esquema |
| Scrapers visuales no-code | Accesible para no ingenieros | Puede romperse con cambios de UI, escala limitada |
| Infra de proxies/unlockers | Evita bloqueos, alto rendimiento | Aún necesitas lógica de extracción, riesgos de cumplimiento |
Nota legal: en general, extraer datos públicos es legal, pero respeta siempre los términos de servicio y los límites de tasa ().
Ideas clave: mejores prácticas para listas en Apollo GraphQL
Lo esencial, sin vueltas:
- Prioriza velocidad y claridad: listas ligeras, paginación y caché bien aprovechada.
- La estructura importa: pide solo lo necesario; lo pesado, a consultas de detalle.
- La caché es tu aliada: normalización y fetch policies para servir datos al instante.
- Automatiza la extracción: herramientas como hacen que el scraping y el enriquecimiento estén al alcance de cualquiera.
- Mide y mejora: Devtools y observabilidad para pillar cuellos de botella pronto.
Para equipos de ventas, operaciones y noticias, estas prácticas significan menos tiempo esperando, más tiempo actuando y muchos menos mensajes de Slack del tipo “¿por qué va tan lento?”.
Conclusión: próximos pasos para optimizar tus listas en Apollo
Si todavía tiras de consultas de lista pesadas, sin paginación o poco amigas de la caché, toca hacer limpieza. Empieza por lo básico: recorta campos, mete paginación y ajusta la caché. Luego sube de nivel integrando herramientas de extracción automatizada como para mantener tus datos frescos y listos para accionar.
¿Quieres profundizar? Mira la , el o pásate por la para consejos reales y troubleshooting. Y si ya estás listo para automatizar la extracción de noticias, prueba la de Thunderbit: es un antes y un después para quien necesita datos en tiempo real sin dolor de cabeza.
Feliz consulta… y que tus listas carguen siempre antes de que se enfríe el café.
Preguntas frecuentes
1. ¿Por qué se ralentizan las consultas de listas en Apollo en dashboards de noticias en tiempo real o ventas?
Las listas se vuelven lentas cuando traen demasiados datos, no tienen paginación o no se cachean bien. En flujos de alta frecuencia como la monitorización de noticias, incluso pequeños retrasos se acumulan, generando lag en la UI y pérdida de productividad.
2. ¿Cuál es la mejor forma de estructurar consultas de listas en Apollo para la extracción automatizada de noticias?
Pide solo los campos necesarios para renderizar la lista (por ejemplo, título, URL y marca de tiempo). Lleva los campos pesados (como el texto completo o imágenes) a consultas de detalle y pagina los resultados para mantener cargas pequeñas y rápidas.
3. ¿Cómo mejora la caché de Apollo Client el rendimiento de las listas?
La caché guarda datos ya consultados y permite respuestas instantáneas en consultas repetidas. Con una buena normalización y fetch policies (como cache-and-network), puedes acelerar mucho las vistas de lista y reducir la carga del servidor.
4. ¿Cómo puede ayudar Thunderbit con el scraping de noticias y la integración con Apollo?
Thunderbit es un Raspador Web IA no-code que extrae datos de noticias estructurados desde cualquier sitio. Puedes automatizar la extracción y luego alimentar tu base de datos o tu API GraphQL para consumirlo con Apollo Client.
5. ¿Qué herramientas puedo usar para monitorizar y depurar el rendimiento de consultas de listas en Apollo?
Las te permiten inspeccionar consultas, estado de caché y rendimiento en tiempo real. Combínalo con paneles de observabilidad (como New Relic o Uptrends) para seguir latencia y errores, e iterar sobre el diseño de tus consultas.
¿Quieres más consejos sobre web scraping, automatización y flujos de datos en tiempo real? Visita el para análisis en profundidad, tutoriales y lo último en productividad con IA.
Más información