
La semana pasada me pasé toda una tarde intentando que un agente de IA completara un formulario de proveedor en un portal con acceso restringido por inicio de sesión. Para la tercera hora, ya estaba viendo un error de "Connection Refused", mi VPS se había quedado sin memoria y, sinceramente, estuve a punto de hacerlo todo a mano.
Esa experiencia es, básicamente, el kit de iniciación de OpenClaw browser automation. La herramienta puede navegar páginas, extraer datos, rellenar formularios y encadenar flujos de trabajo complejos usando instrucciones en lenguaje natural — algo realmente impresionante. Pero el salto entre "esto suena increíble" y "esto funciona de verdad en mi equipo" es donde la mayoría se atasca.
He pasado mucho tiempo en ambos lados de esa brecha, tanto construyendo herramientas de automatización en Thunderbit como probando lo que ofrece el ecosistema open source. Esta guía es la que me habría gustado tener: un recorrido real de instalación, la decisión sobre el modo de navegador que suele confundir a todos, una ruta nativa para Windows (porque WSL no debería ser un requisito previo), una guía para sobrevivir a los anti-bots, ejemplos reales de resultados, errores frecuentes con soluciones concretas y una visión honesta de cuándo OpenClaw es la herramienta adecuada — y cuándo es demasiado para lo que necesitas.
Prueba Thunderbit para extraer datos web sin esfuerzo
Extrae datos de cualquier sitio web con IA Get Started Free
¿Qué es OpenClaw Browser Automation?
OpenClaw es una plataforma gratuita y de código abierto para agentes de IA (licencia MIT) que puede controlar un navegador por ti. En lugar de escribir scripts de Selenium o código de Puppeteer, tú describes lo que quieres hacer en lenguaje natural — "Ve a esta página y extrae todos los nombres y precios de los productos" — y la IA decide cómo hacerlo. Utiliza un sistema de capturas numeradas, en el que el agente identifica los elementos de la página, asigna números de referencia e interactúa con ellos paso a paso.
La arquitectura tiene tres piezas, por eso la configuración implica más que instalar una simple extensión:
- Gateway (VPS/servidor): el "cerebro" que procesa tus instrucciones y se conecta a los LLM. Por defecto funciona en el puerto 18789.
- Node Host (equipo local): un puente que permite al Gateway enviar instrucciones del navegador a tu Chrome local. Se conecta mediante un túnel seguro como Tailscale.
- Extensión de Chrome (Browser Relay): da al agente control directo sobre las pestañas del navegador real.
También hay puertos adicionales como Control Service (18791), CDP Relay (18792) y CDP para navegador gestionado (18800–18899, compatible con hasta 100 perfiles paralelos).
Sí, son muchas piezas en movimiento. Pero una vez entiendes qué hace cada una, la instalación cobra sentido. Piensa en ello como un coche teledirigido: el Gateway es el mando, el Node Host es la señal de radio y la extensión de Chrome es el coche.

Por qué OpenClaw Browser Automation importa para los equipos de negocio
Los profesionales del conocimiento llegan a gastar hasta 60% de su tiempo en tareas administrativas rutinarias en lugar de trabajo de alto valor, incluidas 1,8 horas al día solo buscando y reuniendo información. Smartsheet encontró que más del 40% de los trabajadores dedica al menos una cuarta parte de su semana a tareas manuales y repetitivas. Solo la introducción manual de datos cuesta a las empresas de EE. UU. unos 8.500 dólares por empleado al año.
Ese es el problema que OpenClaw browser automation intenta resolver. En la práctica, encaja con flujos de trabajo empresariales muy concretos:
| Caso de uso | Qué hace OpenClaw | Resultado para el negocio |
|---|---|---|
| Generación de leads | Extrae datos de contacto de directorios y páginas de empresas | El embudo comercial se llena más rápido |
| Seguimiento de precios de la competencia | Navega páginas de producto cada día y extrae precios | Inteligencia competitiva en tiempo real |
| Relleno de formularios / introducción de datos | Completa formularios web repetitivos (CRM, portales, solicitudes) | Horas ahorradas por semana |
| Monitorización de contenido | Revisa blogs de competidores, portales de empleo y notas de prensa | Señales tempranas de la competencia |
| QA / testing | Recorre flujos web para verificar que funcionan | Menos experiencias rotas para el usuario |
El mercado de agentes de IA alcanzó los 7,38 mil millones de dólares en 2025, casi duplicándose desde los 3,7 mil millones de 2023, y el 88% de las organizaciones ya usa automatización con IA en al menos una función. Ya no es una categoría de nicho.
Chromium en sandbox vs Browser Relay vs Chrome Remote Debugging: cómo elegir el modo correcto
Elegir el modo de navegador equivocado es, por experiencia, la mayor fuente de frustración para quienes empiezan con OpenClaw. He visto a gente pasar horas depurando problemas de conexión que se habrían evitado eligiendo otro modo desde el principio. OpenClaw ofrece tres formas de conectarse, y cada una tiene ventajas y desventajas reales:
- Sandbox Chromium (Managed Profile): OpenClaw levanta su propio navegador sin interfaz en el servidor. Sin sesiones iniciadas, rápido y con poca configuración, pero más detectable por sistemas anti-bot.
- Browser Relay (Existing-Session): un node host en tu máquina local reenvía instrucciones desde el VPS a tu Chrome real. Soporta sesiones iniciadas y cookies, y conserva la huella real de tu navegador.
- Chrome Remote Debugging (Remote CDP): se conecta a navegadores remotos mediante una URL WebSocket. Tiene acceso completo a la sesión y es el más complejo de configurar. Funciona con proveedores en la nube como Browserless o Browserbase.
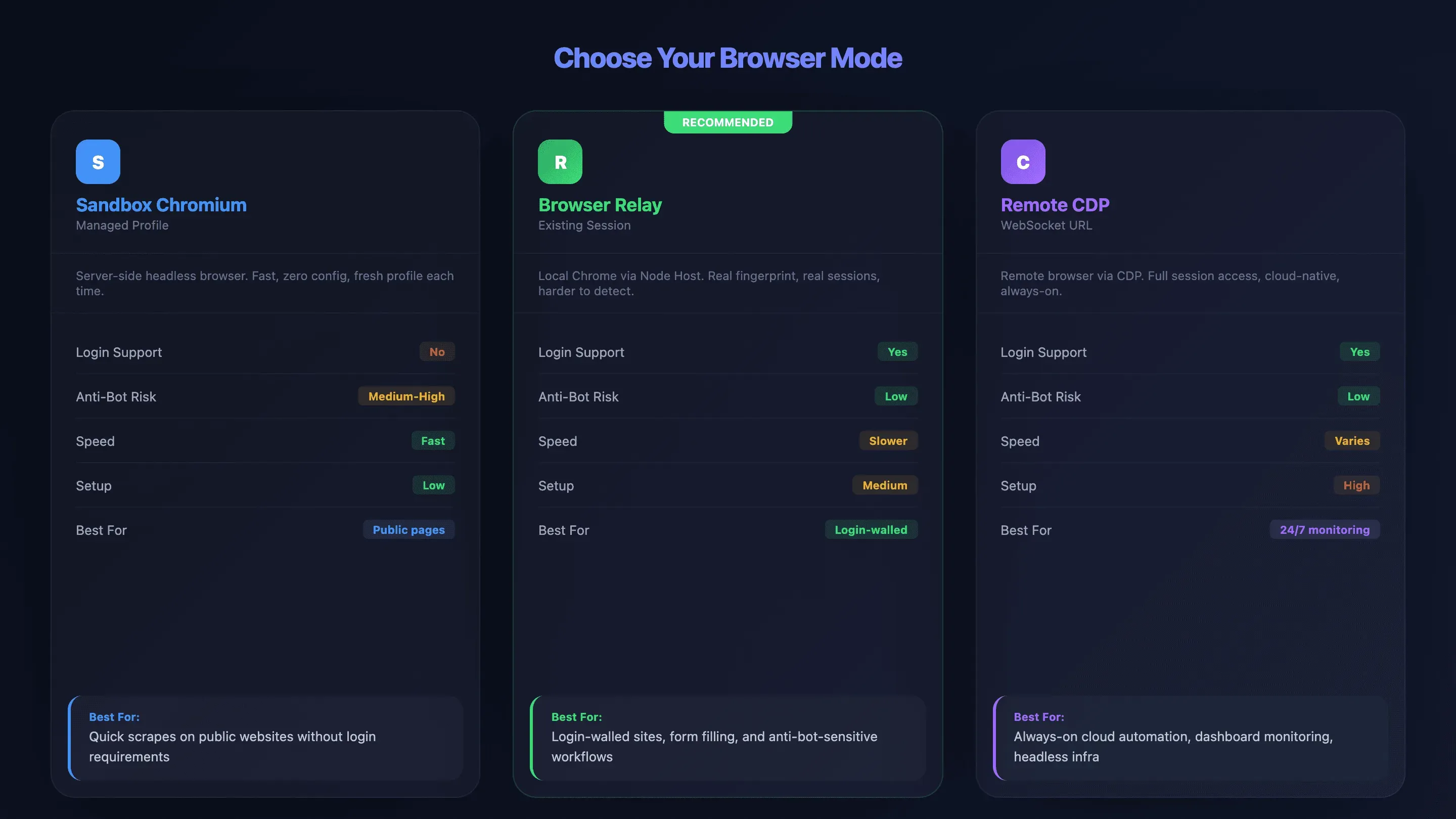
Tabla comparativa: los tres modos de navegador
| Factor | Sandbox Chromium | Browser Relay | Remote CDP |
|---|---|---|---|
| Soporte de inicio de sesión | ❌ No (perfil nuevo) | ✅ Sí (sesiones reales) | ✅ Sí (preautenticado) |
| Riesgo anti-bot | ⚠️ Medio-alto | ✅ Bajo (huella real) | ✅ Bajo (gestionado por el proveedor) |
| Velocidad | ✅ Rápido | ⚠️ Más lento (relay de red) | ⚠️ Variable |
| Complejidad de configuración | Baja | Media | Alta |
| Compatibilidad completa de funciones | ✅ Sí (todas las funciones) | ⚠️ Limitada (sin batch, sin interceptación de descargas) | Depende del proveedor |
| Ideal para | Páginas públicas, extracciones rápidas | Sitios con login, relleno de formularios | Infraestructura en la nube, monitorización 24/7 |
Diagrama de decisión: ¿qué modo deberías elegir?
Sigue estas preguntas en orden:
- "¿Necesitas iniciar sesión?" — No → Sandbox Chromium. Sí → siguiente pregunta.
- "¿El sitio tiene una protección anti-bot fuerte?" — Sí → Browser Relay (la huella real de tu navegador reduce la detección). No → Browser Relay o Remote CDP.
- "¿Necesitas una sesión persistente y siempre activa (por ejemplo, monitorizar un panel 24/7)?" — Sí → Remote CDP con un proveedor cloud. No → Browser Relay.
Ejemplos reales:
- Extraer listados públicos de Amazon → Sandbox Chromium
- Rellenar un formulario de CRM detrás de login → Browser Relay
- Monitorizar un panel interno de analítica todo el día → Remote CDP con Browserless/Browserbase
Si aciertas en esta decisión, te ahorrarás horas de depuración. En serio.
Antes de empezar
- Nivel: Intermedio (conviene manejar la CLI)
- Tiempo estimado: 45–75 minutos para la configuración completa; 10–15 minutos por paso
- Lo que necesitas: un VPS (mínimo 2 GB de RAM, recomendado 4 GB), Node.js v22.12.0 o superior, una cuenta de Tailscale (gratuita), navegador Chrome y paciencia
Paso 1: poner OpenClaw en marcha en un VPS (o de forma local)
El VPS es donde vive el "cerebro" de OpenClaw. Tienes dos formas de arrancarlo:
Opción A: hosting VPS con un clic
Varios proveedores ofrecen imágenes de OpenClaw ya configuradas:
| Proveedor | Precio inicial | Notas |
|---|---|---|
| Hostinger | Desde 6,99 USD/mes | Imagen preconfigurada |
| Tencent Cloud Lighthouse | Desde ~0,08 USD/año (promoción) | Recomendado 2 núcleos / 4 GB |
| Hetzner | Desde 4,09 USD/mes (CX22) | Mejor relación calidad-precio; instalación manual |
| DigitalOcean | Desde 4 USD/mes | Instalación manual |
| Vultr | Desde 3,50 USD/mes | Instalación manual |
Opción B: instalación manual por CLI
# Instalar mediante npm (requiere Node.js v22.12.0+)
npm install -g openclaw
# Ejecutar el asistente de incorporación
openclaw onboard
# Generar un token del gateway (guárdalo; lo necesitarás para el node host)
openclaw doctor --generate-gateway-token
# Validar la configuración
openclaw doctor --fix
Especificaciones mínimas: 2 GB de RAM (se bloquea con 1 GB), 4 GB recomendados. Cada instancia de navegador sin interfaz consume entre 400 y 800 MB en reposo. Si usas Docker, configura shm_size: '2gb' — esto es clave para la estabilidad.
Después de este paso, deberías tener OpenClaw funcionando y un token del Gateway guardado en un lugar seguro. (Yo lo guardo en un gestor de contraseñas. No lo pierdas.)
Paso 2: configurar Tailscale para conectar el VPS y tu equipo local
Tailscale crea un túnel privado y cifrado entre tu VPS y tu dispositivo local para que las instrucciones del navegador no queden expuestas en Internet. Dado que OpenClaw tuvo 512 vulnerabilidades señaladas por Kaspersky a principios de 2026, saltarse este paso no es buena idea.
# En el VPS
curl -fsSL https://tailscale.com/install.sh | sh
sudo tailscale up --ssh=true
# Anota la IP de Tailscale del VPS (100.x.x.x)
# Configura el Gateway para escuchar en la red Tailscale
openclaw config set gateway.listen "100.x.x.x:18789"
Instala Tailscale en tu equipo local desde tailscale.com/download. Ambos dispositivos deben usar la misma cuenta de Tailscale.
Alternativas si Tailscale no te convence:
| Factor | Tailscale | Cloudflare Tunnel | WireGuard |
|---|---|---|---|
| Tiempo de configuración | 5 min | 10–15 min | 20–30 min |
| Coste | Gratis (uso personal) | Gratis | Gratis |
| Traversal de NAT | Automático | Automático | Manual |
Ahora deberías poder hacer ping a la IP de Tailscale de tu VPS desde tu máquina local. Si no, comprueba que ambos dispositivos estén en la misma cuenta de Tailscale.
Paso 3: instalar el Node Host en tu dispositivo local
El node host reenvía las instrucciones del navegador desde el Gateway del VPS a tu Chrome local: es el traductor entre servidor y navegador.
# Instalar el paquete del node host
npm install -g @openclaw/node-host
# Definir el token del gateway del paso 1
export OPENCLAW_GATEWAY_TOKEN="your-token-here"
# Iniciar el node host apuntando a la IP de Tailscale de tu VPS
openclaw node install --host 100.x.x.x --port 18789
# Aprobar la conexión desde el lado del VPS
openclaw node approve <node-id>
Deberías ver una confirmación de que el nodo está conectado y aprobado. Si el paso de aprobación se queda colgado, reinicia el proceso del Gateway en el VPS.
Paso 4: instalar la extensión de Chrome de OpenClaw
La extensión le da al agente control directo sobre las pestañas del navegador. También puedes descargarla desde Chrome Web Store buscando "OpenClaw Browser Relay."
# Instalar los archivos de la extensión
openclaw browser extension install
# O manualmente:
# 1. Abre chrome://extensions
# 2. Activa "Developer mode" (interruptor arriba a la derecha)
# 3. Haz clic en "Load unpacked" → selecciona el directorio de la extensión
# 4. Ancla la extensión a la barra de herramientas
# 5. Comprueba que el indicador muestre "ON"
Si el indicador muestra "ON", ya está todo listo. Si se queda en "OFF", ve a la sección de solución de problemas más abajo.
Paso 5: ejecutar tu primera tarea de OpenClaw Browser Automation
Abre una pestaña de destino y, desde la interfaz de chat de OpenClaw, prueba algo sencillo:
Ve a https://books.toscrape.com y extrae el título y el precio de cada libro de la página
Flujo esperado: se envía la instrucción → el agente toma una captura (identifica los elementos de la página con referencias numeradas) → extrae los datos → devuelve el resultado estructurado en JSON o CSV.
Un consejo basado en experiencia: empieza con prompts muy simples. Describir demasiado lo que quieres puede confundir a la IA; añade más detalle solo si el agente malinterpreta la primera instrucción.
Para 20 libros en la primera página, calcula entre 30 y 60 segundos. ¿Te devuelve datos estructurados? Tu configuración de OpenClaw browser automation ya está funcionando.
OpenClaw Browser Automation en Windows: la ruta nativa de instalación
La mayoría de las guías de OpenClaw asumen macOS o Linux. Si estás en Windows, seguro que ya lo has notado. Un usuario de un foro lo resumió muy bien: "muchas soluciones parecían correctas en teoría, pero ninguna estaba pensada para Windows nativo."
Esto es lo que realmente funciona.
Opción A: Chrome Remote Debugging en Windows (ruta nativa recomendada)
La opción nativa más fiable en Windows. Abre PowerShell y ejecuta Chrome con depuración remota activada:
& "C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
Si Chrome no está en esa ruta, prueba:
# Revisar ubicaciones alternativas
Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse
# O comprobar AppData
& "$env:LOCALAPPDATA\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
Después, configura OpenClaw para conectarse mediante Remote CDP estableciendo cdpUrl en ws://localhost:9222 dentro de tu archivo openclaw.json.
Opción B: Docker Desktop como alternativa en Windows
Si la ruta nativa te da problemas, Docker Desktop en Windows puede ejecutar un contenedor de Chromium sin interfaz:
docker run -d --name openclaw-browser -p 9222:9222 --shm-size=2g browserless/chrome
# Indica a OpenClaw: cdpUrl: "ws://localhost:9222"
Añade otra capa de complejidad, pero para algunos usuarios es más estable. Funciona, aunque no es la solución más elegante.
Catálogo de errores específicos de Windows
| Error | Causa | Solución (PowerShell) |
|---|---|---|
| El puerto 9222 ya está en uso | Ya hay otra sesión de DevTools abierta | `Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess |
| No se encuentra el binario de Chrome | Ruta incorrecta | Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse |
| Conexión Tailscale rechazada | El Firewall de Windows la está bloqueando | New-NetFirewallRule -DisplayName "OpenClaw" -Direction Inbound -LocalPort 18789 -Protocol TCP -Action Allow |
| Errores de permisos con npm | No se está ejecutando como administrador | Ejecuta PowerShell como administrador o usa nvm-windows |
Todos los comandos anteriores son de PowerShell, no de bash. Copia y pega directamente.
Guía de supervivencia anti-bot para OpenClaw Browser Automation
La detección de bots es la principal frustración para quienes usan OpenClaw browser automation. El Chromium por defecto de OpenClaw no incluye medidas stealth integradas — los sitios lo detectan por la marca WebDriver, las dimensiones de pantalla, la huella de fuentes y la reputación de la IP. He visto agentes ser bloqueados en cuestión de segundos en algunos sitios.
Pero hay una estrategia por niveles. Empieza por la solución más sencilla y solo escala si hace falta.
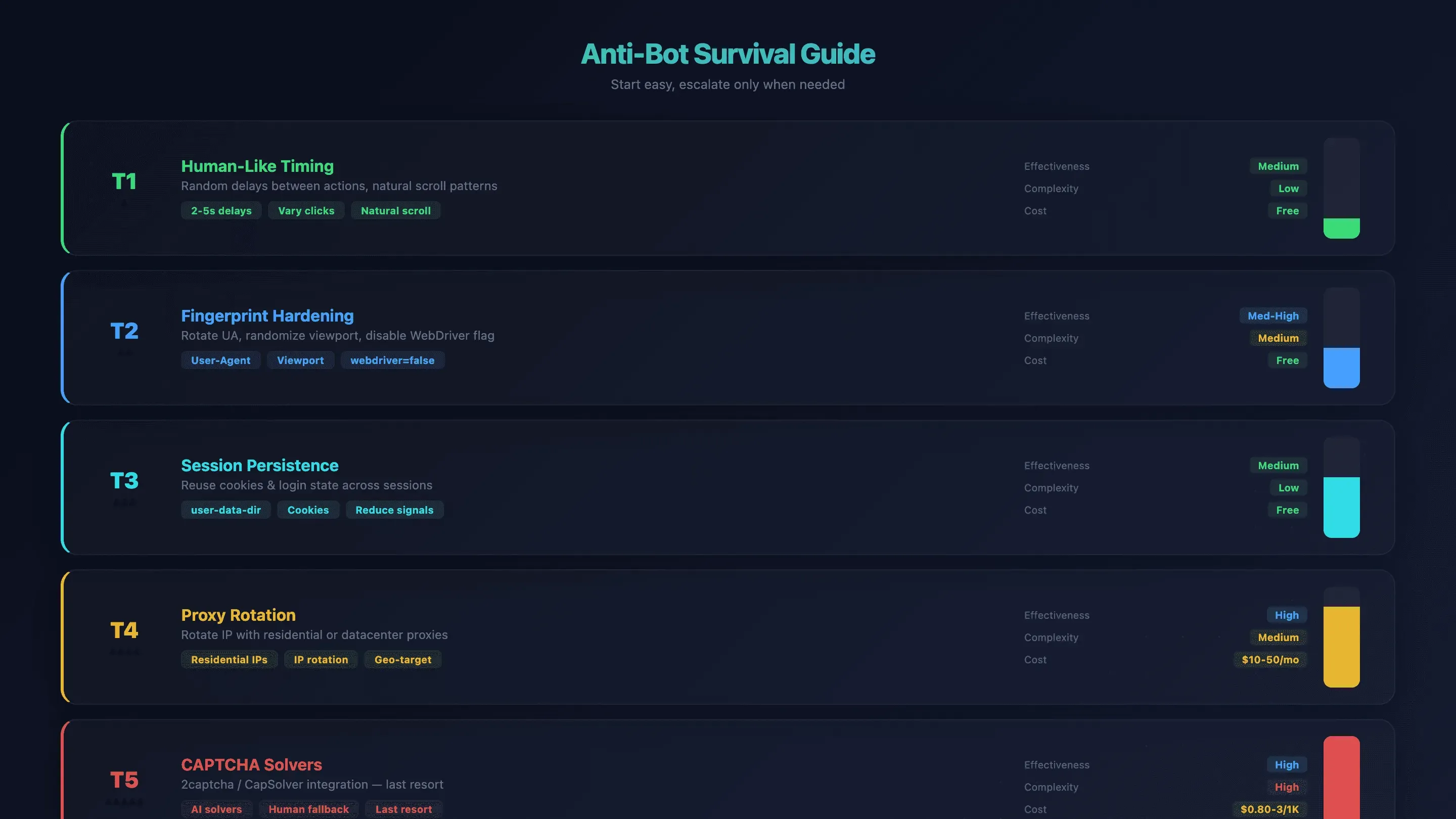
Nivel 1: tiempos y comportamiento parecidos a los humanos
Añade retrasos aleatorios entre acciones en tus prompts. En vez de hacer clic a velocidad de máquina, indica al agente: "espera entre 2 y 5 segundos entre cada clic". La IA ya varía algo el ritmo, pero las instrucciones explícitas ayudan.
Eficacia: media | Complejidad: baja | Coste: gratis
Nivel 2: endurecimiento de la huella digital
Rota las cadenas del user-agent, aleatoriza el tamaño del viewport y deja que OpenClaw desactive automáticamente la marca navigator.webdriver (mediante --disable-blink-features=AutomationControlled).
# Establecer cabeceras personalizadas
openclaw browser set headers --headers-json '{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36"}'
# Aleatorizar el viewport
openclaw browser set viewport 1366 768
# Definir zona horaria y locale
openclaw browser set timezone America/New_York
openclaw browser set locale en-US
Para una mayor evasión de detección, la comunidad recomienda Camoufox (un navegador anti-detección basado en Firefox con spoofing de huella a nivel del motor en C++).
Eficacia: media-alta | Complejidad: media | Coste: gratis
Nivel 3: persistencia de sesión
Usa user-data-dir para conservar cookies y el estado de inicio de sesión entre sesiones. Esto reduce las señales de "navegador recién creado" que activan sistemas anti-bot.
openclaw config set browser.profiles.persistent.userDataDir "/path/to/chrome-profile"
openclaw config set browser.profiles.persistent.cdpPort 18802
Eficacia: media | Complejidad: baja | Coste: gratis
Nivel 4: rotación de proxies
Cuando el timing y la huella digital no bastan, rota tu dirección IP. Los proxies residenciales son más difíciles de detectar; los de centros de datos son más rápidos y baratos.
export OPENCLAW_BROWSER_PROXY="http://user:pass@proxy.example.com:8080"
Nota: la configuración de proxy a nivel de navegador sigue siendo una solicitud de funcionalidad (GitHub Issue #8079). Actualmente, los proxies deben configurarse a nivel de sistema operativo o de entorno.
| Proveedor | Residencial | Centro de datos | Ideal para |
|---|---|---|---|
| Bright Data | 4–8,40 USD/GB | 0,43–0,60 USD/GB | Enterprise, máxima calidad |
| Oxylabs | 6–8 USD/GB | 0,48–5 USD/GB | Extracciones a gran escala |
| Decodo (Smartproxy) | 4–5,50 USD/GB | 0,70–5 USD/GB | Presupuestos medios |
| IPRoyal | 5–7 USD/GB | -- | Económico |
| DataImpulse | 1 USD/GB | -- | Coste más bajo |
Eficacia: alta | Complejidad: media | Coste: 10–50 USD/mes
Nivel 5: solucionadores de CAPTCHA
Último recurso. Integra servicios como 2captcha o CapSolver.
| Servicio | reCAPTCHA v2 | Cloudflare Turnstile | Latencia |
|---|---|---|---|
| 2Captcha | 2,99 USD/1K | 2,99 USD/1K | 15–45 s (solucionadores humanos) |
| CapSolver | 0,80–1,50 USD/1K | 0,80 USD/1K | 0,5–10 s (IA) |
FlareSolverr (bypass open source de Cloudflare) se documenta como poco fiable en 2025–2026 debido a la defensa cada vez más fuerte de Cloudflare.
Eficacia: alta | Complejidad: alta | Coste: 0,80–3 USD/1K resoluciones
Resumen anti-bot
| Técnica | Eficacia | Complejidad | Coste |
|---|---|---|---|
| Timing parecido al humano | Media | Baja | Gratis |
| Endurecimiento de huella digital | Media-alta | Media | Gratis |
| Persistencia de sesión | Media | Baja | Gratis |
| Rotación de proxies | Alta | Media | 10–50 USD/mes |
| Solucionadores de CAPTCHA | Alta | Alta | 0,80–3 USD/1K resoluciones |
Para quienes chocan una y otra vez contra muros anti-bot y solo necesitan los datos: la extracción en la nube de Thunderbit gestiona los anti-bots de forma automática en sitios web públicos — sin configurar proxies ni ajustar huellas digitales. Es un enfoque totalmente distinto (la IA lee el sitio cada vez mediante infraestructura cloud gestionada) que evita por completo la guerra anti-bot en tareas estándar de extracción de datos.
Resultado real: lo que OpenClaw Browser Automation produce de verdad
Antes de invertir 45–75 minutos en la configuración, seguramente querrás ver cómo queda el resultado final. Tiene sentido: aquí tienes tres ejemplos de flujos de trabajo con salida real.
Ejemplo 1: scraping web — extracción de datos de productos
Prompt: "Ve a https://books.toscrape.com y extrae el título y el precio de cada libro de la página"
Salida (primeras 5 filas):
| Título | Precio |
|---|---|
| A Light in the Attic | £51.77 |
| Tipping the Velvet | £53.74 |
| Soumission | £50.10 |
| Sharp Objects | £47.82 |
| Sapiens: A Brief History of Humankind | £54.23 |
Tiempo transcurrido: ~45 segundos para 20 filas (una sola página). La paginación necesitó una instrucción adicional: "Haz clic en el botón Next y repite durante 5 páginas." Total: ~100 filas en unos 3 minutos.
Ejemplo 2: automatización de formularios — relleno de un formulario web con varios campos
Escenario: rellenar un formulario de consulta a proveedor con nombre de empresa, datos de contacto e interés en un producto.
El agente toma una captura del formulario, identifica cada campo por número de referencia y lo rellena de forma secuencial. Antes: campos vacíos. Después: todos los campos completados, mensaje de confirmación mostrado. Los menús desplegables y las casillas también se manejan con el sistema de capturas — el agente "ve" las opciones y selecciona la correcta.
Tiempo transcurrido: ~30 segundos para un formulario de 6 campos.
Ejemplo 3: paginación — extracción a través de varias páginas
Resultado inicial: 20 filas de la página 1. Tras indicar "haz clic en Next y repite para todas las páginas": 1.000 filas en 50 páginas en books.toscrape.com. El agente detecta el botón "Next" mediante la captura y lo pulsa en bucle.
Tiempo transcurrido: ~12 minutos para el conjunto completo de 1.000 filas.
Comparativa lado a lado: la misma tarea de scraping en Thunderbit
Para el mismo ejemplo de books.toscrape.com, así sería el flujo en Thunderbit:
- Instala la extensión de Chrome de Thunderbit (~30 segundos)
- Ve a la página
- Haz clic en "AI Suggest Fields" → la IA detecta Title, Price, Availability y Rating
- Haz clic en "Scrape" → se extraen 20 filas
- Usa los controles de paginación → se raspan todas las páginas
- Exporta a Google Sheets (gratis)
Tiempo total: ~3 minutos desde cero hasta tener los datos exportados, sin VPS, sin CLI y sin configuración.
La idea no es que una herramienta sea "mejor" que la otra. La adecuada depende de lo que realmente quieras hacer.
Prueba la extensión de Chrome de Thunderbit
Cuándo OpenClaw Browser Automation es demasiado para lo que necesitas (y qué usar en su lugar)
OpenClaw destaca en automatizaciones complejas, de varios pasos y estilo agente: flujos con login, encadenar acciones del navegador con comandos de shell, ejecución 24/7 en un VPS. Pero si el objetivo es "extraer datos de productos de una página de listado" o "sacar emails de un directorio", todo el stack de VPS + Tailscale + node host probablemente sea demasiado pesado.
He visto a gente invertir más de 60 minutos en una configuración para una tarea que tarda 2 minutos con una herramienta más simple. Mal negocio.
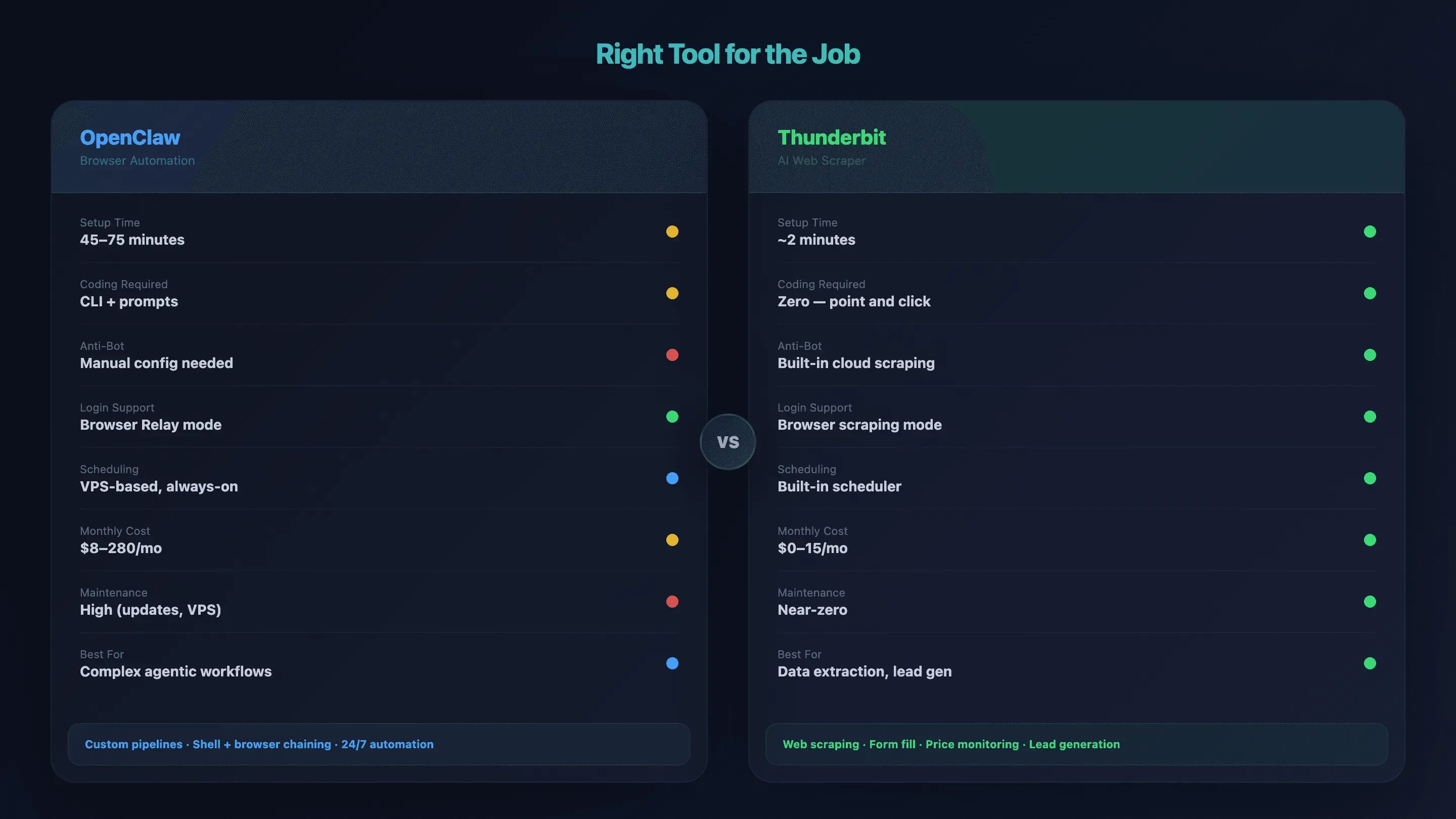
La herramienta adecuada para cada trabajo: tabla comparativa
| Factor | OpenClaw Browser Automation | Thunderbit |
|---|---|---|
| Tiempo de configuración | 45–75 min (VPS + Tailscale + node host) | ~2 min (instalación de la extensión de Chrome) |
| Requiere programación | CLI + prompts en lenguaje natural | Cero — clic en "AI Suggest Fields" → "Scrape" |
| Gestión anti-bot | Manual (proxy, configuración de huella) | Scraping en la nube integrado |
| Navegación tras login | ✅ Browser Relay / debug remoto | ✅ Modo de scraping del navegador |
| Enriquecimiento de subpáginas | Script personalizado por flujo | Scraping de subpáginas con un clic |
| Ejecuciones programadas / 24×7 | Basado en VPS, siempre activo | Scraper programado integrado |
| Coste mensual | 8–14 USD (uso hobby) a 110–280 USD (uso intensivo) | 0 USD (plan gratuito) a 15 USD/mes |
| Carga de mantenimiento | Alta (actualizaciones, VPS, depuración) | Casi nula: la IA se adapta a cambios de diseño |
| Ideal para | Flujos complejos de tipo agente, pipelines personalizados | Extracción de datos, relleno de formularios, generación de leads, seguimiento de precios |
Enrutamiento según el caso de uso
- Necesitas flujos de trabajo multi-paso y tipo agente que encadenen acciones del navegador con comandos de shell, apps de mensajería y bases de datos → OpenClaw es la mejor opción.
- Necesitas extraer datos de sitios web, rellenar formularios o monitorizar precios sin tocar un terminal → Thunderbit te llevará más rápido. Puedes ver el canal de YouTube de Thunderbit para demostraciones rápidas.
- Necesitas un script ligero para un endpoint API concreto → quizá te baste con un script sencillo en Python con requests.
Esa es exactamente la lógica que uso cuando alguien de mi equipo me pregunta "¿qué herramienta debería usar para esto?"
Errores comunes de OpenClaw Browser Automation y cómo solucionarlos
Guarda esta sección en favoritos. Está organizada por síntomas para que puedas usar Ctrl+F y encontrar una solución rápido.
"Connection Refused" o el Node Host no conecta
Causas probables (revísalas en este orden):
- Tailscale no está funcionando en ambos dispositivos → ejecuta
tailscale statusen ambos - El Gateway no está configurado para escuchar en la red Tailscale (sigue en localhost) →
openclaw config set gateway.listen "100.x.x.x:18789" - IP incorrecta → compruébala con
tailscale ip -4 - El firewall bloquea el puerto 18789 →
sudo ufw allow 18789/tcp(Linux) o añade una regla en el Firewall de Windows
El indicador de la extensión sigue en "OFF" o la pestaña no se detecta
- La extensión no se cargó en modo Developer →
chrome://extensions→ activa Developer mode → recarga - El node host no está en ejecución → reinicia con
openclaw node start - Conflicto con la instancia de Chrome → cierra todas las instancias de Chrome, vuelve a abrir y recarga la extensión
El agente devuelve datos vacíos o incorrectos
- La página no cargó por completo: indica al agente que "espere 3 segundos después de navegar antes de extraer". Muchas SPAs necesitan tiempo para renderizar.
- Bloqueo anti-bot: comprueba si estás viendo una página CAPTCHA en lugar del contenido real. Cambia de Sandbox Chromium a Browser Relay.
- Captura desactualizada: pide al agente que "tome una nueva captura" — los números de referencia quedan obsoletos tras navegar.
"Port 9222 Already in Use"
Suele pasar cuando Chrome DevTools u otra herramienta de automatización ya está usando ese puerto.
# macOS/Linux
lsof -i :9222 | grep LISTEN
kill -9 <PID>
# Windows PowerShell
Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess | Stop-Process -Force
El VPS se queda sin memoria
Cada instancia de navegador sin interfaz usa entre 400 y 800 MB de RAM. Ejecutar varias a la vez puede tumbar un VPS pequeño.
Soluciones:
- Desactiva la carga de imágenes, CSS y fuentes:
openclaw browser network route --abort "**/*.{png,jpg,gif,css,woff2}" - Limita las instancias concurrentes a lo que permita tu RAM
- Configura
shm_size: '2gb'en Docker - Activa la hibernación de sesión:
OPENCLAW_HIBERNATE_AFTER=300 - Sube a un VPS con 4 GB o más si necesitas más margen
Consejos para que tu OpenClaw Browser Automation funcione sin problemas
Algunas buenas prácticas que he ido aprendiendo al gestionar estas configuraciones con el tiempo:
- Desactiva imágenes, hojas de estilo y fuentes en tareas de scraping solo de datos. Esto reduce mucho el consumo de recursos y acelera el proceso.
- Reutiliza instancias del navegador en lugar de lanzar una nueva por tarea. Las instancias nuevas cuestan más RAM y generan más señales anti-bot.
- Empieza con prompts simples. Añade detalle solo si el agente interpreta mal la tarea. Explicar demasiado puede confundir más que ayudar.
- Supervisa el uso de recursos del VPS (CPU, RAM) y escala antes de llegar al límite. Depurar un VPS caído a las 2 de la madrugada no es divertido.
- Mantén OpenClaw y la extensión de Chrome actualizados — pero prueba primero las actualizaciones en un entorno de staging. OpenClaw publica aproximadamente 13 versiones al mes, y no todas salen perfectas.
- Para tareas repetitivas y continuas (comprobaciones diarias de precios, capturas semanales de leads), el scraper programado de Thunderbit te permite definir intervalos en lenguaje natural y olvidarte por completo del mantenimiento del VPS.
Consideraciones éticas y legales
Breve, pero importante. Respeta robots.txt (formalizado como estándar IETF en RFC 9309), limita la velocidad de tus solicitudes, revisa los términos de servicio de los sitios objetivo y trata los datos personales conforme al RGPD y las leyes de privacidad. El precedente hiQ v. LinkedIn (2022) estableció que extraer datos públicamente accesibles no viola la CFAA, pero eso no significa que todo valga. Usar la automatización de forma responsable protege tanto a tu negocio como a ti. Para más información sobre este tema, consulta nuestra guía sobre implicaciones legales del web scraping.
Para terminar
OpenClaw browser automation es una opción potente para flujos web complejos de varios pasos controlados mediante lenguaje natural. Lo más importante es esto:
- Elige bien el modo de navegador desde el principio (Sandbox, Relay, Remote CDP) — esa sola decisión te ahorra horas de depuración.
- Los usuarios de Windows sí tienen una ruta viable, pero hay que seguir comandos específicos de Windows y vigilar problemas de firewall y rutas.
- La gestión anti-bot es un reto real — empieza por las técnicas más simples (timing, huella digital) y solo escala cuando haga falta.
- Mira el resultado antes de comprometerte. Si solo necesitas datos estructurados de una página de listados, una herramienta sin código como Thunderbit te lo da en minutos y sin mantenimiento.
- Presupuesta el mantenimiento. OpenClaw publica unas 13 versiones al mes, el coste del VPS suma, y depurar forma parte del trabajo.
Si quieres probar primero la ruta sencilla, Thunderbit ofrece un plan gratuito — instala la extensión, extrae una página y comprueba si cubre tu caso de uso antes de invertir en una configuración completa con VPS. Si decides ir por OpenClaw, guarda esta guía. Vas a necesitar el catálogo de errores tarde o temprano — y que tus instancias del navegador nunca se queden sin RAM.
Preguntas frecuentes
¿Cuál es la diferencia entre OpenClaw Sandbox Chromium y Browser Relay?
Sandbox Chromium ejecuta un navegador sin interfaz en el servidor: es rápido y requiere poca configuración, pero crea un perfil nuevo cada vez (sin sesiones iniciadas) y los sistemas anti-bot lo detectan con más facilidad. Browser Relay envía las instrucciones a tu Chrome real en el equipo local, por lo que soporta inicios de sesión, hereda la huella real de tu navegador y es más difícil de detectar como automatización. La desventaja es que Browser Relay es más lento por el relay de red y tiene algunas limitaciones de funciones (sin acciones por lotes ni interceptación de descargas).
¿Puedo usar OpenClaw browser automation en Windows sin WSL?
Sí, aunque con matices. La ruta nativa más fiable en Windows es Chrome Remote Debugging mediante PowerShell (chrome.exe --remote-debugging-port=9222). Docker Desktop es una alternativa si eso resulta poco fiable. El soporte nativo completo del Node Host en Windows puede tener algunas asperezas — revisa la documentación actual y prepárate para problemas específicos de Windows, como bloqueos del firewall y diferencias en las rutas de los binarios. Todos los comandos de la sección de Windows de esta guía son de PowerShell, no de bash.
¿Cómo manejo los CAPTCHA en OpenClaw browser automation?
Empieza reduciendo el riesgo de detección: añade tiempos parecidos a los humanos, endurece la huella del navegador y usa persistencia de sesión para evitar señales de navegador nuevo. Si los CAPTCHA persisten, integra un servicio de resolución como 2captcha (2,99 USD/1K resoluciones) o CapSolver (0,80–1,50 USD/1K, impulsado por IA). Para sitios públicos donde solo necesitas los datos, la extracción en la nube de Thunderbit gestiona los anti-bots automáticamente sin necesidad de proxy ni configuración de CAPTCHA.
¿OpenClaw browser automation es gratis?
OpenClaw en sí es open source (licencia MIT) y gratuito. Sin embargo, para ejecutarlo necesitas infraestructura: un VPS de 4 a 15 USD/mes, más servicios opcionales como rotación de proxies (10–50 USD/mes) o solucionadores de CAPTCHA (pago por resolución). El coste mensual total va desde 8–14 USD para uso ocasional hasta 110–280 USD para cargas intensivas de automatización. En comparación, el plan gratuito de Thunderbit cubre el scraping básico sin costes de infraestructura.
¿Qué hago si mi agente de OpenClaw sigue devolviendo resultados vacíos?
Tres cosas que revisar, en este orden: primero, puede que la página no haya cargado del todo — indica al agente que "espere 3 segundos después de navegar antes de extraer". Segundo, quizá estés chocando con un muro anti-bot — si el agente está "viendo" una página CAPTCHA en lugar del contenido real, cambia de Sandbox Chromium a Browser Relay. Tercero, las referencias de la captura pueden estar desactualizadas — pide al agente que "tome una nueva captura" después de cualquier navegación. Si nada de esto funciona, revisa el uso de memoria del VPS — una instancia de navegador caída devuelve resultados vacíos sin avisar.
Prueba Thunderbit para extraer datos web más rápido Get Started Free




