

La web es un terreno salvaje en 2026: ya la mitad del tráfico de internet son bots, y los rastreadores web de código abierto son los héroes anónimos que trabajan entre bastidores, impulsando desde el monitoreo de precios hasta el entrenamiento de IA. Llevo años trabajando en SaaS y automatización, y si hay algo que he aprendido es que elegir el rastreador autohospedado adecuado puede ahorrarle a tu equipo meses de dolores de cabeza (y quizá alguna que otra sesión de depuración a medianoche). Tanto si estás extrayendo unos pocos productos como si estás rastreando millones de URLs para investigación, las alternativas de código abierto a Firecrawl de esta lista cubren todas las necesidades, sin importar tu escala, tu stack tecnológico o tu tolerancia a la complejidad.
Pero aquí está la clave: no existe una solución universal para todos. Algunos equipos necesitan la potencia bruta de Scrapy o la capacidad de archivo de Heritrix, mientras que otros quizá encuentren demasiado costoso mantener bibliotecas de código abierto. Así que vamos a desglosar las 9 mejores alternativas de código abierto a Firecrawl para 2026, ver dónde destaca cada una y ayudarte a elegir la herramienta adecuada para las necesidades de tu negocio, sin el dolor del ensayo y error.
Cómo elegir la mejor alternativa de código abierto a Firecrawl para tu negocio
Antes de lanzarte a la lista, hablemos de estrategia. El panorama del rastreo web de código abierto es más diverso que nunca, y tu elección debería depender de algunos factores clave:
- Facilidad de uso: ¿Quieres una interfaz de apuntar y hacer clic, o te sientes cómodo escribiendo en Python, Go o JavaScript?
- Escalabilidad: ¿Vas a extraer datos de un solo sitio o necesitas rastrear millones de páginas en cientos de dominios?
- Tipo de contenido: ¿Tu sitio objetivo es HTML estático o depende de JavaScript pesado y carga dinámica?
- Necesidades de integración: ¿Cómo quieres usar los datos: exportarlos a Excel, enviarlos a una base de datos o incorporarlos a una canalización de analítica?
- Mantenimiento: ¿Tienes recursos para mantener código personalizado o prefieres una herramienta que se adapte automáticamente a los cambios del sitio?
Aquí tienes una guía rápida para ayudarte a decidir:
| Escenario | Mejor herramienta(s) |
|---|---|
| Sin código, navegación sin conexión | HTTrack |
| Rastreo a gran escala y multidominio | Scrapy, Apache Nutch, StormCrawler |
| Sitios dinámicos o con mucho JS | Puppeteer |
| Automatización de formularios / inicio de sesión | MechanicalSoup |
| Descarga/archivo de sitios estáticos | Wget, HTTrack, Heritrix |
| Desarrollador Go, alto rendimiento | Colly |
Ahora sí, vamos a ver las 9 mejores alternativas de código abierto a Firecrawl para 2026.
1. Scrapy: la mejor opción para rastreo en Python a gran escala
Scrapy es el campeón de peso pesado del rastreo web de código abierto. Construido en Python, es el framework preferido por los desarrolladores que necesitan rastrear a gran escala: millones de páginas, actualizaciones frecuentes y lógica compleja del sitio.
¿Por qué Scrapy?
- Escala masiva: Scrapy puede manejar miles de solicitudes por segundo y lo usan empresas que extraen miles de millones de páginas al mes (Zyte).
- Extensible y modular: escribe spiders personalizados, conecta middleware para proxies, gestiona inicios de sesión y exporta a JSON, CSV o bases de datos.
- Comunidad activa: muchísimos plugins, documentación y respuestas en Stack Overflow.
- Probado en producción: lo usan equipos de comercio electrónico, noticias e investigación de todo el mundo.
Limitaciones: curva de aprendizaje pronunciada para quienes no programan, y tendrás que mantener tus spiders cuando los sitios cambien. Pero si buscas control total y escalabilidad, Scrapy es difícil de superar.
2. Apache Nutch: la mejor opción para motores de búsqueda empresariales
Apache Nutch es el veterano de los rastreadores de código abierto, diseñado para rastreo a escala de internet y nivel empresarial. Si sueñas con crear tu propio motor de búsqueda o rastrear millones de dominios, Nutch es tu aliado.
¿Por qué Apache Nutch?
- Escala impulsada por Hadoop: construido sobre Hadoop, Nutch puede rastrear miles de millones de páginas en clústeres de servidores (Common Crawl lo usa para rastrear la web pública).
- Rastreo por lotes: le pasas una lista de URLs semilla y lo dejas correr; ideal para trabajos programados y de gran escala.
- Integración: funciona con Solr, Elasticsearch y canalizaciones de big data.
Limitaciones: configuración compleja (piensa en clústeres Hadoop y archivos de configuración Java) y está más orientado al rastreo bruto que a la extracción de datos estructurados. Es excesivo para proyectos pequeños, pero incomparable para rastreo a escala web.
3. Heritrix: la mejor opción para archivado web y cumplimiento normativo
Heritrix es el rastreador propio de Internet Archive, creado específicamente para archivado web y preservación digital.
¿Por qué Heritrix?
- Completitud de nivel archivístico: captura cada página, recurso y enlace; perfecto para cumplimiento legal o instantáneas históricas.
- Salida WARC: guarda todo en archivos Web ARChive estandarizados, listos para reproducción o análisis.
- Administración web: configura y supervisa los rastreos desde una interfaz de navegador.
Limitaciones: es pesado (requiere mucho disco y memoria), no ejecuta JavaScript y genera archivos brutos en lugar de tablas de datos estructurados. Es ideal para bibliotecas, archivos o sectores regulados.
4. Colly: la mejor opción para desarrolladores Go de alto rendimiento
Colly es el favorito de los desarrolladores Go: un raspador web rápido, ligero y altamente concurrente.
¿Por qué Colly?
- Rapidísimo: la concurrencia de Go permite a Colly extraer miles de páginas con uso mínimo de CPU y RAM (Oxylabs).
- API simple: define callbacks para elementos HTML y gestiona cookies y robots.txt automáticamente.
- Ideal para sitios estáticos: perfecto para páginas renderizadas en servidor, APIs o cuando quieres integrar la extracción en un backend Go.
Limitaciones: no incorpora renderizado de JavaScript, así que para sitios dinámicos tendrás que combinarlo con algo como Chromedp, y necesitarás saber Go.
5. MechanicalSoup: la mejor opción para automatización simple de formularios

MechanicalSoup es una biblioteca de Python que hace de puente entre las simples peticiones HTTP y la automatización completa del navegador.
¿Por qué MechanicalSoup?
- Automatización de formularios: inicia sesión fácilmente, completa formularios y mantiene sesiones; ideal para extraer datos detrás de autenticación.
- Ligero: usa Requests y BeautifulSoup por debajo, así que es rápido y fácil de configurar.
- Perfecto para sitios interactivos: si necesitas enviar formularios de búsqueda o extraer datos después de iniciar sesión, MechanicalSoup es una gran elección (Apify Blog).
Limitaciones: no ejecuta JavaScript, así que no funcionará en sitios con mucho JS. Es mejor para páginas estáticas o renderizadas en servidor con interacciones simples.
6. Puppeteer: la mejor opción para sitios dinámicos y con mucho JavaScript
Puppeteer es la navaja suiza para extraer datos de sitios web modernos con mucho JavaScript. Es una biblioteca de Node.js que te da control total sobre un navegador Chrome sin interfaz.
¿Por qué Puppeteer?
- Gestiona contenido dinámico: extrae datos de SPAs, scroll infinito y páginas que cargan datos mediante AJAX (Browserless Guide).
- Simulación de usuario: haz clic en botones, completa formularios, toma capturas de pantalla e incluso resuelve CAPTCHAs (con plugins).
- Automatización potente: ideal para pruebas, monitoreo y extracción de cualquier cosa que un usuario real pueda ver.
Limitaciones: consume muchos recursos (ejecuta instancias completas de Chrome), es más lento que los raspadores que solo usan HTTP y escalarlo requiere hardware robusto u orquestación en la nube.
7. Wget: la mejor opción para descargas rápidas desde la línea de comandos

Wget es la herramienta clásica de línea de comandos para descargar sitios web y archivos estáticos.
¿Por qué Wget?
- Simplicidad: descarga sitios completos o directorios con un solo comando; no hace falta programar.
- Velocidad: escrito en C, es rápido y eficiente.
- Excelente para contenido estático: perfecto para sitios de documentación, blogs o descargas masivas de archivos (HuggingFace Guide).
Limitaciones: no ejecuta JavaScript ni gestiona formularios, y descarga páginas brutas, no datos estructurados. Piénsalo como una aspiradora digital para sitios estáticos.
8. HTTrack: la mejor opción para navegación sin conexión, sin código
HTTrack es el primo fácil de usar de Wget, con una interfaz gráfica para clonar sitios web.
¿Por qué HTTrack?
- Simplicidad con interfaz gráfica: su asistente paso a paso lo hace accesible para usuarios sin perfil técnico.
- Navegación sin conexión: ajusta los enlaces para que puedas navegar localmente por los sitios copiados.
- Ideal para archivado: perfecto para investigadores, marketers o cualquiera que quiera una instantánea de un sitio sin programar (Reddit DataHoarder).
Limitaciones: no admite contenido dinámico, puede ir lento en sitios grandes y no está pensado para extraer datos estructurados.
9. StormCrawler: la mejor opción para rastreo distribuido en tiempo real

StormCrawler es el rastreador moderno y distribuido para equipos que necesitan datos web continuos y en tiempo real a gran escala.
¿Por qué StormCrawler?
- Rastreo en tiempo real: construido sobre Apache Storm, procesa los datos como flujos; ideal para monitoreo de noticias o motores de búsqueda (Wikipedia).
- Modular y escalable: añade módulos de análisis, indexación y procesamiento personalizado según lo necesites.
- Usado por Common Crawl: impulsa el conjunto de datos de noticias de uno de los mayores archivos web abiertos.
Limitaciones: requiere desarrollo en Java y un clúster de Storm, así que es más adecuado para equipos con experiencia en sistemas distribuidos. Es excesivo para proyectos pequeños.
Comparación de alternativas de código abierto a Firecrawl: ¿qué competidor gratuito se ajusta a tus necesidades?
Aquí tienes una vista comparativa de las 9 herramientas:
| Herramienta | Caso de uso ideal | Ventajas clave | Desventajas | Lenguaje / configuración |
|---|---|---|---|---|
| Scrapy | Rastreo a gran escala y frecuente | Potente, escalable, enorme comunidad | Curva de aprendizaje pronunciada, requiere Python | Framework de Python |
| Apache Nutch | Rastreo empresarial a escala web | Impulsado por Hadoop, probado a gran escala | Configuración compleja, orientado a lotes | Java/Hadoop |
| Heritrix | Rastreo para archivado y cumplimiento | Captura completa del sitio, salida WARC | Pesado, sin JS, archivos brutos | Aplicación Java, interfaz web |
| Colly | Desarrolladores Go, extracción de alto rendimiento | Rápido, API simple, concurrencia | Sin JS, requiere Go | Biblioteca Go |
| MechanicalSoup | Automatización de formularios, extracción con inicio de sesión | Ligero, gestión de sesiones | Sin JS, escala limitada | Biblioteca de Python |
| Puppeteer | Sitios dinámicos y con mucho JS | Control total del navegador, automatización | Consume muchos recursos, requiere Node.js | Biblioteca de Node.js |
| Wget | Descarga de sitios estáticos, acceso sin conexión | Simple, rápido, por CLI | Sin JS, páginas brutas | Herramienta de línea de comandos |
| HTTrack | Usuarios no técnicos, archivado de sitios | Interfaz gráfica, navegación sin conexión fácil | Sin JS, lento en sitios grandes | Aplicación de escritorio (GUI) |
| StormCrawler | Rastreo distribuido en tiempo real | Escalable, modular, en tiempo real | Se necesita experiencia en Java/Storm | Clúster Java/Storm |
¿Deberías construir tu propio rastreador o usar una alternativa de código abierto ya existente a Firecrawl?
Esta es la verdad honesta: construir tu propio rastreador suena divertido, hasta que te ves hundido en mantenimiento, proxies y dolores de cabeza por medidas anti-bot. Las herramientas de código abierto de arriba condensan años de experiencia acumulada y sabiduría de la comunidad. Según informes del sector, usar soluciones ya existentes es la forma más rápida y fiable de obtener resultados y evitar reinventar la rueda (IveerData).
- Adopta código abierto si: tus necesidades encajan con lo que ya existe, quieres reducir el tiempo de desarrollo y valoras el soporte de la comunidad.
- Construye el tuyo si: tienes requisitos realmente únicos, experiencia interna profunda y la extracción de datos es el núcleo de tu negocio.
Sin embargo, el código abierto no es “gratis” si calculas el coste del tiempo de ingeniería, el mantenimiento de servidores y las actualizaciones constantes para combatir las medidas anti-extracción. Si quieres las ventajas de un rastreador potente sin escribir código, hay una opción más.
Bonificación: cuando el código abierto es demasiado complejo, prueba Thunderbit
Aunque las herramientas anteriores son increíbles para desarrolladores, todas comparten limitaciones comunes: requieren conocimientos de programación, tienen problemas con bots anti-IA dinámicos y necesitan mantenimiento constante.
Thunderbit es mi recomendación de referencia para cualquiera que quiera superar esas limitaciones. Tiende un puente entre la potencia de extracción y la facilidad de uso.
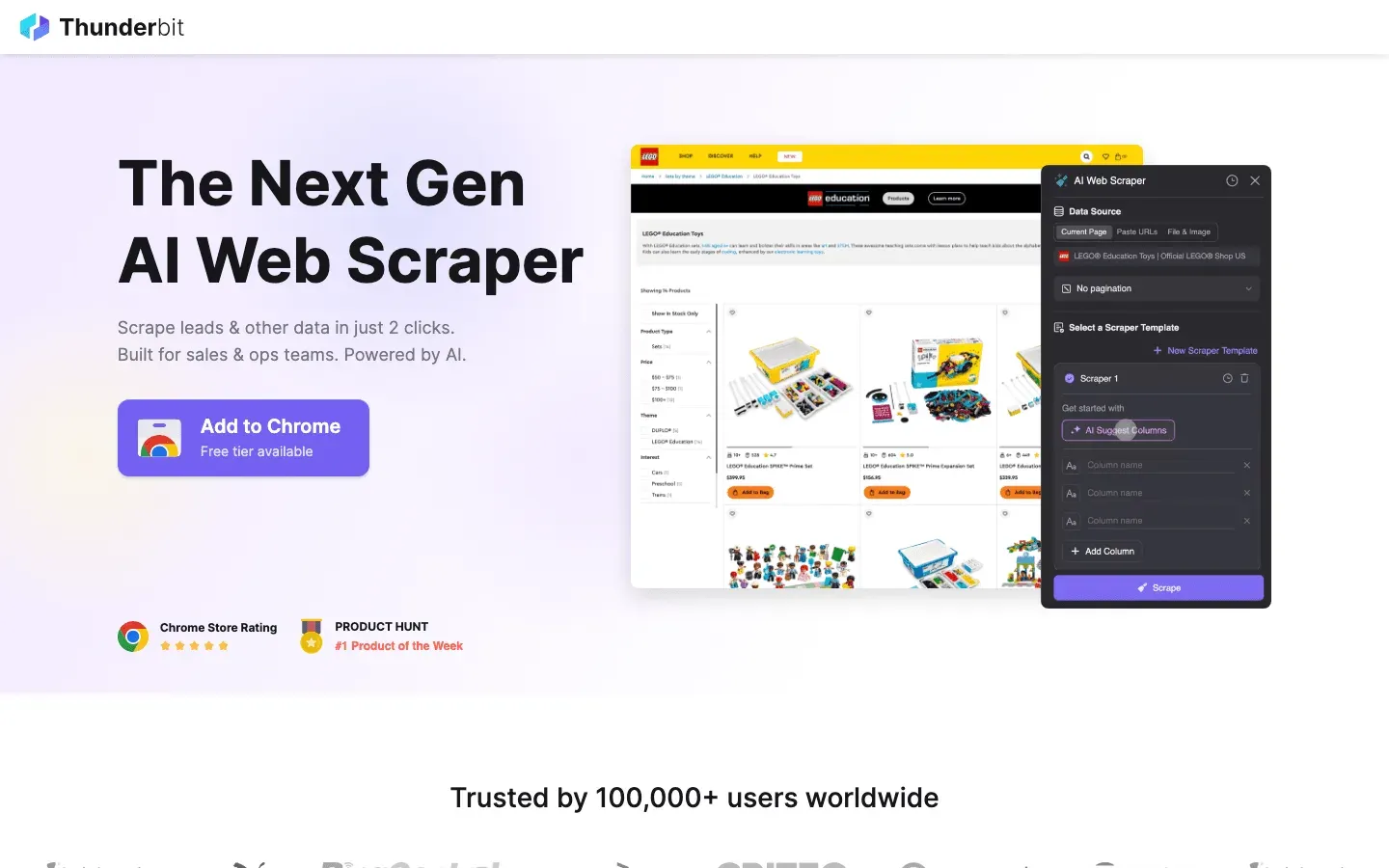
¿Por qué considerar Thunderbit en lugar de una solución de código abierto?
- No requiere programar nada: a diferencia de Scrapy o Puppeteer, Thunderbit es una extensión de Chrome impulsada por IA. Haces clic en “AI Suggest Fields” y la herramienta crea el raspador por ti.
- Resuelve lo difícil: el contenido dinámico, el scroll infinito y la paginación se gestionan automáticamente con IA, ahorrándote horas de escribir scripts personalizados.
- Exportación instantánea: pasa de una web a Excel, Google Sheets o Notion en dos clics.
- Sin mantenimiento: no necesitas actualizar tu código cuando un sitio cambia su diseño; la IA de Thunderbit se adapta por ti.
Si eres comercial, marketer o investigador y quieres datos ya sin aprender Python o Go, Thunderbit es el complemento perfecto para las herramientas de código abierto de esta lista.
¿Quieres verlo en acción? Descarga la extensión de Chrome y pruébala por tu cuenta.
Prueba Thunderbit AI Web Scraper
Conclusión: encontrar el rastreador web autohospedado adecuado para 2026
Lee más guías sobre extracción web Get Started Free
El mundo de las alternativas de código abierto a Firecrawl es más rico que nunca. Tanto si necesitas la escala bruta de Scrapy o Nutch como la fidelidad de archivado de Heritrix, hay una solución para cada escenario empresarial. La clave está en ajustar la herramienta a tus necesidades: no diseñes algo demasiado complejo si solo necesitas una extracción rápida de datos, y no escatimes si vas a rastrear a escala de internet.
Y recuerda: si el camino del código abierto resulta demasiado técnico o consume demasiado tiempo, herramientas de IA como Thunderbit están listas para echarte una mano.
¿Listo para empezar? Pon en marcha Scrapy para tu próximo gran proyecto de datos, o prueba Thunderbit para una extracción sencilla impulsada por IA. Si quieres más consejos sobre extracción web, visita el blog de Thunderbit para encontrar análisis en profundidad y tutoriales.
Prueba Thunderbit para extracción web impulsada por IA
Preguntas frecuentes
1. ¿Cuál es la principal ventaja de usar alternativas de código abierto a Firecrawl?
Las alternativas de código abierto ofrecen flexibilidad, ahorro de costes y la posibilidad de autohospedar y personalizar tu rastreador. Evitas la dependencia del proveedor y te beneficias del soporte y las actualizaciones de la comunidad activa.
2. ¿Qué herramienta es mejor para usuarios no técnicos que necesitan resultados rápidos?
HTTrack es una opción de código abierto sólida para navegación sin conexión. Sin embargo, para extracción de datos estructurados (como tablas de Excel), recomendamos la herramienta adicional Thunderbit por sus capacidades de IA.
3. ¿Cómo gestiono sitios web dinámicos con mucho JavaScript?
Puppeteer es tu mejor opción: controla un navegador real, así que puede extraer cualquier cosa que un usuario pueda ver, incluidas las SPAs y el contenido cargado por AJAX.
4. ¿Cuándo debería usar un rastreador pesado como Apache Nutch o StormCrawler?
Si necesitas rastrear millones de páginas en muchos dominios, o requieres un rastreo distribuido en tiempo real (por ejemplo, para motores de búsqueda o monitoreo de noticias), estas herramientas están pensadas para escalar y ofrecer fiabilidad.
5. ¿Es mejor construir mi propio rastreador o usar una solución de código abierto ya existente?
Para la mayoría de los equipos, usar y personalizar una herramienta de código abierto ya existente es más rápido, barato y fiable. Solo conviene construir la tuya si tienes necesidades muy especializadas y recursos para mantenerla a largo plazo.
Feliz rastreo, y que tus datos estén siempre frescos, estructurados y listos para la acción.
Prueba Thunderbit AI Web Scraper gratis Get Started Free
Saber más
- Las 5 mejores herramientas de extracción de datos web en 2026
- Los 15 mejores rastreadores web con IA que debes conocer en 2025
- Las 5 mejores herramientas de extracción de datos web en 2026
- Las 7 herramientas de extracción web más populares para usar en 2026
- Las 6 herramientas esenciales de raspado web para triunfar en 2025




