La necesidad de datos en la web está por las nubes, y para 2025, se ha vuelto la herramienta predilecta de los equipos que quieren extraer información de forma más lista y eficiente. Si trabajas en ventas, ecommerce o simplemente eres un fanático de los datos como yo, seguro ya notaste que el raspado web no es solo “sacar datos”, sino hacerlo rápido, a gran escala y sin que te bloqueen la IP. Con el mercado del raspado web apuntando a crecer de $7.48 mil millones en 2025 a casi $38.4 mil millones para 2034 (), la competencia y los retos están más duros que nunca.
Pero aquí viene el verdadero desafío: la web de hoy es un laberinto de contenido dinámico, trampas anti-bots y diseños que cambian cada dos por tres. He visto más de un raspador estrellarse por no seguir buenas prácticas o por subestimar lo avanzadas que son las defensas anti-scraping. Así que vamos a repasar las mejores prácticas reales para lograr eficiencia con Node.js en el raspado web, con anécdotas, un toque de humor y muchos tips prácticos.
¿Por qué Node.js es la mejor opción para un raspado web eficiente?
Si alguna vez intentaste extraer cientos o miles de páginas al mismo tiempo, sabes que la velocidad y la concurrencia lo son todo. Ahí es donde Node.js brilla. Su modelo de I/O asíncrono y no bloqueante está hecho para manejar montones de solicitudes de red a la vez—imagínalo como el mejor malabarista de la web (). Mientras otros lenguajes se quedan esperando a que termine cada petición, Node.js sigue girando su event loop, gestionando solicitudes como un artista hiperactivo.
He visto a Node.js dejar atrás a Python y Java en escenarios donde se necesitan actualizaciones en tiempo real y extracción a gran escala, sobre todo en sitios llenos de JavaScript. De hecho, ya usan Node.js para backend y automatización, haciéndolo la tecnología web más popular del planeta.
Node.js vs. Otros Frameworks de Raspado Web
Vamos a ponernos un poco técnicos. Así se compara Node.js con otras opciones:
| Framework | Fortalezas | Debilidades | Mejores usos |
|---|---|---|---|
| Node.js | Asíncrono, excelente para concurrencia, gran ecosistema npm, JS nativo para sitios dinámicos | Puede consumir mucha memoria, callbacks complejos (si no usas async/await) | Raspado en tiempo real, sitios con mucho JS, microservicios escalables |
| Python | Muchas librerías de scraping (BeautifulSoup, Scrapy), sintaxis sencilla | Más lento para alta concurrencia, problemas con sitios renderizados en JS | HTML estático, investigación, prototipos |
| Java | Tipado fuerte, robusto para empresas | Verboso, menos flexible para scripts rápidos | Raspado a gran escala, nivel empresarial |
| Go | Rápido, eficiente en concurrencia | Ecosistema más pequeño, curva de aprendizaje | Raspado de alto rendimiento y baja latencia |
Para la mayoría de los equipos de negocio, Node.js es el punto ideal: rápido, flexible y hecho para la web moderna llena de JavaScript ().
Cómo armar un entorno robusto de raspado web con Node.js
Un buen raspador empieza con una base sólida. Así suelo organizar mis proyectos:
- Estructura del proyecto: Mantén todo modular. Usa carpetas como
/src,/libsy/config. Guarda información sensible (API keys, proxies) en variables de entorno condotenv(). - Cliente HTTP: Usa , o para las peticiones.
- Parseo de HTML: para HTML estático, o Playwright para contenido dinámico.
- Utilidades: Usa para manipular datos, y o para validar.
- Testing y linting: Mocha para pruebas, ESLint para calidad de código ().
Librerías clave para raspado web con Node.js
- axios/got/node-fetch: Para hacer peticiones HTTP. Personalmente, me quedo con Axios por su API basada en promesas y manejo de JSON integrado.
- Cheerio: Analizador HTML rápido, tipo jQuery. Perfecto para páginas estáticas—procesa en unos 0.5s ().
- Puppeteer/Playwright: Automatización de navegador sin interfaz para sitios dinámicos y llenos de JS. Más lento (~4s por página), pero esencial para contenido que se carga después del renderizado ().
- dotenv: Para manejar variables de entorno.
- csv-writer/jsonfile: Para exportar datos.
Errores comunes que debes evitar al raspar con Node.js
He perdido la cuenta de cuántos raspadores he visto bloqueados, caídos o devolviendo datos desordenados. Ten en cuenta lo siguiente:
- Ignorar robots.txt y los Términos de Servicio: Siempre revisa antes de raspar. Saltarte esto puede hacer que te bloqueen la IP o, peor, meterte en líos legales ().
- Sobrecargar servidores: No lances peticiones a lo loco. Limita tu raspador con retrasos aleatorios (1–3 segundos), controla la concurrencia y evita parecerte a un robot hiperactivo ().
- No manejar errores: Siempre envuelve las peticiones en try/catch, gestiona errores HTTP y registra los fallos. Reintenta errores temporales con backoff exponencial ().
- Olvidar los headers de la petición: Usa User-Agent realistas y rótalos. Añade Accept-Language, Referer y otros headers para simular navegadores reales ().
Cómo esquivar los sistemas anti-scraping
Los sitios modernos están llenos de tecnología anti-bots. Así suelo evitar los bloqueos:
- Rotar proxies/IPs: Usa un pool de proxies y cambia de IP para evitar baneos ().
- Randomizar headers: Cambia User-Agent, Accept-Language y otros headers en cada petición.
- Navegador sin interfaz con sigilo: Usa plugins como
puppeteer-extra-plugin-stealthpara ocultar huellas de automatización. - Simular comportamiento humano: Añade retrasos aleatorios, movimientos de ratón, scroll y hasta errores de tipeo ().
Simulando comportamiento humano en raspadores Node.js
Aquí es donde se pone divertido. En vez de hacer clics y scrolls instantáneos, programa tu raspador para:
- Esperar intervalos aleatorios entre acciones (
await page.waitForTimeout(randomDelay)) - Mover el ratón en pequeños saltos irregulares (
page.mouse.move(x, y)) - Escribir con retrasos y errores ocasionales (
page.type(selector, text, {delay: random(100,200)})) - Hacer scroll de forma desigual, no solo hasta el final
Estos trucos pueden mejorar mucho tu tasa de éxito en sitios protegidos ().
Haz fácil la extracción de datos complejos con Thunderbit
Ahora, hablemos claro: el scraping puede ser complicado. Pero no tiene por qué serlo. Por eso creamos .
Thunderbit es una extensión de Chrome para raspado web con IA que te deja extraer datos de cualquier sitio usando lenguaje natural. Solo haz clic en “Sugerir campos con IA”, deja que la IA detecte la info relevante y pulsa “Extraer”. Es como tener un asistente junior que nunca duerme ni pide aumento.
Aún mejor, Thunderbit tiene una API para integrarlo directo en tus flujos con Node.js. En vez de escribir miles de líneas de código, puedes dejar que Thunderbit se encargue de lo difícil—contenido dinámico, subpáginas, paginación y más. Solo tienes que descargar los datos estructurados (CSV, JSON o directo a Google Sheets, Airtable, Notion) y seguir con tu día ().
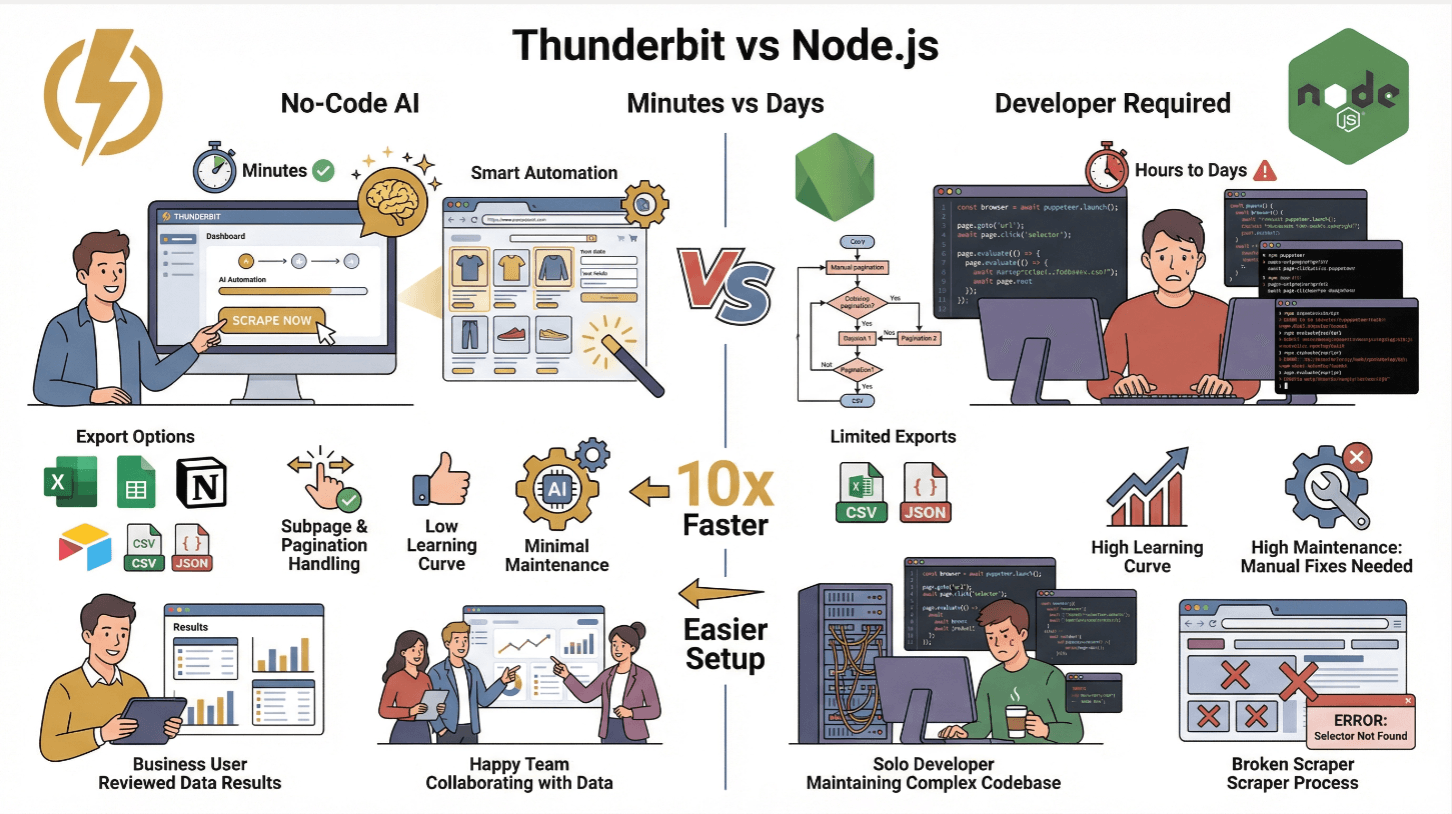
Thunderbit vs. Raspado tradicional con Node.js
| Funcionalidad | Thunderbit | Raspador Node.js tradicional |
|---|---|---|
| Tiempo de configuración | Minutos (sin código) | Horas o días (programación, pruebas) |
| Manejo de contenido dinámico | Sí (IA + navegador) | Sí (con Puppeteer/Playwright) |
| Subpáginas y paginación | 1 clic | Requiere programación manual |
| Exportación de datos | Excel, Sheets, Notion, Airtable, CSV, JSON | CSV/JSON (código personalizado) |
| Curva de aprendizaje | Baja (usuarios de negocio) | Alta (desarrolladores) |
| Mantenimiento | Mínimo (la IA se adapta) | Alto (ajustes manuales ante cambios) |
Thunderbit es perfecto para equipos no técnicos o para quienes quieren enfocarse en el análisis y no en el trabajo repetitivo. Si eres usuario avanzado, puedes usar la API de Thunderbit para automatizar el raspado a gran escala ().
Combinando Cheerio y Puppeteer para contenido dinámico
Esta es mi dupla favorita en Node.js. Así funciona:
- Usa Puppeteer para cargar la página y ejecutar JavaScript (espera a
networkidlepara asegurarte de que todo el contenido esté cargado). - Saca el HTML con
await page.content(). - Analiza con Cheerio: Pasa el HTML a Cheerio para un análisis rápido y extracción de datos al estilo jQuery.
Este enfoque híbrido te da lo mejor de ambos mundos: la potencia de Puppeteer para contenido dinámico y la velocidad de Cheerio para el parseo ().
Tip de rendimiento: Selecciona solo los elementos que necesitas. Cheerio carga todo el DOM en memoria, así que evita selectores amplios y usa caché si raspas las mismas páginas seguido ().
Optimización del parseo HTML y la extracción de datos
- Usa selectores específicos: Evita
$('body *')—apunta solo a lo necesario. - Procesa páginas grandes por partes: Si el HTML es muy grande, divide el trabajo o usa streams.
- Caché de HTML renderizado: Si visitas URLs repetidas, guarda el HTML para evitar peticiones innecesarias.
- Valida y limpia los datos: Usa librerías de validación para asegurar que tu base de datos no se llene de basura ().
Despliegue escalable de raspadores Node.js en la nube
¿Raspado a gran escala? Es momento de ir a la nube.
- Dockeriza tu raspador: Escribe un
Dockerfile, copia tu código, instala dependencias y define el entrypoint. - Despliega en la nube: Usa AWS EC2, Google Cloud Compute o Azure VMs para trabajos simples. Para escalar, usa Kubernetes o servicios gestionados como AWS ECS/EKS, Google Cloud Run o Azure Kubernetes Service ().
- Orquesta con Kubernetes: Ejecuta varios pods, escala automáticamente y usa balanceadores de carga para repartir URLs.
- Programa tareas: Usa programadores en la nube (CloudWatch Events, Cloud Scheduler) o cron jobs para lanzar raspados periódicos.
En un caso real, escalar de 5 a 10 pods en Kubernetes bajó el tiempo de raspado de 400 páginas de varios minutos a menos de un minuto ().
Monitoreo y autoescalado de tu infraestructura de scraping
- Logs: Manda logs a CloudWatch, Stackdriver o Datadog. Configura alertas para errores o lentitud.
- Health checks: Usa Prometheus y Grafana para métricas como páginas por minuto, tasas de error y salud de los pods.
- Autoescalado: Configura HPA (Horizontal Pod Autoscaler) en Kubernetes para escalar según CPU o número de peticiones.
Siempre implementa reintentos con backoff exponencial para recuperarte de fallos de red o bloqueos temporales.
Buenas prácticas para almacenamiento y post-procesamiento de datos
Cuando ya tienes los datos, toca almacenarlos y limpiarlos:
- Trabajos pequeños: Exporta a CSV, JSON o mándalos a Google Sheets, Airtable o Notion (Thunderbit lo hace automático).
- Trabajos grandes: Usa SQL (MySQL/PostgreSQL) para datos estructurados, o NoSQL (MongoDB, DynamoDB) para esquemas flexibles ().
- Almacenamiento en la nube: S3 o Google Cloud Storage para archivos y backups.
- Limpieza de datos: Valida siempre los campos, normaliza formatos (fechas, números) y elimina duplicados. Usa validadores de esquema para asegurar calidad ().
Guarda tanto los datos crudos como los limpios—nunca sabes cuándo vas a necesitar reprocesar o depurar.
Conclusión: Claves para un raspado web eficiente con Node.js
Vamos a resumir lo esencial:
- Aprovecha la asincronía de Node.js para raspados masivos y concurrentes—sobre todo en sitios llenos de JavaScript.
- Combina las herramientas adecuadas: Usa axios/got para peticiones, Cheerio para HTML estático, Puppeteer para contenido dinámico y combínalos para más velocidad y flexibilidad.
- Evita bloqueos anti-bot: Rota proxies y headers, simula comportamiento humano y respeta robots.txt.
- Simplifica con Thunderbit: Si eres usuario de negocio o quieres prototipar rápido, te deja extraer datos complejos con IA e integrarlos a tu stack Node.js vía API.
- Despliega a escala: Dockeriza, orquesta con Kubernetes y monitorea todo para asegurar fiabilidad.
- Almacena y limpia tus datos: Elige el almacenamiento adecuado y valida siempre antes de usar.
La web no se está volviendo más sencilla, pero con estas buenas prácticas, tus raspadores Node.js serán rápidos, confiables y siempre un paso adelante de los sistemas anti-bot. Y si alguna vez te cansas de depurar selectores a las 2am, recuerda: la IA de Thunderbit nunca duerme.
¿Quieres seguir aprendiendo? Visita el para más guías, o prueba la y descubre lo fácil que puede ser el scraping.
Preguntas frecuentes
1. ¿Por qué Node.js es especialmente bueno para el raspado web en 2025?
El modelo asíncrono y orientado a eventos de Node.js le permite manejar miles de solicitudes a la vez, ideal para extraer grandes volúmenes de datos o actualizaciones en tiempo real. Su enorme ecosistema npm y soporte nativo de JavaScript lo hacen perfecto para sitios modernos llenos de JS ().
2. ¿Cómo evito ser bloqueado al raspar con Node.js?
Usa proxies rotativos, randomiza los headers de las peticiones, limita la velocidad con retrasos aleatorios y simula comportamiento humano (movimiento de ratón, scroll, tipeo) usando herramientas como Puppeteer. Respeta siempre robots.txt y los términos del sitio ().
3. ¿Cuándo debo usar Cheerio vs. Puppeteer en mi raspador Node.js?
Usa Cheerio para analizar rápido HTML estático (cuando los datos están en el HTML original). Usa Puppeteer para sitios que cargan contenido dinámicamente con JavaScript. Para mejores resultados, renderiza la página con Puppeteer y luego analiza el HTML con Cheerio ().
4. ¿Cómo simplifica Thunderbit el raspado web con Node.js?
Thunderbit te deja extraer datos estructurados de cualquier sitio usando IA y lenguaje natural—sin necesidad de programar. Gestiona contenido dinámico, subpáginas y paginación, y ofrece una API para integrarlo con Node.js. Los datos pueden exportarse directo a Excel, Google Sheets, Airtable o Notion ().
5. ¿Cuál es la mejor forma de escalar y monitorear raspadores Node.js en la nube?
Dockeriza tu raspador, despliega en Kubernetes o servicios cloud gestionados y usa autoescalado para manejar picos de demanda. Monitorea logs y métricas con herramientas como CloudWatch o Prometheus, y configura alertas para errores o lentitud ().
¿Listo para llevar tu raspado web al siguiente nivel? Prueba Thunderbit y haz que tus raspadores sean rápidos, discretos y siempre un paso adelante.
Sigue aprendiendo