
Cada tutorial de fetch en Node.js te enseña await fetch(url) y da el tema por cerrado. Luego tu app en producción se traga en silencio un error 500, una petición se queda colgada 90 segundos sin timeout y acabas pasando la noche del viernes depurando algo que debería haber sido evidente.
Llevo un tiempo creando herramientas internas y pipelines de datos en , y te puedo decir algo: la distancia entre “fetch funciona en mi tutorial” y “fetch funciona en producción” es donde vive la mayor parte del dolor. Un desarrollador en Reddit lo resumió muy bien: “cuando pasas a producción, te das cuenta de que necesitas algo más robusto que el fetch nativo.”
Otro confesó: “Trabajé 3 años como desarrollador web y hoy aprendí que el bloque catch de la API fetch NO es para errores HTTP.” Esta guía cubre las cinco cosas que la mayoría de los tutoriales se saltan: la trampa del error, los timeouts con AbortController, la lógica de reintentos, la reutilización de conexiones y cuándo ir más allá de fetch para la extracción estructurada de datos. Si alguna vez una llamada a fetch falló en silencio en producción, esto es para ti.
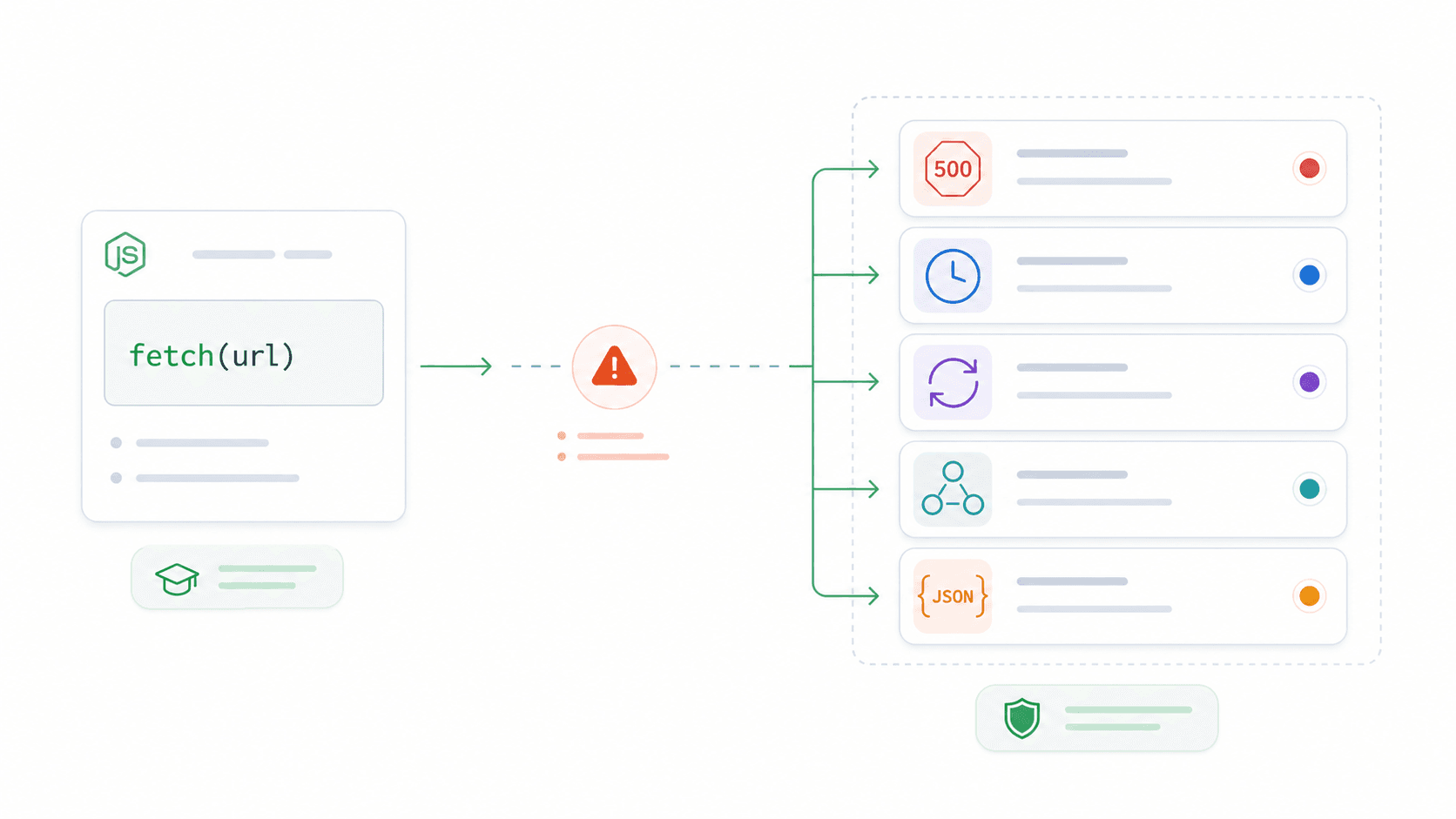
¿Qué es la API Fetch de Node.js?
La API Fetch de Node.js es la forma integrada y compatible con el navegador de hacer peticiones HTTP (GET, POST, PUT, DELETE, etc.) desde Node.js, sin instalar Axios, node-fetch ni ningún otro paquete. Si ya has usado fetch() en el navegador, ya conoces la sintaxis. Ahora la misma API también funciona en el servidor.
Aquí tienes un resumen rápido de su evolución:
| Hito | Versión de Node | Qué pasó |
|---|---|---|
| Bandera experimental de fetch | v17.5.0 / v16.15.0 | Se añadió fetch detrás de --experimental-fetch |
| Fetch global por defecto | v18.0.0 | Fetch experimental disponible globalmente, impulsado por Undici |
| Fetch estable | v21.0.0 | Dejó de ser experimental |
| Base de producción 2026 | v22 LTS / v24 LTS | Recomendado para producción; v20 ya está EOL |
Por debajo, el fetch de Node está impulsado por Undici, un cliente HTTP de alto rendimiento creado específicamente para Node.js. No depende del antiguo módulo http integrado. La ventaja práctica: obtienes una API HTTP moderna basada en Promises que funciona igual en tu código del navegador, tu backend de Express, tu función serverless y tus scripts de CLI.
Por qué la API Fetch de Node.js importa en tus proyectos
Antes de Node 18, cada proyecto nuevo empezaba con el mismo ritual: npm install axios o npm install node-fetch. En 2026, si tu proyecto corre sobre una versión LTS de Node mantenida, las peticiones HTTP básicas no requieren ninguna dependencia. Eso supone una mejora real en el tamaño del bundle, la seguridad de la cadena de suministro y la incorporación de nuevos desarrolladores (frontend y backend por fin comparten la misma API).
Aquí es donde destaca fetch nativo:
| Escenario | Por qué fetch nativo funciona bien | Matiz de producción |
|---|---|---|
| Backend de Express/Fastify llamando APIs REST | async/await familiar, sin dependencia | Añade timeout y comprobaciones de response.ok |
| Funciones serverless (Lambda, Vercel, etc.) | Menor superficie de arranque en frío, sin instalar paquetes | Mantén el timeout por debajo del máximo de la plataforma |
| Scripts de CLI y automatizaciones | GET/POST simples sin configurar el proyecto | Añade reintentos/backoff para APIs inestables |
| Entrega o reenvío de webhooks | Métodos y cabeceras HTTP estándar | No reintentes a ciegas POST no idempotentes |
| Informes y paneles | Muy útil para extraer JSON de APIs | Usa paginación y pooling de conexiones en bucles |
| Comunicación entre microservicios | Funciona para llamadas HTTP internas sencillas | Considera Got o Undici directamente para reintentos, hooks o HTTP/2 |
Para proyectos nuevos en Node 22+, fetch nativo es la opción sensata por defecto, salvo que sepas que necesitas funciones que no ofrece (interceptores, reintentos integrados, HTTP/2, etc.). Los números de descargas de npm cuentan la historia de un ecosistema en transición: , pero gran parte de eso es legado y dependencias transitivas. , , y . La tendencia es clara: fetch nativo es la nueva base, y los clientes de terceros quedan para necesidades concretas.
Fetch nativo vs node-fetch vs Axios vs Got vs Ky: la matriz de decisión de 2026
La pregunta más común que veo en foros de desarrollo es: “¿Qué cliente HTTP debería usar en Node.js?” Un usuario de Reddit lo resumió así: “¿por qué importar una biblioteca… cuando el lenguaje o framework ya trae esa funcionalidad integrada?” Buena observación, pero la respuesta depende de lo que necesites.
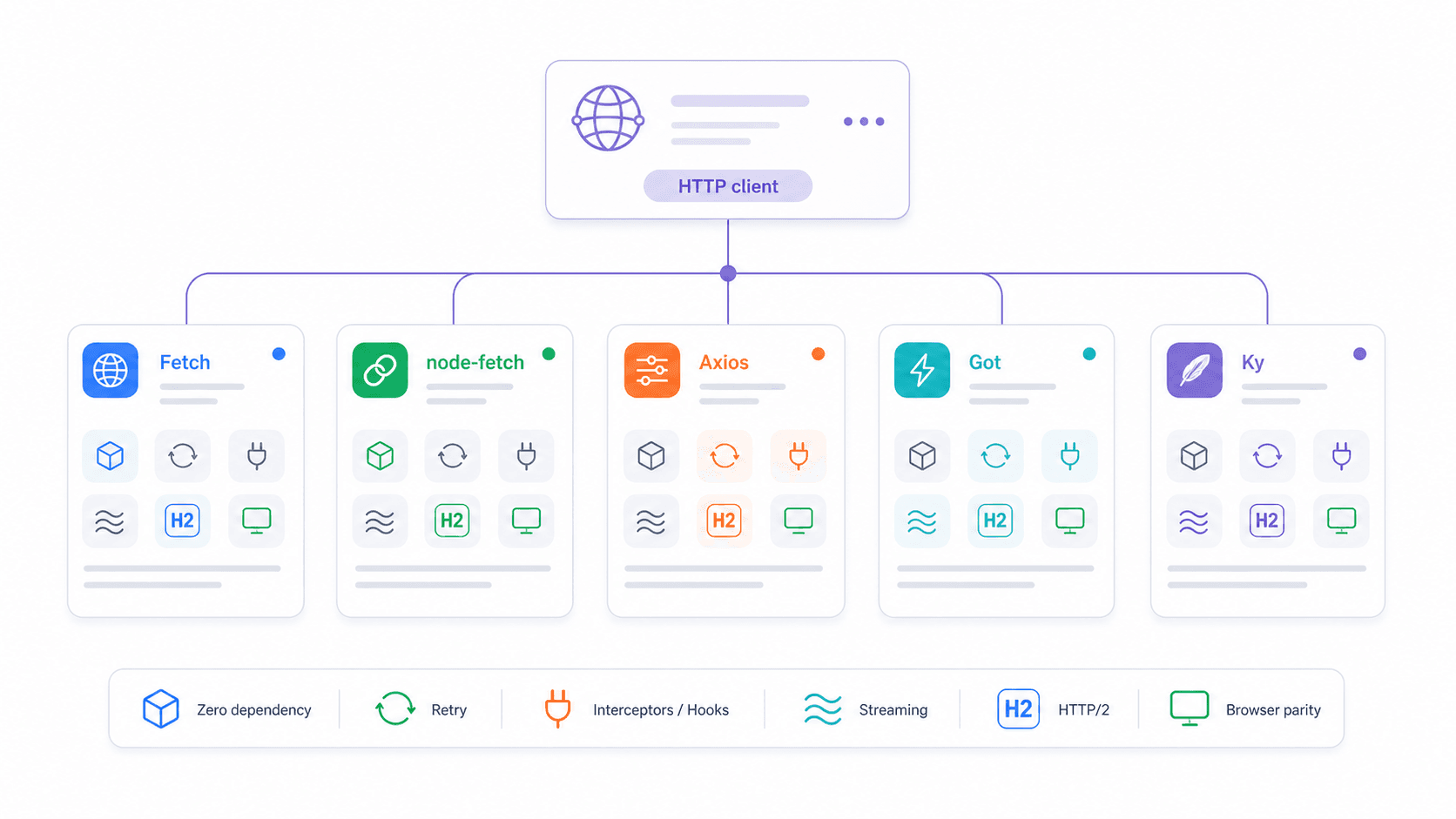
| Funcionalidad | fetch nativo | node-fetch v3 | axios | got v15 | ky v2 |
|---|---|---|---|---|---|
| Versión de Node.js | ≥18 (recomendado 22/24 LTS) | ≥12.20 | Amplio | ≥22 | ≥22 |
| Requiere instalación | No | Sí | Sí | Sí | Sí |
| Compatibilidad ESM + CJS | Ambas (global) | Solo ESM (v3) | Ambas | Solo ESM | Solo ESM |
| Rechazo automático en 4xx/5xx | No | No | Sí | Sí | Sí |
| Reintento integrado | No | No | No | Sí | Sí |
| Interceptores de petición | No | No | Sí | Sí (hooks) | Sí (hooks) |
| Compatibilidad con streaming | Web ReadableStream | Sí | Limitada | Potentes streams de Node | Basado en fetch |
| Huella de bundle/instalación | 0 KB | ~107 KB, 3 deps | ~2,8 MB, 4 deps | ~355 KB, 12 deps | ~405 KB, 0 deps |
| Soporte HTTP/2 | Mediante dispatcher de Undici | No | No | Sí | No (wrapper de fetch) |
Una nota rápida sobre el problema de ESM/CJS: node-fetch v3 es solo ESM, lo que rompió muchos proyectos que usaban require(). Fetch nativo es global; funciona tanto en archivos CJS como ESM sin malabares de importación. Si estabas atascado en node-fetch v2 por CommonJS, fetch nativo resuelve ese problema por completo.
Y sobre las dudas de estabilidad temprana: sí, hubo errores reales en la implementación inicial de fetch en Node 18. Un desarrollador en Reddit comentó: “Tuve un bug bastante raro con fetch nativo en Node 18 recientemente, así que tuvimos que migrar nuestra app.” Eso fue en 2023. En 2026, con Node 22 y 24 LTS, esos problemas ya están resueltos. Fetch nativo está listo para producción.
Cuándo quedarse con fetch nativo
Usa fetch nativo cuando:
- Tu proyecto corre en Node 22 LTS o Node 24 LTS.
- Las peticiones son llamadas REST sencillas (GET, POST, PUT, DELETE).
- Te vale añadir un pequeño wrapper para
response.ok, parseo JSON, timeouts y reintentos. - Quieres cero dependencias y menos preocupación por la cadena de suministro.
- Valoras que la API del navegador y la del servidor se comporten igual.
- Trabajas en entornos serverless o edge donde se prefieren las APIs integradas.
Cuándo Axios, Got o Ky tienen más sentido
Axios es la mejor opción cuando tu equipo depende de interceptores de petición/respuesta (por ejemplo, renovación automática de tokens de autenticación, cabeceras por tenant, logging centralizado), cuando quieres que los errores HTTP rechacen por defecto o cuando necesitas compatibilidad hacia atrás con runtimes de Node más antiguos.
Got está pensado para servicios Node de alto rendimiento que necesitan reintentos integrados, hooks, fases de timeout avanzadas, streams, ayuda con paginación, sockets Unix, flujos con proxy/caché o soporte para HTTP/2. Es la navaja suiza del trabajo HTTP solo en Node.
Ky encaja perfecto si te gusta la simplicidad de fetch pero quieres menos código repetitivo: añade reintentos, timeout, hooks y HTTPError en un paquete pequeño y sin dependencias.
Cómo hacer peticiones GET con la API Fetch de Node.js
Una petición GET con async/await se ve así:
1const response = await fetch('https://jsonplaceholder.typicode.com/posts/1');
2const post = await response.json();
3console.log(post.title);
4// → "sunt aut facere repellat provident occaecati excepturi optio reprehenderit"Y si prefieres la cadena con .then():
1fetch('https://jsonplaceholder.typicode.com/posts/1')
2 .then(response => response.json())
3 .then(post => console.log(post.title))
4 .catch(error => console.error(error));Ambas funcionan. Pero ninguna es todavía segura para producción (ahora veremos por qué).
Lectores de respuesta que deberías conocer:
| Método | Cuándo usarlo |
|---|---|
response.json() | El servidor devuelve JSON |
response.text() | El servidor devuelve HTML, texto plano, CSV o Markdown |
response.arrayBuffer() | Necesitas datos binarios (imágenes, archivos) |
response.body | Necesitas procesamiento por streaming o por fragmentos |
Un patrón mejor, uno que realmente comprueba errores:
1async function getPost(id) {
2 const response = await fetch(`https://jsonplaceholder.typicode.com/posts/$\{id\}`);
3 if (!response.ok) {
4 throw new Error(`HTTP $\{response.status\} $\{response.statusText\}`);
5 }
6 return response.json();
7}
8const post = await getPost(1);
9console.log(post.title);Esa línea if (!response.ok) es la diferencia entre un tutorial y código de producción. Y eso nos lleva a la trampa más grande.
Cómo enviar peticiones POST con la API Fetch de Node.js
Las peticiones POST siguen la misma estructura: solo tienes que definir el método, las cabeceras y el cuerpo:
1const response = await fetch('https://jsonplaceholder.typicode.com/posts', {
2 method: 'POST',
3 headers: {
4 'Content-Type': 'application/json',
5 },
6 body: JSON.stringify({
7 title: 'Guía de Node fetch',
8 body: 'El fetch en producción necesita manejo de errores.',
9 userId: 1,
10 }),
11});
12if (!response.ok) {
13 throw new Error(`HTTP $\{response.status\}`);
14}
15const created = await response.json();
16console.log(created.id); // → 101Enviar otros tipos de petición (PUT, DELETE, PATCH)
PUT, PATCH y DELETE usan la misma estructura con un valor distinto en method:
1// PUT — reemplazo completo
2await fetch('https://jsonplaceholder.typicode.com/posts/1', {
3 method: 'PUT',
4 headers: { 'Content-Type': 'application/json' },
5 body: JSON.stringify({ id: 1, title: 'Reemplazado', body: 'Reemplazo completo', userId: 1 }),
6});
7// PATCH — actualización parcial
8await fetch('https://jsonplaceholder.typicode.com/posts/1', {
9 method: 'PATCH',
10 headers: { 'Content-Type': 'application/json' },
11 body: JSON.stringify({ title: 'Actualización parcial' }),
12});
13// DELETE
14await fetch('https://jsonplaceholder.typicode.com/posts/1', {
15 method: 'DELETE',
16});La trampa de body-parser en Express: si estás enviando JSON a un servidor Express y req.body vuelve como undefined, la solución casi siempre es esta: usa express.json(), no express.urlencoded(). El servidor necesita el middleware express.json() antes de tu ruta para analizar cuerpos Content-Type: application/json. Esta es una de las preguntas más comunes en sobre Express, y suele pillar a la gente una y otra vez.
1import express from 'express';
2const app = express();
3app.use(express.json()); // ← Este es el que necesitas para cuerpos JSON en POST
4app.post('/api/posts', (req, res) => {
5 res.json({ received: req.body });
6});La trampa de error de fetch() que rompe apps en producción
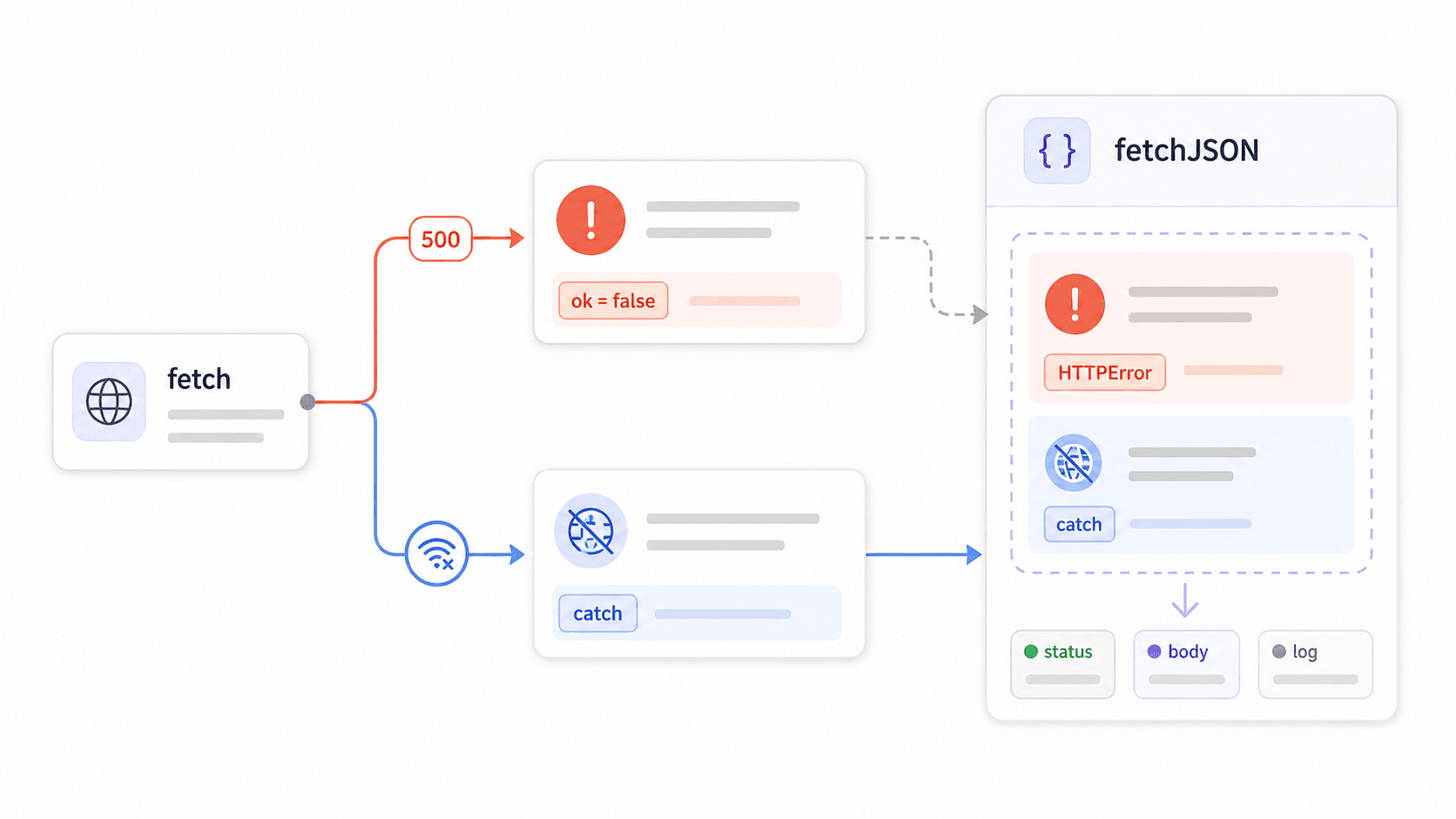
Aquí es donde nacen la mayoría de los fallos de fetch en producción.
fetch() no rechaza su promesa ante errores HTTP 4xx o 5xx. Solo rechaza ante fallos a nivel de red: errores DNS, falta de conexión, peticiones abortadas. Si el servidor devuelve un 403 Forbidden o un 500 Internal Server Error, fetch considera esa respuesta como exitosa. Tu bloque .catch() nunca se ejecuta. Tu try/catch nunca lo atrapa. Tu código procesa alegremente lo que el servidor haya devuelto.
lo deja claro, pero la mayoría de los tutoriales pasa por encima. ¿El resultado? Código que parece correcto pero se traga los errores sin decir nada:
1try {
2 const response = await fetch('https://api.example.com/private');
3 const data = await response.json(); // ← Esto se ejecuta incluso con un 403
4 console.log('Parece correcto:', data);
5} catch (error) {
6 // Aquí solo llegan los fallos a nivel de red
7 console.error('Capturado:', error);
8}Un desglose rápido de qué captura realmente cada patrón:
| Patrón | Captura errores de red | Captura 4xx/5xx | Parsea JSON con seguridad | Reutilizable |
|---|---|---|---|---|
.then(res => res.json()) en bruto | Sí (vía .catch()) | No | Sin comprobación de content-type | No |
try/catch con await fetch() | Sí | No | Sin comprobación de content-type | No |
if (!res.ok) manual en cada llamada | Sí | Sí | Depende de cada llamada | Parcial |
Wrapper personalizado fetchJSON() | Sí | Sí | Sí | Sí |
Crea un wrapper reutilizable fetchJSON()
Crea un wrapper. Impórtalo en todas partes. Deja de copiar y pegar if (!response.ok) en cada archivo:
1export class HTTPError extends Error {
2 constructor(message, { status, statusText, url, body }) {
3 super(message);
4 this.name = 'HTTPError';
5 this.status = status;
6 this.statusText = statusText;
7 this.url = url;
8 this.body = body;
9 }
10}
11export async function fetchJSON(url, options = {}) {
12 const response = await fetch(url, {
13 headers: {
14 Accept: 'application/json',
15 ...options.headers,
16 },
17 ...options,
18 });
19 const contentType = response.headers.get('content-type') || '';
20 const isJSON = contentType.includes('application/json');
21 const body = isJSON ? await response.json().catch(() => null) : await response.text();
22 if (!response.ok) {
23 throw new HTTPError(`HTTP $\{response.status\} $\{response.statusText\}`, {
24 status: response.status,
25 statusText: response.statusText,
26 url: response.url,
27 body,
28 });
29 }
30 return body;
31}Ahora, cuando el servidor devuelve un 403:
1try {
2 const data = await fetchJSON('https://api.example.com/private');
3} catch (error) {
4 if (error instanceof HTTPError) {
5 console.error(`El servidor devolvió $\{error.status\}:`, error.body);
6 } else {
7 console.error('Falló la red u otra cosa:', error);
8 }
9}El error lleva el código de estado, el cuerpo de la respuesta y la URL: todo lo que necesitas para registrar, alertar o mostrar mensajes al usuario. Impórtalo una vez, úsalo en todas partes.
AbortController y timeouts: el patrón de producción para la API Fetch de Node.js
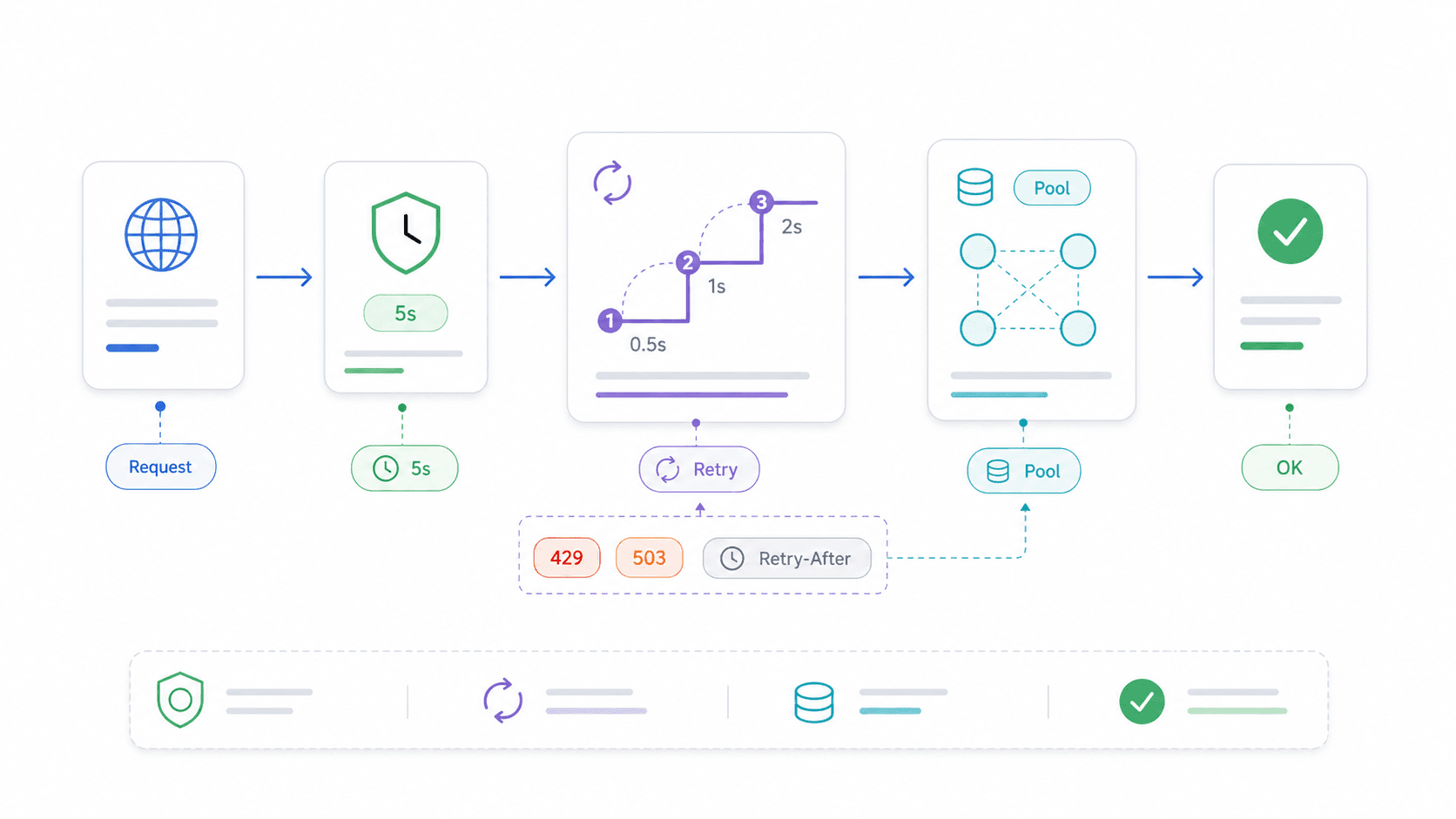
Sin timeout, una llamada fetch se queda colgada indefinidamente cuando el servidor remoto deja de responder. Tu ruta de Express se bloquea. Tu Lambda consume su presupuesto de ejecución. Tu script simplemente... se queda ahí.
Revisé los principales resultados de búsqueda: ni un solo tutorial de fetch específico para Node.js cubre cancelación de peticiones o timeouts. Y, sin embargo, los timeouts son una de las razones principales por las que la gente sigue usando Axios o Got. Hay un hilo de Reddit cuyo título es literalmente “Node fetch does not timeout”.
Usar AbortSignal.timeout() (Node 18.11+)
La forma más simple: una opción extra:
1try {
2 const response = await fetch('https://api.example.com/data', {
3 signal: AbortSignal.timeout(5000), // 5 segundos
4 });
5 if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
6 const data = await response.json();
7 console.log(data);
8} catch (error) {
9 if (error.name === 'TimeoutError') {
10 console.error('La petición superó el tiempo límite de 5 segundos.');
11 } else {
12 throw error;
13 }
14}Nota: AbortSignal.timeout() lanza un TimeoutError, no un AbortError. Este es un detalle que incluso algunos desarrolladores con experiencia confunden.
Timeout manual con AbortController
Para tener más control, o si necesitas cancelar una petición por acción del usuario y no solo por un temporizador:
1const controller = new AbortController();
2const timeout = setTimeout(() => controller.abort(), 5000);
3try {
4 const response = await fetch('https://api.example.com/data', {
5 signal: controller.signal,
6 });
7 const data = await response.json();
8 console.log(data);
9} catch (error) {
10 if (error.name === 'AbortError') {
11 console.error('La petición se abortó manualmente.');
12 } else {
13 throw error;
14 }
15} finally {
16 clearTimeout(timeout);
17}Manejar AbortError vs TimeoutError
Esta distinción importa para logs y mensajes de cara al usuario:
| Ruta de aborto | Nombre del error en el bloque catch |
|---|---|
AbortSignal.timeout(ms) | TimeoutError |
controller.abort() | AbortError |
| Fallo de DNS/red | Normalmente TypeError: fetch failed |
Aquí va un escenario práctico: una ruta de Express que llama a una API externa y debe responder en menos de 3 segundos:
1app.get('/dashboard', async (req, res, next) => {
2 try {
3 const data = await fetchJSON('https://api.example.com/report', {
4 signal: AbortSignal.timeout(3000),
5 });
6 res.json(data);
7 } catch (error) {
8 if (error.name === 'TimeoutError') {
9 res.status(504).json({ error: 'La API upstream agotó el tiempo de espera' });
10 return;
11 }
12 next(error);
13 }
14});Sin este patrón, una API upstream lenta bloquearía toda tu ruta hasta que el cliente se rindiera.
Lógica de reintentos y reutilización de conexiones: cómo hacer que la API Fetch de Node.js sea de nivel producción
Fetch nativo no trae reintentos integrados. Un pequeño bache de red o un 503 temporal hacen que la petición simplemente falle. Para la mayoría de lecturas en producción, eso no es aceptable.
Un wrapper de reintento componible con backoff exponencial
Está hecho a propósito para ser corto: unas 10 líneas de lógica real:
1const wait = ms => new Promise(resolve => setTimeout(resolve, ms));
2export async function fetchWithRetry(url, options = {}, retries = 2) {
3 for (let attempt = 0; ; attempt++) {
4 try {
5 const response = await fetch(url, options);
6 if (response.ok || ![408, 429, 500, 502, 503, 504].includes(response.status)) {
7 return response;
8 }
9 if (attempt >= retries) return response;
10 } catch (error) {
11 if (attempt >= retries) throw error;
12 }
13 await wait(250 * 2 ** attempt); // 250ms, 500ms, 1000ms...
14 }
15}Cuándo reintentar y cuándo no
- Sí reintentes: peticiones GET y HEAD idempotentes, estados transitorios (408, 429, 500, 502, 503, 504), fallos intermitentes de red.
- No reintentes: peticiones POST no idempotentes que crean registros, cobran dinero o disparan efectos secundarios, salvo que uses claves de idempotencia.
- Respeta Retry-After: para 429 (límite de tasa) y 503 (servicio no disponible), revisa la cabecera
Retry-Afterantes de hacer backoff.
Si prefieres no construir tu propia lógica de reintentos, es un wrapper ligero de fetch que añade reintentos, timeout, hooks y HTTPError de serie, sin dependencias.
Reutilización de conexiones con Agent y Pool de Undici
En bucles de alto rendimiento — raspar cientos de páginas, llamar a una API por lotes, consultar periódicamente un servicio — reutilizar conexiones TCP ahorra bastante tiempo. Cada conexión nueva implica una nueva búsqueda DNS, un handshake TCP y, en HTTPS, negociación TLS.
Como el fetch de Node está impulsado por Undici, puedes pasar un dispatcher personalizado:
1import { Agent } from 'undici';
2const agent = new Agent({
3 keepAliveTimeout: 10_000,
4 keepAliveMaxTimeout: 60_000,
5});
6const response = await fetch('https://api.example.com/data', {
7 dispatcher: agent,
8});Para tener todavía más control con un origen concreto:
1import { Pool } from 'undici';
2const pool = new Pool('https://api.example.com', { connections: 10 });
3const response = await fetch('https://api.example.com/data', {
4 dispatcher: pool,
5});
6// Cuando termines:
7await pool.close();Los muestran que la reutilización de conexiones y el pooling pueden mejorar mucho el rendimiento: undici - dispatch llegó a unas 22.234 req/s frente a unas 5.904 req/s con undici - fetch en su benchmark local. Los números reales variarán, pero la tendencia es clara: si haces muchas peticiones al mismo origen, el pooling importa.
Una cosa más: consume o cancela siempre los cuerpos de respuesta. Los cuerpos no consumidos pueden provocar fugas de recursos en los internos HTTP de Node.
Respuestas en streaming con la API Fetch de Node.js
Descargas de archivos grandes, feeds JSON por fragmentos, eventos enviados por el servidor, salidas de LLM: son casos en los que esperar a recibir toda la respuesta antes de procesarla desperdicia tiempo y memoria. El streaming te permite manejar los datos a medida que llegan.
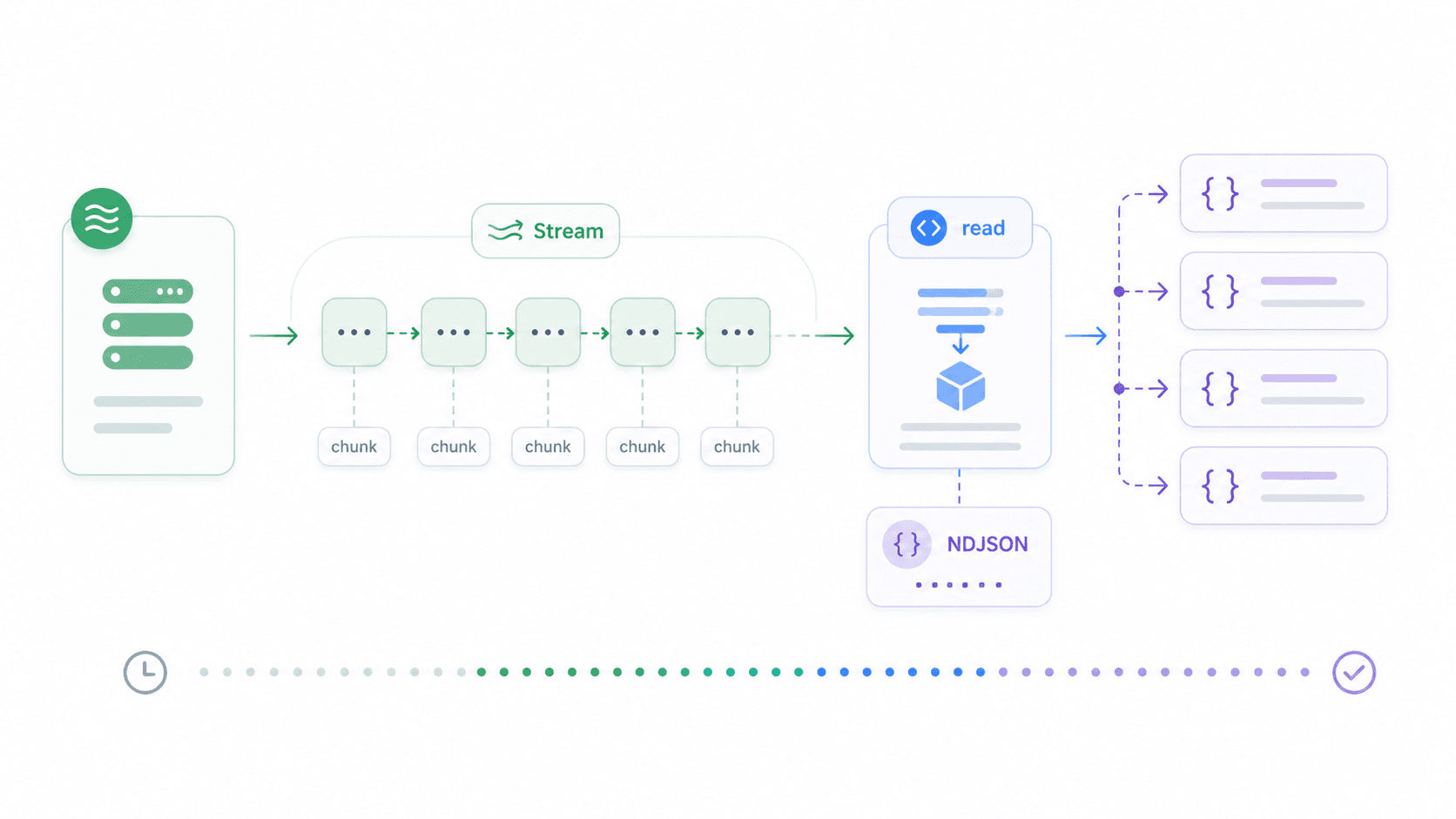
Node 18+ incluye ReadableStream compatible con el navegador. Así puedes hacer streaming de una respuesta JSON delimitada por saltos de línea y procesar cada línea a medida que llega:
1const response = await fetch('https://example.com/large-file.ndjson');
2if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
3const reader = response.body.getReader();
4const decoder = new TextDecoder();
5let buffer = '';
6while (true) {
7 const { value, done } = await reader.read();
8 if (done) break;
9 buffer += decoder.decode(value, { stream: true });
10 let newlineIndex;
11 while ((newlineIndex = buffer.indexOf('\n')) >= 0) {
12 const line = buffer.slice(0, newlineIndex).trim();
13 buffer = buffer.slice(newlineIndex + 1);
14 if (line) {
15 const item = JSON.parse(line);
16 console.log('Procesado:', item.id);
17 }
18 }
19}Para un streaming de texto más simple, por ejemplo, redirigir la salida de un LLM a stdout:
1const response = await fetch('https://example.com/stream');
2const reader = response.body.getReader();
3const decoder = new TextDecoder();
4for (;;) {
5 const { value, done } = await reader.read();
6 if (done) break;
7 process.stdout.write(decoder.decode(value, { stream: true }));
8}El streaming es un área donde tanto fetch nativo como Got brillan. La compatibilidad de streaming de Axios es más limitada.
Cuando fetch() llega a su límite: scraping web estructurado con APIs
Llega un punto en que fetch deja de ser el cuello de botella. El verdadero problema pasa a ser: “Tengo HTML, ¿y ahora qué?”
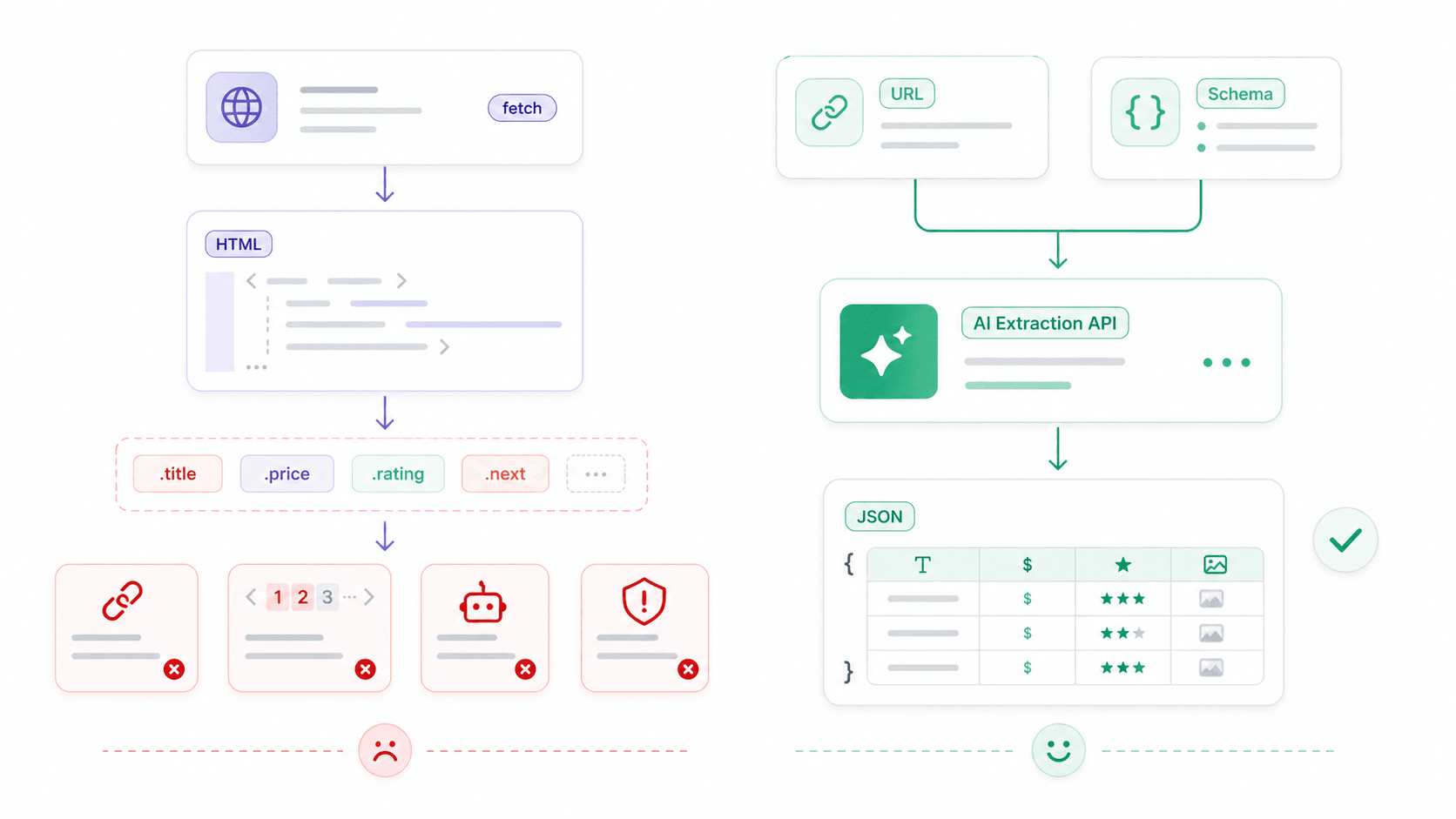
Fetch es un cliente HTTP: recupera bytes, texto, JSON o HTML. No sabe qué es una ficha de producto, un precio, una valoración o una tabla de contacto. Para scraping web estructurado, la pila cruda típica se ve así:
fetch()para descargar HTML- Cheerio (o similar) para seleccionar elementos con selectores CSS
- Lógica personalizada de paginación
- Renderizado JavaScript cuando las páginas son del lado del cliente
- Manejo de proxy/anti-bot/CAPTCHA
- Mantenimiento de selectores cada vez que cambia el diseño del sitio
Aquí tienes un ejemplo típico con fetch + Cheerio: unas 15 líneas para extraer títulos de producto:
1import * as cheerio from 'cheerio';
2const response = await fetch('https://example-store.com/products');
3if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
4const html = await response.text();
5const $ = cheerio.load(html);
6const products = $('.product-card')
7 .map((_, el) => ({
8 name: $(el).find('.product-title').text().trim(),
9 price: $(el).find('.price').text().trim(),
10 url: new URL($(el).find('a').attr('href'), response.url).href,
11 }))
12 .get();
13console.log(products);Esto funciona para páginas estables con HTML predecible. Pero se vuelve frágil muy rápido: contenido renderizado con JavaScript, cambios en nombres de clases, medidas anti-bot y paginación añaden complejidad.
La API abierta de Thunderbit: de HTML en bruto a datos estructurados en una sola llamada
Aquí es donde otro tipo de herramienta se vuelve útil. En , construimos una capa API que se encarga de las partes engorrosas — renderizado JavaScript, protección anti-bot, cambios de diseño — para que tú te centres en los datos que realmente quieres.
Distill API (POST /distill): convierte cualquier URL en Markdown limpio. Útil para alimentar LLMs, crear bases de conocimiento o analizar contenido, sin necesidad de parser HTML.
Extract API (POST /extract): defines un JSON Schema que describe los datos estructurados que quieres (nombre del producto, precio, valoración) y la IA los extrae. Sin selectores CSS y sin roturas cuando cambia el diseño.
Aquí tienes la misma tarea de scraping de productos usando la Extract API de Thunderbit, llamada con fetch nativo:
1const response = await fetch('https://openapi.thunderbit.com/openapi/v1/extract', {
2 method: 'POST',
3 headers: {
4 Authorization: `Bearer $\{process.env.THUNDERBIT_API_KEY\}`,
5 'Content-Type': 'application/json',
6 },
7 body: JSON.stringify({
8 url: 'https://example-store.com/products',
9 renderMode: 'basic',
10 schema: {
11 type: 'object',
12 properties: {
13 products: {
14 type: 'array',
15 items: {
16 type: 'object',
17 properties: {
18 name: { type: 'string', description: 'Nombre del producto' },
19 price: { type: 'string', description: 'Precio mostrado del producto' },
20 rating: { type: 'number', description: 'Valoración media de los clientes' },
21 },
22 required: ['name', 'price'],
23 },
24 },
25 },
26 required: ['products'],
27 },
28 }),
29});
30if (!response.ok) throw new Error(`Thunderbit API: $\{response.status\}`);
31const result = await response.json();
32console.log(result.data);La comparación: unas 15 líneas de fetch + Cheerio, además de selectores frágiles, frente a una sola llamada a la API que devuelve JSON limpio. Para trabajos por lotes, Thunderbit admite hasta 50 URL por llamada de extracción por lotes y hasta 100 URL por llamada de distill por lotes.
Thunderbit no sustituye a fetch: fetch es el transporte. Thunderbit es la capa de extracción a la que recurres cuando parsear HTML en bruto se convierte en el verdadero problema. Si tienes curiosidad por los precios, el te da 600 unidades de API para experimentar, y los planes de pago empiezan en 6 $/mes. También puedes probar la para extracción sin código directamente en tu navegador.
Para saber más sobre enfoques de scraping estructurado, nuestras guías sobre , y cubren flujos de trabajo concretos en detalle.
Referencia rápida: chuleta de la API Fetch de Node.js
Esta sección está pensada para guardarla en favoritos. Vuelve cuando necesites un patrón para copiar y pegar.
| Patrón | Fragmento |
|---|---|
| GET básico | const res = await fetch(url); const data = await res.json(); |
| POST básico | await fetch(url, { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(payload) }); |
| Comprobación de error HTTP | if (!res.ok) throw new Error(\HTTP ${res.status}`);` |
| Timeout (simple) | await fetch(url, { signal: AbortSignal.timeout(5000) }); |
| Abortar manualmente | const c = new AbortController(); setTimeout(() => c.abort(), 5000); await fetch(url, { signal: c.signal }); |
| Estados para reintentar | Reintenta 408, 429, 500, 502, 503, 504. No reintentes POST a ciegas. |
| Wrapper JSON | Usa fetchJSON() para comprobar ok, parsear el tipo de contenido y lanzar HTTPError. |
| Pool de conexiones | import { Pool } from 'undici'; const pool = new Pool(origin, { connections: 10 }); fetch(url, { dispatcher: pool }); |
| Leer fragmentos en streaming | const reader = res.body.getReader(); loop over await reader.read() |
| Extracción estructurada | Usa la Extract API de Thunderbit cuando el objetivo sean campos de una página web, no HTML en bruto. |
Conclusión y puntos clave
Fetch nativo en Node.js está listo para producción en 2026: no hace falta node-fetch para proyectos nuevos ni dependencias por defecto de Axios. Pero fetch() en bruto por sí solo no es una estrategia HTTP de producción.
Las cinco cosas que la mayoría de los tutoriales se saltan, y que esta guía cubre:
- La trampa del error:
fetch()no lanza en 4xx/5xx. Comprueba siempreresponse.oko usa un wrapper comofetchJSON(). - Timeouts: usa
AbortSignal.timeout()en casos sencillos.AbortSignal.timeout()lanzaTimeoutError;controller.abort()manual lanzaAbortError. - Lógica de reintento: no viene integrada. Añade backoff exponencial para peticiones idempotentes y fallos transitorios. O usa Ky para tener reintentos estilo fetch de serie.
- Reutilización de conexiones: en bucles de alto rendimiento, usa
AgentoPoolde Undici mediante la opcióndispatcher. - Extracción estructurada: cuando necesites datos de páginas web — no solo HTML en bruto — considera una API de extracción como Thunderbit en lugar de mantener selectores CSS frágiles.
La matriz de decisión en una frase: usa fetch nativo para la mayoría de proyectos, Axios para interceptores, Got para reintentos integrados y HTTP/2, Ky para fetch con mejores valores por defecto, y la API de Thunderbit cuando tus scripts de scraping basados en fetch se vuelvan demasiado complejos de mantener.
Prueba los patrones de esta guía. Y si quieres ver cómo Thunderbit maneja la extracción estructurada, el es un buen punto de partida, o puedes ver una demostración en el .
Preguntas frecuentes
1. ¿Fetch viene integrado en Node.js o tengo que instalarlo?
Fetch viene integrado en Node.js 18 y posteriores; no hace falta instalar nada. Se volvió estable en Node 21 y está totalmente soportado en Node 22 LTS y Node 24 LTS. Para versiones más antiguas de Node, puedes usar el paquete npm node-fetch, pero los proyectos nuevos deberían apuntar a una versión LTS mantenida.
2. ¿Fetch lanza un error en respuestas 404 o 500?
No. Fetch solo rechaza su promesa ante fallos a nivel de red (errores DNS, falta de conexión, peticiones abortadas). Respuestas HTTP como 404, 403 y 500 se resuelven normalmente con response.ok === false. Debes comprobar response.ok o response.status de forma explícita, o usar un wrapper como la función fetchJSON() mostrada en esta guía.
3. ¿Cómo añado un timeout a fetch en Node.js?
La forma más sencilla es AbortSignal.timeout(ms), disponible desde Node 18.11+: await fetch(url, { signal: AbortSignal.timeout(5000) }). Esto lanza un TimeoutError si la petición supera 5 segundos. Para más control, crea un AbortController manualmente y llama a controller.abort() desde un setTimeout. Captura AbortError para el patrón manual y TimeoutError para AbortSignal.timeout().
4. ¿Puedo usar fetch para web scraping en Node.js?
Sí, pero fetch solo devuelve HTML en bruto. Necesitarás un parser como Cheerio para extraer elementos concretos, además de lógica personalizada para paginación, páginas renderizadas con JavaScript y medidas anti-bot. Para extracción de datos estructurados a escala — cuando quieres JSON limpio con nombres de producto, precios o información de contacto — considera la , que usa IA para devolver datos estructurados sin selectores CSS ni código dependiente del diseño.
5. ¿Debería pasar de Axios a fetch nativo en 2026?
Para proyectos nuevos en Node 22+, fetch nativo es una muy buena opción por defecto. No tiene dependencias, usa Promises y comparte la misma API que el fetch del navegador. Mantén Axios si dependes de interceptores de petición/respuesta, rechazo por defecto de errores HTTP o compatibilidad con versiones antiguas de Node. Ambas son opciones válidas; la decisión depende de las funciones que tu proyecto realmente use.
Más información