La web está llena de datos y todas las empresas quieren sacarles el máximo jugo. Pero, seamos realistas: copiar a mano información de cientos de páginas es tan emocionante como ver secar el cemento (y casi igual de inútil). Aquí es donde el raspado web con Node se vuelve tu mejor aliado. En los últimos años, he visto cómo cada vez más equipos —ventas, operaciones, investigación de mercados y más— se lanzan a la automatización para conseguir datos valiosos a gran escala. De hecho, se calcula que el mercado global del raspado web superará los , y no solo las grandes tecnológicas están aprovechando la ola. Desde monitorear precios en e-commerce hasta generar leads, el raspado web con Node se está volviendo una habilidad clave para quienes quieren seguir en la pelea.
Si alguna vez te has preguntado cómo extraer datos de páginas web usando Node.js —o por qué Node.js es tan potente para raspar sitios llenos de JavaScript y contenido dinámico— esta guía es para ti. Te voy a contar qué es el raspado web con Node, por qué es tan útil para los negocios y cómo puedes armar tu propio flujo de raspado desde cero. Y si eres de los que quieren resultados ya, también te mostraré cómo herramientas como pueden ahorrarte horas (y dolores de cabeza) automatizando todo el proceso. ¿Listo para convertir la web en tu mina de oro? Vamos a ello.
¿Qué es el raspado web con Node? Tu entrada al mundo de la extracción automática de datos
En pocas palabras, el raspado web con Node es usar Node.js (el entorno de JavaScript más popular fuera del navegador) para extraer información de sitios web de forma automática. Imagina que creas un robot rapidísimo que visita páginas, lee su contenido y saca justo los datos que necesitas, ya sean precios, contactos o titulares de noticias.
Así funciona, en resumen:
- Tu script de Node.js manda una solicitud HTTP a un sitio web (igual que tu navegador).
- Recibe el HTML de la página.
- Con librerías como Cheerio, analiza el HTML y te deja “buscar” los datos que te interesan (como si usaras jQuery).
- Para sitios donde el contenido se carga con JavaScript (por ejemplo, apps web modernas), puedes usar Puppeteer para controlar un navegador real en segundo plano, renderizar la página y extraer los datos cuando todo esté listo.
¿Por qué Node.js? Porque JavaScript es el idioma de la web, y Node.js te deja usarlo fuera del navegador. Así puedes manejar tanto sitios estáticos como dinámicos, automatizar interacciones complejas (como logins o clics) y procesar datos a toda velocidad. Además, la arquitectura asíncrona y no bloqueante de Node te permite raspar muchas páginas a la vez, ideal para escalar la extracción de datos.
Herramientas clave para el raspado web con Node:
- Axios: Para obtener páginas web (maneja solicitudes HTTP).
- Cheerio: Para analizar y buscar datos en HTML de sitios estáticos.
- Puppeteer: Para automatizar un navegador real en sitios interactivos o llenos de JavaScript.
Si te imaginas un ejército de navegadores trabajando en silencio mientras tomas tu café... no vas tan desencaminado.
¿Por qué el raspado web con Node es clave para los equipos de negocio?
Vamos al grano: el raspado web ya no es solo cosa de hackers o data scientists. Es una superpotencia para cualquier empresa. Negocios de todos los sectores están usando el raspado web con Node para:
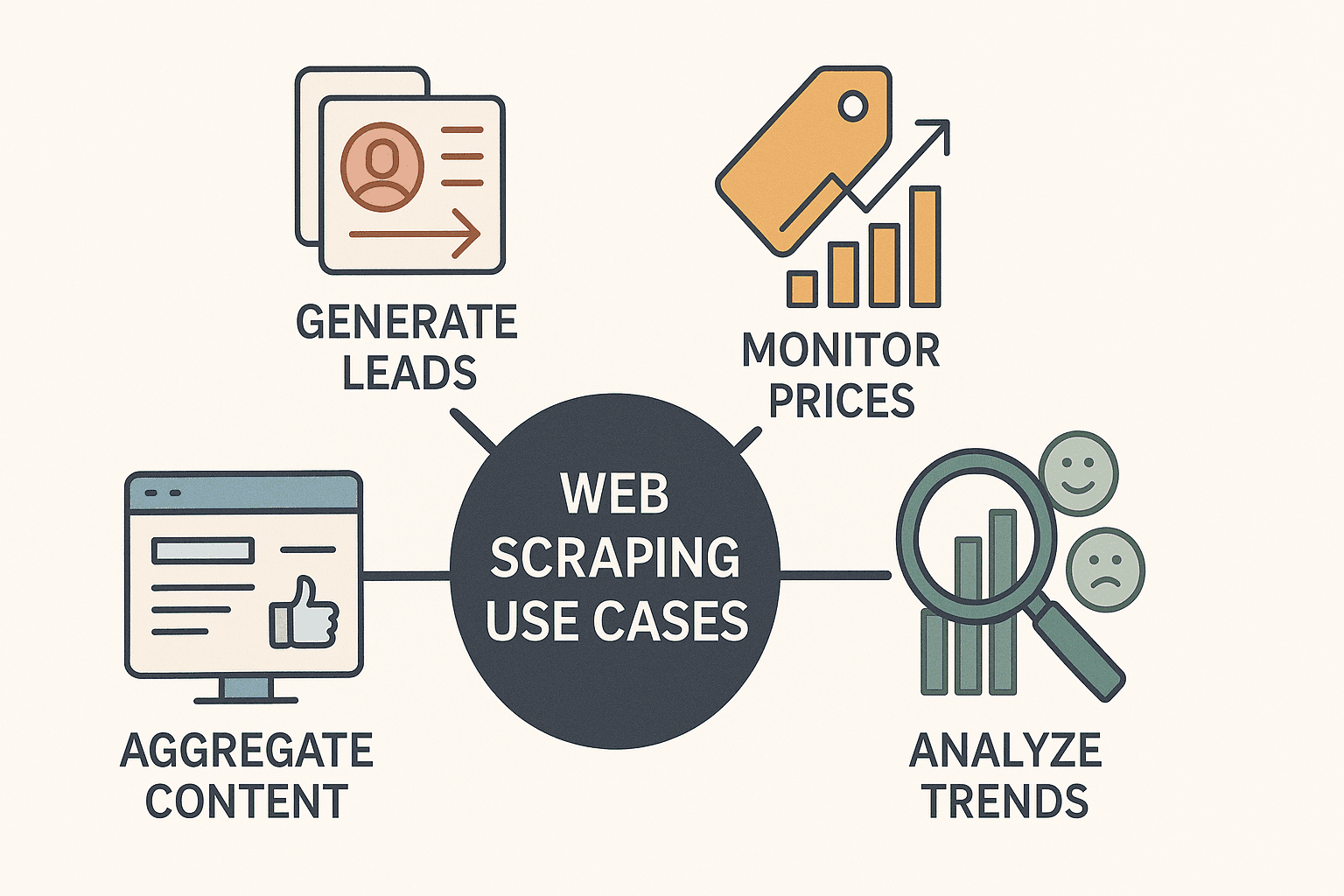
- Generar leads: Sacar información de contacto de directorios o LinkedIn para ventas.
- Monitorear precios de la competencia: Seguir productos y ajustar precios en tiempo real (más del raspan precios de la competencia a diario).
- Agregar contenido: Crear paneles con noticias, reseñas o menciones en redes sociales.
- Analizar tendencias de mercado: Raspar reseñas, foros o portales de empleo para detectar oportunidades y analizar el sentimiento.
¿Lo mejor? Node.js hace que todo esto sea más rápido, flexible y fácil de automatizar que nunca. Su naturaleza asíncrona permite procesar decenas (o cientos) de páginas a la vez, y su base en JavaScript lo hace perfecto para raspar sitios hechos con frameworks modernos.
Aquí tienes un vistazo rápido a algunos casos reales:
| Caso de uso | Descripción y ejemplo | Ventaja de Node.js |
|---|---|---|
| Generación de leads | Extraer emails, nombres y teléfonos de directorios empresariales. | Raspado rápido y en paralelo; fácil integración con CRMs y APIs. |
| Monitoreo de precios | Seguir precios de la competencia en sitios de e-commerce. | Solicitudes asíncronas para muchas páginas; fácil programación para revisiones diarias/horarias. |
| Investigación de mercado | Agregar reseñas, foros o publicaciones sociales para análisis de sentimiento. | Manejo versátil de datos; ecosistema rico para procesamiento y limpieza de texto. |
| Agregación de contenido | Extraer artículos de noticias o blogs en un solo panel. | Actualizaciones en tiempo real; integración sencilla con herramientas de notificación (Slack, email, etc.). |
| Análisis de competencia | Raspar catálogos de productos, descripciones y valoraciones de sitios rivales. | Análisis de JavaScript para sitios complejos; código modular para rastreos multipágina. |
Node.js es especialmente útil cuando necesitas raspar sitios que dependen mucho de JavaScript, algo con lo que Python y otros lenguajes suelen batallar. Y con la configuración adecuada, puedes pasar de “ojalá tuviera estos datos” a “aquí está mi Excel” en minutos.
Lo básico del raspado web con Node: Herramientas y librerías que no pueden faltar
Antes de meternos en el código, vamos a conocer las herramientas principales para hacer scraping con Node.js:
1. Axios (Cliente HTTP)

- Para qué sirve: Obtener páginas web enviando solicitudes HTTP.
- Cuándo usarlo: Siempre que necesites el HTML de una página.
- Por qué mola: API sencilla basada en promesas; gestiona redirecciones y cabeceras sin líos.
- Instalación:
npm install axios
2. Cheerio (Analizador HTML)

- Para qué sirve: Analizar HTML y buscar datos usando selectores tipo jQuery.
- Cuándo usarlo: Para sitios estáticos donde los datos están en el HTML inicial.
- Por qué mola: Rápido, ligero y muy familiar si ya has usado jQuery.
- Instalación:
npm install cheerio
3. Puppeteer (Automatización de navegador sin interfaz)

- Para qué sirve: Controlar un navegador Chrome real en segundo plano, interactuando con páginas como un usuario.
- Cuándo usarlo: Para sitios interactivos o llenos de JavaScript (scroll infinito, login, pop-ups).
- Por qué mola: Puede hacer clics, rellenar formularios, desplazarse y extraer datos tras la ejecución de scripts.
- Instalación:
npm install puppeteer
Extra: Hay otras herramientas como Playwright (automatización multi-navegador) y frameworks como Crawlee de Apify para flujos más avanzados, pero Axios, Cheerio y Puppeteer son el trío básico para empezar.
Requisitos previos: Asegúrate de tener Node.js instalado. Inicia un proyecto con npm init -y y luego instala las librerías que mencionamos.
Paso a paso: Crea tu primer raspador web con Node desde cero
Vamos a la acción y armemos un raspador sencillo. Usaremos Axios y Cheerio para extraer datos de libros del sitio de prueba .
Paso 1: Consigue el HTML de la página
1import axios from 'axios';
2import { load } from 'cheerio';
3const startUrl = 'http://books.toscrape.com/';
4async function scrapePage(url) {
5 const resp = await axios.get(url);
6 const html = resp.data;
7 const $ = load(html);
8 // ...extraer datos a continuación
9}Paso 2: Analiza y saca los datos
1$('.product_pod').each((i, element) => {
2 const title = $(element).find('h3').text().trim();
3 const price = $(element).find('.price_color').text().replace('£', '');
4 const stock = $(element).find('.instock').text().trim();
5 const ratingClass = $(element).find('p.star-rating').attr('class') || '';
6 const rating = ratingClass.split(' ')[1];
7 const relativeUrl = $(element).find('h3 a').attr('href');
8 const bookUrl = new URL(relativeUrl, startUrl).href;
9 console.log({ title, price, rating, stock, url: bookUrl });
10});Paso 3: Maneja la paginación
1const nextHref = $('.next > a').attr('href');
2if (nextHref) {
3 const nextUrl = new URL(nextHref, url).href;
4 await scrapePage(nextUrl);
5}Paso 4: Guarda los datos
Cuando termines de recolectar los datos, puedes guardarlos en un archivo JSON o CSV usando el módulo fs de Node.
1import fs from 'fs';
2// Tras finalizar el raspado:
3fs.writeFileSync('books_output.json', JSON.stringify(booksList, null, 2));
4console.log(`Se extrajeron ${booksList.length} libros.`);¡Y ya está! Tienes un raspador web básico y funcional con Node.js. Este método es ideal para sitios estáticos, pero ¿qué pasa con esas páginas que dependen mucho de JavaScript?
Cómo raspar páginas cargadas de JavaScript: Usando Puppeteer con Node
Algunos sitios esconden sus datos detrás de capas de JavaScript. Si intentas rasparlos con Axios y Cheerio, probablemente verás una página vacía o incompleta. Aquí es donde Puppeteer es tu as bajo la manga.
¿Por qué usar Puppeteer? Porque lanza un navegador real (sin interfaz), carga la página, espera a que se ejecuten todos los scripts y luego te deja extraer el contenido renderizado, igual que haría una persona.
Ejemplo de script con Puppeteer
1import puppeteer from 'puppeteer';
2async function scrapeWithPuppeteer(url) {
3 const browser = await puppeteer.launch({ headless: true });
4 const page = await browser.newPage();
5 await page.goto(url, { waitUntil: 'networkidle2' });
6 await page.waitForSelector('.product_pod'); // Espera a que los datos se carguen
7 const data = await page.evaluate(() => {
8 let items = [];
9 document.querySelectorAll('.product_pod').forEach(elem => {
10 items.push({
11 title: elem.querySelector('h3').innerText,
12 price: elem.querySelector('.price_color').innerText,
13 });
14 });
15 return items;
16 });
17 console.log(data);
18 await browser.close();
19}¿Cuándo usar Cheerio/Axios y cuándo Puppeteer?
- Cheerio/Axios: Rápido, ligero, perfecto para contenido estático.
- Puppeteer: Más lento, pero imprescindible para páginas dinámicas o interactivas (login, scroll infinito, etc.).
Tip: Prueba primero con Cheerio/Axios por su velocidad. Si faltan datos, pásate a Puppeteer.
Raspado web avanzado con Node: paginación, login y limpieza de datos
Cuando ya domines lo básico, es hora de enfrentarte a escenarios más complejos.
Gestión de paginación
Recorre páginas detectando y siguiendo enlaces “siguiente”, o generando URLs si siguen un patrón.
1let pageNum = 1;
2while (true) {
3 const resp = await axios.get(`https://example.com/products?page=${pageNum}`);
4 // ...extraer datos
5 if (!hasNextPage) break;
6 pageNum++;
7}Automatización de logins
Con Puppeteer, puedes rellenar formularios de login igual que lo haría cualquier usuario:
1await page.type('#username', 'miUsuario');
2await page.type('#password', 'miContraseña');
3await page.click('#loginButton');
4await page.waitForNavigation();Limpieza de datos
Después de raspar, limpia tus datos:
- Eliminando duplicados (usa un Set o filtra por claves únicas).
- Formateando números, fechas y textos.
- Gestionando valores faltantes (rellena con null o salta registros incompletos).
Las expresiones regulares y los métodos de cadena de JavaScript serán tus mejores amigos aquí.
Buenas prácticas en el raspado web con Node: evita líos y raspa como pro
El raspado web es potente, pero tiene sus trucos. Así puedes evitar los problemas más comunes:
- Respeta robots.txt y los términos del sitio: Siempre revisa si el sitio permite el raspado y evita zonas restringidas.
- Regula tus solicitudes: No satures un sitio con cientos de peticiones por segundo. Añade retrasos y varíalos para parecer más humano ().
- Rota agentes de usuario e IPs: Usa cabeceras realistas y, para raspados grandes, cambia de IP para evitar bloqueos.
- Gestiona errores bien: Captura excepciones, reintenta solicitudes fallidas y registra errores para depurar.
- Valida tus datos: Revisa campos faltantes o mal formateados para detectar cambios en la estructura del sitio a tiempo.
- Escribe código modular y limpio: Separa la lógica de obtención, análisis y guardado. Usa archivos de configuración para selectores y URLs.
Y lo más importante: raspa con ética. La web es de todos y nadie quiere bots abusivos.
Thunderbit vs. raspado web con Node a mano: ¿cuándo programar y cuándo usar una herramienta?
Ahora, el dilema de siempre: ¿hacer tu propio raspador o usar una herramienta como ?
Raspador Node.js a mano:
- Ventajas: Control total, súper personalizable, se integra con cualquier flujo.
- Desventajas: Necesitas saber programar, lleva tiempo montarlo y mantenerlo, se rompe si el sitio cambia.
Thunderbit AI Web Scraper:
- Ventajas: No necesitas programar, detección de campos con IA, gestiona subpáginas y paginación, exporta al instante a Excel, Google Sheets, Notion y más (). Sin mantenimiento: la IA se adapta sola a los cambios del sitio.
- Desventajas: Menos flexibilidad para flujos muy personalizados o complejos (pero cubre el 99% de los casos de negocio).
Aquí tienes una comparación rápida:
| Aspecto | Raspador Node.js DIY | Thunderbit AI Web Scraper |
|---|---|---|
| Habilidad técnica | Requiere programación | Sin código, solo apuntar y hacer clic |
| Tiempo de configuración | Horas o días | Minutos (la IA sugiere los campos) |
| Mantenimiento | Constante (cambios en el sitio) | Mínimo (la IA se adapta sola) |
| Contenido dinámico | Configuración manual de Puppeteer | Soporte integrado |
| Paginación/subpáginas | Programación manual | Soporte de subpáginas/paginación con 1 clic |
| Exportación de datos | Código manual para exportar | 1 clic a Excel, Sheets, Notion |
| Coste | Gratis (tiempo de desarrollo, proxies) | Plan gratuito, créditos según uso |
| Ideal para | Desarrolladores, lógica personalizada | Usuarios de negocio, resultados rápidos |
Thunderbit es un salvavidas para equipos de ventas, marketing y operaciones que necesitan datos ya, no después de una semana de código y pruebas. Y para desarrolladores, es una forma genial de prototipar o automatizar tareas rutinarias de scraping sin reinventar la rueda.
Conclusión y puntos clave: Tu viaje en el raspado web con Node empieza aquí
El raspado web con Node es tu pase para acceder a los datos ocultos de la web, ya sea para crear listas de leads, monitorear precios o impulsar tu próximo gran proyecto. Recuerda:
- Node.js + Cheerio/Axios es ideal para sitios estáticos; Puppeteer es tu aliado para páginas dinámicas y llenas de JavaScript.
- El impacto en el negocio es real: Las empresas que usan el raspado web para tomar decisiones basadas en datos están viendo resultados tangibles, desde hasta duplicar ventas internacionales.
- Empieza simple: Haz un raspador básico y añade funciones como paginación, login automático y limpieza de datos a medida que avances.
- Usa la herramienta adecuada: Para raspados rápidos y sin código, es difícil de superar. Para flujos personalizados e integrados, los scripts Node.js te dan control total.
- Raspa con responsabilidad: Respeta las políticas de los sitios, regula tus bots y mantén tu código limpio y sostenible.
¿Listo para empezar? Prueba a crear tu propio raspador con Node.js o y descubre lo fácil que es extraer datos de la web. Si quieres más consejos, visita el para tutoriales, guías y lo último en scraping con IA.
¡Feliz raspado! Que tus datos siempre estén frescos, ordenados y un paso adelante de la competencia.
Preguntas frecuentes
1. ¿Qué es el raspado web con Node y por qué Node.js es una buena opción?
El raspado web con Node es el proceso de usar Node.js para automatizar la extracción de datos de sitios web. Node.js destaca porque maneja solicitudes asíncronas de forma eficiente y es excelente para raspar sitios llenos de JavaScript, gracias a herramientas como Puppeteer.
2. ¿Cuándo debo usar Cheerio/Axios y cuándo Puppeteer para raspar?
Usa Cheerio y Axios para sitios estáticos donde los datos están en el HTML inicial. Usa Puppeteer cuando necesites extraer contenido generado por JavaScript, interactuar con la página (como iniciar sesión) o manejar scroll infinito.
3. ¿Cuáles son los casos de uso más comunes del raspado web con Node en negocios?
Los principales casos incluyen generación de leads, monitoreo de precios de la competencia, agregación de contenido, análisis de tendencias de mercado y extracción de catálogos de productos. Node.js hace que estas tareas sean rápidas y escalables.
4. ¿Cuáles son los mayores retos del raspado web con Node y cómo evitarlos?
Los problemas más comunes son bloqueos por medidas anti-bots, cambios en la estructura del sitio y gestión de la calidad de los datos. Evítalos regulando las solicitudes, rotando agentes de usuario/IPs, validando tus datos y escribiendo código modular.
5. ¿Cómo se compara Thunderbit con crear mi propio raspador en Node.js?
Thunderbit ofrece una solución sin código, potenciada por IA, que detecta campos, subpáginas y paginación automáticamente. Es ideal para usuarios de negocio que quieren resultados rápidos, mientras que el raspado DIY con Node.js es mejor para desarrolladores que necesitan personalización total o integración con otros sistemas.
Para más guías e inspiración, no olvides visitar el y suscribirte a nuestro para tutoriales prácticos.
Aprende más