El ritmo de las noticias digitales hoy es simplemente vertiginoso. Cada minuto se publican, actualizan o editan en silencio miles de titulares en medios generalistas, blogs especializados y redes sociales.
Para hacerse una idea, ingiere más de 4 millones de artículos de noticias cada día, mientras que rastrea noticias en más de 100 idiomas y actualiza su feed global cada 15 minutos.
Para cualquiera que trabaje en medios, investigación o inteligencia de negocio, intentar seguir este torrente a mano es como vaciar con una taza de café un barco que se hunde.
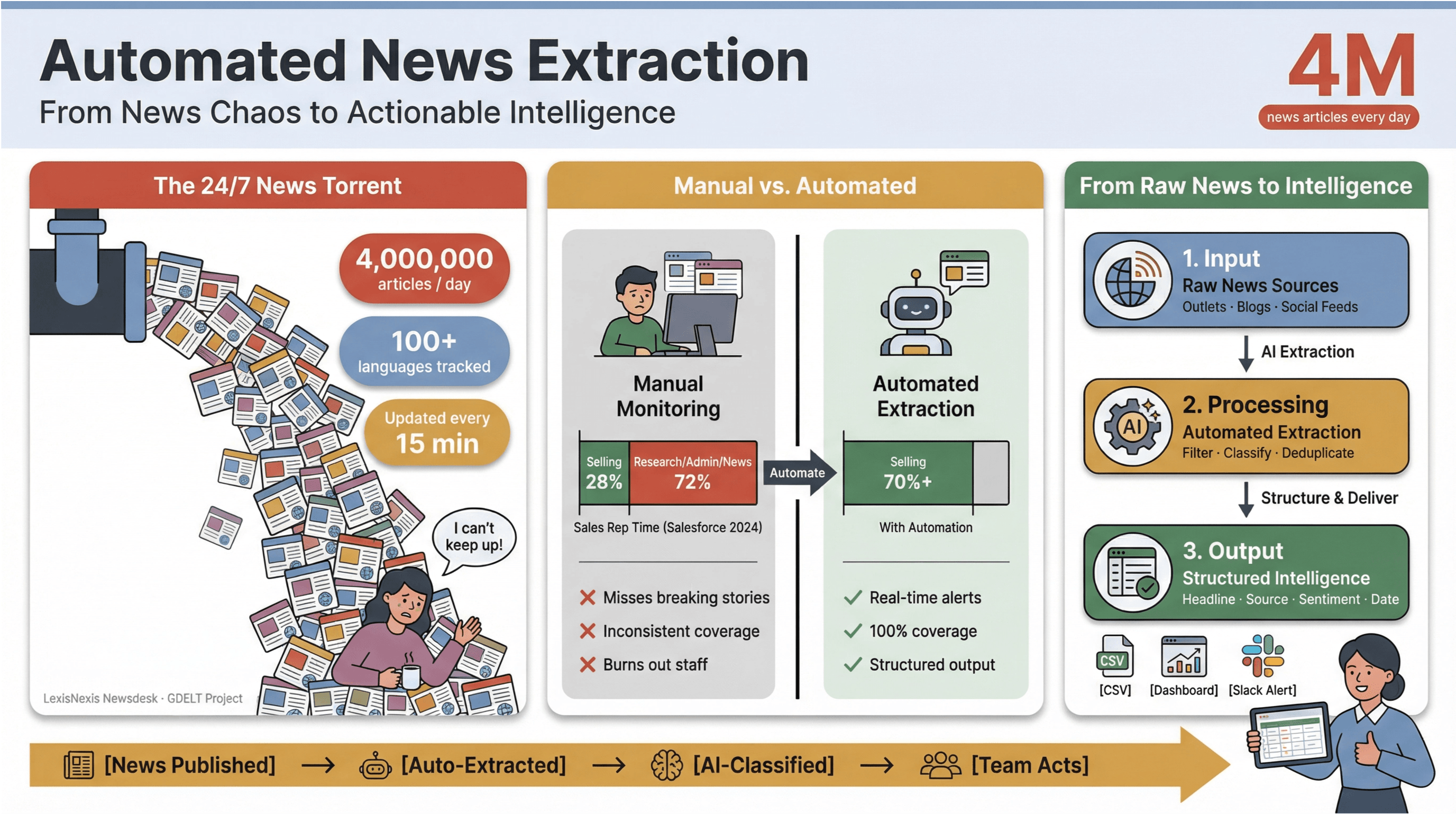
He visto de primera mano cómo el seguimiento manual de noticias consume tiempo y agota recursos. Los equipos de ventas dedican menos de un tercio de la semana a vender de verdad —— y el resto se va en investigación, tareas administrativas y, sí, en cambiar sin parar entre pestañas de noticias.
Por eso la extracción automatizada de noticias se ha convertido en el arma secreta de los equipos modernos: es la única forma de convertir el caos del ciclo informativo 24/7 en inteligencia estructurada y accionable, sin quemar al equipo ni dejar pasar las historias que más importan.
Vamos a ver qué significa realmente la extracción automatizada de noticias, por qué es esencial para cualquiera que valore los datos de noticias en tiempo real y cómo construir un flujo de trabajo sólido y conforme a la normativa usando las mejores herramientas (incluido cómo hace que todo el proceso sea sorprendentemente sencillo, incluso para personas poco técnicas como mi madre).
Extracción automatizada de noticias: por qué es esencial para los medios modernos
La extracción automatizada de noticias es exactamente lo que parece: usar software para recopilar contenido de noticias automáticamente y transformarlo en datos estructurados y buscables, es decir, filas y columnas en lugar de páginas web o PDF desordenados. En la práctica, esto te permite monitorizar cientos o miles de fuentes, extraer campos clave como titular, marca de tiempo, autor y cuerpo del texto, y llevar esos datos a paneles, alertas o análisis posteriores, sin tocar nunca Ctrl+C/Ctrl+V.
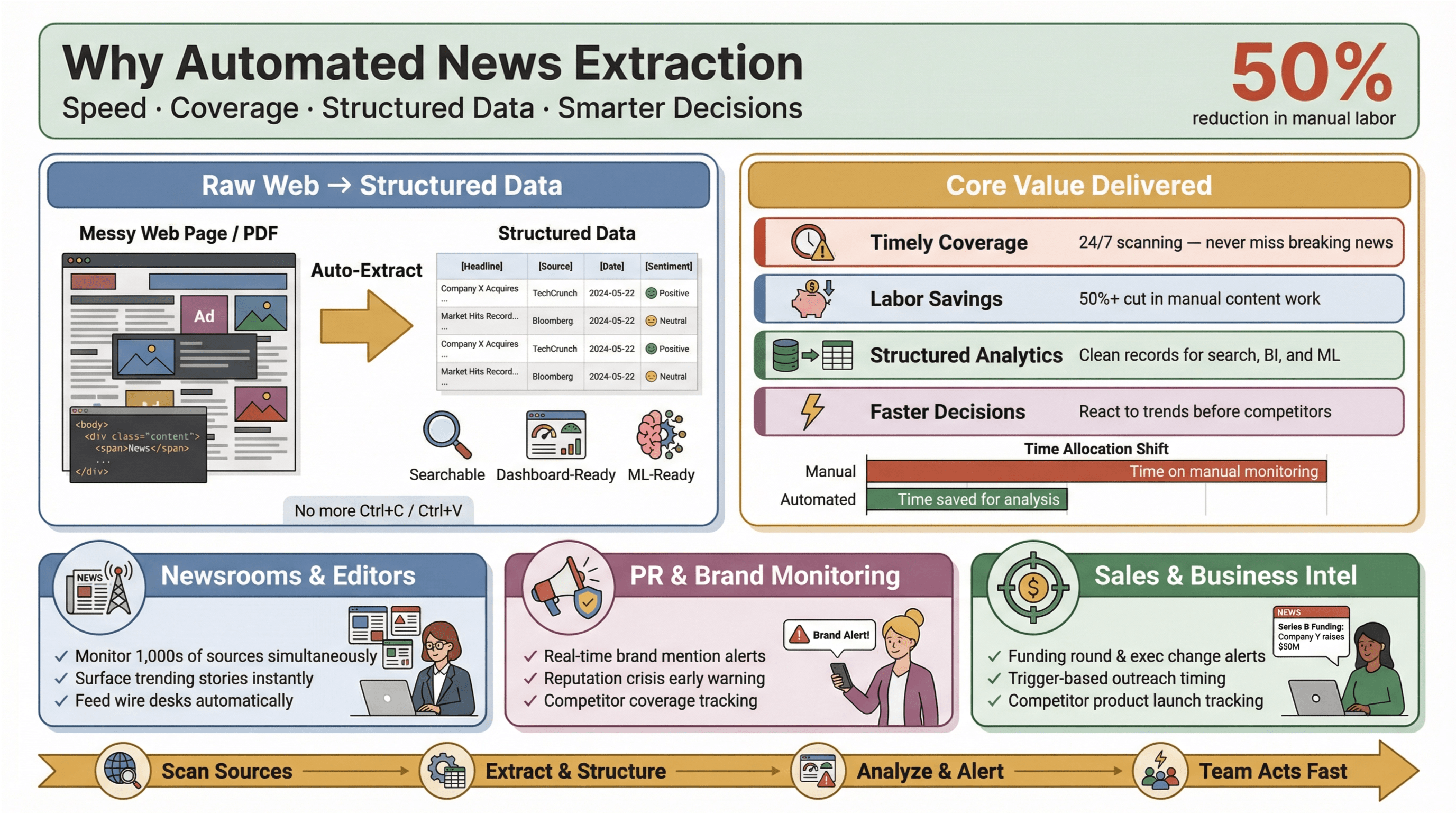 ¿Por qué importa esto? Porque en el panorama informativo actual, la velocidad lo es todo. Tanto si eres editor de una redacción, responsable de PR que vigila menciones de marca o analista de negocio que sigue los movimientos de la competencia, enterarte primero puede marcar la diferencia entre aprovechar una oportunidad o ir a remolque. Las herramientas de extracción automatizada permiten que incluso los equipos pequeños rindan por encima de su tamaño, recopilando datos de noticias en tiempo real de toda la web, reduciendo el trabajo manual y sacando a la luz las historias que más importan.
¿Por qué importa esto? Porque en el panorama informativo actual, la velocidad lo es todo. Tanto si eres editor de una redacción, responsable de PR que vigila menciones de marca o analista de negocio que sigue los movimientos de la competencia, enterarte primero puede marcar la diferencia entre aprovechar una oportunidad o ir a remolque. Las herramientas de extracción automatizada permiten que incluso los equipos pequeños rindan por encima de su tamaño, recopilando datos de noticias en tiempo real de toda la web, reduciendo el trabajo manual y sacando a la luz las historias que más importan.
Y el impacto es real: los estudios muestran que la automatización puede reducir el trabajo manual de actualización de contenidos en al menos un 50 %, liberando tiempo para el análisis y la toma de decisiones reales.
Valor central de la extracción automatizada de noticias en la industria informativa
Vayamos a lo práctico. ¿Qué aporta de verdad la extracción automatizada de noticias a redacciones y equipos de negocio?
- Cobertura oportuna y completa: se acabó perderse noticias de última hora porque alguien olvidó revisar un feed. Las herramientas automatizadas escanean fuentes 24/7 y garantizan que no te pierdas nada.
- Ahorro de trabajo y costes: los equipos pequeños y medianos pueden monitorizar tantas fuentes como los grandes, sin contratar un ejército de becarios.
- Datos estructurados para análisis: en lugar de revisar artículos desestructurados, obtienes registros limpios y estructurados listos para búsqueda, paneles y aprendizaje automático.
- Decisiones más rápidas e inteligentes: los datos de noticias en tiempo real te permiten reaccionar antes que la competencia a cambios del mercado, crisis de PR o tendencias emergentes.
Pensemos en PR y comunicación: plataformas como y presentan la monitorización de medios en tiempo real como algo esencial para proteger la reputación y actuar rápido ante coberturas perjudiciales. En ventas, las alertas de noticias en tiempo real se convierten en “tarjetas de contexto” para prospección: rondas de financiación, cambios ejecutivos o lanzamientos de productos que activan el contacto justo en el momento adecuado.
Cómo elegir las herramientas adecuadas de raspado de noticias para distintos escenarios
No todas las herramientas de raspado de noticias son iguales. La elección correcta depende de tus objetivos, de tu nivel técnico y del tipo de noticias que te interesen. Aquí tienes un marco para ayudarte a elegir la mejor opción:
Evaluar la facilidad de uso y la accesibilidad
Para la mayoría de usuarios de negocio y periodistas, la facilidad de uso no es negociable. Quieres una herramienta que funcione desde el primer momento, sin programación ni configuraciones complicadas. Las plataformas sin código y con poco código como , y te permiten crear raspadores de forma visual: apunta, haz clic y extrae.
Thunderbit, en particular, destaca por su proceso en dos pasos: describes lo que quieres, la IA sugiere los campos y pulsas “Raspar”. Incluso usuarios sin perfil técnico pueden montar una canalización de datos de noticias en minutos, no en horas.
Seguridad y privacidad de los datos
Con grandes datos viene una gran responsabilidad. Las herramientas de raspado de noticias suelen acceder a contenido sensible, así que la seguridad y el cumplimiento deben ser prioritarios. Busca lo siguiente:
- Cifrado de datos (en tránsito y en reposo)
- Políticas de privacidad claras (Thunderbit, por ejemplo, declara que no vende datos de usuario y solo accede al contenido que eliges raspar)
- Permisos granulares (especialmente en extensiones de navegador: revisa siempre a qué datos puede acceder la herramienta)
- Cumplimiento de la normativa local (RGPD, CCPA y, para usuarios de la UE, la )
Para mayor tranquilidad, elige proveedores de confianza, verifica los permisos de la extensión y limita el acceso solo a lo necesario.
Ajustar las herramientas al tipo de noticias y a las necesidades del sector
Algunas herramientas destacan en dominios concretos de noticias:
- Finanzas: APIs como y ofrecen agrupación, análisis de sentimiento y detección de eventos para noticias financieras.
- Tecnología y startups: el raspado personalizado con Thunderbit u Octoparse te permite dirigirte a blogs especializados, notas de prensa o listados de eventos.
- Política y regulación: bases de datos con licencia como y dan acceso a fuentes premium y archivos históricos.
Si necesitas monitorizar una mezcla de fuentes generalistas, nicho e internacionales, incluidas aquellas sin API, los raspadores flexibles impulsados por IA como Thunderbit son tu mejor apuesta.
Las ventajas únicas de Thunderbit para la extracción de datos de noticias en tiempo real
Ahora hablemos de lo que convierte a en una opción destacada para la extracción automatizada de noticias, especialmente si quieres datos de noticias en tiempo real sin complicaciones técnicas.
Thunderbit es una extensión de Chrome de raspador web con IA diseñada para usuarios de negocio, periodistas y analistas que necesitan contenido de noticias estructurado y actualizado desde cualquier sitio web. Estas son las razones por las que se ha convertido en mi herramienta de referencia:
- Sugerencia de campos con IA: Thunderbit lee la página de noticias y sugiere automáticamente las mejores columnas para extraer: titular, marca de tiempo, autor, resumen y más. No hace falta pelearse con selectores ni plantillas.
- Raspado de subpáginas: ¿Necesitas el artículo completo, no solo el titular? Thunderbit puede visitar cada enlace de noticia, extraer el cuerpo del texto, las entidades y las etiquetas, y fusionarlo todo en una única tabla estructurada.
- Exportación masiva y actualizaciones instantáneas: exporta tus datos de noticias directamente a Excel, Google Sheets, Airtable o Notion con un clic. Se acabaron las maratones de copiar y pegar o el lío con CSV.
- Raspado programado: configura tareas recurrentes (cada hora, a diario o con intervalos personalizados) para mantener tu canal de noticias siempre fresco, ideal para noticias de última hora, seguimiento de mercado o investigación continua.
- Adaptabilidad: la IA de Thunderbit se adapta a cambios de diseño y a sitios de noticias de larga cola, así que dedicas menos tiempo a arreglar raspadores rotos y más a analizar datos.
Con más de y una valoración de 4,8 estrellas, equipos de todo el mundo confían en él para todo, desde monitorización de PR hasta inteligencia competitiva.
Detección de campos impulsada por IA y raspado de subpáginas
Una de las funciones más potentes de Thunderbit es su detección de campos impulsada por IA. Solo tienes que hacer clic en “Sugerir campos con IA” y la herramienta analizará la página de noticias, identificando campos clave como título, fecha, autor y resumen. Puedes ajustar o añadir campos personalizados (por ejemplo, “etiquetar este artículo como ‘resultados’ si menciona resultados trimestrales”), y la IA de Thunderbit se encarga del resto.
El raspado de subpáginas cambia por completo la extracción de noticias: raspa la página de inicio o un listado de secciones para obtener titulares y luego deja que Thunderbit visite la URL de cada artículo para extraer la historia completa, las entidades e incluso las imágenes. Así obtienes registros de noticias completos y enriquecidos, listos para búsqueda, paneles o análisis posteriores con IA.
Exportación masiva y actualizaciones instantáneas
Thunderbit hace que exportar datos de noticias sea muy fácil. Con un clic, puedes enviar tu feed estructurado de noticias a Google Sheets, Airtable, Notion o descargarlo como CSV/Excel. Para equipos que viven en hojas de cálculo o herramientas de BI, esto ahorra muchísimo tiempo.
Y como Thunderbit admite raspado programado, puedes configurarlo para que se ejecute cada hora, cada día o con tu propio calendario personalizado, asegurando que tus datos de noticias estén siempre al día. Se acabó esperar a que Google Alerts indexe historias con días de retraso.
Cómo superar los desafíos operativos en soluciones de datos de noticias en tiempo real
Incluso con las mejores herramientas, la extracción de noticias en tiempo real presenta sus propios retos. Así puedes abordar los más comunes:
Gestionar la latencia y la frescura de los datos
- Programa los raspados según la velocidad de las noticias: para noticias de última hora, configura los raspadores para que se ejecuten cada 15-30 minutos (siguiendo el ciclo de actualización del ). Para temas más lentos, puede bastar con intervalos diarios u horarios.
- Supervisa el desfase entre la publicación y la captura: mide la diferencia entre cuándo se publica un artículo y cuándo lo recoge tu sistema. Si el retraso aumenta, revisa si hay bloqueos o ralentizaciones.
- Vuelve a raspar para detectar “ediciones silenciosas”: los artículos de noticias suelen actualizarse después de publicarse. Programa un segundo raspado 24 horas más tarde para captar correcciones o ediciones discretas ().
Gestionar los límites de API y la variabilidad de las fuentes
- Respeta las cuotas de API: si usas APIs de noticias, vigila los límites de velocidad; reparte las solicitudes en el tiempo y almacena resultados en caché cuando sea posible ().
- Elimina duplicados y canoniza: las noticias suelen aparecer en varias URL o actualizarse. Captura las URL canónicas y usa hashes (por ejemplo, título + fecha) para evitar duplicados ().
- Gestiona contenido dinámico: en sitios con scroll infinito o carga perezosa, utiliza herramientas que admitan renderizado dinámico y vigila los cambios de diseño ().
Análisis inteligente de datos de noticias: el papel de la IA y el aprendizaje automático
Extraer noticias es solo el primer paso. El verdadero valor está en analizar y actuar sobre esos datos, y ahí es donde brillan la IA y el aprendizaje automático.
- Extracción de entidades: usa PLN para sacar personas, organizaciones y lugares mencionados en cada artículo ().
- Clasificación de temas: etiqueta automáticamente artículos por tema, sentimiento o urgencia, lo que permite paneles y alertas más inteligentes ().
- Agrupación de eventos: agrupa historias duplicadas o relacionadas entre distintos medios para ver la foto completa, no solo un aluvión de titulares casi idénticos.
- Personalización y segmentación: usa datos de noticias en tiempo real para segmentar audiencias, mejorar la segmentación publicitaria o recomendar contenido, aumentando la interacción y el ROI.
Por ejemplo, los equipos de PR usan analítica de noticias en tiempo real para detectar crisis emergentes antes de que se viralicen, mientras que los equipos de ventas enriquecen listas de prospectos con “eventos disparadores” como rondas de financiación o contrataciones ejecutivas.
Lista de buenas prácticas para la extracción automatizada de noticias
Aquí tienes una lista rápida para mantener tu canal de extracción de noticias funcionando sin problemas:
| Mejor práctica | Por qué importa | Cómo implementarla |
|---|---|---|
| Programar raspados frecuentes | Minimiza el retraso de datos y captura noticias de última hora | Ajusta la frecuencia de actualización a la velocidad de las noticias (por ejemplo, cada 15 min en temas muy rápidos) |
| Usar extracción impulsada por IA | Se adapta a cambios de diseño y reduce el tiempo de configuración | Herramientas como Thunderbit, Diffbot, Zyte API |
| Eliminar duplicados y canonizar | Evita alertas duplicadas y garantiza datos limpios | Captura URL canónicas, usa hashes para deduplicación |
| Supervisar la calidad de la extracción | Detecta campos faltantes, desviaciones o fallos | Controla el porcentaje de registros completos, el retraso y las tasas de error |
| Respetar los límites legales y de cumplimiento | Evita riesgos legales y mantiene la confianza | Prioriza APIs o feeds oficiales, revisa los términos y minimiza los datos personales |
| Exportar a formatos estructurados | Facilita el análisis posterior | CSV, Excel, Sheets, Notion, Airtable |
| Programar re-raspados para cambios | Detecta modificaciones tras la publicación | Revisa los artículos después de 24 h/1 semana (modelo GDELT) |
| Asegurar tu canal | Protege datos sensibles | Cifrado, controles de acceso, herramientas de confianza |
Cómo construir un flujo de trabajo robusto de extracción automatizada de noticias
¿Listo para crear tu propio “cerebro” para datos de noticias? Aquí tienes un flujo de trabajo paso a paso:
- Identifica tus fuentes: haz una lista de los sitios de noticias, blogs o APIs que quieres monitorizar.
- Configura la extracción: usa Thunderbit o la herramienta que prefieras para definir campos (Sugerir campos con IA lo pone muy fácil).
- Programa los raspados: ajusta la frecuencia según la velocidad de las noticias: cada hora para última hora, diario para temas más lentos.
- Enriquecimiento de subpáginas: para cada titular, raspa el artículo completo para obtener cuerpo del texto, entidades y etiquetas.
- Elimina duplicados y normaliza: captura URL canónicas, genera hashes de los registros y estandariza los campos.
- Exporta e integra: envía los datos estructurados a Excel, Google Sheets, Airtable o Notion para analizarlos.
- Supervisa y adapta: controla la calidad de la extracción, vigila cambios de diseño y ajusta según sea necesario.
- Mantente conforme: revisa los términos, respeta robots.txt y minimiza los datos personales.
Para visualizarlo, piensa en esto: Fuentes → Extracción (campos con IA) → Enriquecimiento de subpáginas → Eliminación de duplicados → Exportación → Análisis/alertas → Supervisión
Conclusión y conclusiones clave
La extracción automatizada de noticias ya no es solo algo “deseable”: es imprescindible para cualquiera que necesite ir un paso por delante en un mundo donde las noticias surgen y cambian cada minuto. Siguiendo buenas prácticas y usando las herramientas adecuadas, puedes convertir el grifo inagotable de noticias digitales en un flujo constante de inteligencia estructurada y accionable.
Puntos clave:
- La escala y la velocidad de las noticias online exigen automatización: la monitorización manual simplemente no da abasto.
- Las herramientas de extracción automatizada de noticias ahorran tiempo, reducen costes y permiten que los equipos pequeños igualen la cobertura de organizaciones mucho mayores.
- Elegir la herramienta adecuada implica equilibrar facilidad de uso, seguridad y adaptabilidad; Thunderbit destaca por su simplicidad impulsada por IA y sus opciones de exportación en tiempo real.
- Construye tu flujo de trabajo alrededor de la frescura, la deduplicación, el cumplimiento normativo y la supervisión de la calidad para garantizar datos de noticias fiables y accionables.
- La IA y el aprendizaje automático desbloquean aún más valor, al permitir una mejor segmentación, personalización y toma de decisiones.
Si sigues copiando y pegando titulares o esperando a que Google Alerts se ponga al día, ha llegado el momento de subir de nivel. y descubre lo fácil que puede ser la extracción automatizada de noticias. Para más consejos, flujos de trabajo y análisis en profundidad, visita el .
Preguntas frecuentes
1. ¿Qué es la extracción automatizada de noticias y cómo funciona?
La extracción automatizada de noticias es el proceso de usar software para recopilar artículos de noticias y convertirlos en datos estructurados (como tablas o JSON) para su análisis, búsqueda o alertas. Herramientas como Thunderbit usan IA para identificar campos clave (titular, marca de tiempo, autor, cuerpo del texto) y extraerlos automáticamente de páginas web o APIs.
2. ¿Por qué los datos de noticias en tiempo real son tan importantes para las empresas?
Los datos de noticias en tiempo real permiten a las empresas reaccionar rápidamente a acontecimientos del mercado, crisis de PR o movimientos de la competencia. Tanto si trabajas en ventas, PR o investigación, contar con noticias actualizadas te ayuda a tomar decisiones más inteligentes y rápidas, y a ir por delante de la competencia.
3. ¿Cómo facilita Thunderbit el raspado de noticias a usuarios sin perfil técnico?
Thunderbit ofrece un proceso sencillo en dos pasos: describes qué datos quieres y la IA sugiere los campos. Con funciones como el raspado de subpáginas y la exportación instantánea a Excel o Google Sheets, incluso usuarios sin experiencia técnica pueden crear canalizaciones robustas de datos de noticias en minutos.
4. ¿Cuáles son las consideraciones legales y de cumplimiento para el raspado de noticias?
Revisa siempre los términos de servicio de los sitios objetivo, prioriza las APIs o feeds oficiales cuando estén disponibles y respeta las directrices de robots.txt. Evita raspar contenido que requiera inicio de sesión o esté tras un muro de pago sin permiso, y minimiza la recopilación de datos personales para cumplir con las leyes de privacidad.
5. ¿Cómo puedo asegurarme de que mi flujo de trabajo de extracción de noticias siga siendo fiable con el tiempo?
Programa raspados periódicos, supervisa la calidad de la extracción y usa herramientas que se adapten a cambios de diseño (como la extracción impulsada por IA de Thunderbit). Elimina duplicados, controla el retraso entre publicación y extracción y configura alertas para fallos o campos faltantes para mantener tu canal sano y actualizado.
Saber más