

El web scraping ha pasado de ser una habilidad de nicho a convertirse en un superpoder imprescindible para cualquiera que trabaje en ventas, operaciones o investigación de mercado. Con el enorme volumen de datos web disparándose —la creación global de datos aumentó casi un 193 % entre 2019 y 2023—, no sorprende que el 81 % de las empresas ya trate los datos como el “corazón” de su toma de decisiones. Pero aquí está el problema: el 95 % de las organizaciones dice que gestionar datos no estructurados (como HTML caótico) es un reto importante. He visto a muchos equipos ahogándose en maratones de copiar y pegar, intentando convertir información de sitios web en hojas de cálculo; créeme, no es nada bonito.
Extrae datos de cualquier sitio web con IA Get Started Free
Ahí es donde entra BeautifulSoup de Python. En este tutorial práctico, te mostraré cómo usar BeautifulSoup para web scraping, con un ejemplo real de Python Beautiful Soup que puedes adaptar a las necesidades de tu negocio. Y como soy de la idea de trabajar de forma más inteligente, no más dura, también te enseñaré a combinar BeautifulSoup con Thunderbit, nuestro raspador web con IA, para acelerar tu flujo de trabajo y obtener datos más limpios y estructurados, sin importar tu nivel de programación.
¿Qué es BeautifulSoup y por qué usarlo para web scraping?
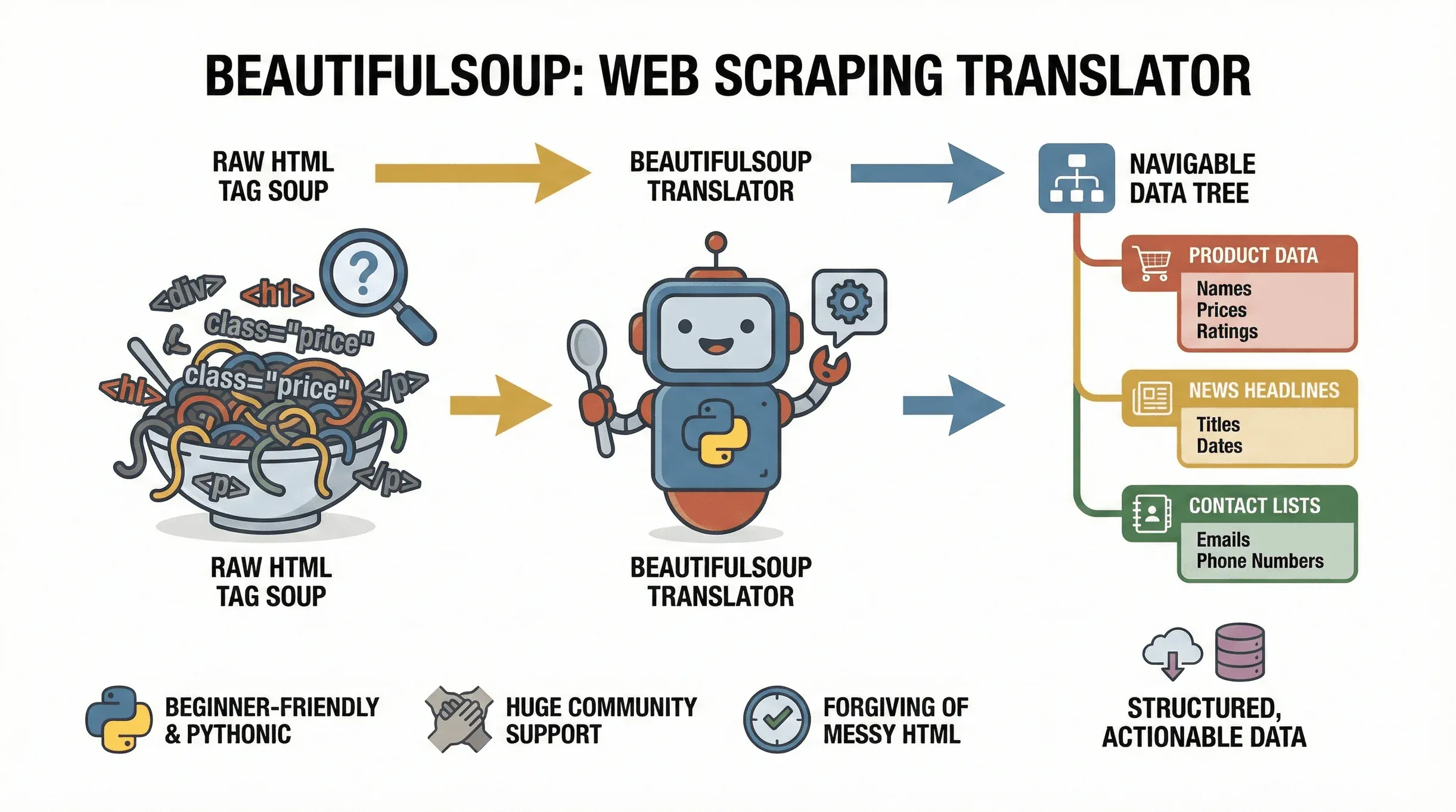 Empecemos por lo básico. BeautifulSoup es una biblioteca de Python que facilita el análisis de documentos HTML y XML. Piénsalo como un traductor: toma la “sopa de etiquetas” de una página web y la convierte en un árbol navegable, para que puedas encontrar, extraer y manipular fácilmente los datos que necesitas. El proyecto sigue mantenido activamente —
Empecemos por lo básico. BeautifulSoup es una biblioteca de Python que facilita el análisis de documentos HTML y XML. Piénsalo como un traductor: toma la “sopa de etiquetas” de una página web y la convierte en un árbol navegable, para que puedas encontrar, extraer y manipular fácilmente los datos que necesitas. El proyecto sigue mantenido activamente —beautifulsoup4 4.14.3 se publicó en PyPI a finales de 2025—, así que todo lo que aprendas aquí sigue vigente. Tanto si extraes precios de productos de un sitio de e-commerce, recopilas titulares de noticias o rastreas directorios de empresas para conseguir leads, BeautifulSoup es la herramienta ideal para convertir páginas web en datos estructurados y accionables.
¿Por qué es tan popular? Para empezar, es increíblemente amigable para principiantes. BeautifulSoup tolera bien el HTML desordenado (y, seamos sinceros, la web está llena de él), y su sintaxis estilo Python te permite pasar de cero a extraer datos en solo unas pocas líneas de código. Además, cuenta con un gran respaldo, millones de descargas y una comunidad enorme; así que, si te atascas, la ayuda está a una búsqueda en Google de distancia.
Los usos típicos de BeautifulSoup incluyen:
- Extraer nombres de productos, precios y valoraciones de páginas de e-commerce
- Obtener titulares, autores y fechas de publicación de sitios de noticias
- Analizar tablas o directorios (como listas de empresas o contactos)
- Recopilar correos electrónicos o números de teléfono de sitios de listados
- Supervisar actualizaciones (cambios de precio, nuevas ofertas de empleo, etc.)
Si tus datos viven en HTML estático, BeautifulSoup es tu mejor aliado para el web scraping.
Las ventajas únicas de BeautifulSoup para web scraping
Hay muchas bibliotecas de Python para web scraping, así que ¿por qué elegir BeautifulSoup? Así se compara con la competencia:
- Simplicidad: BeautifulSoup es ligero y fácil de aprender. No necesitas montar un framework completo ni escribir montones de código repetitivo. Es perfecto para tareas rápidas y puntuales, o para quienes están empezando.
- Tolerancia: Puede manejar HTML roto o mal formado, algo mucho más común de lo que imaginas.
- Flexibilidad: No te obliga a seguir una arquitectura de rastreo rígida. Solo pásale HTML y extrae lo que necesitas.
- Integración: BeautifulSoup se lleva muy bien con otras bibliotecas de Python como
requests(para obtener páginas web),csv(para guardar datos) ypandas(para análisis de datos).
¿Cómo se compara con otras herramientas?
| Herramienta | Ideal para | Ventajas | Desventajas |
|---|---|---|---|
| BeautifulSoup | Análisis de HTML estático, principiantes | Sencillo, arranque rápido, tolerante, flexible | No es ideal para sitios con mucho JavaScript |
| Scrapy | Trabajos asíncronos a gran escala | Potente, escalable, rastreo integrado | Curva de aprendizaje más alta, requiere más configuración |
| Selenium | Contenido JavaScript/dinámico | Puede interactuar con JS, rellenar formularios y hacer clic en botones | Más lento, más pesado, consume más recursos |
Si apenas estás empezando o necesitas analizar rápidamente páginas estáticas, BeautifulSoup es la “navaja suiza” del web scraping (medium.com). Para sitios más complejos o dinámicos, puedes combinarlo con Selenium o Scrapy, pero BeautifulSoup es la mejor forma de aprender la base.
Configurar tu entorno de Python para BeautifulSoup
¿Listo para empezar? Así puedes preparar tu entorno:
-
Instala Python: Descarga la última versión desde python.org.
-
Crea un entorno virtual (opcional, pero recomendado):
python -m venv venv source venv/bin/activate # En Windows: venv\Scripts\activate -
Instala BeautifulSoup y sus dependencias:
pip install beautifulsoup4 requests lxml html5libbeautifulsoup4: La biblioteca principalrequests: Para obtener páginas weblxmlohtml5lib: Parsers HTML más rápidos y/o fiables
-
Consejos para solucionar problemas:
- Si te aparece el error “pip not found”, prueba con
pip3opy -m pip. - En Mac/Linux, quizá necesites
sudopor permisos. - Si estás en Windows, asegúrate de que Python esté añadido a tu PATH.
- Si te aparece el error “pip not found”, prueba con
Para comprobar que todo está bien, ejecuta esta prueba rápida:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
Si ves <title>Example Domain</title>, todo está listo (Thunderbit Blog).
Un ejemplo paso a paso de Python Beautiful Soup
Vamos a ver un ejemplo real de python beautiful soup. Imagina que quieres extraer los últimos titulares de noticias de un sitio público. Así lo harías:
1. Obtener la página web
import requests
from bs4 import BeautifulSoup
url = "https://www.bbc.com/news"
response = requests.get(url)
html = response.text
2. Analizar el HTML
soup = BeautifulSoup(html, "html.parser")
3. Inspeccionar la estructura HTML
Abre las Herramientas para desarrolladores de tu navegador (clic derecho → Inspeccionar) y busca las etiquetas que contienen los titulares. En muchos sitios de noticias, los titulares están en etiquetas <h3> con clases específicas.
Por ejemplo, podrías ver:
<h3 class="gs-c-promo-heading__title">Título del titular</h3>
4. Extraer los datos
headlines = soup.find_all("h3", class_="gs-c-promo-heading__title")
for h in headlines:
print(h.get_text(strip=True))
Esto imprimirá todos los titulares de noticias de la página.
5. Guardar los datos en CSV
Guardemos esos titulares para analizarlos más adelante:
import csv
with open("headlines.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["titular"])
for h in headlines:
writer.writerow([h.get_text(strip=True)])
Ahora ya tienes un archivo CSV listo para Excel o Google Sheets.
Entender la estructura HTML para una extracción eficaz de datos
Antes de escribir una sola línea de código, inspecciona siempre el HTML de la página. Así se hace:
- Abre las herramientas para desarrolladores: Haz clic derecho en la página y selecciona “Inspeccionar”.
- Encuentra los datos: Pasa el cursor sobre los elementos para ver qué etiquetas contienen la información que buscas (por ejemplo, titulares, precios, autores).
- Fíjate en las etiquetas y clases: Busca identificadores únicos como
class="product-title"oid="main-content". - Prueba tus selectores: Usa los métodos
.find(),.find_all()o.select()de BeautifulSoup para apuntar a esos elementos.
Consejo profesional: usa soup.prettify() para imprimir una versión legible del HTML en la consola de Python.
Extraer y estructurar datos con BeautifulSoup
Supongamos que quieres extraer tanto títulos como autores de una página de blog:
articles = soup.find_all("article")
data = []
for article in articles:
title = article.find("h2").get_text(strip=True)
author = article.find("span", class_="author").get_text(strip=True)
data.append({"title": title, "author": author})
Ahora tienes una lista de diccionarios, perfecta para exportarla a CSV o para hacer un análisis más profundo.
Puedes extraer enlaces, imágenes o cualquier atributo así:
for link in soup.find_all("a"):
print(link.get("href"))
O imágenes:
for img in soup.find_all("img"):
print(img.get("src"))
Guardar los datos extraídos: de Python a Excel o CSV
Una vez que hayas estructurado tus datos, exportarlos es fácil. Así se hace con el módulo csv:
import csv
with open("articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
O, si eres fan de pandas:
import pandas as pd
df = pd.DataFrame(data)
df.to_csv("articles.csv", index=False)
df.to_excel("articles.xlsx", index=False)
Usa siempre codificación UTF-8 para evitar problemas con caracteres raros, especialmente en datos internacionales.
Caso práctico: extraer datos de un sitio de noticias con BeautifulSoup
Veamos un ejemplo práctico de python beautiful soup: extraer títulos de artículos, autores y fechas de publicación de un sitio de noticias.
Supongamos que quieres hacer scraping de CNN para obtener datos de artículos:
import requests
from bs4 import BeautifulSoup
import csv
url = "https://edition.cnn.com/world"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
articles = soup.find_all("article")
data = []
for article in articles:
title_tag = article.find("h3")
date_tag = article.find("span", class_="date")
author_tag = article.find("span", class_="author")
title = title_tag.get_text(strip=True) if title_tag else ""
date = date_tag.get_text(strip=True) if date_tag else ""
author = author_tag.get_text(strip=True) if author_tag else ""
data.append({"title": title, "date": date, "author": author})
with open("cnn_articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "date", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
Este script obtendrá los artículos más recientes, extraerá el título, la fecha y el autor, y los guardará en un CSV, suponiendo que el marcado actual de CNN siga coincidiendo con las etiquetas anteriores. Los grandes sitios de noticias cambian con frecuencia los nombres de sus clases y la estructura del DOM, así que vuelve a inspeccionar la página antes de usar esto en datos de producción. La estructura (<article> como contenedor y luego find en las etiquetas hijas) es el patrón resistente; los nombres concretos de clase como "date" y "author" son marcadores de posición que deberías ajustar a lo que la página esté sirviendo en ese momento.
Mejorar tu flujo de trabajo: combinar BeautifulSoup con Thunderbit
Ahora hablemos de cómo hacer tu flujo de trabajo de scraping aún más fluido. Thunderbit es una extensión de Chrome para web scraping con IA que elimina las conjeturas de la extracción de datos. Con Thunderbit, puedes:
- Usar “AI Suggest Fields”: Thunderbit lee la página y sugiere automáticamente qué campos de datos extraer; ya no tendrás que buscar entre el HTML ni ajustar selectores.
- Rastrear subpáginas: Thunderbit puede seguir enlaces a subpáginas (como páginas individuales de productos o artículos) y enriquecer tu conjunto de datos con detalles adicionales.
- Exportar al instante: Envía tus datos directamente a Excel, Google Sheets, Airtable o Notion con un solo clic.
- Gestionar la paginación: Thunderbit puede extraer datos a través de varias páginas (incluido el scroll infinito).
- Programar extracciones: Configura tareas recurrentes para mantener tus datos actualizados.
Este es un flujo híbrido que me encanta:
- Empieza con Thunderbit: Abre tu sitio objetivo, haz clic en el icono de Thunderbit y deja que “AI Suggest Fields” identifique las columnas adecuadas (como título, autor y fecha).
- Exporta los datos: Descarga los resultados como CSV o envíalos a Google Sheets.
- Usa BeautifulSoup para el procesamiento personalizado: Si necesitas hacer un análisis más profundo (como limpieza de texto, deduplicación o combinación con otras fuentes), carga el CSV exportado en Python y usa BeautifulSoup o pandas para el postprocesado.
Esta combinación te ofrece lo mejor de ambos mundos: la velocidad y la detección de campos con IA de Thunderbit, más la flexibilidad de BeautifulSoup para lógica personalizada.
Prueba gratis Thunderbit AI Web Scraper
Velocidad y calidad de datos: ¿por qué usar Thunderbit y BeautifulSoup juntos?
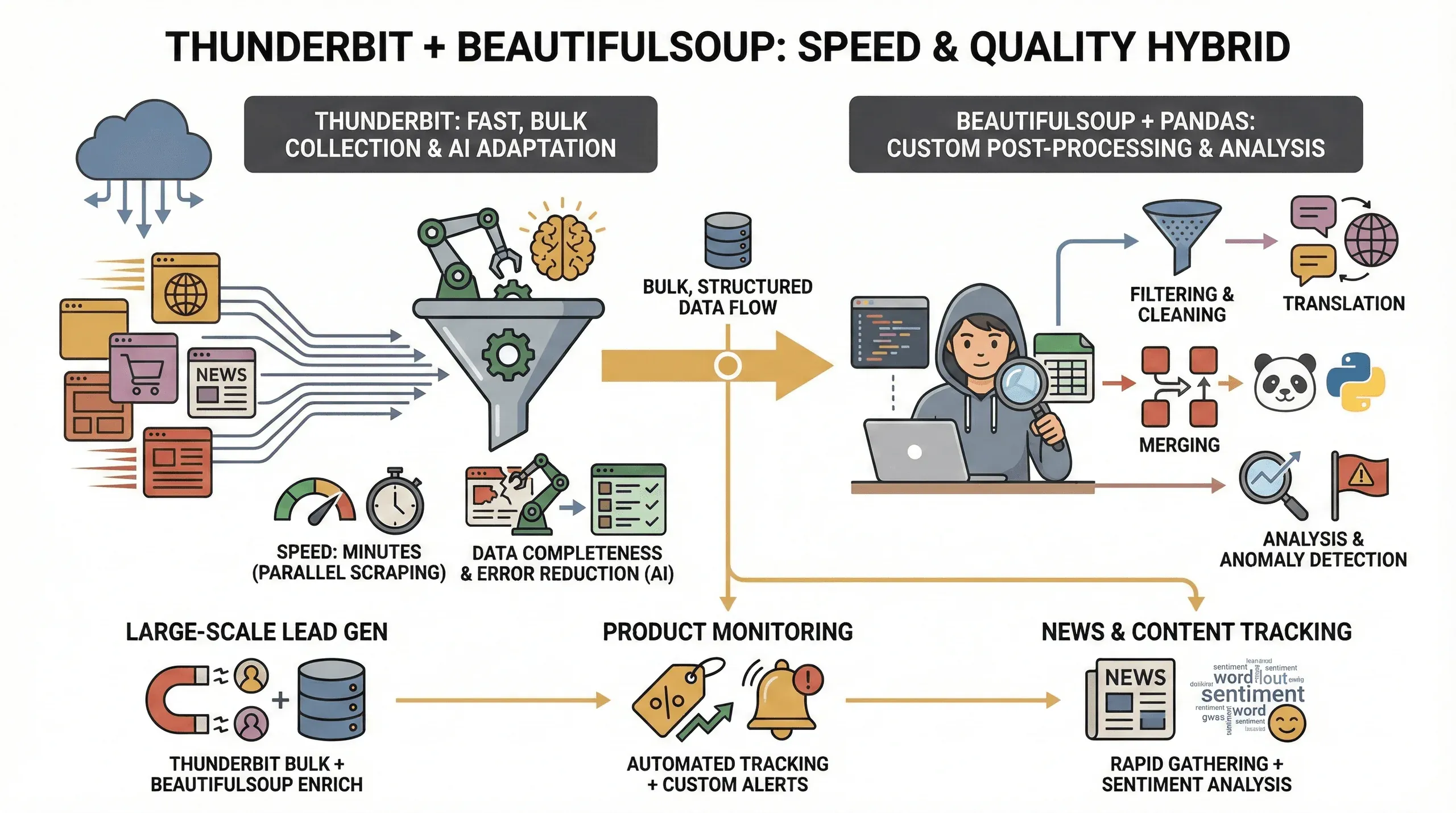 ¿Por qué usar ambas herramientas? Esto es lo que he comprobado:
¿Por qué usar ambas herramientas? Esto es lo que he comprobado:
- Velocidad: Thunderbit puede extraer docenas de páginas en paralelo (hasta 50 a la vez en modo nube), así que obtienes tus datos en minutos en lugar de horas.
- Completitud de los datos: La IA de Thunderbit se adapta a cambios de diseño y puede extraer datos estructurados incluso de sitios complicados, reduciendo la probabilidad de que falten campos.
- Reducción de errores: Se acabaron los scripts rotos cuando cambia un nombre de clase: la IA de Thunderbit reevalúa la página cada vez.
- Postprocesado personalizado: Para necesidades avanzadas (como filtrar, traducir o fusionar conjuntos de datos), BeautifulSoup y pandas te dan control total.
Este enfoque híbrido es especialmente valioso para:
- Generación de leads a gran escala: Usa Thunderbit para obtener el volumen principal de datos y luego BeautifulSoup para limpiarlos y enriquecerlos.
- Monitorización de productos: Thunderbit se encarga del scraping repetitivo, mientras BeautifulSoup te permite analizar tendencias o detectar anomalías.
- Seguimiento de noticias y contenido: Reúne artículos rápidamente con Thunderbit y luego usa Python para análisis de sentimiento o extracción de palabras clave.
Solución de problemas comunes en el web scraping con BeautifulSoup
Prueba la extensión de Chrome de Thunderbit Extrae cualquier sitio web con IA en 2 clics. Get Started Free
El web scraping no siempre es un camino de rosas; aquí van algunos problemas comunes y cómo solucionarlos:
- Contenido dinámico: Si un sitio carga datos con JavaScript (scroll infinito, AJAX), BeautifulSoup por sí solo no los verá. Usa Selenium o el modo navegador de Thunderbit en estos casos.
- Medidas anti-bot: Algunos sitios bloquean las solicitudes automatizadas. Prueba a añadir un encabezado User-Agent personalizado, introduce pausas entre solicitudes o usa el scraping en la nube de Thunderbit para saltarte bloqueos sencillos.
- Cambios en la estructura HTML: Si tu script deja de funcionar de repente, probablemente el HTML del sitio cambió. Vuelve a inspeccionar la página y actualiza tus selectores. La IA de Thunderbit puede ayudarte adaptándose sobre la marcha.
- Datos faltantes: Comprueba siempre que los elementos existan antes de llamar a
.get_text(). Usa.get()en lugar de[]para los atributos y evitar errores KeyError. - Problemas de codificación: Guarda los archivos con codificación UTF-8 para manejar caracteres especiales.
Y, siempre, siempre, respeta robots.txt y los términos de servicio del sitio. Haz scraping de forma responsable; a nadie le gusta un robot maleducado.
Conclusión y conclusiones clave
El web scraping con BeautifulSoup es una de las habilidades más prácticas que puedes aprender en el mundo actual, impulsado por los datos. Esto es lo que hemos visto en este tutorial de web scraping con BeautifulSoup:
- BeautifulSoup es el punto de partida ideal para analizar HTML estático y extraer datos estructurados con Python.
- La configuración es muy sencilla: solo instala Python, pip y un par de bibliotecas.
- Inspeccionar el HTML es clave para apuntar a los datos correctos.
- Exportar a CSV/Excel hace que tus datos sean utilizables al instante para análisis de negocio.
- Combinarlo con Thunderbit te da detección de campos con IA, scraping más rápido y exportaciones más fáciles: perfecto para usuarios de negocio y personas sin perfil técnico.
- Los flujos híbridos (Thunderbit para extracción masiva, BeautifulSoup para procesamiento personalizado) ofrecen la mejor combinación de velocidad, calidad de datos y flexibilidad.
Si estás listo para llevar tu web scraping al siguiente nivel, prueba ambas herramientas: experimenta con un script sencillo de BeautifulSoup y luego comprueba cuánto más rápido puedes avanzar con el raspador web con IA de Thunderbit. Y para más guías prácticas, visita el Thunderbit Blog.
¡Feliz scraping y que tus datos estén siempre limpios, estructurados y listos para la acción!
Prueba Thunderbit AI Web Scraper Get Started Free
Preguntas frecuentes
1. ¿Qué es BeautifulSoup y para qué se usa?
BeautifulSoup es una biblioteca de Python para analizar documentos HTML y XML. Te ayuda a extraer datos de páginas web y convertirlos en formatos estructurados como listas o tablas, lo que la hace ideal para proyectos de web scraping.
2. ¿Cómo se compara BeautifulSoup con Selenium y Scrapy?
BeautifulSoup es ligera y fácil de usar para páginas HTML estáticas. Selenium es mejor para extraer datos de sitios dinámicos y con mucho JavaScript, mientras que Scrapy es un framework completo para scraping asíncrono a gran escala. BeautifulSoup es la mejor opción para principiantes y tareas rápidas.
3. ¿Puedo usar BeautifulSoup y Thunderbit juntos?
Por supuesto. Thunderbit puede identificar y extraer rápidamente campos de páginas web usando IA, y puedes usar BeautifulSoup para el postprocesado personalizado o un análisis más profundo de los datos exportados.
4. ¿Cuáles son los retos comunes del web scraping con BeautifulSoup?
Los problemas más comunes incluyen manejar contenido dinámico, lidiar con medidas anti-bot y adaptarse a cambios en la estructura HTML. Usar las funciones de IA de Thunderbit o el modo navegador puede ayudar a superar muchos de estos retos.
5. ¿Cómo exporto a Excel o CSV los datos extraídos con BeautifulSoup?
Puedes usar el módulo csv integrado de Python o la biblioteca pandas para escribir los datos extraídos en archivos CSV o Excel. Usa siempre codificación UTF-8 para manejar caracteres especiales y garantizar la compatibilidad con las herramientas de hoja de cálculo.
¿Listo para probarlo tú mismo? Descarga la extensión de Chrome de Thunderbit y empieza a hacer scraping de forma más inteligente hoy mismo. Para más tutoriales y consejos, visita el Thunderbit Blog.
Más información




