

En 2026, los datos web ya no son solo un “extra interesante”: son la base de la estrategia empresarial. Desde gigantes del comercio electrónico que vigilan en tiempo real los precios de la competencia hasta equipos de ventas que alimentan su pipeline con leads nuevos, las empresas tratan los datos públicos de la web como si fueran petróleo digital. Los números lo respaldan: casi el 65 % de las empresas ya usa herramientas de web scraping o extracción de datos, y más del 70 % de los negocios digitales depende de datos públicos de la web para obtener inteligencia de mercado. Y aunque Python se lleve buena parte del protagonismo, Java sigue siendo el caballo de batalla que impulsa proyectos de scraping a gran escala y de misión crítica, sobre todo en entornos empresariales donde la fiabilidad y la integración pesan más.
 Después de años trabajando en SaaS y automatización, he visto de primera mano cómo el web scraping con Java puede cambiar por completo las operaciones de una empresa. Pero también he visto equipos atascados: unos perdidos en las entrañas de código de bajo nivel, otros desbordados por sitios dinámicos y bloqueos anti-bot. Por eso me hace ilusión compartir una guía práctica, paso a paso, para dominar el web scraping con Java en 2026, con un enfoque especial en combinar código con herramientas modernas impulsadas por IA como Thunderbit. Tanto si eres desarrollador, responsable de operaciones o usuario de negocio que solo quiere datos sin complicaciones, esta guía es para ti.
Después de años trabajando en SaaS y automatización, he visto de primera mano cómo el web scraping con Java puede cambiar por completo las operaciones de una empresa. Pero también he visto equipos atascados: unos perdidos en las entrañas de código de bajo nivel, otros desbordados por sitios dinámicos y bloqueos anti-bot. Por eso me hace ilusión compartir una guía práctica, paso a paso, para dominar el web scraping con Java en 2026, con un enfoque especial en combinar código con herramientas modernas impulsadas por IA como Thunderbit. Tanto si eres desarrollador, responsable de operaciones o usuario de negocio que solo quiere datos sin complicaciones, esta guía es para ti.
¿Qué es el web scraping con Java? Una explicación sin tecnicismos
Aclaremos la jerga: el web scraping con Java no es más que usar código Java para extraer información de sitios web de forma automática. Imagínate contratar a un becario virtual ultrarrápido capaz de leer miles de páginas web y copiar ordenadamente los datos que necesitas en una hoja de cálculo; solo que este becario nunca se cansa, no comete erratas y trabaja a la velocidad de tu conexión a internet.
En la práctica, funciona así:
- Enviar una solicitud a un sitio web (como abrir una página en tu navegador).
- Descargar el contenido HTML (el código bruto que forma la página).
- Analizar ese HTML para convertirlo en una estructura que tu programa pueda entender.
- Extraer los datos concretos que te interesan (como nombres de productos, precios o correos electrónicos).
- Guardar los resultados en un formato útil: CSV, Excel, una base de datos o incluso Google Sheets.
No hace falta ser un desarrollador experto para entender lo básico. Con las herramientas adecuadas y un poco de guía, incluso los usuarios de negocio pueden automatizar la recopilación de datos y convertir páginas web desordenadas en información útil y accionable.
Por qué el web scraping con Java importa para las empresas en 2026
El web scraping no es solo un proyecto secundario para perfiles técnicos: es una necesidad empresarial. Veamos cómo las empresas están usando el web scraping con Java para adelantarse y por qué genera un ROI real.
| Caso de uso de web scraping | Beneficios para el negocio (ROI) | Sectores de ejemplo |
|---|---|---|
| Seguimiento de precios de la competencia | Inteligencia de precios en tiempo real; aumentos de ventas del 20 % o más al reaccionar más rápido a los cambios del mercado | Comercio electrónico, Retail |
| Generación de leads e inteligencia comercial | Listas de prospectos automatizadas y siempre actualizadas; 70 % menos de tiempo en investigación manual | Ventas B2B, Marketing, Reclutamiento |
| Investigación de mercado y análisis de tendencias | Detección temprana de tendencias; 5–15 % más de ingresos y 10–20 % más de ROI de marketing | Productos de consumo, Agencias de marketing |
| Datos financieros y de inversión | Datos alternativos para trading; mercado de más de 5.000 millones de dólares para el “alt-data” extraído de la web | Finanzas, Hedge funds, Fintech |
| Automatización de flujos de trabajo y monitoreo | Recopilación rutinaria de datos automatizada; 73 % de ahorro de costes y 85 % de despliegue más rápido | Bienes raíces, Cadena de suministro, Gobierno |
(Fuente)
¿Por qué Java? Porque está pensado para escalar, ser fiable e integrarse bien. Muchos pipelines de datos empresariales ya funcionan con Java, así que conectar un Raspador Web es una extensión natural. Además, el multihilo y el manejo de errores de Java lo hacen ideal para trabajos grandes: piensa en extraer miles de páginas al día, no solo unas pocas.
¿Cómo funciona el web scraping con Java? Principios básicos y ventajas únicas
Desglosemos las piezas de un Raspador Web típico en Java:
- Solicitudes HTTP: Java usa bibliotecas como JSoup o Apache HttpClient para obtener páginas web. Puedes definir encabezados, usar proxies y simular navegadores reales para evitar bloqueos.
- Análisis de HTML: Bibliotecas como JSoup convierten el HTML bruto en un “DOM” (una estructura en forma de árbol), lo que facilita encontrar los datos que buscas con selectores CSS.
- Extracción de datos: Defines reglas (como “extrae todos los elementos
<span class='price'>”) para sacar la información que necesitas. - Almacenamiento de datos: Guarda los resultados en CSV, Excel, JSON o una base de datos.
¿Qué hace especial a Java para el web scraping?
- Multihilo: Java puede obtener y procesar muchas páginas en paralelo, acelerando de forma drástica los rastreos grandes. El GIL de Python puede ser un cuello de botella aquí, pero los hilos de Java funcionan de verdad y con rapidez.
- Rendimiento: La naturaleza compilada de Java hace que gestione trabajos grandes y tareas intensivas en memoria con facilidad.
- Integración empresarial: Los raspadores en Java pueden conectarse directamente con sistemas existentes —CRM, ERP, bases de datos— sin soluciones rebuscadas.
- Manejo de errores: El tipado estricto y las excepciones de Java hacen que los raspadores sean más robustos y fáciles de mantener en proyectos a largo plazo.
Si estás ejecutando un pipeline de datos de misión crítica, la estabilidad y escalabilidad de Java son difíciles de superar.
Bibliotecas y frameworks esenciales de web scraping en Java: qué elegir y por qué
No faltan bibliotecas de Java para web scraping, pero tres destacan para la mayoría de las necesidades empresariales: JSoup, HtmlUnit y Selenium. Así se comparan:
| Biblioteca | ¿Maneja JavaScript? | Facilidad de uso | Rendimiento | Ideal para |
|---|---|---|---|---|
| JSoup | ❌ (sin JS) | Muy fácil | Alto | Páginas estáticas, tareas rápidas, trabajos ligeros |
| HtmlUnit | ⚠️ Parcial | Moderada | Medio | JS simple, envío de formularios, scraping sin interfaz |
| Selenium | ✅ Sí (completo) | Moderada/difícil | Más bajo (por página) | Sitios con mucho JS, páginas interactivas o dinámicas |
JSoup: la opción preferida para analizar HTML sencillo
JSoup es mi punto de partida para la mayoría de trabajos de scraping. Es ligero, fácil de usar y perfecto para páginas estáticas en las que los datos ya están en el HTML.
Ejemplo:
Document doc = Jsoup.connect("https://www.scrapingcourse.com/ecommerce/").get();
String bannerTitle = doc.select("div.site-title").text();
System.out.println("Banner: " + bannerTitle);
Así de simple. Si vas a extraer entradas de blog, listados de productos o directorios que no dependen de JavaScript, JSoup es tu aliado.
HtmlUnit: simular navegadores para tareas más complejas
HtmlUnit es un navegador sin interfaz escrito en Java. Puede manejar algo de JavaScript, rellenar formularios y hacer clic en botones, todo sin abrir una ventana real del navegador.
Cuándo usarlo: si necesitas iniciar sesión en un sitio o trabajar con contenido dinámico básico, pero no quieres la sobrecarga de Selenium.
Ejemplo:
WebClient webClient = new WebClient();
HtmlPage page = webClient.getPage("https://example.com/login");
// ... rellenar el formulario y enviarlo ...
Selenium: para páginas con mucho JavaScript e interactivas
Selenium es el peso pesado. Controla un navegador real (como Chrome o Firefox), así que puede manejar cualquier sitio que pueda manejar una persona, incluidos los que están construidos por completo en JavaScript.
Cuándo usarlo: para extraer datos de aplicaciones web modernas, sitios con scroll infinito o cualquier cosa que requiera hacer clic, esperar o interactuar como un usuario.
Ejemplo:
WebDriver driver = new ChromeDriver();
driver.get("https://www.scrapingcourse.com/ecommerce/");
List<WebElement> products = driver.findElements(By.cssSelector("li.product"));
// ... extraer datos ...
driver.quit();
Potencia el web scraping con Java con Thunderbit: automatización visual y código
Extrae datos de cualquier sitio web usando IA Get Started Free
Aquí es donde la cosa se pone realmente interesante, sobre todo para usuarios de negocio y equipos que no quieren vivir pegados al código. Thunderbit es un Raspador Web sin código impulsado por IA que te permite definir tareas de scraping de forma visual —directamente en tu navegador— y luego exportar los datos a Excel, Google Sheets, Airtable o Notion.
¿Por qué usar Thunderbit con Java?
- Campos sugeridos por IA: la función “AI Suggest Fields” de Thunderbit lee la página y te recomienda exactamente qué extraer, sin necesidad de rebuscar en el HTML ni escribir selectores.
- Scraping de subpáginas: ¿Necesitas más detalles? Thunderbit puede visitar automáticamente cada subpágina (como páginas de detalle de productos) y enriquecer tu conjunto de datos.
- Plantillas instantáneas: para sitios populares (Amazon, Zillow, LinkedIn), Thunderbit ofrece plantillas con un clic, sin configuración.
- Exportación sencilla: una vez extraídos, exporta tus datos en segundos, listos para que tu código Java los procese, analice o integre.
Thunderbit ahorra muchísimo tiempo en la fase de prototipado, para manejar sitios complicados o para dar autonomía a personas sin perfil técnico que necesitan los datos. Y para desarrolladores, es una forma fantástica de descargar las partes repetitivas o frágiles del scraping y centrarse en la lógica de negocio.
Combinar Thunderbit y Java para proyectos complejos
Este es un flujo de trabajo que me encanta:
- Prototipa con Thunderbit: usa la extensión de Chrome para configurar visualmente tu scraping. Deja que la IA sugiera campos, gestione la paginación y exporte los datos a Google Sheets o CSV.
- Procesa en Java: escribe código Java para leer los datos exportados (desde Sheets, CSV o Airtable) y luego realiza cualquier postprocesado, análisis o integración con tus sistemas empresariales.
- Automatiza y programa: usa el programador integrado de Thunderbit para mantener los datos actualizados y deja que tu pipeline de Java recoja automáticamente las últimas exportaciones.
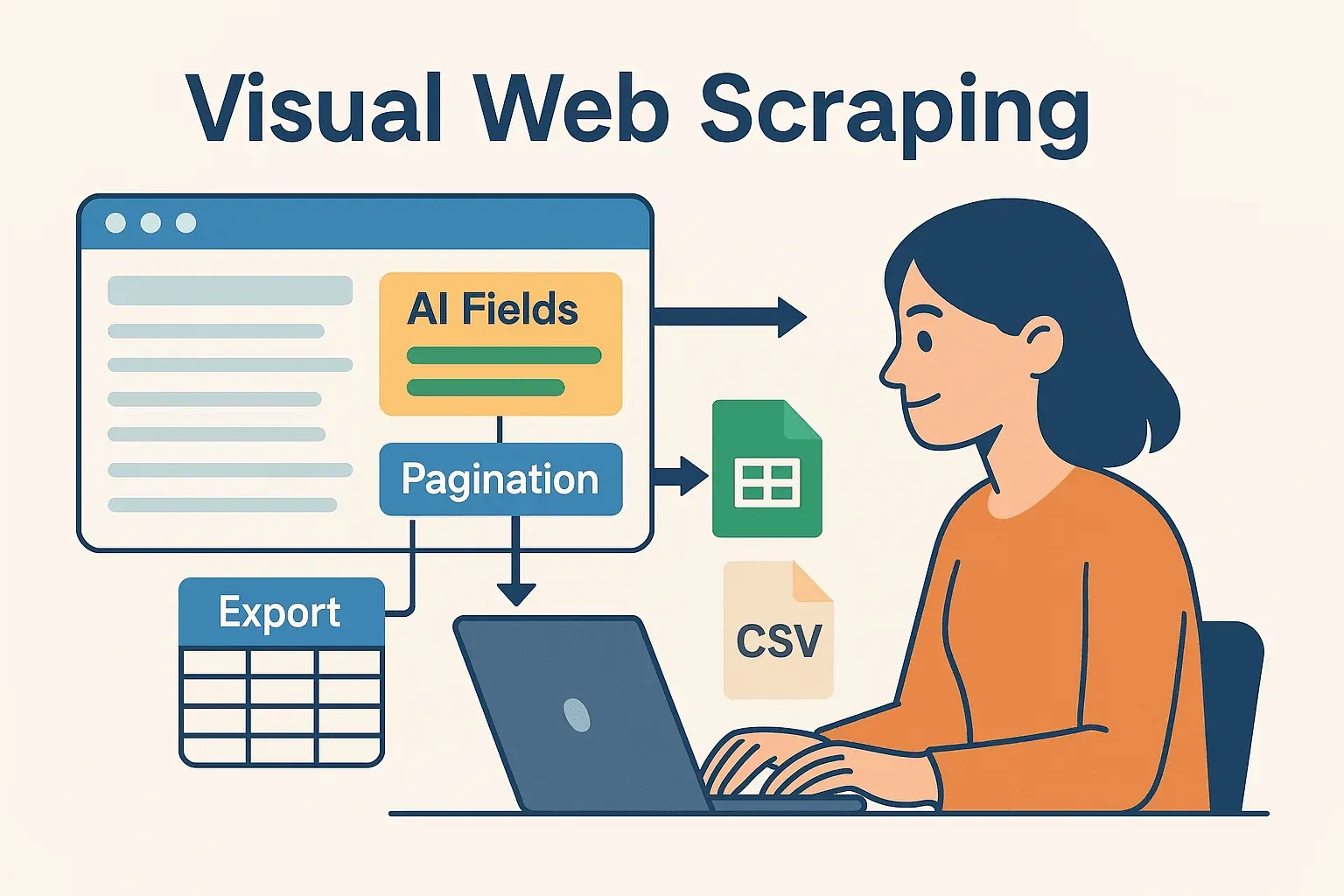 Este enfoque híbrido te da lo mejor de ambos mundos: la velocidad y flexibilidad del scraping sin código impulsado por IA, más la potencia y fiabilidad de Java para el procesamiento posterior.
Este enfoque híbrido te da lo mejor de ambos mundos: la velocidad y flexibilidad del scraping sin código impulsado por IA, más la potencia y fiabilidad de Java para el procesamiento posterior.
Prueba gratis la extensión de Chrome de Thunderbit
Guía paso a paso: crea tu primer Raspador Web en Java
Vamos a ponernos prácticos. Así puedes construir desde cero un Raspador Web sencillo en Java.
Configurar tu entorno Java
- Instala Java (JDK): usa Java 21 o 25 para contar con soporte LTS actual. Las actualizaciones gratuitas de Oracle para Java 17 terminaron en septiembre de 2024 y las de Java 21 están previstas para terminar en septiembre de 2026, así que los proyectos nuevos que empiecen en 2026 deberían apuntar a Java 25 (publicado en septiembre de 2025, LTS hasta 2033), salvo que dependas de una base de código existente en Java 21.
- Configura Maven: se encarga de las dependencias por ti.
- Elige un IDE: IntelliJ IDEA, Eclipse o VSCode funcionan muy bien.
- Añade JSoup a tu
pom.xml:<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.22.2</version> </dependency>
Escribir y ejecutar tu raspador
Vamos a extraer nombres y precios de productos de un sitio e-commerce de demostración.
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
public class ProductScraper {
public static void main(String[] args) {
String url = "https://www.scrapingcourse.com/ecommerce/";
try {
Document doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0")
.get();
Elements productElements = doc.select("li.product");
for (Element productEl : productElements) {
String name = productEl.selectFirst("h2").text();
String price = productEl.selectFirst("span.price").text();
System.out.println(name + " -> " + price);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
Consejo profesional: establece siempre un user-agent para simular un navegador real. Algunos sitios bloquean el user-agent predeterminado de Java.
Exportar y usar tus datos
- Exportación a CSV: usa
FileWritero una biblioteca como OpenCSV para escribir los resultados en un archivo CSV. - Exportación a Excel: usa Apache POI para archivos .xls/.xlsx.
- Integración con bases de datos: usa JDBC para insertar los datos directamente en tu base de datos.
- Google Sheets: exporta desde Thunderbit y léelo con la API de Google Sheets de Java.
Cómo superar los desafíos más comunes del web scraping con Java
El web scraping no es todo color de rosa. Estos son los dolores de cabeza más habituales y cómo resolverlos:
- Bloqueo de IP y limitación de velocidad: ralentiza tus solicitudes (
Thread.sleep()), rota proxies y aleatoriza los retrasos. Para trabajos de alto volumen, usa servicios de proxies. - CAPTCHAs y detección de bots: usa Selenium para imitar el comportamiento de un usuario real o recurre a APIs anti-bot. A veces, el scraping en la nube de Thunderbit puede sortear estos obstáculos.
- Contenido dinámico: si JSoup devuelve resultados vacíos, es probable que los datos se carguen mediante JavaScript. Cambia a Selenium o HtmlUnit, o localiza la API subyacente del sitio.
- Cambios en la estructura del sitio: escribe código mantenible con selectores flexibles. Supervisa tus raspadores y prepárate para actualizarlos cuando el sitio cambie. Con Thunderbit, los cambios de diseño normalmente significan volver a ejecutar “AI Suggest Fields” en lugar de editar XPath a mano; sigue siendo un paso manual, pero mucho más barato que rehacer selectores desde cero.
- Gestión de sesiones: para scraping con inicio de sesión, administra cookies y sesiones con cuidado. Selenium y Thunderbit (cuando estás conectado en Chrome) pueden trabajar con páginas autenticadas.
Consejos avanzados para mejorar la eficiencia del web scraping con Java
Aprende más sobre la extracción de datos con IA Get Started Free
¿Listo para subir de nivel? Aquí van algunas tácticas profesionales:
- Multihilo: usa
ExecutorServicede Java para extraer varias páginas en paralelo. Solo no te pases y termines bloqueado. - Programación: usa Quartz Scheduler en Java, o deja que Thunderbit gestione la programación en la nube con lenguaje natural (“todos los lunes a las 9:00”).
- Escalado en la nube: para trabajos masivos, ejecuta navegadores sin interfaz en la nube o distribuye tareas entre varias máquinas.
- Flujos híbridos: usa Thunderbit para los sitios difíciles y de alto mantenimiento, y código Java para el resto. Combina los resultados en tu data warehouse.
- Monitoreo y registro: usa los frameworks de logging de Java para supervisar el estado del raspador, detectar errores pronto y activar alertas si algo falla.
Conclusión y puntos clave
Los datos web son el nuevo oro, y Java sigue siendo una de las mejores palas y picos del negocio, sobre todo para equipos que necesitan fiabilidad, escala e integración. El flujo básico es sencillo: obtener, analizar, extraer y exportar. Con bibliotecas como JSoup, HtmlUnit y Selenium, puedes abarcar desde directorios básicos hasta los sitios más rebeldes y cargados de JavaScript.
Pero no tienes por qué hacerlo todo a mano. Herramientas como Thunderbit aportan IA y automatización visual al proceso, permitiéndote prototipar, adaptarte y escalar tus proyectos de scraping más rápido que nunca. ¿Mi consejo? No tengas miedo de combinar código y no-code. Usa Thunderbit para una configuración y un mantenimiento rápidos, y deja que tu pipeline de Java haga el trabajo pesado.
¿Quieres ver cómo Thunderbit puede potenciar tu flujo de trabajo? Descarga la extensión de Chrome y prueba a extraer tu primer sitio en cuestión de minutos. Y si quieres más, consulta el Blog de Thunderbit para análisis en profundidad, tutoriales y lo último en automatización de web scraping.
Prueba Thunderbit AI Web Scraper
¡Feliz scraping y que tus datos estén siempre estructurados, frescos y listos para actuar!
Preguntas frecuentes
1. ¿Sigue siendo Java relevante para el web scraping en 2026?
Sí. Aunque Python es popular para scripts rápidos, Java sigue siendo una opción muy común para pipelines de scraping empresariales y de larga duración, especialmente cuando los servicios existentes ya se ejecutan sobre la JVM y se benefician del multihilo real y del ecosistema consolidado de Maven, logging y JDBC.
2. ¿Cuándo debería usar JSoup, HtmlUnit o Selenium?
Usa JSoup para páginas estáticas, HtmlUnit para contenido dinámico sencillo o envío de formularios, y Selenium para sitios con mucho JavaScript o interactivos. Elige la herramienta que mejor se adapte a la complejidad del sitio.
3. ¿Cómo puedo evitar que me bloqueen mientras hago scraping?
Reduce la frecuencia de las solicitudes, usa proxies rotativos, configura user-agents realistas e imita el comportamiento humano. Para sitios difíciles, considera usar el scraping en la nube de Thunderbit o APIs anti-bot.
4. ¿Pueden Thunderbit y Java trabajar juntos?
Sin duda. Usa Thunderbit para definir visualmente y programar los scrapes, exportar los datos y luego procesarlos o integrarlos con tu código Java. Es una combinación potente tanto para usuarios de negocio como para desarrolladores.
5. ¿Cuál es la forma más rápida de empezar con el web scraping en Java?
Configura Java y Maven, añade JSoup y prueba a extraer datos de un sitio sencillo. Para trabajos más complejos o para prototipado rápido, instala Thunderbit y deja que la IA haga el trabajo pesado; luego conecta los resultados con tu flujo de trabajo en Java.
¿Quieres más consejos, ejemplos de código o trucos de automatización? Sumérgete en el Blog de Thunderbit o suscríbete a nuestro canal de YouTube para ver tutoriales prácticos y lo último en tecnología de web scraping. Más información
- Los 15 mejores raspadores de páginas web que deberías conocer en 2025
- Cómo hacer web scraping: guía completa para principiantes
- Las 12 mejores herramientas gratuitas de extracción de datos en 2025
Prueba AI Web Scraper para proyectos en Java Get Started Free




