

Si alguna vez has intentado sacar de un sitio web justo los datos que necesitas —tal vez una lista de precios de la competencia, un catálogo de productos o un lote reciente de leads de ventas—, seguro que conoces esa sensación: las herramientas de scraping estándar te llevan el 80% del camino, pero ese último 20%... ahí es donde aparece la magia (y la frustración). En el mundo actual, impulsado por los datos, las empresas no pueden conformarse con un “casi”. Los servicios de extracción personalizada y de extracción de datos se han convertido en la columna vertebral de las operaciones modernas, y se prevé que el mercado global de web scraping pase de **754 millones de dólares en 2024 a 2.870 millones de dólares en 2034**. Los equipos cuya estrategia de datos sigue dependiendo de un scraping estándar, de una sola plantilla para todo, se están perdiendo la información más valiosa.
He pasado años ayudando a equipos —desde startups con pocos recursos hasta empresas consolidadas— a dejar atrás las maratones de copiar y pegar y las herramientas frágiles y genéricas. ¿La diferencia? Dominar la extracción personalizada de datos. En esta guía, te explicaré qué significa realmente la extracción personalizada, por qué es esencial, cómo Thunderbit (el AI web scraper que mi equipo y yo construimos) la hace radicalmente simple, y cómo elegir el servicio de extracción de datos adecuado para tu negocio. Incluso compartiré un par de historias de guerra, porque, seamos sinceros, todo friki de los datos tiene unas cuantas.
¿Qué es la extracción personalizada? Descubre el poder de los servicios de extracción de datos a medida
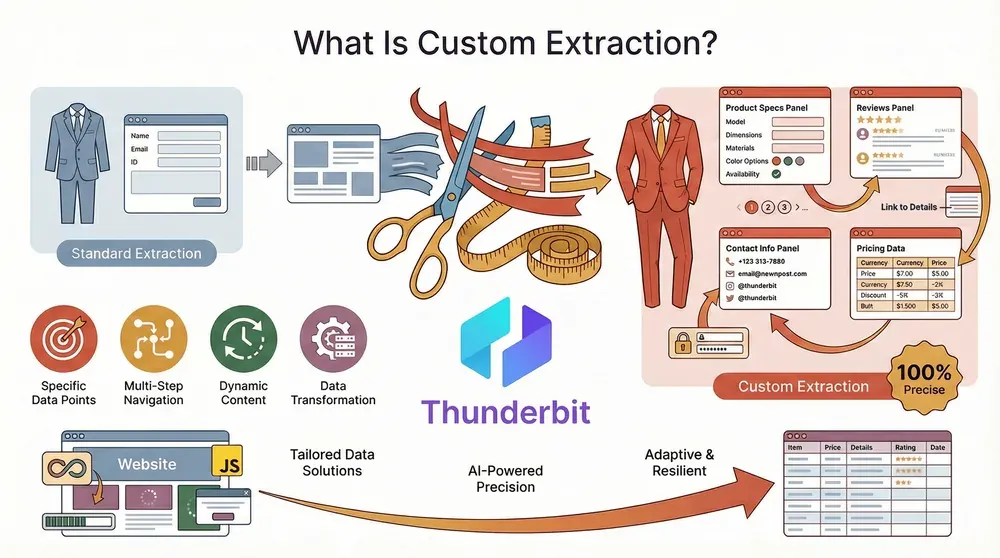 Empecemos por lo básico: la extracción personalizada consiste en obtener exactamente los datos que necesitas, en el formato que quieres, desde los sitios web que importan para tu negocio. A diferencia de las herramientas de scraping estándar, que capturan lo que resulta fácil o visible, la extracción personalizada de datos es precisa, adaptable y resistente, incluso cuando los sitios son complejos, dinámicos o cambian de diseño cada dos semanas.
Empecemos por lo básico: la extracción personalizada consiste en obtener exactamente los datos que necesitas, en el formato que quieres, desde los sitios web que importan para tu negocio. A diferencia de las herramientas de scraping estándar, que capturan lo que resulta fácil o visible, la extracción personalizada de datos es precisa, adaptable y resistente, incluso cuando los sitios son complejos, dinámicos o cambian de diseño cada dos semanas.
Piensa en ello como encargar un traje a medida en lugar de comprar uno estándar. Con la extracción personalizada, no estás limitado a los campos o plantillas “predeterminados”. Puedes:
- Elegir puntos de datos específicos (como especificaciones de producto, reseñas o información de contacto)
- Gestionar navegación en varios pasos (paginación, subpáginas, inicios de sesión)
- Adaptarte a contenido dinámico (scroll infinito, datos cargados por JavaScript)
- Dar formato, limpiar o transformar los datos mientras los extraes
¿Por qué importa esto? Porque las necesidades reales de negocio rara vez son simples. Quizá necesites extraer listados de productos y luego seguir cada enlace para obtener especificaciones detalladas y reseñas. O tal vez quieras vigilar los precios de la competencia en decenas de páginas, pero solo para ciertos SKU. Las herramientas estándar se rompen, pierden datos o te obligan a convertirte en un detective aficionado de HTML. En cambio, los servicios de extracción personalizada están diseñados para manejar estos escenarios, a menudo con la ayuda de la IA y el procesamiento del lenguaje natural.
Si quieres profundizar en la diferencia entre el scraping personalizado y el estándar, consulta De los clics a las columnas: entender la extracción personalizada de datos.
Por qué los servicios de extracción personalizada de datos son importantes para el crecimiento del negocio
Vamos a lo práctico. ¿Por qué debería importarte la extracción personalizada de datos? Porque no es solo una mejora tecnológica: es un acelerador de negocio. Así es como los servicios de extracción personalizada impulsan resultados reales:
| Necesidad de negocio | Solución de scraping de datos personalizada | Resultado típico |
|---|---|---|
| Generación de leads | Extraer contactos actualizados de directorios, LinkedIn o sitios de reseñas | Mucha menos investigación manual; listas de leads más grandes y mejor cualificadas |
| Seguimiento de precios de la competencia | Rastrear precios y stock en sitios rivales, incluso con diseños dinámicos | Reacción más rápida a los movimientos de la competencia; mejora real del margen al aplicar precios dinámicos |
| Inteligencia de mercado e investigación | Agregar noticias, reseñas o registros regulatorios a gran escala | Mayor cobertura de datos entre equipos; decisiones más rápidas y mejor informadas |
| Actualización de catálogos de productos | Extraer información de productos de varias fuentes, gestionar subpáginas y variantes | Catálogos siempre actualizados; menos errores y menos actualizaciones manuales |
| Automatización operativa | Programar scraping recurrente para informes, cumplimiento o inventario | Un 85% más rápido el time-to-market para nuevas fuentes de datos; un 73% menos coste de recopilación frente a enfoques con mucho desarrollo |
(ScrapeGraphAI: Economics of Web Scraping, abr. 2026)
En resumen: la extracción personalizada no es un lujo, es una necesidad competitiva. Las empresas que la dominan superan a sus rivales, reaccionan más rápido a los cambios del mercado y descubren insights que impulsan el crecimiento.
El enfoque de Thunderbit: extracción personalizada de datos hecha simple
Extrae datos de cualquier sitio web usando IA Get Started Free
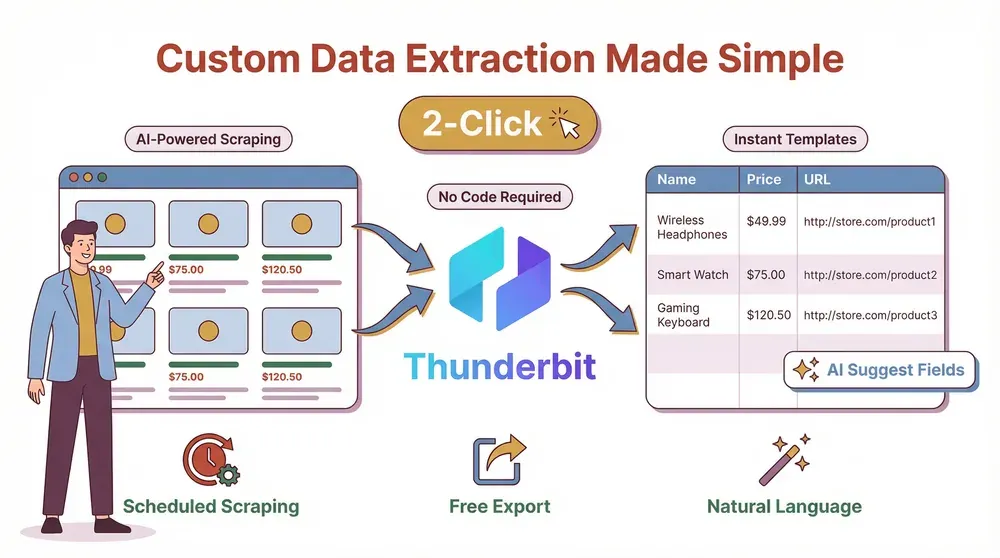
Ahora, te seré sincero: construí Thunderbit porque estaba cansado de ver a los equipos pelearse con scrapers torpes y llenos de código que se rompían cada vez que un sitio web estornudaba. Thunderbit es una extensión de Chrome con AI web scraper diseñada para que la extracción personalizada de datos sea accesible para todos, no solo para desarrolladores.
Esto es lo que hace diferente a Thunderbit:
- Sugerencias de campos impulsadas por IA: Haz clic en “Sugerir campos con IA” y Thunderbit analizará la página, recomendando las mejores columnas para extraer, como “Nombre del producto”, “Precio”, “URL de imagen” o “Email”. Se acabó adivinar o pelearte con selectores.
- Indicaciones en lenguaje natural: ¿Quieres extraer una fecha, traducir una descripción o categorizar elementos? Solo díselo a Thunderbit en español sencillo. La IA se encarga del resto.
- Scraping en 2 clics: Entra en el sitio que te interesa, abre Thunderbit y pulsa “Scrapear”. Y ya está. Sin código, sin plantillas (salvo que quieras usarlas), sin dolores de cabeza.
- Gestiona páginas complejas: Thunderbit puede con la paginación, el scroll infinito, las subpáginas e incluso contenido dinámico cargado por JavaScript. Se adapta a medida que cambian los sitios.
- Scraping de subpáginas: ¿Necesitas más detalles de cada elemento? Thunderbit puede visitar automáticamente cada subpágina (como las fichas de producto) y enriquecer tu tabla.
- Scraping programado: Configura extracciones recurrentes con lenguaje natural (“todos los lunes a las 9:00”) y deja que Thunderbit haga el resto.
- Plantillas instantáneas: Para sitios populares como Amazon, Zillow o LinkedIn, Thunderbit ofrece plantillas de 1 clic, sin configuración.
- Exportación gratuita de datos: Exporta tus datos a Excel, Google Sheets, Airtable, Notion, CSV o JSON, sin muros de pago ni límites.
La misión de Thunderbit es simple: que los usuarios de negocio describan lo que quieren y que la IA se encargue del trabajo técnico pesado. Es como tener un asistente de investigación con IA que nunca se cansa ni se queja por el café.
Paso a paso: usar Thunderbit para el scraping personalizado de datos
Veamos un flujo de trabajo real de extracción personalizada con Thunderbit. Usaré el ejemplo de un catálogo de productos, pero los pasos son similares para leads, reseñas o cualquier otra cosa.
Paso 1: instala Thunderbit
Ve a la página de la extensión de Chrome de Thunderbit y añádela a tu navegador. Crea una cuenta gratuita; no necesitas tarjeta de crédito para el plan gratis.
Paso 2: abre el sitio web objetivo
Navega a la página que quieres scrapear (por ejemplo, una página de categoría con listados de productos).
Paso 3: inicia Thunderbit y usa Sugerir campos con IA
Haz clic en el icono de Thunderbit. Pulsa “Sugerir campos con IA”: la IA de Thunderbit analizará la página y propondrá columnas como “Nombre del producto”, “Precio”, “URL de imagen”, etc. Puedes cambiar el nombre de los campos, añadirlos o eliminarlos según necesites.
Paso 4: personaliza con indicaciones de IA por campo
¿Quieres extraer algo concreto? Para cada campo, puedes añadir una instrucción personalizada, como “extrae la fecha en formato AAAA-MM-DD” o “traduce la descripción al español”. La IA de Thunderbit aplicará tu regla durante la extracción.
Paso 5: activa la paginación o el scraping de subpáginas (si hace falta)
Si tus datos abarcan varias páginas, activa la paginación. Si necesitas detalles de subpáginas (como páginas de producto), usa el scraping de subpáginas: Thunderbit visitará cada enlace y añadirá información extra a tu tabla.
Paso 6: haz clic en “Scrapear” y mira cómo fluyen los datos
Thunderbit extraerá tus datos y gestionará automáticamente la navegación y el formato. Verás una tabla de vista previa mientras trabaja.
Paso 7: exporta tus datos
Cuando estés satisfecho con el resultado, exporta directamente a Google Sheets, Excel, Airtable o Notion. También puedes descargarlos como CSV o JSON.
Cómo extraer datos de un sitio web a Excel usando IA Get Started Free
Eso es todo. Sin código, sin plantillas (salvo que quieras usarlas) y sin esos momentos de “¿por qué esto no funciona?”. Para más detalles, consulta la documentación de Thunderbit.
Comparación de Thunderbit con otros servicios de extracción de datos
Pongámonos frikis por un momento. ¿Cómo se compara Thunderbit con otros servicios de extracción de datos como Azure AI Document Intelligence o los scrapers tradicionales?
| Función / criterio | Thunderbit | Azure AI Document Intelligence | Scrapers tradicionales (p. ej., Octoparse, Scrapy) |
|---|---|---|---|
| Facilidad de uso | Sin código, impulsado por IA, configuración en 2 clics | Orientado a desarrolladores, basado en API | Curva de aprendizaje pronunciada, a menudo requiere código |
| Extracción personalizada | Indicaciones en lenguaje natural, IA por campo | Modelos de ML personalizados para documentos | Configuración manual, selectores, scripts |
| Gestiona páginas web | Sí (HTML, dinámicas, subpáginas) | No (centrado en documentos/PDF) | Sí, pero sufre con sitios dinámicos |
| Gestiona documentos/PDF | Sí (mediante navegador/modo PDF) | Sí (OCR, ML) | A veces, pero de forma limitada |
| Adaptabilidad | La IA se adapta a los cambios de diseño | El ML se adapta a nuevos documentos | Se rompe cuando cambian los sitios y necesita actualizaciones |
| Programación | Integrada, en lenguaje natural | Vía API, necesita integración | A veces, pero complejo |
| Opciones de exportación | Sheets, Excel, Airtable, Notion, CSV, JSON | API/JSON, requiere integración de desarrollo | CSV, Excel, BD, varía |
| Soporte | SaaS moderno, respuesta rápida | Empresarial, soporte formal | Comunidad o proveedor, varía |
| Precio | Plan gratis, créditos de pago por uso | Basado en uso, enfoque empresarial | Gratis (código abierto) o planes mensuales |
El punto fuerte de Thunderbit es la extracción de datos web para usuarios de negocio que quieren potencia sin sufrimiento. Azure es fantástico para procesar documentos a gran escala, pero no para rastrear sitios web. Los scrapers tradicionales son potentes en las manos adecuadas, pero requieren conocimientos técnicos y mantenimiento constante.
Para una comparación más profunda, consulta De los clics a las columnas: entender la extracción personalizada de datos.
Cómo elegir el servicio de extracción personalizada de datos adecuado para tus necesidades
Elegir un servicio de extracción de datos no va solo de funciones: va de encaje. Aquí tienes una lista de verificación para ayudarte a decidir:
- Calidad y fiabilidad de los datos: ¿Entrega datos precisos, limpios y completos? ¿Puedes probarlo en tus sitios objetivo?
- Flexibilidad y personalización: ¿Puede con tus sitios específicos, contenido dinámico, inicios de sesión o subpáginas? ¿Puedes definir campos o transformaciones personalizadas?
- Cumplimiento y ética: ¿Sigue las directrices legales y éticas? ¿Respeta las leyes de privacidad y los términos del sitio?
- Escalabilidad y rendimiento: ¿Puede manejar tu volumen y frecuencia de datos? ¿Ofrece scraping en la nube o procesamiento paralelo?
- Integración y flujo de trabajo: ¿Puedes exportar los datos a tus herramientas (Sheets, Excel, CRM, etc.)? ¿Admite programación o automatización?
- Soporte y documentación: ¿Hay soporte ágil y documentación clara? ¿Existen tutoriales o una base de conocimientos?
- Seguridad: ¿Gestiona tus datos de forma segura? ¿La información de inicio de sesión está cifrada? ¿Tiene certificaciones de cumplimiento?
- Coste: ¿El precio es transparente y rentable para tus necesidades? ¿Hay cargos ocultos o muros de pago?
Prueba cada opción. Extrae datos de un sitio real, exporta la información y comprueba cómo encaja con tu flujo de trabajo. Para más consejos, consulta Cómo elegir el servicio de web scraping adecuado.
Prueba Thunderbit para la extracción personalizada de datos
Integrar el scraping personalizado de datos en los flujos de trabajo de tu negocio
Extraer datos es solo la mitad de la batalla: el verdadero valor llega cuando lo conviertes en parte de tus operaciones diarias. Así puedes integrar la extracción personalizada en tu negocio:
- Automatiza tareas recurrentes: Usa scraping programado para mantener tus datos al día: revisiones diarias de precios, actualizaciones semanales de leads, etc.
- Inyecta los datos en tus herramientas: Exporta directamente a Google Sheets, Airtable, Notion o Excel. Usa Zapier, Make o n8n para automatizar aún más, por ejemplo, enviar nuevos leads a tu CRM.
- Configura alertas: Integra Slack o email para recibir avisos sobre cambios importantes, como una bajada de precios de la competencia o el lanzamiento de un nuevo producto.
- Colabora en la nube: Usa bases de datos compartidas (Airtable, Notion) para que los datos extraídos estén disponibles entre equipos.
- Automatiza de extremo a extremo: Combina el scraping con herramientas de BI (Tableau, Power BI) para paneles en vivo, o activa acciones (como reajustes de precios) según los datos extraídos.
Para inspirarte, consulta Web Scraping con n8n: 8 potentes plantillas de flujo de trabajo.
Empieza la extracción personalizada de datos con Thunderbit
Mejores prácticas para maximizar el valor de los servicios de extracción personalizada de datos
¿Quieres sacar el máximo partido a tus esfuerzos de extracción personalizada? Esto es lo que he aprendido, a veces por las malas:
- Define objetivos claros: Ten claro qué datos necesitas y por qué. No hagas scraping solo porque sí: hazlo con un propósito.
- Empieza pequeño y prueba a menudo: Haz pilotos pequeños, revisa los datos y escala cuando tengas confianza.
- Vigila la calidad de los datos: Revisa resultados de forma periódica. Configura reglas de validación o alertas para anomalías.
- Optimiza la frecuencia: Extrae datos tan a menudo como haga falta, pero no más. Hacer scraping en exceso puede hacer que te bloqueen (y fastidiar a tu equipo de TI).
- Mantén la ética y el cumplimiento: Respeta los términos del sitio, las leyes de privacidad y las pautas éticas. No extraigas datos sensibles o restringidos.
- Aprovecha las indicaciones por campo: Usa prompts de IA para limpiar, dar formato o enriquecer los datos durante la extracción.
- Protege tus datos: Trata con cuidado las credenciales y los datos extraídos; usa cifrado y controles de acceso.
- Documenta tu proceso: Lleva un registro de qué extraes, de dónde y con qué frecuencia. Te ahorrará dolores de cabeza más adelante.
- Itera y mejora: Trata la extracción personalizada como un proceso en evolución. Ajusta tu enfoque a medida que cambien las necesidades.
Para más información sobre buenas prácticas, consulta De los clics a las columnas: entender la extracción personalizada de datos.
Conclusión y puntos clave: eleva tu estrategia de datos con la extracción personalizada
La extracción personalizada de datos y los servicios de scraping de datos no son solo para frikis de los datos: son herramientas imprescindibles para cualquier empresa que quiera moverse rápido, seguir siendo competitiva y tomar mejores decisiones. La era de copiar y pegar manualmente y de scripts frágiles ya quedó atrás. Con herramientas impulsadas por IA como Thunderbit, cualquiera puede dominar la extracción personalizada, sin necesidad de programar.
Quédate con esto:
- Extracción personalizada = extracción relevante. Consigue los datos correctos, no solo más datos.
- El valor de negocio está demostrado. Desde ventas hasta operaciones e investigación de mercado, el scraping personalizado aporta un ROI real.
- La facilidad de uso ya está aquí. Herramientas como Thunderbit democratizan la extracción de datos para todos.
- La integración lo es todo. Haz que los datos extraídos formen parte de tu flujo diario, no de un silo.
- Elige con criterio. Adapta la herramienta a tus necesidades: prueba, compara e itera.
- Las buenas prácticas ganan. Objetivos claros, controles de calidad y estándares éticos mantienen sólida tu estrategia de datos.
¿Listo para subir de nivel? Descarga Thunderbit y prueba un scraping personalizado con un problema real de negocio. O, si quieres profundizar aún más, visita el Blog de Thunderbit para encontrar análisis en profundidad, tutoriales y lo último en extracción de datos con IA.
La web es una mina de oro de insights: la extracción personalizada es tu pico. ¡Feliz scraping!
Prueba AI Web Scraper para la extracción personalizada de datos Get Started Free
FAQs
1. ¿Qué es la extracción personalizada de datos y en qué se diferencia del scraping estándar?
La extracción personalizada de datos consiste en adaptar tu scraping para obtener exactamente la información que necesitas, en el formato que quieres, desde cualquier sitio web, incluso si es complejo o dinámico. A diferencia de las herramientas estándar, que capturan lo que resulta fácil, la extracción personalizada se adapta a las necesidades de tu negocio y a los cambios en el diseño de los sitios.
2. ¿Quién se beneficia más de los servicios de extracción personalizada de datos?
Los equipos de ventas (para leads), marketing (para seguimiento de la competencia), operaciones (para automatización), product managers (para actualizar catálogos) e investigadores de mercado (para inteligencia) obtienen grandes beneficios de la extracción personalizada, especialmente cuando las herramientas estándar se quedan cortas.
3. ¿Cómo hace Thunderbit más fácil la extracción personalizada?
Thunderbit usa IA para sugerir campos, gestionar navegación compleja (paginación, subpáginas) y permitirte describir lo que quieres en lenguaje natural. Sin código, sin plantillas (salvo que quieras usarlas) y con exportación instantánea a tus herramientas favoritas.
4. ¿Qué debo buscar al elegir un servicio de extracción de datos?
Prioriza la calidad de los datos, la flexibilidad, el cumplimiento, la escalabilidad, las opciones de integración, el soporte, la seguridad y el coste. Prueba cada servicio con tus necesidades reales antes de comprometerte.
5. ¿Cómo puedo integrar el scraping personalizado de datos en los flujos de trabajo de mi negocio?
Automatiza tareas recurrentes, exporta datos a Sheets/Excel/Notion, configura alertas y usa herramientas de flujo de trabajo como Zapier o n8n. El objetivo: convertir los datos web en una parte viva de tus operaciones diarias, no en un proyecto aislado.
¿Listo para ver lo que la extracción personalizada puede hacer por tu negocio? Prueba Thunderbit gratis y empieza a convertir el caos de la web en claridad para el negocio.
Más información




