Un estudio basado en rastreo sobre cómo los sitios web de alto tráfico están publicando orientación legible por máquinas para los modelos de lenguaje grandes, cómo lucen las primeras implementaciones y por qué medir la adopción requiere algo más que contar respuestas HTTP 200.
- Dataset:
data/llms_probe_results_top_10000.csv - Lista Tranco descargada: 6 de mayo de 2026
- Alcance:
/llms.txty/llms-full.txten la raíz
Métricas clave
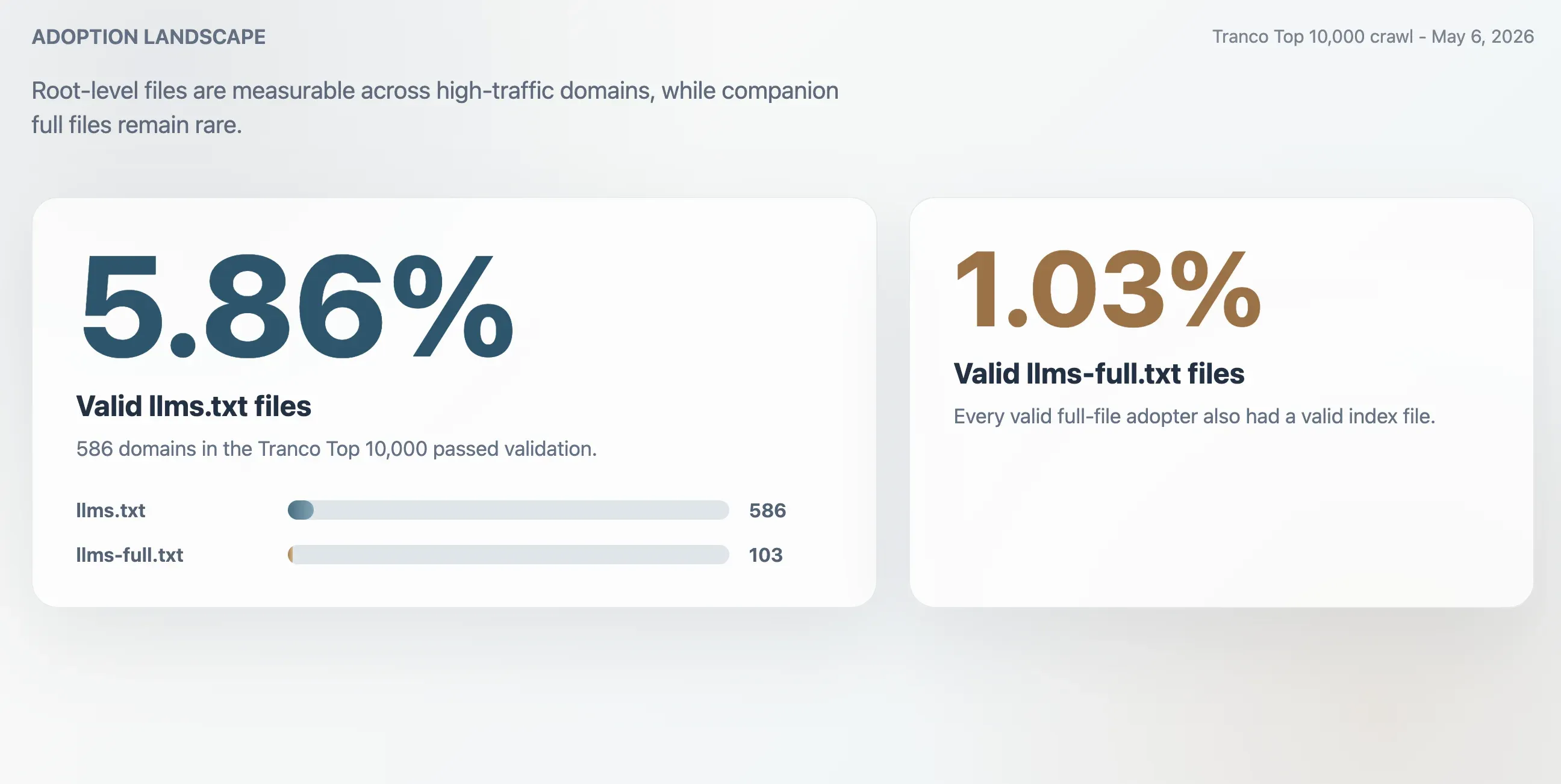
- 5,86%: adopción válida de
llms.txten el Top 10.000 de Tranco, equivalente a 586 dominios. - 1,03%: adopción válida de
llms-full.txt, equivalente a 103 dominios. Todos los adoptantes válidos del archivo completo también tenían un archivo índice válido. - 63,51%: proporción de respuestas HTTP 200 para
/llms.txtque no superaron la validación. - 2,74x: sobreconteo aproximado si la adopción se midiera solo por respuestas HTTP 200 en bruto.
Resumen ejecutivo
llms.txt sigue siendo una convención web temprana, pero ya no es un experimento marginal. En un rastreo del 6 de mayo de 2026 sobre los 10.000 dominios principales de Tranco, este estudio encontró 586 archivos llms.txt válidos, lo que supone una tasa de adopción observada del 5,86%. El archivo complementario llms-full.txt era mucho menos común: 103 dominios tenían un archivo completo válido, para una tasa de adopción del 1,03%.
El hallazgo metodológico más importante es que los códigos de estado son un mal proxy de la adopción. El rastreador observó 1.606 respuestas HTTP 200 para /llms.txt, pero solo 586 superaron la validación. Las 1.020 restantes eran en su mayoría redirecciones fuera de objetivo, páginas HTML genéricas, cuerpos vacíos u otras respuestas no válidas. Un rastreador ingenuo que contara cada respuesta 200 como adopción sobreestimaría la adopción válida en unas 2,74 veces.
Entre los adoptantes válidos, la calidad de implementación es superior a lo que sugeriría una simple narrativa de marcador de posición. El tamaño mediano del archivo válido era de unos 7,1 KB, el 61,77% de los archivos válidos superaba los 5 KB, el 70,82% contenía seis o más secciones Markdown y el 77,47% incluía 11 o más enlaces Markdown. El conjunto de primeros adoptantes incluye Cloudflare, Azure, GitHub, DigiCert, WordPress.org, Adobe, Dropbox, PayPal, Stripe, Salesforce, Slack, Zendesk, Okta, Datadog y Cloudinary.
llms.txtse entiende mejor como una señal explicativa y de navegación para sistemas de IA, no como sustituto derobots.txt. Su valor no es solo que exista el archivo, sino que ayude a las máquinas a encontrar información autorizada, compacta y actual.
Contexto: la web está añadiendo señales para la IA
Los sitios web llevan mucho tiempo usando robots.txt para expresar preferencias de rastreo, sitemap.xml para mejorar el descubrimiento de URLs y datos estructurados para ayudar a los buscadores y a las plataformas a interpretar las páginas. La IA generativa introduce un problema distinto. El contenido puede usarse para entrenamiento, recuperación, resumido, navegación con agentes, asistencia de código, atención al cliente y generación de respuestas. Eso crea dos necesidades simultáneas: los editores quieren más control sobre el uso automatizado, pero también quieren que los sistemas de IA encuentren la información canónica correcta cuando sí interactúan con sus sitios.
La , introducida por Jeremy Howard en 2024, presenta el archivo como un documento Markdown ubicado en la raíz de un sitio web para ofrecer información amigable para los LLM en tiempo de inferencia. La propuesta sostiene que las páginas HTML suelen incluir navegación, publicidad, scripts y otros elementos ruidosos que dificultan el procesamiento por parte de los modelos de lenguaje. Un archivo Markdown conciso puede orientar a los modelos hacia las páginas, documentación, APIs, ejemplos, políticas e información de producto más importantes.
La investigación externa sobre la web ofrece el contexto general. describe un aumento rápido de las restricciones relacionadas con la IA en robots.txt y en los términos de servicio, y sostiene que los mecanismos existentes de consentimiento web no fueron diseñados para la reutilización masiva de datos por IA. también ha hecho visibles los patrones de rastreadores de IA y robots.txt a nivel de los 10.000 dominios principales. En ese entorno, llms.txt se sitúa en el lado constructivo de la señalización a la IA: no “no rastrees esto”, sino “si necesitas entender este sitio, empieza aquí”.
Evidencia externa y el debate sobre la adopción
El debate público en torno a llms.txt se divide entre dos afirmaciones. La postura optimista es que el archivo ofrece a los sistemas de IA una ruta más limpia y eficiente hacia contenido autorizado. La postura escéptica es que ningún gran proveedor de LLM ha prometido públicamente usarlo como señal de ranking, rastreo o citación, por lo que los editores no deberían esperar beneficios de tráfico solo por tener el archivo. Las tres referencias externas revisadas para esta actualización apoyan una conclusión más matizada: llms.txt es una infraestructura útil, pero la evidencia de un impacto directo en el tráfico sigue siendo limitada y dependiente del contexto.
Los referentes externos de adopción avanzan rápido
informó una tasa de adopción del 0,3% entre los 1.000 sitios web principales al 22 de junio de 2025, es decir, 3 de cada 1.000 sitios. Describe un rastreo automatizado mensual de domain.com/llms.txt, con validación que excluye redirecciones y respuestas HTML. Esa metodología es direccionalmente similar al enfoque conservador de validación de este estudio.
La diferencia en los resultados es grande: este estudio encontró 75 archivos llms.txt válidos en el Top 1.000 de Tranco el 6 de mayo de 2026, es decir, un 7,50%. Esos dos números no deben tratarse como una serie temporal estricta porque la fuente del ranking, los detalles de implementación, la lógica de validación y el momento del rastreo pueden diferir. Aun así, el contraste sugiere que la adopción cambió de forma material entre mediados de 2025 y mayo de 2026, especialmente entre sitios de desarrolladores, SaaS, nube, seguridad y documentación.
| Fuente | Instantánea | Muestra | Adopción válida informada | Interpretación |
|---|---|---|---|---|
| Rankability | 22 de junio de 2025 | 1.000 sitios web principales | 0,3% | Punto de referencia público temprano que muestra una adopción mínima a mediados de 2025. |
| Este estudio | 6 de mayo de 2026 | Top 1.000 de Tranco | 7,50% | Rastreo posterior que muestra una adopción visible entre sitios de alto tráfico. |
| Este estudio | 6 de mayo de 2026 | Top 10.000 de Tranco | 5,86% | Muestra más amplia que indica que la adopción es medible, aunque aún no generalizada. |
Los experimentos de tráfico siguen siendo mixtos
publicó en enero de 2026 un análisis de 10 sitios que siguió a los sitios durante 90 días antes y 90 días después de la implementación. El artículo informó que dos sitios vieron aumentos de tráfico de IA del 12,5% y del 25%, ocho no mostraron mejoras medibles y uno cayó un 19,7%. Su interpretación clave fue de cautela causal: los dos casos aparentemente exitosos también lanzaron nuevas plantillas, reconstruyeron centros de recursos, añadieron tablas comparativas extraíbles, obtuvieron cobertura de prensa, corrigieron problemas técnicos o publicaron nuevo contenido tipo FAQ. Bajo ese marco, llms.txt documentaba un trabajo de contenido y técnico más sólido; no parecía causar el crecimiento por sí solo.
llegó a una conclusión más positiva a partir de una observación más pequeña a nivel de sitio. Comparó dos periodos de cuatro meses en Yandex.Metrica tras añadir tanto llms.txt como llms-full.txt. Las sesiones de referencia desde LLM subieron de 75 a 92, un aumento del 23%, mientras que los usuarios pasaron de 51 a 64. Las sesiones de Perplexity aumentaron de 29 a 55, mientras que las de ChatGPT bajaron de 31 a 26. La misma publicación también señala que el tráfico total de referencia creció más rápido, de 160 a 290 sesiones, por lo que la cuota de sesiones de LLM cayó del 47% al 32%.
| Tipo de evidencia | Resultado observado | Principal advertencia | Cómo afecta a este informe |
|---|---|---|---|
| Estudio de 10 sitios antes/después de Search Engine Land | Dos sitios subieron, ocho no mostraron cambios medibles y uno cayó. | Los casos positivos tuvieron cambios simultáneos de contenido, relaciones públicas y técnica. | Apoya tratar llms.txt como infraestructura, no como palanca de crecimiento autónoma. |
| Observación antes/después del blog personal de Alimbekov | Las sesiones de referencia desde LLM subieron un 23% en el periodo posterior. | No hay grupo de control; el tráfico total de referencia subió un 81% y la cuota de LLM bajó. | Sugiere una posible ventaja para blogs técnicos, especialmente vía Perplexity, pero la causalidad no queda aislada. |
| Este estudio de adopción basado en rastreo | 586 archivos válidos y muchas implementaciones estructuradas. | Mide presencia y estructura, no el impacto posterior en el tráfico. | Muestra adopción y madurez de implementación, pero no el ROI por sí solo. |
Lo que aclara el debate
La evidencia externa afina la interpretación de este conjunto de datos. Un archivo llms.txt bien estructurado puede reducir la fricción de análisis por parte de máquinas, sobre todo para documentación de desarrolladores, referencias de API y contenido de bases de conocimiento. Pero los casos de tráfico más fuertes siguen pareciendo depender de contenido útil, extraíble, autorizado y descubrible fuera del archivo. Por eso, la cuestión práctica no es “¿importa llms.txt?” de forma aislada. Es si el archivo forma parte de un sistema de contenido más amplio, legible por IA.
Interpretación actualizada:
llms.txtdebe implementarse como una infraestructura de bajo coste orientada a la IA. No debe presentarse como sustituto de una mejor documentación, contenido estructurado, accesibilidad técnica, citas, enlaces o autoridad de marca.
Metodología
Este estudio utilizó como muestra los 10.000 dominios principales de Tranco. Tranco es un ranking de sitios principales orientado a investigación, diseñado para ser más estable y resistente a la manipulación que muchas listas tradicionales. El archivo fuente de Tranco se descargó el 6 de mayo de 2026, con una marca Last-Modified de la fuente del 5 de mayo de 2026 a las 22:17:59 GMT.
El rastreador probó dos rutas en la raíz de cada dominio:
https://example.com/llms.txt, con fallback HTTP cuando fue necesario.https://example.com/llms-full.txt, con fallback HTTP cuando fue necesario.
Para cada prueba, el rastreador registró el código de estado, la URL final, el método de obtención, los bytes de la respuesta, el tipo de contenido, el mensaje de error, el tiempo transcurrido y el resultado de la validación. Los cuerpos de respuesta satisfactorios se guardaron en raw_llms_txt/ para revisión y análisis secundario.
Reglas de validación
Una respuesta solo se contó como archivo válido si devolvía un cuerpo correcto y no parecía un fallback web genérico. La ruta final de la URL tenía que seguir siendo /llms.txt o /llms-full.txt. Se rechazaron los cuerpos vacíos. Se rechazaron los documentos HTML obvios y los shells de aplicaciones. El tipo de contenido se consideró una evidencia de apoyo y no la única regla, porque un pequeño número de archivos válidos de apariencia textual se sirvieron con tipos de contenido inusuales.
Panorama de adopción
El rastreo encontró 586 archivos llms.txt válidos en el Top 10.000 de Tranco. Esto da una tasa de adopción válida del 5,86%. El archivo complementario más pequeño llms-full.txt estaba presente y era válido en 103 dominios, o el 1,03% de la muestra.
| Métrica | Cantidad | Cuota del Top 10.000 |
|---|---|---|
| Dominios rastreados | 10.000 | 100,00% |
| Archivos llms.txt válidos | 586 | 5,86% |
| Archivos llms-full.txt válidos | 103 | 1,03% |
| Respuestas HTTP 200 para /llms.txt | 1.606 | 16,06% |
| Respuestas HTTP 200 rechazadas como inválidas | 1.020 | 10,20% |
La adopción no es puramente de los sitios más grandes
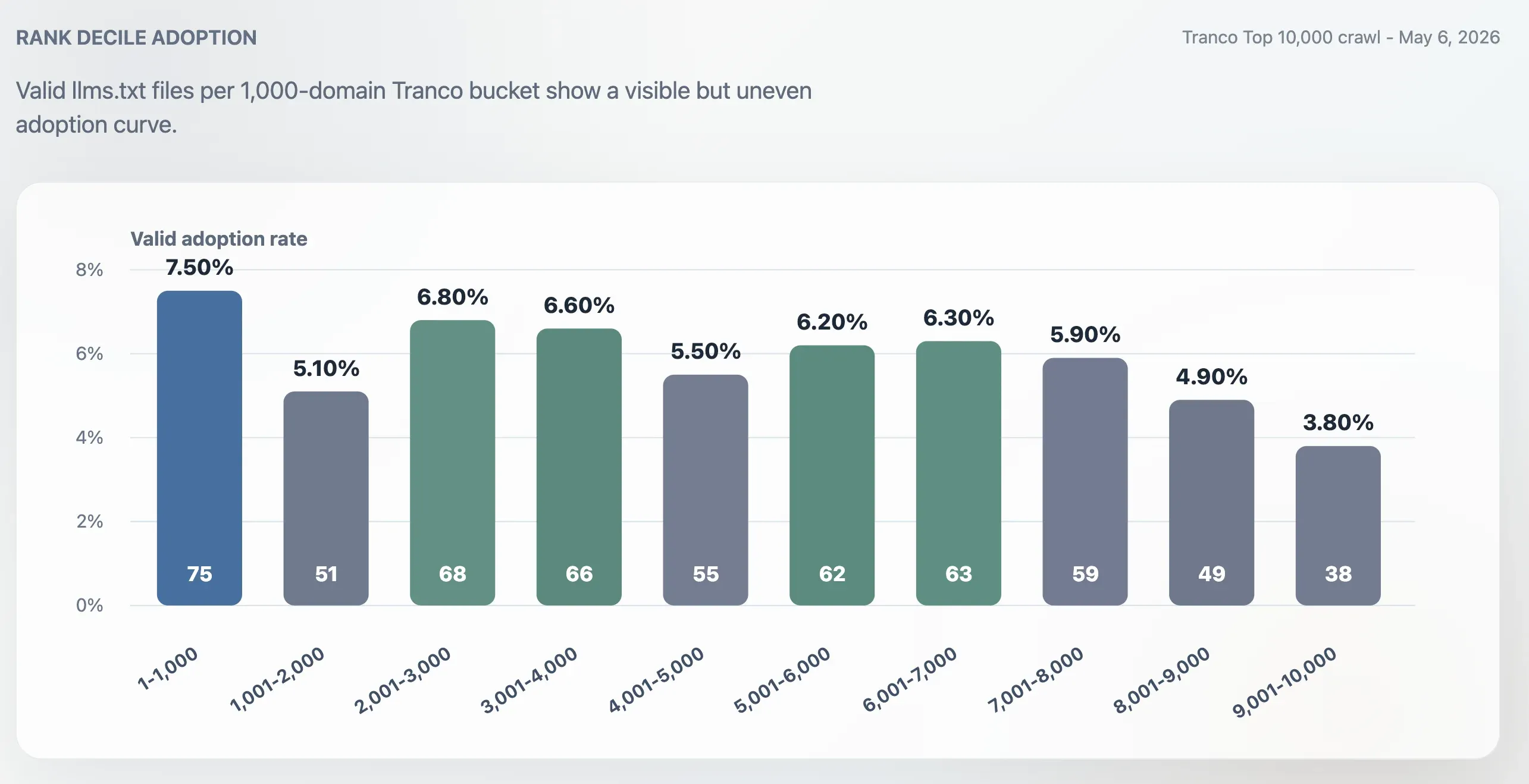
La adopción fue mayor en el Top 1.000 que en el Top 10.000 completo, pero no se limitó a los sitios más grandes. La tasa de adopción del Top 1.000 fue del 7,50%. El último tramo de 1.000 dominios, posiciones 9.001-10.000, cayó al 3,80%. La mitad del ranking se mantuvo activa: los tramos 2.001-3.000, 3.001-4.000, 5.001-6.000 y 6.001-7.000 se situaron todos en torno al 6%.
Primeros adoptantes
El adoptante válido mejor posicionado fue Cloudflare, en el puesto 4 de Tranco. Otros adoptantes bien posicionados fueron Azure, GitHub, DigiCert, WordPress.org, Adobe, Sentry, Dropbox, PayPal, Shopify, Taboola, Avast, Weather.com, Oxylabs, SourceForge, Cisco, Stripe, Slack, Dell, NVIDIA, Indeed, Zendesk, Calendly, Palo Alto Networks, Okta, Braze, Klaviyo, Intercom, Datadog, Cloudinary, ClassLink y OneSignal.
Estos adoptantes no son aleatorios. Suelen tener grandes superficies de documentación, líneas de producto que requieren explicación, APIs o ecosistemas para desarrolladores, contenido de soporte, páginas de precios, material de seguridad y privacidad, y suficiente autoridad de marca como para preocuparse por cómo interpretan los sistemas de IA sus sitios.
| Posición | Dominio | Tamaño del archivo | Patrón observado |
|---|---|---|---|
| 4 | cloudflare.com | 4.225 B | Índice compacto de producto, desarrolladores, empresa y precios. |
| 26 | azure.com | 47.037 B | Herramientas para desarrolladores, IA, cómputo, almacenamiento, seguridad, monitorización y recursos opcionales. |
| 28 | github.com | 27.108 B | Acceso programático, Copilot, MCP, API REST, Actions, repositorios y enlaces de CLI. |
| 248 | stripe.com | 64.229 B | Pagos, Connect, Checkout, Billing, Tax, Atlas, Radar y documentación para desarrolladores. |
| 265 | salesforce.com | 1,02 MB | Catálogo masivo de productos y enlaces de Agentforce, sin encabezados de sección Markdown. |
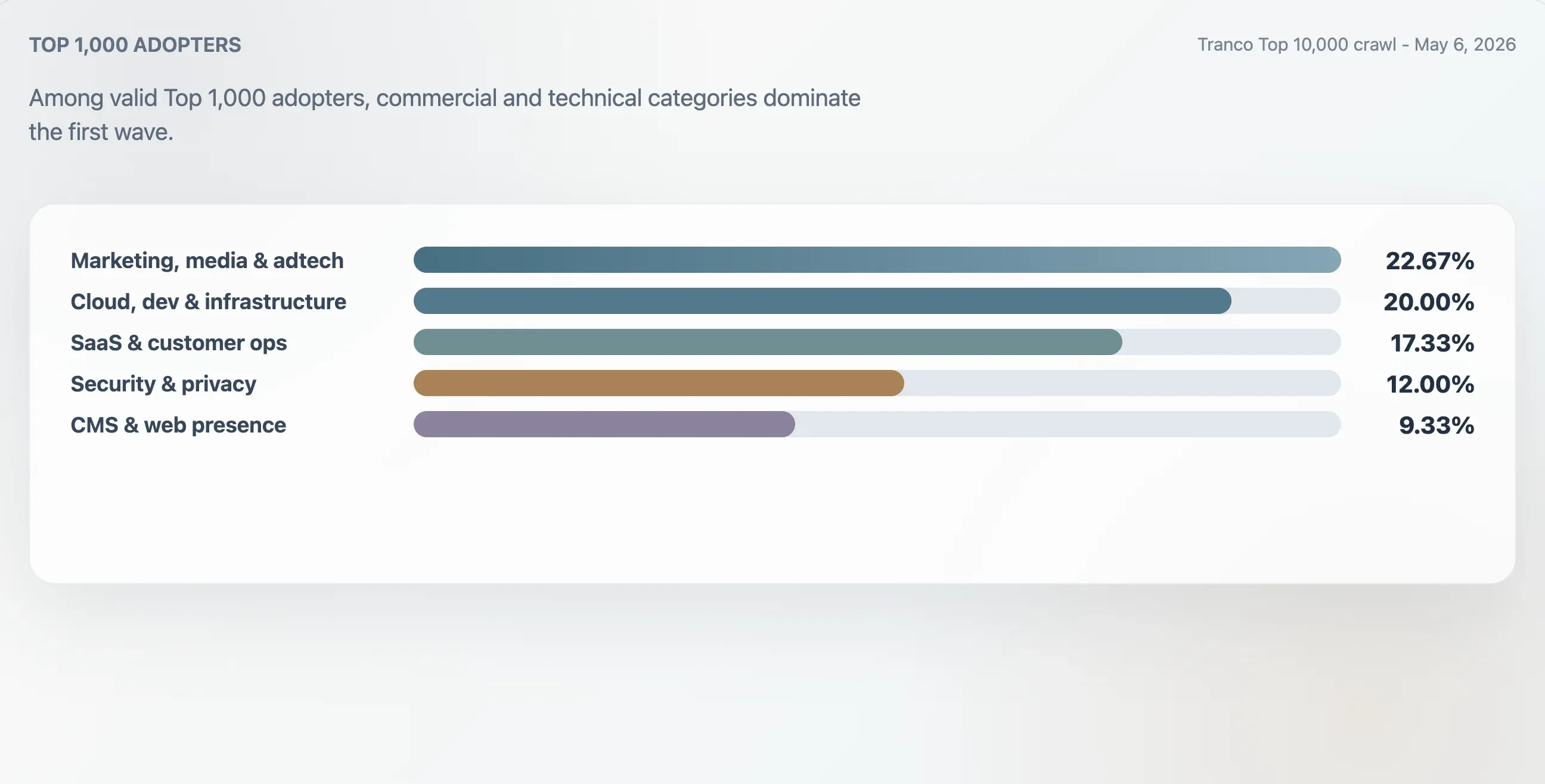
Categorías de los adoptantes del Top 1.000
Este estudio clasificó los 75 adoptantes válidos del Top 1.000 de Tranco usando el contexto del dominio, los primeros encabezados, la estructura bruta del archivo y las palabras clave del contenido. El grupo más grande fue marketing, medios y adtech, con un 22,67%. Los sitios de nube, desarrollo e infraestructura representaron el 20,00%. Los sitios de SaaS, productividad y operaciones de clientes representaron el 17,33%. Los sitios de seguridad, identidad y privacidad representaron el 12,00%.
| Categoría | Dominios | Cuota de los adoptantes del Top 1.000 | Puntuación mediana de calidad | Enlaces medianos |
|---|---|---|---|---|
| Marketing, medios y adtech | 17 | 22,67% | 94 | 25 |
| Nube, desarrollo e infraestructura | 15 | 20,00% | 94 | 62 |
| SaaS, productividad y operaciones de clientes | 13 | 17,33% | 94 | 46 |
| Seguridad, identidad y privacidad | 9 | 12,00% | 98 | 78 |
| CMS, hosting y presencia web | 7 | 9,33% | 100 | 24 |
Patrones por TLD
Los dominios de nivel superior no son etiquetas de sector, pero sí señales direccionales útiles. Entre los TLD con al menos 50 dominios en la muestra, .io tuvo la tasa de adopción válida más alta, con un 14,44%. .com le siguió con un 8,19%. La menor adopción en .gov, .edu y .net sugiere que la base de primeros adoptantes es más comercial y técnica que institucional.
Calidad de implementación
La adopción válida no significa una calidad de implementación uniforme. Algunos archivos son índices concisos y bien seccionados. Otros son sobre todo prosa. Otros son catálogos de enlaces en bruto. Algunos son marcadores de posición casi vacíos. Otros son volcados de contenido de varios megabytes que pueden estar completos, pero resultan caros de obtener y analizar.
Entre los archivos válidos llms.txt, 362 eran más grandes que 5 KB, o el 61,77% de los adoptantes válidos. El tamaño mediano del archivo era de unos 7,1 KB. El tamaño P90 era de 156 KB, el P95 de 356 KB, el P99 de 2,54 MB y el archivo más grande observado fue de 7,97 MB.
Señales de contenido comunes
Un análisis a nivel de palabras clave de los archivos válidos encontró que muchos sitios no se limitan a publicar una declaración; están orientando a los modelos hacia material útil operativamente. Los términos de soporte o ayuda aparecieron en el 70,31% de los archivos válidos. Blog, guía o tutorial aparecieron en el 67,92%. Seguridad, privacidad, cumplimiento o términos aparecieron en el 61,43%. Precios apareció en el 53,92%, documentación en el 52,22%, términos de API en el 33,96% y señales de changelog o lanzamientos en el 27,30%.
Puntuación de calidad y arquetipos
Para pasar de la presencia a la madurez, este estudio creó una puntuación ligera de implementación. La puntuación tiene en cuenta el tipo de contenido, el tamaño del archivo, la estructura Markdown, el número de enlaces, la cobertura temática y señales de alerta como ausencia de encabezados, ausencia de enlaces Markdown, tipos de contenido inusuales, archivos pequeños, archivos muy grandes y comportamiento de volcado de enlaces. Esto no es un estándar formal. Es un modelo de puntuación de investigación para comparar implementaciones observadas.
Con este modelo, 416 archivos válidos se clasificaron como índices estructurados sólidos, 107 como índices utilizables, 24 como delgados o irregulares y 39 como simbólicos o de baja utilidad. Un análisis separado de arquetipos encontró 296 índices estructurados, 113 archivos de texto seccionado, 63 catálogos de enlaces, 52 índices delgados, 50 archivos simbólicos o de marcador de posición y 12 volcados masivos de contenido.
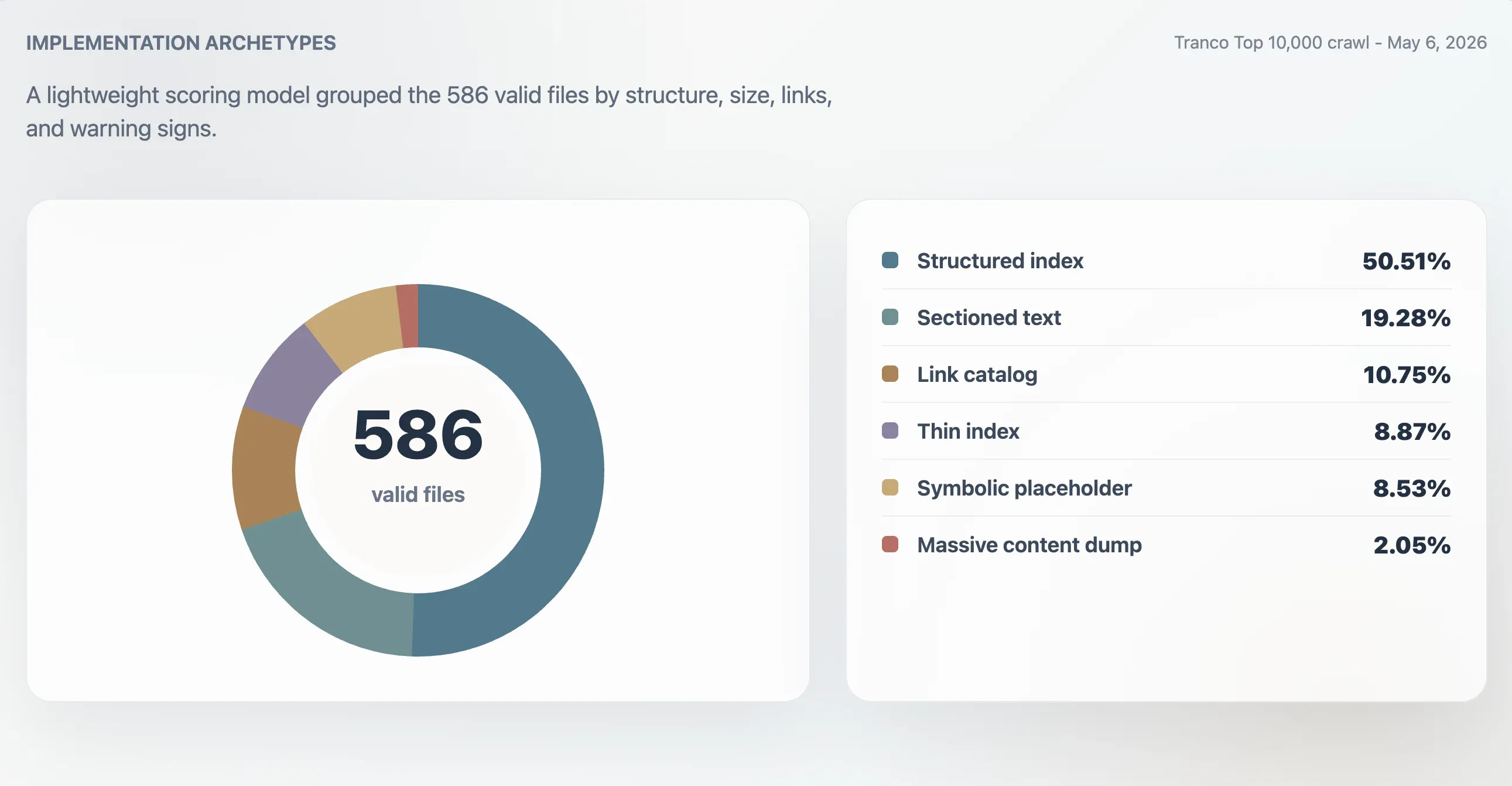
| Arquetipo | Dominios | Cuota de archivos válidos | Puntuación mediana | Tamaño mediano del archivo | Enlaces medianos |
|---|---|---|---|---|---|
| Índice estructurado | 296 | 50,51% | 98 | 11.241 B | 61,5 |
| Texto seccionado | 113 | 19,28% | 78 | 4.718 B | 0 |
| Catálogo de enlaces | 63 | 10,75% | 86 | 4.160 B | 23 |
| Índice delgado | 52 | 8,87% | 66 | 2.814 B | 0 |
| Simbólico o de marcador de posición | 50 | 8,53% | 27 | 15 B | 0 |
| Volcado masivo de contenido | 12 | 2,05% | 74 | 2,84 MB | 7.259,5 |
Los principales adoptantes tienen implementaciones más densas
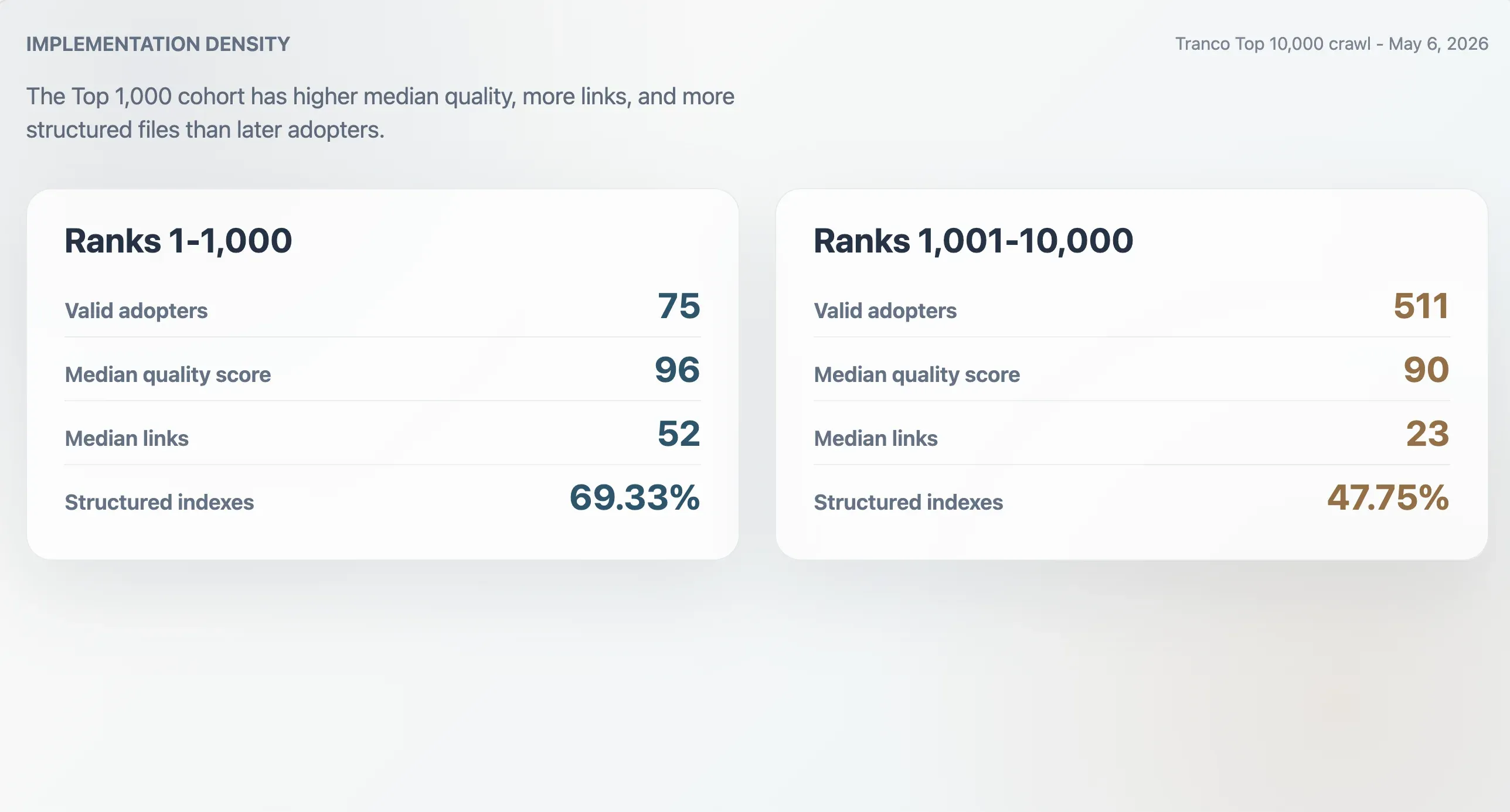
Los 75 adoptantes válidos del Top 1.000 de Tranco tuvieron una puntuación mediana de calidad de 96, un tamaño mediano de archivo de 9.068 bytes, un recuento mediano de 52 enlaces Markdown y una mediana de 11 secciones. Los 511 adoptantes situados entre las posiciones 1.001 y 10.000 tuvieron medianas más bajas: puntuación 90, tamaño de archivo 6.506 bytes, 23 enlaces Markdown y 9 secciones. Los adoptantes del Top 1.000 también tenían más probabilidades de ser índices estructurados: 69,33% frente a 47,75% en la cohorte posterior.
El problema de los falsos positivos

El mayor riesgo de medición son los falsos positivos. De los 1.606 dominios que devolvieron HTTP 200 para /llms.txt, 1.020 no superaron la validación. La razón inválida más común fue la redirección fuera de objetivo, con 618 casos. Otras 367 respuestas fueron documentos HTML genéricos. Veintinueve devolvieron un cuerpo vacío y seis fueron otras respuestas inválidas o no clasificadas.
Esto importa porque muchos sitios grandes enrutan rutas desconocidas a páginas de inicio de sesión, páginas principales, shells de aplicaciones, páginas regionales, superficies de consentimiento o fallbacks de marketing. Estas respuestas pueden parecer correctas para un rastreador basado en códigos de estado, pero no contienen ninguna señal válida de llms.txt.
llms-full.txt: más escaso y más desigual
El archivo complementario llms-full.txt era mucho menos común que llms.txt. El rastreo encontró 103 archivos completos válidos, equivalentes al 17,58% de los adoptantes válidos de llms.txt y al 1,03% de la muestra total del Top 10.000.
Las implementaciones del archivo completo fueron desiguales. Entre los 103 adoptantes de doble archivo, 57 tenían un archivo llms-full.txt más grande que el archivo índice, pero 46 o bien tenían un archivo completo no mayor que el índice o un archivo completo de menos de 100 bytes. La proporción mediana de tamaño entre archivo completo e índice fue de 1,43, pero hubo casos extremos mucho mayores. El archivo completo de Supabase era aproximadamente 7.139 veces el tamaño de su archivo índice. Made-in-China.com tenía un archivo completo de 89,89 MB.
| Dominio | llms.txt | llms-full.txt | Proporción |
|---|---|---|---|
| made-in-china.com | 4,49 MB | 89,89 MB | 20,0x |
| sendbird.com | 281,86 KB | 11,99 MB | 42,5x |
| taboola.com | 286,78 KB | 11,73 MB | 40,9x |
| supabase.co | 1,26 KB | 8,98 MB | 7.139,3x |
| neon.tech | 27,44 KB | 5,01 MB | 182,7x |
Recomendación: publica
llms-full.txtsolo cuando el sitio ya tenga una canalización de documentación estable, disciplina de versionado y una razón clara para exponer grandes volúmenes de contenido en un único archivo legible por máquinas.
llms.txt, robots.txt y sitemap.xml
llms.txt no debe tratarse como un nuevo robots.txt. Ambos son archivos legibles por máquinas ubicados en la raíz, pero comunican cosas distintas. robots.txt es una señal de preferencia de rastreo y control de acceso. sitemap.xml es una señal de descubrimiento de URLs. llms.txt es una señal explicativa y de navegación.
| Señal | Función principal | Lector típico | Interpretación en este estudio |
|---|---|---|---|
robots.txt | Declarar preferencias de rastreo y restricciones a nivel de ruta. | Rastreadores de búsqueda, rastreadores de IA, rastreadores de archivo, bots genéricos. | Señal de gobernanza y acceso. |
sitemap.xml | Enumerar URLs descubribles para sistemas de indexación. | Motores de búsqueda y canalizaciones de indexación. | Señal de descubrimiento. |
llms.txt | Proporcionar contexto compacto del sitio, enlaces importantes, documentación, APIs, ejemplos y referencias de políticas. | Aplicaciones LLM, agentes de IA, herramientas para desarrolladores, sistemas de recuperación. | Señal de explicación y navegación. |
Recomendaciones
Para los sitios que estén considerando llms.txt, las implementaciones más sólidas en este conjunto de datos y la evidencia externa sobre tráfico sugieren un patrón pragmático:
- Publica
/llms.txten la raíz y manténlo accesible sin inicio de sesión, ejecución de JavaScript, muros de consentimiento ni redirecciones fuera de ruta. - Sírvete de
text/plainotext/markdowncuando sea posible. - Empieza con una breve descripción del sitio y luego agrupa los enlaces por producto, documentación, API, precios, changelog, ejemplos, soporte, políticas y recursos de la empresa.
- Prefiere enlaces canónicos frente a listas exhaustivas de URLs.
- Evita archivos simbólicos vacíos; como mucho cuentan como una señal débil.
- Evita volcados masivos e indiferenciados salvo que exista un caso de uso fuerte de consumo por máquina y una canalización de generación fiable.
- Valida la URL final, el cuerpo de la respuesta, el tipo de contenido, la estructura Markdown, el número de enlaces y el tamaño del archivo después de publicar.
Los equipos también deberían ajustar bien las expectativas. Los experimentos públicos disponibles no demuestran que llms.txt aumente de forma independiente el tráfico de referencia desde IA. Si un equipo quiere probar el impacto comercial, debería seguir juntos las referencias desde LLM, las páginas citadas, las solicitudes de bots, la frescura del índice y los cambios de contenido. Un experimento útil compararía grupos de páginas emparejados, mantendría constantes las actualizaciones de contenido siempre que fuera posible y separaría el tráfico específico de plataformas como Perplexity, ChatGPT, Gemini, Claude y Bing/Copilot.
Limitaciones
Esta es una instantánea basada en rastreo, no una verdad permanente. Los sitios web pueden añadir, eliminar o cambiar archivos llms.txt en cualquier momento. Algunos dominios pueden bloquear solicitudes automatizadas o comportarse de forma diferente según la geografía, la configuración TLS, la lógica de redirección, el user agent o la mitigación de bots. El estudio solo probó archivos en la raíz y no buscó en subdominios ni en rutas no estándar.
La puntuación de calidad y los arquetipos son herramientas de investigación, no etiquetas oficiales de cumplimiento. El análisis temático se basa en palabras clave y debe leerse como orientativo. El estudio no demuestra que ninguna plataforma concreta de IA lea, respete o use actualmente llms.txt en producción.
La evidencia externa de tráfico revisada en esta versión también tiene limitaciones. El análisis de Search Engine Land es más sólido como observación cautelar de varios sitios que como experimento aleatorizado. El resultado de Alimbekov es útil como estudio de caso transparente a nivel de sitio, pero carece de grupo de control e incluye un periodo en el que el tráfico total de referencia subió de forma importante. Estas referencias ayudan a enmarcar el debate, pero no convierten este rastreo en un estudio causal de tráfico.
Archivos y reproducibilidad
| Archivo | Propósito |
|---|---|
crawl_llms_txt.py | Rastreador para /llms.txt y /llms-full.txt. |
analyze_llms_txt.py | Análisis principal de adopción y generación de gráficos. |
deep_analyze_llms_txt.py | Análisis secundario para deciles de ranking, TLD, señales temáticas, puntuaciones de calidad, arquetipos y comportamiento de doble archivo. |
deep_dive_early_quality.py | Clasificación de primeros adoptantes y análisis en profundidad de la calidad de implementación. |
data/llms_probe_results_top_10000.csv | Conjunto principal de resultados del rastreo. |
data/deep_analysis_top_10000.json | Resumen del análisis secundario. |
data/deep_early_quality_analysis.json | Categorías de primeros adoptantes, comparación de cohortes de calidad, detalles de arquetipos y estudios de caso. |
Fuentes
- , Jeremy Howard, 2024.
- .
- .
- .
- , Data Provenance Initiative.
- .
- , Search Engine Land, enero de 2026.
- , Rankability, junio de 2025.
- , Renat Alimbekov.
Las correcciones metodológicas, los problemas del conjunto de datos y los análisis de seguimiento son bienvenidos en support@thunderbit.com. Este informe se publica de forma independiente de cualquier posición comercial que tenga Thunderbit. Los datos de este informe se sostienen por sí solos. — El equipo de investigación de Thunderbit, mayo de 2026.