

La web en 2025 es un terreno salvaje: la mitad del tráfico que ves ni siquiera es humano. Así es: los bots y crawlers ya representan más del 50% de toda la actividad de internet (Thales Group), y solo una parte de ellos son los “buenos” bots que sí te interesan: buscadores, previsualizadores de redes sociales y herramientas de analítica. ¿El resto? Digamos que no siempre vienen a ayudar. Como alguien que lleva años creando herramientas de automatización e IA en Thunderbit, he visto de primera mano cómo el crawler adecuado —o el equivocado— puede marcar la diferencia en tu SEO, sesgar tus analíticas, agotar tu ancho de banda o incluso desencadenar un incidente de seguridad de los gordos.
Si diriges un negocio, gestionas un sitio web o simplemente intentas mantener bajo control tu presencia digital, saber quién está llamando a la puerta de tu servidor es más importante que nunca. Por eso he preparado esta guía de 2025 sobre los crawlers más importantes: qué hacen, cómo detectarlos y cómo mantener tu sitio abierto a los buenos bots mientras mantienes a raya a los malos.
¿Qué hace que un crawler sea “conocido”? User-Agent, IPs y verificación
Empecemos por lo básico: ¿qué es exactamente un crawler “conocido”? En términos simples, es un bot que se identifica con una cadena de user-agent coherente (como Googlebot/2.1 o bingbot/2.0) y, idealmente, rastrea desde rangos de IP publicados o bloques ASN que puedes verificar (verificación de Googlebot). Los grandes —Google, Microsoft, Baidu, Yandex, DuckDuckGo— publican documentación sobre sus bots y, en muchos casos, ofrecen herramientas o archivos JSON con sus IP oficiales (lista de IP de Googlebot, lista de IP de Bingbot, IPs de DuckDuckBot).
Pero aquí está el problema: confiar solo en el user-agent es arriesgado. La suplantación está muy extendida; los bots maliciosos a menudo fingen ser Googlebot o Bingbot solo para esquivar tus defensas (SecurityWeek). Por eso el estándar de oro es la verificación dual: comprobar tanto el user-agent como la dirección IP (o el ASN), usando búsquedas DNS inversas o listas publicadas. Si usas una herramienta como Thunderbit, puedes automatizar este proceso: extraer registros, emparejar user-agents y cruzar IPs para construir una lista fiable y en tiempo real de quién está rastreando tu sitio.
Cómo usar esta lista de crawlers
Entonces, ¿qué haces realmente con una lista de crawlers conocidos? Así es como recomiendo sacarle partido:
- Allowlisting: Asegúrate de que los bots que sí quieres (buscadores, previsualizadores de redes sociales) nunca sean bloqueados por error por tu firewall, CDN o WAF. Usa sus IPs y user-agents oficiales para crear allowlists precisas.
- Filtrado de analítica: Filtra el tráfico de bots en tus analíticas para que tus números reflejen visitas humanas reales, y no solo a Googlebot y AhrefsBot dando vueltas por tu sitio (SecurityWeek).
- Gestión de bots: Configura reglas de crawl-delay o limitación para herramientas SEO agresivas, y bloquea o desafía a los bots desconocidos o maliciosos.
- Análisis automatizado de logs: Usa herramientas de IA como Thunderbit para extraer, clasificar y etiquetar la actividad de crawlers en tus registros, de modo que puedas detectar tendencias, identificar impostores y mantener tus políticas al día.
Tener actualizada tu lista de crawlers no es algo de “lo configuras y te olvidas”. Aparecen bots nuevos, otros cambian de comportamiento y los atacantes se vuelven más astutos cada año. Automatizar las actualizaciones —por ejemplo, rastreando documentación oficial o repositorios de GitHub con Thunderbit— puede ahorrarte horas y más de un dolor de cabeza.
1. Thunderbit: identificación de crawlers y gestión de datos con IA
Gestión de crawlers con IA gracias a Thunderbit Get Started Free
Thunderbit no es solo un Raspador Web IA: es un asistente de datos para equipos que quieren entender y gestionar el tráfico de crawlers. Esto es lo que diferencia a Thunderbit:
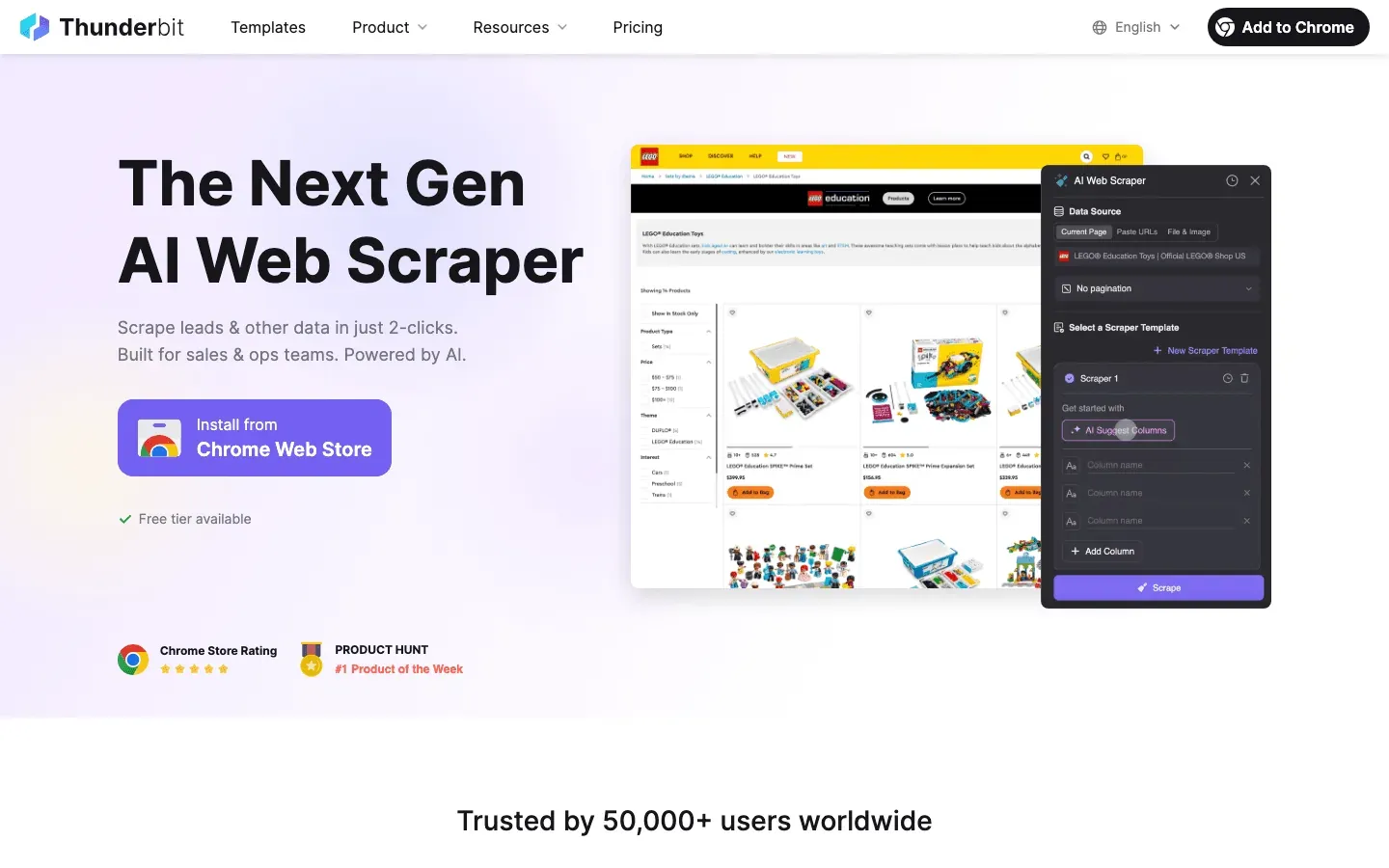
- Preprocesamiento semántico: Antes de extraer datos, Thunderbit convierte páginas web y registros en contenido estructurado con formato Markdown. Este preprocesamiento semántico permite que la IA entienda de verdad el contexto, los campos y la lógica de lo que está leyendo. Es una solución estupenda en páginas complejas, dinámicas o con mucho JavaScript (piensa en Facebook Marketplace o hilos de comentarios largos), donde los scrapers tradicionales basados en DOM se quedan cortos.
- Verificación dual: Thunderbit puede recopilar rápidamente documentación oficial de IPs de crawlers y listas ASN, y luego compararlas con tus logs del servidor. ¿El resultado? Una “allowlist de crawlers de confianza” en la que realmente puedes apoyarte, sin comprobaciones manuales.
- Extracción automatizada de logs: Alimenta a Thunderbit con tus registros en bruto y los convertirá en tablas estructuradas (Excel, Sheets, Airtable), etiquetando visitantes de alta frecuencia, rutas sospechosas y bots conocidos. A partir de ahí, puedes enviar los resultados a tu WAF o CDN para bloquear, limitar o desafiar automáticamente con CAPTCHA.
- Cumplimiento y auditoría: La extracción semántica de Thunderbit deja un rastro de auditoría claro: quién accedió a qué, cuándo y cómo lo gestionaste. Eso ayuda muchísimo con GDPR, CCPA y otros requisitos de cumplimiento.
He visto equipos usar Thunderbit para reducir en un 80% la carga de trabajo de gestión de crawlers, y por fin entender qué bots ayudan, cuáles perjudican y cuáles simplemente están fingiendo.
Prueba Thunderbit para la gestión de crawlers
2. Googlebot: el estándar de los buscadores
Googlebot es el estándar de oro para los crawlers web. Es el responsable de indexar tu sitio para Google Search; si lo bloqueas, es como poner un cartel de “Cerrado” en tu escaparate digital.
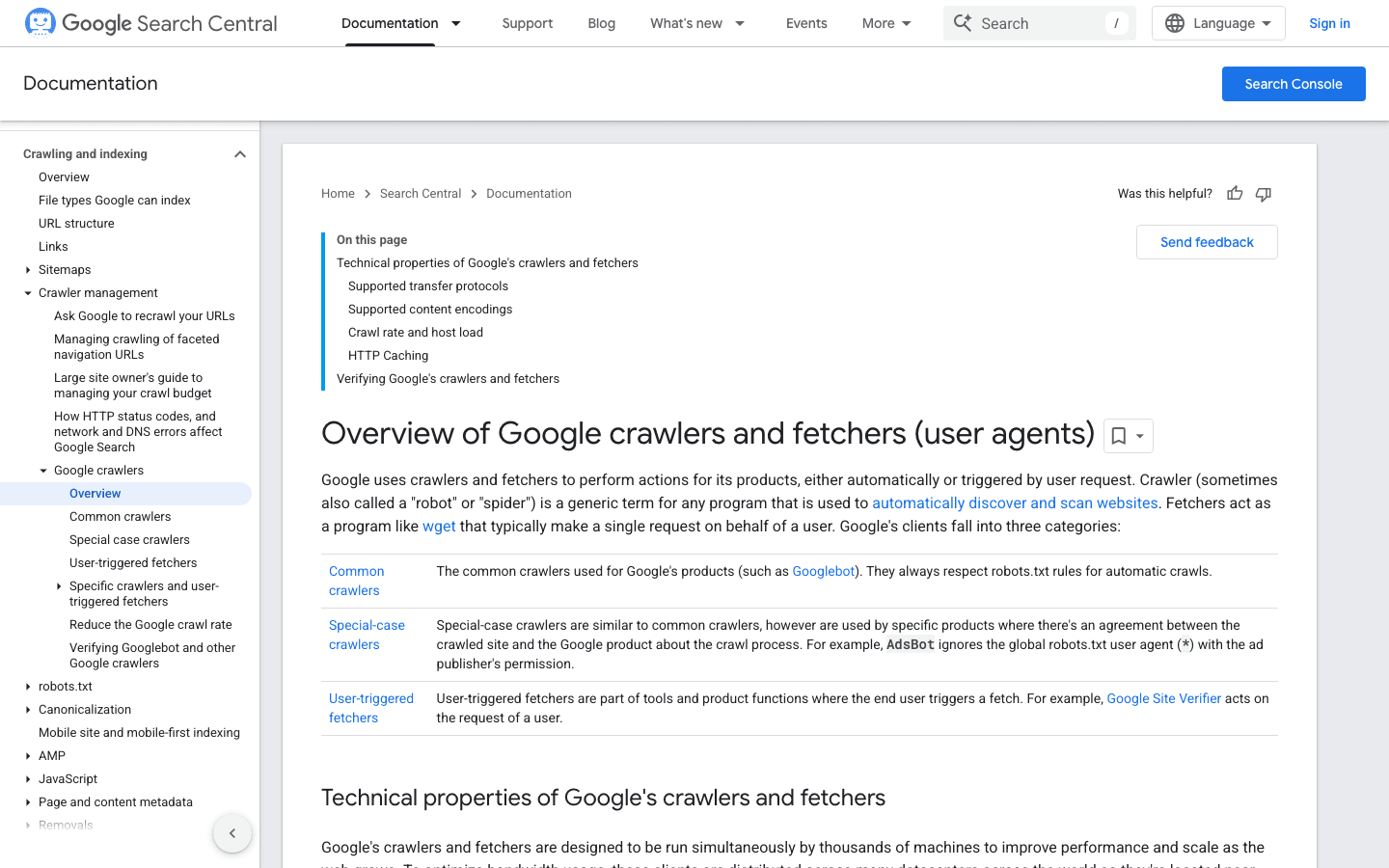
- User-Agent:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - Verificación: Usa el método DNS inverso de Google o la lista oficial de IP.
- Consejos de gestión: Permite siempre Googlebot. Usa robots.txt para guiar —no bloquear— su rastreo, y ajusta la tasa de rastreo en Google Search Console si hace falta.
3. Bingbot: el explorador web de Microsoft
Bingbot impulsa los resultados de Bing y Yahoo. Es el segundo crawler más importante para la mayoría de los sitios.
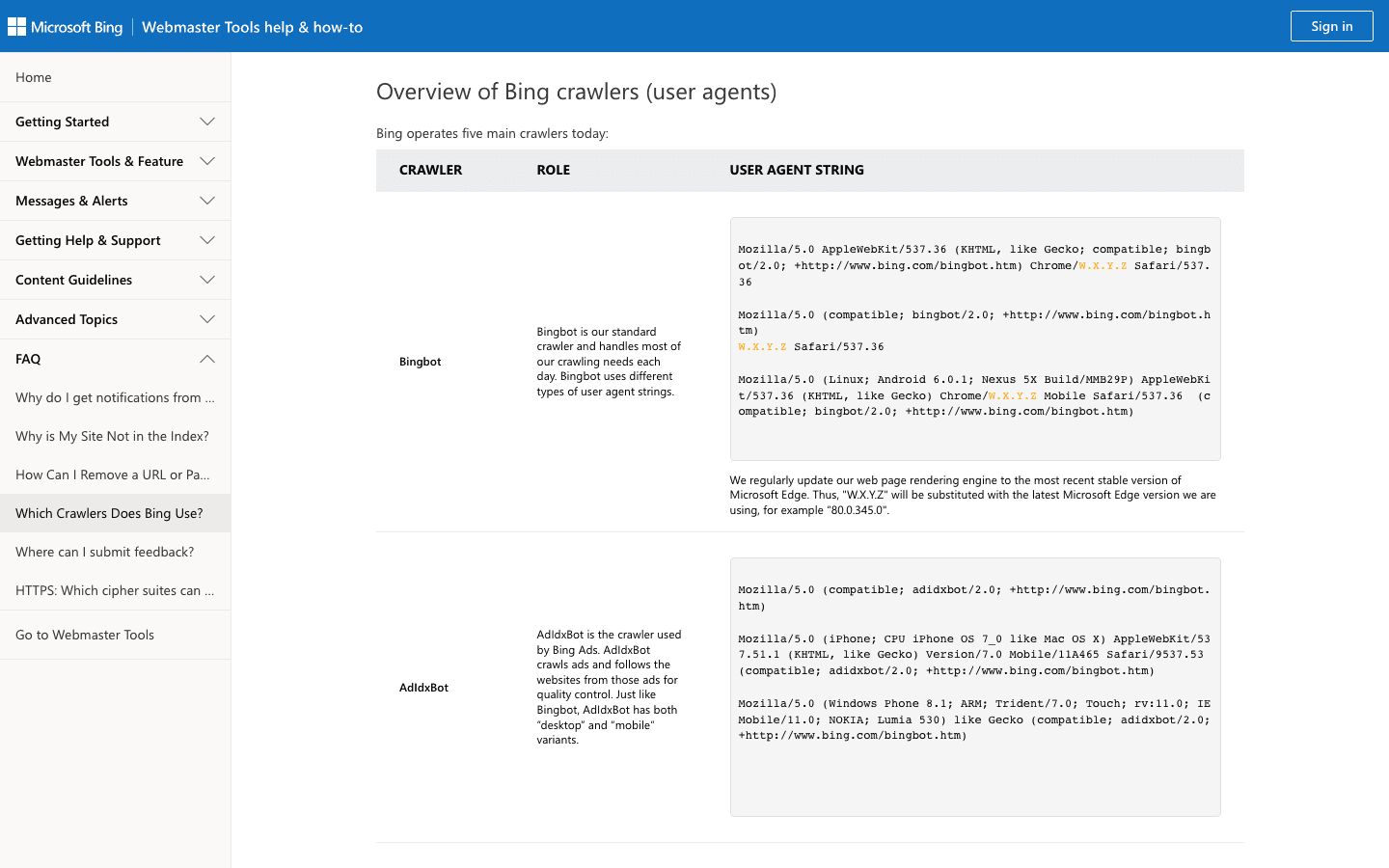
- User-Agent:
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - Verificación: Usa la herramienta de verificación de Microsoft y la lista oficial de IP.
- Consejos de gestión: Permite Bingbot, gestiona la tasa de rastreo en Bing Webmaster Tools y usa robots.txt para ajustar con precisión.
4. Baiduspider: el principal crawler de búsqueda en China
Baiduspider es la puerta de entrada al tráfico de búsqueda chino.
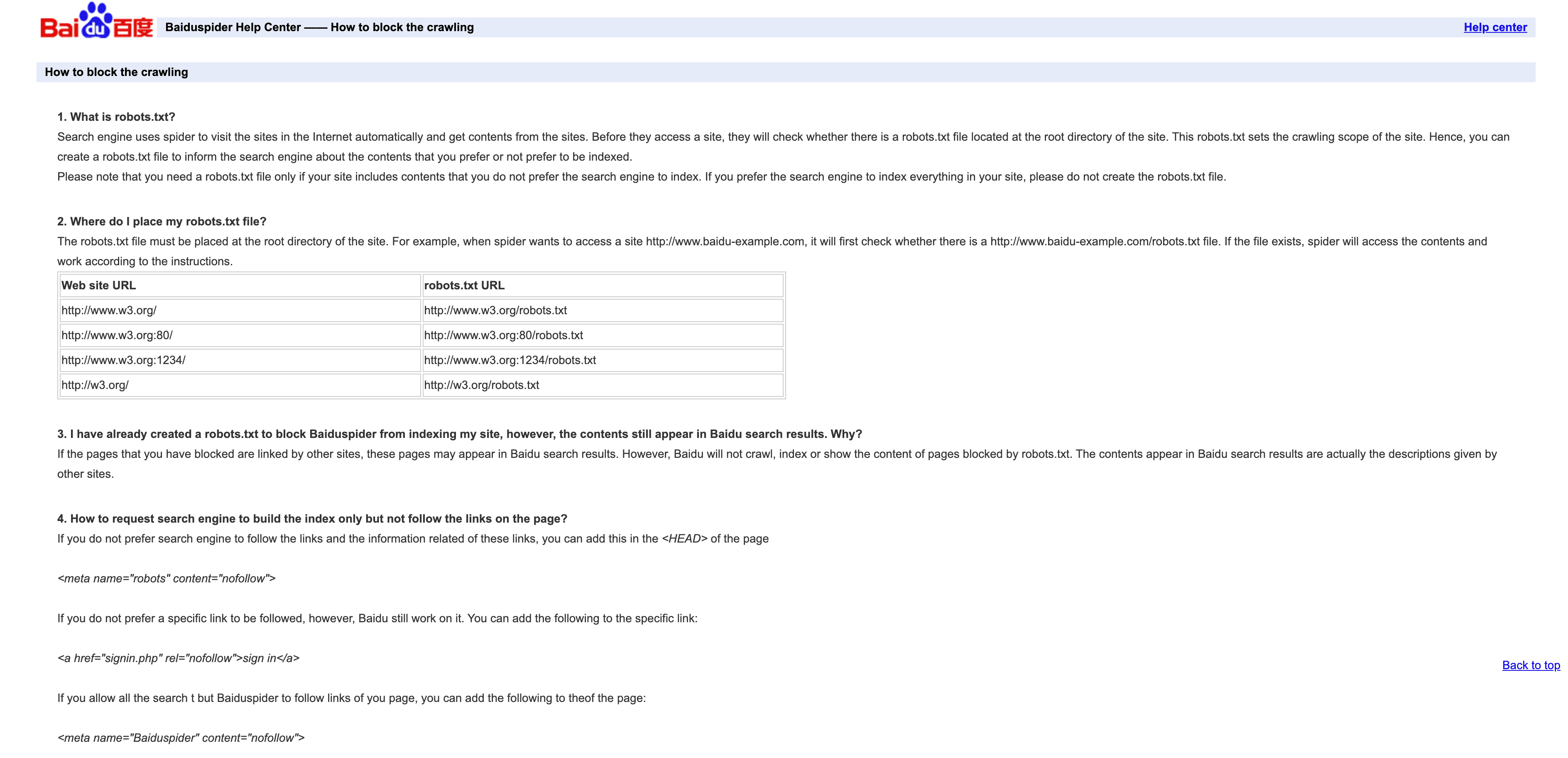
- User-Agent:
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) - Verificación: No hay una lista oficial de IP; comprueba si aparece
.baidu.comen el DNS inverso, pero ten en cuenta sus limitaciones. - Consejos de gestión: Permítelo si quieres tráfico desde China. Usa robots.txt para definir reglas, pero ten en cuenta que Baiduspider a veces las ignora. Si no necesitas SEO en chino, considera limitarlo o bloquearlo para ahorrar ancho de banda.
5. YandexBot: el crawler del buscador ruso
YandexBot es esencial para los mercados ruso y de la CEI.
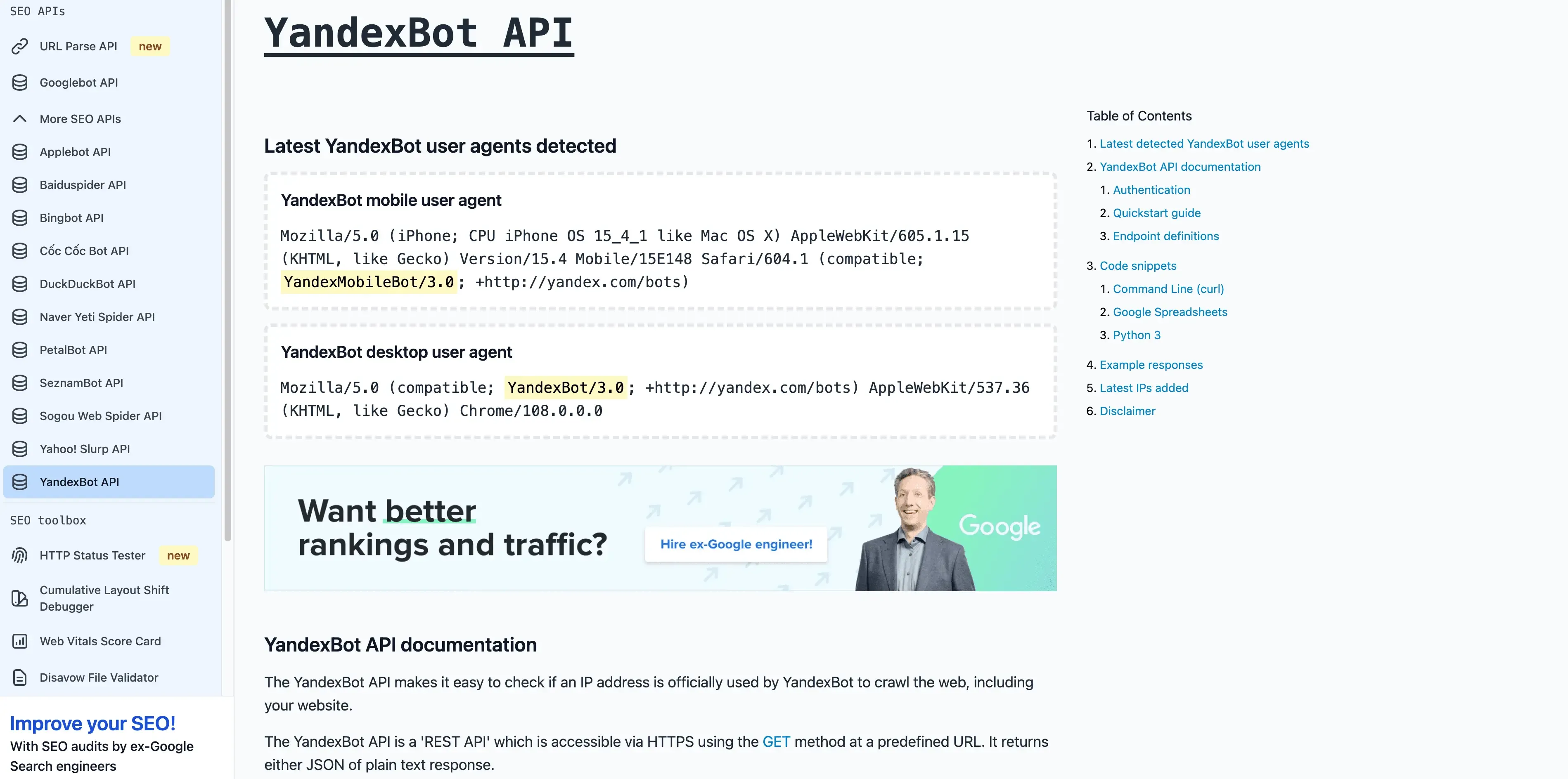
- User-Agent:
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) - Verificación: El DNS inverso debe terminar en
.yandex.ru,.yandex.neto.yandex.com. - Consejos de gestión: Permítelo si te diriges a usuarios de habla rusa. Usa Yandex Webmaster para controlar el rastreo.
6. DuckDuckBot: crawler de búsqueda centrado en la privacidad
DuckDuckBot impulsa la búsqueda centrada en la privacidad de DuckDuckGo.
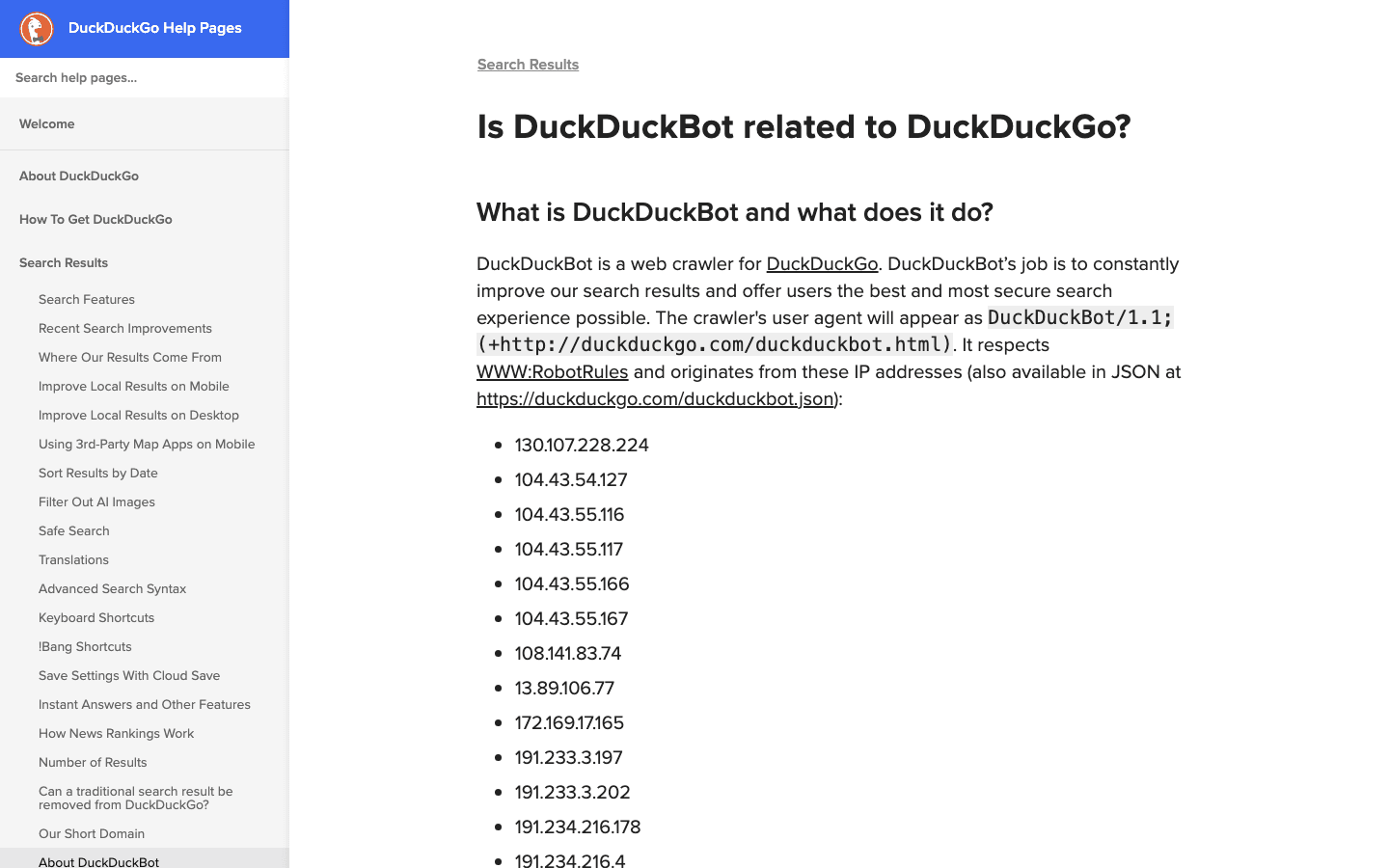
- User-Agent:
DuckDuckBot/1.1; (+http://duckduckgo.com/duckduckbot.html) - Verificación: Lista oficial de IP (JSON).
- Consejos de gestión: Permítelo salvo que no te interesen en absoluto los usuarios preocupados por la privacidad. Tiene una carga de rastreo baja y es fácil de gestionar.
7. AhrefsBot: análisis de SEO y backlinks
AhrefsBot es uno de los principales crawlers de herramientas SEO: muy útil para el análisis de backlinks, aunque puede consumir mucho ancho de banda.
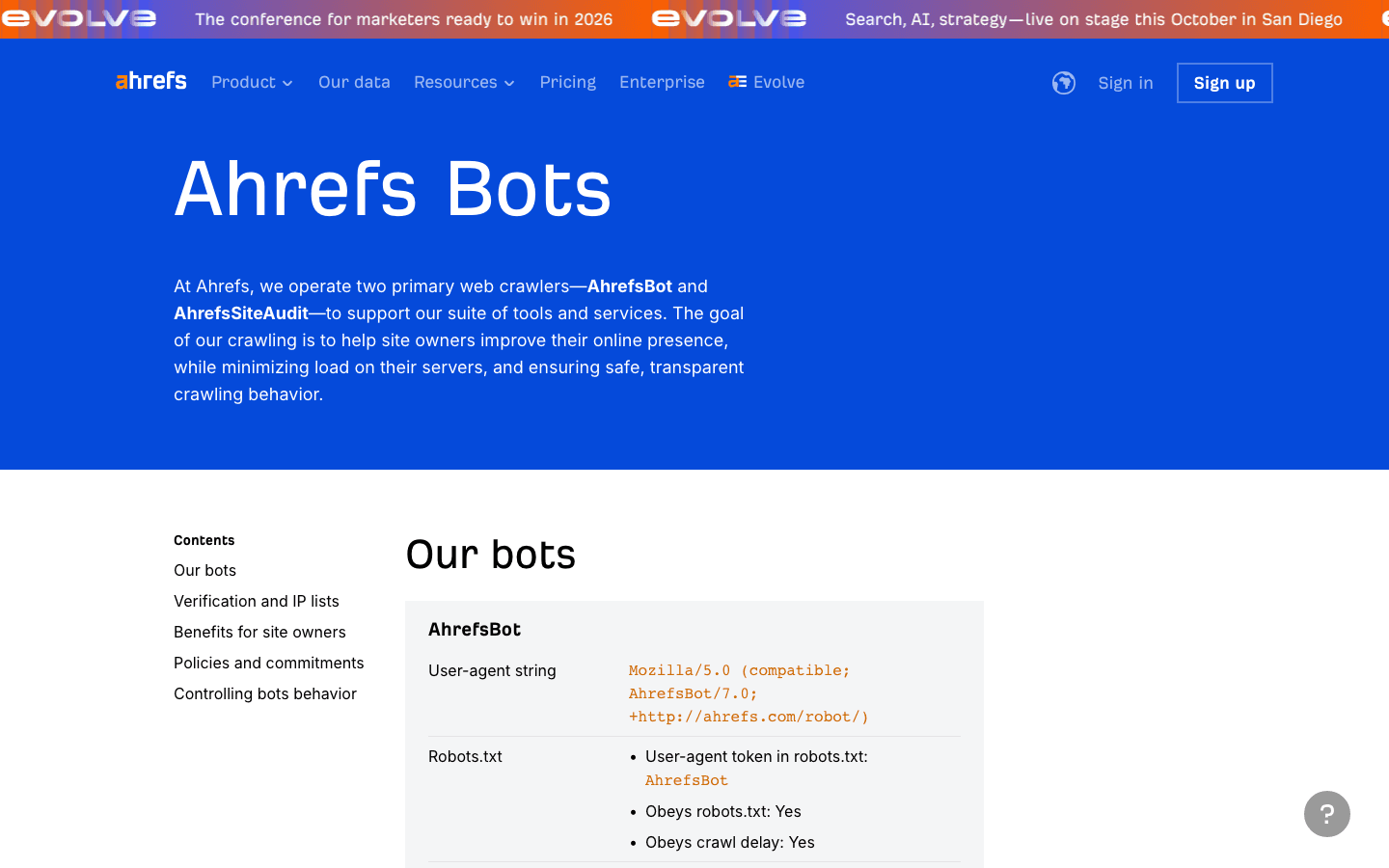
- User-Agent:
Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) - Verificación: No hay lista pública de IP; verifica mediante el UA y el DNS inverso.
- Consejos de gestión: Permítelo si usas Ahrefs. Usa robots.txt para establecer crawl-delay o bloquear. Puedes darte de baja por correo electrónico.
8. SemrushBot: información competitiva de SEO
SemrushBot es otro crawler SEO importante.
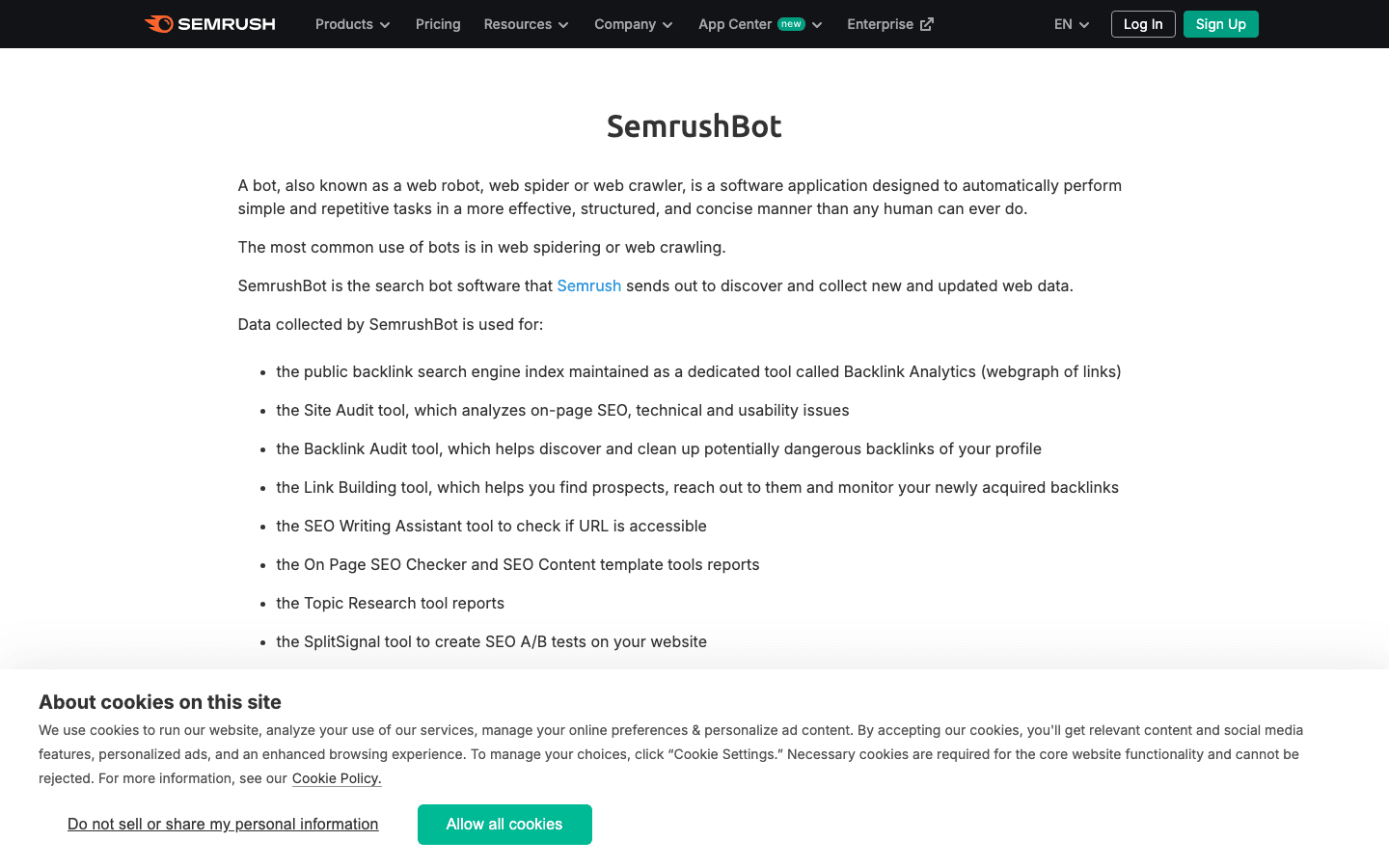
- User-Agent:
Mozilla/5.0 (compatible; SemrushBot/1.0; +http://www.semrush.com/bot.html)(más variantes comoSemrushBot-BA,SemrushBot-SI, etc.) - Verificación: Por user-agent; no hay lista pública de IP.
- Consejos de gestión: Permítelo si usas Semrush; si no, limítalo o bloquéalo con robots.txt o con reglas del servidor.
9. FacebookExternalHit: bot de vista previa para redes sociales
FacebookExternalHit obtiene datos de Open Graph para las vistas previas de enlaces en Facebook e Instagram.
- User-Agent:
facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) - Verificación: Por user-agent; las IP pertenecen al ASN de Facebook.
- Consejos de gestión: Permítelo para obtener vistas previas ricas en redes sociales. Bloquearlo significa no tener miniaturas ni resúmenes en Facebook/Instagram.
10. Twitterbot: crawler de vista previa de enlaces de X (Twitter)
Twitterbot obtiene datos de Twitter Card para X (Twitter).
- User-Agent:
Twitterbot/1.0 - Verificación: Por user-agent; ASN de Twitter (AS13414).
- Consejos de gestión: Permítelo para las vistas previas de Twitter. Usa las meta tags de Twitter Card para obtener los mejores resultados.
Tabla comparativa: lista de crawlers de un vistazo
| Crawler | Propósito | Ejemplo de User-Agent | Método de verificación | Impacto en el negocio | Consejos de gestión |
|---|---|---|---|---|---|
| Thunderbit | Análisis de logs/crawlers con IA | N/A (herramienta, no un bot) | N/A | Gestión de datos, clasificación de bots | Úsalo para extraer logs y crear allowlists |
| Googlebot | Indexación de Google Search | Googlebot/2.1 | DNS y lista de IP | Fundamental para el SEO | Permitir siempre, gestionar en Search Console |
| Bingbot | Bing/Yahoo Search | bingbot/2.0 | DNS y lista de IP | Importante para el SEO en Bing/Yahoo | Permitir, gestionar en Bing Webmaster Tools |
| Baiduspider | Baidu Search (China) | Baiduspider/2.0 | DNS inverso, cadena UA | Clave para el SEO en China | Permitir si apuntas a China, vigilar el ancho de banda |
| YandexBot | Yandex Search (Rusia) | YandexBot/3.0 | DNS inverso hasta .yandex.ru | Clave para Rusia y Europa del Este | Permitir si apuntas a RU/CEI, usar herramientas de Yandex |
| DuckDuckBot | DuckDuckGo Search | DuckDuckBot/1.1 | Lista oficial de IP | Audiencia centrada en la privacidad | Permitir, bajo impacto |
| AhrefsBot | Análisis de SEO/backlinks | AhrefsBot/7.0 | Cadena UA, DNS inverso | Herramienta SEO, puede consumir mucho ancho de banda | Permitir/limitar/bloquear con robots.txt |
| SemrushBot | Análisis SEO y competitivo | SemrushBot/1.0 (más variantes) | Cadena UA | Herramienta SEO, puede ser agresiva | Permitir/limitar/bloquear con robots.txt |
| FacebookExternalHit | Previsualizaciones de enlaces sociales | facebookexternalhit/1.1 | Cadena UA, ASN de Facebook | Interacción en redes sociales | Permitir para vistas previas, usar OG tags |
| Twitterbot | Previsualizaciones de enlaces en Twitter | Twitterbot/1.0 | Cadena UA, ASN de Twitter | Interacción en Twitter | Permitir para vistas previas, usar Twitter Card tags |
Gestión de tu lista de crawlers: mejores prácticas para 2025
Aprende más sobre list crawling con IA Get Started Free
- Actualízala con regularidad: El panorama de crawlers cambia rápido. Programa revisiones trimestrales y usa herramientas como Thunderbit para rastrear y comparar listas oficiales (Human Security).
- Verifica, no confíes: Comprueba siempre tanto el user-agent como la IP/ASN. No dejes que impostores se cuelen y distorsionen tus analíticas o extraigan tus datos (FriendlyCaptcha).
- Allowlist para los bots buenos: Asegúrate de que los crawlers de búsqueda y redes sociales nunca queden bloqueados por reglas anti-bot o firewalls.
- Limita o bloquea los bots agresivos: Usa robots.txt, crawl-delay o reglas del servidor para las herramientas SEO que van demasiado lejos.
- Automatiza el análisis de logs: Usa herramientas impulsadas por IA como Thunderbit para extraer, clasificar y etiquetar la actividad de crawlers: ahorrarás tiempo y detectarás tendencias que podrías pasar por alto.
- Equilibra SEO, analítica y seguridad: No bloquees a los bots que impulsan tu negocio, pero tampoco dejes que los malos hagan lo que quieran.
Descarga la extensión de Chrome de Thunderbit
Conclusión: mantener tu lista de crawlers actualizada y accionable
En 2025, gestionar tu lista de crawlers no es solo una tarea de TI: es una labor crítica para el negocio que afecta al SEO, la analítica, la seguridad y el cumplimiento. Con los bots representando ya la mayoría del tráfico web, necesitas saber quién visita tu sitio, por qué y qué hacer al respecto. Mantén tu lista actualizada, automatiza siempre que puedas y usa herramientas como Thunderbit para ir un paso por delante. La web solo se está volviendo más concurrida, y una estrategia de crawlers inteligente y accionable es tu mejor defensa —y también tu mejor ataque— en un mundo impulsado por bots.
Preguntas frecuentes
1. ¿Por qué es importante mantener una lista de crawlers actualizada?
Porque los bots ya representan más de la mitad de todo el tráfico web, y solo una pequeña parte es beneficiosa. Mantener tu lista al día garantiza que permites los bots buenos (para SEO y vistas previas sociales) y bloqueas o limitas los malos, protegiendo tus analíticas, tu ancho de banda y la seguridad de tus datos.
2. ¿Cómo puedo saber si un crawler es legítimo o falso?
No confíes solo en el user-agent: verifica siempre la dirección IP o el ASN usando listas oficiales o búsquedas DNS inversas. Herramientas como Thunderbit pueden automatizar este proceso comparando tus logs con las IP y user-agents publicados de los bots.
3. ¿Qué debo hacer si un bot desconocido está rastreando mi sitio?
Investiga el user-agent y la IP. Si no está en tu allowlist y no coincide con un bot conocido, considera limitarlo, desafiarlo o bloquearlo. Usa herramientas de IA para clasificar y supervisar nuevos crawlers a medida que aparecen.
4. ¿Cómo ayuda Thunderbit en la gestión de crawlers?
Thunderbit usa IA para extraer, estructurar y clasificar la actividad de crawlers a partir de logs, lo que facilita crear allowlists, detectar impostores y automatizar la aplicación de políticas. Su preprocesamiento semántico es especialmente sólido para sitios complejos o dinámicos.
5. ¿Cuál es el riesgo de bloquear un crawler importante como Googlebot o Bingbot?
Bloquear crawlers de buscadores puede hacer que tu sitio desaparezca de los resultados de búsqueda, eliminando tu tráfico orgánico. Comprueba siempre tu firewall, robots.txt y las reglas anti-bot para asegurarte de que no estás dejando fuera por error a los bots más importantes.
Más información:
- Cómo rastrear cualquier sitio web usando IA
- Guía de Python para el web scraping: aprende con ejemplos reales
- La lista definitiva de 2025 de web crawlers y buenos bots: identificación, ejemplos y mejores prácticas
- Los bots de web crawler más populares
Prueba Thunderbit para la gestión de crawlers impulsada por IA Get Started Free




