

“¿es legal extraer datos de sitios web?”—esa es la pregunta que me lanzan casi cada semana los equipos de ventas, operaciones y marketing. Hoy en día, el 웹 스크래퍼 mueve desde la generación de leads hasta la inteligencia competitiva, así que no es raro que todos quieran una respuesta clara. Pero la verdad es que el panorama legal es tan enredado como un tazón de fideos fríos. Solo hay que mirar los titulares: un tribunal dice que extraer datos públicos está bien, otro advierte sobre la “recolección ilegal de datos”. Por eso, muchos equipos prefieren no arriesgarse a cruzar la línea.
Dato curioso: más de dos tercios de las organizaciones ya usan el 웹 스크래퍼 para análisis y proyectos de IA, y un impresionante 78% de las empresas de e-commerce lo emplean para estrategias de precios. Pero con demandas mediáticas como LinkedIn vs. hiQ Labs, el riesgo nunca ha sido mayor. Entonces, ¿cómo aprovechar el valor de los datos web sin meterte en líos legales? Vamos a repasar el marco legal, los puntos clave de cumplimiento y las mejores prácticas que cualquier equipo de negocio debería tener en el radar. Y sí, te mostraré cómo Thunderbit hace que el 웹 스크래퍼 sea mucho más sencillo y conforme a la normativa.
Entendiendo el panorama legal: ¿es legal extraer datos de sitios web?
Implicaciones legales del Web Scraping Descubre más sobre el aspecto legal del web scraping y cómo mantenerte en regla. Get Started Free
Vamos al grano: la legalidad del 웹 스크래퍼 depende de qué datos extraes, cómo lo haces y desde dónde. No existe una ley universal que diga “el scraping es legal” o “el scraping es ilegal”. En vez de eso, hay un mosaico de reglas: leyes anti-hackeo, regulaciones de privacidad, derechos de autor e incluso los términos de uso de cada página (Thunderbit Blog).
Estos son los factores clave que determinan si tu proyecto de scraping está dentro de la ley:
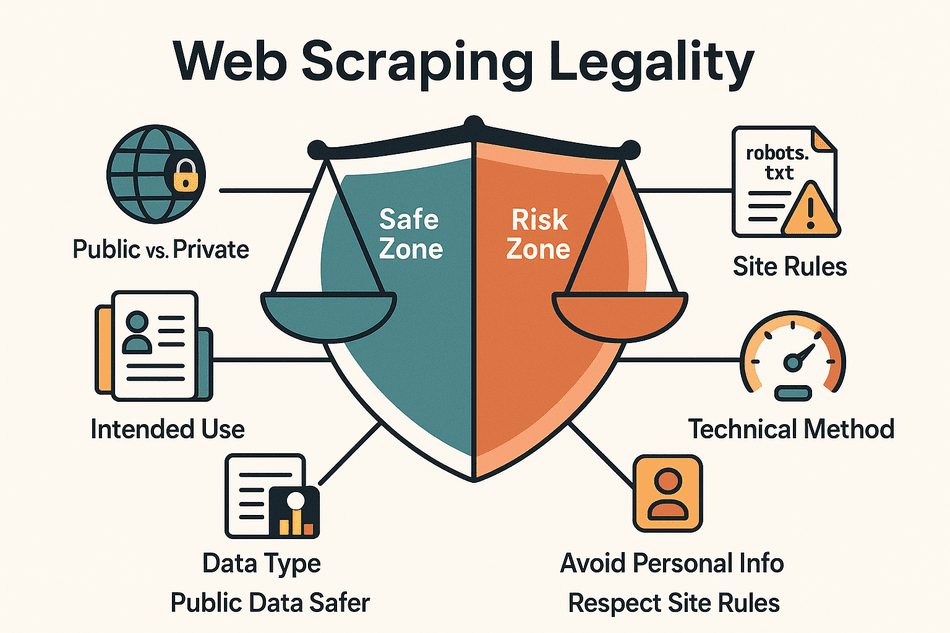
- Datos públicos vs. privados: Extraer información accesible para todos (sin login ni muro de pago) suele ser más seguro. Si entras a contenido tras iniciar sesión, probablemente ya estás pisando terreno peligroso.
- Tipo de datos: Los datos personales (nombres, emails, perfiles sociales) y el contenido protegido por derechos de autor (artículos, imágenes) son mucho más delicados que extraer información factual (precios, especificaciones, listados de negocios).
- Uso previsto: Usar los datos extraídos solo para análisis interno o investigación implica menos riesgo que republicarlos o venderlos.
- Cumplimiento de las normas del sitio: Saltarse los términos de uso o ignorar el archivo robots.txt puede traerte problemas, incluso si los datos son públicos.
- Método técnico: Extraer datos a un ritmo similar al humano y sin saltarse medidas de seguridad (como CAPTCHAs o bloqueos de IP) te mantiene en terreno más seguro.
 (https://strapi.thunderbit.com/uploads/webscrapinglegalitysafevsriskzones_6ee3935a34.png)
En resumen: Extraer datos públicos y no personales para uso interno es ampliamente aceptado en muchas regiones, pero hay matices importantes, sobre todo en temas de privacidad, derechos de autor y la intensidad con la que raspas (Thunderbit Blog).
(https://strapi.thunderbit.com/uploads/webscrapinglegalitysafevsriskzones_6ee3935a34.png)
En resumen: Extraer datos públicos y no personales para uso interno es ampliamente aceptado en muchas regiones, pero hay matices importantes, sobre todo en temas de privacidad, derechos de autor y la intensidad con la que raspas (Thunderbit Blog).
Marco legal del scraping: visión global de las principales regulaciones
 Vamos a dar una vuelta rápida por los marcos legales más importantes del mundo para el 웹 스크래퍼:
Vamos a dar una vuelta rápida por los marcos legales más importantes del mundo para el 웹 스크래퍼:
Estados Unidos: CFAA, derechos de autor y contratos
- Computer Fraud and Abuse Act (CFAA): Esta ley anti-hackeo prohíbe acceder a sistemas informáticos “sin autorización”. Sin embargo, los tribunales han aclarado que extraer datos de sitios públicos no viola la CFAA, ya que no se requiere autorización (California Lawyers Association).
- Caso clave: En hiQ Labs v. LinkedIn, el tribunal dictaminó que extraer perfiles públicos de LinkedIn no violaba la CFAA. Sin embargo, LinkedIn aún podía demandar por incumplimiento de contrato (violar los términos de uso) o por derechos de autor.
- Otros riesgos: Si raspas de forma agresiva (como el bot en eBay v. Bidder’s Edge que hacía 100,000 solicitudes al día), podrías ser responsable de “intrusión en bienes ajenos”, es decir, interferir con los servidores de otro (Wikipedia).
Unión Europea: RGPD y derechos sobre bases de datos
- RGPD: El Reglamento General de Protección de Datos de la UE se aplica incluso a datos personales públicos. Si extraes cualquier dato que identifique a una persona, necesitas una base legal (como consentimiento o interés legítimo) y cumplir estrictas normas de privacidad.
- Directiva de bases de datos: La UE también protege las bases de datos como conjunto. Extraer una “parte sustancial” de una base estructurada (como todos los anuncios de un portal inmobiliario) puede violar estos derechos, aunque los datos individuales no tengan copyright (Thunderbit Blog).
Reino Unido: UK GDPR y Ley de Protección de Datos
- UK GDPR: Tras el Brexit, las normas del Reino Unido son similares a las de la UE. Extraer datos públicos y no personales suele estar permitido, pero los datos personales están muy regulados.
- Computer Misuse Act: Similar a la CFAA, esta ley puede convertir el acceso no autorizado en delito.
China: PIPL y Ley de Seguridad de Datos
- Ley de Protección de Información Personal (PIPL): Exige consentimiento para recolectar datos personales. Extraer información personal de sitios chinos sin permiso está prohibido.
- Ley de Seguridad de Datos: Se utiliza para sancionar el scraping que perjudica a los propietarios de datos o genera competencia desleal.
Otras regiones
- Canadá, Australia, APAC: La mayoría cuenta con leyes anti-hackeo y normas de privacidad similares a la UE/Reino Unido. Siempre revisa la legislación local antes de extraer datos.
En resumen: Lo más seguro es extraer datos públicos y no personales para uso interno, y siempre revisar las normas de tu región (Thunderbit Blog).
Lista de verificación de cumplimiento: ¿cómo asegurar que tu scraping sea legal?
Antes de lanzarte a extraer datos, revisa esta lista de cumplimiento:
- Lee los Términos de Servicio del sitio: Si los ToS prohíben el scraping, mejor detente o pide permiso primero (Thunderbit Blog).
- Limítate a datos públicos: No extraigas nada detrás de un login o muro de pago sin autorización explícita.
- Revisa robots.txt: Visita
site.com/robots.txtpara ver si se prohíbe el acceso de bots a ciertas secciones. No es legalmente vinculante, pero es buena práctica respetarlo. - Evita datos personales: No extraigas nombres, emails u otros datos personales salvo que tengas base legal y un plan de privacidad.
- No copies contenido creativo: Limítate a hechos y datos. Republicar artículos, imágenes o grandes fragmentos puede generar reclamos de derechos de autor.
- Usa APIs oficiales si existen: Si el sitio ofrece una API, utilízala; es más seguro y estable.
- Raspa con moderación: No sobrecargues los servidores. Extrae datos a un ritmo humano y evita saltarte protecciones técnicas.
- Documenta tu proceso: Guarda registros de qué datos extraes, cuándo y por qué. Esto ayuda si surgen dudas después.
- Prepárate para detenerte: Si recibes una carta de cese y desista, detén el scraping de inmediato y reevalúa.
Prácticas de cumplimiento de Thunderbit: extracción de datos más segura y confiable
Cuando creamos Thunderbit, el cumplimiento fue una prioridad. Así es como Thunderbit te ayuda a mantenerte dentro de la legalidad:
- Scraping basado en navegador: Thunderbit solo extrae lo que ves en tu navegador—sin llamadas ocultas a APIs ni saltos de login. Si no lo ves, Thunderbit no lo extrae (Thunderbit Blog).
- Alertas integradas: Si intentas extraer datos de un sitio con políticas estrictas, Thunderbit te avisará. Es como tener un experto en cumplimiento a tu lado.
- Sugerencias de campos con IA: La IA de Thunderbit analiza la página y recomienda solo los campos relevantes, ayudándote a evitar datos sensibles o innecesarios (Thunderbit Blog).
- Velocidad similar a la humana: Ya sea local o en la nube, Thunderbit ajusta el ritmo para no saturar los servidores.
- Sin almacenamiento en nuestros servidores: Los datos extraídos van directamente a ti; Thunderbit no guarda copias, lo que favorece el cumplimiento de privacidad.
- Exportaciones compatibles con cumplimiento: Exporta datos directamente a Google Sheets, Excel, Airtable o Notion—ideal para uso interno.
- Gestión de subpáginas y paginación: Thunderbit navega los sitios como un usuario real, avanzando por páginas y subpáginas sin forzar los endpoints.
- Scraping programado con moderación: Programa extracciones a intervalos responsables, sin saturar el sitio.
- Soporte multilingüe: La interfaz de Thunderbit está disponible en 34 idiomas, facilitando el cumplimiento en todo el mundo.
En resumen, Thunderbit “incorpora el cumplimiento en el producto”, guiándote para extraer datos de forma responsable, incluso si no eres experto legal (Thunderbit Blog).
Prueba Thunderbit para extracción web conforme
Raspado de datos vs. reutilización: ¿dónde están los límites legales?
 No es lo mismo extraer datos para uso interno que republicar, revender o reutilizar esa información. Aquí es donde la línea legal se vuelve clara:
No es lo mismo extraer datos para uso interno que republicar, revender o reutilizar esa información. Aquí es donde la línea legal se vuelve clara:
- Uso interno: Extraer datos públicos para análisis interno (como leads o monitoreo de precios) suele ser seguro—siempre que no sean datos personales ni se violen leyes de privacidad.
- Redistribución o reventa: Publicar o vender datos extraídos (en tu web, producto o como dataset) puede generar reclamos de derechos de autor, bases de datos o incumplimiento de contrato.
- Derechos de autor y bases de datos: En EE. UU., los hechos no tienen copyright, pero la selección o disposición de los datos sí puede estar protegida. En la UE/Reino Unido, extraer una “parte sustancial” de una base puede violar derechos sui generis.
- Uso legítimo (Fair Use): La ley estadounidense permite el “uso legítimo” en ciertos casos (como análisis o comentarios), pero copiar grandes cantidades de contenido casi nunca es uso legítimo.
- Atribución: Siempre cita tus fuentes si usas datos extraídos públicamente, pero recuerda que atribuir no te exime si violas otros derechos.
- No vendas datos en bruto: Vender datasets sin procesar es especialmente arriesgado. Utiliza los datos para generar análisis, no como producto final.
Consejo: Usa los datos extraídos para inteligencia interna y toma de decisiones. Si necesitas compartirlos externamente, agrégalos o transfórmalos, y revisa si necesitas permiso (Thunderbit Blog).
Casos de estudio: cómo mitigar riesgos legales
Veamos algunos casos reales—porque nada enseña mejor el cumplimiento que los errores ajenos:
LinkedIn vs. hiQ Labs
- Qué ocurrió: hiQ Labs extrajo perfiles públicos de LinkedIn para crear análisis sobre rotación de empleados. LinkedIn intentó bloquearlos, pero el tribunal dictaminó que extraer datos públicos no violaba la CFAA.
- Lección: Extraer datos públicos es defendible legalmente en EE. UU., pero hay que vigilar los términos de uso y la privacidad (California Lawyers Association).
eBay vs. Bidder’s Edge
- Qué ocurrió: Bidder’s Edge extrajo listados de subastas de eBay de forma agresiva (100,000 solicitudes/día), violando los términos y el robots.txt. El tribunal ordenó una medida cautelar por “intrusión en bienes ajenos”.
- Lección: Incluso extraer datos públicos puede ser ilegal si se hace de forma agresiva o violando normas explícitas (Wikipedia).
Facebook (Meta) vs. Power Ventures
- Qué ocurrió: Power Ventures extrajo datos de Facebook con consentimiento de usuarios, pero tras ser bloqueados, siguieron extrayendo. El tribunal lo consideró “acceso no autorizado”.
- Lección: Si el propietario del sitio te pide que dejes de extraer datos, debes detenerte o arriesgarte a violar leyes anti-hackeo.
Casos de éxito en cumplimiento
Muchos sitios de comparación de precios en la UE operan legalmente extrayendo solo datos factuales, respetando exclusiones y sin copiar bases completas. La ausencia de demandas muestra que limitarse a datos públicos y cumplir las normas funciona.
Cómo ayuda Thunderbit
Las alertas, límites de velocidad y el enfoque basado en navegador de Thunderbit habrían evitado muchos de estos errores legales, avisando sobre sitios de riesgo y aplicando buenas prácticas por defecto.
Lista de autoevaluación para el scraping en escenarios empresariales
Aquí tienes una lista práctica para auditar tu próximo proyecto de extracción:
- ¿Los datos son públicos? (Sin login requerido)
- ¿Qué dicen los términos del sitio? (¿Hay cláusulas anti-scraping?)
- ¿Has revisado robots.txt? (¿Tu sección objetivo está prohibida?)
- ¿Estás extrayendo datos personales? (Si sí, ¿tienes un plan de privacidad?)
- ¿Estás extrayendo una gran parte del sitio? (Evita copiar bases completas)
- ¿Cuál es tu propósito? (Uso interno = más seguro; reutilización pública = más riesgo)
- ¿Raspas con moderación? (Ritmo humano, sin saltar protecciones técnicas)
- ¿Has buscado una API? (Úsala si existe)
- ¿Estás listo para detenerte si te lo piden? (¿Tienes plan para cese y desista?)
- ¿Cómo almacenarás y protegerás los datos? (Limita el acceso, protege la privacidad)
- ¿Documentas tu proceso? (Guarda registros para cumplimiento)
Si respondes “no” o tienes dudas en alguna, detente y aclara antes de seguir (Thunderbit Blog).
Ejemplo de flujo de trabajo conforme para usuarios de Thunderbit
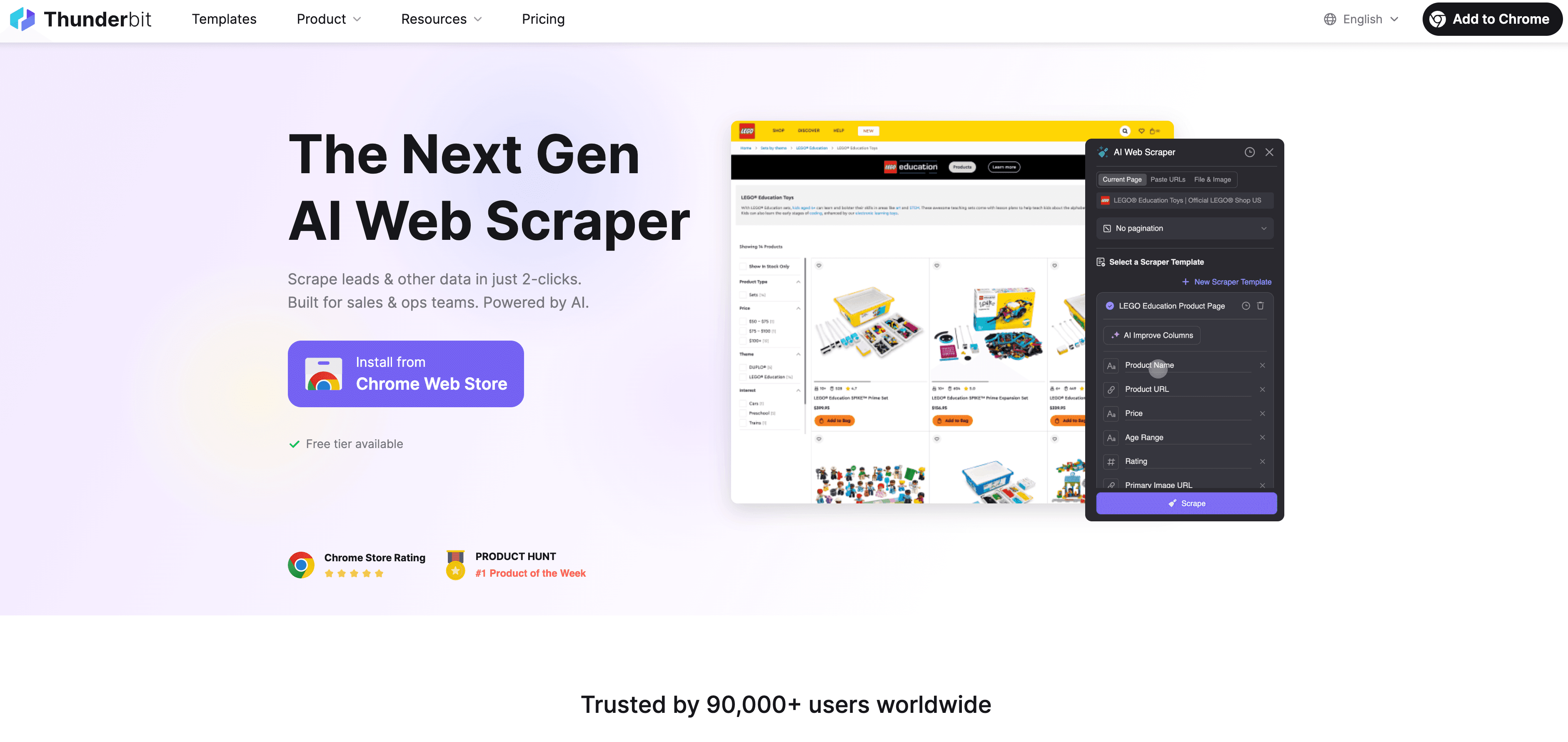 Así sería un flujo típico y conforme usando Thunderbit:
Así sería un flujo típico y conforme usando Thunderbit:
- Revisión previa: Consulta el robots.txt y los términos del sitio. ¿No hay lenguaje anti-scraping? Adelante.
- Abre Thunderbit: Ve a la página objetivo y lanza la extensión de Chrome de Thunderbit.
- Sugerencias de IA: Deja que la IA de Thunderbit recomiende campos relevantes y no sensibles. Verifica que no se incluyan datos personales salvo que tengas base legal.
- Personaliza campos: Ajusta columnas y tipos de datos según lo necesario—solo recoge lo imprescindible.
- Extrae: Haz clic en “Extraer”. Thunderbit recopila los datos a ritmo humano, respetando la estructura del sitio.
- Scraping de subpáginas: Si hace falta, usa la función de subpáginas para enriquecer tus datos—siempre solo información pública.
- Exporta: Envía los datos directamente a Google Sheets, Excel, Airtable o Notion para análisis interno.
- Programa (opcional): Configura extracciones programadas a intervalos razonables—nunca demasiado frecuentes.
- Documenta: Guarda registro de qué, cuándo y por qué extrajiste los datos.
La interfaz de Thunderbit te avisará en cada paso si hay consideraciones de cumplimiento, para que nunca vayas a ciegas.
Descubre más sobre las funciones de cumplimiento de Thunderbit
Conclusión y recomendaciones clave: aprovecha el valor de los datos de forma segura y legal
El 웹 스크래퍼 es una herramienta poderosa para el crecimiento empresarial, pero no es un “todo vale”. El marco legal es complejo, pero los principios básicos son claros:
- Extrae datos públicos y no personales para uso interno siempre que sea posible.
- Revisa siempre los términos del sitio, robots.txt y las leyes aplicables antes de empezar.
- Evita extraer datos personales o contenido creativo salvo que tengas base legal y un plan de privacidad.
- Utiliza herramientas como Thunderbit que te guíen y minimicen riesgos.
- Documenta tu proceso y prepárate para detenerte si te lo piden.
Si haces del cumplimiento un hábito, podrás aprovechar el valor de los datos web sin dolores de cabeza legales. Y si quieres comprobar lo fácil que puede ser extraer datos cumpliendo la normativa, prueba Thunderbit. Tu equipo legal (y tu yo del futuro) te lo agradecerán.
Para más artículos sobre web scraping, cumplimiento y automatización, visita el Blog de Thunderbit.
Prueba AI Web Scraper para extracción de datos conforme Get Started Free
Preguntas frecuentes
1. ¿Es legal extraer datos de cualquier sitio web?
No siempre. Extraer datos públicos y no personales para uso interno suele ser legal en muchas regiones, pero extraer datos personales, contenido protegido o información tras un login puede ser arriesgado o directamente ilegal. Revisa siempre los términos del sitio y la legislación local antes de extraer datos (Thunderbit Blog).
2. ¿Cuál es la diferencia entre extraer y reutilizar datos?
Extraer es recolectar datos; reutilizar es publicarlos, venderlos o distribuirlos. El uso interno es mucho más seguro. Republicar o vender datos extraídos puede generar reclamos de derechos de autor, bases de datos o incumplimiento de contrato (Thunderbit Blog).
3. ¿Cómo ayuda Thunderbit a garantizar el cumplimiento?
Thunderbit solo extrae lo que ves en tu navegador, te avisa sobre sitios de riesgo, sugiere campos relevantes (no sensibles) y ajusta la velocidad para no sobrecargar servidores. Además, no almacena tus datos y sus opciones de exportación están pensadas para uso interno (Thunderbit Blog).
4. ¿Qué debo hacer si recibo una carta de cese y desista?
Detén la extracción de inmediato y reevalúa tu proyecto. Continuar tras una petición directa puede convertir una zona gris legal en una violación clara de leyes anti-hackeo o de contrato (Thunderbit Blog).
5. ¿Puedo extraer datos personales si son públicos?
No sin una base legal. Las leyes de privacidad como el RGPD y la CCPA se aplican incluso a datos personales públicos. Necesitarás consentimiento o un interés legítimo sólido, y deberás gestionar los datos de forma responsable (Thunderbit Blog).
Esta guía es solo informativa y no constituye asesoría legal. Para proyectos complejos o de alto riesgo, consulta a un abogado especializado en datos y privacidad en tu jurisdicción.
Lee más




