

Hace unos meses, uno de nuestros usuarios hizo una pregunta que me dejó a mitad de un sorbo de café: "Si extraigo precios públicos de productos de Coupang, ¿acabaré en un tribunal coreano?" Sinceramente, no tenía una respuesta corta y segura, y tampoco la tenían la mayoría de las guías legales que encontré en internet.
Esa pregunta se me quedó grabada porque es la misma que miles de responsables de e-commerce, equipos de ventas y fundadores de SaaS buscan en Google cada semana sin decirlo en voz alta. El mercado global de servicios de web scraping alcanzó aproximadamente 1.030 millones de USD en 2024 y crece con rapidez. Cada vez más empresas recopilan datos web, y cada vez más se preguntan dónde están los límites legales en Corea. Corea no prohíbe el scraping de forma absoluta.
Pero hay cuatro leyes principales que pueden aplicarse según qué extraigas, cómo lo hagas y para qué. El caso clave que todo el mundo cita es la sentencia del Tribunal Supremo de Corea en el caso Yanolja (2021Do1533, resuelto el 12 de mayo de 2022), que absolvió a una herramienta de scraping de la competencia de los cargos penales y luego, en una vía civil separada, condenó a la misma empresa a pagar cerca de 1.000 millones de KRW en daños y perjuicios. Ese doble resultado es lo más importante que un no abogado necesita entender sobre la legislación coreana de scraping, y es la base de esta guía. No hace falta un título de Derecho: solo un marco práctico de riesgo que puedas usar de verdad.
Dificultad: Principiante (no se necesita experiencia legal ni técnica)
Tiempo necesario: ~15 minutos de lectura; consulta de referencia continua
Qué necesitas: Una comprensión básica de lo que hace el web scraping (si necesitas repasar, mira nuestro artículo sobre qué es el web scraping)
¿Es legal el web scraping en Corea? La respuesta corta
El web scraping en sí no es ilegal en Corea. Es una tecnología neutral, como un navegador web o una fórmula de hoja de cálculo. Los tribunales coreanos se han centrado siempre no en la herramienta, sino en la conducta que rodea su uso.
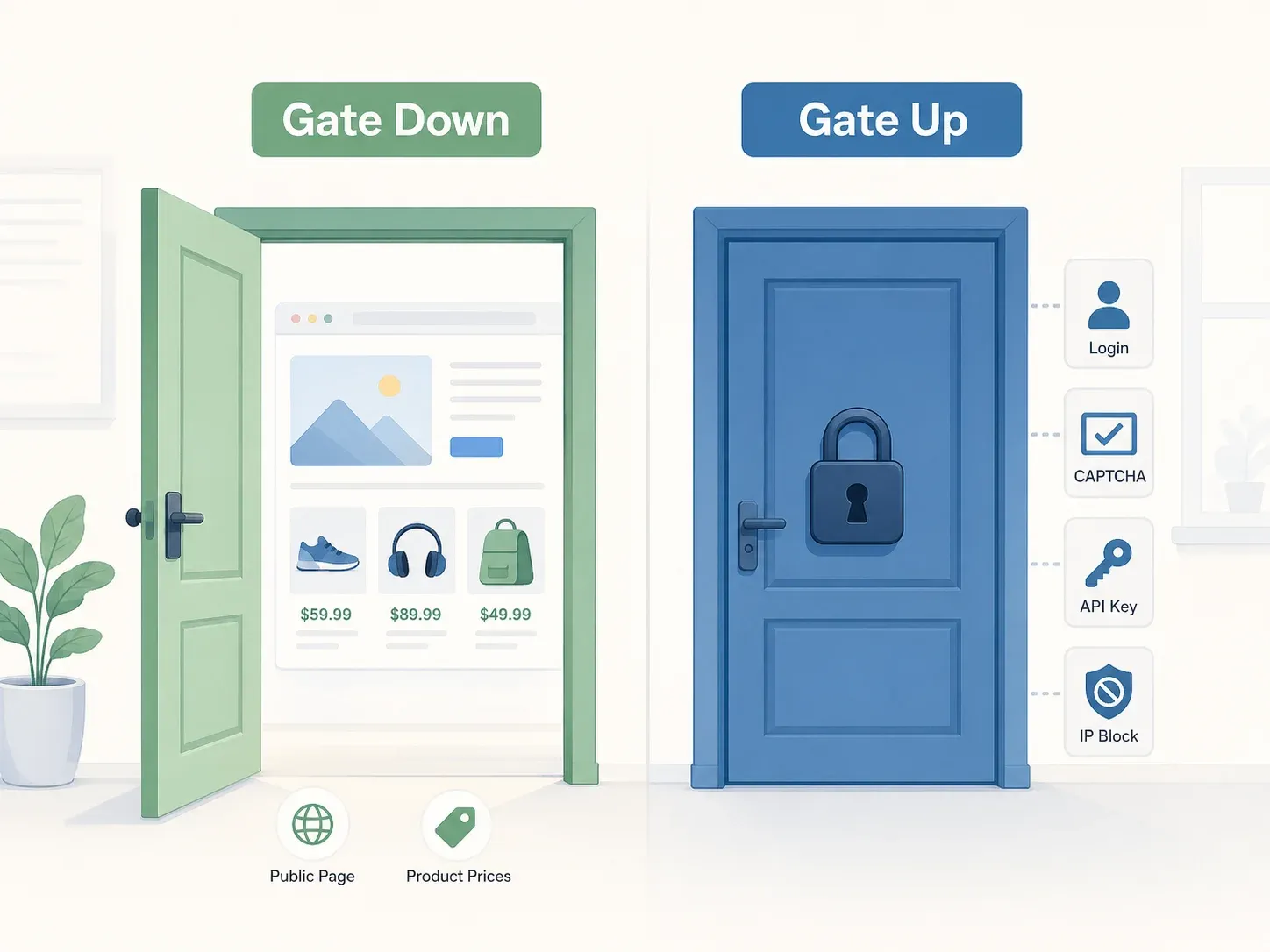
La mejor forma de entenderlo viene de la decisión del Tribunal Supremo en el caso Yanolja: el principio de "puerta arriba vs. puerta abajo". Si un sitio web no tiene restricciones objetivas de acceso —sin muro de inicio de sesión, sin CAPTCHA, sin requisito de clave API, sin bloqueo de IP—, la puerta está "abajo" y acceder a datos disponibles públicamente no suele constituir un delito penal según la Ley de Redes de Información y Comunicaciones de Corea (ICNA). El Tribunal examinó específicamente si las "medidas de protección, las condiciones de uso y otras circunstancias objetivamente reveladas" restringían el acceso, y concluyó que el servidor API de Yanolja era accesible libremente a través de la app pública.
Pero "no penal" no significa "sin riesgo".
La responsabilidad civil es otra historia. Puedes evitar una acusación penal y aun así enfrentarte a una indemnización de mil millones de wones. El caso Yanolja lo dejó clarísimo.
Cuatro leyes coreanas pueden aplicarse al web scraping:
- ICNA (Ley de Redes de Información y Comunicaciones) — la norma de "no entrar sin permiso"
- Ley de Copyright — derechos del productor de bases de datos
- PIPA (Ley de Protección de Información Personal) — reglas sobre la recopilación de datos personales
- UCPA (Ley de Prevención de la Competencia Desleal) — la cláusula general de "no aprovecharse del esfuerzo ajeno"
El resto de esta guía relaciona estas leyes con situaciones reales para que puedas averiguar en qué punto cae realmente tu proyecto de scraping.
Marco de riesgo verde-amarillo-rojo para el web scraping en Corea
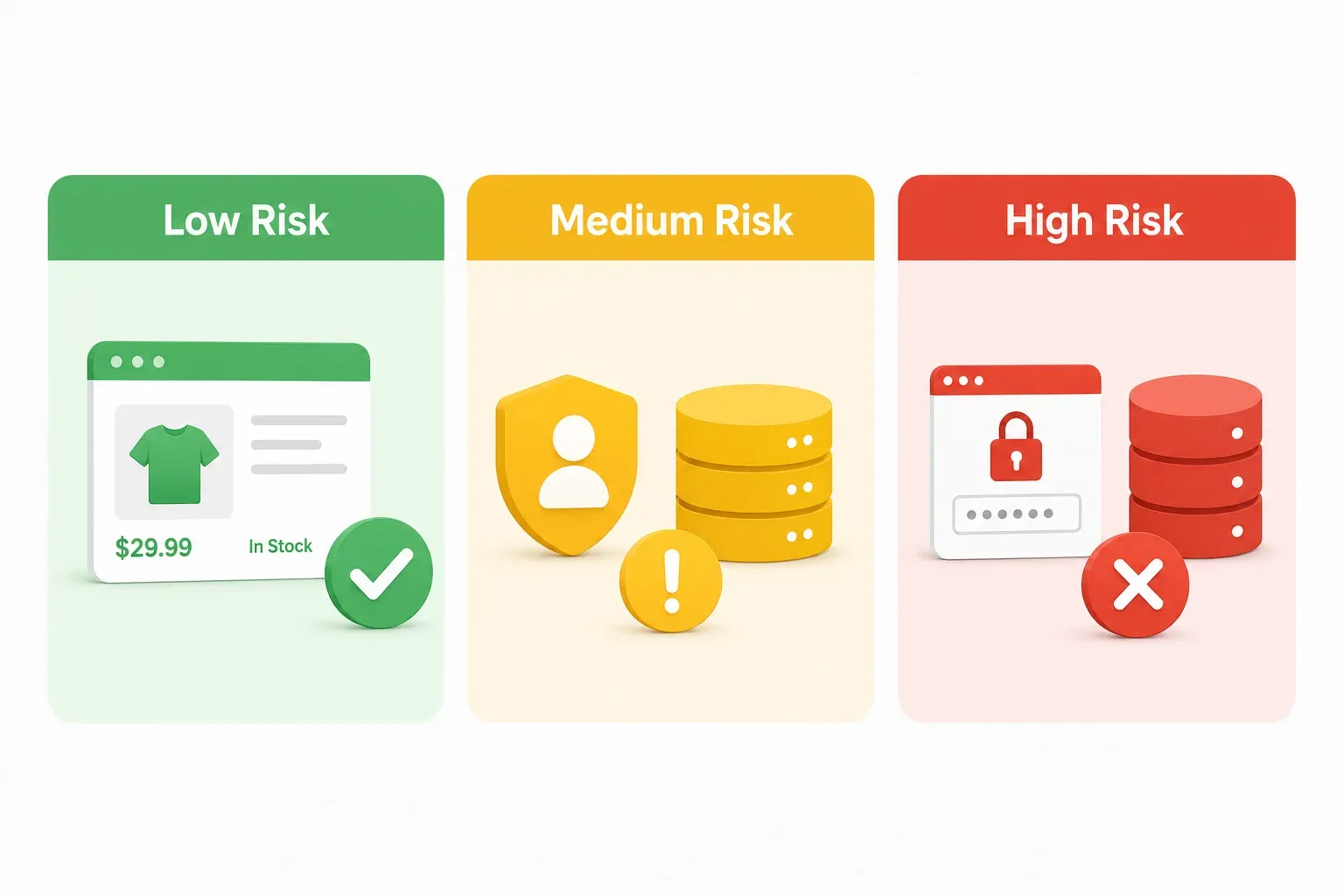
Todos los artículos legales que encontré sobre scraping en Corea parecen escritos para abogados. Si eres responsable de operaciones de e-commerce o fundador de una startup SaaS, no necesitas un análisis normativo de 40 páginas: necesitas una forma rápida de evaluar el riesgo antes de empezar un proyecto. Piensa en esto como un semáforo. Verde significa seguir adelante (con la cautela habitual). Amarillo significa bajar la velocidad y mirar por los retrovisores. Rojo significa parar y llamar a un abogado.
Zona verde: escenarios de scraping de bajo riesgo
| Escenario | Nivel de riesgo | Ley o leyes clave | Por qué |
|---|---|---|---|
| Extraer listados públicos de productos (sin inicio de sesión ni CAPTCHA) | 🟢 Bajo | ICNA, Ley de Copyright | La sentencia Yanolja: sin restricción de acceso = sin infracción de la ICNA; los datos fácticos (precios, disponibilidad) no son expresión creativa |
| Extraer precios públicos solo para análisis interno | 🟢 Bajo | UCPA, Ley de Copyright | Datos fácticos, alcance limitado, sin redistribución competitiva |
| Recopilar hechos públicos sin carácter personal ni copyright de páginas públicas | 🟢 Bajo | ICNA, Ley de Copyright | No se elude ninguna barrera de acceso; los hechos individuales no están protegidos |
La decisión penal del caso Yanolja es el ancla de esta zona. El Tribunal Supremo concluyó que no hubo intrusión según la ICNA porque el servidor API era libremente accesible: los usuarios normales podían acceder a él mediante la app, con o sin membresía, y no existían medidas técnicas separadas que bloquearan el acceso a la API.
Para los usuarios de Thunderbit, este es el punto ideal. Si estás extrayendo páginas públicas de e-commerce o inmobiliarias usando el modo de scraping en la nube —recopilando nombres de productos, precios, disponibilidad o metadatos de listados y excluyendo campos de datos personales—, normalmente estás operando en la zona verde. (Eso sí, "normalmente" no significa "siempre", y más abajo explico los matices.)
Prueba Thunderbit para extraer datos públicos
Zona amarilla: escenarios de scraping de riesgo medio
| Escenario | Nivel de riesgo | Ley o leyes clave | Por qué |
|---|---|---|---|
| Extraer datos personales (nombres, correos electrónicos, números de teléfono) incluso desde páginas públicas | 🟡 Medio | PIPA, ICNA | La PIPA se aplica aunque sean visibles públicamente; las enmiendas de 2023 endurecieron las reglas de consentimiento |
| Extraer grandes volúmenes que puedan constituir una "parte sustancial" de la base de datos de un competidor | 🟡 Medio | Ley de Copyright, UCPA | Prueba cuantitativa y cualitativa según la ley coreana |
| Ignorar señales de robots.txt | 🟡 Medio | Indicio de mala fe | No es delito por sí mismo, pero puede usarse en tu contra en un juicio |
| Extraer datos públicos pero utilizarlos para competir directamente con la fuente | 🟡 Medio | UCPA | Aprovecharse de la inversión de otra plataforma |
Los datos personales son, con diferencia, el principal desencadenante de la zona amarilla.
Aunque un número de teléfono o un correo electrónico sean visibles en una página pública, la PIPA sigue aplicándose. La reforma de la PIPA de 2023 amplió los derechos de los titulares de los datos y endureció los requisitos de consentimiento. Y en 2024, la Comisión de Protección de Información Personal de Corea (PIPC) publicó una guía específica sobre información personal disponible públicamente en el contexto de la IA y la recopilación de datos, dejando claro que la mera accesibilidad pública no equivale a permiso general.
El volumen también importa. El Tribunal Supremo en el caso Yanolja dijo que tanto los factores cuantitativos como los cualitativos determinan si has copiado una "parte sustancial" de una base de datos. Compara la parte copiada con toda la base de datos y pregúntate si refleja la inversión sustancial del productor.
Zona roja: escenarios de scraping de alto riesgo
| Escenario | Nivel de riesgo | Ley o leyes clave | Por qué |
|---|---|---|---|
| Extraer contenido detrás de un muro de inicio de sesión o eludir controles de acceso | 🔴 Alto | ICNA Art. 48 | "Puerta arriba" = acceso no autorizado; alto riesgo de persecución penal |
| Eludir CAPTCHAs, bloqueos de IP o sistemas de detección de bots | 🔴 Alto | ICNA Art. 48(4) | La enmienda de 2024 apunta específicamente a herramientas/dispositivos de evasión |
| Copiar y revender la base de datos completa de un competidor | 🔴 Alto | Ley de Copyright (derechos de bases de datos), UCPA | Reproducción sustancial + aprovechamiento comercial gratuito |
| Recopilar información personal sin base legal para marketing o prospección | 🔴 Alto | PIPA | Hasta 5 años / multa de 50 millones de KRW; sanciones administrativas de hasta el 3% de los ingresos |
Una adición de 2024 a la ICNA —el artículo 48(4)— prohíbe ahora específicamente instalar, transferir o distribuir programas o dispositivos técnicos que eludan los "procedimientos normales de protección o autenticación" sin una razón legítima.
Por separado, una sentencia del Tribunal Supremo de noviembre de 2024 (2021Do5555) reforzó que puede existir una intrusión no autorizada en la red incluso sin destrucción física de las medidas de protección. Usar los identificadores de otra persona o comandos impropios para esquivar límites de acceso es suficiente.
Las cuatro leyes coreanas que se aplican al web scraping
| Ley | Qué protege | Cuándo entra en juego para el scraping |
|---|---|---|
| ICNA artículo 48 | Estabilidad de la red, autoridad de acceso | Eludir inicio de sesión, CAPTCHA, autenticación, bloqueos de IP, límites de clave API |
| Ley de Copyright (art. 93) | Obras creativas + derechos del productor de bases de datos | Copiar contenido expresivo, imágenes o todo/parte sustancial de una base de datos |
| PIPA | Información personal, derechos del titular de los datos | Recopilar nombres, teléfonos, correos electrónicos, identificadores — incluso desde páginas públicas |
| UCPA (art. 2(1)(k) y (m)) | Competencia leal, datos de valor comercial | Aprovechar la inversión en datos de otra plataforma para tu propio negocio competidor |
ICNA artículo 48: la norma de "no entrar sin permiso"
El artículo 48(1) de la ICNA establece que nadie debe entrar en una red de información y comunicaciones "sin autoridad legítima de acceso o más allá de la autoridad de acceso permitida". En términos de scraping: si el sitio web tiene restricciones de acceso que eludes, estás infringiendo la norma. Si no hay restricciones —página pública, sin inicio de sesión—, probablemente estés dentro de lo permitido.
La sanción por infringirla puede llegar a cinco años de prisión o una multa de hasta 50 millones de KRW según el artículo 71 de la ICNA.
Un matiz importante: el Tribunal Supremo de Corea ha tratado de forma consistente las restricciones de las Condiciones de Servicio como algo distinto de las restricciones de acceso. En el caso de Yanolja, las condiciones de la app limitaban la reutilización comercial y prohibían programas automatizados que cargaran el servidor, pero el Tribunal concluyó que esas cláusulas no restringían objetivamente el acceso al propio servidor API.
Ley de Copyright: derechos del productor de bases de datos
La Ley de Copyright de Corea protege a los productores de bases de datos de forma separada del copyright sobre el contenido individual. Según el artículo 93, reproducir "todo o una parte sustancial" de una base de datos es ilegal, incluso si cada dato aislado es un hecho público.
La prueba es cuantitativa (¿cuánto copiaste en relación con el conjunto?) y cualitativa (¿la parte copiada refleja la inversión sustancial del productor en construir, verificar o mantener la base de datos?). La copia repetida o sistemática de porciones pequeñas también puede contar si, en la práctica, logra el mismo resultado que copiar una parte sustancial.
La pena por infracción de los derechos del productor de bases de datos es de hasta tres años o 30 millones de KRW según el artículo 136(2)(3). Los daños estatutarios del artículo 125-2 permiten hasta 10 millones de KRW por obra, o 50 millones de KRW por obra en caso de infracción dolosa con fines de lucro.
PIPA: Ley de Protección de Información Personal
La PIPA regula la recopilación de datos personales —nombres, información de contacto, identificadores— incluso si son visibles públicamente. La reforma de 2023 fue importante: amplió los derechos de los titulares de los datos, endureció los requisitos de consentimiento, introdujo reglas sobre la toma de decisiones automatizada y fijó sanciones administrativas de hasta el 3% de las ventas totales para infracciones concretas.
La guía de 2024 de la PIPC sobre IA y datos públicos menciona de forma expresa los datos obtenidos mediante "web crawling and scraping" en el contexto de la información personal disponible públicamente. La guía aclara que el interés legítimo puede servir como base en algunos contextos, pero las organizaciones necesitan ponderación, medidas de seguridad, protección de derechos y gobernanza.
Y la tendencia se está endureciendo. En marzo de 2026, la prensa coreana informó de una enmienda a la PIPA que eleva las sanciones máximas por fallos graves y repetidos en filtraciones de datos hasta el 10% de los ingresos, con entrada en vigor más adelante en 2026.
UCPA: la cláusula general de competencia desleal
La UCPA es la ley que atrapó a GC Company en el caso civil de Yanolja. La ley vigente contiene dos disposiciones relevantes:
- Artículo 2(1)(k): cubre usos desleales de datos técnicos o empresariales acumulados y gestionados electrónicamente que no sean secretos
- Artículo 2(1)(m): la cláusula general más amplia para usar, sin permiso y contra las prácticas comerciales justas, los resultados de otra persona obtenidos mediante una inversión o esfuerzo sustanciales, para el propio negocio
La UCPA es solo civil en estas disposiciones —sin sanción penal—, pero puede dar lugar a medidas cautelares según el artículo 4, daños y perjuicios según el artículo 5, e incluso daños triples en casos dolosos concretos según el artículo 14-2. El caso civil de Yanolja concedió alrededor de 1.000 millones de KRW con este marco.
El caso Yanolja: por qué puedes ganar en lo penal pero perder en lo civil
Este es el caso que cualquier usuario empresarial en Corea necesita entender. Voy a contarlo como una sola historia, porque así ocurrió realmente, y porque el resultado dividido es precisamente la clave.
Qué ocurrió: GC Company extrajo datos de viajes de Yanolja
GC Company operaba una plataforma online de viajes competidora. Desarrolló un rastreador propio que accedía al servidor API de la app Baro Reservation de Yanolja, descubría las URL de la API y los comandos de solicitud y los enviaba al servidor. El scraper recopiló información de alojamientos —nombres de socios, direcciones, precios, disponibilidad e imágenes—. GC Company usó estos datos internamente para marketing y posicionamiento competitivo.
Yanolja presentó tanto una denuncia penal como una demanda civil.
Veredicto penal: inocente en todos los cargos (Tribunal Supremo 2021Do1533)
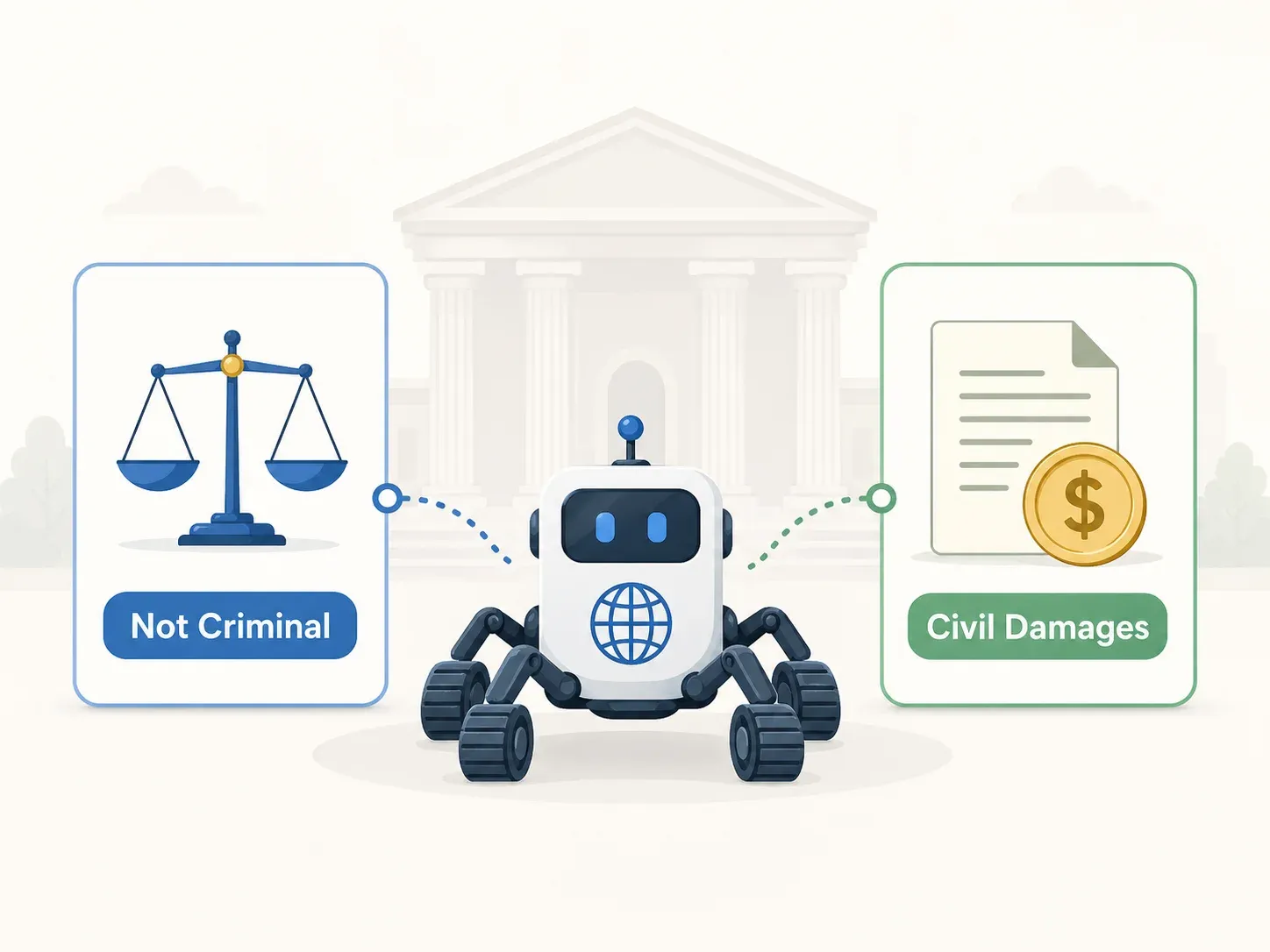
El Tribunal Supremo confirmó la absolución dictada por la corte de apelación el 12 de mayo de 2022 respecto de los tres cargos:
- ICNA artículo 48 (intrusión): no existían restricciones de acceso. El servidor API era accesible públicamente desde el navegador y la app móvil. No había bloqueos técnicos. Las cláusulas de las condiciones de uso limitaban el uso, no el acceso.
- Ley de Copyright (derechos del productor de bases de datos): los acusados no reprodujeron "todo o una parte sustancial" de la base de datos. Los datos copiados ya eran públicos y las pruebas no demostraron que la parte copiada reflejara la inversión sustancial de Yanolja.
- Artículo 314 del Código Penal (interferencia empresarial): no se probó ninguna interrupción real del funcionamiento del servidor API de Yanolja. No hubo modificación de datos. No existió mens rea para interferencia empresarial.
La regla que merece citarse: las restricciones de acceso deben evaluarse mediante "medidas de protección, condiciones de uso y otras circunstancias objetivamente reveladas". Si la puerta está abajo, pasar por ella no es allanamiento.
Veredicto civil: 1.000 millones de KRW en daños bajo la UCPA
Aquí es donde la historia cambia. El Tribunal del Distrito Central de Seúl —y después el Tribunal Superior de Seúl (caso 2021Na2034740, resuelto el 25 de agosto de 2022)— consideró que GC Company infringió la cláusula general de la UCPA. El tribunal concedió aproximadamente 1.000 millones de KRW (~800.000 USD) en daños compensatorios y ordenó cesar toda duplicación adicional de datos.
La razón: la base de datos de alojamientos de Yanolja tenía valor comercial y reflejaba una inversión sustancial —recopilar, verificar y actualizar datos de alojamientos—. GC Company se aprovechó gratuitamente de esa inversión. La sentencia civil quedó firme en la instancia del Tribunal Superior de Seúl.
Idea práctica: una absolución penal no equivale a seguridad civil
Esta es la lección más contraintuitiva de toda la legislación coreana sobre scraping. Un acceso penalmente lícito no inmuniza frente a un uso comercialmente desleal. "¿Pueden acusarme?" y "¿Pueden demandarme?" son preguntas distintas y pueden tener respuestas opuestas.
Para usuarios empresariales: aunque tu método de scraping esté claramente en la zona verde a efectos penales, el uso que hagas de los datos —sobre todo si compite directamente con la fuente— determina tu riesgo civil.
Corea vs. EE. UU. vs. UE: comparación de las leyes de web scraping
No encontré ninguna guía que pusiera esto en una sola tabla, lo cual resulta sorprendente teniendo en cuenta cuántas empresas extraen datos a través de fronteras.
| Dimensión | Corea del Sur | Estados Unidos | UE / EEE |
|---|---|---|---|
| Ley principal | ICNA art. 48, Ley de Copyright | CFAA (18 U.S.C. §1030), leyes estatales | RGPD, Directiva sobre bases de datos (96/9/CE) |
| Caso emblemático | Yanolja v. GC Company (Tribunal Supremo 2021Do1533, 2022) | hiQ v LinkedIn (9th Cir. 2022), Van Buren v. US (2021) | Ryanair v PR Aviation (TJUE C-30/14, 2015) |
| Scraping de datos públicos | Legal si no hay barreras objetivas de acceso ("puerta abajo") | Legal según la lógica de hiQ (datos públicos); Van Buren limitó la CFAA | Depende de los derechos de base de datos, contrato, copyright, RGPD y la ley del Estado miembro |
| Reglas sobre datos personales | PIPA (enmendada en 2023): consentimiento o base legal | Sectoriales: CCPA (California), leyes estatales de privacidad | RGPD: consentimiento estricto / interés legítimo; multa máxima de 20 millones de € o el 4% de los ingresos globales |
| ¿Incumplir las ToS es un delito? | No (los tribunales sostienen que ToS ≠ infracción de la ICNA) | No (Van Buren 2021: ToS ≠ CFAA) | En general no, aunque puede haber incumplimiento contractual (Ryanair) |
| Protección de bases de datos | Derechos del productor de bases de datos en la Ley de Copyright | No hay derecho federal general sobre bases de datos | Derecho sui generis sobre bases de datos |
| Pena penal máxima | Hasta 5 años / 50 millones de KRW (ICNA) | Hasta 10 años / 250.000 USD (CFAA) | Varía según el Estado miembro |
Diferencias clave que importan para tu negocio
- Corea no tiene una excepción amplia de text and data mining (TDM) como la Directiva DSM de la UE. Si entrenas modelos de IA con datos coreanos extraídos, no cuentas con una exención legal específica.
- La cláusula general de la UCPA en Corea es más amplia y menos predecible que la ley estadounidense de competencia desleal. El resultado civil de Yanolja sería mucho más difícil de reproducir bajo la ley de EE. UU.
- Las tres jurisdicciones coinciden: violar solo las Condiciones de Servicio no es un delito penal.
- La protección de bases de datos en Corea es estatutaria (como en la UE), mientras que EE. UU. no tiene un derecho federal general sobre bases de datos. Eso da a los propietarios de plataformas coreanas más herramientas civiles.
- Si extraes datos a través de fronteras, se aplica la ley más estricta de entre las aplicables. Un proyecto que toque datos coreanos, estadounidenses y europeos necesita cumplir los tres regímenes.
Escenarios por sector: ¿es legal el web scraping en Corea para tu industria?
El perfil de riesgo cambia muchísimo según el sector, y ninguna guía que encontré mapea la ley coreana de scraping a verticales concretos. Así que lo reuní yo mismo.
E-commerce: seguimiento de precios y datos de productos

Extraer precios públicos de productos de Coupang, Gmarket o 11Street es el ejemplo más limpio de la zona verde: quédate con campos fácticos (precio, disponibilidad, nombre del producto), evita áreas de solo inicio de sesión, no eludas bloqueos técnicos y usa los datos internamente para benchmarking.
El riesgo aumenta cuando extraes descripciones de producto (contenido creativo → copyright), información de contacto de vendedores (PIPA), imágenes (copyright) o un catálogo completo (derechos del productor de bases de datos + UCPA).
No encontré una demanda coreana importante de scraping de e-commerce comparable a Yanolja. El precedente más desarrollado está en viajes y reclutamiento, pero la ausencia de demandas no equivale a ausencia de riesgo.
El programador de scraping de Thunderbit y el modo de scraping en la nube están pensados precisamente para este patrón: revisiones recurrentes de precios e inventario en páginas públicas, con AI Suggest Fields para que selecciones las columnas que quieres y excluyas los campos de datos personales.
Inmobiliario: listados de propiedades
El sector inmobiliario es, por naturaleza, territorio de zona amarilla. Los listados en plataformas como Zigbang o Naver Real Estate mezclan datos fácticos (precio, superficie, barrio) con nombres de agentes, teléfonos de oficina, móviles, fotos y bases de datos curadas de la plataforma.
Extraer detalles públicos de propiedades puede ser menos arriesgado. Pero recopilar columnas de contacto de agentes activa inmediatamente la PIPA, y extraer todos los listados de una región empieza a parecer copia sustancial de una base de datos.
Mitigación: excluye columnas personales, reduce el ámbito geográfico, documenta una finalidad empresarial legítima, respeta los límites de ritmo de solicitudes y evita reproducir un servicio competidor de anuncios. La IA de Thunderbit puede configurarse para extraer solo los campos inmobiliarios que necesitas —precio, metros cuadrados, ubicación— y omitir los datos de contacto personales.
Reclutamiento: ofertas de empleo
El reclutamiento es el sector de alto riesgo, sin rodeos. Corea tiene un precedente directo: JobKorea v. Saramin. Saramin extrajo la base de datos de ofertas de empleo de JobKorea y fue considerada responsable por infracción de derechos de base de datos y competencia desleal. Los datos de reclutamiento suelen combinar inversión de plataforma (listados curados y verificados), copia de bases de datos de gran volumen e información personal o de contacto de reclutadores.
Mi recomendación: por norma general, evita extraer una plataforma de empleo competidora para crear o enriquecer una base de datos rival. Si el caso de uso es limitado, obtén revisión legal antes de recopilar, minimiza el volumen, elimina contactos personales y no redistribuyas los resultados.
Referencia completa de sanciones: lo que arriesgas si el web scraping sale mal en Corea
| Ley coreana | Tipo de infracción | Pena penal máxima | Remedio civil/administrativo máximo | Cambio clave 2023–2026 |
|---|---|---|---|---|
| ICNA art. 48 | Acceso no autorizado / interferencia | 5 años / multa de 50 millones de KRW | Daños e indemnización + medida cautelar | 2024: se añadió el art. 48(4), dirigido a herramientas de evasión |
| Ley de Copyright (derechos de base de datos, art. 93) | Reproducción sustancial de la base de datos | 3 años / multa de 30 millones de KRW | Daños estatutarios de hasta 50 millones de KRW por obra (infracción dolosa con fines de lucro) | — |
| PIPA | Recopilación ilícita de datos personales | 5 años / multa de 50 millones de KRW | Sanción administrativa de hasta el 3% de las ventas totales; posible demanda colectiva | Reforma de 2023; guía de 2024 sobre IA y datos públicos; tendencia en 2026 hacia el 10% por filtraciones reiteradas |
| UCPA art. 2(1)(k)/(m) | Obtención / uso desleal de datos | Solo civil (sin sanción penal para la cláusula general) | Daños e indemnización + medida cautelar; daños triples en casos dolosos concretos | La Ley Marco de Datos de 2022 reforzó disposiciones |
| Código Penal art. 314 | Interferencia empresarial mediante medios tecnológicos | 5 años / multa de 15 millones de KRW | — | Yanolja: no se probó una interrupción real |
El punto crítico: las vías penal y civil funcionan de forma independiente. Puedes enfrentarte a ambas al mismo tiempo y ganar una mientras pierdes la otra.
Tu lista de verificación de 10 puntos para cumplir con el web scraping en Corea
Aquí tienes diez preguntas de sí/no que conviene repasar antes de empezar cualquier proyecto de scraping. Imprímela, añádela a favoritos, pégala en el monitor, lo que te funcione.
- ¿El sitio objetivo no requiere inicio de sesión para acceder a los datos que quieres? Si hace falta un inicio de sesión, un token o una cuenta, el riesgo se desplaza rápidamente hacia el artículo 48 de la ICNA.
- ¿No existen restricciones técnicas de acceso? CAPTCHAs, bloqueos de IP, claves API, límites de frecuencia y muros anti-bot son señales claras de zona roja.
- ¿Has revisado el robots.txt del sitio? No es jurídicamente vinculante por sí solo en la jurisprudencia coreana, pero sí sirve como prueba útil de las expectativas del sitio y de tu buena fe.
- ¿Estás recopilando algún dato personal? Si entran en alcance nombres, teléfonos, correos electrónicos, identificadores o datos de contacto individuales, hace falta un análisis de PIPA.
- ¿Estás copiando una "parte sustancial" de la base de datos del sitio? Pregunta tanto en términos cuantitativos como cualitativos: cuánto y si la parte copiada refleja la inversión de la fuente.
- ¿Has definido tu finalidad? El análisis interno implica menos riesgo que la redistribución o la creación de una base de datos competidora. (Aun así, Yanolja demuestra que el uso competitivo interno no es un escudo completo.)
- ¿Has documentado por escrito tu finalidad empresarial legítima? La documentación ayuda a la ponderación del interés legítimo en PIPA y sirve como prueba de buena fe.
- ¿Has eliminado o anonimizado los campos de datos personales antes de almacenarlos o usarlos? Excluir los datos de contacto suele sacar el scraping inmobiliario, de reclutamiento y de directorios del patrón más peligroso de la PIPA.
- ¿Estás usando intervalos razonables entre solicitudes? Evita sobrecargar el servidor: los riesgos del artículo 314 del Código Penal y del artículo 48(3) de la ICNA aumentan cuando el scraping perjudica el funcionamiento del servicio.
- ¿Has consultado a un abogado en Corea para proyectos de alto volumen, comerciales o transfronterizos? Pueden aplicarse a la vez la ley coreana y el RGPD, la privacidad estadounidense o las leyes de acceso informático.
⚠️ Aviso legal: Esta lista es orientativa, no asesoramiento jurídico. Consulta siempre a un abogado local en Corea para situaciones concretas.
Cómo ayuda Thunderbit a extraer sitios web coreanos de forma responsable
Transparencia total: trabajo en el equipo de marketing de Thunderbit. Pero de verdad creo que aquí la compatibilidad entre producto y normativa es útil, no solo un argumento de ventas.
Thunderbit está diseñado para los casos de uso de la zona verde que describe este artículo: extraer datos disponibles públicamente sin necesidad de iniciar sesión. Así es como encajan sus funciones con el marco de cumplimiento:
- Modo de scraping en la nube para sitios públicos: no hace falta iniciar sesión ni mantener una sesión local, y se permanece dentro de los límites de acceso público. Esto encaja con el principio de "puerta abajo" del caso Yanolja.
- AI Suggest Fields te permite definir exactamente qué columnas de datos extraer. ¿Necesitas precios y disponibilidad, pero no teléfonos de vendedores? Simplemente excluye las columnas personales. Es la forma más sencilla de evitar desencadenantes de PIPA.
- Programador de scraping para revisiones recurrentes de precios, inventario o listados a intervalos razonables: no hace falta bombardear un servidor con solicitudes constantes.
- Exportación gratuita de datos a Excel, Google Sheets, Airtable y Notion para flujos de trabajo de análisis interno.
- Scraping de subpáginas para enriquecer datos de listados públicos (por ejemplo, entrar en páginas individuales de productos para obtener especificaciones) sin acceder a áreas restringidas o solo con inicio de sesión.
- Adaptación de diseño con IA: el scraper relee la estructura del sitio en cada ejecución y se adapta a cambios de diseño sin selectores rígidos codificados.
Thunderbit admite uso multilingüe en decenas de idiomas, algo importante para equipos que trabajan con sitios en coreano. Puedes probarlo gratis a través de la extensión de Chrome de Thunderbit.
Ninguna herramienta elimina el riesgo legal. Pero una configuración responsable —páginas públicas, datos fácticos, campos personales excluidos, intervalos razonables— te mantiene dentro del marco de cumplimiento que describe este artículo.
Ideas clave sobre la legalidad del web scraping en Corea
Cinco cosas que merece la pena recordar:
- La tecnología de web scraping en sí es legal en Corea. El Tribunal Supremo lo confirmó en la decisión Yanolja.
- El riesgo depende del método de acceso (puerta arriba vs. puerta abajo), del tipo de datos (personales vs. fácticos) y del uso (interno vs. redistribución competitiva).
- Absolución penal ≠ seguridad civil. El caso Yanolja demuestra que puedes evitar una acusación pero aun así enfrentarte a daños por valor de miles de millones de wones.
- Cuando extraes datos públicos, no personales y fácticos para uso interno sin barreras de acceso, normalmente estás en la zona segura. Pero ese "normalmente" pesa: el alcance, el volumen y la finalidad importan.
- Consulta siempre a un abogado local en Corea para proyectos comerciales o de gran escala. Este artículo es orientativo, no asesoramiento jurídico.
Si quieres empezar a extraer sitios web coreanos de forma responsable, el plan gratuito de Thunderbit te permite probar el flujo de trabajo a pequeña escala. Para saber más sobre cómo funciona en la práctica el scraping con IA, consulta nuestras guías sobre web scraping con IA y web scraping sin programar. Y si quieres ver la herramienta en acción, nuestro canal de YouTube incluye tutoriales para casos de uso comunes.
Preguntas frecuentes
1. ¿Es legal extraer datos disponibles públicamente en Corea?
En general, sí a efectos penales: según la sentencia del Tribunal Supremo en Yanolja, acceder a datos de un sitio sin restricciones objetivas de acceso no infringe la ICNA. Aun así, puede existir responsabilidad civil bajo la UCPA o la Ley de Copyright, según el volumen, la inversión de la fuente y tu uso comercial de los datos.
2. ¿Pueden demandarme por web scraping en Corea aunque no sea un delito?
Sí. Las vías penal y civil son independientes. GC Company fue absuelta de todos los cargos penales, pero se le ordenó pagar aproximadamente 1.000 millones de KRW en daños civiles bajo la cláusula general de la UCPA. La absolución penal no protege frente a reclamaciones civiles.
3. ¿Violar las Condiciones de Servicio de un sitio hace que el scraping sea ilegal en Corea?
Los tribunales coreanos han sostenido de forma consistente que incumplir las ToS por sí solo no constituye un delito penal según la ICNA: el Tribunal distinguió entre restringir el uso (ToS) y restringir el acceso (barreras técnicas). Dicho esto, una violación de las ToS aún podría respaldar una reclamación civil por incumplimiento contractual o servir como prueba de mala fe en un análisis de competencia desleal.
4. ¿Cómo se compara la ley coreana de web scraping con la de EE. UU.?
Ambas jurisdicciones protegen el scraping de datos públicos (Yanolja en Corea, hiQ v. LinkedIn en EE. UU.) y ambas sostienen que incumplir las ToS por sí solo no es un delito penal (Van Buren en EE. UU.). La diferencia clave: Corea tiene una protección estatutaria más fuerte de las bases de datos y una cláusula general de competencia desleal más amplia que EE. UU., que no cuenta con un derecho federal general sobre bases de datos. Los propietarios de plataformas coreanas tienen más herramientas civiles contra los scrapers.
5. ¿Qué pasa si extraigo datos personales de sitios web coreanos?
La PIPA se aplica aunque la información sea visible públicamente. Recopilar información personal —nombres, números de teléfono, correos electrónicos— sin consentimiento u otra base legal es una infracción. La enmienda de 2023 a la PIPA reforzó estas protecciones, y la guía de 2024 de la PIPC sobre información personal disponible públicamente aborda específicamente el web crawling y el scraping. Las sanciones pueden llegar a 5 años de prisión, multas de 50 millones de KRW y sanciones administrativas de hasta el 3% de las ventas totales.
Prueba Thunderbit para un web scraping responsable Get Started Free
Más información




