
Internet está lleno de datos: tanta información que se ha vuelto el motor de los negocios modernos. Ya sea que trabajes en ventas, e-commerce, bienes raíces o simplemente quieras estar al tanto de la competencia, tener los datos correctos a la mano puede marcar la diferencia. Pero seamos realistas: nadie quiere perder horas copiando y pegando información de páginas web a hojas de cálculo. Aquí es donde entra el 웹 스크래퍼, y créeme, es mucho más fácil de lo que imaginas.
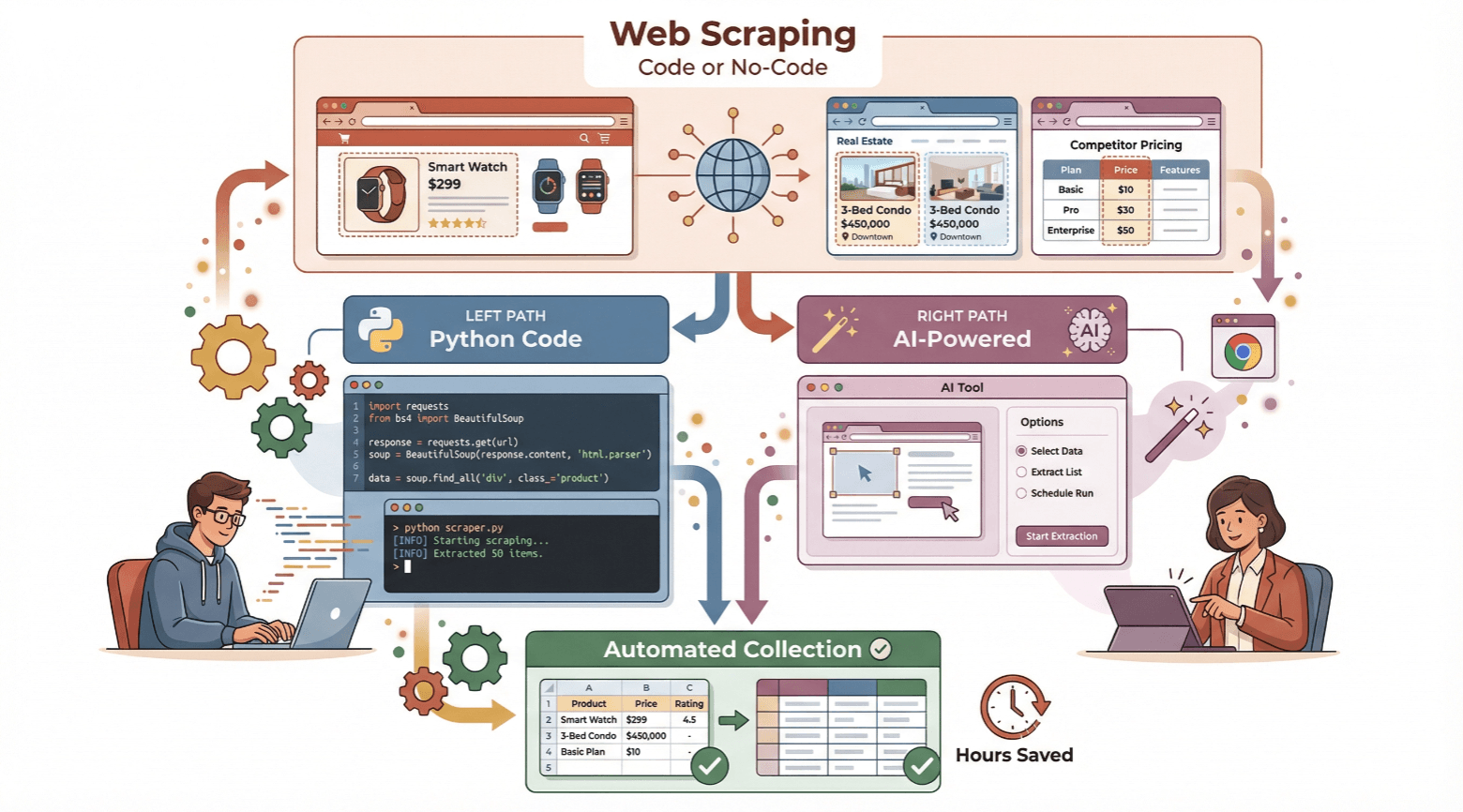
En esta guía te voy a mostrar cómo hacer y crear un 웹 스크래퍼, tanto si eres principiante y quieres probar con Python, como si prefieres evitar la programación y usar una herramienta sin código e impulsada por IA como . Te explicaré los conceptos básicos, te enseñaré ambos métodos paso a paso y te ayudaré a elegir el que mejor se adapte a lo que necesitas. ¿Listo para ahorrar tiempo y aprovechar la automatización de datos? ¡Vamos a ello!
¿Qué es un 웹 스크래퍼? Conceptos básicos
Un 웹 스크래퍼 es simplemente una herramienta—ya sea un software o un servicio—que extrae información de páginas web de forma automática. Imagina que necesitas una lista de todas las cafeterías de tu ciudad, con direcciones y teléfonos. Podrías pasar horas navegando y copiando cada dato a mano (el clásico Ctrl+C), o dejar que un 웹 스크래퍼 haga el trabajo pesado por ti.
Piensa en un 웹 스크래퍼 como un asistente digital que revisa páginas web, encuentra los datos que te interesan (precios, nombres de productos, contactos, etc.) y los organiza en una hoja de cálculo o base de datos. En vez de estar saltando entre el navegador y Excel, el 웹 스크래퍼 automatiza todo el proceso: consigue, analiza y guarda los datos en mucho menos tiempo.
Así funciona por dentro:
- Solicitud: El 웹 스크래퍼 manda una petición a la página y descarga el HTML.
- Análisis: Examina el HTML para encontrar los datos que buscas (por ejemplo, el precio dentro de una etiqueta
<span>). - Extracción: Saca la información y la guarda en un formato estructurado (CSV, Excel, Google Sheets, etc.).
Copiar y pegar a mano es como cavar con una cuchara. El 웹 스크래퍼 es como usar una excavadora.
Por qué crear un 웹 스크래퍼 es clave para tu negocio
El 웹 스크래퍼 ya no es solo para expertos o científicos de datos: hoy es imprescindible para cualquiera que necesite información confiable y actualizada. Casi el ya toman decisiones basadas en datos, y se espera que el mercado global de 웹 스크래퍼 se duplique para 2030.
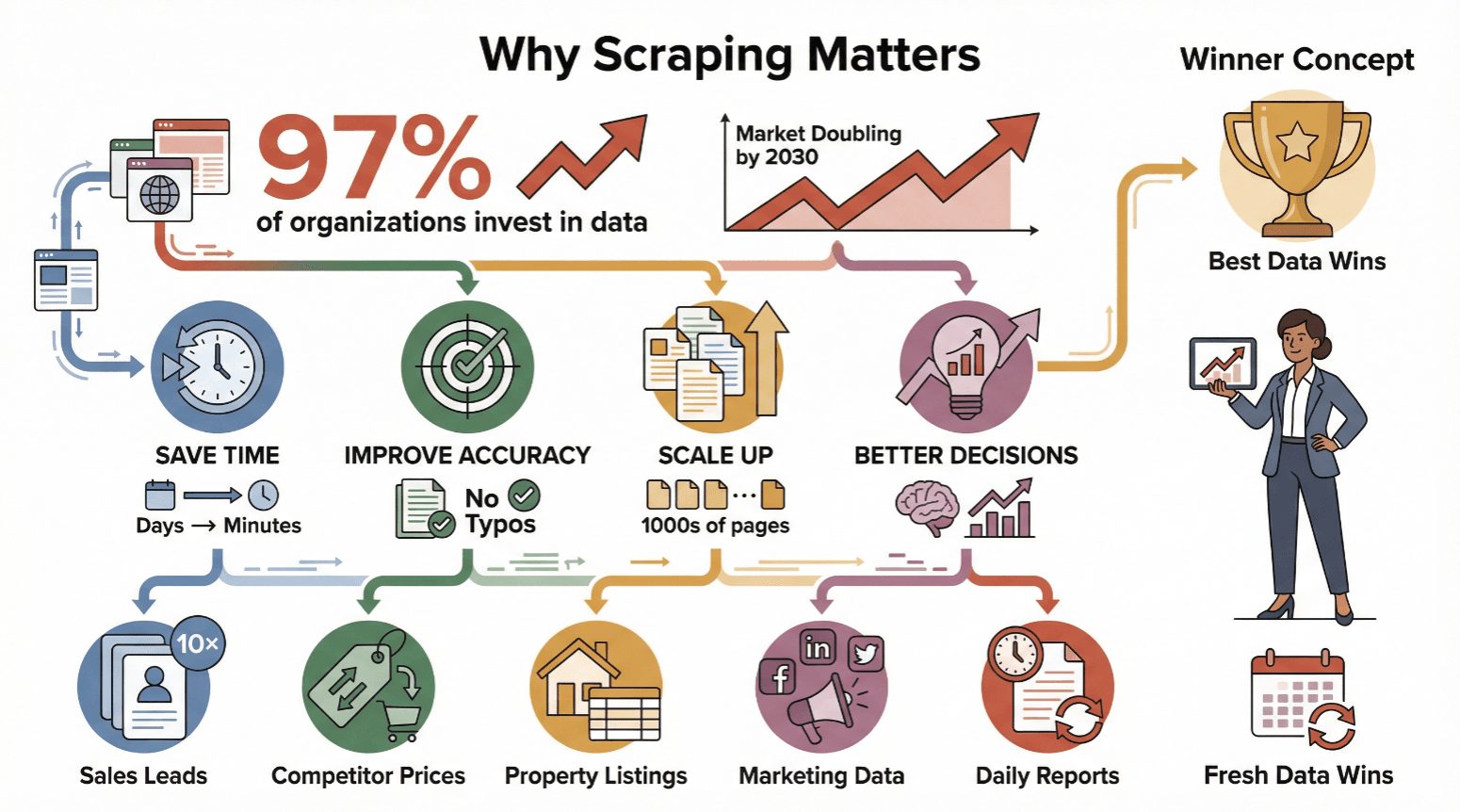
Estas son algunas razones por las que empresas de todos los tamaños apuestan por el 웹 스크래퍼:
- Ahorro de tiempo: Automatizar el raspado convierte días de trabajo manual en minutos.
- Mayor precisión: El software no se cansa ni comete errores de tipeo.
- Escalabilidad: Puedes extraer datos de miles de páginas, no solo unas pocas.
- Mejores decisiones: Datos frescos permiten ajustar precios, encontrar clientes potenciales o detectar tendencias a tiempo.
Mira estos ejemplos reales:
| Caso de uso | Quién se beneficia | Resultado típico |
|---|---|---|
| Extraer leads de ventas de directorios | Equipos de ventas | 10× más prospectos, horas ahorradas en búsqueda |
| Monitorizar precios de la competencia | Gestores de e-commerce | Ajustes de precios en tiempo real, protección de márgenes |
| Agregar anuncios inmobiliarios | Agencias inmobiliarias | Descubrimiento de oportunidades más rápido, datos de mercado actualizados |
| Recopilar datos de marketing de web/redes sociales | Equipos de marketing | Campañas mejor segmentadas, seguimiento de resultados |
| Automatizar reportes diarios de datos web | Operaciones, analistas | Menos costes laborales, menos errores, informes consistentes y puntuales |
En resumen: quien tiene los datos más frescos, gana.
Guía para principiantes: Cómo crear un 웹 스크래퍼 sencillo con Python
Si tienes curiosidad por saber cómo funciona el 웹 스크래퍼 "por dentro", Python es un excelente punto de partida. Incluso si nunca has programado, puedes crear un raspador básico en pocos pasos. Así se hace:
Preparando el entorno
Primero, instala Python en tu computador. Descarga la última versión desde y sigue las instrucciones según tu sistema operativo (Windows o Mac). No olvides marcar “Add Python to PATH” durante la instalación.
Luego, abre la terminal o consola de comandos e instala las librerías necesarias:
1pip install requests
2pip install bs4
3pip install pandasrequestssirve para obtener páginas web.bs4(Beautiful Soup) te ayuda a analizar el HTML.pandases ideal para guardar datos en CSV o Excel.
Analizando la estructura de la web
Antes de programar, necesitas saber dónde están los datos en el HTML. Abre la web objetivo en Chrome, haz clic derecho sobre el dato que quieres (por ejemplo, un título de empleo) y selecciona “Inspeccionar”. Verás resaltado el elemento HTML—quizá una etiqueta <a> con la clase jobtitle. Apunta estas etiquetas y clases; las usarás para indicarle al 웹 스크래퍼 qué buscar.
Escribiendo y ejecutando el 웹 스크래퍼
Supongamos que quieres extraer títulos de empleo y nombres de empresa de una página de ofertas. Aquí tienes un script sencillo:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4URL = "https://example.com/jobs" # Cambia por la URL que quieras
5response = requests.get(URL)
6soup = BeautifulSoup(response.text, 'html.parser')
7# Encuentra todos los títulos y empresas (ajusta los selectores según la web)
8titles = [t.get_text().strip() for t in soup.find_all('a', class_='jobtitle')]
9companies = [c.get_text().strip() for c in soup.find_all('div', class_='company')]
10# Guarda en CSV
11df = pd.DataFrame({'Título': titles, 'Empresa': companies})
12df.to_csv('empleos.csv', index=False)
13print("¡Raspado completo! Datos guardados en empleos.csv")- Ajusta la URL y los nombres de clase según tu web objetivo.
- Ejecuta el script en la terminal:
python tu_script.py - Abre
empleos.csvpara ver los resultados.
Tip: Para webs más complejas (con paginación o contenido dinámico), tendrás que añadir bucles o usar herramientas como Selenium. Pero para muchas páginas estáticas, este método es suficiente.
Sin código: Cómo crear un 웹 스크래퍼 con Thunderbit
¿Y si no quieres programar nada? Aquí es donde entra : un 웹 스크래퍼 sin código, potenciado por IA y pensado para usuarios de negocio. Con Thunderbit, puedes pasar de “necesito estos datos” a “aquí está mi hoja de cálculo” en solo dos clics.
Así funciona:
Paso 1: Instala la extensión de Chrome de Thunderbit
Ve a la y añádela a tu navegador. Regístrate gratis (el plan gratuito te deja probar con algunas páginas).
Paso 2: Accede a la web que quieres raspar
Abre la página que te interesa en Chrome. Inicia sesión si hace falta y desplázate para cargar todo el contenido dinámico.
Paso 3: Describe los datos que necesitas
Haz clic en el icono de Thunderbit para abrir la barra lateral. Puedes:
- Pulsar “Sugerir campos con IA” y dejar que la IA de Thunderbit analice la página y proponga columnas (como “Nombre del producto”, “Precio”, “Imagen”).
- O escribir una instrucción en español sencillo (por ejemplo, “Extraer todos los títulos de libros y autores de esta página”).
La IA de Thunderbit sugerirá automáticamente los campos y tipos de datos. Puedes renombrar, añadir o eliminar campos según lo que necesites.
Paso 4: Ejecuta tu primer raspado
Cuando tengas los campos listos, haz clic en “Raspar”. Thunderbit extraerá los datos, gestionará la paginación si hace falta y mostrará todo en una tabla ordenada. Si quieres más detalles de subpáginas (como fichas de productos), haz clic en “Raspar subpáginas”—Thunderbit visitará cada enlace y recopilará la información extra.
Paso 5: Revisa y exporta los resultados
Revisa tus datos en la tabla de Thunderbit. Cuando estés conforme, haz clic en “Exportar” y elige el formato: Excel, CSV, Google Sheets, Airtable, Notion o JSON. Las exportaciones son gratuitas e ilimitadas.
Así de fácil. Sin código, sin plantillas, sin complicaciones.
Comparativa: 웹 스크래퍼 tradicionales vs. sin código
Veamos cómo se comparan ambos métodos:
| Solución | Tiempo de configuración | Habilidades necesarias | Mantenimiento | Flexibilidad | Opciones de exportación |
|---|---|---|---|---|---|
| Python + Beautiful Soup | Horas/días | Programación, HTML básico | Alto (se rompe fácil) | Muy alta | CSV, Excel, JSON (por código) |
| Herramientas sin código antiguas | 30-60 min | Algo de conocimientos tech | Medio (arreglos manuales) | Buena para páginas estáticas | CSV, Excel |
| Thunderbit (IA sin código) | Minutos | Ninguna (español simple) | Bajo (la IA se adapta) | Alta (páginas dinámicas) | Excel, CSV, Sheets, Notion... |
El enfoque de Thunderbit, basado en IA, te permite dedicar menos tiempo a configurar y mantener 웹 스크래퍼, y más a aprovechar los datos.
Cómo superar los retos del 웹 스크래퍼 tradicional
Los 웹 스크래퍼 tradicionales suelen tener varios problemas conocidos:
- Cambios en la web: Si una página cambia su diseño, tu código puede dejar de funcionar. La IA de Thunderbit se adapta automáticamente a la mayoría de cambios, sin que tengas que reprogramar nada.
- Bloqueos anti-bots: Muchas webs bloquean scripts automáticos. Thunderbit puede ejecutarse en tu navegador (usando tu sesión) o en la nube para mayor velocidad.
- Contenido dinámico: Páginas con scroll infinito o botones “Cargar más” pueden ser un reto para los 웹 스크래퍼 básicos. Thunderbit gestiona el scroll automático y los elementos interactivos por defecto.
- Datos tras login: Con el modo navegador de Thunderbit, si puedes ver los datos en Chrome, puedes extraerlos.
En resumen, Thunderbit está pensado para lidiar con las complejidades de las webs modernas—para que tú no tengas que preocuparte.
Más eficiencia: Funciones avanzadas de Thunderbit para el 웹 스크래퍼
Thunderbit no solo te ayuda a conseguir datos, sino a obtenerlos rápido, limpios y listos para usar. Algunas de sus funciones top:
Paginación automática y raspado de subpáginas
¿Necesitas extraer cientos de productos en varias páginas? Thunderbit detecta la paginación (botones de siguiente, scroll infinito) y recopila todo de una vez. ¿Quieres más detalles de subpáginas? Haz clic en “Raspar subpáginas” y Thunderbit visitará cada enlace, trayendo campos extra (como información del vendedor o especificaciones).
Sugerencias de campos con IA y estructuración de datos
La IA de Thunderbit no solo adivina columnas: entiende el contexto. Puede etiquetar columnas, asignar tipos de datos (texto, número, imagen, email) e incluso aplicar instrucciones personalizadas (como “solo precios mayores a 100€” o “traducir descripciones al español”). Puedes añadir indicaciones para categorizar, resumir o reformatear los datos mientras se extraen.
Plantillas y raspado instantáneo
Para webs populares (Amazon, Zillow, Google Maps, Instagram), Thunderbit ofrece plantillas listas para usar: solo elige el sitio y los campos ya están configurados. Sin necesidad de ajustes.
Programación y automatización
¿Quieres datos frescos cada día? Programa una tarea (“cada lunes a las 9am”) y Thunderbit raspará automáticamente, actualizando tu Google Sheet o base de datos sin que tengas que intervenir.
Raspado en la nube o local
Elige entre ejecutar el raspado en tu navegador (ideal para webs con login o interactivas) o en la nube (más rápido para datos públicos—hasta 50 páginas a la vez).
Las funciones avanzadas de Thunderbit lo convierten en la opción favorita para empresas que buscan una solución confiable, escalable y fácil de usar.
Guía paso a paso: Cómo crear un 웹 스크래퍼 con Thunderbit
Aquí tienes un checklist rápido para arrancar:
- Instala Thunderbit: y regístrate.
- Abre la web objetivo: Inicia sesión si hace falta y desplázate para cargar el contenido.
- Abre la barra lateral de Thunderbit: Haz clic en el icono de la extensión.
- Describe los datos: Pulsa “Sugerir campos con IA” o escribe tu instrucción.
- Revisa los campos: Renombra, añade o elimina columnas según lo que necesites.
- Haz clic en “Raspar”: Deja que Thunderbit haga el trabajo.
- (Opcional) Raspa subpáginas: Para datos más profundos, haz clic en “Raspar subpáginas”.
- Revisa los resultados: Comprueba la tabla para verificar los datos.
- Exporta los datos: Elige Excel, CSV, Google Sheets, Notion, Airtable o JSON.
- Guarda/plantilla/programa: Guarda tu configuración para la próxima vez o programa raspados recurrentes.
Tips para resolver problemas:
- Si falta algún dato, prueba a reformular tu instrucción o usa indicaciones personalizadas.
- Para contenido dinámico, asegúrate de estar en modo navegador.
- Si llegas al límite del plan gratuito, considera actualizar para más páginas.
Conclusión y puntos clave
Crear un 웹 스크래퍼 ya no es solo para programadores. Tanto si quieres aprender Python como si prefieres que la IA haga el trabajo, hoy las herramientas son más accesibles que nunca.
Recuerda:
- El 웹 스크래퍼 ahorra tiempo, mejora la precisión y permite decisiones basadas en datos.
- Python es ideal para aprender y proyectos personalizados, pero requiere programación y mantenimiento.
- Thunderbit ofrece una solución rápida y sin código: solo describe lo que quieres y haz clic en “Raspar”.
- Funciones avanzadas como paginación automática, subpáginas y sugerencias de campos con IA hacen de Thunderbit una herramienta potente para empresas.
- Puedes probar Thunderbit gratis y ver resultados en minutos.
¿Listo para dejar de copiar y pegar y empezar a automatizar? y descubre lo fácil que puede ser el 웹 스크래퍼. Y si quieres aprender más, visita el para más tutoriales y consejos.
Preguntas frecuentes
1. ¿Necesito saber programar para crear un 웹 스크래퍼?
¡No! Aunque programar (por ejemplo, con Python y Beautiful Soup) te da control total, herramientas sin código como Thunderbit permiten a cualquiera crear potentes 웹 스크래퍼 usando instrucciones en español y unos pocos clics.
2. ¿Qué tipo de datos puedo extraer con Thunderbit?
Thunderbit puede extraer texto, números, imágenes, emails, teléfonos y más de casi cualquier web, incluyendo listas paginadas y subpáginas. También puedes usar plantillas para sitios populares.
3. ¿Cómo gestiona Thunderbit los cambios en el diseño de las webs?
La IA de Thunderbit se adapta automáticamente a la mayoría de cambios de diseño. A diferencia de los 웹 스크래퍼 tradicionales, que se rompen cuando una web se actualiza, Thunderbit usa comprensión semántica para seguir funcionando con mínimos ajustes.
4. ¿Es legal y seguro el 웹 스크래퍼?
El 웹 스크래퍼 es legal cuando se recopilan datos públicos y se respetan los términos de uso del sitio. Thunderbit fomenta el uso responsable y ofrece funciones para ayudarte a cumplir con las normas.
5. ¿Puedo programar raspados recurrentes o automatizar exportaciones?
¡Sí! Thunderbit te permite programar raspados con la frecuencia que quieras (diaria, semanal, etc.) y exportar los resultados directamente a Google Sheets, Notion, Airtable, Excel o CSV—sin trabajo manual.
¿Listo para automatizar la recopilación de datos? y comprueba lo fácil que es el 웹 스크래퍼 para todos.
Más información