
La web está creciendo a un ritmo que cuesta imaginar. En 2024, hablamos de más de 1.100 millones de sitios web, con 149 zettabytes de datos moviéndose por ahí (y se espera que el año que viene lleguemos a los 181 ZB). Eso son muchísimos menús de pizza, ¿no? Pero aquí viene lo curioso: solo cerca del 4% del contenido online está indexado por los buscadores. El resto está en la “deep web”, fuera del alcance de nuestras búsquedas normales. Entonces, ¿cómo hacen los buscadores y las empresas para orientarse en este caos digital? Aquí es donde entra el raspador web.
En esta guía te voy a contar qué es el web crawling, cómo funciona y por qué es clave—no solo para los techies, sino para cualquiera que quiera sacarle jugo al enorme mundo de los datos online. También te explicaré la diferencia entre web crawling y web scraping (créeme, no es lo mismo), veremos ejemplos reales y repasaremos soluciones tanto para quienes saben programar como para quienes no (incluyendo mi favorita, Thunderbit). Seas un curioso que empieza o un profesional buscando exprimir la web, aquí tienes lo que necesitas.
¿Qué es un Raspador Web? Entendiendo los Fundamentos del Web Crawling
Vamos a lo básico. Un raspador web (también llamado spider, bot o rastreador web) es un programa automático que navega por la web de forma sistemática, accediendo a páginas y siguiendo enlaces para descubrir contenido nuevo. Imagina un robot bibliotecario que empieza con una lista de libros (URLs), lee cada uno y sigue todas las referencias para encontrar más libros. Así funciona un raspador web—pero en vez de libros, son páginas web, y en vez de una biblioteca, es todo Internet.
La idea principal es:
- Arrancar con una lista de URLs (las “semillas”)
- Visitar cada página, descargar su contenido (HTML, imágenes, etc.)
- Buscar enlaces en esas páginas y sumarlos a la cola
- Repetir—visitar nuevos enlaces, descubrir más páginas, y así sucesivamente
La función principal de un raspador web es descubrir y catalogar páginas. En el caso de los buscadores, los raspadores copian el contenido de las páginas y lo mandan para ser indexado y analizado. En otros casos, los raspadores especializados pueden extraer datos concretos (aquí es donde entra el web scraping, pero eso lo vemos en un momento).
En resumen:
El web crawling es explorar y mapear la web, no solo extraer datos. Es la base de cómo buscadores como Google y Bing saben qué hay en Internet.
¿Cómo Funciona un Buscador? El Papel de los Raspadores
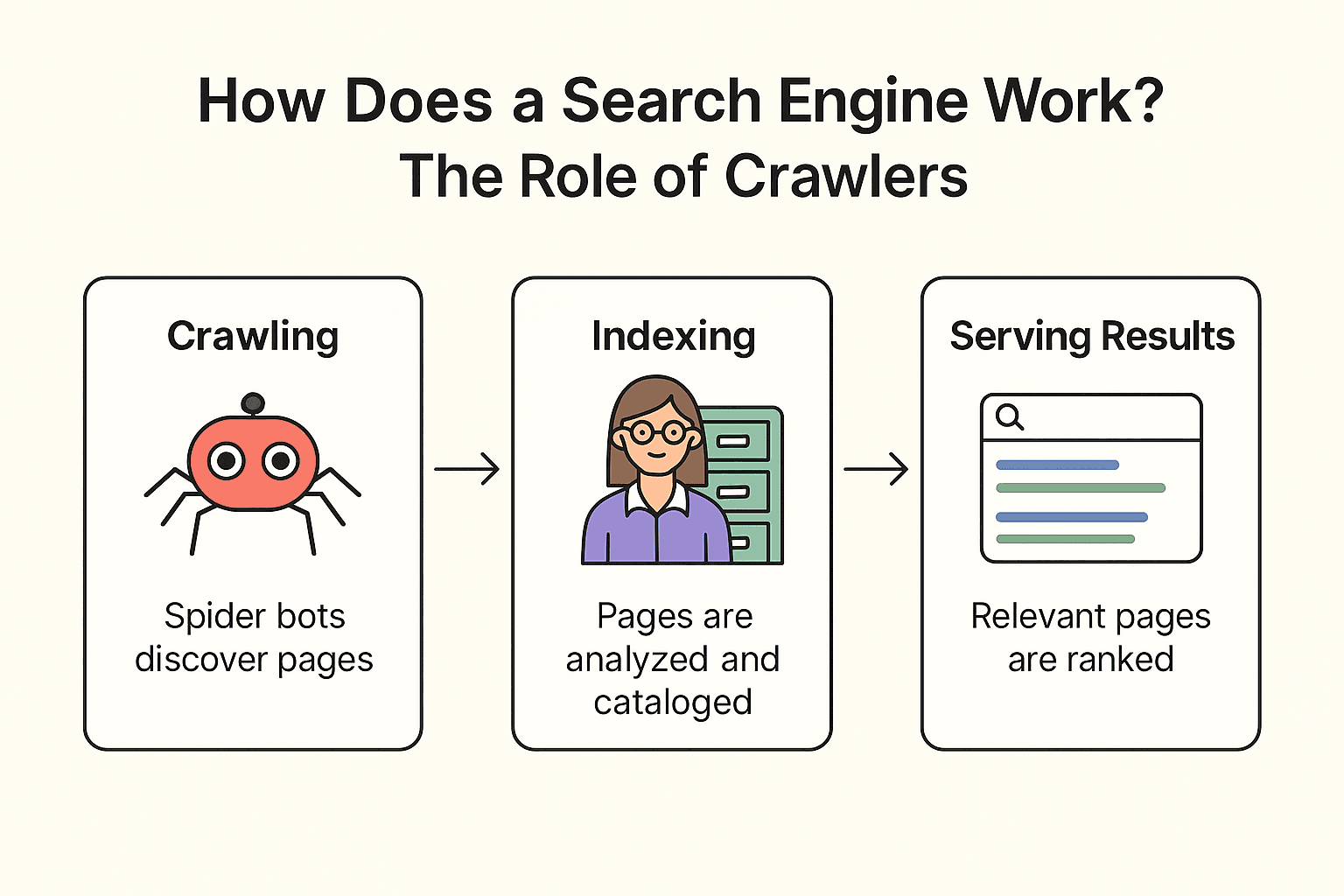
Entonces, ¿cómo funciona realmente Google (o Bing, o DuckDuckGo)? Es un proceso de tres pasos: crawling, indexación y mostrar resultados (Documentación oficial de Google).
Vamos con una analogía de biblioteca (porque, ¿a quién no le gustan las comparaciones con libros?):
-
Crawling:
El buscador manda sus “spider bots” (como Googlebot) a recorrer la web. Empiezan con páginas conocidas, sacan su contenido y siguen los enlaces para descubrir nuevas páginas—como un bibliotecario revisando cada estante y siguiendo las referencias para encontrar más libros.
-
Indexación:
Cuando encuentran una página, el buscador analiza su contenido, ve de qué trata y guarda la información clave en un catálogo digital gigante (el índice). No todas las páginas entran—algunas se saltan si están bloqueadas, son de baja calidad o son duplicadas.
-
Mostrar resultados:
Cuando buscas “mejor pizza cerca de mí”, el buscador consulta las páginas relevantes de su índice y las ordena según cientos de factores (palabras clave, popularidad, actualidad, etc.). El resultado: una lista ordenada de páginas web lista para que explores.
Dato curioso:
Los buscadores no rastrean todas las páginas de la web. Las páginas protegidas por login, bloqueadas por robots.txt o sin enlaces entrantes pueden no ser descubiertas nunca. Por eso, muchas empresas mandan sus URLs o sitemaps directamente a Google.
Web Crawling vs. Web Scraping: ¿En Qué se Diferencian?
Aquí es donde suele haber lío. Mucha gente usa “web crawling” y “web scraping” como si fueran lo mismo, pero en realidad son cosas distintas.
| Aspecto | Web Crawling (Rastreo) | Web Scraping |
|---|---|---|
| Objetivo | Descubrir e indexar la mayor cantidad de páginas posible | Extraer datos específicos de una o varias páginas web |
| Analogía | Bibliotecario catalogando todos los libros de una biblioteca | Estudiante copiando apuntes clave de algunos libros relevantes |
| Resultado | Lista de URLs o contenido de páginas (para indexar) | Conjunto de datos estructurados (CSV, Excel, JSON) con información concreta |
| Usado por | Motores de búsqueda, auditores SEO, archivadores web | Equipos de ventas, marketing, investigación, etc. |
| Escala | Masiva (millones/miles de millones de páginas) | Enfocada (decenas, cientos o miles de páginas) |
Consulta una comparación visual aquí.
En palabras simples:
- Web crawling es para encontrar páginas (mapear la web)
- Web scraping es para sacar los datos que te interesan de esas páginas (llevar la info a una hoja de cálculo)
La mayoría de los usuarios de negocio (sobre todo en ventas, ecommerce o marketing) están más interesados en el scraping—obtener datos estructurados para análisis—que en rastrear toda la web. El crawling es clave para buscadores y descubrimiento a gran escala, mientras que el scraping va directo a la extracción de datos concretos.
¿Por Qué Usar un Raspador Web? Aplicaciones Reales en Empresas
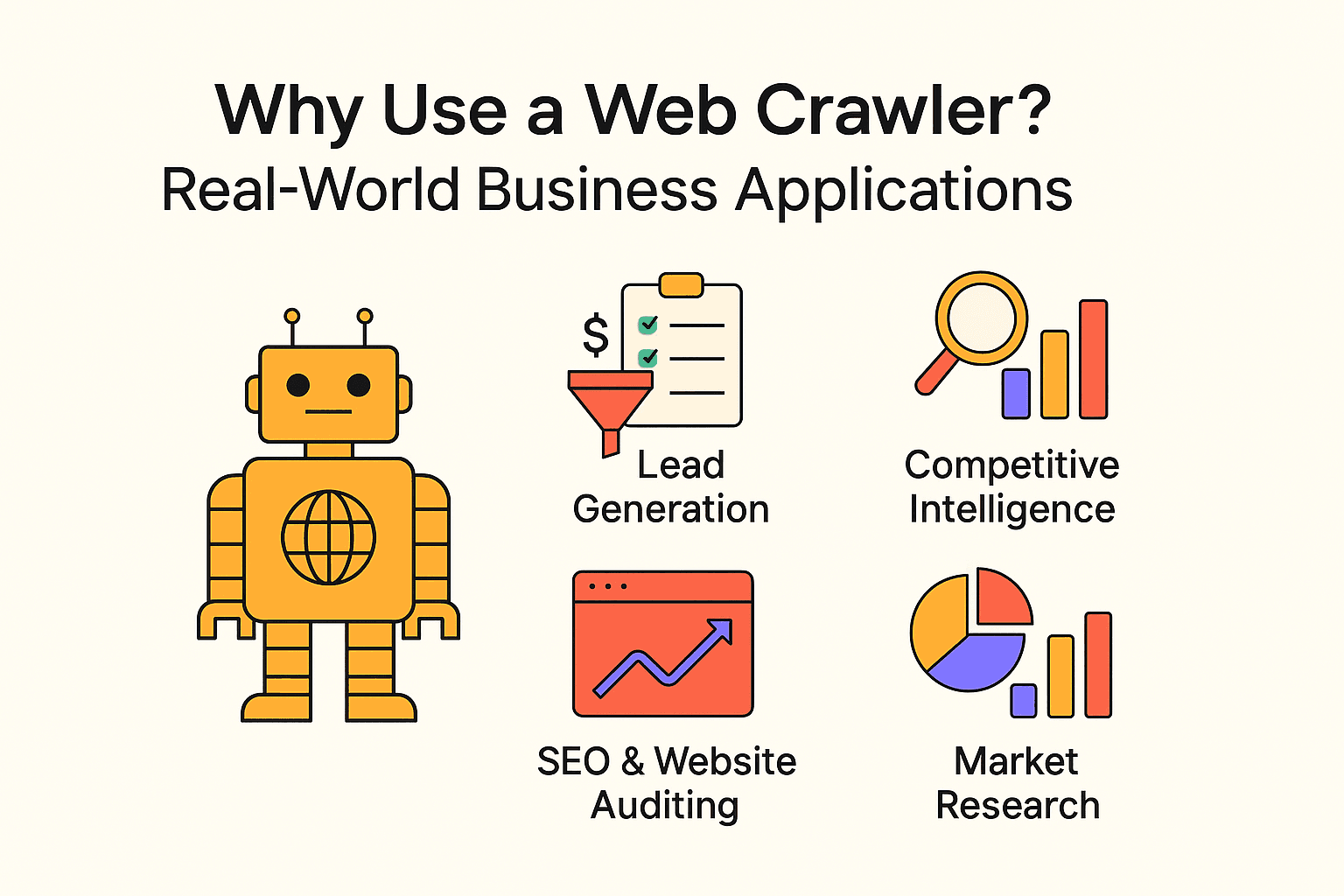
El web crawling no es solo para buscadores. Empresas de todos los tamaños usan raspadores y scraping para conseguir información valiosa y automatizar tareas repetitivas. Aquí tienes algunos ejemplos reales:
| Caso de uso | Usuario objetivo | Beneficio esperado |
|---|---|---|
| Generación de leads | Equipos de ventas | Automatizar la prospección, llenar el CRM con nuevos contactos |
| Inteligencia competitiva | Retail, e-commerce | Monitorizar precios, stock y cambios de productos de la competencia |
| SEO y auditoría web | Marketing, equipos SEO | Detectar enlaces rotos, optimizar la estructura del sitio |
| Agregación de contenido | Medios, investigación, RRHH | Recopilar noticias, ofertas de empleo o bases de datos públicas |
| Investigación de mercado | Analistas, equipos de producto | Analizar reseñas, tendencias o sentimiento a gran escala |
- Groupon duplicó sus leads entrantes automatizando la generación de prospectos con web crawling.
- El 82% de las empresas de e-commerce y el 71% de las firmas de servicios financieros dependen del web scraping para tomar decisiones.
- El web scraping puede reducir hasta un 90% los costes de infraestructura y ahorrar un 60% de tiempo frente a la recolección manual de datos.
En resumen: Si no aprovechas los datos web, seguro que tu competencia sí lo está haciendo.
Cómo Programar un Raspador Web en Python: Lo Básico
Si tienes algo de experiencia programando, Python es la mejor opción para crear raspadores a medida. El proceso básico es:
- Usar requests para descargar páginas web
- Usar BeautifulSoup para analizar el HTML y sacar enlaces/datos
- Escribir bucles (o recursividad) para seguir enlaces y rastrear más páginas
Ventajas:
- Máxima flexibilidad y control
- Permite lógica compleja, flujos de datos personalizados e integración con bases de datos
Desventajas:
- Hace falta saber programar
- El mantenimiento puede ser un lío: si la web cambia, tu script puede romperse
- Tienes que gestionar tú mismo los bloqueos anti-bots, los retrasos y los errores
Ejemplo sencillo de raspador en Python:
Aquí tienes un script básico que saca frases y autores de quotes.toscrape.com:
import requests
from bs4 import BeautifulSoup
url = "<http://quotes.toscrape.com/page/1/>"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for quote in soup.find_all('div', class_='quote'):
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
print(f"{text} --- {author}")
Para rastrear varias páginas, solo tienes que añadir lógica para encontrar el botón “Next” y repetir hasta que no haya más páginas.
Errores típicos:
- No respetar robots.txt o los tiempos de espera (no seas esa persona)
- Ser bloqueado por sistemas anti-bots
- Caer en bucles infinitos (como calendarios que nunca terminan)
Guía Paso a Paso: Cómo Crear un Raspador Web Básico en Python
Si te animas a programar, aquí tienes una guía rápida para montar un raspador sencillo.
Paso 1: Prepara tu Entorno de Python
Primero, asegúrate de tener Python instalado. Luego, instala las librerías necesarias:
pip install requests beautifulsoup4
Si tienes problemas, revisa tu versión de Python (python --version) y que pip funcione bien.
Paso 2: Escribe la Lógica Principal del Raspador
El patrón básico sería:
import requests
from bs4 import BeautifulSoup
def crawl(url, depth=1, max_depth=2, visited=None):
if visited is None:
visited = set()
if url in visited or depth > max_depth:
return
visited.add(url)
print(f"Crawling: {url}")
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Extraer enlaces
for link in soup.find_all('a', href=True):
next_url = link['href']
if next_url.startswith('http'):
crawl(next_url, depth + 1, max_depth, visited)
start_url = "<http://quotes.toscrape.com/>"
crawl(start_url)
Consejos:
- Limita la profundidad del rastreo para evitar bucles infinitos
- Lleva un registro de las URLs visitadas para no repetir
- Respeta robots.txt y añade pausas (time.sleep(1)) entre peticiones
Paso 3: Extrae y Guarda los Datos
Para guardar los datos, puedes escribir en un archivo CSV o JSON:
import csv
with open('quotes.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Quote', 'Author'])
# Dentro de tu bucle de rastreo:
writer.writerow([text, author])
O usa el módulo json de Python para guardar en formato JSON.
Consejos Clave y Buenas Prácticas para el Web Crawling
El web crawling es muy potente, pero conlleva responsabilidad (y el riesgo de que te bloqueen la IP). Aquí tienes cómo hacerlo bien:
- Respeta el robots.txt: Siempre revisa y cumple el archivo robots.txt del sitio. Indica qué está prohibido rastrear.
- Hazlo con calma: Añade pausas entre peticiones (al menos unos segundos). No sobrecargues los servidores.
- Limita el alcance: Rastrea solo lo necesario. Define límites de profundidad y dominio.
- Identifícate: Usa un User-Agent descriptivo.
- Cumple la ley: No extraigas información privada o sensible. Limítate a datos públicos.
- Sé ético: No copies sitios completos ni uses los datos para spam.
- Haz pruebas pequeñas: Empieza con rastreos pequeños y amplía solo si todo va bien.
Para más detalles, revisa esta guía de buenas prácticas.
¿Cuándo Elegir Web Scraping? Thunderbit para Usuarios de Negocio
Extrae datos de cualquier web usando IA Get Started Free
Te lo digo claro: salvo que quieras crear tu propio buscador o mapear la estructura completa de un sitio, la mayoría de los usuarios de negocio sacan más partido a las herramientas de web scraping.
Ahí es donde entra Thunderbit. Como cofundador y CEO, puede que no sea imparcial, pero de verdad creo que Thunderbit es la forma más sencilla para que cualquiera, sin saber de tecnología, saque datos de la web.
¿Por qué Thunderbit?
- Configuración en dos clics: Haz clic en “AI Suggest Fields” y luego en “Scrape”—¡y listo!
- Impulsado por IA: Thunderbit analiza la página y te sugiere las mejores columnas para extraer (nombres de productos, precios, imágenes, lo que necesites).
- Soporte para lotes y PDF: Saca datos de la página actual, de varias URLs o incluso de archivos PDF.
- Exportación flexible: Descarga en CSV/JSON, o manda los datos directo a Google Sheets, Airtable o Notion.
- Sin necesidad de programar: Si sabes usar un navegador, puedes usar Thunderbit.
- Rastreo de subpáginas: ¿Necesitas más detalle? Thunderbit puede visitar subpáginas y enriquecer tus datos automáticamente.
- Programación de tareas: Configura extracciones recurrentes en lenguaje natural (por ejemplo, “cada lunes a las 9am”).
Prueba la extensión de Thunderbit para Chrome gratis
¿Cuándo deberías usar un raspador en su lugar?
Si tu objetivo es mapear un sitio completo (como crear un índice de búsqueda o un sitemap), un raspador es la herramienta adecuada. Pero si solo quieres datos estructurados de páginas concretas (como listados de productos, reseñas o información de contacto), el scraping es más rápido, sencillo y eficiente.
Conclusión y Puntos Clave
Resumiendo:
- El web crawling permite a los buscadores y grandes proyectos de datos descubrir y mapear la web. Se trata de amplitud—encontrar la mayor cantidad de páginas posible.
- El web scraping va a la profundidad—extraer los datos concretos que te interesan de esas páginas. La mayoría de los usuarios de negocio necesitan scraping, no crawling.
- Puedes programar tu propio raspador (Python es ideal para esto), pero requiere tiempo, conocimientos y mantenimiento.
- Las herramientas sin código y con IA como Thunderbit hacen que la extracción de datos web sea accesible para todos—sin necesidad de programar.
- Las buenas prácticas importan: Rastrea y extrae datos de forma responsable, respeta las normas de los sitios y usa la información de manera ética.
Si estás empezando, elige un proyecto sencillo—por ejemplo, sacar precios de productos o recopilar leads de un directorio. Prueba una herramienta como Thunderbit para obtener resultados rápidos, o experimenta con Python si quieres aprender cómo funciona todo por dentro.
La web es una mina de oro de información. Con el enfoque adecuado, puedes descubrir datos que te ayuden a tomar mejores decisiones, ahorrar tiempo y mantener a tu empresa un paso adelante.
Empieza a extraer datos con Thunderbit
Preguntas Frecuentes
- ¿Cuál es la diferencia entre web crawling y web scraping?
Crawling descubre y mapea páginas. Scraping extrae datos concretos de ellas. Crawling = descubrimiento; scraping = extracción.
- ¿Es legal el web scraping?
Extraer datos públicos suele ser legal si respetas el robots.txt y los términos de uso. Evita contenido privado o protegido por derechos de autor.
- ¿Necesito programar para extraer datos de sitios web?
No. Herramientas como Thunderbit te permiten extraer datos con unos clics y ayuda de IA—sin programar.
- ¿Por qué Google no indexa toda la web?
Porque la mayor parte está detrás de logins, muros de pago o bloqueada. Solo alrededor del 4% está realmente indexada.
Lecturas recomendadas
- FreeCodeCamp – Web Scraping con Python y BeautifulSoup
- Tutorial oficial de Scrapy
- Real Python – Cómo usar Selenium y Python para Web Scraping
- Apify Academy: Web Scraping y Automatización
Prueba Raspador Web IA Get Started Free




