¿Alguna vez te has visto copiando y pegando precios, opiniones o listas de clientes potenciales de la web, una y otra vez, hasta que se te acaba la paciencia o el café? Si es así, sabes lo tedioso que puede ser. Hoy en día, el tutorial de extracción de datos web es el truco secreto de los equipos de ventas, operaciones y marketing. No solo te ahorra un montón de tiempo (¡y vaya que lo hace!), sino que te abre la puerta a nuevas oportunidades, automatiza tareas repetitivas y te ayuda a tomar decisiones más inteligentes y rápidas que la competencia.
He visto cómo un buen flujo de trabajo de extracción de datos web puede convertir una semana entera de investigación manual en solo cinco minutos de trabajo. Tanto si estás empezando como si quieres pulir tus habilidades, este tutorial de extracción de datos web te va a llevar por los conceptos clave, los errores más comunes y los pasos prácticos—usando desde métodos clásicos hasta herramientas con IA como . Vamos a sumergirnos y a convertir la web en tu propio tesoro de datos.
¿Qué es la extracción de datos web? Conceptos básicos
En pocas palabras, la extracción de datos web (o web scraping) es el proceso de recolectar información automáticamente de páginas web y convertirla en un formato ordenado—como una hoja de cálculo o una base de datos—para analizarla o usarla en tu negocio. En vez de pasar horas copiando y pegando, un Raspador Web es como un asistente digital: navega por las páginas, encuentra los datos que necesitas (precios, nombres de productos, correos, reseñas) y los organiza para ti ().
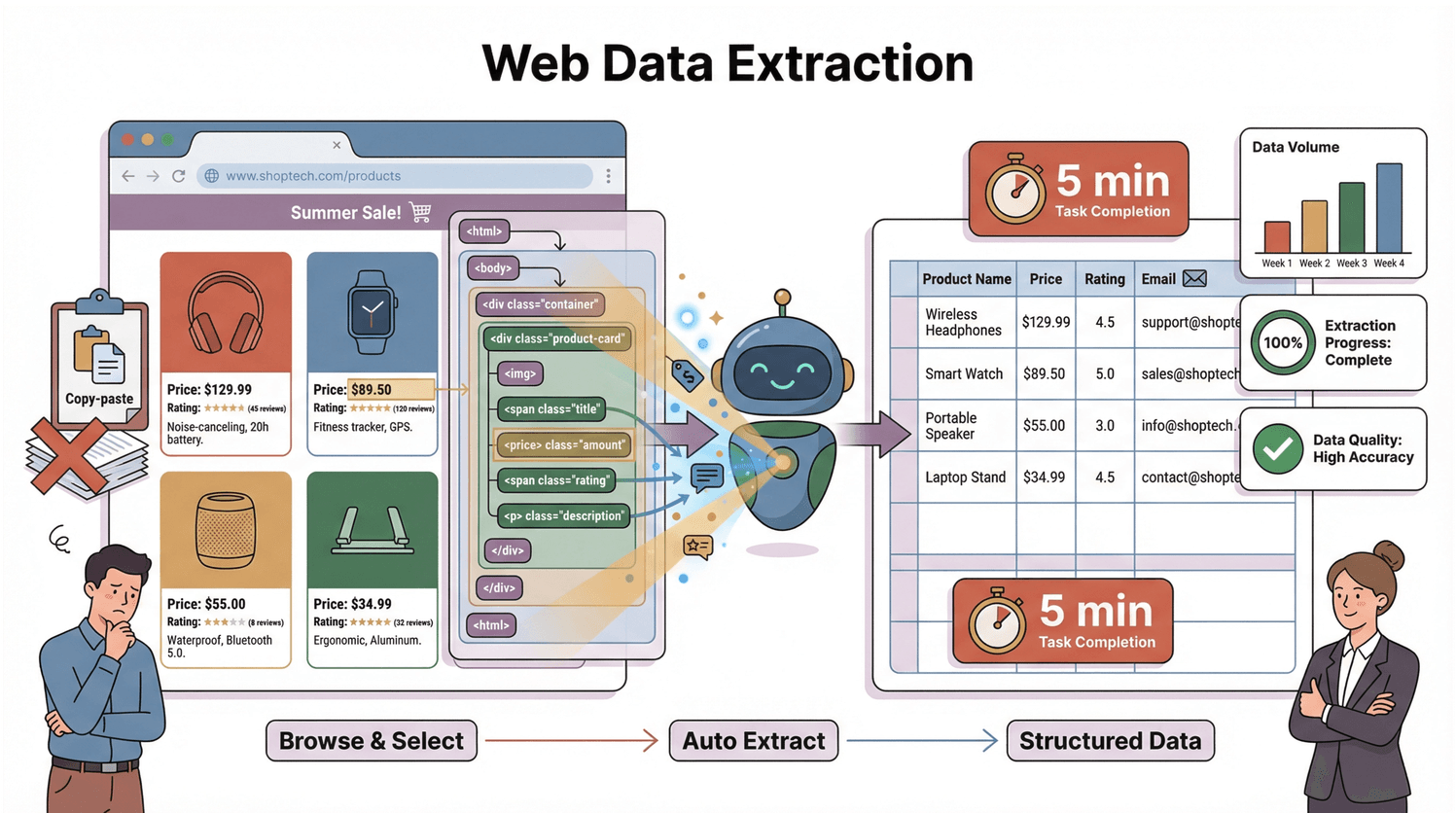
¿Pero cómo funciona esto? Cada página web tiene una estructura llamada DOM (Modelo de Objetos del Documento)—imagínate que es el plano que le dice al navegador (y a cualquier Raspador Web) dónde está cada cosa. El Raspador Web lee ese plano, encuentra los elementos que te interesan y los saca en filas y columnas. Es como tener un ayudante súper organizado que nunca se cansa ni se distrae con vídeos de gatos.
¿Por qué la extracción de datos web es clave para ventas y operaciones?
Seamos realistas: la extracción de datos web ya no es solo para los más techies—es una ventaja competitiva real. Por eso los equipos de ventas, operaciones y marketing la están usando cada vez más:
| Caso de uso | Beneficio empresarial | Impacto real |
|---|---|---|
| Generación de leads | Llena tu embudo con prospectos calificados rápidamente | 70% de ROI en 6 meses; 40% más leads de calidad; cientos de horas ahorradas (Grepsr) |
| Monitoreo de precios | Precios dinámicos, protección de márgenes | 65% de ROI en medio año; 12% más ventas; 75% menos trabajo manual (Grepsr) |
| Benchmarking de competencia | Inteligencia de mercado en tiempo real | 55% de ROI para aerolíneas; 68% de ROI en seguimiento de tendencias e-commerce (Grepsr) |
| Monitoreo operativo | Evita quiebres de stock, optimiza la cadena de suministro | 62% de ROI para minoristas globales; sin más sorpresas de inventario (Grepsr) |
Y no es solo por el retorno de inversión. Automatizar la recolección de datos web permite que tu equipo se enfoque en la estrategia, no en tareas repetitivas. De hecho, algunas empresas han logrado reducir los costos de obtención de datos hasta en un 40% (), y se espera que el mercado global de web scraping pase de $5 mil millones en 2023 a más de $140 mil millones en 2032 (). Eso es mucho dato—y mucha oportunidad.
¿Cómo funciona la extracción de datos web? Del DOM a la tabla de datos
Vamos a ver qué pasa detrás de cámaras (sin rollos técnicos):
- Solicitud: El Raspador Web manda una petición al sitio y recibe el HTML.
- Análisis: Lee el DOM de la página—la estructura en árbol que organiza cada elemento.
- Extracción: Encuentra los datos que buscas (precios, nombres, correos) y los pone en una tabla ordenada (CSV, Excel, Google Sheets, etc.) ().
Entendiendo el DOM: la base de la extracción de datos web
Piensa en el DOM como el árbol genealógico de una página web. Arriba está el documento, que se divide en <html>, luego <head> y <body>, y así hasta cada <div>, <span> y texto (). Cada nodo es un elemento que puedes seleccionar.
Por ejemplo, para sacar el precio de un producto, el Raspador Web buscaría un <span class="price"> dentro de un <div> dentro del <body>. Es como decirle a tu ayudante: “Ve a la cocina, abre la nevera y busca la leche”. El DOM es el mapa; tu Raspador Web es el explorador.
Pero aquí viene el truco: muchos sitios modernos usan JavaScript para cargar contenido dinámico. Eso significa que los datos que buscas pueden no estar en el HTML inicial—solo aparecen cuando la página termina de cargar y se ejecutan los scripts. Así que tu Raspador Web debe ver el DOM renderizado, no solo el HTML crudo (). Aquí es donde fallan muchos raspadores clásicos (y donde brillan las herramientas modernas).
Errores comunes en la extracción de datos web (y cómo evitarlos)
El tutorial de extracción de datos web no siempre es pan comido. Estos son los problemas más típicos—y cómo sortearlos:
- Contenido dinámico y scroll infinito: Muchos sitios cargan datos sobre la marcha o requieren que bajes para ver más elementos. Si tu Raspador Web solo toma el HTML inicial, te vas a perder información. Solución: usa herramientas que puedan renderizar JavaScript o simular el scroll (Thunderbit lo hace solo) ().
- Paginación y subpáginas: ¿Los datos están repartidos en varias páginas o en páginas de detalle? Asegúrate de que tu herramienta pueda seguir los botones de “Siguiente” y entrar en subpáginas. La función “Extraer subpáginas” de Thunderbit es perfecta para esto ().
- Cambios en la estructura del sitio: Un pequeño cambio en el diseño puede romper los raspadores clásicos. Las herramientas con IA como Thunderbit se adaptan solas, así que no tendrás que estar arreglando scripts rotos ().
- Medidas anti-scraping: CAPTCHAs, bloqueos de IP y límites de velocidad pueden frenarte. Haz scraping de forma ética (más lento, con peticiones aleatorias), usa herramientas basadas en navegador para simular usuarios reales y respeta las normas del sitio ().
- Datos desordenados o inconsistentes: No todos los sitios están bien estructurados. A veces tendrás que usar prompts de IA o reglas personalizadas para sacar la información correcta (el Field AI Prompt de Thunderbit es ideal para esto).
Cómo lidiar con páginas dinámicas y JavaScript
Algunas páginas no muestran todos sus datos de inmediato—usan JavaScript para cargar más contenido al hacer scroll o clic. Los raspadores clásicos no ven esto, pero las extensiones de navegador (como Thunderbit) capturan todo lo que ves, incluso en scrolls infinitos o ventanas emergentes ().
Cómo sortear las medidas anti-scraping
Si te bloquean o ves CAPTCHAs, baja la velocidad de tus peticiones, rota tus IPs y usa herramientas que simulan usuarios reales. Y siempre revisa los términos del sitio y su robots.txt ().
Comparativa de herramientas de extracción de datos web: Thunderbit vs. soluciones tradicionales
Hay muchas formas de extraer datos—unas más fáciles que otras. Así se comparan los métodos principales:
| Solución | Tiempo de configuración | Habilidades necesarias | Mantenimiento | Funciones y opciones de exportación |
|---|---|---|---|---|
| Copiar y pegar manualmente | Ninguno | Ninguna | Manual constante | Sin automatización; propenso a errores |
| Código personalizado (Python, etc.) | Horas–días | Programación + HTML | Alto | Flexible; exporta a cualquier sitio; curva de aprendizaje alta |
| Herramientas no-code tradicionales | ~1 hora/sitio | Algo de conocimientos técnicos | Medio | Configuración visual; soporta paginación; curva de aprendizaje moderada |
| Thunderbit (IA No-Code) | Minutos | Ninguna (lenguaje natural) | Bajo (IA se adapta) | Detección de campos con IA; subpáginas; programación; exporta a Sheets/Excel/Notion |
Thunderbit destaca para usuarios de negocio porque está pensado para la sencillez. No necesitas saber programar—solo describe lo que quieres y la IA hace el resto ().
Por qué Thunderbit es ideal para usuarios de negocio
- Simplicidad en dos clics: “Sugerir campos con IA” y luego “Extraer”. Así de fácil.
- Reconocimiento de campos con IA: La IA analiza la página y sugiere las mejores columnas—sin adivinanzas.
- Sin código, lenguaje natural: Solo escribe lo que necesitas (“Obtener todos los nombres y precios de productos”) y Thunderbit lo resuelve.
- Automatización de subpáginas y paginación: Extrae todas las páginas y enlaces de detalle con un clic.
- Exportación rápida: Envía los datos directamente a Excel, Google Sheets, Notion o Airtable—sin costes extra.
- Modo nube o navegador: Extrae en la nube para mayor velocidad, o en tu navegador para páginas con sesión iniciada.
Thunderbit está pensado para el mundo real—donde los sitios cambian, los datos son un caos y los usuarios de negocio necesitan resultados, no dolores de cabeza.
Tutorial paso a paso de extracción de datos web con Thunderbit
¿Listo para ponerte manos a la obra (sin enredos)? Así puedes extraer datos de cualquier web usando :
Paso 1: Instala la extensión de Thunderbit para Chrome
Ve a la y añade Thunderbit. Regístrate gratis—el plan gratuito te deja probar con varias páginas.
Paso 2: Accede al sitio web objetivo
Abre la web de la que quieres extraer datos. Inicia sesión si hace falta y asegúrate de que toda la información que buscas esté visible.
Paso 3: Abre Thunderbit y describe los datos que necesitas
Haz clic en el icono de Thunderbit. Puedes:
- Pulsar “Sugerir campos con IA” para que la IA analice y proponga columnas.
- O escribir un prompt personalizado: “Extraer nombre del producto, precio y reseñas”.
Thunderbit te mostrará una vista previa de los campos encontrados. Puedes renombrar, eliminar o añadir columnas según lo necesites.
Paso 4: Ejecuta la extracción
Haz clic en “Extraer”. Thunderbit recopilará los datos en una tabla. Si hay varias páginas o subpáginas, te preguntará si quieres extraerlas todas—acepta para obtener todo.
Paso 5: Revisa y exporta
Verifica los resultados. Si falta algo, prueba a reformular tu prompt o asegúrate de que todo el contenido esté cargado. Cuando estés satisfecho, haz clic en “Exportar” para descargar en CSV o enviar directamente a Google Sheets, Excel, Notion o Airtable.
Ejemplo práctico: Extrayendo reseñas de productos de Amazon con Thunderbit
Supón que quieres analizar las reseñas de un producto de la competencia en Amazon. Así de fácil lo hace Thunderbit:
- Accede a la página del producto en Amazon y haz clic en “Ver todas las reseñas”.
- Activa Thunderbit. Si ves la plantilla Amazon Reviews Scraper, úsala—ya está configurada con los campos correctos ().
- Haz clic en “Extraer”. Thunderbit recopila nombres de usuarios, valoraciones, texto de la reseña, fechas y más—en todas las páginas.
- Exporta. Ahora tienes una hoja lista para análisis de sentimiento, benchmarking de la competencia o un informe rápido de “¿Qué les importa realmente a los clientes?”.
¿Quieres personalizar? Solo usa un prompt en lenguaje natural: “Extraer nombre del revisor, puntuación, fecha y texto de la reseña”. La IA de Thunderbit se encarga, incluso si Amazon cambia su diseño.
Consejos avanzados: personaliza y automatiza tu extracción de datos web
Cuando ya domines lo básico, las funciones avanzadas de Thunderbit pueden llevar tu flujo de trabajo al siguiente nivel:
- Prompts de IA por campo: Añade instrucciones personalizadas para cada campo (por ejemplo, “Solo extraer reseñas de 1 o 2 estrellas” o “Traducir el texto de la reseña al inglés”).
- Extracción programada: Configura tareas recurrentes (diarias, semanales, etc.) para mantener tus datos siempre actualizados—ideal para monitoreo de precios o generación de leads ().
- AI Autofill: Automatiza el llenado de formularios o flujos de varios pasos (perfecto para webs que requieren búsquedas o inicio de sesión).
- Extracción en la nube: Para grandes volúmenes, ejecuta la extracción en la nube para mayor velocidad y fiabilidad.
- Plantillas instantáneas: Usa plantillas preconfiguradas para sitios populares como Amazon, Zillow, Yelp, LinkedIn y más ().
Incluso puedes integrar Thunderbit en el flujo de trabajo de tu equipo—exporta a Google Sheets, comparte resultados o conecta con otras herramientas para automatizar procesos.
El futuro de la extracción de datos web: tendencias de IA e impacto empresarial
La IA está revolucionando la extracción de datos web:
- Resiliencia: Los Raspadores Web con IA se adaptan automáticamente a los cambios en los sitios, reduciendo el mantenimiento y los tiempos muertos ().
- Scraping agente: Los bots ahora pueden navegar, hacer clic e interactuar como un humano—abriendo nuevas fuentes y flujos de datos.
- Flujos de datos continuos: Las empresas pasan de extracciones puntuales a pipelines de datos en tiempo real y siempre activos.
- Accesibilidad: Herramientas no-code y de lenguaje natural como Thunderbit hacen que la extracción de datos web esté al alcance de todos, no solo de desarrolladores.
- Insight inmediato: La próxima ola combinará scraping con análisis impulsado por IA—imagina extraer reseñas de la competencia y obtener al instante un resumen de los principales puntos de dolor.
En resumen: la extracción de datos web con IA es tan esencial como una hoja de cálculo o un CRM. Los equipos que la dominen irán un paso por delante—mientras los demás siguen copiando y pegando.
Conclusión y puntos clave
- La extracción de datos web convierte internet en tu base de datos personal—automatizando la recolección de leads, precios, reseñas y más.
- El DOM es el plano de cada página web; entenderlo es clave para extraer datos de forma efectiva.
- Los errores comunes (contenido dinámico, bloqueos anti-bot, datos desordenados) se evitan con las herramientas adecuadas y algo de experiencia.
- Thunderbit hace que la extracción de datos web sea accesible para todos: dos clics, detección de campos con IA, extracción de subpáginas y exportación instantánea a tus herramientas favoritas.
- La IA es el futuro—haciendo el scraping más rápido, inteligente y fiable para usuarios de negocio.
¿Listo para probarlo? y descubre lo fácil que puede ser la extracción de datos web. Para más consejos, guías y casos reales, visita el .
Preguntas frecuentes
1. ¿Qué es la extracción de datos web y cómo funciona?
La extracción de datos web (web scraping) es el proceso automatizado de recolectar información de sitios web y convertirla en datos estructurados, como una hoja de cálculo. Funciona leyendo el DOM del sitio, localizando los datos que necesitas y exportándolos para su análisis ().
2. ¿Cuáles son los mayores retos en la extracción de datos web?
Los principales obstáculos son el contenido dinámico (datos cargados con JavaScript), las medidas anti-scraping (CAPTCHAs, bloqueos de IP) y los datos desordenados o inconsistentes. Herramientas modernas como Thunderbit usan IA y scraping basado en navegador para superar estos retos ().
3. ¿En qué se diferencia Thunderbit de otras herramientas de scraping?
Thunderbit es un Raspador Web sin código impulsado por IA, pensado para usuarios de negocio. Ofrece configuración en dos clics (“Sugerir campos con IA” y “Extraer”), prompts en lenguaje natural, extracción de subpáginas y exportación instantánea a Excel, Google Sheets, Notion y Airtable ().
4. ¿Puedo usar Thunderbit para extraer datos de sitios dinámicos o multipágina?
Por supuesto. Thunderbit gestiona automáticamente el contenido dinámico (como scroll infinito o datos cargados con JavaScript) y puede extraer datos de varias páginas o subpáginas con un solo clic ().
5. ¿Es legal la extracción de datos web?
Extraer datos públicos suele ser legal, especialmente para inteligencia de negocio, pero siempre revisa los términos de uso del sitio y su robots.txt. Evita extraer datos personales o privados y haz scraping de forma responsable—no sobrecargues los sitios ni infrinjas sus políticas ().
¡Feliz extracción! Que tus hojas de cálculo siempre estén llenas, tus datos frescos y el copiar-pegar sea cosa del pasado.
Más información