

Mi panel de OpenRouter ya mostraba 47 dólares gastados antes del almuerzo de un martes. Había ejecutado quizá una docena de tareas de programación — nada exagerado, solo algo de refactorización y unos cuantos arreglos de bugs. Ahí entendí que los valores predeterminados de OpenClaw estaban mandando en silencio cada interacción, incluidas las pings de latido en segundo plano, a Claude Opus, que cuesta más de 15 dólares por millón de tokens.
Si te han pasado sorpresas parecidas — y por lo que se ve en los foros, a mucha gente sí ("ya llevo gastados 40 dólares y ni siquiera lo uso mucho", escribió un usuario) — esta guía te muestra el enfoque completo de auditoría y optimización que usé para recortar mi gasto mensual en alrededor de un 90%. No se trata solo de "cambiar a un modelo más barato", sino de hacer una revisión sistemática de adónde van realmente los tokens, cómo vigilarlos, qué modelos de bajo presupuesto aguantan trabajo agentivo real y tres configuraciones listas para copiar y pegar que puedes usar hoy mismo. Todo el proceso me tomó una tarde.
Qué es el uso de tokens de OpenClaw y por qué es tan alto por defecto
Los tokens son la unidad de facturación de cada interacción con IA en OpenClaw. Piénsalos como pequeños fragmentos de texto — aproximadamente 4 caracteres en inglés por token. Cada mensaje que envías, cada respuesta que recibes y cada proceso en segundo plano que se activa se cobra en tokens.
El problema es que los valores predeterminados de OpenClaw están pensados para ofrecer la máxima capacidad, no el menor coste. Nada más instalarlo, el modelo principal queda configurado como anthropic/claude-opus-4-5, la opción más cara disponible. ¿Las pings de latido? También corren sobre Opus. ¿Los subagentes que se crean para tareas secundarias? Igual. Usar Opus para una ping de latido es como contratar a un neurocirujano para poner una tirita. Técnicamente funciona, pero sale carísimo.
La mayoría de usuarios no se da cuenta de que está pagando tarifas premium por tareas triviales de fondo. En la práctica, la configuración por defecto asume que quieres el mejor modelo para todo, siempre — y te cobra en consecuencia.
Por qué reducir el uso de tokens de OpenClaw ahorra más que dinero
La ventaja obvia es el ahorro. Pero hay beneficios secundarios que se van acumulando con el tiempo.
Los modelos más baratos suelen ser más rápidos. Gemini 2.5 Flash-Lite procesa alrededor de 214 tokens por segundo frente a unos 51 de Opus — es decir, una mejora de 4x en cada interacción. GPT-OSS-120B en Cerebras llega a 1.917 tokens por segundo, unas 35 veces más rápido que Opus. En un flujo agentivo con más de 50 rondas de llamadas a herramientas, esa diferencia significa terminar en minutos en lugar de esperar los dolorosos 13,6 segundos hasta el primer token de Opus en cada ida y vuelta.
También ganas más margen antes de topar con límites de tasa, menos sesiones frenadas y espacio para escalar sin que tu ansiedad por la factura crezca al mismo ritmo.
Ahorro estimado según distintos perfiles de uso:
| Perfil de usuario | Gasto mensual estimado (por defecto) | Tras optimización completa | Ahorro mensual |
|---|---|---|---|
| Ligero (~10 consultas/día) | ~$100 | ~$12 | ~88% |
| Moderado (~50 consultas/día) | ~$500 | ~$90 | ~82% |
| Intenso (~200+ consultas/día) | ~$1,750 | ~$220 | ~87% |
No es teoría. Un desarrollador documentó pasar de 600–750 dólares/mes a 3–4 dólares/día — un recorte real del 90% — combinando el enrutamiento de modelos con las fugas ocultas que cubrimos más adelante en esta guía.
Anatomía del uso de tokens de OpenClaw: adónde va realmente cada token
Esta es la parte que la mayoría de guías de optimización se saltan, y es la que más importa. No puedes arreglar lo que no puedes ver.
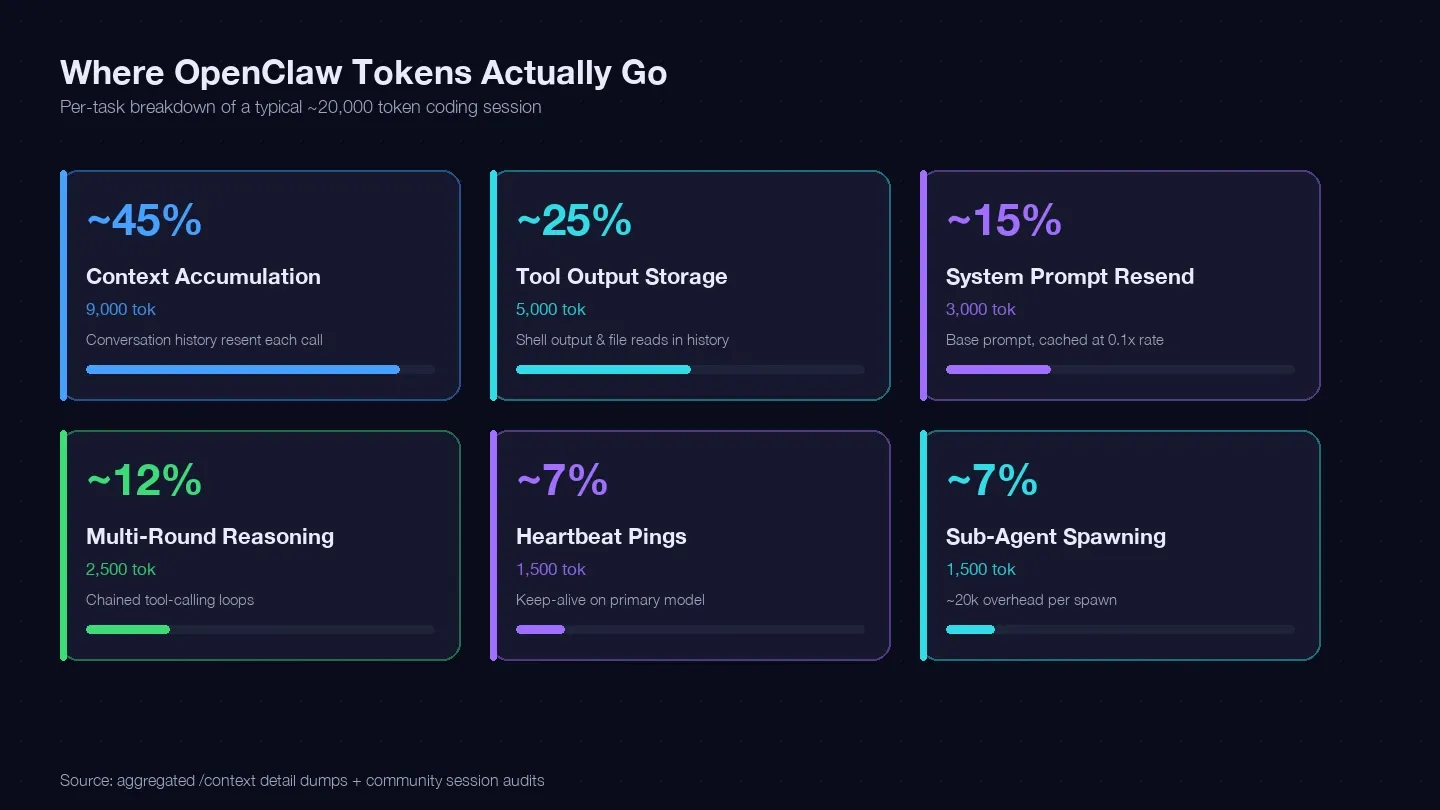
Audité varias sesiones y contrasté los datos con la guía de optimización de costes de LaoZhang y volcados de /context de la comunidad para construir un registro de tokens de una tarea de programación típica. Aquí fue donde se fueron aproximadamente 20.000 tokens:
| Categoría de tokens | % típico del total | Ejemplo (1 tarea de código) | ¿Se puede controlar? |
|---|---|---|---|
| Acumulación de contexto (el historial se reenvía en cada llamada) | ~40–50% | ~9.000 tokens | Sí — /clear, /compact, sesiones más cortas |
| Almacenamiento de salida de herramientas (salida de shell, lecturas de archivos guardadas en el historial) | ~20–30% | ~5.000 tokens | Sí — lecturas más pequeñas, alcance más preciso de las herramientas |
| Reenvío del prompt del sistema (~15K base) | ~10–15% | ~3.000 tokens | Parcialmente — lecturas cacheadas a 0,1x |
| Razonamiento en varias rondas (bucles encadenados de llamadas a herramientas) | ~10–15% | ~2.500 tokens | Elección del modelo + mejores prompts |
| Pings de latido / keep-alive | ~5–10% | ~1.500 tokens | Sí — cambio de configuración |
| Llamadas a subagentes | ~5–10% | ~1.500 tokens | Sí — enrutamiento de modelos |
El mayor bloque con diferencia — la acumulación de contexto — es el historial de conversación que se vuelve a enviar con cada llamada a la API. Un volcado real de sesión mostró 185.400 tokens solo en la categoría Messages, incluso antes de que el modelo respondiera. El prompt del sistema y las herramientas añadieron otros ~35.800 tokens fijos encima de eso.
La conclusión: si no limpias las sesiones entre tareas no relacionadas, estás pagando por retransmitir todo tu historial de conversación en cada turno.
Cómo monitorear el uso de tokens de OpenClaw (no puedes recortar lo que no ves)
Antes de cambiar nada, necesitas visibilidad sobre adónde van tus tokens. Ir directo a "usa un modelo más barato" sin medir nada es como intentar adelgazar sin pisar nunca una báscula.
Revisa tu panel de OpenRouter
Si enrutas a través de OpenRouter, la página de actividad es el panel más fácil y sin configuración. Puedes filtrar por modelo, proveedor, clave API y periodo de tiempo. La vista de Usage Accounting desglosa tokens de prompt, completion, reasoning y cacheados en cada solicitud. Además, hay un botón de exportación (CSV o PDF) para análisis a más largo plazo.
En qué fijarte: qué modelo consumió más tokens y si las solicitudes de latido o de subagentes aparecen como partidas inesperadamente grandes.
Audita tus registros locales de API
OpenClaw guarda los datos de sesión en ~/.openclaw/agents.main/sessions/sessions.json, donde aparece totalTokens por sesión. También puedes ejecutar openclaw logs --follow --json para obtener registros en tiempo real por solicitud.
Un matiz importante: sessions.json totalTokens no se actualiza después de la compactación, así que el panel puede mostrar valores antiguos previos a compactar. Dale más confianza a /status y /context detail que a los totales guardados.
Usa seguimiento de terceros (para usuarios moderados o intensivos)
LiteLLM proxy te da un endpoint compatible con OpenAI delante de más de 100 proveedores y registra automáticamente el gasto por clave virtual, modelo, usuario y equipo. Su gran ventaja: presupuestos duros por clave que sobreviven a /clear — un subagente descontrolado no puede pasarse del límite que fijaste.
Helicone es aún más simple — un cambio de base URL en una sola línea que te ofrece una vista de sesiones agrupando solicitudes relacionadas. Un prompt tipo "arregla este bug" que se ramifica en 8+ llamadas de subagentes aparece como una sola fila de sesión con el coste total real. Plan gratuito: 10.000 solicitudes/mes.
Comprobaciones rápidas dentro de OpenClaw
Para el control diario, estos cuatro comandos dentro de la sesión bastan:
/status— muestra uso de contexto, últimos tokens de entrada/salida y coste estimado/usage full— pie de uso por cada respuesta/context detail— desglose de tokens por archivo, habilidad y herramienta/compact [guidance]— compactación forzada con cadena de enfoque opcional
Ejecuta /context detail antes y después de cambiar la configuración. Así sabrás si tus optimizaciones realmente funcionaron.
El duelo de los modelos más baratos de OpenClaw: qué LLMs económicos sí aguantan trabajo agentivo
La mayoría de guías fallan aquí. Enseñan una tabla de precios, señalan la fila más barata y listo. Los benchmarks no predicen el rendimiento agentivo del mundo real — algo que la comunidad ha repetido alto y claro. Como dijo un usuario: "los benchmarks no ayudan de verdad a entender cuál funciona mejor para IA agentiva".
La idea clave: el modelo más barato no siempre produce el resultado más barato. Un modelo que falla y reintenta cuatro veces cuesta más que uno intermedio que acierta a la primera. En sistemas agentivos de producción, conviene planificar una tasa de reintento del 5–10% — y si encadenas cinco llamadas a LLM y falla el paso cuatro, un reintento ingenuo vuelve a ejecutar los cinco pasos.
Aquí tienes mi matriz de capacidades, con una "Puntuación agentiva real" basada en informes de usuarios reales y no en benchmarks sintéticos:
| Modelo | Entrada $/1M | Salida $/1M | Fiabilidad en llamadas a herramientas | Razonamiento multietapa | Puntuación agentiva real (1–5) | Ideal para |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | Mixta — bucles ocasionales | Básico | ⭐2.5 | Latidos, búsquedas simples |
| GPT-OSS-120B | $0.04 | $0.19 | Aceptable | Aceptable | ⭐3.0 | Experimentación de bajo presupuesto, velocidad crítica |
| DeepSeek V3.2 | $0.26 | $0.38 | Inconsistente (6 issues abiertos) | Buena | ⭐3.0 | Mucho razonamiento, poca llamada a herramientas |
| Kimi K2.5 | $0.38 | $1.72 | Buena (vía :exacto) | Aceptable | ⭐3.5 | Programación simple a media |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | Buena | Buena | ⭐4.0 | Modelo diario general para código |
| Claude Haiku 4.5 | $1.00 | $5.00 | Excelente | Buena | ⭐4.5 | Fallback intermedio fiable |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Excelente | Excelente | ⭐5.0 | Tareas complejas de varios pasos |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | Excelente | Excelente | ⭐5.0 | Solo para los problemas más difíciles |
Una advertencia sobre DeepSeek y Gemini Flash para llamadas a herramientas
DeepSeek V3.2 pinta muy bien sobre el papel — 72–74% en SWE-Bench, 11–36 veces más barato que Sonnet. En la práctica, seis issues distintos de GitHub en Cline, Roo Code, Continue y NVIDIA NIM documentan un comportamiento roto al llamar herramientas. El veredicto comparativo de Composio: "DeepSeek V3.2 construyó partes de la app, pero tropezó en ejecución, velocidad y fiabilidad." La frase breve de Zvi Mowshowitz: "okay and cheap, but."
Gemini 2.5 Flash tiene una brecha parecida. Un hilo del Google AI Developers Forum titulado "Very frustrating experience with Gemini 2.5 function calling performance" arranca así: "el comportamiento de function calling de los modelos Gemini se ha vuelto completamente poco fiable e impredecible."
OpenRouter señaló un matiz crítico: "la propensión de un modelo a llamar herramientas y la precisión de esas llamadas puede variar muchísimo entre hosts con los mismos pesos." Si enrutas modelos baratos a través de OpenRouter, busca la etiqueta :exacto — un cambio silencioso de proveedor puede convertir un modelo barato y fiable en un bucle de reintentos caro de la noche a la mañana.
Cuándo usar cada modelo
- Gemini Flash-Lite: latidos, pings de keep-alive, preguntas y respuestas simples. Nunca para llamadas a herramientas de varios pasos.
- MiniMax M2.5/M2.7: tu modelo diario para tareas generales de programación. SWE-Pro 56,22, Terminal-Bench 2 57,0% por una fracción del precio de Sonnet.
- Claude Haiku 4.5: el fallback fiable cuando los modelos baratos se atascan con llamadas a herramientas. Fiabilidad excelente en tool calling a un precio unas 3x menor que Sonnet.
- Claude Sonnet 4.6: trabajo agentivo complejo de varios pasos. Aquí es donde de verdad compensa lo que pagas.
- Claude Opus: resérvalo para los problemas más duros. No dejes que sea el modelo por defecto para nada.
(Los precios de los modelos cambian con frecuencia — verifica las tarifas actuales en OpenRouter o en las páginas directas del proveedor antes de fijar una configuración.)
Las fugas ocultas de tokens que la mayoría de guías se salta
Usuarios de foros cuentan que desactivar ciertas funciones reduce drásticamente los costes, pero no he encontrado ninguna guía que reúna todas las fugas ocultas con su impacto real en tokens. Aquí va el desglose completo:
| Fuga oculta | Coste en tokens por ocurrencia | Cómo arreglarlo | Clave de configuración |
|---|---|---|---|
| Latido por defecto en Opus | ~100.000 tokens/ejecución sin aislamiento | Sustituir por Haiku + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| Creación de subagentes | ~20.000 tokens por creación antes de empezar cualquier trabajo | Enrutar subagentes a Haiku | subagents.model |
| Carga completa del contexto del codebase | ~3.000–15.000 tokens por autoexploración | .clawignore para node_modules, dist y lockfiles | .clawrules + .clawignore |
| Auto-resumen de memoria | ~500–2.000 tokens/sesión | Desactivar o reducir frecuencia | memory: false o memory.max_context_tokens |
| Acumulación del historial de conversación | ~500+ tokens/turno (acumulativo) | Empezar sesiones nuevas entre tareas no relacionadas | Disciplina con /clear |
| Sobrecoste de herramientas MCP | ~7.000 tokens para 4 servidores; 50.000+ para 5 o más | Mantener MCP al mínimo | Eliminar MCPs no usados |
| Inicialización de skills/plugins | 200–1.000 tokens por skill cargada | Desactivar skills no usadas | skills.entries.<name>.enabled: false |
| Agent Teams (modo plan) | ~7x el coste de una sesión estándar | Usarlo solo para trabajo realmente paralelo | Preferir secuencial |
La fuga del latido merece una mención aparte. Por defecto, los heartbeats se ejecutan en el modelo principal (Opus) cada 30 minutos. Poner isolatedSession: true baja eso de ~100.000 tokens por ejecución a 2.000–5.000 tokens — una reducción del 95–98% en ese único bloque.
Tres victorias rápidas que recortan más tokens en menos de dos minutos
Las tres son de riesgo cero y llevan menos de dos minutos:
-
/clearentre tareas no relacionadas (5 segundos). Es el mayor ahorro de tokens por sí solo. El consenso en foros lo sitúa en una reducción del 50–70% solo por limpiar el historial de sesión antes de empezar trabajo nuevo. ¿Recuerdas ese bloque de Messages de 185k tokens del volcado /context?/clearlo borra. -
/model haiku-4.5para trabajo rutinario (10 segundos). Cambiar de modelo de forma táctica logra una reducción del 60–80% en costes en tareas habituales. Haiku resuelve sin problema la mayoría de tareas de programación sencillas, búsquedas de archivos y mensajes de commit. -
Reduce
.clawrulesa menos de 200 líneas + añade.clawignore(90 segundos). Tu archivo de reglas se carga en cada mensaje. Con 200 líneas eso equivale a ~1.500–2.000 tokens por turno; con 1.000 líneas son 8.000–10.000 tokens cobrando peaje permanente en cada solicitud. Sumado a un.clawignoreque excluyanode_modules/,dist/, lockfiles y código generado, un desarrollador afirma haber conseguido una reducción del 92% de tokens solo con esta disciplina.
Paso a paso: tres configuraciones listas para copiar que reducen drásticamente el uso de tokens en OpenClaw

A continuación tienes tres configuraciones completas y comentadas de openclaw.json, desde "solo empezar a ahorrar" hasta "stack completo de optimización". Cada una incluye comentarios en línea y estimaciones de coste mensual.
Antes de empezar:
- Dificultad: Principiante (Config A) → Intermedio (Config B) → Avanzado (Config C)
- Tiempo necesario: ~5 minutos para Config A, ~15 minutos para Config C
- Lo que necesitas: OpenClaw instalado, un editor de texto y acceso a
~/.openclaw/openclaw.json
Config A: Principiante — solo ahorrar dinero
Cinco líneas. Cero complejidad. Cambia el modelo por defecto de Opus a Sonnet, desactiva la sobrecarga de memoria y aísla los heartbeats en Haiku.
// ~/.openclaw/openclaw.json
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-6" }, // antes era Opus — ahorro instantáneo de 3-5x
"heartbeat": {
"every": "55m", // alineado con un TTL de caché de 1h para maximizar aciertos
"model": "anthropic/claude-haiku-4-5", // Haiku para pings, no Opus
"isolatedSession": true // ~100k → 2-5k tokens por ejecución
}
}
},
"memory": { "enabled": false } // ahorra ~500-2k tokens/sesión
}
Lo que deberías ver después de aplicarlo: ejecuta /status antes y después. El coste por solicitud debería bajar de forma visible y las entradas de heartbeat en tu página de actividad de OpenRouter deberían mostrar Haiku en lugar de Opus.
| Nivel de uso | Por defecto (Opus) | Config A (Sonnet + heartbeats en Haiku) | Ahorro |
|---|---|---|---|
| Ligero (~10 q/día) | ~$100 | ~$35 | 65% |
| Moderado (~50 q/día) | ~$500 | ~$250 | 50% |
| Intenso (~200 q/día) | ~$1,750 | ~$900 | 49% |
Config B: Intermedio — enrutamiento inteligente en tres niveles
Sonnet principal para el trabajo real. Haiku para subagentes y compactación. Gemini Flash-Lite como respaldo económico cuando Claude se satura. Las cadenas de fallback manejan automáticamente las caídas de proveedor.
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"anthropic/claude-haiku-4-5", // si Sonnet está limitado
"google/gemini-2.5-flash-lite" // último recurso ultra barato
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m", // 55min < TTL de caché de 1h = aciertos de caché
"model": "google/gemini-2.5-flash-lite", // céntimos por ping
"isolatedSession": true,
"lightContext": true // contexto mínimo en llamadas de latido
},
"subagents": {
"maxConcurrent": 4, // baja desde el valor por defecto de 8
"model": "anthropic/claude-haiku-4-5" // los subagentes no necesitan Sonnet
},
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5", // resúmenes de compactación vía Haiku
"memoryFlush": { "enabled": true }
}
}
}
}
Resultado esperado: las entradas de subagentes en tus registros deberían mostrar ahora precios de Haiku. Los heartbeats deberían costar casi nada. Tu cadena de fallback evita que una caída de Claude bloquee la sesión — simplemente degrada a Gemini.
| Nivel de uso | Por defecto | Config B | Ahorro |
|---|---|---|---|
| Ligero | ~$100 | ~$20 | 80% |
| Moderado | ~$500 | ~$150 | 70% |
| Intenso | ~$1,750 | ~$500 | 71% |
Config C: Usuario avanzado — stack completo de optimización
Asignación de modelos por subagente, compactación de contexto fijada en Haiku, enrutamiento de visión a Gemini Flash, .clawrules y .clawignore ajustados al máximo, y skills no usadas desactivadas. Esta es la configuración que te lleva al rango de ahorro del 85–90%.
{
"agents": {
"defaults": {
"workspace": "~/clawd",
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openrouter/anthropic/claude-sonnet-4-6", // otro proveedor como respaldo
"minimax/minimax-m2-7", // fallback barato para el día a día
"anthropic/claude-haiku-4-5" // último recurso
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
},
"minimax/minimax-m2-7": {
"params": { "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m",
"model": "google/gemini-2.5-flash-lite",
"isolatedSession": true,
"lightContext": true,
"activeHours": "09:00-19:00" // sin heartbeats por la noche
},
"subagents": {
"maxConcurrent": 4,
"model": "anthropic/claude-haiku-4-5"
},
"contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5",
"identifierPolicy": "strict",
"memoryFlush": { "enabled": true }
},
"bootstrapMaxChars": 12000, // baja desde el valor por defecto de 20000
"imageModel": "google/gemini-3-flash" // tareas de visión con modelo barato
}
},
"memory": { "enabled": true, "max_context_tokens": 800 }, // memoria mínima
"skills": {
"entries": {
"web-search": { "enabled": false },
"image-generation": { "enabled": false },
"audio-transcribe": { "enabled": false }
}
}
}
Ejemplo de sobrescritura por subagente — pega esto en ~/.openclaw/agents/lint-runner/SOUL.md:
---
name: lint-runner
description: Ejecuta comprobaciones de lint/format y aplica correcciones triviales
tools: [Bash, Read, Edit]
model: anthropic/claude-haiku-4-5
---
.clawignore mínimo viable — esto por sí solo reduce los arranques típicos de 150k caracteres hacia 30–50k:
node_modules/
dist/
build/
.next/
coverage/
.venv/
vendor/
*.lock
package-lock.json
yarn.lock
pnpm-lock.yaml
*.min.js
*.min.css
**/__snapshots__/
**/*.snap
| Nivel de uso | Por defecto | Config C | Ahorro |
|---|---|---|---|
| Ligero | ~$100 | ~$12 | 88% |
| Moderado | ~$500 | ~$90 | 82% |
| Intenso | ~$1,750 | ~$220 | 87% |
Estos números encajan con dos informes independientes de usuarios reales: el caso documentado por Praney Behl de $600–750/mes → $3–4/día (recorte del 90%) y los estudios de caso de LaoZhang que muestran $943 → $347 (63%), $1.750 → $1.000 (64%), $200 → $70 (65%) con optimización parcial.
Cómo usar el comando /model para controlar el uso de tokens de OpenClaw sobre la marcha
El comando /model cambia el modelo activo para el siguiente turno mientras mantiene intacto el contexto de conversación — sin reinicio y sin perder historial. Este es el hábito diario que, con el tiempo, multiplica el ahorro.
Flujo práctico:
- ¿Estás en una refactorización complicada de varios archivos? Quédate en Sonnet.
- ¿Pregunta rápida tipo "qué hace esta regex"?
/model haiku, preguntas, y luego/model sonnetpara volver. - ¿Mensaje de commit o retoque de documentación?
/model flash-litey listo.
Puedes crear alias en openclaw.json dentro de commands.aliases para mapear nombres cortos (haiku, sonnet, opus, flash) a cadenas completas de proveedor. Ahorra unos cuantos teclazos en cada cambio.
La matemática: 50 consultas/día con Sonnet cuestan unos 3 dólares diarios. Las mismas 50 consultas repartidas 70/20/10 entre Haiku/Sonnet/Opus cuestan alrededor de 1,10 dólares al día. En un mes, eso pasa de 90 a 33 dólares — 63% más barato sin cambiar herramientas, solo hábitos.
Extra: seguimiento de precios de modelos de OpenClaw entre proveedores con Thunderbit
Seguimiento de precios de modelos entre proveedores con IA Get Started Free
Con tantos modelos y proveedores — OpenRouter, la API directa de Anthropic, Google AI Studio, DeepSeek, MiniMax — los precios cambian con frecuencia. Anthropic redujo de golpe el precio de salida de Opus en un 67%. Google recortó los límites del plan gratuito de Gemini 50–80% en diciembre de 2025. Mantener una hoja de cálculo fija actualizada a mano es una batalla perdida.
Thunderbit resuelve esto sin escribir código de scraping. Es una extensión de Chrome de IA web scraper Chrome extension creada precisamente para este tipo de extracción estructurada de datos.
El flujo de trabajo que uso:
- Abre la página de modelos de OpenRouter en Chrome y haz clic en "AI Suggest Fields" de Thunderbit. Lee la página y propone columnas — nombre del modelo, precio de entrada, precio de salida, ventana de contexto, proveedor.
- Pulsa Scrape y exporta directamente a Google Sheets.
- Configura una extracción programada en lenguaje natural — "cada lunes a las 9:00, vuelve a extraer la lista de modelos de OpenRouter" — y se ejecuta automáticamente en la nube.
A partir de ahí, tu rastreador de precios personal se actualiza solo. Cualquier modelo que de repente baje un 30% — o cualquier proveedor que obtenga la etiqueta Exacto — aparece en tu hoja del lunes por la mañana sin que tengas que mover un dedo. Hemos escrito más sobre extracción de datos con IA para negocios en nuestro blog.
¿Quieres comparar precios en páginas directas de proveedores (Anthropic, Google, DeepSeek)? El scraping de subpáginas de Thunderbit sigue cada enlace de modelo hasta su página de detalle y extrae las tarifas por proveedor — útil cuando quieres saber si enrutar Kimi K2.5 a través de OpenRouter sale más barato que ir directo por NVIDIA Build. Consulta precios de Thunderbit para ver el plan gratuito y los detalles de los planes.
Conclusiones clave para reducir el uso de tokens de OpenClaw
El marco mental es: Entender → Medir → Enrutar → Optimizar.
Acciones con mayor impacto, ordenadas:
- No pongas Opus como predeterminado. Cambia tu modelo principal a Sonnet o MiniMax M2.7. Solo esto ya suele recortar el coste entre 3 y 5 veces.
- Aísla los heartbeats. Activa
isolatedSession: truey envía los heartbeats a Gemini Flash-Lite. Con eso, una fuga de ~100k tokens pasa a ~2–5k. - Envía los subagentes a Haiku. Cada creación carga ~20k tokens de contexto antes de hacer trabajo útil. No dejes que eso ocurra en Opus.
- Usa
/clearcon disciplina. Es gratis, tarda 5 segundos y el consenso de la comunidad dice que ahorra más que cualquier otra acción aislada. - Añade
.clawignore. Excluirnode_modules, lockfiles y artefactos de build reduce de forma drástica el contexto de arranque. - Monitorea con
/context detailantes y después de los cambios. Si no lo puedes medir, no lo puedes mejorar.
El modelo más barato depende de la tarea. Gemini Flash-Lite para heartbeats. MiniMax M2.7 para programación diaria. Haiku para llamadas a herramientas fiables. Sonnet para trabajo complejo de varios pasos. Opus solo para los problemas realmente más difíciles — y para nada más.
La mayoría de lectores puede ver ahorros del 50–70% en una sola tarde con la Config A o B. El 85–90% completo requiere apilar todo lo anterior — enrutamiento de modelos, corrección de fugas ocultas, .clawignore, disciplina de sesiones — pero es alcanzable y se mantiene.
Preguntas frecuentes
1. ¿Cuánto cuesta OpenClaw al mes?
Depende por completo de tu configuración, del volumen de uso y de los modelos que elijas. Los usuarios ligeros (~10 consultas/día) suelen gastar entre 5 y 30 dólares/mes con optimización, o más de 100 con la configuración por defecto. Los usuarios moderados (~50 consultas/día) se mueven entre 90 y 400 dólares/mes. Los intensivos pueden llegar a 600–2.000+ dólares/mes con valores por defecto — un caso extremo documentado fue de 5.623 dólares en un solo mes. La telemetría interna de Anthropic sugiere una mediana de 13 dólares por desarrollador y día activo.
2. ¿Cuál es el modelo más barato de OpenClaw que sigue funcionando bien para programar?
MiniMax M2.5/M2.7 es el mejor modelo general para el día a día — buena fiabilidad en llamadas a herramientas, SWE-Pro 56,22, y un coste de aproximadamente $0.28/$1.10 por millón de tokens. Para heartbeats y búsquedas simples, Gemini 2.5 Flash-Lite, con $0.10/$0.40, es difícil de superar. Claude Haiku 4.5, con $1/$5, es el fallback intermedio fiable cuando necesitas un gran comportamiento en tool calling sin pagar los precios de Sonnet.
3. ¿Puedo usar modelos gratuitos con OpenClaw?
Técnicamente sí. GPT-OSS-120B es gratis en la etiqueta :free de OpenRouter y en NVIDIA Build. Gemini Flash-Lite tiene plan gratuito (15 RPM, 1.000 solicitudes/día). DeepSeek ofrece 5 millones de tokens gratis al registrarte. Pero los planes gratuitos tienen límites de tasa agresivos, velocidades más lentas y disponibilidad menos fiable. Los modelos de pago baratos — céntimos por millón de tokens — son mucho más estables para uso normal.
4. ¿Cambiar de modelo a mitad de conversación con /model me hace perder contexto?
No. /model conserva todo el contexto de la sesión — el siguiente turno se envía al nuevo modelo con todo el historial intacto. Esto está verificado en la documentación de conceptos de OpenClaw y funciona igual que en Claude Code. Puedes alternar libremente entre Haiku para preguntas rápidas y Sonnet para trabajo complejo sin perder nada.
5. ¿Cuál es la forma más rápida de bajar hoy mismo mi factura de OpenClaw?
Escribe /clear entre tareas no relacionadas. Es gratis, tarda cinco segundos y borra el historial de conversación que se reenvía en cada llamada a la API. Una sesión real mostró 185.000 tokens de historial acumulado — todo eso se retransmitía y se volvía a cobrar en cada turno. Limpiar eso antes de empezar trabajo nuevo es el hábito con mayor retorno de inversión que puedes construir.
Prueba Thunderbit para scraping web con IA Get Started Free




