

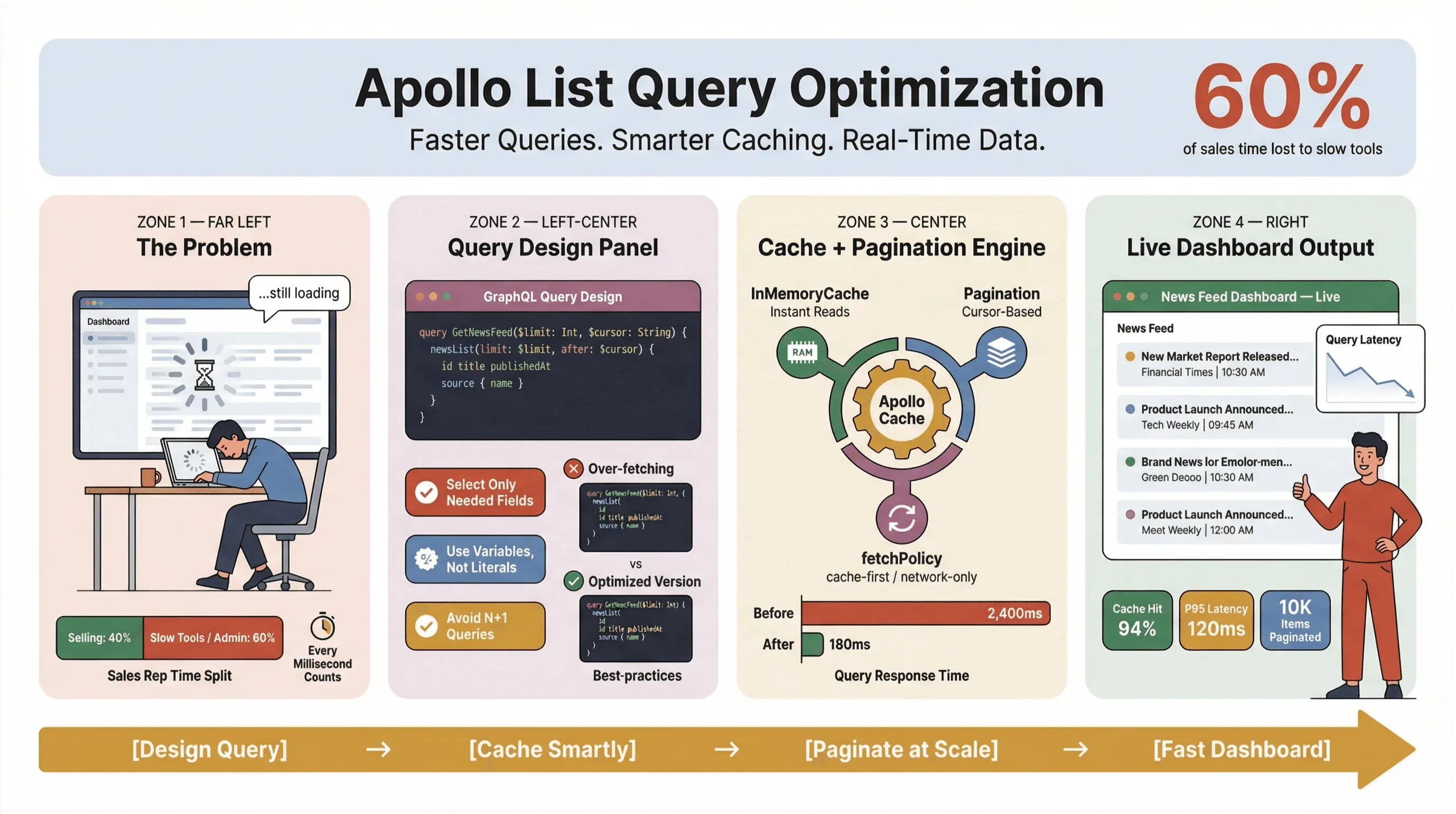
Optimizar las consultas de listas en Apollo no es solo un tema técnico: es una habilidad clave para cualquiera que dependa de datos de noticias en tiempo real, extracción automatizada de noticias o flujos de trabajo de ventas y operaciones a toda velocidad. He visto de primera mano cómo una consulta de lista lenta puede convertir un panel elegante en un cuello de botella, dejando a los equipos de ventas mirando barras de carga interminables y a operaciones improvisando soluciones en hojas de cálculo. En un mundo donde el 60% del tiempo de los representantes de ventas ya se pierde en tareas que no venden, cada milisegundo cuenta.
Entonces, ¿cómo haces para que las consultas de listas en Apollo Client sigan siendo rápidas, confiables y consistentes a gran escala, sobre todo cuando estás extrayendo noticias, haciendo seguimiento de leads o alimentando paneles críticos para el negocio? En esta guía te voy a mostrar las prácticas que mejor me han funcionado en producción: diseño de consultas, caché, paginación e integración de herramientas sin código como Thunderbit para automatizar el trabajo pesado de la extracción de noticias.
--- Tanto si eres desarrollador, product manager o simplemente la persona a la que todos culpan cuando el panel va lento, este es tu manual para el rendimiento de listas en Apollo GraphQL.
Prueba Thunderbit para la extracción automatizada de noticias
¿Por qué optimizar las consultas de lista en Apollo? (apollo client list performance, optimize apollo list queries)
Hablemos claro: nadie quiere esperar a que carguen los titulares o los leads de ventas. En entornos empresariales —sobre todo los que dependen de extracción automatizada de noticias o de datos en tiempo real— las consultas lentas de Apollo no solo fastidian a los usuarios; también cuestan dinero, retrasan decisiones y empujan a la gente a volver al trabajo manual. La investigación recurrente de Slack Workforce Lab ha mostrado de forma constante que los trabajadores de oficina dedican alrededor de un tercio —y en informes más recientes, cerca del 40%— de su jornada a tareas repetitivas y de poco valor, muchas veces porque sus herramientas fragmentan el trabajo en interfaces lentas.
Esto es lo que pasa cuando las consultas de lista no están optimizadas:
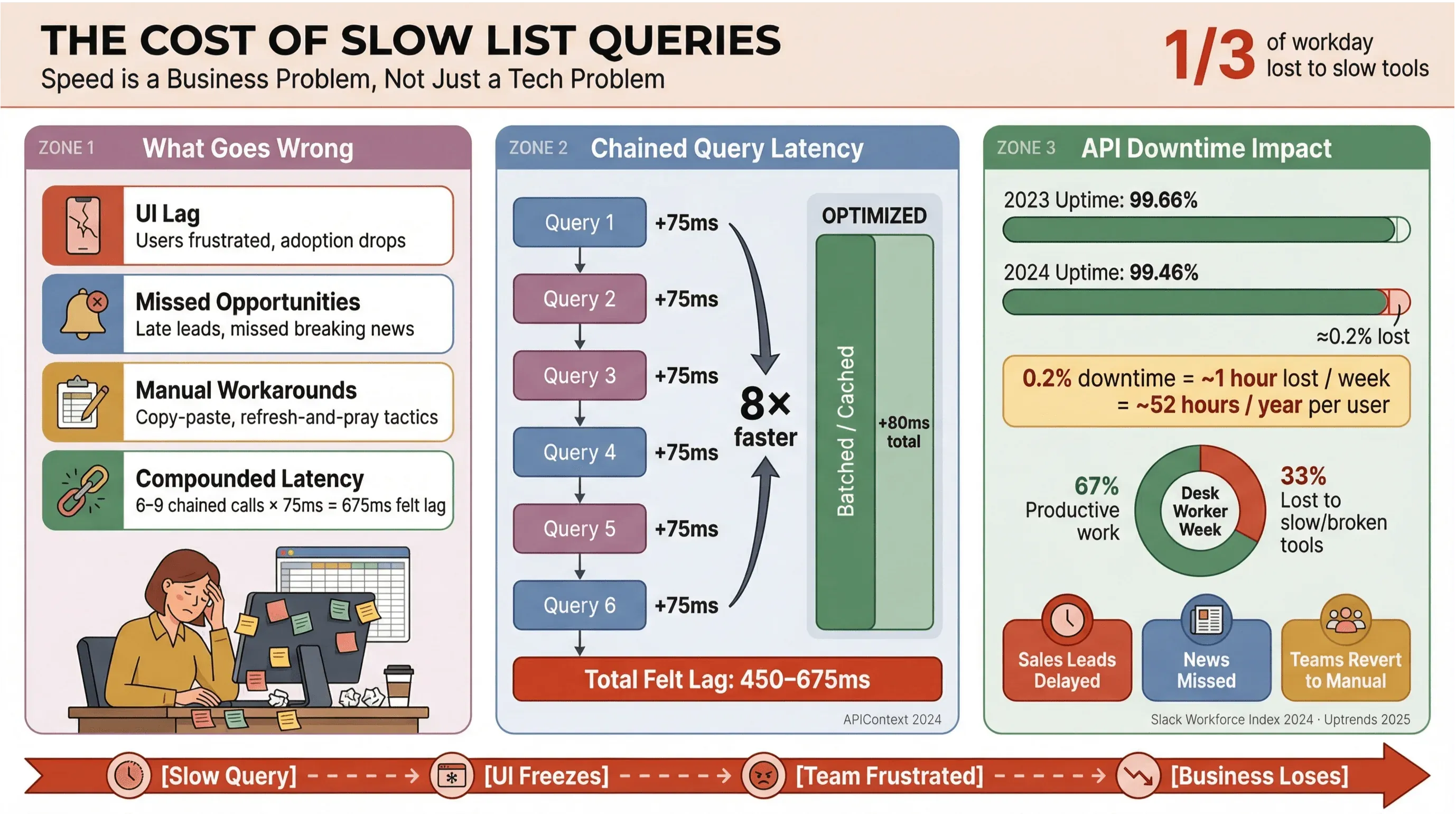
- Demoras en la interfaz: los usuarios notan el retraso, se frustran y termina bajando la adopción.
- Oportunidades perdidas: en ventas o en monitoreo de noticias, incluso unos segundos de atraso pueden hacer que pierdas un lead caliente o una noticia de última hora.
- Soluciones manuales: los equipos vuelven al copiar y pegar, a las hojas de cálculo o al típico “actualiza y reza”.
- Latencia acumulada: cada llamada lenta a la API suma; si tu flujo dispara 6–9 consultas dependientes, un retraso moderado de 75 ms por llamada puede terminar sintiéndose como 450–675 ms de lentitud (APIContext).
Y no se trata solo de velocidad. Las caídas de API van en aumento, con una disponibilidad media que bajó de 99,66% a 99,46% en solo un año, lo que se traduce en casi una hora de productividad perdida por semana para aplicaciones con muchas listas. Cuando tu negocio depende de datos de noticias en tiempo real, ese es un riesgo que no puedes darte el lujo de asumir.
Elegir la estructura de datos y los campos adecuados (apollo graphql list best practices)
Uno de los errores más comunes que veo —y sí, yo mismo también lo he cometido— es tratar cada consulta de lista como si fuera una consulta de detalle. En GraphQL tienes la ventaja de pedir exactamente lo que necesitas, así que aprovéchala. Pedir datos de más es el enemigo del rendimiento, especialmente en herramientas de scraping de noticias y paneles en tiempo real.
Ajustar los campos para la extracción automatizada de noticias
Imagina que estás construyendo un feed de noticias. ¿De verdad necesitas el artículo completo, todas las etiquetas, los comentarios y la biografía del autor en tu consulta de lista? Probablemente no. Mira la diferencia:
Consulta de lista eficiente:
query NewsFeed($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
cursor
node {
id
title
url
sourceName
publishedAt
}
}
pageInfo { endCursor hasNextPage }
}
}
Consulta de lista ineficiente (no hagas esto):
query NewsFeedTooHeavy($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
node {
id title url publishedAt
fullText
summary
entities { ... }
relatedArticles { ... }
}
}
}
}
La primera consulta es liviana y eficiente, perfecta para ordenar, filtrar y renderizar filas. ¿La segunda? Es una consulta de detalle disfrazada, que arrastra cargas enormes y lo ralentiza todo (especificación GraphQL, mejores prácticas de Apollo).
Consejo profesional: usa un enfoque de dos niveles: pide solo campos livianos en la lista y carga los detalles pesados —como el texto completo o el enriquecimiento NLP— solo cuando el usuario abra un elemento o pase el cursor sobre él.
Aprovechar la caché de Apollo Client para acelerar las consultas (apollo client list performance)
La caché de Apollo Client es el mayor impulso que tienes para mejorar el rendimiento de las consultas de lista. Cuando está bien configurada, te permite:
- Responder al instante a consultas repetidas (sin ida y vuelta a la red)
- Reducir la carga del servidor y los costes de API
- Ofrecer navegación atrás/adelante y cambios de filtro fluidos
Pero la caché no hace magia sola: requiere cierta configuración y disciplina.
Configurar políticas de caché eficaces
Apollo admite varias fetch policies:
| Política | Qué hace | Mejor caso de uso para listas de noticias |
|---|---|---|
| cache-first | Lee de la caché y consulta la red si falta | Volver a listas, cambiar filtros, navegación atrás/adelante |
| network-only | Siempre consulta la red | Actualización manual, “últimos titulares” |
| cache-and-network | Devuelve primero la caché y luego actualiza con la red | Primera carga rápida + actualización en segundo plano (ideal para feeds de noticias) |
| no-cache | Siempre consulta, nunca guarda en caché | Consultas puntuales sensibles (raro en listas) |
Para datos de noticias en tiempo real, me gusta cache-and-network: te da resultados inmediatos y luego actualiza en segundo plano. Solo ten cuidado con el parpadeo de la interfaz si los datos cambian de orden al refrescar (issue de GitHub).
Consejos de configuración de caché:
- Usa IDs estables (
ido_id) para la normalización (docs de caché de Apollo). - Ajusta el tamaño de la caché y la recolección de basura para listas grandes (gestión de memoria).
- Evita guardar blobs enormes sin normalizar bajo
ROOT_QUERY; eso puede trabar tu app (reporte de la comunidad).
Implementar paginación y limitar la cantidad de elementos (apollo graphql list best practices)
Si cargas cientos o miles de artículos o leads de ventas de una sola vez, te estás buscando problemas. La paginación no es solo una mejora de UX: es una necesidad de rendimiento.
Apollo admite tanto paginación basada en offset como en cursor. Así se comparan:
| Tipo de paginación | Ventajas | Desventajas | Mejor para |
|---|---|---|---|
| Basada en offset | Simple, fácil de implementar | Puede saltarse o duplicar elementos si los datos cambian | Listas pequeñas o inmutables |
| Basada en cursor | Estable, maneja bien los cambios de datos | Algo más compleja | Feeds de noticias, listas grandes |
Para la mayoría de listas de noticias o leads en tiempo real, la paginación basada en cursor es la mejor opción. Mantiene los datos consistentes incluso cuando llegan nuevos elementos o se eliminan otros antiguos (GraphQL Foundation).
Consejos de paginación en Apollo:
- Configura
keyArgspara controlar las claves de caché en campos paginados (docs). - Implementa una función
mergepara combinar páginas en la caché. - Usa
fetchMorepara cargar páginas adicionales sin sobrescribir resultados anteriores.
Patrones prácticos de paginación para herramientas de scraping de noticias
Una interfaz típica de scraping de noticias suele:
- Mostrar los 20–50 titulares más recientes (solo campos livianos)
- Cargar más al desplazarte o al hacer clic en “siguiente página”
- Obtener detalles solo cuando hacen falta
Así mantienes la interfaz rápida, la API tranquila y a tus usuarios productivos.
Integrar Thunderbit para la extracción automatizada de noticias
Ahora sí, hablemos del elefante en la habitación: ¿de dónde sale toda esa información estructurada de noticias en primer lugar? Ahí es donde entra Thunderbit.
Consigue la extensión de Chrome de Thunderbit Get Started Free
Thunderbit es una extensión de Chrome de AI web scraper sin código que puede extraer titulares de noticias, URLs, fuentes, autores, fechas de publicación, resúmenes e imágenes de casi cualquier sitio web, sin que tengas que programar. He visto equipos usar Thunderbit para automatizar todo el proceso de extracción de noticias, convirtiendo páginas web desordenadas en datos limpios y estructurados que pueden ir directo a una base de datos o a una API GraphQL.
Combinar Thunderbit con Apollo para datos de noticias en tiempo real
Este es un flujo de trabajo que me gusta mucho para equipos de ventas y operaciones que necesitan noticias actualizadas:
- Capa de extracción: usa la plantilla News Scraper de Thunderbit para extraer datos estructurados de noticias de los sitios objetivo según un calendario.
- Capa de almacenamiento: guarda los datos extraídos en una base de datos optimizada para una recuperación rápida.
- Capa GraphQL: expón un campo de lista
newsFeedy un campo de detallenewsArticle(id)a través de tu API. - Capa cliente: usa Apollo Client para consultar la lista (campos livianos, paginada) y obtener detalles solo cuando se necesiten.
Este flujo “extraer → guardar → consultar” hace que tus consultas de Apollo trabajen siempre con datos frescos y estructurados, sin copiar y pegar manualmente ni scripts frágiles.
Extra: Thunderbit también puede enriquecer tus listas con campos adicionales —como sentimiento o categoría— usando sus sugerencias de campos impulsadas por IA, haciendo que tu feed de noticias sea todavía más inteligente.
Guía paso a paso: optimizar consultas de lista en Apollo
¿Listo para ponerlo en práctica? Aquí tienes mi checklist de referencia para optimizar consultas de lista en Apollo:
-
Reduce el tamaño de tus consultas
- Pide solo los campos necesarios para renderizar la lista (título, URL, marca temporal, etc.).
- Mueve los campos pesados (texto completo, imágenes, enriquecimiento) a las consultas de detalle.
-
Implementa paginación
- Usa paginación basada en cursor para listas grandes o dinámicas.
- Configura
keyArgsy funcionesmergepara que la caché funcione bien.
-
Aprovecha la caché de Apollo
- Normaliza las entidades con IDs estables.
- Elige la política de fetch adecuada (
cache-and-networkes ideal para noticias). - Ajusta el tamaño de la caché y la recolección de basura según tu volumen de datos.
-
Integra la extracción automatizada
- Usa Thunderbit para automatizar el scraping de noticias y mantener tus datos actualizados.
- Exporta datos estructurados directamente a tu base de datos o hoja de cálculo.
-
Monitorea y soluciona problemas
- Usa Apollo Client Devtools para inspeccionar consultas, caché y rendimiento.
- Vigila escrituras grandes en caché, demasiadas consultas observadas y tirones en la interfaz.
- Haz seguimiento de la latencia p95/p99 y de las tasas de error (New Relic, Uptrends).
Supervisión y resolución de problemas de rendimiento de consultas
Apollo Devtools es un salvavidas en este punto. Puedes:
- Inspeccionar consultas activas y el estado de la caché
- Detectar consultas duplicadas o demasiados watchers
- Identificar blobs grandes en caché o problemas de normalización
Si ves lentitud en la interfaz o actualizaciones lentas, revisa:
- Consultas de lista demasiado grandes (redúcelas)
- Normalización deficiente de la caché (corrige tus IDs)
- Problemas al combinar páginas (audita
keyArgsymerge)
Y no olvides medir la latencia de cola larga, no solo los promedios. Ahí es donde se esconde el verdadero dolor del usuario.
Comparación entre enfoques tradicionales y basados en IA para el scraping de noticias
Seamos honestos: antes extraer datos de noticias significaba escribir scripts a medida, lidiar con navegadores sin cabeza y rezar para que el diseño del sitio no cambiara de la noche a la mañana. Ahora, con herramientas impulsadas por IA como Thunderbit, puedes automatizar todo el proceso: sin código y sin tanto drama.
| Enfoque | Puntos fuertes | Limitaciones para usuarios empresariales |
|---|---|---|
| Scraping con scripts | Totalmente personalizable, económico a escala | Mucho mantenimiento, requiere tiempo de ingeniería |
| Plataformas de scraping gestionadas | Rápidas para empezar, delegan el manejo anti-bot | Aun así requieren configuración, los costes escalan con el uso |
| Extracción impulsada por IA (Thunderbit) | Maneja diseños desordenados, no requiere código | El resultado necesita QA e integración con tu esquema |
| Scrapers visuales sin código | Accesibles para no ingenieros | Pueden romperse con cambios de UI, escala limitada |
| Infraestructura de proxies/desbloqueo | Evita bloqueos, soporta alto rendimiento | Sigue necesitando lógica de extracción y conlleva riesgos de cumplimiento |
Nota legal: extraer datos públicos suele ser legal, pero siempre respeta los términos del servicio y los límites de velocidad (Reuters).
Ideas clave sobre las mejores prácticas para listas en Apollo GraphQL
Recapitulemos lo esencial:
- Optimiza para velocidad y claridad: recorta las consultas de lista, pagina y usa la caché con intención.
- La estructura importa: pide solo lo que necesitas; mueve los campos pesados a consultas de detalle.
- La caché es tu aliada: usa la normalización y las políticas de fetch de Apollo para servir datos al instante.
- Automatiza la extracción: herramientas como Thunderbit hacen que el scraping de noticias y el enriquecimiento de listas sea accesible para todos.
- Mide e itera: usa Devtools y paneles de observabilidad para detectar cuellos de botella cuanto antes.
Para equipos de ventas, operaciones y noticias, estas buenas prácticas significan menos tiempo esperando, más tiempo actuando y muchos menos mensajes de Slack preguntando “¿por qué va tan lento?”.
Conclusión: próximos pasos para optimizar tus consultas de lista en Apollo
Si todavía ejecutas consultas de lista pesadas, sin paginación o poco compatibles con la caché, ahora es el momento de revisarlas y mejorarlas. Empieza por algo pequeño: recorta los campos, añade paginación y ajusta la caché. Después, da un paso más integrando herramientas de extracción automatizada como Thunderbit para mantener tus datos frescos y accionables.
¿Quieres profundizar más? Consulta la documentación de Apollo, el blog de Thunderbit o únete a la comunidad de Apollo para obtener consejos reales y soluciones de problemas. Y si estás listo para automatizar la extracción de noticias, prueba la plantilla News Scraper de Thunderbit: es un cambio radical para cualquiera que necesite datos en tiempo real sin complicaciones.
Usa la plantilla News Scraper de Thunderbit
Si no haces nada más después de leer esto: reduce la selección de campos en tus consultas de lista, añade paginación basada en cursor y elige una política de fetch sensata. Solo esos tres cambios suelen llevar una consulta de lista de “notablemente” lenta a “imperceptible” — y te liberan para centrarte en los datos, no en el estado de carga.
Preguntas frecuentes
1. ¿Por qué se ralentizan las consultas de lista de Apollo en paneles de noticias o ventas en tiempo real?
Las consultas de lista pueden volverse lentas si traen demasiados datos, no tienen paginación o no están bien almacenadas en caché. En flujos de trabajo de alta frecuencia como la monitorización de noticias, incluso pequeños retrasos se acumulan y generan lentitud en la interfaz y pérdida de productividad.
2. ¿Cuál es la mejor forma de estructurar consultas de lista en Apollo para la extracción automatizada de noticias?
Pide solo los campos necesarios para renderizar tu lista (por ejemplo, título, URL, marca temporal). Mueve los campos pesados (como el texto completo del artículo o las imágenes) a consultas de detalle y pagina tus resultados para mantener las cargas pequeñas y rápidas.
3. ¿Cómo mejora la caché de Apollo Client el rendimiento de las listas?
La caché de Apollo guarda los datos obtenidos previamente, lo que permite respuestas instantáneas en consultas repetidas. Una normalización adecuada de la caché y políticas de fetch como cache-and-network pueden acelerar mucho las vistas de lista y reducir la carga del servidor.
4. ¿Cómo puede Thunderbit ayudar con el scraping de noticias y la integración con Apollo?
Thunderbit es un AI web scraper sin código que extrae datos estructurados de noticias de cualquier sitio web. Puedes usarlo para automatizar la extracción de noticias y luego enviar esos datos a tu base de datos o API GraphQL para usarlos con Apollo Client.
5. ¿Qué herramientas puedo usar para supervisar y depurar el rendimiento de las consultas de lista en Apollo?
Las Apollo Client Devtools te permiten inspeccionar consultas, el estado de la caché y el rendimiento en tiempo real. Combínalas con paneles de observabilidad (como New Relic o Uptrends) para seguir la latencia y las tasas de error, e ir ajustando el diseño de tus consultas para obtener mejores resultados.
¿Quieres más consejos sobre web scraping, automatización y flujos de datos en tiempo real? Visita el blog de Thunderbit para guías profundas, tutoriales y lo último en productividad impulsada por IA.
Prueba Thunderbit AI Web Scraper Get Started Free
Saber más
- Cómo optimizar las listas de Apollo para una gestión eficaz de leads
- Enriquecimiento de datos en Apollo: funciones, beneficios y mejora con IA
- Cómo dominar la prospección en Apollo: guía paso a paso
- Cómo usar la paginación en Web Scraper para una extracción eficiente
- Cómo usar la paginación en Web Scraper para una extracción eficiente




