Si alguna vez has intentado extraer datos de un sitio web moderno —por ejemplo, un portal inmobiliario, una tienda de ecommerce o incluso tu feed favorito de redes sociales— seguramente te has topado con un muro. Cargas la página, miras el HTML y… nada. Los detalles que de verdad te interesan (precios, anuncios, reseñas) simplemente no están ahí. Eso se debe a que la web actual ya no es solo HTML: funciona con JavaScript, y casi el 99 % de todos los sitios web usan scripts del lado del cliente para renderizar contenido (). Los rastreadores tradicionales son como intentar ver una película leyendo el guion: se pierden la acción en vivo.
Llevo años trabajando en SaaS y automatización, y he visto de primera mano cómo este cambio ha dejado rascándose la cabeza a usuarios de negocio, equipos de ventas e investigadores. Pero aquí va la buena noticia: dominar el rastreo con JavaScript ya no es solo cosa de desarrolladores. Con el enfoque adecuado —y un poco de ayuda de herramientas de IA como — cualquiera puede extraer datos incluso de los sitios más dinámicos e interactivos. Vamos a desglosar qué es el rastreo con JavaScript, por qué importa y cómo puedes empezar sin escribir código.
¿Qué es el rastreo con JavaScript? ¿Por qué importa para la extracción moderna de datos web?
Empecemos por lo básico. El rastreo con JavaScript consiste en usar una herramienta o bot capaz de cargar una página web, ejecutar todo su JavaScript y extraer el contenido que aparece después de que se ejecutan los scripts. Es un salto enorme frente al scraping HTML de toda la vida, que solo toma el código fuente en bruto enviado por el servidor. En la web actual, ese HTML en bruto suele ser solo un esqueleto: el contenido real (listados de productos, reseñas, precios) se rellena con JavaScript, a veces solo después de desplazarte, hacer clic o interactuar.
¿Por qué importa esto? Porque la web moderna se basa en frameworks como React, Angular y Vue. Estas aplicaciones de una sola página (SPA) cargan datos sobre la marcha, lo que deja a los raspadores estáticos “ciegos” ante gran parte del contenido. Por ejemplo:
- Ecommerce: Los precios y el stock de los productos se cargan solo después de hacer scroll o seleccionar un filtro.
- Inmobiliaria: Los anuncios aparecen a medida que bajas, con detalles cargados de forma dinámica.
- Redes sociales: Las publicaciones, comentarios y “me gusta” se obtienen de forma asíncrona, y no son visibles en el HTML inicial.
Los rastreadores tradicionales obtienen la página, ven una carcasa vacía y se pierden lo importante. El rastreo con JavaScript, en cambio, es como abrir la página en Chrome, dejar que se ejecuten todos los scripts y luego capturar lo que ves, igual que lo haría una persona.
En resumen: si quieres extraer datos de casi cualquier sitio web moderno en 2025, necesitas dominar el rastreo con JavaScript. Si no, te estarás perdiendo buena parte de la acción ().
Principales retos del rastreo con JavaScript (y cómo superarlos)
El rastreo con JavaScript no es solo “scraping, pero con más pasos”. Tiene sus propios obstáculos. Esto es a lo que te enfrentas y cómo superar cada reto.
Renderizado dinámico del contenido
El reto: La mayor parte del contenido ni siquiera está en el HTML. Se carga mediante JavaScript después de abrir la página, a veces tras hacer scroll, hacer clic o una llamada de red. Si solo descargas el HTML, obtienes marcadores de posición o contenedores vacíos.
La solución: Usa un navegador sin interfaz gráfica —una herramienta que simula un navegador real, ejecuta todos los scripts y espera a que aparezca el contenido. Herramientas como y son los estándares del sector. Te permiten:
- Abrir una página y dejar que JavaScript se ejecute.
- Esperar a que carguen elementos concretos (como “.product-list”).
- Extraer el contenido renderizado por completo desde el DOM.
Hoy en día, este enfoque es el estándar de oro para extraer sitios dinámicos ().
Barreras anti-bot y de automatización
El reto: Los sitios web son cada vez más listos a la hora de bloquear bots. Es normal encontrarse con:
- CAPTCHAs
- Bloqueos de IP o limitación de velocidad
- Fingerprinting del navegador (comprobar si eres un usuario real)
- Trampas honeypot (enlaces falsos para atrapar bots)
La solución: Rastrea con responsabilidad y simula el comportamiento humano:
- Respeta robots.txt y las condiciones de servicio.
- Limita la velocidad de tus solicitudes: añade retrasos aleatorios y no satures el servidor.
- Rota IPs si haces scraping a gran escala, pero de forma ética.
- Usa encabezados reales del navegador y evita firmas obvias de bot.
- No extraigas datos detrás de inicios de sesión ni eludas CAPTCHAs sin permiso.
Thunderbit, por ejemplo, anima a los usuarios a extraer solo datos de acceso público e incorpora buenas prácticas de cumplimiento ().
Scroll infinito y eventos activados por el usuario
El reto: Muchos sitios usan scroll infinito o requieren clics para cargar más datos. Si tu raspador solo toma lo que se ve al principio, te perderás la mayor parte del contenido.
La solución: Usa automatización del navegador para:
- Simular el desplazamiento (cargar más resultados como lo haría un usuario).
- Hacer clic en botones “Cargar más” o en pestañas.
- Esperar a que aparezca el contenido nuevo antes de extraerlo.
La IA de Thunderbit puede detectar estos patrones y encargarse del scroll o la paginación por ti, así no tienes que escribir scripts personalizados ().
Mantener el rendimiento y la escala
El reto: Ejecutar un navegador sin interfaz gráfica para cada página consume muchos recursos. Extraer cientos o miles de páginas puede ser lento y pesado para tu ordenador.
La solución: Usa rastreo concurrente: ejecuta varios navegadores o pestañas en paralelo. O, mejor aún, descarga el trabajo a la nube. El acelerador de scraping en la nube de Thunderbit (también conocido como Lightning Network) puede extraer hasta 50 páginas a la vez, acelerando muchísimo los trabajos grandes ().
Thunderbit: haciendo que el rastreo con JavaScript sea simple y potente
Seamos sinceros: la mayoría de los usuarios de negocio no quiere escribir código, depurar selectores ni vigilar scripts. Por eso creamos : un raspador web con IA diseñado para personas sin perfil técnico que necesitan datos de sitios dinámicos y cargados de JavaScript.
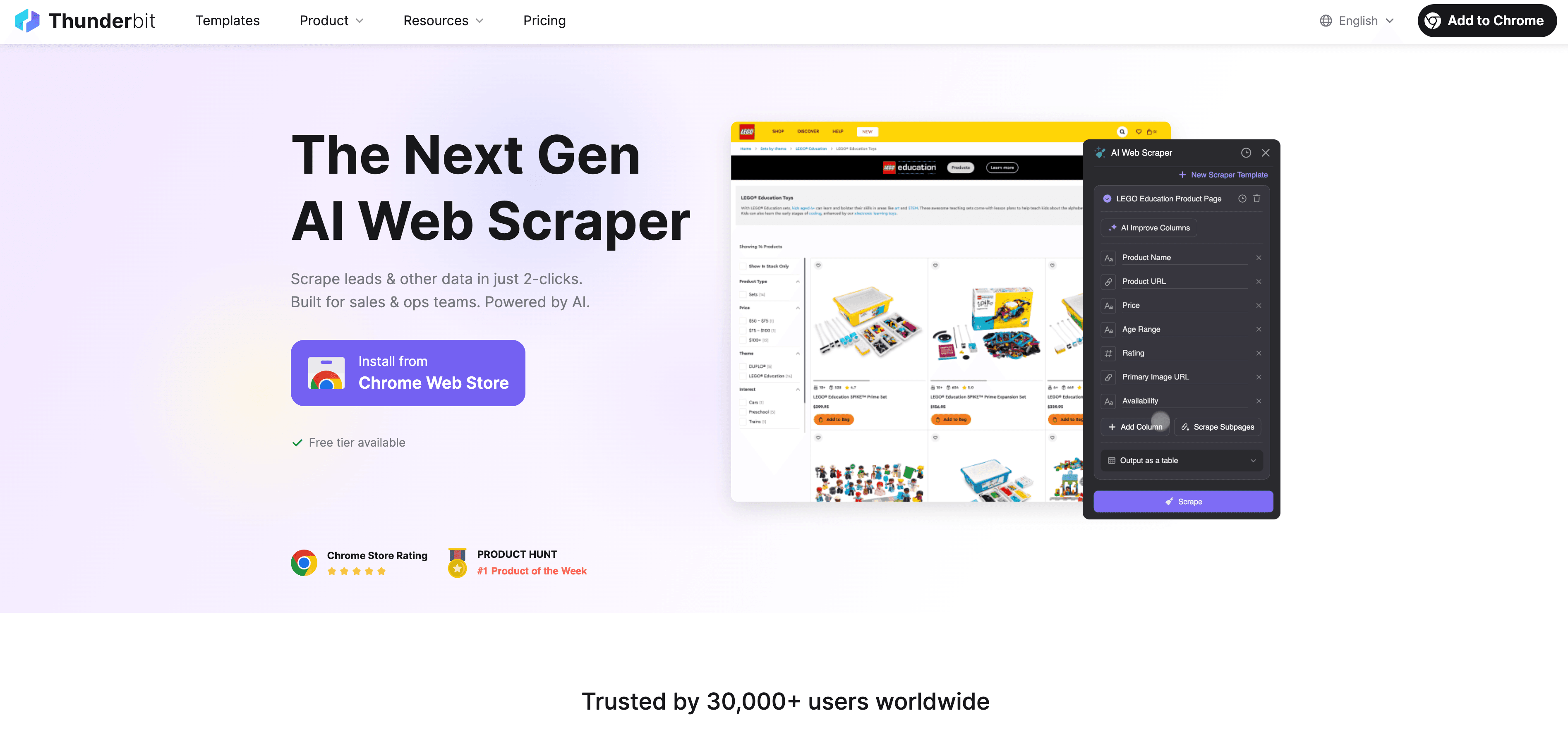
Así es como Thunderbit elimina el dolor del rastreo con JavaScript:
- Sugerir campos con IA: Solo haz clic en “AI Suggest Fields” y la IA de Thunderbit analiza la página, recomienda las mejores columnas para extraer y asigna los tipos de datos correctos. Se acabó adivinar o probar por ensayo y error.
- Extracción en lenguaje natural: Describe lo que quieres en inglés sencillo (“Toma el nombre del producto, el precio y la valoración”) y Thunderbit descubre cómo obtenerlo.
- Gestiona contenido dinámico: Thunderbit funciona en un navegador real (tu Chrome o en la nube), así que ejecuta todo JavaScript y espera a que cargue el contenido, igual que una persona.
- Soporte para subpáginas y paginación: ¿Necesitas rastrear varias páginas o seguir enlaces a subpáginas (como fichas de producto)? Thunderbit lo hace automáticamente y reúne todos los datos en una sola tabla.
- Aceleración en la nube: Para trabajos grandes, Lightning Network de Thunderbit extrae hasta 50 páginas a la vez en la nube, así que tu ordenador apenas lo nota.
- Interfaz sin código y fácil de usar: Si sabes usar Excel, puedes usar Thunderbit. Es de apuntar y hacer clic, sin configuración técnica.
- Exportación gratuita de datos: Exporta tus datos a Excel, Google Sheets, Airtable, Notion o JSON, sin costes extra.
Thunderbit cuenta con la confianza de más de 30.000 usuarios en todo el mundo, desde equipos de ventas hasta operadores de ecommerce y profesionales inmobiliarios ().
Sugerencia de campos con IA y extracción en lenguaje natural
Aquí es donde Thunderbit realmente brilla. En lugar de rebuscar en el HTML o escribir selectores XPath, solo haces clic en un botón y la IA de Thunderbit hace el trabajo pesado. Lee la página, entiende la estructura y recomienda exactamente qué extraer. Si quieres algo concreto, solo escríbelo en inglés sencillo: la IA de Thunderbit lo traducirá a los elementos adecuados.
Esto cambia por completo la experiencia de los principiantes. No necesitas saber nada de HTML, CSS o JavaScript. Solo di lo que quieres y deja que la IA se encargue del resto ().
Rastreo de paginación y subpáginas
Thunderbit no es solo para una sola página. Puede:
- Detectar y gestionar la paginación (hacer clic en “Siguiente” o desplazarse para cargar más).
- Extraer subpáginas (como fichas de producto, perfiles de autor o reseñas) y fusionar los datos en tu tabla principal.
- Gestionar el scroll infinito simulando acciones de usuario, para que obtengas todos los datos y no solo lo que se ve al principio.
Por ejemplo, ¿quieres extraer una categoría de ecommerce con 20 páginas de productos? Thunderbit hará clic automáticamente en cada página y combinará los resultados. ¿Necesitas detalles de cada página de producto? Usa el scraping de subpáginas y Thunderbit visitará cada enlace, capturará la información extra y enriquecerá tu conjunto de datos ().
Lightning Network y aceleración en la nube: escalando tu rastreo con JavaScript
Cuando necesitas extraer cientos o miles de páginas, hacerlo una por una simplemente no es práctico. Ahí entra en juego la Lightning Network de Thunderbit.
- Scraping en la nube: Descarga el trabajo pesado en los servidores en la nube de Thunderbit (en EE. UU., la UE y Asia). La nube puede extraer hasta 50 páginas a la vez, acelerando muchísimo los trabajos grandes.
- Rastreo concurrente: En lugar de esperar a que cada página cargue en tu navegador, la nube de Thunderbit reparte el trabajo entre muchos workers. ¿Tienes que extraer 1.000 páginas de productos? La nube puede terminar en minutos, no en horas.
- Scraping programado: ¿Necesitas vigilar precios o anuncios todos los días? Configura una extracción programada en lenguaje sencillo (“todos los días a las 9 a. m.”), y Thunderbit ejecutará el trabajo automáticamente, exportando los datos a tu Google Sheet o base de datos ().
Esto es una salvación para equipos de ventas, ecommerce y operaciones que necesitan datos frescos a gran escala, sin contratar a un desarrollador ni mantener servidores.
Extracción de datos multipágina y en lote
Thunderbit facilita:
- Extraer directorios o catálogos completos (por ejemplo, todos los productos de una categoría o todos los anuncios de una región).
- Exportar los resultados a Excel, Google Sheets, Airtable o Notion con un solo clic.
- Ahorrar horas, o incluso días, de trabajo manual: un usuario extrajo cientos de anuncios inmobiliarios, con todos los datos del agente, en menos de 10 minutos.
Guía paso a paso: cómo empezar a rastrear con JavaScript con Thunderbit
¿Listo para probarlo? Aquí tienes cómo empezar con Thunderbit, incluso si nunca has extraído datos de un sitio web.
Configurar tu primer rastreo
- Instala Thunderbit: Descarga la . Crea una cuenta gratuita.
- Elige tu objetivo: Ve al sitio web del que quieras extraer datos. Si requiere iniciar sesión, hazlo primero (Thunderbit funciona en el contexto de tu navegador).
- Abre Thunderbit: Haz clic en el icono de Thunderbit en la barra de herramientas de Chrome. Elige tu fuente de datos (página actual, lista de URLs o carga de archivo).
- Elige el modo de ejecución: Para trabajos pequeños o sitios que requieran inicio de sesión, usa Browser mode. Para trabajos a gran escala, cambia a Cloud mode para hacer scraping en paralelo.
- AI Suggest Fields: Haz clic en “AI Suggest Fields”. La IA de Thunderbit analizará la página y recomendará las columnas a extraer (como “Nombre del producto”, “Precio” o “URL de imagen”).
- Ajusta las columnas: Cambia el nombre, añade o elimina campos según necesites. Añade instrucciones personalizadas de IA si quieres formatear o categorizar los datos.
- Configura la paginación o el scroll: Si el sitio usa paginación o scroll infinito, activa la opción correspondiente en los ajustes de Thunderbit.
- Haz clic en “Scrape”: Thunderbit cargará la(s) página(s), ejecutará todo JavaScript y extraerá los datos en una tabla.
Extraer y exportar datos
- Previsualiza los resultados: Thunderbit muestra tus datos en una tabla. Revisa por encima para comprobar que estén completos y sean correctos.
- Exporta: Haz clic en “Export” para descargar en Excel, CSV o JSON, o enviar directamente a Google Sheets, Airtable o Notion.
- Valida: Compara algunas filas con el sitio en vivo para asegurarte de que todo coincide.
- Solución de problemas: Si te faltan datos, prueba primero a hacer scroll en la página, ajustar las instrucciones de la IA o cambiar a Cloud mode para mejorar el rendimiento.
Para ver una guía más detallada, consulta los o el .
Mejores prácticas para un rastreo con JavaScript seguro y conforme a la normativa
Con gran poder de scraping viene gran responsabilidad. Así es como te mantienes del lado correcto de la ley y la ética:
- Respeta robots.txt y las Condiciones de servicio: Comprueba siempre si el sitio permite extraer datos. Si dice “no bots”, no tientes a la suerte ().
- Evita extraer datos personales: El RGPD y la CCPA consideran protegidos nombres, correos y perfiles, aunque sean públicos. Solo extrae información personal si tienes una razón legítima y consentimiento.
- No eludas inicios de sesión ni CAPTCHAs: Eso entra en una zona legal gris, o peor. Quédate con los datos públicos.
- Limita la velocidad de tus solicitudes: No sobrecargues los servidores. El modo en la nube de Thunderbit distribuye las solicitudes en el tiempo y rota IPs para evitar bloqueos.
- Usa los datos de forma ética: No vuelvas a publicar contenido con copyright ni uses mal la información extraída.
- Elimina los datos si te lo piden: Si alguien solicita que borres sus datos, hazlo.
Thunderbit está diseñado para fomentar el cumplimiento: solo datos públicos, sin hacking y con opciones claras de exportación para un uso responsable.
Cómo evitar riesgos legales
- Quédate con datos públicos y no personales.
- No extraigas sitios que lo prohíban explícitamente.
- Si tienes dudas, pide permiso o usa la API oficial del sitio.
- Guarda registros de lo que extraíste y cuándo.
- Respeta de inmediato cualquier requerimiento de cese y desistimiento.
Para profundizar más, consulta .
Comparación de soluciones de rastreo con JavaScript: Thunderbit frente a herramientas tradicionales
| Aspecto | Puppeteer/Playwright (código) | Sitebulb (rastreador SEO) | Thunderbit (IA sin código) |
|---|---|---|---|
| Tiempo de configuración | Horas (requiere programar) | Moderado (configuración) | Minutos (apuntar y hacer clic) |
| Nivel de conocimientos | Alto (solo desarrolladores) | Medio | Bajo (cualquiera) |
| Gestiona contenido JS | Sí (script manual) | Sí (para SEO) | Sí (IA, automático) |
| Paginación/subpáginas | Script manual | Limitado | Automático (la IA lo detecta) |
| Mantenimiento | Alto (se rompe con cambios) | Moderado | Bajo (la IA se adapta) |
| Escalabilidad | Manual (hay que programar) | Limitada | Nube integrada (50x) |
| Opciones de exportación | Manual (hay que programar) | CSV/Excel | Excel, Sheets, Notion |
| Ideal para | Desarrolladores, flujos personalizados | Auditorías SEO | Usuarios de negocio, analistas |
Thunderbit es el ganador claro para usuarios de negocio que quieren resultados rápidos, sin dolores de cabeza técnicos ().
Conclusión y puntos clave
El rastreo con JavaScript ya no es una habilidad de nicho: en 2025 es imprescindible para cualquiera que necesite datos web. Con casi el 99 % de los sitios web ejecutando scripts del lado del cliente, el scraping tradicional ya no da la talla (). ¿La buena noticia? No hace falta ser desarrollador para dominarlo.
Esto es lo que debes recordar:
- El contenido dinámico está en todas partes: si quieres extraer sitios modernos, necesitas una herramienta capaz de ejecutar JavaScript.
- Los retos son reales, pero se pueden resolver: los navegadores sin interfaz gráfica, la espera inteligente y la aceleración en la nube hacen posible extraer incluso los datos más complicados.
- Thunderbit lo hace fácil: con sugerencias de campos con IA, extracción en lenguaje natural, soporte para subpáginas y paginación, y aceleración en la nube, Thunderbit pone el rastreo con JavaScript al alcance de todos.
- Mantente dentro de la normativa: respeta siempre las reglas del sitio, las leyes de privacidad y las pautas éticas.
- Empieza hoy mismo: instala Thunderbit, elige un sitio y descubre cuántos datos puedes desbloquear en solo unos clics.
¿Quieres profundizar más? Consulta el para más guías o mira nuestros para demostraciones paso a paso.
Feliz rastreo, y que tus datos sean siempre dinámicos, completos y estén listos para la acción.
Preguntas frecuentes
1. ¿Qué es el rastreo con JavaScript y en qué se diferencia del scraping tradicional?
El rastreo con JavaScript usa una herramienta que carga una página web, ejecuta todo su JavaScript y extrae el contenido que aparece después de que se ejecutan los scripts. El scraping tradicional solo toma el HTML en bruto, por lo que se pierde la mayor parte del contenido de los sitios modernos.
2. ¿Por qué necesito rastreo con JavaScript para extraer datos de negocio?
Porque casi todos los sitios web modernos usan JavaScript para cargar contenido de forma dinámica. Sin rastreo con JavaScript, te perderás listados de productos, reseñas, precios y otros datos clave.
3. ¿Cómo simplifica Thunderbit el rastreo con JavaScript para principiantes?
Thunderbit usa IA para sugerir campos, gestionar contenido dinámico y automatizar la paginación y el scraping de subpáginas. Puedes describir lo que quieres en inglés sencillo, sin necesidad de programar.
4. ¿Es legal el rastreo con JavaScript? ¿Qué debo vigilar?
El rastreo con JavaScript es legal cuando se hace con responsabilidad: quédate con datos públicos, respeta robots.txt y las condiciones de servicio, y evita extraer información personal sin consentimiento. Thunderbit fomenta el cumplimiento y el uso responsable.
5. ¿Cómo puedo escalar mi rastreo con JavaScript para trabajos grandes?
La Lightning Network de Thunderbit (scraping en la nube) te permite extraer hasta 50 páginas a la vez, lo que facilita trabajos grandes como el seguimiento de precios o la generación de leads en miles de páginas.
Más información: