

Internet rebosa de datos, tanto que se ha convertido en el motor de los negocios modernos. Ya sea que trabajes en ventas, comercio electrónico, bienes raíces o simplemente quieras vigilar a tu competencia, contar con los datos adecuados al alcance de la mano puede marcar la diferencia. Pero seamos sinceros: nadie quiere pasarse horas copiando y pegando información de sitios web en hojas de cálculo. Ahí es donde entra el web scraping, y créeme: es mucho menos intimidante de lo que parece.
En esta guía, te mostraré cómo crear un raspador web, tanto si eres principiante y quieres probar a programar en Python como si prefieres saltarte el código y usar una herramienta sin código impulsada por IA como Thunderbit. Te explicaré lo básico, te enseñaré ambos enfoques paso a paso y te ayudaré a decidir cuál se adapta mejor a tus necesidades. ¿Listo para ahorrar tiempo y aprovechar el poder de la recopilación automatizada de datos? Vamos allá.
¿Qué es un raspador web? Entendiendo lo básico
Un raspador web es simplemente una herramienta, ya sea software o un servicio, que extrae automáticamente información de sitios web. Imagina que necesitas una lista de todas las cafeterías de tu ciudad, con direcciones y números de teléfono. Podrías pasarte horas navegando por páginas y copiando cada detalle a mano (hola, cansancio de Ctrl+C), o podrías dejar que un raspador web haga el trabajo pesado por ti.
Piensa en un raspador web como un asistente digital que lee páginas web, encuentra los datos que quieres (como precios, nombres de productos o información de contacto) y los organiza ordenadamente en una hoja de cálculo o una base de datos. En lugar de cambiar manualmente entre pestañas del navegador y Excel, el raspador automatiza el proceso: obtiene, analiza y guarda los datos en una fracción del tiempo.
Así funciona por dentro:
- Solicitud: el raspador envía una solicitud a una página web y descarga el HTML en bruto.
- Análisis: examina el HTML para encontrar los datos concretos que buscas (como el precio dentro de una etiqueta
<span>). - Extracción: extrae los datos y los guarda en un formato estructurado (CSV, Excel, Google Sheets, etc.).
Copiar y pegar a mano es como cavar un hoyo con una cuchara. El web scraping es traer una retroexcavadora.
Por qué crear un raspador web es importante para los negocios
El web scraping no es solo para técnicos o científicos de datos: se ha convertido en algo imprescindible para cualquiera que necesite información fiable y actualizada. Casi el 97 % de las grandes organizaciones ya invierte en la toma de decisiones basada en datos, y la cobertura de analistas sobre el mercado del web scraping proyecta de forma consistente un crecimiento sostenido durante varios años hasta finales de la década.
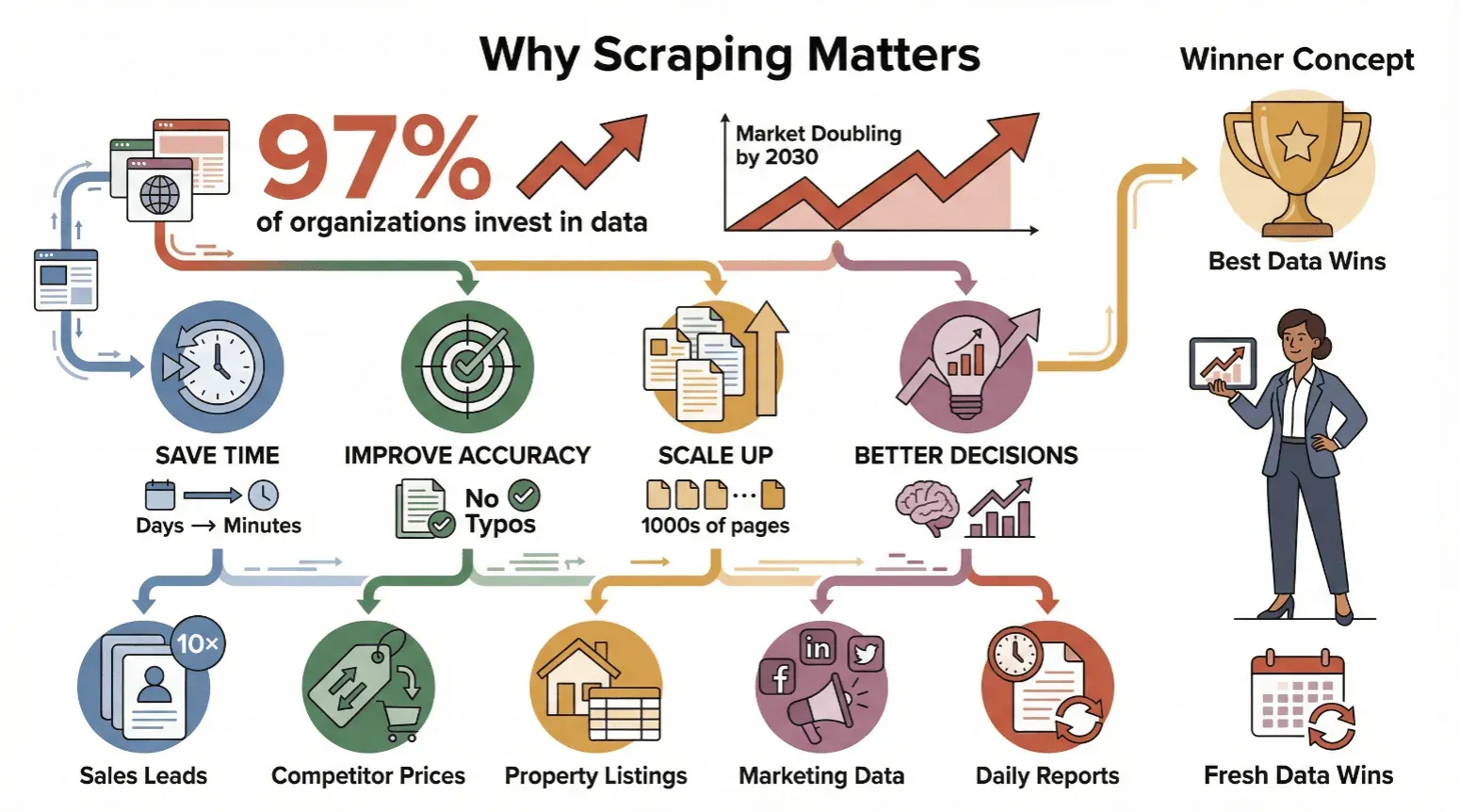
Estas son algunas razones por las que empresas de todos los tamaños están adoptando el web scraping:
- Ahorra tiempo: la extracción automatizada convierte días de trabajo manual en minutos.
- Mejora la precisión: el software no se cansa ni comete erratas.
- Escala fácilmente: extrae datos de miles de páginas, no solo de unas pocas.
- Toma mejores decisiones: datos actualizados significan movimientos más inteligentes, ya sea al ajustar precios, encontrar leads o seguir tendencias.
Veamos algunos casos de uso reales:
| Caso de uso | Quién se beneficia | Resultado habitual |
|---|---|---|
| Extraer leads de ventas desde directorios | Equipos de ventas | 10× más leads, horas ahorradas en prospección |
| Vigilar precios de la competencia en e-commerce | Responsables de e-commerce | Ajustes de precios en tiempo real, protección del margen |
| Agrupar anuncios inmobiliarios | Agencias inmobiliarias | Detección más rápida de oportunidades, datos de mercado actualizados |
| Recopilar datos de marketing de web/redes sociales | Equipos de marketing | Campañas mejor segmentadas, seguimiento del rendimiento mejorado |
| Automatizar informes diarios de datos web | Operaciones, analistas | Menores costos laborales, menos errores, informes consistentes y puntuales |
En resumen: gana quien tiene los mejores datos y los más recientes.
Guía para principiantes: cómo crear un raspador web simple con Python
Si te intriga cómo funciona el web scraping “por dentro”, Python es un gran punto de partida. Aunque no tengas experiencia programando, puedes construir un raspador básico en solo unos pasos. Así es como se hace:
Preparar tu entorno
Primero, necesitas tener Python instalado en tu ordenador. Descarga la versión más reciente desde python.org y sigue las instrucciones para tu sistema operativo (Windows o Mac). Asegúrate de marcar “Add Python to PATH” durante la instalación.
Después, abre tu terminal o símbolo del sistema e instala las bibliotecas que vas a necesitar:
pip install requests
pip install bs4
pip install pandas
requestste permite obtener páginas web.bs4(Beautiful Soup) ayuda a analizar el HTML.pandases ideal para guardar datos en CSV o Excel.
Inspeccionar la estructura del sitio web
Antes de escribir código, necesitas saber dónde están los datos dentro del HTML. Abre el sitio web objetivo en Chrome, haz clic derecho sobre el dato que quieras (como un título de empleo) y selecciona “Inspeccionar”. Verás cómo se resalta el elemento HTML, quizá una etiqueta <a> con una clase como jobtitle. Toma nota de esas etiquetas y clases; las usarás para decirle a tu raspador qué debe buscar.
Escribir y ejecutar el raspador
Supongamos que quieres extraer títulos de empleo y nombres de empresa de una página de ofertas de trabajo. Aquí tienes un script sencillo:
import requests
from bs4 import BeautifulSoup
import pandas as pd
URL = "https://example.com/jobs" # Sustituye por tu URL objetivo
response = requests.get(URL)
soup = BeautifulSoup(response.text, 'html.parser')
# Encuentra todos los títulos de empleo y nombres de empresa (ajusta los selectores según sea necesario)
titles = [t.get_text().strip() for t in soup.find_all('a', class_='jobtitle')]
companies = [c.get_text().strip() for c in soup.find_all('div', class_='company')]
# Guardar en CSV
df = pd.DataFrame({'Título del puesto': titles, 'Empresa': companies})
df.to_csv('jobs.csv', index=False)
print("¡Extracción completada! Datos guardados en jobs.csv")
- Ajusta la URL y los nombres de clase para que coincidan con tu sitio objetivo.
- Ejecuta el script en tu terminal:
python yourscript.py - Abre
jobs.csvpara ver los resultados.
Consejo profesional: para sitios más complejos (con paginación o contenido dinámico), tendrás que añadir bucles o usar herramientas como Selenium. Pero para muchas páginas estáticas, este enfoque funciona perfectamente.
Sencillez sin código: cómo crear un raspador web con Thunderbit
Ahora bien, ¿qué pasa si no quieres lidiar con código en absoluto? Ahí es donde entra Thunderbit, un raspador web sin código impulsado por IA y diseñado para usuarios de negocio. En páginas sencillas y bien estructuradas, Thunderbit puede llevarte de “necesito estos datos” a una hoja de cálculo útil en un par de clics; en sitios más pesados, con inicios de sesión, defensas anti-bot o diseños poco habituales, todavía hace falta algo de ajuste, pero el nivel de entrada es mucho más bajo que escribir un analizador a mano.
Extrae datos de cualquier sitio web usando IA Get Started Free
Así funciona:
Paso 1: instala la extensión de Chrome de Thunderbit
Ve a la página de descarga de la extensión de Chrome de Thunderbit y añádela a tu navegador. Crea una cuenta gratuita (el plan gratuito te permite extraer algunas páginas para probarlo).
Paso 2: abre el sitio web objetivo
Abre en Chrome la página que quieres extraer. Inicia sesión si hace falta y desplázate hacia abajo para cargar cualquier contenido dinámico.
Paso 3: describe los datos que necesitas
Haz clic en el icono de Thunderbit para abrir la barra lateral. Puedes:
- Hacer clic en “Sugerir campos con IA” y dejar que la IA de Thunderbit analice la página y proponga columnas (como “Nombre del producto”, “Precio”, “Imagen”).
- O escribir una instrucción en lenguaje natural (por ejemplo, “Extrae todos los títulos de libros y autores de esta página”).
La IA de Thunderbit recomendará automáticamente los campos y los tipos de datos. Puedes renombrar, añadir o eliminar campos según lo necesites.
Paso 4: ejecuta tu primera extracción
Una vez definidos los campos, solo tienes que pulsar “Extraer”. Thunderbit sacará los datos, gestionará la paginación si hace falta y mostrará todo en una tabla ordenada. Si quieres más detalles de subpáginas (como páginas individuales de producto), haz clic en “Extraer subpáginas”: Thunderbit visitará cada enlace y obtendrá información adicional.
Paso 5: revisa y exporta los resultados
Revisa los datos en la tabla de Thunderbit. Cuando estés satisfecho, haz clic en “Exportar” y elige el formato: Excel, CSV, Google Sheets, Airtable, Notion o JSON. Las exportaciones son gratuitas e ilimitadas.
Y eso es todo. Sin código, sin plantillas, sin dolores de cabeza.
Prueba gratis Thunderbit AI Web Scraper
Comparación entre soluciones tradicionales y sin código para raspadores web
Veamos cómo se comparan ambos enfoques:
| Solución | Tiempo de configuración | Habilidades necesarias | Mantenimiento | Flexibilidad | Opciones de exportación |
|---|---|---|---|---|---|
| Python + Beautiful Soup | Horas/días | Programación, nociones de HTML | Alto (se rompe con facilidad) | Muy alta | CSV, Excel, JSON (mediante código) |
| Herramientas antiguas sin código | 30–60 min | Algo de conocimiento técnico | Medio (arreglo manual) | Buena para páginas estáticas | CSV, Excel |
| Thunderbit (IA sin código) | Minutos | Ninguna (lenguaje natural) | Bajo (la IA se adapta) | Alta (sitios dinámicos) | Excel, CSV, Sheets, Notion... |
El enfoque basado en IA de Thunderbit hace que pases menos tiempo configurando y arreglando raspadores, y más tiempo usando realmente tus datos.
Superar los retos de los raspadores web tradicionales
Los raspadores tradicionales tienen algunos puntos débiles muy conocidos:
- Cambios en el sitio web: si un sitio actualiza su diseño, tu código puede dejar de funcionar. La IA de Thunderbit se adapta automáticamente a la mayoría de los cambios, así que no tienes que volver a programar nada.
- Medidas anti-bot: muchos sitios bloquean scripts automáticos. Thunderbit puede ejecutarse en tu navegador (usando tu inicio de sesión/sesión) o en la nube para mayor velocidad.
- Contenido dinámico: las páginas con scroll infinito o botones de “Cargar más” pueden dejar en blanco a los raspadores básicos. La IA de Thunderbit gestiona el desplazamiento automático y los elementos interactivos por defecto.
- Datos que requieren inicio de sesión: con el modo navegador de Thunderbit, si puedes verlo en Chrome, puedes extraerlo.
En resumen, Thunderbit está diseñado para manejar la realidad compleja de los sitios web modernos, así tú no tienes que hacerlo.
Aumentar la eficiencia: funciones avanzadas de web scraping de Thunderbit
Thunderbit no solo sirve para obtener datos, sino para obtenerlos rápido, limpios y listos para usar. Estas son algunas funciones que me encantan:
Paginación automática y extracción de subpáginas
¿Necesitas extraer cientos de productos repartidos en varias páginas? Thunderbit detecta la paginación (botones de Siguiente, scroll infinito) y recoge todo de una sola vez. ¿Quieres más detalles desde subpáginas? Haz clic en “Extraer subpáginas” y Thunderbit visitará cada enlace, incorporando campos extra (como información del vendedor o especificaciones del producto).
Sugerencias de campos con IA y estructuración de datos
La IA de Thunderbit no solo adivina columnas: entiende el contexto. Puede etiquetar columnas, asignar tipos de datos (texto, número, imagen, email) e incluso aplicar instrucciones personalizadas (como “solo precios superiores a 100 $” o “traducir las descripciones al inglés”). Puedes añadir indicaciones para categorizar, resumir o reformatear los datos mientras se extraen.
Plantillas y extracción instantánea
Para sitios populares (Amazon, Zillow, Google Maps, Instagram), Thunderbit ofrece plantillas instantáneas: solo elige tu sitio y todos los campos ya estarán configurados. No hace falta preparar nada.
Programación y automatización
¿Necesitas datos nuevos cada día? Configura una programación (“todos los lunes a las 9:00”) y Thunderbit extraerá automáticamente, actualizando tu hoja de Google o base de datos sin que levantes un dedo.
Extracción en la nube vs. local
Elige entre ejecutar las extracciones en tu navegador (ideal para sitios con inicio de sesión o interactivos) o en la nube (más rápido para datos públicos, hasta 50 páginas a la vez).
Qué es el data scraping y cómo hacerlo en 2025 Get Started Free
Las funciones avanzadas de Thunderbit lo convierten en una opción de primer nivel para usuarios de negocio que necesitan web scraping fiable, escalable y fácil de usar.
Guía paso a paso: cómo crear un raspador web con Thunderbit
Aquí tienes tu lista rápida para empezar:
- Instala Thunderbit: añade la extensión de Chrome y regístrate.
- Abre tu sitio web objetivo: inicia sesión si hace falta y desplázate para cargar el contenido.
- Abre la barra lateral de Thunderbit: haz clic en el icono de la extensión.
- Describe tus datos: haz clic en “Sugerir campos con IA” o escribe tu instrucción.
- Revisa los campos: renombra, añade o elimina columnas según sea necesario.
- Haz clic en “Extraer”: deja que Thunderbit haga su trabajo.
- (Opcional) Extrae subpáginas: para datos más profundos, haz clic en “Extraer subpáginas”.
- Revisa los resultados: comprueba que la tabla sea correcta.
- Exporta los datos: elige Excel, CSV, Google Sheets, Notion, Airtable o JSON.
- Guarda/plantilla/programa: guarda tu configuración para la próxima vez o programa extracciones recurrentes.
Consejos para solucionar problemas:
- Si faltan datos, prueba a reformular tu instrucción o usa indicaciones personalizadas.
- Para contenido dinámico, asegúrate de estar en modo navegador.
- Si alcanzas el límite del plan gratuito, considera actualizar para extraer más páginas.
Ver precios y planes de Thunderbit
Conclusión y conclusiones clave
Crear un raspador web ya no es solo cosa de programadores. Tanto si quieres arremangarte y escribir Python como si prefieres dejar que la IA haga el trabajo pesado, las herramientas son más accesibles que nunca.
Qué debes recordar:
- El web scraping ahorra tiempo, mejora la precisión y desbloquea decisiones basadas en datos.
- Python es excelente para aprender y para proyectos a medida, pero exige programación y mantenimiento.
- Thunderbit ofrece una solución rápida y sin código: solo describe lo que quieres y haz clic en “Extraer”.
- Funciones avanzadas como la paginación automática, la extracción de subpáginas y las sugerencias de campos con IA convierten a Thunderbit en una herramienta potentísima para usuarios de negocio.
- Puedes probar Thunderbit gratis y ver resultados en minutos.
¿Listo para dejar de copiar y pegar y empezar a automatizar? Descarga Thunderbit y descubre lo fácil que puede ser el web scraping. Y si quieres profundizar más, visita el blog de Thunderbit para encontrar más tutoriales y consejos.
Prueba gratis Thunderbit AI Web Scraper Get Started Free
Preguntas frecuentes
1. ¿Necesito saber programar para crear un raspador web?
¡No! Aunque programar (como con Python + Beautiful Soup) te da control total, las herramientas sin código como Thunderbit permiten que cualquiera cree raspadores web potentes usando instrucciones en lenguaje natural y un par de clics.
2. ¿Qué tipo de datos puedo extraer con Thunderbit?
Thunderbit puede extraer texto, números, imágenes, emails, números de teléfono y más de casi cualquier sitio web, incluidas listas con paginación y subpáginas. También puedes usar plantillas para sitios populares.
3. ¿Cómo maneja Thunderbit los sitios web que cambian su diseño?
La IA de Thunderbit se adapta automáticamente a la mayoría de los cambios de diseño. A diferencia de los raspadores tradicionales, que dejan de funcionar cuando un sitio se actualiza, Thunderbit usa comprensión semántica para seguir funcionando con ajustes mínimos.
4. ¿El web scraping es legal y seguro?
El web scraping es legal cuando recopilas datos disponibles públicamente y respetas las condiciones de uso del sitio. Thunderbit promueve un uso responsable y ofrece funciones para ayudarte a mantener el cumplimiento.
5. ¿Puedo programar extracciones recurrentes o automatizar exportaciones?
¡Sí! Thunderbit te permite programar extracciones en cualquier intervalo (diario, semanal, etc.) y exportar los resultados directamente a Google Sheets, Notion, Airtable, Excel o CSV, sin trabajo manual.
¿Listo para automatizar tu recopilación de datos? Prueba Thunderbit gratis y comprueba lo fácil que puede ser el web scraping para cualquiera.
Más información
- Cómo empezar a crear un raspador web: guía para principiantes
- Cómo extraer datos de un sitio web: guía para principiantes de 2025
- Cómo rastrear sitios web: guía paso a paso para principiantes
- Cómo escribir un raspador web con Python: de principio a fin
- Guía completa de web scraping en Python: paso a paso




