En la era digital, los datos web son como el oro negro moderno, pero están esparcidos por millones de páginas, escondidos en HTML caótico y protegidos por todo tipo de barreras, desde CAPTCHAs hasta scripts anti-bots. Si alguna vez te tocó copiar y pegar precios, info de la competencia o leads a mano, sabes que es una receta para acabar con dolor de muñeca y perder oportunidades valiosas. Por eso el raspado web se ha vuelto una habilidad clave para cualquier negocio actual. De hecho, el mercado de datos alternativos (donde el raspado web es protagonista) llegó a los y sigue creciendo a toda velocidad.

Pero ojo: aunque Python es el preferido de quienes recién empiezan, Go (o Golang, como también se le conoce) está detrás de algunos de los raspadores web más veloces y sólidos del planeta. ¿El truco de Go? Concurrencia rapidísima, una librería estándar súper completa y un rendimiento que enamora a los ingenieros de backend. He visto equipos reducir a la mitad el tiempo de sus scrapers solo por pasarse a Go—y con las herramientas correctas, no hace falta ser ingeniero de Google para arrancar.
¿Listo para hacer de Go tu as bajo la manga en el raspado web? Te llevo paso a paso—desde la instalación hasta scraping avanzado—con ejemplos reales, tips útiles y cómo herramientas de IA como pueden llevar tu flujo de trabajo a otro nivel.
¿Por qué apostar por Go para el raspado web? El lado práctico
Vamos al grano: cuando tienes que raspar miles (o millones) de páginas, cada segundo cuenta. Go fue creado justo para este tipo de tareas pesadas. Aquí te dejo las razones por las que cada vez más empresas eligen Go para el raspado web:
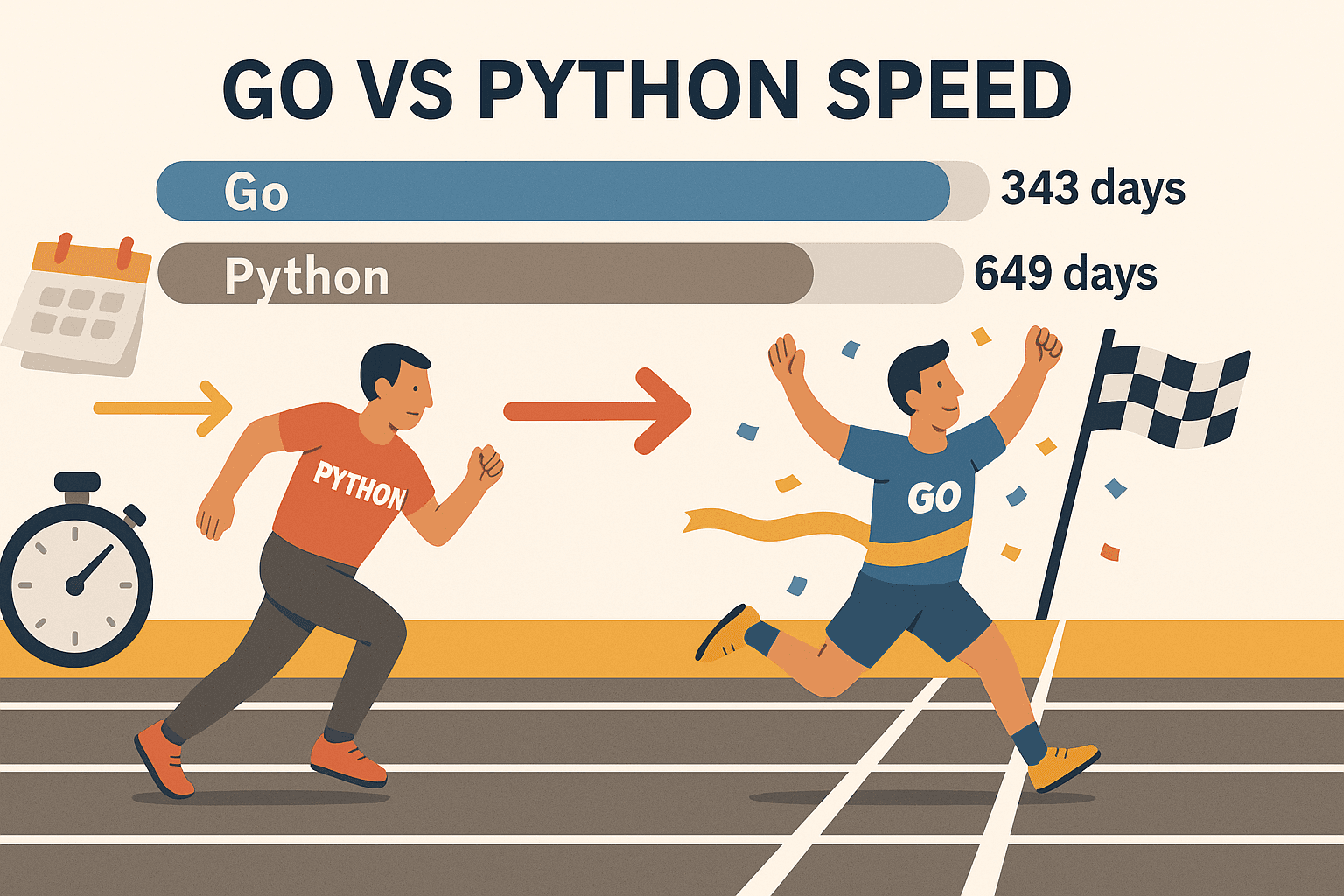
- Concurrencia que realmente escala: Las goroutines de Go (hilos ligeros) te dejan raspar cientos de páginas al mismo tiempo—sin que tu compu se derrita. En una prueba, Go raspó , mientras que Python tardó 649 días en lo mismo. No es solo más rápido, es otro nivel.
- Estabilidad y fiabilidad: El tipado fuerte y la gestión eficiente de memoria de Go lo hacen ideal para scrapers grandes y de larga duración. Olvídate de que tu script se caiga a mitad de la noche.
- Red de primer nivel: La librería estándar de Go trae todo lo que necesitas para peticiones HTTP, parseo de HTML y manejo de JSON—sin depender de paquetes externos para arrancar.
- Despliegue fácil: Go compila en un solo binario, así que puedes correr tu scraper donde quieras—sin líos de entornos virtuales ni dependencias.
- Adopción en la industria: Go es ahora el (por encima de Node.js), y lo usan gigantes como Google, Uber y Netflix.
Claro, Python sigue siendo genial para tareas rápidas o cuando necesitas librerías de machine learning. Pero si buscas velocidad, escalabilidad y fiabilidad, Go es difícil de igualar—sobre todo con librerías como Colly y Goquery.
Paso 1: Prepara tu entorno Go para el raspado web
Antes de empezar a raspar, necesitas tener Go instalado y listo. La buena noticia: es súper fácil.
1. Instala Go
- Ve a la y baja el instalador para tu sistema (Windows, macOS o Linux).
- Ejecuta el instalador y sigue los pasos. En Linux, también puedes usar tu gestor de paquetes.
- Abre una terminal y escribe:
Si ves algo como1go versiongo version go1.21.0 darwin/amd64, todo está bien.
¿Problemas? Si go no aparece, revisa que tu PATH esté bien configurado. En Linux/macOS, puede que necesites agregar export PATH=$PATH:/usr/local/go/bin a tu ~/.bash_profile o ~/.zshrc.
2. Arranca un nuevo proyecto Go
- Crea una carpeta para tu scraper:
1mkdir mi-scraper && cd mi-scraper - Inicializa un módulo Go:
Esto crea un archivo1go mod init github.com/tuusuario/mi-scrapergo.modpara manejar tus dependencias.
3. Elige tu editor
- con la extensión de Go es una gran opción (autocompletado, linting y depuración).
- JetBrains GoLand es otra favorita entre los fans de Go.
- Vim/Neovim con plugins de Go si eres de la vieja escuela.
4. Prueba tu entorno
Crea un archivo rápido main.go:
1package main
2import "fmt"
3func main() {
4 fmt.Println("¡Go está instalado y funcionando!")
5}Ejecuta:
1go run main.goSi ves tu mensaje, ya puedes arrancar.
Paso 2: Haz tu primera petición HTTP en Go
¡Hora de traer tu primera página web! El paquete net/http de Go lo hace facilísimo.
Ejemplo básico de HTTP GET:
1package main
2import (
3 "fmt"
4 "io"
5 "net/http"
6)
7func main() {
8 resp, err := http.Get("https://example.com")
9 if err != nil {
10 fmt.Println("Error al obtener la URL:", err)
11 return
12 }
13 defer resp.Body.Close()
14 body, err := io.ReadAll(resp.Body)
15 if err != nil {
16 fmt.Println("Error al leer la respuesta:", err)
17 return
18 }
19 fmt.Println(string(body))
20}Puntos clave:
- Siempre revisa errores después de
http.Get. - Usa
defer resp.Body.Close()para evitar fugas de recursos. - Usa
io.ReadAllpara leer toda la respuesta.
Tips pro:
- Para agregar cabeceras personalizadas (como User-Agent), usa
http.NewRequest:1req, _ := http.NewRequest("GET", "https://example.com", nil) 2req.Header.Set("User-Agent", "Mozilla/5.0") 3client := &http.Client{} 4resp, err := client.Do(req) - Siempre revisa
resp.StatusCode—un 200 es éxito, pero 403 o 404 significa que te bloquearon o la página no existe.
Paso 3: Parsear HTML y extraer datos con Go
Tener el HTML es solo el primer paso. Ahora toca sacar lo que importa—nombres de productos, precios, enlaces, lo que busques.
Aquí entra Goquery: Es una librería de Go que te da selectores tipo jQuery para parsear HTML.
Instala Goquery:
1go get github.com/PuerkitoBio/goqueryEjemplo: Extraer nombres y precios de productos
1package main
2import (
3 "fmt"
4 "net/http"
5 "github.com/PuerkitoBio/goquery"
6)
7func main() {
8 resp, err := http.Get("https://example.com/products")
9 if err != nil {
10 panic(err)
11 }
12 defer resp.Body.Close()
13 doc, err := goquery.NewDocumentFromReader(resp.Body)
14 if err != nil {
15 panic(err)
16 }
17 doc.Find("div.product").Each(func(i int, s *goquery.Selection) {
18 name := s.Find("h2").Text()
19 price := s.Find(".price").Text()
20 fmt.Printf("Producto %d: %s - %s\n", i+1, name, price)
21 })
22}¿Cómo funciona?
doc.Find("div.product")selecciona todos los contenedores de productos.- Dentro de cada uno,
s.Find("h2").Text()saca el nombre ys.Find(".price").Text()el precio.
Expresiones regulares: Para patrones simples (como emails), el paquete regexp de Go es rápido y sencillo. Para lo demás, mejor usa Goquery.
Paso 4: Lleva tu scraper al siguiente nivel con librerías Go (Colly & Gocolly)
¿Listo para subir de nivel? es el framework estrella para el raspado web en Go. Se encarga del crawling, concurrencia, cookies y más—para que tú te concentres en los datos, no en la infraestructura.
Por qué Colly es top:
- API sencilla: Registra callbacks para los elementos que quieres extraer.
- Concurrencia: Raspa cientos de páginas en paralelo con
colly.Async(true). - Crawling automático: Sigue enlaces y maneja paginación sin complicaciones.
- Anti-bot: Configura cabeceras, rota user agents y gestiona cookies.
- Gestión de errores: Hooks integrados para peticiones fallidas.
Instala Colly:
1go get github.com/gocolly/colly/v2Ejemplo básico con Colly:
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly/v2"
5)
6func main() {
7 c := colly.NewCollector(
8 colly.AllowedDomains("example.com"),
9 colly.Async(true),
10 )
11 c.OnHTML(".product-list-item", func(e *colly.HTMLElement) {
12 name := e.ChildText("h2")
13 price := e.ChildText(".price")
14 fmt.Printf("Producto: %s - %s\n", name, price)
15 })
16 c.OnRequest(func(r *colly.Request) {
17 r.Headers.Set("User-Agent", "Mozilla/5.0")
18 })
19 c.OnError(func(r *colly.Response, err error) {
20 fmt.Println("Fallo en la petición:", r.Request.URL, "->", err)
21 })
22 c.Visit("https://example.com/products")
23 c.Wait()
24}Comparativa: Goquery vs. Colly
| Funcionalidad | Goquery | Colly |
|---|---|---|
| Parseo de HTML | Sí | Sí (usa Goquery internamente) |
| Peticiones HTTP | Manual | Integrado |
| Concurrencia | Manual (goroutines) | Fácil (Async(true)) |
| Crawling/Enlaces | Manual | Automático |
| Anti-bot | Manual | Integrado |
| Gestión de errores | Manual | Integrado |
Colly te ahorra un montón de tiempo en cualquier proyecto que vaya más allá de un scraping básico.
Paso 5: Cómo superar los retos reales del raspado web en Go
El raspado web en la vida real no siempre es fácil. Así puedes sortear los obstáculos más comunes:
1. Bloqueo de IP
- Rota proxies usando
http.Transportde Go o el soporte de proxies de Colly. - Baja la velocidad de tus peticiones con delays aleatorios.
2. User-Agent y cabeceras
- Siempre usa un User-Agent realista (tipo Chrome o Firefox).
- Imita cabeceras de navegador reales (Accept-Language, etc.).
3. CAPTCHAs
- Si te sale un CAPTCHA, probablemente estás raspando muy rápido o de forma muy obvia.
- Usa navegadores headless (como ) para sitios que requieren JavaScript o interacción visual.
- Para sitios muy protegidos, considera integrar un servicio de resolución de CAPTCHAs.
4. Paginación
- Con Colly, puedes seguir enlaces “Siguiente” automáticamente:
1c.OnHTML("a.next", func(e *colly.HTMLElement) { 2 e.Request.Visit(e.Attr("href")) 3})
5. Contenido dinámico (JavaScript)
- Las librerías HTTP de Go no ejecutan JS. Usa un navegador headless (Rod, chromedp) o raspa los endpoints de la API si los encuentras.
6. Cuando todo se complica… Usa Thunderbit
A veces, te topas con un muro—quizá el sitio es muy dinámico o necesitas los datos rápido y sin programar. Ahí entra . Thunderbit es una extensión de Chrome para el raspado web con IA que:
- Usa IA para detectar y extraer campos—solo haz clic en “AI Suggest Columns”.
- Navega subpáginas y paginación automáticamente.
- Funciona en un navegador real (o en la nube), así que puede con sitios llenos de JavaScript y la mayoría de medidas anti-bot.
- Exporta directo a Excel, Google Sheets, Airtable o Notion—sin escribir código.
- Permite programar extracciones y automatizar la recolección de datos para tu equipo.
Thunderbit es la solución ideal para usuarios de negocio, equipos de ventas o cualquiera que necesite datos estructurados sin programar. Y sí, lo admito—mi equipo y yo lo creamos para resolver justo estos problemas.
Combina Go y Thunderbit para máxima productividad
Aquí va el tip: no tienes que elegir entre Go y Thunderbit. Los equipos más cracks usan ambos.
Ejemplo de flujo de trabajo:
- Usa Go (con Colly) para rastrear una gran lista de URLs o recolectar datos básicos a escala.
- Pasa las URLs a Thunderbit para extraer información detallada y estructurada—ideal para subpáginas, contenido dinámico o defensas anti-bot complicadas.
- Exporta los datos de Thunderbit a Google Sheets o CSV.
- Usa Go de nuevo para procesar, unir o analizar los datos como necesites.
Este enfoque mixto te da la velocidad y control de Go, más la flexibilidad y la inteligencia de IA de Thunderbit. Es como tener una navaja suiza y un taladro eléctrico en tu caja de herramientas.
Comparativa de soluciones de raspado web en Go: Go puro vs. Colly vs. Thunderbit
Aquí tienes una tabla rápida para ayudarte a elegir la mejor herramienta para cada caso:
| Aspecto | Go puro (net/http + html) | Go + Colly (Librería) | Thunderbit (IA sin código) |
|---|---|---|---|
| Configuración y curva | Alta (requiere código) | Media (API más sencilla) | Muy baja (sin código, IA) |
| Concurrencia | Manual (goroutines) | Integrada (Async(true)) | Paralelismo en la nube/navegador |
| Contenido dinámico (JS) | Requiere navegador headless | Algo de soporte JS, o Rod | Navegador completo, JS nativo |
| Anti-bot | Manual (proxies, headers) | Funciones integradas | Automático, IPs en la nube |
| Estructura de datos | Código personalizado | Callbacks, structs propios | IA sugiere y da formato automático |
| Opciones de exportación | Personalizado (CSV, BD, etc.) | Personalizado | Excel, Sheets, Notion, Airtable |
| Mantenimiento | Alto (actualizar código) | Medio | Bajo (IA se adapta a cambios) |
| Ideal para | Devs, pipelines a medida | Devs, prototipos rápidos | No programadores, usuarios negocio |
Tip: Usa Go/Colly para proyectos personalizados, a gran escala o integrados en backend. Usa Thunderbit cuando busques rapidez, facilidad o tengas que lidiar con sitios complejos del lado del cliente.
Resumen: Cómo empezar con el raspado web en Go
- Go es una bestia para el raspado web—sobre todo si necesitas velocidad, concurrencia y fiabilidad.
- Empieza simple: Prepara tu entorno Go, haz peticiones HTTP y parsea HTML con Goquery.
- Potencia con Colly: Para crawling, concurrencia y trucos anti-bot, Colly es tu mejor amigo.
- Supera los retos reales: Rota proxies, configura cabeceras y usa navegadores headless o Thunderbit para sitios difíciles.
- Combina herramientas: No dudes en mezclar Go y Thunderbit para aprovechar lo mejor de ambos mundos.
El raspado web multiplica la productividad de ventas, operaciones e investigación. Con Go y las librerías adecuadas (y un toque de IA), puedes automatizar lo tedioso y enfocarte en los insights que hacen crecer tu negocio.
Recursos extra para el raspado web con Go
¿Quieres profundizar más? Aquí tienes algunos de mis recursos favoritos:
¡Feliz scraping! Que tus datos siempre estén ordenados, tus scrapers sean veloces y tu café bien cargado.
Preguntas frecuentes
1. ¿Por qué debería usar Go para el raspado web en vez de Python o JavaScript?
Go ofrece mejor concurrencia, velocidad y fiabilidad—sobre todo para proyectos de scraping grandes o de larga duración. Es ideal si necesitas raspar miles de páginas rápido y quieres un binario portátil y compilado.
2. ¿Cuál es la forma más sencilla de parsear HTML en Go?
Utiliza la librería . Te da selectores tipo jQuery para recorrer el DOM y extraer datos fácilmente.
3. ¿Cómo manejo sitios con contenido generado por JavaScript en Go?
Necesitarás una librería de navegador headless como o . O usa para una solución sin código que maneja JS de forma nativa.
4. ¿Cuál es la mejor forma de evitar bloqueos al raspar?
Rota tu User-Agent, usa proxies, agrega delays entre peticiones e imita el comportamiento de un navegador real. Colly facilita estos trucos y Thunderbit gestiona la mayoría de medidas anti-bot automáticamente.
5. ¿Puedo combinar Go y Thunderbit en mi flujo de trabajo?
¡Claro! Usa Go para crawling a gran escala o integración backend, y Thunderbit para extracción con IA, scraping de subpáginas y exportación a herramientas de negocio. Es una combinación potente tanto para devs como para usuarios de negocio.
¿Listo para llevar tu scraping al siguiente nivel? Prueba la o visita el para más consejos, tutoriales y guías sobre scraping, automatización e IA.