
Resumen ejecutivo
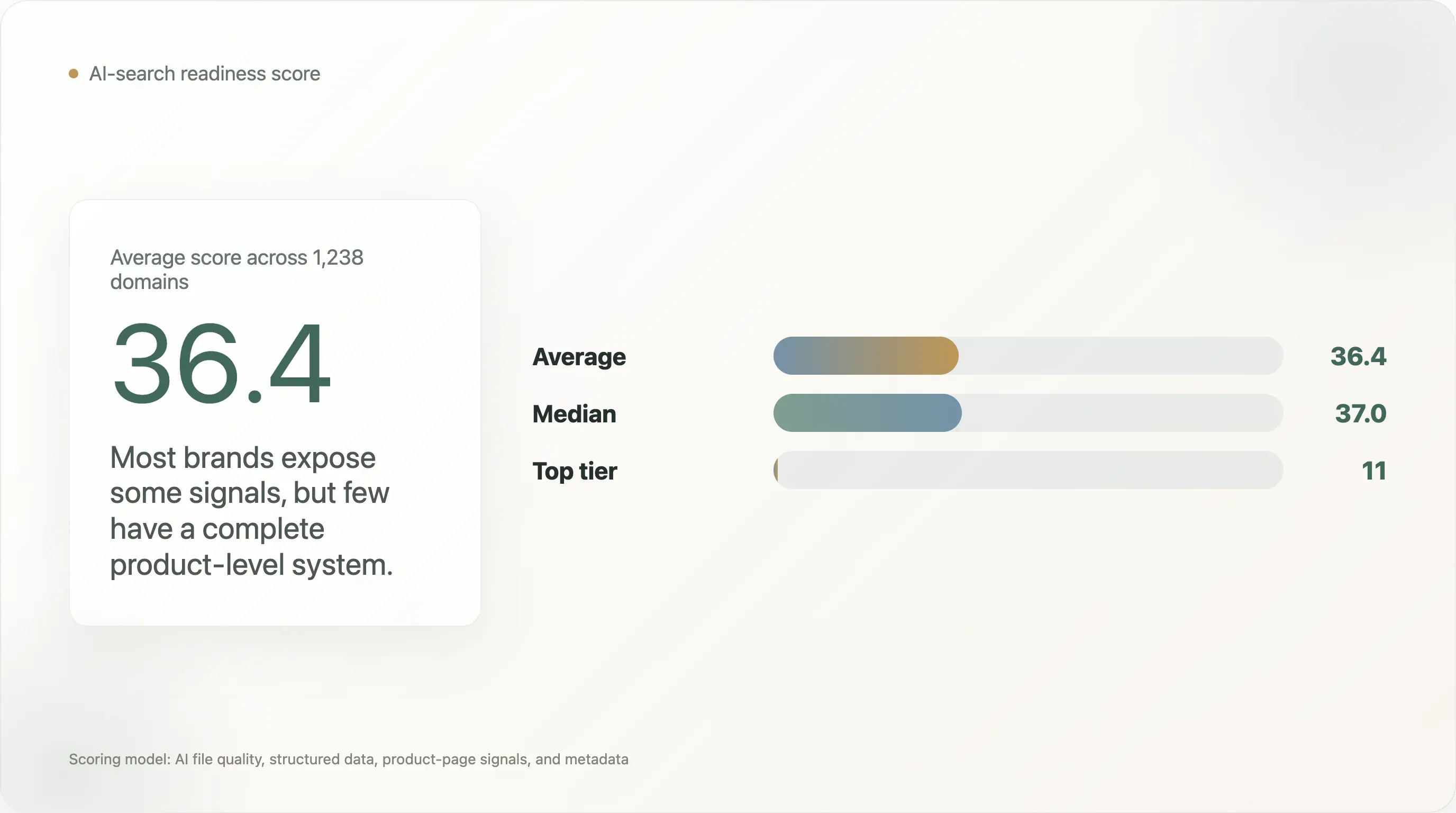
Esta investigación puntúa 1.238 dominios DTC según su preparación para la búsqueda con IA usando cuatro capas: calidad del archivo de IA, datos estructurados generales, señales estructuradas de páginas de producto y metadatos. La puntuación media es de 36,4 sobre 100, y la mediana es de 37,0. Solo 11 dominios alcanzaron el nivel ai_ready según este modelo de puntuación.
El hallazgo principal es la brecha entre la descubibilidad superficial y la comprensión a nivel de producto. El grupo de calidad de llms.txt más grande es platform_default, con 629 dominios. Eso significa que muchas marcas tienen un archivo básico legible por IA porque su plataforma lo generó. Pero el esquema Product en la página de inicio aparece solo en el 0,9% de los dominios puntuados, y el esquema Product en páginas de producto aparece en el 39,2% de los dominios puntuados donde se intentaron páginas de producto. Las señales de precio en páginas de producto aparecen en el 48,1%, y las señales de reseñas o valoraciones en el 43,5%.
La distribución por niveles muestra lo temprano que sigue estando el mercado:
| Nivel de preparación para IA | Dominios |
|---|---|
| No preparado | 435 |
| Parcialmente preparado | 425 |
| Descubribilidad básica | 367 |
| Preparado para IA | 11 |
Esa división es útil porque separa tres ideas que a menudo se mezclan. Una marca puede ser descubierta. Una marca puede tener metadatos. Una marca puede tener llms.txt. Pero ser detectable no es lo mismo que ser comprensible a nivel de producto.
La distribución de calidad de llms.txt lo deja aún más claro:
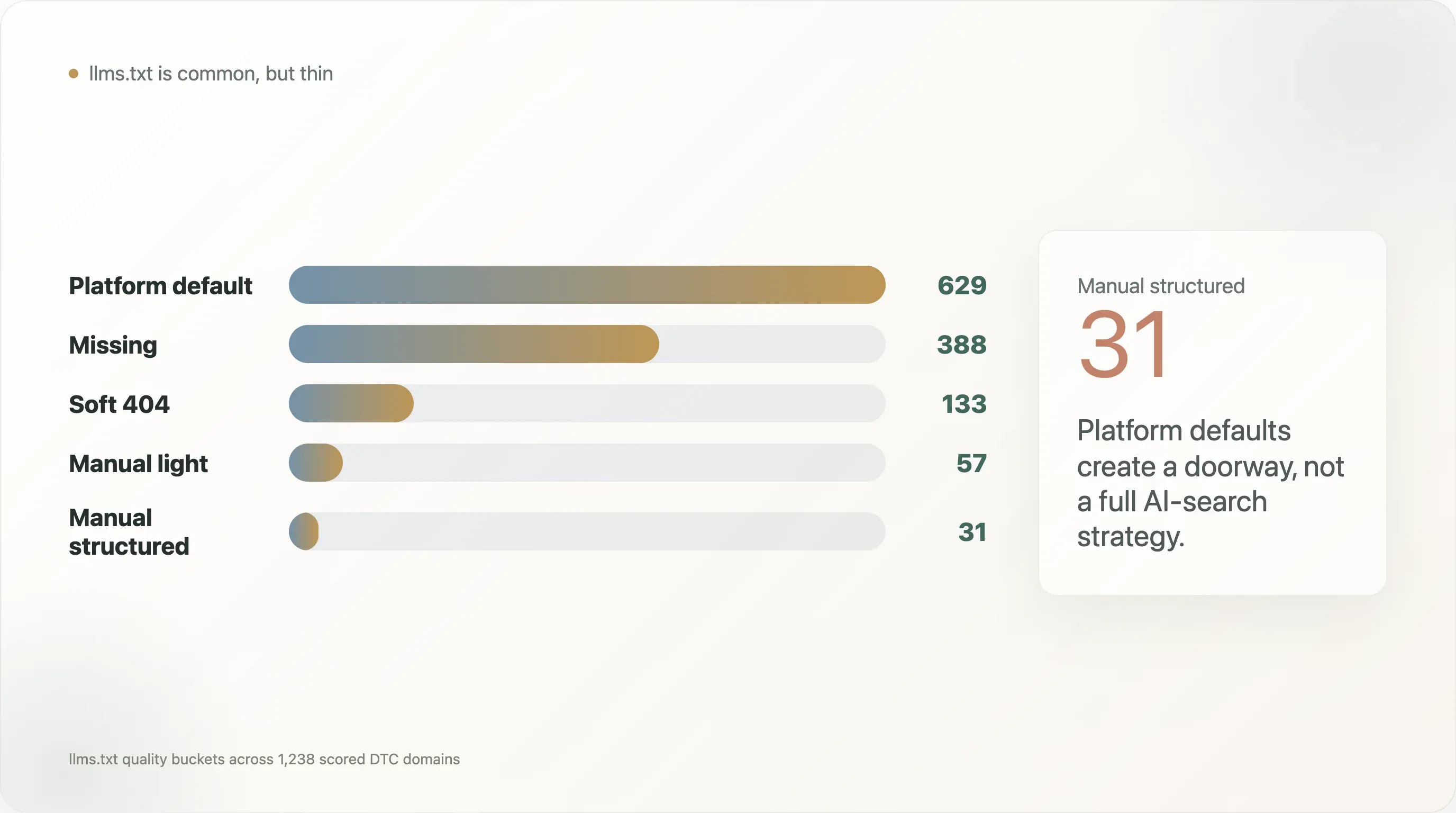
| Categoría de calidad de llms.txt | Dominios |
|---|---|
| Valor predeterminado de la plataforma | 629 |
| Ausente | 388 |
| Soft 404 | 133 |
| Manual ligero | 57 |
| Manual estructurado | 31 |
Por eso, el mejor ángulo del informe no es "las marcas DTC tienen llms.txt". Ese titular se queda demasiado en la superficie. El ángulo correcto es: los valores predeterminados de la plataforma han creado una primera capa fina de descubibilidad para IA, pero la mayoría de las marcas DTC no ha construido la capa de datos estructurados a nivel de producto que necesitan las compras con IA y los motores de respuesta.
Los ejemplos positivos muestran cómo puede verse una mejor preparación. El nivel ai_ready incluye marcas como Mokobara, Magic Mind, Le Petit Ballon, Maine Lobster Now, Yo Mama's Foods, La Maison Convertible, Unbloat, NuRange Coffee, Three Ships Beauty y Manukora. Estos ejemplos importan porque muestran que la preparación para IA no está reservada a una sola categoría ni a un solo tipo de marca. Alimentos, belleza, bienestar, muebles, moda y comercio especializado pueden mejorar su capa de producto legible por máquinas.
Los hallazgos más compartibles
-
La puntuación media de preparación para IA de DTC es solo de 36,4/100.
-
Solo 11 de los 1.238 dominios puntuados alcanzaron el nivel
ai_ready. -
llms.txt es común, pero en su mayoría generado por la plataforma. La categoría de calidad más grande es el valor predeterminado de la plataforma, con 629 dominios.
-
El llms.txt manual estructurado es raro. Solo 31 dominios entran en la categoría manual estructurada.
-
El esquema Product en la página de inicio casi no existe. Aparece solo en el 0,9% de los dominios puntuados.
-
El esquema Product en páginas de producto es mejor, pero sigue siendo incompleto. Aparece en el 39,2% de los dominios puntuados donde se intentaron páginas de producto.
-
La preparación para compras con IA requiere hechos de producto, no solo acceso del rastreador. El precio, la oferta, las reseñas, la disponibilidad y las señales del esquema Product importan más que un archivo liviano por sí solo.
1. Por qué la preparación para la búsqueda con IA es distinta del SEO básico
El SEO tradicional pregunta si una página puede rastrearse, indexarse, posicionarse y generar clics. La búsqueda con IA añade otra capa: ¿puede el sistema entender la marca, el producto, la oferta, el precio, las reseñas, la disponibilidad, las políticas y las relaciones entre entidades lo bastante bien como para responder preguntas o recomendar productos?
Esa diferencia importa para DTC porque las páginas de ecommerce están llenas de detalles que pueden ser fáciles para una persona y confusos para una máquina. Un comprador puede mirar una página de producto y entender el nombre, el precio, la talla, la opción de suscripción, el descuento, las reseñas, el estado de stock y la política de devoluciones. Un rastreador o un agente de IA necesita que esos datos estén expresados de forma coherente.
Los metadatos ayudan. Open Graph ayuda. Las etiquetas canonical ayudan. llms.txt puede ayudar a los rastreadores a encontrar contenido importante. Pero la verdadera prueba está en la estructura a nivel de producto. Si un asistente de compras con IA compara cinco proteínas en polvo, productos de cuidado de la piel, velas, vestidos o suscripciones de café, necesita hechos estructurados. Sin esos hechos, la marca puede ser visible, pero no se entenderá de forma fiable.
Este informe separa cuatro capas de preparación:
- Capa de archivo de IA: si existe llms.txt y si falta, es un soft 404, un valor predeterminado de la plataforma, un manual ligero o un manual estructurado.
- Capa de datos estructurados generales: JSON-LD, Organization, WebSite, BreadcrumbList y esquema Product.
- Capa de páginas de producto: esquema Product, señales de oferta o precio, señales de reseñas o valoraciones y señales de disponibilidad.
- Capa de metadatos: canonical, meta description, imagen Open Graph, tarjeta de Twitter, hreflang y contexto legible por máquina similar.
El modelo por capas importa porque evita una conclusión superficial. Una marca con llms.txt pero sin datos de producto no está tan preparada como parece. Una marca sin llms.txt pero con un esquema rico en las páginas de producto puede ser más comprensible de lo que sugiere la capa de archivos.
2. La historia de llms.txt: una capa delgada, creada sobre todo por plataformas
La auditoría de llms.txt produjo cinco categorías de calidad:
| Categoría de calidad | Dominios | Interpretación |
|---|---|---|
| Valor predeterminado de la plataforma | 629 | Un archivo estándar generado por la plataforma, normalmente liviano pero válido |
| Ausente | 388 | No se encontró ningún archivo utilizable |
| Soft 404 | 133 | Una respuesta engañosa o poco útil |
| Manual ligero | 57 | Archivo creado por una persona o personalizado, pero con estructura limitada |
| Manual estructurado | 31 | Archivo manual más sólido, con encabezados, enlaces y términos de producto o política |
Este es el matiz más importante del informe. A primera vista, la adopción de llms.txt parece sólida porque los archivos con valor predeterminado de la plataforma son comunes. Pero valor predeterminado de la plataforma no es lo mismo que una estrategia de búsqueda con IA pensada con cuidado. A menudo es solo una capa básica de referencia.
Eso no significa que los archivos predeterminados por la plataforma no sirvan. Pueden ayudar a los rastreadores a encontrar rutas importantes. También muestran lo rápido que las decisiones a nivel de plataforma pueden mover el mercado. Una plataforma puede darle a cientos de tiendas un nuevo archivo legible por máquina antes de que la mayoría de los equipos de marca siquiera haya hablado sobre operaciones de búsqueda con IA.
Pero la categoría manual estructurada es mucho más pequeña: 31 dominios. Entre los ejemplos de la auditoría figuran archivos manuales estructurados de marcas como Dermalogica, Ad Hoc Atelier, DKNY y varios ejemplos ai_ready como Magic Mind, Le Petit Ballon, Maine Lobster Now, Yo Mama's Foods y Three Ships Beauty. Son ejemplos positivos útiles porque muestran lo que significa ir más allá de un archivo predeterminado: más enlaces, más encabezados, más términos de producto, más términos de política y una estructura más deliberada.
La categoría soft 404 también es importante. Un soft 404 significa que la solicitud devuelve algo, pero no un archivo llms.txt útil. Eso puede engañar a auditorías sencillas. Para la preparación para la búsqueda con IA, no basta con comprobar la existencia. La calidad también importa.
3. La estructura a nivel de producto es la verdadera brecha
La brecha más fuerte en los datos está en el esquema Product.
El esquema Product en la página de inicio aparece solo en el 0,9% de los dominios puntuados. El esquema Product en páginas de producto aparece en el 39,2% de los dominios puntuados donde se intentaron páginas de producto. Las señales de precio en páginas de producto aparecen en el 48,1%, y las señales de reseñas o valoraciones aparecen en el 43,5%.
Estas cifras cuentan una historia clara. Los datos básicos del producto no siempre son legibles por máquinas, incluso cuando la marca tiene una tienda ecommerce.
Esto importa porque la búsqueda con IA y las compras con IA probablemente premiarán la claridad. Si una página de producto expone esquema Product, ofertas, precio, disponibilidad, señales de reseñas y enlaces a políticas, ofrece a las máquinas hechos más fiables. Si esos hechos están ocultos en JavaScript, plantillas incoherentes, imágenes o widgets dinámicos, las máquinas pueden malinterpretarlos o ignorarlos.
La brecha de preparación no es solo cuestión de posicionamiento. Es cuestión de representación. Cuando los sistemas de IA resumen una categoría de productos, comparan opciones, responden preguntas de "lo mejor para" o generan recomendaciones de compra, las marcas con hechos de producto más limpios pueden incluirse con mayor precisión.
Los ejemplos positivos del grupo ai_ready dejan claro el punto:
- Mokobara alcanzó la puntuación más alta en el conjunto de resultados, con 83.
- Magic Mind, Le Petit Ballon y Maine Lobster Now obtuvieron 81.
- Yo Mama's Foods obtuvo 80.
- La Maison Convertible, Unbloat, Vinocheepo y NuRange Coffee obtuvieron 79.
- Three Ships Beauty obtuvo 77.
- Manukora obtuvo 75.
Estos ejemplos abarcan varias categorías. La preparación para IA no es solo un tema de belleza ni solo un tema tecnológico. Importa para alimentos, bienestar, muebles, moda, productos especializados y cualquier categoría en la que un comprador pueda pedirle recomendaciones, comparaciones o explicaciones a un sistema de IA.
4. Niveles de preparación para IA: la mayoría de las marcas sigue por debajo del umbral
La distribución por niveles es:
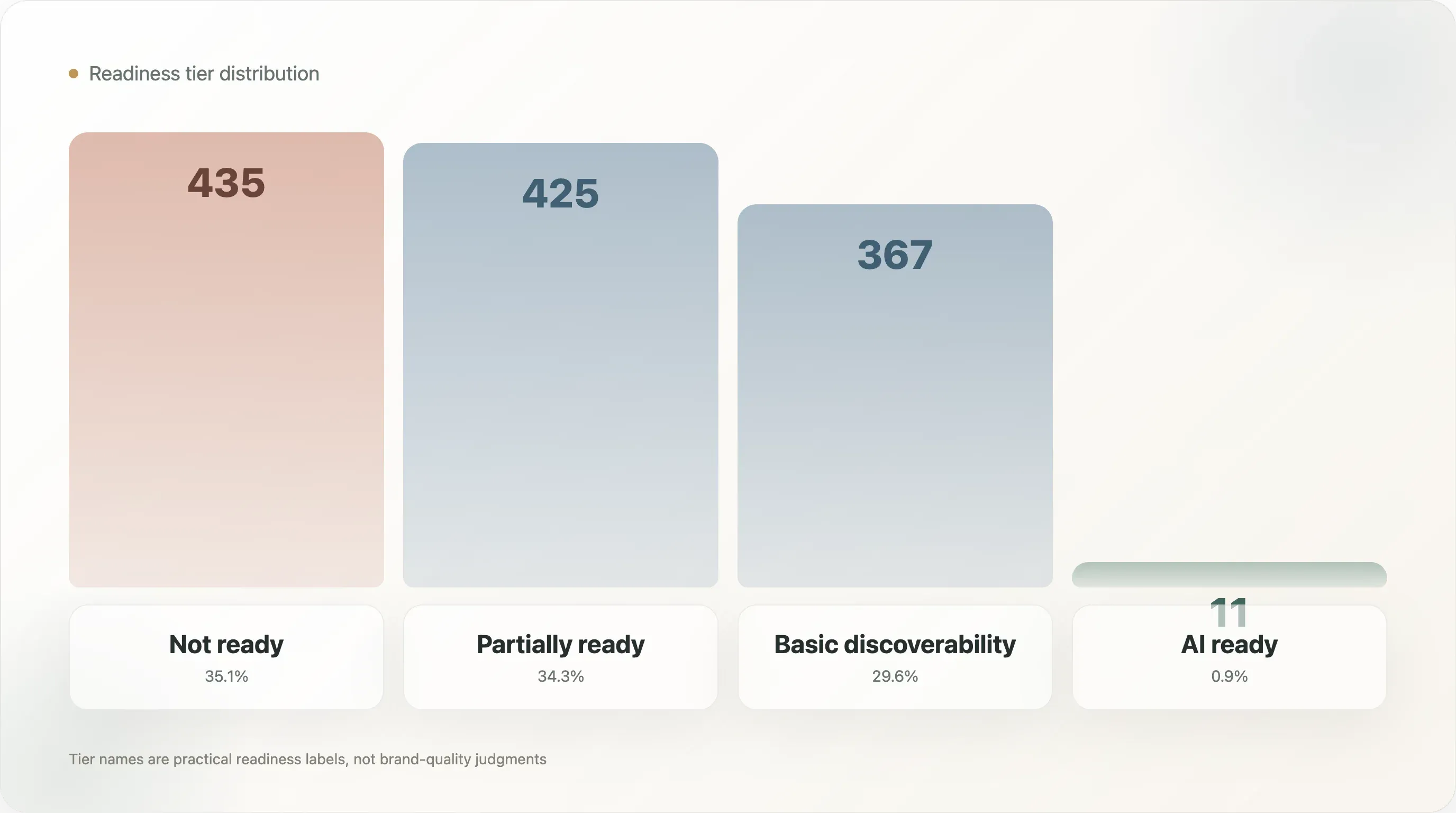
| Nivel | Dominios | Cuota de la muestra |
|---|---|---|
| No preparado | 435 | 35,1% |
| Parcialmente preparado | 425 | 34,3% |
| Descubribilidad básica | 367 | 29,6% |
| Preparado para IA | 11 | 0,9% |
Los nombres son deliberadamente prácticos. No preparado no significa que la marca sea mala. Significa que las señales públicas usadas por este modelo no muestran suficiente preparación para la búsqueda con IA. Parcialmente preparado significa que existen algunas piezas, pero faltan capas importantes. Descubribilidad básica significa que la marca es más visible para las máquinas, pero todavía puede carecer de completitud a nivel de producto. Preparado para IA significa que el dominio muestra una combinación más fuerte de calidad de archivos, datos estructurados, hechos de producto y metadatos.
Solo 11 dominios alcanzaron el nivel superior. Ese es el titular, pero la idea más útil es la forma de la zona intermedia. La muestra está casi dividida en partes iguales entre no preparado, parcialmente preparado y descubribilidad básica. El mercado no está vacío. Está en transición. Muchas marcas tienen algunas señales, pero pocas tienen un sistema completo.
Eso crea una oportunidad a corto plazo. La preparación para la búsqueda con IA sigue siendo lo bastante temprana como para que una marca pueda pasar de media a fuerte con un trabajo relativamente práctico: mejorar llms.txt, validar el esquema, exponer hechos de producto, limpiar los metadatos y facilitar que las máquinas analicen las páginas de producto.
5. Patrones por categoría: belleza y moda van por delante, pero ninguna categoría está completa
La clasificación por categoría es orientativa, no exacta. Aun así, la tabla de categorías muestra patrones útiles:
| Categoría | Muestra | Preparación media para IA | llms estructurado o manual | Esquema en página de producto | Tasa de esquema en página de producto |
|---|---|---|---|---|---|
| Belleza y cuidado de la piel | 98 | 46,2 | 3 | 56 | 57,1% |
| Moda y calzado | 149 | 45,7 | 6 | 79 | 53,0% |
| Joyería y accesorios | 34 | 44,5 | 0 | 20 | 58,8% |
| Mascotas | 15 | 43,5 | 0 | 8 | 53,3% |
| Bebés y niños | 27 | 42,6 | 1 | 15 | 55,6% |
| Alimentos y bebidas | 118 | 42,5 | 5 | 58 | 49,2% |
| Hogar y muebles | 48 | 42,3 | 0 | 23 | 47,9% |
| Salud y bienestar | 58 | 40,7 | 6 | 27 | 46,6% |
| Aire libre y deporte | 49 | 39,8 | 1 | 23 | 46,9% |
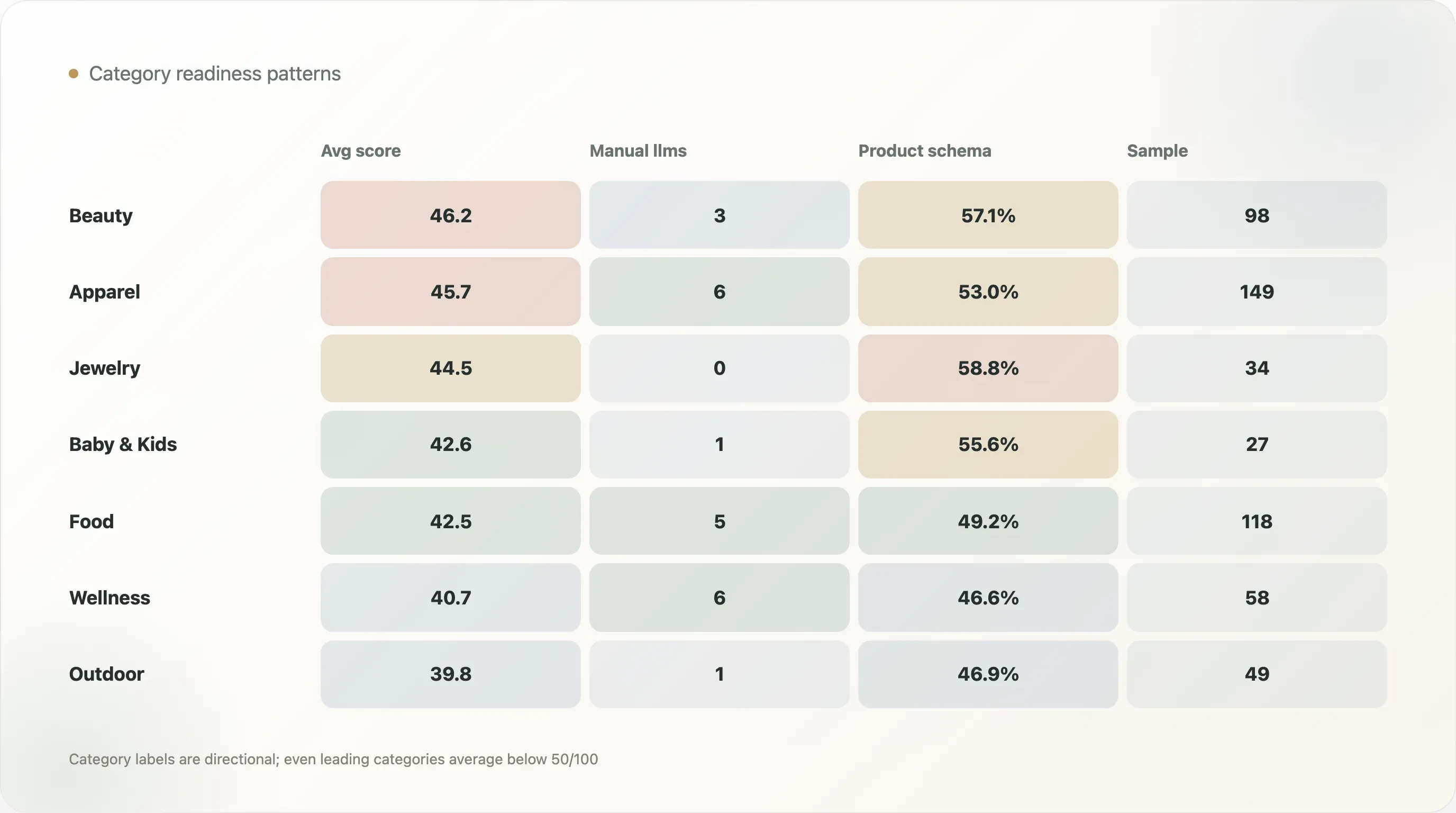
Belleza y cuidado de la piel tiene la puntuación media más alta de preparación para IA, con 46,2. Le sigue moda y calzado, con 45,7. Estas categorías suelen contar con plantillas de ecommerce sólidas, catálogos ricos, reseñas, variantes, recursos visuales y necesidades de contenido. Pueden beneficiarse más rápido del trabajo estructurado sobre producto.
Joyería y accesorios tiene una tasa alta de esquema en página de producto, con 58,8%, pero ninguna detección de llms.txt manual o estructurado en la tabla de categorías. Eso demuestra por qué la preparación debe ser por capas. Una categoría puede ser fuerte en esquema de producto y débil en calidad de archivo de IA.
Alimentos y bebidas incluye varios ejemplos positivos sólidos, entre ellos Maine Lobster Now, Yo Mama's Foods, NuRange Coffee y Manukora. Esto es importante porque los productos de alimentación y bebidas suelen necesitar hechos muy claros: ingredientes, nutrición, tamaño de porción, suscripción, origen, envío, conservación, reseñas y disponibilidad. Los sistemas de IA solo pueden representar esos detalles con precisión si el sitio los expone de forma limpia.
Salud y bienestar tiene una tasa de llms manual o estructurado del 10,3%, la más alta entre las principales categorías de la tabla, pero una puntuación media de 40,7. Esto sugiere que algunas marcas de la categoría están experimentando activamente con archivos legibles por IA, mientras que la estructura de las páginas de producto aún tiene margen de mejora. Dada la carga de confianza y educación en bienestar, esta categoría debería ser de las más agresivas en estructurar sus hechos.
Ninguna categoría está terminada. Incluso las categorías líderes promedian por debajo de 50/100. Eso convierte el contenido sobre preparación para IA específico por categoría en una gran oportunidad para redactores y consultores SEO.
6. Qué se ve bien: patrones positivos de las marcas preparadas para IA
El grupo ai_ready es pequeño, pero útil porque muestra patrones que merece la pena copiar.
Mokobara obtuvo 83, la puntuación más alta del conjunto. Aparece como un ejemplo de preparación sólida combinada, no como una victoria de una sola señal.
Magic Mind, Le Petit Ballon y Maine Lobster Now obtuvieron 81 cada una y entran en la categoría de llms manual estructurado. Eso importa porque muestran trabajo deliberado a nivel de archivo, no solo valores predeterminados de la plataforma.
Yo Mama's Foods obtuvo 80, también con llms manual estructurado. Las marcas de alimentos pueden beneficiarse de una estructura legible por IA porque a los sistemas se les puede preguntar por ingredientes, sabor, casos de uso, recetas, adecuación dietética y comparaciones.
Three Ships Beauty obtuvo 77 con llms manual estructurado. La belleza es una categoría ideal para la preparación estructurada para IA porque los compradores preguntan por tipo de piel, ingredientes, rutinas, textura, reseñas y alternativas.
Manukora obtuvo 75. La miel y los productos alimentarios cercanos al bienestar suelen requerir educación sobre origen, calidad, beneficios, certificaciones y uso, por lo que las señales estructuradas de producto y políticas son valiosas.
La lección no es que todas las marcas deban verse iguales. La lección es que la preparación para IA es un sistema:
- Un archivo llms.txt útil
- Metadatos limpios
- Datos estructurados de organización y sitio web
- Esquema en páginas de producto
- Señales de precio y oferta
- Señales de reseñas o valoraciones
- Señales de disponibilidad
- Claridad en políticas y soporte
Cualquiera de esas capas ayuda. La combinación es lo que crea preparación.
7. Por qué llms.txt por sí solo no basta
llms.txt se ha convertido en una forma cómoda de resumir la preparación para IA. Es comprensible, porque es visible, fácil de comprobar y lo bastante nuevo como para parecer estratégico. Pero esta investigación muestra por qué no debería tratarse como toda la historia.
Un archivo llms.txt predeterminado por la plataforma puede crear una puerta de entrada básica. Puede indicar a los rastreadores páginas importantes. Puede decirles a las máquinas que el sitio tiene un punto de entrada legible por IA. Pero si las páginas de producto no exponen con claridad los datos del producto, la puerta conduce a una habitación desordenada.
El problema de la búsqueda con IA no es solo "¿puede el rastreador encontrar el sitio?" También es:
- ¿Puede el rastreador identificar el producto?
- ¿Puede identificar la marca?
- ¿Puede analizar el precio?
- ¿Puede analizar la disponibilidad?
- ¿Puede identificar reseñas o valoraciones?
- ¿Puede distinguir el contenido del producto del contenido de marketing?
- ¿Puede entender las políticas?
- ¿Puede comparar variantes?
- ¿Puede citar la página canonical correcta?
llms.txt ayuda con la navegación y la priorización. Los datos estructurados de producto ayudan con la comprensión. La preparación para IA necesita ambas cosas.
8. El manual del operador: cómo mejorar la preparación para la búsqueda con IA
Para equipos de DTC y ecommerce, el flujo de trabajo práctico es sencillo.
Paso 1: Revisar la capa del archivo de IA. ¿El dominio tiene llms.txt? ¿Es real o es un soft 404? ¿Es un valor predeterminado de la plataforma, un manual ligero o uno estructurado? ¿Apunta a páginas útiles?
Paso 2: Auditar los metadatos. Confirma las etiquetas canonical, las meta descriptions, las imágenes Open Graph, las tarjetas de Twitter, el hreflang donde corresponda y el viewport móvil. No son glamorosos, pero ayudan a las máquinas a construir contexto.
Paso 3: Validar JSON-LD. Revisa el esquema Organization, WebSite, BreadcrumbList y Product. El esquema Product es la brecha más importante del ecommerce.
Paso 4: Auditar las páginas de producto, no solo la página de inicio. Las compras con IA prestarán atención a las páginas de producto. Confirma nombre del producto, descripción, imagen, precio, oferta, disponibilidad, SKU, reseñas, valoraciones, variantes y política de devoluciones.
Paso 5: Hacer estables los hechos de producto. Evita ocultar hechos críticos solo en imágenes, pestañas que no se renderizan bien o widgets de JavaScript que los rastreadores pueden no analizar.
Paso 6: Mejorar la claridad de las políticas. El envío, las devoluciones, los términos de suscripción, las garantías, las certificaciones y las afirmaciones de seguridad deben ser fáciles de encontrar y de analizar.
Paso 7: Volver a probar después de cambios de plantilla. El esquema suele romperse durante rediseños, cambios de tema, cambios de app y migraciones a headless. Trata los datos estructurados como parte del control de calidad.
Paso 8: Asumir la responsabilidad del sistema. La preparación para IA no debería recaer solo en SEO. Afecta a ecommerce, producto, contenido, ingeniería, legal y atención al cliente.
9. Qué pueden citar SEO y contenido
Esta investigación genera varios ángulos sólidos de cita:
"Solo 11 de los 1.238 dominios DTC puntuados alcanzaron el nivel preparado para IA." Este es el gancho más amplio sobre preparación.
"llms.txt es común, pero en su mayoría generado por la plataforma." La categoría de valor predeterminado de la plataforma contiene 629 dominios, mientras que los archivos manuales estructurados solo aparecen en 31.
"El esquema Product en la página de inicio aparece solo en el 0,9% de los dominios puntuados." Esta es la brecha más aguda en datos estructurados.
"El esquema Product en páginas de producto aparece en el 39,2% donde se intentaron páginas de producto." Esto añade matiz: las páginas de producto son mejores que las de inicio, pero siguen incompletas.
"Belleza y moda lideran la tabla por categoría, pero aun así promedian por debajo de 50/100." Esto crea un ángulo específico por categoría.
"La preparación para IA es por capas." Este es el punto educativo más importante para lectores que, de otro modo, podrían equiparar llms.txt con preparación completa.
La advertencia es esencial: los datos reflejan señales públicas del sitio web en esta muestra, no la adopción total de la industria ni el rendimiento interno de búsqueda.
10. Qué cambia las compras con IA para los equipos DTC
El descubrimiento tradicional en ecommerce se construía alrededor de páginas, rankings, anuncios y clics. Un comprador buscaba, comparaba resultados, abría páginas, leía reseñas y tomaba decisiones. Las compras con IA y los motores de respuesta comprimen ese recorrido. Un comprador puede preguntar por "la mejor salsa baja en azúcar para pasta entre semana", "una mochila de mano por menos de 200 dólares con buenas reseñas" o "un limpiador suave para piel sensible sin fragancia". El sistema de IA puede resumir opciones antes de que el comprador vea la página de una marca.
Eso cambia el trabajo de la página de producto. La página sigue teniendo que convencer a personas, pero también debe describir el producto con suficiente claridad para que las máquinas lo comparen. El tono de marca no basta. Las imágenes bonitas no bastan. Un nombre de producto ingenioso no basta. La máquina necesita hechos: qué es, para quién es, cuánto cuesta, si está disponible, qué variantes existen, qué dicen las reseñas, qué afirmaciones están respaldadas, qué ingredientes o materiales importan y qué políticas aplican.
Por eso la estructura a nivel de producto importa más que un archivo genérico de IA. llms.txt puede ayudar a un rastreador a entender dónde mirar. El esquema Product y los hechos limpios de la página de producto le ayudan a entender lo que encontró.
El riesgo para las marcas DTC no es solo quedar fuera. Es ser mal representadas. Si una página de producto es poco clara, una respuesta de IA puede resumir la característica equivocada, pasar por alto un diferenciador clave, omitir una política importante o comparar el producto de forma injusta con competidores mejor estructurados. En ese sentido, la preparación para IA también es una cuestión de protección de marca.
Para categorías con recorridos de decisión complejos, las apuestas son más altas. Los compradores de belleza preguntan por tipo de piel, ingredientes, rutinas, sensibilidad y resultados. Los compradores de alimentos preguntan por nutrición, alérgenos, origen, sabor, recetas y adecuación dietética. Los compradores de moda preguntan por ajuste, talla, materiales, devoluciones y estilo. Los compradores de bienestar preguntan por evidencia, uso, seguridad y confianza. Los compradores de hogar preguntan por dimensiones, materiales, entrega, montaje y durabilidad. Todos esos son, tanto como problemas de marketing, problemas de contenido legible por máquinas.
La oportunidad es que la mayoría de las marcas sigue muy temprano. La puntuación media de preparación es solo de 36,4/100, y solo 11 dominios alcanzaron el nivel ai_ready. Una marca no necesita esperar a una reconstrucción completa del sitio. Puede empezar por plantillas, esquema, claridad de políticas y hechos de producto.
11. Un plan de preparación para IA por departamento
La preparación para IA no debería pertenecer solo a SEO. Afecta a varios equipos.
SEO se encarga de la descubibilidad y de validar el esquema. Los equipos SEO deberían auditar etiquetas canonical, metadatos, datos estructurados, esquema Product, breadcrumbs, hreflang y rastreabilidad. También deberían vigilar si el esquema Product sobrevive a los cambios de tema y a las actualizaciones de apps.
Ecommerce se encarga de los hechos de la página de producto. El nombre del producto, el precio, las variantes, la disponibilidad, los paquetes, las suscripciones, las reseñas, las condiciones de envío y los detalles de devolución deben ser claros y coherentes. Si esos hechos están fragmentados entre widgets, pestañas, imágenes y scripts, las máquinas pueden tener dificultades.
Contenido se encarga de la profundidad explicativa. Los sistemas de IA premian las páginas que responden preguntas con claridad. Guías de compra, tablas comparativas, explicaciones de ingredientes, páginas de casos de uso, guías de tallas y secciones de preguntas frecuentes pueden ayudar tanto a personas como a máquinas.
Ingeniería se encarga de la calidad de implementación. El esquema debe ser válido, estable y basado en plantillas. Los hechos de producto no deberían depender por completo de un renderizado frágil del lado del cliente. Las plantillas de página de producto deberían probarse después de cada lanzamiento.
Legal y compliance se encargan de las afirmaciones. Si un producto hace afirmaciones de salud, sostenibilidad, seguridad, ingredientes o rendimiento, esas afirmaciones deben ser precisas, justificables y fáciles de interpretar. Los sistemas de IA pueden amplificar afirmaciones poco claras.
Atención al cliente se encarga de las preguntas recurrentes. Los tickets de soporte revelan lo que los compradores y los sistemas de IA pueden preguntar: tiempo de envío, ajuste, ingredientes, compatibilidad, devoluciones, cancelación de suscripción, instrucciones de cuidado y comparaciones de productos. Esas preguntas deberían alimentar el contenido de la página de producto.
La dirección se encarga de priorizar. La preparación para IA compite con muchos otros proyectos. El argumento para la dirección es simple: los hechos estructurados del producto apoyan el SEO, la búsqueda con IA, los feeds de producto, las compras de pago, la búsqueda interna, el soporte y la conversión. No es solo un proyecto de IA.
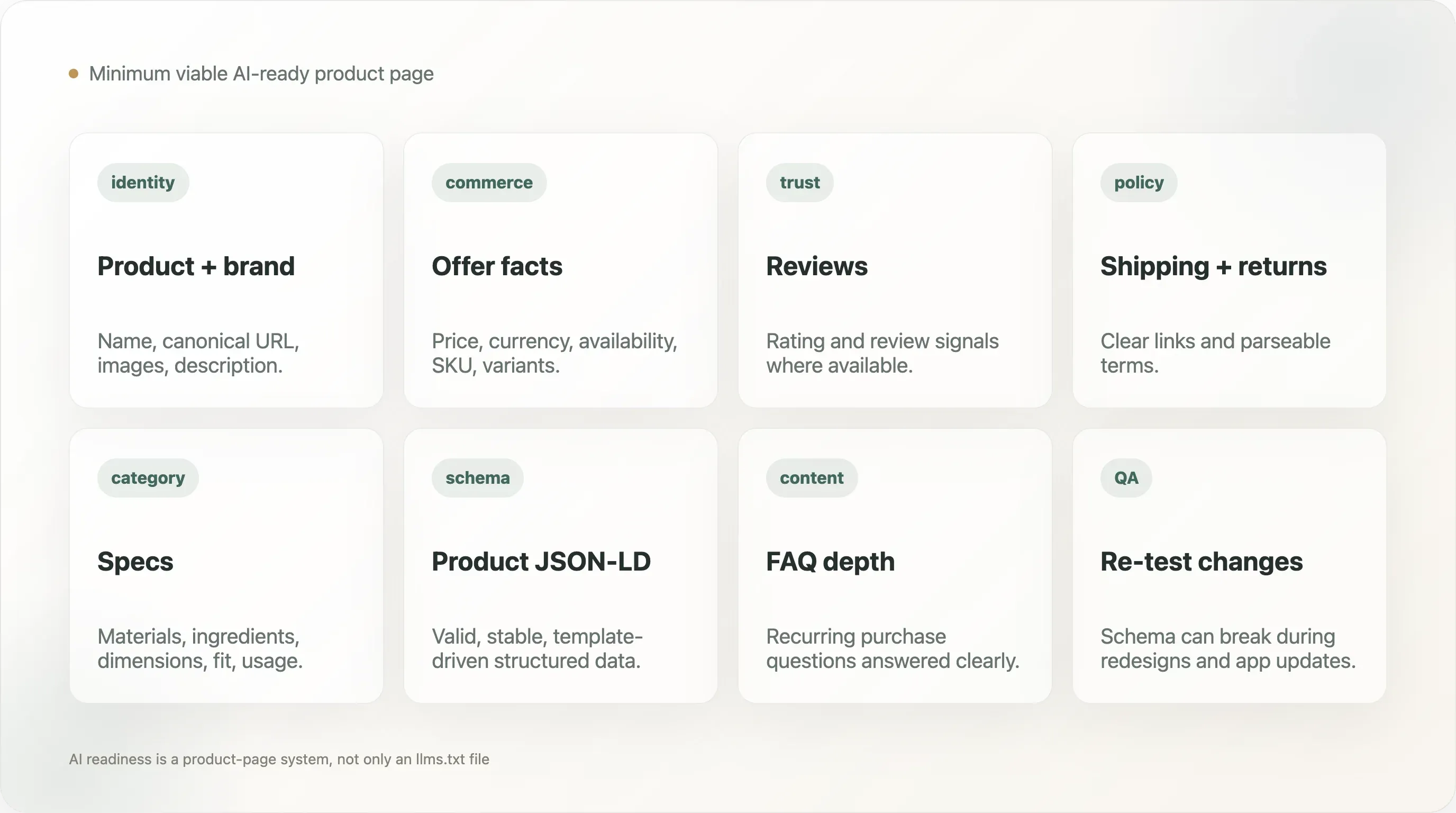
12. La página de producto mínima viable para IA
Una página de producto DTC práctica debería exponer:
- Nombre del producto
- Nombre de la marca
- URL canonical
- Descripción del producto
- Imágenes del producto
- Precio
- Moneda
- Disponibilidad
- Información de variantes
- SKU o identificador de producto cuando corresponda
- Señales de reseñas o valoraciones cuando estén disponibles
- Detalles de la oferta
- Enlaces a políticas de envío y devoluciones
- Datos de materiales, ingredientes o especificaciones cuando sean relevantes para la categoría
- Contenido de preguntas frecuentes o soporte para dudas recurrentes de compra
La página también debería incluir un esquema Product válido y evitar ocultar hechos críticos solo dentro de imágenes o scripts que los rastreadores pueden no analizar. Esto no exige páginas de producto aburridas. Exige separar el diseño persuasivo de los hechos estructurados fiables.
Para muchas marcas, la victoria más rápida no es escribir un largo documento de estrategia de IA. Es validar diez páginas de producto importantes, corregir el esquema y asegurarse de que los hechos más importantes del producto sean visibles en el HTML y en los datos estructurados.
Metodología
Esta investigación utiliza el conjunto de datos del doble informe DTC recopilado el 11 de mayo de 2026. Puntuó 1.238 dominios usando master.csv, detection.csv, seo_signals.csv, archivos llms.txt sin procesar y HTML de páginas de producto sin procesar cuando estuvo disponible.
El modelo de puntuación separa cuatro capas:
- Capa de archivo de IA: existencia y calidad de llms.txt.
- Capa de datos estructurados generales: JSON-LD, Organization, WebSite, BreadcrumbList, Product y señales estructuradas relacionadas.
- Capa de páginas de producto: esquema Product, señales de oferta o precio, señales de reseñas o valoraciones y señales de disponibilidad.
- Capa de metadatos: canonical, meta description, imagen Open Graph, tarjeta de Twitter, hreflang y contexto de página relacionado.
El modelo genera una puntuación de preparación para IA de 0 a 100 y asigna los dominios a uno de cuatro niveles: no preparado, parcialmente preparado, descubribilidad básica y ai_ready.
Advertencias
-
La preparación para IA no es tráfico de IA. La puntuación no mide las derivaciones reales desde sistemas de búsqueda con IA o agentes de compra.
-
Las señales públicas son un límite inferior. Algunos datos estructurados pueden cargarse dinámicamente o aparecer de formas que el rastreo no captó.
-
La calidad de llms.txt es heurística. Los archivos manuales estructurados se identifican mediante características observables, como encabezados, enlaces y términos de producto o política.
-
La detección en páginas de producto depende de los intentos de obtener esas páginas. Los porcentajes de esquema en páginas de producto se aplican donde se intentaron y estuvieron disponibles páginas de producto.
-
La muestra no es un censo completo de DTC. Está sesgada hacia marcas visibles en ecosistemas de herramientas de ecommerce y listas públicas de DTC.
-
Las etiquetas de categoría son orientativas. Son útiles para comparaciones amplias, pero no para una taxonomía exacta.
-
Los estándares de búsqueda con IA siguen evolucionando. El modelo de puntuación está diseñado como un punto de referencia práctico para 2026, no como una definición permanente.
Notas de reproducibilidad
La carpeta de entrega incluye:
analyze_ai_search_readiness.py— script de puntuación usado para evaluar dominios DTC a través dellms.txt, datos estructurados, señales de páginas de producto y señales de metadatos.ai_search_readiness_scores.csv— puntuaciones de preparación para IA a nivel de dominio, niveles y señales por componente.llms_quality_audit.csv— auditoría de calidad dellms.txta nivel de dominio, incluidas las clasificaciones valor predeterminado de la plataforma, soft 404, ausente, manual ligero y manual estructurado.category_ai_readiness.csv— comparación de preparación para IA a nivel de categoría.top_ai_ready_brands.csv— dominios con mayor puntuación para revisión editorial y selección de ejemplos.lowest_ai_ready_brands.csv— dominios con menor puntuación para análisis de brechas y revisión editorial.summary.json— métricas agregadas destacadas citadas en este informe, incluidos tamaño de la muestra, recuento por niveles, puntuación media, puntuación mediana y tasas de señales en páginas de producto.
Las correcciones metodológicas, los problemas del conjunto de datos y los análisis de seguimiento son bienvenidos en support@thunderbit.com. Este informe se publica de forma independiente de cualquier posición comercial que Thunderbit mantenga; construimos un raspador web con IA y tenemos un interés estructural en que los sitios web de ecommerce públicos sean más fáciles de entender con precisión para personas, motores de búsqueda y agentes de IA. El punto de referencia se basa en 1.238 dominios DTC puntuados a partir de señales públicas de sitios web recopiladas el 11 de mayo de 2026. Los datos de este informe se sostienen por sí mismos. — El equipo de investigación de Thunderbit, mayo de 2026.