La web en 2025 es como la jungla digital: la mitad del tráfico que ves no viene de personas de verdad. Así tal cual: los bots y crawlers ya suman más del 50% de toda la actividad online (), y solo una parte chiquita son los bots “buenos” que te interesan: motores de búsqueda, generadores de previews en redes sociales y herramientas de analítica. ¿El resto? Mejor ni te cuento, porque no siempre están para ayudarte. Después de años creando herramientas de automatización e IA en , he visto cómo un crawler bien configurado (o uno malicioso) puede levantar tu SEO, arruinar tus métricas, comerse tu ancho de banda o incluso meterte en líos de seguridad.
Si tienes un negocio, administras una web o simplemente quieres tener tu espacio digital bajo control, saber quién entra a tu servidor es más importante que nunca. Por eso armé esta guía 2025 con los crawlers más importantes: qué hacen, cómo reconocerlos y cómo dejar pasar a los bots útiles mientras mantienes a raya a los indeseados.
¿Qué hace que un Crawler sea “Reconocido”? User-Agent, IPs y Verificación
Vamos a lo básico: ¿qué es un crawler “reconocido”? En pocas palabras, es un bot que se identifica con un user-agent claro (tipo Googlebot/2.1 o bingbot/2.0) y, de preferencia, opera desde rangos de IPs o bloques ASN públicos y verificables (). Los grandes—Google, Microsoft, Baidu, Yandex, DuckDuckGo—publican info sobre sus bots y, muchas veces, te dan herramientas o archivos JSON con sus IPs oficiales (, , ).
Pero ojo: confiar solo en el user-agent es jugársela. El spoofing está a la orden del día—muchos bots malos se hacen pasar por Googlebot o Bingbot para saltarse tus defensas (). Por eso, lo ideal es la verificación doble: checar tanto el user-agent como la IP (o ASN), usando búsquedas DNS inversas o listas oficiales. Si usas una herramienta como , puedes automatizar todo esto—sacas los logs, comparas user-agents y cruzas IPs para tener una lista confiable y en tiempo real de quién está rastreando tu web.
Cómo Usar Esta Lista de Crawlers
¿Y para qué te sirve una lista de crawlers reconocidos? Aquí te dejo cómo sacarle jugo:
- Deja pasar a los bots útiles: Asegúrate de que los bots que te interesan (motores de búsqueda, previews sociales) nunca sean bloqueados por tu firewall, CDN o WAF. Usa sus IPs y user-agents oficiales para permitirlos con precisión.
- Filtra en tu analítica: Excluye el tráfico de bots en tus métricas para que tus datos reflejen visitas humanas reales—no solo Googlebot y AhrefsBot paseando por tu web ().
- Gestión de bots: Aplica reglas de crawl-delay o limita herramientas SEO muy agresivas, y bloquea o desafía a bots desconocidos o sospechosos.
- Análisis automático de logs: Usa herramientas de IA (como Thunderbit) para extraer, clasificar y etiquetar la actividad de crawlers en tus registros, así puedes detectar tendencias, identificar impostores y mantener tus políticas al día.
Tener tu lista de crawlers al día no es algo que puedas dejar en automático. Salen nuevos bots, otros cambian de comportamiento y los atacantes se ponen más creativos cada año. Automatizar las actualizaciones—raspando documentación oficial o repos de GitHub con Thunderbit—te ahorra tiempo y dolores de cabeza.
1. Thunderbit: Identificación de Crawlers y Gestión de Datos con IA
no es solo un Raspador Web IA—es como un copiloto de datos para equipos que quieren entender y controlar el tráfico de crawlers. ¿Por qué es diferente?

- Preprocesamiento semántico: Antes de extraer datos, Thunderbit convierte páginas web y logs en contenido estructurado tipo Markdown. Así la IA entiende el contexto, los campos y la lógica de lo que analiza. Perfecto para páginas complejas, dinámicas o llenas de JavaScript (como Facebook Marketplace o hilos de comentarios largos) donde los scrapers clásicos fallan.
- Verificación doble: Thunderbit puede recopilar rápido la documentación oficial de IPs y listas ASN de crawlers, y compararlas con tus logs. ¿El resultado? Una “lista blanca de crawlers confiables” en la que sí puedes confiar—sin tener que revisar todo a mano.
- Extracción automática de logs: Sube tus logs a Thunderbit y los transforma en tablas estructuradas (Excel, Sheets, Airtable), etiquetando visitantes frecuentes, rutas sospechosas y bots reconocidos. Desde ahí, puedes mandar los resultados a tu WAF o CDN para bloquear, limitar o poner CAPTCHAs automáticamente.
- Cumplimiento y auditoría: La extracción semántica de Thunderbit deja un historial claro—quién accedió, cuándo y cómo lo gestionaste. Esto es clave para cumplir con GDPR, CCPA y otras leyes.
He visto equipos reducir hasta un 80% el trabajo de gestión de crawlers usando Thunderbit—y por fin saber qué bots ayudan, cuáles molestan y cuáles solo fingen ser útiles.
2. Googlebot: El Estándar de los Motores de Búsqueda
es el rey de los crawlers web. Se encarga de indexar tu sitio para Google Search—si lo bloqueas, es como ponerle un letrero de “Cerrado” a tu negocio online.
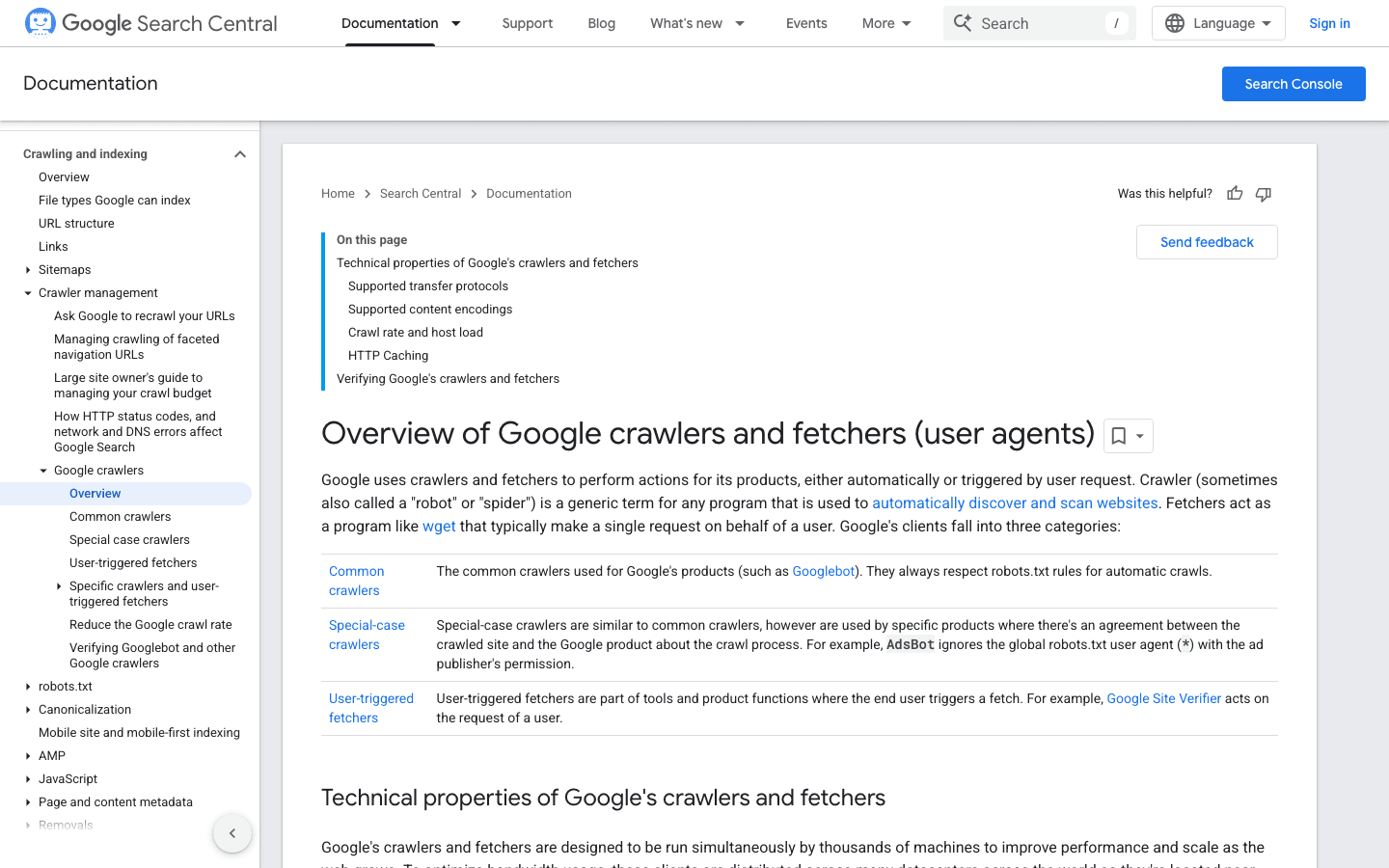
- User-Agent:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - Verificación: Usa el o la .
- Consejos de gestión: Deja siempre pasar a Googlebot. Usa robots.txt para guiar (no bloquear) su rastreo y ajusta la frecuencia en Google Search Console si hace falta.
3. Bingbot: El Explorador Web de Microsoft
alimenta los resultados de Bing y Yahoo. Es el segundo crawler más importante para la mayoría de los sitios.
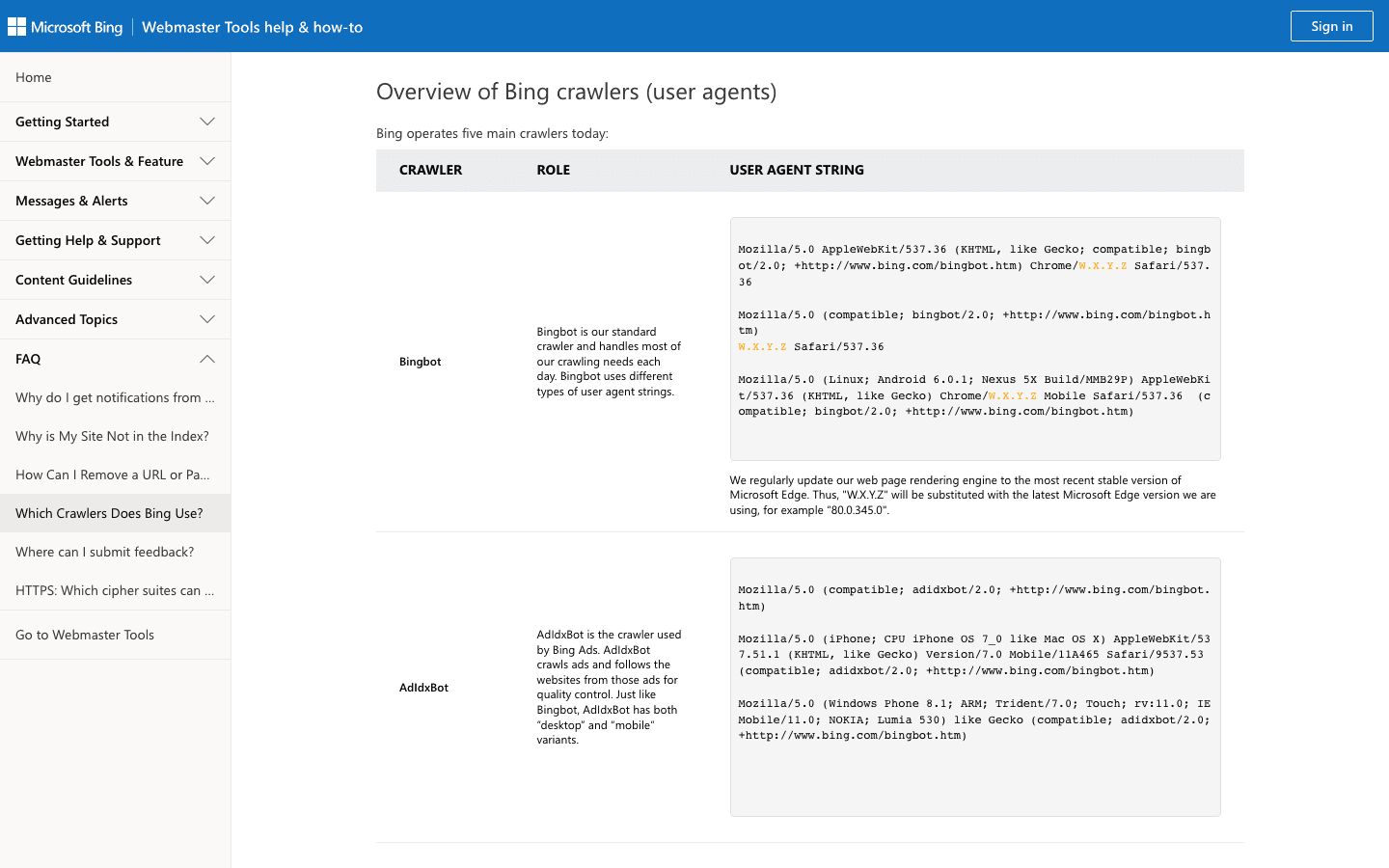
- User-Agent:
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - Verificación: Usa la y la .
- Consejos de gestión: Permite a Bingbot, gestiona la frecuencia de rastreo en Bing Webmaster Tools y usa robots.txt para ajustes finos.
4. Baiduspider: El Crawler Líder en China
es la llave para el tráfico de búsqueda chino.
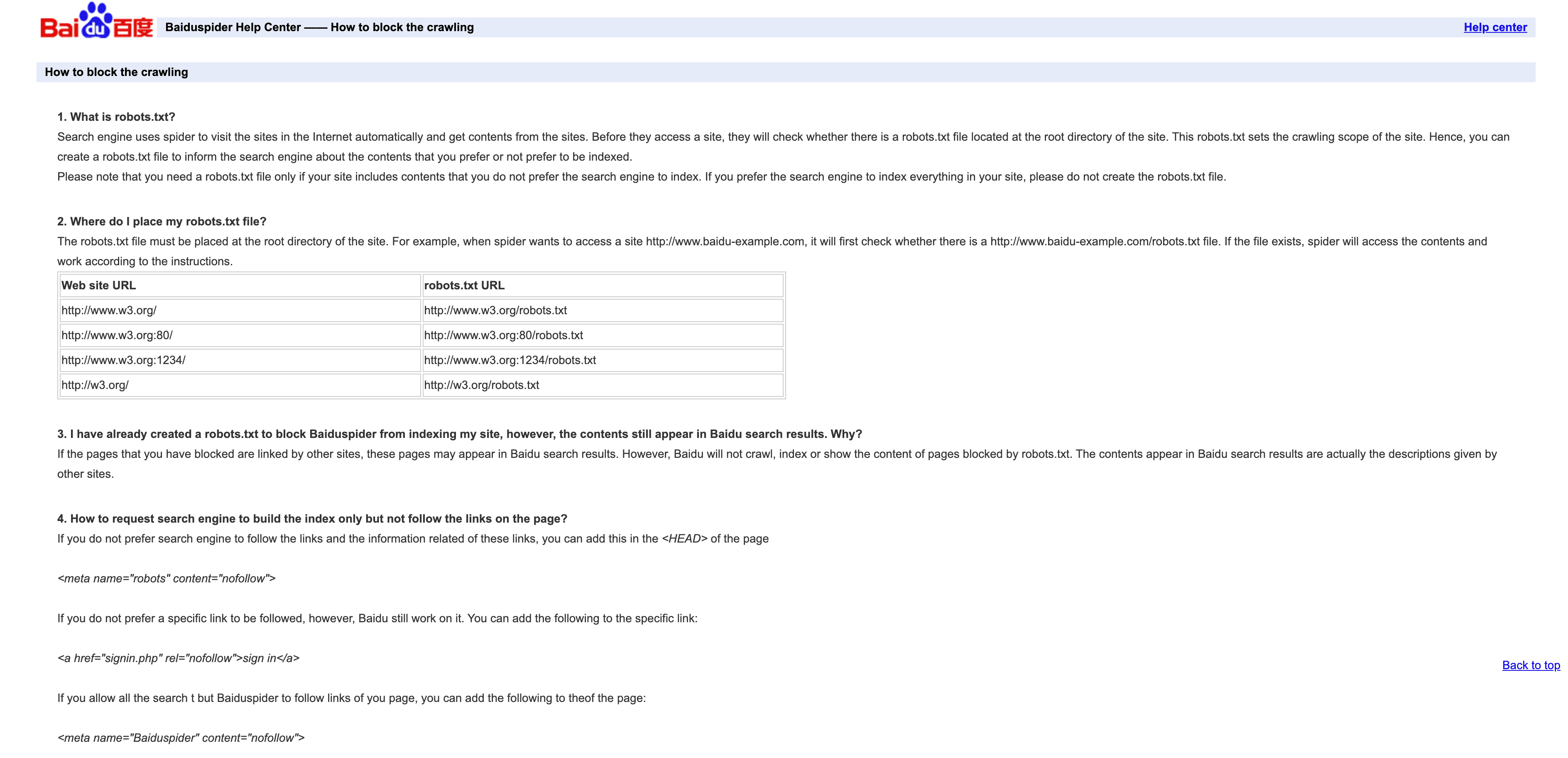
- User-Agent:
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) - Verificación: No hay lista oficial de IPs; revisa que el DNS inverso termine en
.baidu.com, aunque no es infalible. - Consejos de gestión: Permite si te interesa el tráfico de China. Usa robots.txt para definir reglas, pero ojo que Baiduspider a veces las ignora. Si no te interesa el SEO en China, considera limitarlo o bloquearlo para ahorrar ancho de banda.
5. YandexBot: El Crawler de Búsqueda de Rusia
es clave para mercados rusos y de la CEI.
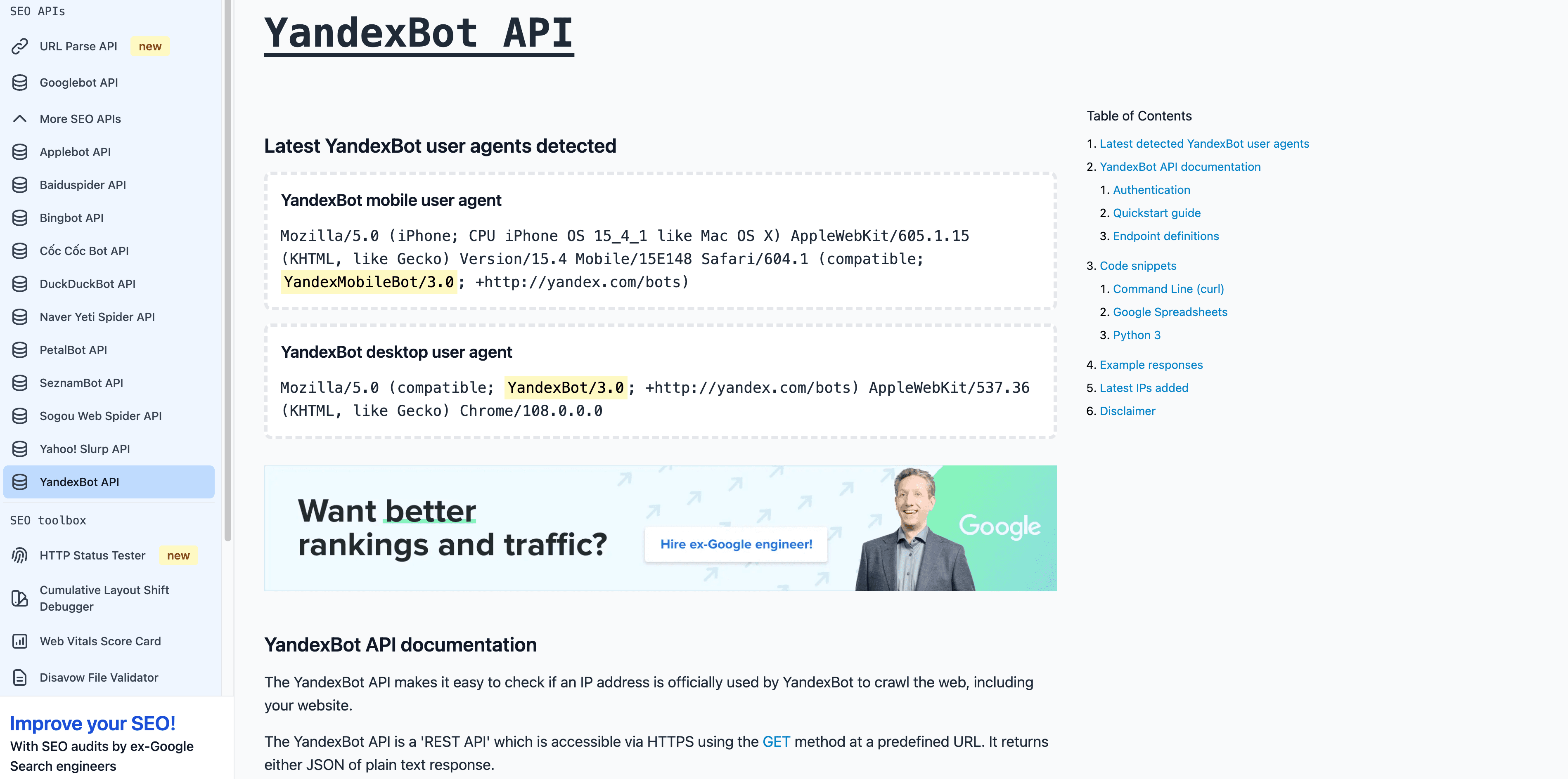
- User-Agent:
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) - Verificación: El DNS inverso debe terminar en
.yandex.ru,.yandex.neto.yandex.com. - Consejos de gestión: Permite si apuntas a usuarios de habla rusa. Usa Yandex Webmaster para controlar el rastreo.
6. DuckDuckBot: Crawler de Búsqueda Enfocado en Privacidad
es el bot detrás del buscador centrado en privacidad DuckDuckGo.
- User-Agent:
DuckDuckBot/1.1; (+http://duckduckgo.com/duckduckbot.html) - Verificación: .
- Consejos de gestión: Permite salvo que no te interese el público preocupado por la privacidad. Baja carga de rastreo, fácil de gestionar.
7. AhrefsBot: Análisis SEO y de Backlinks
es uno de los crawlers SEO más usados—ideal para análisis de enlaces, pero puede consumir mucho ancho de banda.
- User-Agent:
Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) - Verificación: Sin lista pública de IPs; verifica por user-agent y DNS inverso.
- Consejos de gestión: Permite si usas Ahrefs. Usa robots.txt para limitar o bloquear. Puedes .
8. SemrushBot: Insights SEO Competitivos
es otro crawler SEO importante.
- User-Agent:
Mozilla/5.0 (compatible; SemrushBot/1.0; +http://www.semrush.com/bot.html)(y variantes comoSemrushBot-BA,SemrushBot-SI, etc.) - Verificación: Por user-agent; sin lista pública de IPs.
- Consejos de gestión: Permite si usas Semrush, si no, limita o bloquea con robots.txt o reglas de servidor.
9. FacebookExternalHit: Bot de Previsualización en Redes Sociales
recoge datos Open Graph para las previews de enlaces en Facebook e Instagram.
- User-Agent:
facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) - Verificación: Por user-agent; las IPs son del ASN de Facebook.
- Consejos de gestión: Permite para previews sociales. Si lo bloqueas, no habrá miniaturas ni resúmenes en Facebook/Instagram.
10. Twitterbot: Crawler de Previsualización de Enlaces en X (Twitter)
recoge los datos de Twitter Card para X (Twitter).
- User-Agent:
Twitterbot/1.0 - Verificación: Por user-agent; ASN de Twitter (AS13414).
- Consejos de gestión: Permite para previews en Twitter. Usa metaetiquetas de Twitter Card para mejores resultados.
Tabla Comparativa: Lista de Crawlers de un Vistazo
| Crawler | Propósito | Ejemplo de User-Agent | Método de Verificación | Impacto en el Negocio | Consejos de Gestión |
|---|---|---|---|---|---|
| Thunderbit | Análisis de logs/crawlers con IA | N/A (herramienta, no bot) | N/A | Gestión de datos, clasificación de bots | Úsalo para extracción de logs, creación de listas blancas |
| Googlebot | Indexación en Google Search | Googlebot/2.1 | DNS & lista de IPs | Crítico para SEO | Permitir siempre, gestiona en Search Console |
| Bingbot | Búsqueda en Bing/Yahoo | bingbot/2.0 | DNS & lista de IPs | Importante para SEO en Bing/Yahoo | Permitir, gestiona en Bing Webmaster Tools |
| Baiduspider | Búsqueda en Baidu (China) | Baiduspider/2.0 | DNS inverso, user-agent | Clave para SEO en China | Permitir si apuntas a China, monitorea el ancho de banda |
| YandexBot | Búsqueda en Yandex (Rusia) | YandexBot/3.0 | DNS inverso a .yandex.ru | Clave para Rusia/E. Europa | Permitir si apuntas a RU/CIS, usa herramientas de Yandex |
| DuckDuckBot | Búsqueda en DuckDuckGo | DuckDuckBot/1.1 | Lista oficial de IPs | Audiencia preocupada por privacidad | Permitir, bajo impacto |
| AhrefsBot | Análisis SEO/backlinks | AhrefsBot/7.0 | User-agent, DNS inverso | Herramienta SEO, puede consumir ancho de banda | Permitir/limitar/bloquear vía robots.txt |
| SemrushBot | Análisis SEO/competencia | SemrushBot/1.0 (y variantes) | User-agent | Herramienta SEO, puede ser agresivo | Permitir/limitar/bloquear vía robots.txt |
| FacebookExternalHit | Vistas previas sociales | facebookexternalhit/1.1 | User-agent, ASN de Facebook | Engagement en redes sociales | Permitir para vistas previas, usa etiquetas OG |
| Twitterbot | Vistas previas en Twitter | Twitterbot/1.0 | User-agent, ASN de Twitter | Engagement en Twitter | Permitir para vistas previas, usa etiquetas Twitter Card |
Cómo Gestionar tu Lista de Crawlers: Buenas Prácticas para 2025
- Actualiza seguido: El mundo de los crawlers cambia rápido. Haz revisiones cada tres meses y usa herramientas como Thunderbit para comparar y extraer listas oficiales ().
- Verifica, no te fíes: Checa siempre user-agent y IP/ASN. No dejes que impostores distorsionen tus métricas o se lleven tus datos ().
- Deja pasar los bots buenos: Asegúrate de que los crawlers de búsqueda y redes sociales nunca sean bloqueados por reglas anti-bot o firewalls.
- Limita o bloquea bots pesados: Usa robots.txt, crawl-delay o reglas de servidor para herramientas SEO que rastrean demasiado.
- Automatiza el análisis de logs: Usa herramientas con IA (como Thunderbit) para extraer, clasificar y etiquetar la actividad de crawlers—ahorrando tiempo y detectando tendencias que podrías pasar por alto.
- Equilibra SEO, analítica y seguridad: No bloquees los bots que ayudan a tu negocio, pero tampoco dejes que los malos hagan lo que quieran.
Conclusión: Mantén tu Lista de Crawlers Actualizada y Útil
En 2025, gestionar tu lista de crawlers ya no es solo cosa de técnicos—es clave para el SEO, la analítica, la seguridad y el cumplimiento de normas. Con los bots dominando el tráfico web, necesitas saber quién te visita, por qué y cómo actuar. Mantén tu lista al día, automatiza lo que puedas y apóyate en herramientas como para ir siempre un paso adelante. La web solo se va a poner más movida—y una buena estrategia de gestión de crawlers es tu mejor defensa (y ataque) en este mundo lleno de bots.
Preguntas Frecuentes
1. ¿Por qué es importante mantener una lista actualizada de crawlers?
Porque los bots ya son más de la mitad del tráfico web, y solo unos pocos son útiles. Mantener tu lista al día te permite dejar pasar los bots buenos (para SEO y previews sociales) y bloquear o limitar los dañinos, cuidando tus métricas, ancho de banda y seguridad de datos.
2. ¿Cómo sé si un crawler es real o falso?
No te fíes solo del user-agent—verifica siempre la IP o ASN usando listas oficiales o búsquedas DNS inversas. Herramientas como Thunderbit pueden automatizar esto comparando logs con IPs y user-agents publicados.
3. ¿Qué hago si un bot desconocido rastrea mi web?
Investiga el user-agent y la IP. Si no está en tu lista blanca ni coincide con un bot reconocido, considera limitar, desafiar o bloquear su acceso. Usa IA para clasificar y monitorear nuevos crawlers a medida que aparecen.
4. ¿Cómo ayuda Thunderbit en la gestión de crawlers?
Thunderbit usa IA para extraer, estructurar y clasificar la actividad de crawlers en los logs, facilitando la creación de listas blancas, la detección de impostores y la automatización de políticas. Su preprocesamiento semántico es especialmente útil para webs complejas o dinámicas.
5. ¿Qué pasa si bloqueo un crawler importante como Googlebot o Bingbot?
Bloquear crawlers de motores de búsqueda puede sacar tu web de los resultados, acabando con tu tráfico orgánico. Revisa siempre tu firewall, robots.txt y reglas anti-bot para no bloquear por error los bots más importantes.
Más información: