La web avanza tan rápido que hasta mi café de la mañana se queda corto—y eso que me lo tomo volando. Para 2026, la extracción de datos web ya no es solo cosa de frikis de la tecnología; es el as bajo la manga para ventas, monitoreo de precios en ecommerce, estudios de mercado y hasta análisis inmobiliario. Con , elegir la biblioteca o herramienta correcta puede ser la diferencia entre perder horas en tareas repetitivas o tener una hoja de cálculo lista para usar—todo antes de que tu competencia termine de comer.
Y aquí viene lo bueno: en 2026, las bibliotecas de raspado web son de todos los colores, desde extensiones de Chrome con IA y sin código hasta frameworks avanzados para programadores. Seas un comercial que solo quiere leads en Excel, alguien de operaciones con 500 productos a cuestas, o un crack de Python armando tu propio crawler, hay una opción hecha a tu medida. Después de años en el mundo SaaS y la automatización (y más noches sin dormir de las que me gustaría admitir) probando estas bibliotecas, te traigo el top 10 de bibliotecas de raspado web que tienes que conocer este año, y cómo elegir la que te va a hacer la vida más fácil.
¿Qué hace que una biblioteca de raspado web sea top en 2026?
Antes de meternos en la lista, hablemos de lo que realmente importa al elegir una biblioteca de raspado web. Por experiencia, las mejores herramientas en 2026 tienen esto en común:
- Facilidad de uso: ¿Puede alguien sin idea de programación sacar resultados en minutos? ¿O necesitas ser un gurú de Python?
- Gestión de contenido dinámico: ¿Aguanta páginas modernas llenas de JavaScript? ¿O se queda corta con algo más complicado que HTML plano?
- Compatibilidad de lenguajes y plataformas: ¿Funciona en tu lenguaje favorito—Python, JavaScript, Java—o incluso directo en el navegador?
- Escalabilidad: ¿Aguanta cientos o miles de páginas sin despeinarse?
- Integración y exportación: ¿Se conecta fácil con Excel, Google Sheets, Notion o tu pipeline de datos?
- IA y automatización: En 2026, las herramientas con IA que entienden instrucciones en lenguaje natural son un golazo—sobre todo para equipos de negocio que no quieren programar.
La realidad es que los equipos de negocio buscan velocidad, precisión y cero complicaciones. Cuanto menos tiempo pierdas arreglando raspadores rotos o peleando con código, más rápido aprovechas los datos. Y con la IA y la automatización en el navegador, hasta los que no son técnicos pueden extraer información que antes solo un desarrollador podía sacar ().
Vamos a lo que importa.
Las 10 bibliotecas de raspado web más potentes para 2026
- para raspado web sin código y con IA desde el navegador
- para analizar HTML y limpiar datos fácil en Python
- para crawling a gran escala y pipelines potentes
- para automatizar navegadores y extraer datos de sitios dinámicos con JavaScript
- para análisis ultrarrápido de XML/HTML en Python
- para seleccionar HTML al estilo jQuery en Python
- para HTTP, análisis de HTML y renderizado de JS en Python
- para automatizar formularios y tareas sencillas de navegador en Python
- para automatización de Chrome sin interfaz en Node.js
- para análisis robusto de HTML en Java
1. Thunderbit
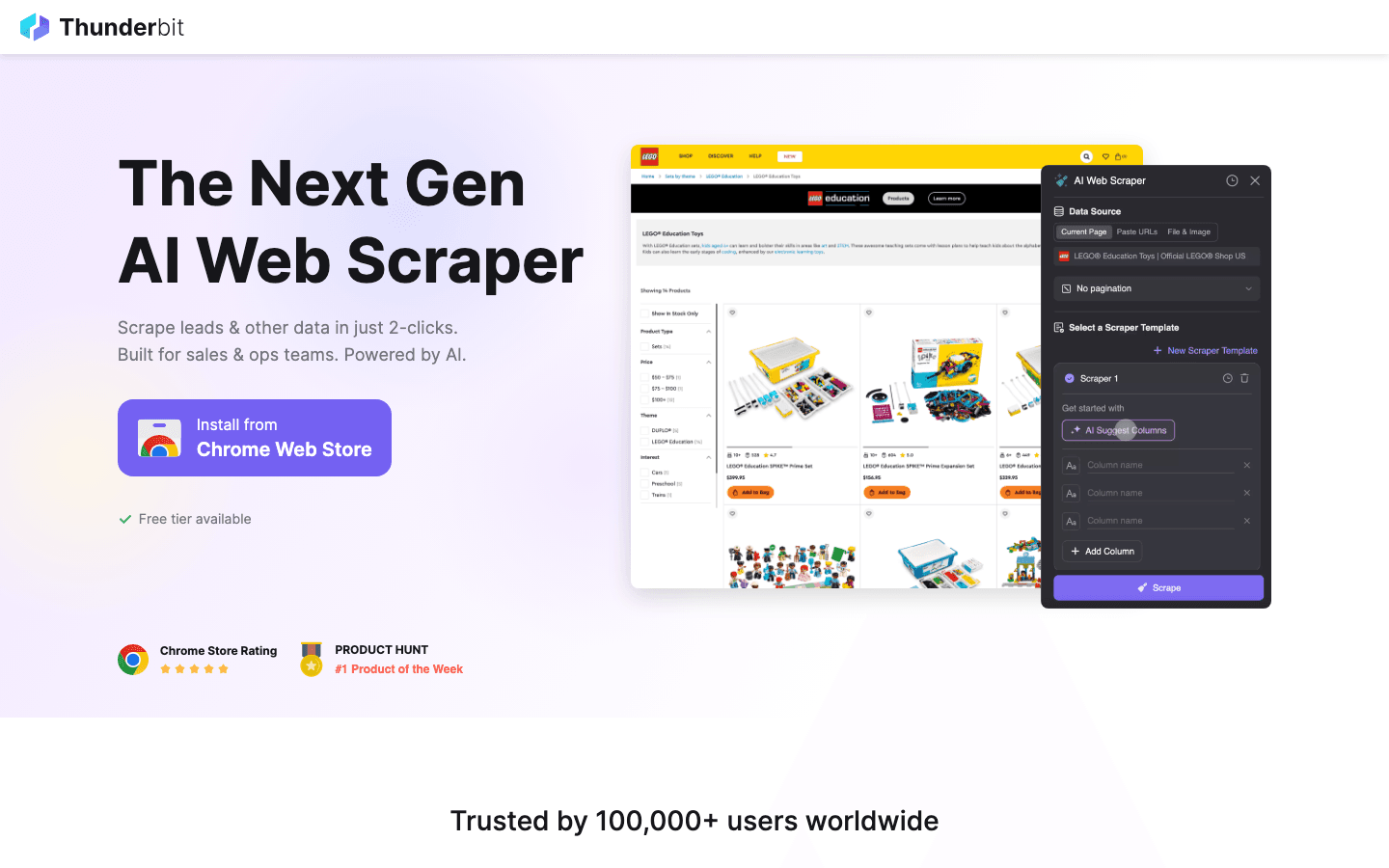
es mi primera recomendación para quienes quieren extraer datos web sin escribir ni una línea de código. Esta te deja describir lo que necesitas (“Consigue todos los nombres de productos, precios e imágenes de esta página”) y la IA hace el resto. Sin plantillas, sin líos—solo haz clic en “Sugerir campos con IA”, ajusta si hace falta y dale a “Extraer”.
Por qué Thunderbit es la estrella en 2026:
- Interfaz sin código y en lenguaje natural: Cualquiera puede usarlo—ventas, operaciones, marketing, inmobiliaria. No hace falta saber Python.
- Sugerencia de campos con IA: La IA analiza la página y te recomienda las mejores columnas para extraer.
- Raspado de subpáginas: ¿Quieres más detalles? Thunderbit puede visitar cada subpágina (como fichas de producto o perfiles) y enriquecer tu tabla automáticamente ().
- Plantillas instantáneas para sitios populares: Amazon, Zillow, Shopify y más—extrae datos con un solo clic.
- Exporta a Excel, Google Sheets, Notion, Airtable: Tus datos llegan directo donde los necesita tu equipo.
- Soporta 34 idiomas: Perfecto para equipos internacionales.
- Raspado en la nube o en el navegador: Elige lo que más te convenga—la nube es rapidísima para sitios públicos, el modo navegador va genial para logins.
Thunderbit ya lo usan más de 30,000 personas en todo el mundo, y el plan gratis te deja extraer hasta 6 páginas (o 10 si usas el impulso de prueba). Si quieres ver cómo es el raspado web moderno, aquí tienes que empezar.
2. Beautiful Soup

es una biblioteca clásica de Python que adoran los científicos de datos y analistas por su sencillez y potencia para analizar HTML desordenado. Si alguna vez intentaste extraer datos de una página con etiquetas rotas o formato raro, Beautiful Soup es tu mejor amiga.
Por qué Beautiful Soup mola:
- Maneja HTML feo: Perfecta para limpiar y extraer datos de páginas web “complicadas” ().
- Fácil de aprender: Incluso si eres nuevo en Python, puedes empezar rápido.
- Flexible: Va genial con clientes HTTP como Requests y se puede combinar con lxml para más velocidad.
- Usos típicos: Extracción rápida de datos, limpieza de información web, scripts pequeños.
Si trabajas con páginas estáticas o HTML complicado, Beautiful Soup es una apuesta segura.
3. Scrapy

es el gigante del raspado web en Python. Es un framework completo para crear crawlers escalables y pipelines de datos. Si necesitas extraer miles de páginas, seguir enlaces y procesar datos a lo grande, Scrapy es tu herramienta.
Por qué Scrapy es de lo mejor:
- Muy modular: Crea spiders complejos, pipelines y middlewares ().
- Ideal para proyectos grandes: Perfecto para estudios de mercado, análisis de competencia o cualquier tarea de crawling masivo.
- Asíncrono y rápido: Hecho para velocidad y eficiencia.
- Comunidad enorme: Muchos plugins, tutoriales y soporte.
Scrapy tiene su curva de aprendizaje, pero para trabajos grandes, es una bestia.
4. Selenium

es la referencia para automatizar navegadores. Se usa tanto para pruebas de apps web como para extraer datos de sitios que piden login, clics o gestionan pop-ups. Si necesitas interactuar con sitios llenos de JavaScript o muy dinámicos, Selenium puede simular el comportamiento de un usuario real ().
Puntos fuertes de Selenium:
- Automatiza navegadores reales: Chrome, Firefox, Safari, Edge, etc.
- Gestiona logins, pop-ups y acciones de usuario: Ideal para extraer datos tras autenticación o flujos de varios pasos.
- Soporte multilenguaje: Python, Java, C#, y más.
- Perfecto para: Sitios que bloquean raspadores simples o cuando necesitas simular a un usuario real.
Es más pesado que las bibliotecas basadas en HTTP, pero a veces, necesitas un navegador real.
5. lxml
es un analizador de XML y HTML rapidísimo para Python. Si la velocidad es lo tuyo (por ejemplo, analizar miles de documentos grandes), lxml es difícil de superar ().
Por qué lxml es favorita:
- Velocidad brutal: Supera a la mayoría de los analizadores de Python, sobre todo con archivos grandes.
- Robusta: Maneja tanto XML como HTML, e integra bien con otras herramientas.
- Ideal para: Procesar grandes volúmenes de datos, combinar con Beautiful Soup o Scrapy para más potencia.
Si necesitas extraer datos a lo grande o procesar archivos enormes, lxml es clave.
6. PyQuery
lleva la magia de los selectores de jQuery a Python. Si te mola lo fácil que es seleccionar elementos con $('.class') en jQuery, PyQuery te deja hacer lo mismo en tus scripts de raspado ().
Lo mejor de PyQuery:
- Selectores tipo jQuery: Intuitivo para quienes vienen del desarrollo web.
- Código limpio y corto: Hace fáciles las selecciones complejas.
- Se integra con lxml: Rápido y eficiente por detrás.
- Ideal para: Proyectos donde quieres manipular HTML rápido y fácil en Python.
Es un gran puente para quienes pasan del desarrollo web a la extracción de datos.
7. Requests-HTML
es una biblioteca de Python que junta la facilidad de Requests (para HTTP) con análisis de HTML y renderizado de JavaScript en un solo paquete.
Por qué Requests-HTML destaca:
- Todo en uno: Descarga páginas, analiza HTML y hasta renderiza JavaScript en un solo paquete.
- Fácil para principiantes: Perfecta para proyectos de raspado pequeños o medianos.
- Ideal para: Scripts rápidos, sitios con algo de contenido dinámico y usuarios que buscan simplicidad.
Si estás empezando o necesitas una herramienta flexible para trabajos pequeños, Requests-HTML es una gran opción.
8. MechanicalSoup

es una biblioteca de Python que automatiza formularios web y tareas sencillas de navegador. Está construida sobre Beautiful Soup y Requests, lo que facilita iniciar sesión, rellenar formularios y navegar flujos básicos ().
Por qué MechanicalSoup es útil:
- Automatiza formularios e inicios de sesión: Ideal para extraer datos tras autenticación.
- API sencilla: Fácil de aprender para principiantes.
- Ideal para: Tareas repetitivas de navegador, flujos simples y sitios donde Selenium sería demasiado.
No es tan potente como Selenium para sitios complejos, pero es mucho más ligera y fácil para necesidades básicas.
9. Puppeteer
es una biblioteca de Node.js para controlar Chrome o Chromium sin interfaz gráfica. Es la favorita para extraer datos de sitios interactivos y llenos de JavaScript ().
Superpoderes de Puppeteer:
- Automatización total del navegador: Haz clic, desplázate, rellena formularios e interactúa como un usuario real.
- Gestiona contenido dinámico: Perfecto para sitios que cargan datos vía JavaScript.
- Ideal para: Ecommerce, redes sociales o cualquier sitio donde los raspadores tradicionales fallan.
Si eres desarrollador JavaScript o necesitas extraer datos de la “web moderna”, Puppeteer es imprescindible.
10. Jsoup
es el estándar de oro para analizar HTML en Java. Es como Beautiful Soup, pero para desarrolladores Java ().
Por qué los equipos Java adoran Jsoup:
- API simple y potente: Extrae y manipula datos con pocas líneas de código.
- Maneja HTML desordenado: Limpia y analiza incluso páginas mal formateadas.
- Ideal para: Integrar el raspado en aplicaciones empresariales Java o flujos backend.
Si tu stack es Java, Jsoup es la opción obvia.
Tabla comparativa de bibliotecas de raspado web
Aquí tienes una comparación rápida de las 10 bibliotecas:
| Biblioteca | Lenguaje | Facilidad de uso | Contenido dinámico | IA/Sin código | Casos de uso típicos | Ideal para |
|---|---|---|---|---|---|---|
| Thunderbit | Ext. Chrome | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Sí | Ventas, operaciones, investigación, inmobiliaria | Usuarios sin código, equipos de negocio |
| Beautiful Soup | Python | ⭐⭐⭐⭐ | ⭐ | No | Análisis HTML, limpieza de datos | Principiantes en Python, analistas |
| Scrapy | Python | ⭐⭐⭐ | ⭐⭐ | No | Crawling a gran escala, pipelines | Desarrolladores, proyectos big data |
| Selenium | Multi | ⭐⭐ | ⭐⭐⭐⭐⭐ | No | Automatización de navegador, logins | QA, scraping de sitios dinámicos |
| lxml | Python | ⭐⭐⭐ | ⭐ | No | Análisis rápido, archivos grandes | Usuarios avanzados, grandes volúmenes |
| PyQuery | Python | ⭐⭐⭐⭐ | ⭐ | No | Selección estilo jQuery | Desarrolladores web, scripts concisos |
| Requests-HTML | Python | ⭐⭐⭐⭐ | ⭐⭐ | No | Scripts rápidos, renderizado JS | Principiantes, proyectos pequeños |
| MechanicalSoup | Python | ⭐⭐⭐⭐ | ⭐⭐ | No | Automatización de formularios, logins | Tareas sencillas de navegador |
| Puppeteer | Node.js | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | No | Sitios con mucho JS, automatización | Devs JS, scraping web dinámico |
| Jsoup | Java | ⭐⭐⭐⭐ | ⭐ | No | Análisis HTML en Java | Equipos Java, flujos backend |
¿Cómo elegir la biblioteca de raspado web ideal para tu negocio?
Entonces, ¿cuál deberías usar? Aquí va mi consejo, después de años de prueba y error (y muchas noches de depuración):
- Usuarios sin conocimientos técnicos o equipos de negocio: Empieza con Thunderbit. Su enfoque sin código e IA te da resultados en minutos, no días. Si tu equipo solo quiere datos en Excel o Sheets, no te compliques.
- Desarrolladores Python: Beautiful Soup y Requests-HTML son perfectos para tareas pequeñas. Scrapy es tu aliado para proyectos grandes. Combínalos con lxml o PyQuery para más potencia.
- ¿Necesitas gestionar logins o contenido dinámico? Selenium (multilenguaje) o Puppeteer (Node.js) son tus mejores aliados.
- Equipos Java: Jsoup es la mejor alternativa para integrar el raspado en aplicaciones Java.
- ¿Automatizar formularios o flujos simples? MechanicalSoup es ligero y fácil de usar.
Factores clave a tener en cuenta:
- Nivel técnico: Herramientas sin código como Thunderbit son perfectas para equipos no técnicos. Los desarrolladores pueden preferir la flexibilidad de las bibliotecas de código.
- Complejidad de los datos: Para páginas simples y estáticas, Beautiful Soup o Jsoup van de lujo. Para sitios dinámicos y con mucho JavaScript, elige Selenium o Puppeteer.
- Escalabilidad: Scrapy y lxml brillan en trabajos de gran volumen y alta velocidad.
- Integración: La exportación directa de Thunderbit a Sheets, Notion y Airtable ahorra mucho tiempo en flujos de negocio.
Para más consejos sobre cómo elegir la herramienta adecuada, échale un ojo a la .
Conclusión: Saca el máximo partido a los datos web con las herramientas adecuadas
El raspado web en 2026 ya no es solo para programadores o científicos de datos. Con la llegada de herramientas sin código y potenciadas por IA, cualquier equipo—desde ventas hasta investigación—puede acceder al tesoro de datos de la web. La herramienta adecuada puede ahorrarte cientos de horas al año (), mejorar tu precisión y dar a tu negocio una ventaja real.
¿Mi consejo? Empieza por tus necesidades—velocidad, escala, nivel técnico—y prueba varias opciones. es una excelente forma de iniciarte, y las bibliotecas open source como Beautiful Soup o Scrapy siempre están ahí si quieres profundizar.
¿Quieres aprender más? Pásate por el para más guías, o suscríbete a nuestro para tutoriales prácticos.
¡Feliz raspado! Que tus datos siempre sean limpios, ordenados y listos para usar.
Preguntas frecuentes
1. ¿Cuál es la biblioteca de raspado web más fácil para usuarios sin conocimientos técnicos en 2026?
es la mejor opción para quienes no programan. Su extensión de Chrome con IA permite extraer datos usando instrucciones en lenguaje natural—sin necesidad de código.
2. ¿Qué biblioteca es mejor para extraer datos de sitios dinámicos o con mucho JavaScript?
(Node.js) y (multilenguaje) son ideales para sitios dinámicos y renderizados con JavaScript. Automatizan navegadores reales y gestionan interacciones complejas.
3. ¿Cuál es la diferencia entre Beautiful Soup y Scrapy?
es ideal para analizar y extraer datos de páginas individuales o proyectos pequeños, especialmente con HTML desordenado. es un framework completo para crear crawlers escalables y procesar grandes volúmenes de datos.
4. ¿Puedo exportar los datos extraídos directamente a Google Sheets o Notion?
Sí— permite exportar directamente a Google Sheets, Notion, Airtable y Excel. La mayoría de las bibliotecas de código requieren que programes la exportación por tu cuenta.
5. ¿Cómo elijo la biblioteca de raspado web adecuada para mi empresa?
Considera tus habilidades técnicas, la complejidad de los sitios que quieres extraer, el volumen de datos y las necesidades de integración. Las herramientas sin código como Thunderbit son ideales para equipos de negocio, mientras que los desarrolladores pueden preferir Scrapy, Beautiful Soup o Puppeteer para mayor control.
Más información