La web está llena de datos valiosos, pero la mayoría no está pensada para que los descargues fácilmente. En 2025, el raspado web se ha convertido en una herramienta clave para equipos que siguen precios, ofertas de empleo, inmuebles o a la competencia. ¿El detalle? Github está repleto de proyectos de raspado web: algunos súper pulidos, otros un dolor de cabeza, y muchos que llevan años sin recibir ni un solo update. Entonces, ¿cómo eliges el mejor, sobre todo si no eres programador?
En esta guía te traigo los 15 proyectos de raspado web más top en Github para 2025. Pero no es solo una lista: los analizo según lo fácil que es instalarlos, para qué sirven, si soportan webs dinámicas, si siguen activos, cómo exportan los datos y para quién están realmente pensados. Y si ya te cansaste de pelearte con el código, te cuento por qué herramientas sin código y con IA como están cambiando el juego para usuarios de negocio y gente sin perfil técnico.
¿Cómo elegimos los 15 mejores proyectos de Raspado Web en Github?
Vamos al grano: no todos los proyectos de Github valen lo mismo. Algunos los usan miles de personas, otros son experimentos de fin de semana que nunca salieron del cajón. Para esta selección, me fijé en proyectos que cumplen con estos puntos:
- Estrellas y Comunidad en Github: Proyectos con buena cantidad de estrellas (desde unos miles hasta más de 90k) y colaboradores activos.
- Actividad Reciente: Herramientas que siguen recibiendo actualizaciones en 2025, nada de fósiles digitales.
- Documentación y Facilidad de Uso: Documentos claros, ejemplos de código y curva de aprendizaje razonable.
- Uso en la Vida Real: Que se usen en empresas o investigaciones, no solo para demos de “hola mundo”.
Y como el raspado web no es igual para todos, comparo cada proyecto según:
- Dificultad de Instalación y Configuración: ¿Puedes empezar en minutos o te vas a pelear con drivers y dependencias?
- Para qué Sirve Mejor: ¿Está pensado para e-commerce, noticias, investigación u otro sector?
- Soporte para Páginas Dinámicas: ¿Puede con webs modernas llenas de JavaScript?
- Estado del Proyecto: ¿Sigue vivo o su último commit es de hace años?
- Opciones de Exportación de Datos: ¿Te da datos listos para usar o solo HTML crudo?
- Perfil de Usuario: ¿Es para principiantes en Python, ingenieros de datos o equipos no técnicos?
Cada proyecto lleva etiquetas rápidas para estos criterios, así puedes ver de un vistazo cuál te conviene más, seas un crack del código o solo quieras tus datos en Google Sheets.

Instalación y Configuración: ¿Qué tan fácil es empezar a raspar?
Seamos sinceros: el mayor obstáculo para la mayoría es simplemente lograr que un raspador funcione. Así clasifico la dificultad de instalación:
- Plug & Play (Sin Configuración): Instala y listo. Casi sin configurar, ideal si eres nuevo en esto.
- Moderado (Línea de Comandos, Algo de Código): Hay que programar un poco o usar la terminal, pero si ya has hecho scripts antes, no te asustará.
- Avanzado (Drivers, Anti-bots, Código Profundo): Necesita configurar el entorno, drivers de navegador o saber bastante de Python/JS.
Así se reparten los proyectos más conocidos:
- Plug & Play: MechanicalSoup (Python), Nokogiri (Ruby), Maxun (para usuarios finales, una vez desplegado)
- Moderado: Scrapy, Crawlee, Node Crawler, Selenium, Playwright, Colly, Puppeteer, Katana, Scrapling, WebMagic
- Avanzado: Heritrix, Apache Nutch (ambos requieren Java, archivos de configuración o stacks de big data)
Si no eres desarrollador, las opciones "Plug & Play" o sin código son tus mejores amigas. Para el resto, "Moderado" significa que tendrás que escribir algo de código, pero nada del otro mundo—salvo que odies las llaves.
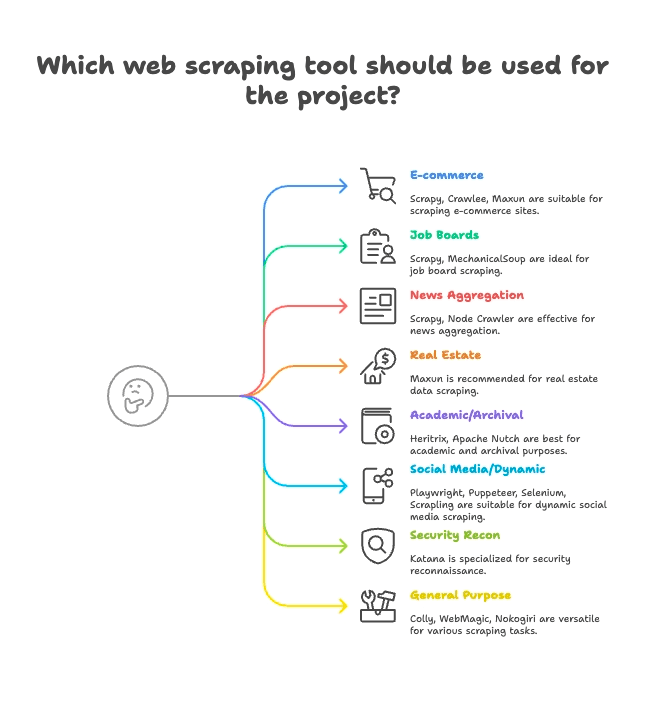
Agrupación por Caso de Uso: Encuentra el raspador perfecto para tu sector
No todos los raspadores sirven para lo mismo. Así agrupo los 15 principales según para qué brillan:
E-commerce y Monitoreo de Precios
- Scrapy: Raspado de productos a gran escala y en varias páginas
- Crawlee: Muy versátil, sirve para tiendas online estáticas y dinámicas
- Maxun: Sin código, ideal para sacar listas de productos rápido
Portales de Empleo y Reclutamiento
- Scrapy: Perfecto para paginación y listados estructurados
- MechanicalSoup: Va bien con portales de empleo que piden login
Noticias y Agregadores de Contenido
- Scrapy: Pensado para rastrear sitios de noticias a gran escala
- Node Crawler: Rápido para juntar noticias de sitios estáticos
Inmobiliarias
- Thunderbit: Raspado de subpáginas con IA para listados y detalles
- Maxun: Selección visual para datos de propiedades
Investigación Académica y Archivado Web
- Heritrix: Archivado completo de sitios (archivos WARC)
- Apache Nutch: Rastreo distribuido para datasets de investigación
Redes Sociales y Contenido Dinámico
- Playwright, Puppeteer, Selenium: Raspado de feeds dinámicos, simula logins
- Scrapling: Raspado sigiloso para sitios con defensas anti-bot
Seguridad y Reconocimiento
- Katana: Descubrimiento rápido de URLs, rastreo para seguridad
Propósito General / Multipropósito
- Colly: Raspado de alto rendimiento en Go para cualquier web
- WebMagic: Basado en Java, flexible para muchos tipos de sitios
- Nokogiri: Parsing en Ruby para scripts a medida
Soporte para Páginas Dinámicas: ¿Estos proyectos de Github pueden con webs modernas?
Las webs de hoy aman el JavaScript. React, Vue, scroll infinito, AJAX... Si alguna vez intentaste raspar una página y te salió un gran “nada”, sabes de lo que hablo.
Así se maneja el contenido dinámico en cada proyecto:
- Soporte Completo para JS (Navegador Headless):
- Selenium: Controla navegadores reales, ejecuta todo el JS
- Playwright: Multi-navegador, multi-lenguaje, soporte robusto para JS
- Puppeteer: Chrome/Firefox sin interfaz, renderiza JS completo
- Crawlee: Cambia entre HTTP y navegador (usando Puppeteer/Playwright)
- Katana: Modo headless opcional para JS
- Scrapling: Integra Playwright para scraping sigiloso de JS
- Maxun: Usa navegador en segundo plano para contenido dinámico
- Sin Soporte Nativo para JS (Solo HTML Estático):
- Scrapy: Necesita plugin Selenium/Playwright para JS
- MechanicalSoup, Node Crawler, Colly, WebMagic, Nokogiri, Heritrix, Apache Nutch: Solo sacan HTML, no pueden con JS de fábrica
La IA de Thunderbit es un puntazo aquí: detecta y raspa automáticamente contenido dinámico—sin que tengas que configurar nada, sin plugins, sin dolores de cabeza con selectores. Solo haz clic en “AI Suggest Fields” y deja que la IA haga el trabajo, incluso en webs hechas con React. Si quieres saber más, échale un ojo a .
Salud y Fiabilidad del Proyecto: ¿Seguirá funcionando este raspador el año que viene?
No hay nada peor que montar tu flujo de trabajo en una herramienta y descubrir que la han dejado tirada. Así están los proyectos más conocidos:
- Mantenidos Activamente (Actualizaciones Frecuentes):
- Scrapy:
- Crawlee:
- Playwright:
- Puppeteer:
- Katana:
- Colly:
- Maxun:
- Scrapling:
- Estables pero con Menos Actualizaciones:
- MechanicalSoup:
- Node Crawler:
- WebMagic:
- Nokogiri:
- Modo Mantenimiento (Especializados, Lentos):
- Heritrix:
- Apache Nutch:
Thunderbit es un servicio gestionado, así que nunca tendrás que preocuparte por código abandonado. El equipo mantiene la IA, plantillas e integraciones siempre al día—además, tienes onboarding, tutoriales y soporte si lo necesitas.
Manejo y Exportación de Datos: De HTML crudo a datos listos para usar
Sacar los datos es solo la mitad del trabajo. Necesitas que estén en un formato útil para tu equipo—CSV, Excel, Google Sheets, Airtable, Notion o incluso una API en tiempo real.
- Exportación Estructurada Integrada:
- Scrapy: Exportadores a CSV, JSON, XML
- Crawlee: Datasets y almacenamientos flexibles
- Maxun: CSV, Excel, Google Sheets, API JSON
- Thunderbit:
- Manejo Manual de Datos (Definido por el Usuario):
- MechanicalSoup, Node Crawler, Selenium, Playwright, Puppeteer, Colly, WebMagic, Nokogiri, Scrapling: Tienes que programar la exportación de datos
- Exportación Especializada:
- Heritrix: WARC (archivos de archivo web)
- Apache Nutch: Contenido crudo a almacenamiento/índice
La exportación estructurada y las integraciones de Thunderbit ahorran mucho tiempo a los usuarios de negocio. Olvídate de pelearte con CSVs o escribir código extra—solo haz clic y tus datos estarán listos para usar.
¿Para quién es cada proyecto de Raspado Web en Github?
Vamos al grano: no todas las herramientas son para todos. Aquí mis recomendaciones:
- Principiantes en Python: MechanicalSoup, Scrapling (si te animas)
- Ingenieros de Datos: Scrapy, Crawlee, Colly, WebMagic, Node Crawler
- QA y Automatización: Selenium, Playwright, Puppeteer
- Investigadores de Seguridad: Katana
- Rubyistas: Nokogiri
- Desarrolladores Java: WebMagic, Heritrix, Apache Nutch
- Usuarios No Técnicos / Equipos de Negocio: Maxun, Thunderbit
- Growth Hackers, Analistas: Maxun, Thunderbit
Si no te llevas bien con el código, o solo quieres resultados rápidos, Thunderbit y Maxun son tus mejores opciones. Para el resto, elige la herramienta que se adapte a tu lenguaje y caso de uso.
Los 15 Mejores Proyectos de Raspado Web en Github: Comparativa Detallada
Vamos a ver cada proyecto, agrupados por caso de uso, con etiquetas rápidas y lo más destacado.
E-commerce, Monitoreo de Precios y Raspado General
— 57.1k estrellas, actualización junio 2025

- Resumen: Framework asíncrono de alto nivel en Python para crawling y scraping a gran escala.
- Instalación: Moderada (programación en Python, framework async)
- Uso: E-commerce, noticias, investigación, spiders multipágina
- Soporte JS: No (requiere plugin Selenium/Playwright)
- Salud del Proyecto: Mantenido activamente
- Exportación de Datos: CSV, JSON, XML integrados
- Audiencia: Desarrolladores, ingenieros de datos
- Destacados: Escalable, robusto, muchos plugins. Curva de aprendizaje pronunciada para principiantes.
— 17.9k estrellas, 2025

- Resumen: Librería completa en Node.js para scraping estático y dinámico.
- Instalación: Moderada (programación en Node/TS)
- Uso: E-commerce, redes sociales, automatización
- Soporte JS: Sí (integración con Puppeteer/Playwright)
- Salud del Proyecto: Muy activo
- Exportación de Datos: Flexible (datasets, almacenamientos)
- Audiencia: Equipos de desarrollo en JS/TS
- Destacados: Herramientas anti-bloqueo, fácil cambio entre HTTP/navegador.
— 13k estrellas, junio 2025

- Resumen: Plataforma open-source sin código para extracción de datos web con interfaz visual.
- Instalación: Moderada (despliegue en servidor), Fácil (para usuarios finales)
- Uso: Propósito general, e-commerce, scraping de negocio
- Soporte JS: Sí (navegador en segundo plano)
- Salud del Proyecto: Activo y en crecimiento
- Exportación de Datos: CSV, Excel, Google Sheets, API JSON
- Audiencia: Usuarios no técnicos, analistas, equipos
- Destacados: Scraping por clic, navegación multinivel, autohospedable.
Portales de Empleo, Reclutamiento e Interacciones Simples
— 4.8k estrellas, 2024

- Resumen: Librería Python para automatizar formularios y navegación sencilla.
- Instalación: Plug & Play (Python, poco código)
- Uso: Portales de empleo con login, sitios estáticos
- Soporte JS: No
- Salud del Proyecto: Maduro, poco mantenimiento
- Exportación de Datos: Ninguna integrada (manual)
- Audiencia: Principiantes en Python, scripts rápidos
- Destacados: Simula sesiones de navegador en pocas líneas. No apto para sitios dinámicos.
Agregadores de Noticias y Contenido Estático
— 6.8k estrellas, 2024

- Resumen: Crawler rápido y concurrente del lado servidor con parsing Cheerio.
- Instalación: Moderada (callbacks/async en Node)
- Uso: Noticias, scraping estático de alta velocidad
- Soporte JS: No (solo HTML)
- Salud del Proyecto: Actividad moderada (v2 beta)
- Exportación de Datos: Ninguna integrada (definida por el usuario)
- Audiencia: Desarrolladores Node.js, necesidades de alta concurrencia
- Destacados: Crawling asíncrono, limitación de tasa, API tipo jQuery.
Inmobiliarias, Listados y Raspado de Subpáginas

- Resumen: Raspador web sin código, potenciado por IA, para usuarios de negocio.
- Instalación: Plug & Play (extensión Chrome, configuración en 2 clics)
- Uso: Inmobiliarias, e-commerce, ventas, marketing, cualquier web
- Soporte JS: Sí (la IA detecta contenido dinámico automáticamente)
- Salud del Proyecto: Actualizaciones continuas, servicio gestionado
- Exportación de Datos: Un clic a Sheets, Airtable, Notion, CSV, JSON
- Audiencia: Usuarios no técnicos, equipos de negocio, ventas, marketing
- Destacados: “AI Suggest Fields”, raspado de subpáginas, exportación instantánea, onboarding, plantillas, .
Investigación Académica y Archivado Web
— 3k estrellas, 2023

- Resumen: Crawler de archivado web a escala de Internet Archive.
- Instalación: Avanzada (aplicación Java, archivos de configuración)
- Uso: Archivado web, rastreos de dominios completos
- Soporte JS: No (solo fetch)
- Salud del Proyecto: Mantenido (lento pero estable)
- Exportación de Datos: WARC (archivos de archivo web)
- Audiencia: Archivos, bibliotecas, instituciones
- Destacados: Escalable, robusto, cumple estándares. No apto para scraping dirigido.
— 3k estrellas, 2024

- Resumen: Crawler open-source para big data y motores de búsqueda.
- Instalación: Avanzada (Java+Hadoop para escalar)
- Uso: Rastreo para motores de búsqueda, big data
- Soporte JS: No (solo HTTP)
- Salud del Proyecto: Activo (Apache)
- Exportación de Datos: Contenido crudo a almacenamiento/índice
- Audiencia: Empresas, big data, investigación académica
- Destacados: Arquitectura de plugins, rastreo distribuido.
Redes Sociales, Contenido Dinámico y Automatización
— ~30k estrellas, 2025

- Resumen: Automatización de navegadores para scraping y testing, soporta todos los navegadores principales.
- Instalación: Moderada (drivers, multi-lenguaje)
- Uso: Sitios con mucho JS, testing de flujos, redes sociales
- Soporte JS: Sí (automatización completa de navegador)
- Salud del Proyecto: Activo, maduro
- Exportación de Datos: Ninguna (manual)
- Audiencia: Ingenieros QA, desarrolladores
- Destacados: Multi-lenguaje, simula comportamiento real de usuario.
— 73.5k estrellas, 2025

- Resumen: Automatización moderna de navegadores para scraping y pruebas E2E.
- Instalación: Moderada (scripting multi-lenguaje)
- Uso: Apps web modernas, redes sociales, automatización
- Soporte JS: Sí (headless o navegador real)
- Salud del Proyecto: Muy activo
- Exportación de Datos: Ninguna (a cargo del usuario)
- Audiencia: Desarrolladores que necesitan control robusto de navegador
- Destacados: Multi-navegador, auto-wait, interceptación de red.
— 90.9k estrellas, 2025

- Resumen: API de alto nivel para automatización de Chrome/Firefox.
- Instalación: Moderada (scripting en Node)
- Uso: Scraping headless en Chrome, contenido dinámico
- Soporte JS: Sí (Chrome/Firefox)
- Salud del Proyecto: Activo (equipo de Chrome)
- Exportación de Datos: Ninguna (personalizada en código)
- Audiencia: Desarrolladores Node.js, front-end
- Destacados: Control de navegador, capturas de pantalla, PDF, interceptación de red.
— 5.4k estrellas, junio 2025

- Resumen: Scraping sigiloso y de alto rendimiento con funciones anti-bot.
- Instalación: Moderada (código Python)
- Uso: Scraping sigiloso, anti-bloqueo, sitios dinámicos
- Soporte JS: Sí (integración Playwright)
- Salud del Proyecto: Activo, vanguardia
- Exportación de Datos: Ninguna integrada (manual)
- Audiencia: Desarrolladores Python, hackers, ingenieros de datos
- Destacados: Stealth, proxy, anti-bloqueo, async.
Reconocimiento de Seguridad
— 13.8k estrellas, 2025

- Resumen: Crawler web rápido para seguridad, automatización y descubrimiento de enlaces.
- Instalación: Moderada (CLI o librería Go)
- Uso: Rastreo de seguridad, descubrimiento de endpoints
- Soporte JS: Sí (modo headless opcional)
- Salud del Proyecto: Activo (ProjectDiscovery)
- Exportación de Datos: Salida en texto (listas de URLs)
- Audiencia: Investigadores de seguridad, desarrolladores Go
- Destacados: Velocidad, concurrencia, parsing JS headless.
Scraping Multipropósito / General
— 24.3k estrellas, 2025

- Resumen: Framework de scraping rápido y elegante para Go.
- Instalación: Moderada (código Go)
- Uso: Scraping de alto rendimiento, multipropósito
- Soporte JS: No (solo HTML)
- Salud del Proyecto: Activo, commits recientes
- Exportación de Datos: Ninguna integrada (definida por el usuario)
- Audiencia: Desarrolladores Go, enfocados en rendimiento
- Destacados: Async, limitación de tasa, scraping distribuido.
— 11.6k estrellas, 2023

- Resumen: Framework flexible de crawling en Java, estilo Scrapy.
- Instalación: Moderada (Java, API sencilla)
- Uso: Scraping general en Java
- Soporte JS: No (puede extenderse con Selenium)
- Salud del Proyecto: Comunidad activa
- Exportación de Datos: Pipelines enchufables
- Audiencia: Desarrolladores Java
- Destacados: Pool de hilos, schedulers, anti-bloqueo.
— 6.2k estrellas, 2025

- Resumen: Parser HTML/XML nativo y rápido para Ruby.
- Instalación: Plug & Play (gem de Ruby)
- Uso: Parsing HTML/XML en apps Ruby
- Soporte JS: No (solo parsing)
- Salud del Proyecto: Activo, sigue el ritmo de Ruby
- Exportación de Datos: Ninguna (usa Ruby para formatear)
- Audiencia: Rubyistas, desarrolladores Rails
- Destacados: Velocidad, cumplimiento, seguro por defecto.
Tabla Comparativa de Características
Aquí tienes una tabla rápida de comparación—incluyendo Thunderbit:
| Proyecto | Complejidad de Instalación | Caso de Uso | Soporte JS | Mantenimiento | Exportación de Datos | Audiencia | Estrellas Github |
|---|---|---|---|---|---|---|---|
| Scrapy | Moderada | E-commerce, noticias | No | Activo | CSV, JSON, XML | Devs, ingenieros de datos | 57.1k |
| Crawlee | Moderada | Versátil, automatización | Sí | Muy activo | Datasets flexibles | Equipos JS/TS | 17.9k |
| MechanicalSoup | Plug & Play | Estático, formularios | No | Maduro | Ninguna (manual) | Principiantes Python | 4.8k |
| Node Crawler | Moderada | Noticias, estático | No | Moderado | Ninguna (manual) | Devs Node.js | 6.8k |
| Selenium | Moderada | JS intensivo, testing | Sí | Activo | Ninguna (manual) | QA, devs | ~30k |
| Heritrix | Avanzada | Archivado, investigación | No | Mantenido | WARC | Archivos, instituciones | 3k |
| Apache Nutch | Avanzada | Big data, búsqueda | No | Activo | Contenido crudo | Empresas, investigación | 3k |
| WebMagic | Moderada | Java, general | No | Comunidad activa | Pipelines enchufables | Devs Java | 11.6k |
| Nokogiri | Plug & Play | Parsing Ruby | No | Activo | Ninguna (manual) | Rubyistas | 6.2k |
| Playwright | Moderada | Dinámico, automatización | Sí | Muy activo | Ninguna (manual) | Devs, QA | 73.5k |
| Katana | Moderada | Seguridad, descubrimiento | Sí | Activo | Salida texto | Seguridad, Go devs | 13.8k |
| Colly | Moderada | Alto rendimiento, general | No | Activo | Ninguna (manual) | Go devs | 24.3k |
| Puppeteer | Moderada | Dinámico, automatización | Sí | Activo | Ninguna (manual) | Devs Node.js | 90.9k |
| Maxun | Fácil (usuario) | No-code, negocio | Sí | Activo | CSV, Excel, Sheets, API | No técnicos, analistas | 13k |
| Scrapling | Moderada | Stealth, anti-bot | Sí | Activo | Ninguna (manual) | Devs Python, hackers | 5.4k |
| Thunderbit | Plug & Play | No-code, negocio | Sí | Gestionado, actualizado | Sheets, Airtable, Notion | No técnicos, negocio | N/A |
Por qué Thunderbit es la mejor opción para usuarios de negocio y sin perfil técnico
Seamos sinceros: la mayoría de proyectos open-source en Github están hechos por y para desarrolladores. Eso implica instalación, mantenimiento y resolver problemas por tu cuenta. Si eres usuario de negocio, marketing, ventas o simplemente quieres resultados—sin dolores de cabeza con regex—Thunderbit está pensado para ti.
¿Por qué Thunderbit destaca?
- Simplicidad sin código y con IA: Instala la , haz clic en “AI Suggest Fields” y empieza a raspar. Sin Python, sin selectores, sin dramas de “pip install”.
- Soporte para páginas dinámicas: La IA de Thunderbit lee y extrae datos de sitios modernos llenos de JavaScript (React, Vue, AJAX) sin configuraciones manuales.
- Raspado de subpáginas: ¿Necesitas extraer detalles de cada producto o anuncio? La IA de Thunderbit puede navegar subpáginas y unir los datos en una sola tabla—sin código personalizado.
- Exportaciones listas para negocio: Exporta con un clic a Google Sheets, Airtable, Notion, CSV o JSON. Perfecto para leads, monitoreo de precios o agregación de contenido.
- Actualizaciones y soporte continuo: Thunderbit es un servicio gestionado—sin riesgo de “abandonware”. Incluye onboarding, tutoriales y una biblioteca de plantillas en crecimiento para sitios comunes.
- Perfil de usuario: Thunderbit es para usuarios no técnicos, equipos de negocio y cualquiera que valore la rapidez y fiabilidad por encima de trastear con código.
No te lo digo solo yo—Thunderbit ya es la herramienta de confianza de más de 30,000 usuarios en todo el mundo, incluyendo equipos de Accenture, Grammarly y Puma. Y sí, también fuimos el Producto de la Semana #1 en Product Hunt.
¿Quieres ver lo fácil que puede ser el scraping? .
Conclusión: ¿Qué solución de Raspado Web elegir en 2025?
En resumen: Github es un tesoro de herramientas potentes de raspado web, pero la mayoría están pensadas para desarrolladores. Si te gusta programar, frameworks como Scrapy, Crawlee, Playwright y Colly te dan control total. Si eres de academia o seguridad, Heritrix, Nutch y Katana son tus aliados.
Pero si eres usuario de negocio, analista o simplemente quieres datos—rápidos, estructurados y listos para usar—Thunderbit es la mejor opción. Sin instalaciones, sin mantenimiento, sin código. Solo resultados.
¿Y ahora qué? Si tienes curiosidad, prueba un proyecto de Github que se adapte a tu nivel y caso de uso. O, si quieres saltarte la curva de aprendizaje y ver resultados en minutos, y empieza a raspar hoy mismo.
Y si quieres aprender más sobre raspado web, revisa más guías en el , como o .
¡Feliz scraping! Que tus datos siempre sean limpios, estructurados y listos para la acción. Y si alguna vez te atascas, recuerda: seguro hay un repo de Github para eso... o simplemente deja que la IA de Thunderbit lo haga por ti.