Mi primer proyecto de scraping fue un script de Python hecho a mano, un proxy compartido y una oración. Se rompía cada tres días.
En 2026, las APIs de scraping se ocupan de lo complicado —proxies, renderizado, CAPTCHAs, reintentos— para que tú no tengas que hacerlo. Son la base de todo, desde el seguimiento de precios hasta los pipelines de datos para entrenar IA.
Pero hay un matiz: herramientas impulsadas por IA como están dejando obsoletos muchos casos de uso de las APIs para quienes no son desarrolladores. Más sobre eso abajo.
Aquí tienes 10 APIs de scraping que he usado o evaluado: qué hace bien cada una, en qué se queda corta y cuándo quizá no necesites una API en absoluto.
¿Por qué considerar Thunderbit AI en lugar de las APIs tradicionales de Web Scraping?
Antes de entrar en la lista de APIs, hablemos del elefante en la habitación: la automatización con IA. He pasado años ayudando a equipos a automatizar tareas tediosas, y te puedo decir que hay un motivo por el que cada vez más empresas están dejando de lado las APIs complicadas y yendo directas a agentes de IA como Thunderbit.
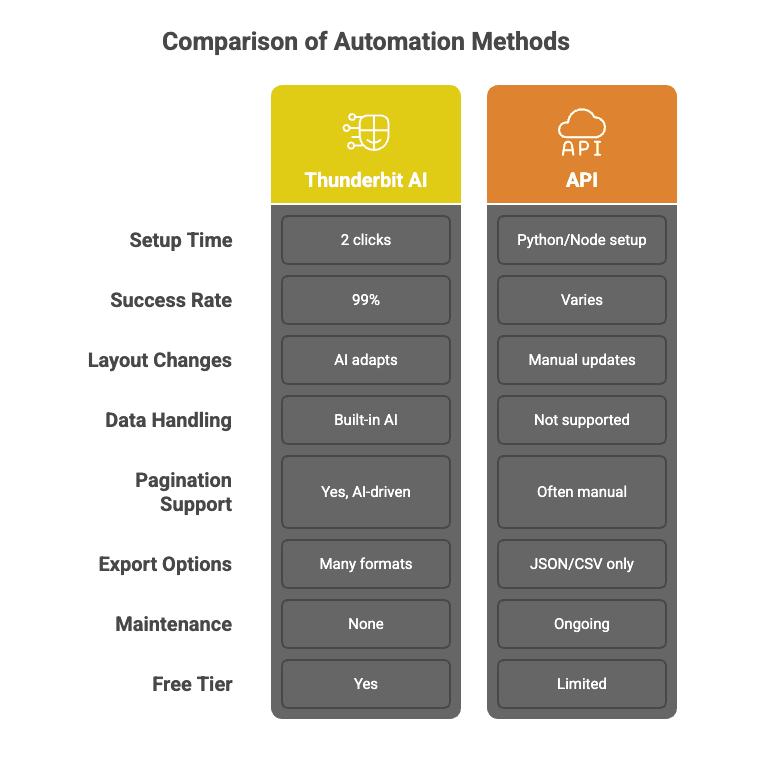
Esto es lo que diferencia a Thunderbit de las APIs tradicionales de web scraping:
-
Llamadas API en cascada para lograr un 99% de éxito
La IA de Thunderbit no se limita a llamar a una sola API y cruzar los dedos. Usa un patrón en cascada: selecciona automáticamente el mejor método de scraping para cada tarea, reintenta cuando hace falta y garantiza una tasa de éxito del 99%. Obtienes los datos, no el dolor de cabeza.
-
Configuración sin código en dos clics
Olvídate de escribir scripts en Python o de pelearte con la documentación de una API. Con Thunderbit, solo haces clic en “Sugerir campos con IA” y “Extraer”. Eso es todo. Hasta mi madre podría usarlo (y todavía cree que “la nube” es solo mal tiempo).
-
Scraping por lotes: rápido y preciso
El modelo de IA de Thunderbit puede procesar miles de sitios web distintos en paralelo, adaptándose sobre la marcha a cada diseño. Es como tener un ejército de becarios, solo que no piden pausas para el café.
-
Sin mantenimiento
Los sitios web cambian todo el tiempo. ¿Las APIs tradicionales? Se rompen. ¿Thunderbit? La IA vuelve a leer la página cada vez, así que no tienes que actualizar código cuando un sitio cambia su diseño o añade un botón nuevo.
-
Extracción de datos personalizada y posprocesamiento
¿Necesitas que tus datos se limpien, etiqueten, traduzcan o resuman? Thunderbit puede hacerlo durante la extracción: piensa en ello como lanzar 10.000 páginas web a ChatGPT y recibir un conjunto de datos perfectamente estructurado.
-
Scraping de subpáginas y paginación
La IA de Thunderbit puede seguir enlaces, gestionar la paginación e incluso enriquecer tu tabla con datos de subpáginas, todo sin código personalizado.
-
Exportación e integraciones de datos gratis
Exporta a Excel, Google Sheets, Airtable, Notion o descárgalo como CSV/JSON: sin muros de pago, sin tonterías.
Aquí tienes una comparación rápida para verlo más claro:
¿Quieres verlo en acción? Echa un vistazo a la .
¿Qué es una API de scraping de datos?
Volvamos un momento a lo básico. Una api de scraping de datos es una herramienta que te permite extraer datos de sitios web de forma programática, sin tener que construir tus propios scrapers desde cero. Piensa en ella como un robot al que puedes enviar a buscar los últimos precios, reseñas o listados, y que te devuelve los datos en un formato limpio y estructurado (normalmente JSON o CSV).
¿Cómo funciona? La mayoría de las APIs de scraping se encargan de las partes más pesadas —proxies rotativos, resolución de CAPTCHAs, renderizado de JavaScript— para que tú te concentres en lo que realmente necesitas: los datos. Envías una solicitud (normalmente con una URL y algunos parámetros), y la API devuelve el contenido listo para tu flujo de trabajo.
Ventajas principales:
- Velocidad: las APIs pueden extraer miles de páginas por minuto.
- Escalabilidad: ¿necesitas monitorizar 10.000 productos? No hay problema.
- Integración: conéctalas a tu CRM, herramienta de BI o almacén de datos con muy poco esfuerzo.
Pero, como veremos, no todas las APIs son iguales, y no todas son tan de “configura y olvídate” como prometen.
Cómo evalué estas APIs
He pasado mucho tiempo en el campo de batalla: probando, rompiendo y, a veces, haciendo sin querer un DDoS a mis propios servidores (no se lo digas a mi antiguo equipo de IT). Para esta lista, me centré en:
- Fiabilidad: ¿funciona de verdad, incluso en sitios complicados?
- Velocidad: ¿qué tan rápido puede entregar resultados a escala?
- Precio: ¿es asequible para startups y escalable para empresas?
- Escalabilidad: ¿puede manejar millones de solicitudes o se cae con 100?
- Facilidad para desarrolladores: ¿la documentación es clara? ¿hay SDKs y ejemplos de código?
- Soporte: cuando las cosas se complican (y se complicarán), ¿hay ayuda disponible?
- Opiniones de usuarios: reseñas reales, no solo marketing.
También me apoyé mucho en pruebas prácticas, análisis de reseñas y comentarios de la comunidad de Thunderbit (somos bastante exigentes).
Las 10 APIs que vale la pena considerar en 2026
¿Listo para el plato fuerte? Aquí tienes mi lista actualizada de las mejores APIs y plataformas de web scraping para usuarios de negocio y desarrolladores en 2026.
1. Oxylabs
 Resumen:
Resumen:
Oxylabs es el campeón de peso pesado para la extracción de datos web a nivel empresarial. Con un enorme pool de proxies y APIs especializadas para todo, desde SERP hasta e-commerce, es la opción preferida de las empresas Fortune 500 y de cualquiera que necesite fiabilidad a gran escala.
Funciones clave:
- Enorme red de proxies (residenciales, de centros de datos, móviles, ISP) en más de 195 países
- APIs de scraping con anti-bot, resolución de CAPTCHA y renderizado con navegador sin interfaz
- Geoobjetivo, persistencia de sesión y alta precisión de datos (tasas de éxito del 95%+)
- OxyCopilot: asistente de IA que genera automáticamente código de parsing y consultas API
Precios:
Desde unos $49/mes para una sola API, y $149/mes para acceso todo en uno. Incluye una prueba gratis de 7 días con hasta 5.000 solicitudes.
Opiniones de usuarios:
Valorado con , con elogios por su fiabilidad y soporte. ¿La principal desventaja? Es caro, pero obtienes lo que pagas.
2. ScrapingBee
 Resumen:
Resumen:
ScrapingBee es el mejor amigo del desarrollador: simple, asequible y directo. Tú envías una URL, él se encarga de Chrome sin interfaz, los proxies y los CAPTCHAs, y devuelve la página renderizada o solo los datos que necesitas.
Funciones clave:
- Renderizado con navegador sin interfaz (compatibilidad con JavaScript)
- Rotación automática de IP y resolución de CAPTCHA
- Pool de proxies furtivos para sitios difíciles
- Configuración mínima: solo una llamada a la API
Precios:
Plan gratuito con unas 1.000 llamadas al mes. Los planes de pago empiezan en unos $29/mes por 5.000 solicitudes.
Opiniones de usuarios:
Mantiene una puntuación de . A los desarrolladores les encanta su simplicidad; quienes no programan pueden encontrarlo un poco demasiado básico.
3. Apify
 Resumen:
Resumen:
Apify es la navaja suiza del web scraping. Puedes crear scrapers personalizados (“Actors”) en JavaScript o Python, o usar su enorme biblioteca de actores ya preparados para sitios populares. Es tan flexible como necesites que sea.
Funciones clave:
- Scrapers personalizados y preconstruidos (Actors) para casi cualquier sitio
- Infraestructura en la nube, programación y gestión de proxies incluidas
- Exportación de datos a JSON, CSV, Excel, Google Sheets y más
- Comunidad activa y soporte en Discord
Precios:
Plan gratis para siempre con $5/mes en créditos. Los planes de pago empiezan en $39/mes.
Opiniones de usuarios:
. A los desarrolladores les encanta la flexibilidad; los principiantes se encuentran con una curva de aprendizaje.
4. Decodo (antes Smartproxy)
 Resumen:
Resumen:
Decodo (renombrado desde Smartproxy) apuesta por el valor y la facilidad. Combina una infraestructura sólida de proxies con APIs de scraping para web general, SERP, e-commerce y redes sociales, todo bajo una sola suscripción.
Funciones clave:
- API de scraping unificada para todos los endpoints (se acabaron los complementos separados)
- Scrapers especializados para Google, Amazon, TikTok y más
- Panel de control fácil de usar con playground y generadores de código
- Soporte de chat en vivo 24/7
Precios:
Desde unos $50/mes por 25.000 solicitudes. Prueba gratuita de 7 días con 1.000 solicitudes.
Opiniones de usuarios:
Elogiado por su “relación calidad-precio” y su soporte ágil. .
5. Octoparse
 Resumen:
Resumen:
Octoparse es el campeón del no-code. Si odias el código pero amas los datos, esta app de escritorio de apuntar y hacer clic (con funciones en la nube) te permite construir scrapers visualmente y ejecutarlos en local o en la nube.
Funciones clave:
- Creador visual de flujos de trabajo: solo haz clic para seleccionar los campos de datos
- Extracción en la nube, programación y rotación automática de IP
- Plantillas para sitios populares y un marketplace para scrapers personalizados
- Octoparse AI: integra RPA y ChatGPT para limpieza de datos y automatización de flujos
Precios:
Plan gratuito para hasta 10 tareas locales. Los planes de pago empiezan en $119/mes (funciones en la nube, tareas ilimitadas). Prueba gratis de 14 días para funciones premium.
Opiniones de usuarios:
. Muy querido por quienes no programan, pero los usuarios avanzados pueden encontrarse con límites.
6. Bright Data
 Resumen:
Resumen:
Bright Data es el gran coloso: si necesitas escala, velocidad y todas las funciones posibles, esta es tu plataforma. Con la red de proxies más grande del mundo y un potente IDE de scraping, está pensada para empresas.
Funciones clave:
- Más de 150M de IPs (residenciales, móviles, ISP, centros de datos)
- Web Scraper IDE, recopiladores de datos preconstruidos y conjuntos de datos listos para comprar
- Anti-bot avanzado, resolución de CAPTCHA y compatibilidad con navegador sin interfaz
- Enfoque en cumplimiento y legalidad (iniciativa Ethical Web Data)
Precios:
Pago por uso: unos $1,05 por 1.000 solicitudes; proxies desde $3–$15/GB. Pruebas gratis para la mayoría de los productos.
Opiniones de usuarios:
Elogiado por su rendimiento y funciones, pero el precio y la complejidad pueden ser un obstáculo para equipos pequeños.
7. WebAutomation
 Resumen:
Resumen:
WebAutomation es una plataforma en la nube diseñada para quienes no desarrollan. Con un marketplace de extractores preconstruidos y un creador sin código, es perfecta para usuarios de negocio que quieren datos, no código.
Funciones clave:
- Extractores preconstruidos para sitios populares (Amazon, Zillow, etc.)
- Creador de extractores sin código con interfaz de apuntar y hacer clic
- Programación en la nube, entrega de datos y mantenimiento incluidos
- Precio basado en filas (pagas por lo que extraes)
Precios:
Plan Project a $74/mes (~400k filas/año), pago por uso a $1 por 1.000 filas. Prueba gratuita de 14 días con 10 millones de créditos.
Opiniones de usuarios:
A los usuarios les encanta la facilidad de uso y la transparencia en precios. El soporte es útil y el equipo se encarga del mantenimiento.
8. ScrapeHero
 Resumen:
Resumen:
ScrapeHero empezó como una consultora de scraping a medida y ahora ofrece una plataforma en la nube de autoservicio. Puedes usar scrapers preconstruidos para sitios populares o solicitar proyectos totalmente gestionados.
Funciones clave:
- ScrapeHero Cloud: scrapers preconstruidos para Amazon, Google Maps, LinkedIn y más
- Operación sin código, programación y entrega en la nube
- Soluciones personalizadas para necesidades únicas
- Acceso API para integración programática
Precios:
Los planes en la nube empiezan tan bajo como $5/mes. Proyectos personalizados desde $550 por sitio (pago único).
Opiniones de usuarios:
Elogiado por su fiabilidad, calidad de datos y soporte. Muy bueno para pasar de una solución DIY a una gestionada.
9. Sequentum
 Resumen:
Resumen:
Sequentum es la navaja suiza empresarial: diseñada para cumplimiento, trazabilidad y gran escala. Si necesitas certificación SOC-2, registros de auditoría y colaboración en equipo, esta es tu herramienta.
Funciones clave:
- Diseñador de agentes low-code (apuntar y hacer clic + scripting)
- Despliegue como SaaS en la nube o en local
- Gestión de proxies integrada, resolución de CAPTCHA y navegadores sin interfaz
- Registros de auditoría, acceso basado en roles y cumplimiento SOC-2
Precios:
Pago por uso ($6/hora de ejecución, $0,25/GB exportado), plan Starter a $199/mes. Crédito gratis de $5 al registrarte.
Opiniones de usuarios:
A las empresas les encantan las funciones de cumplimiento y la escalabilidad. Tiene curva de aprendizaje, pero el soporte y la formación son de primer nivel.
10. Grepsr
 Resumen:
Resumen:
Grepsr es un servicio de extracción de datos gestionado: solo dinos lo que necesitas y ellos construyen, ejecutan y mantienen los scrapers por ti. Perfecto para empresas que quieren datos sin las complicaciones técnicas.
Funciones clave:
- Extracción gestionada (“Grepsr Concierge”): ellos configuran y mantienen todo
- Panel en la nube para programar, supervisar y descargar datos
- Múltiples formatos de salida e integraciones (Dropbox, S3, Google Drive)
- Pago por registro de datos, no por solicitud
Precios:
Starter pack a $350 (extracción única); las suscripciones recurrentes se cotizan de forma personalizada.
Opiniones de usuarios:
A los clientes les encanta la experiencia sin complicaciones y el soporte ágil. Muy bueno para equipos no técnicos y para quienes valoran el tiempo por encima de trastear.
Tabla rápida comparativa: las mejores APIs de Web Scraping
Aquí tienes la chuleta de las 10 plataformas:
| Plataforma | Tipos de datos compatibles | Precio inicial | Prueba gratis | Facilidad de uso | Soporte | Funciones destacadas |
|---|---|---|---|---|---|---|
| Oxylabs | Web, SERP, e-commerce, bienes raíces | $49/mes | 7 días/5k solicitudes | Enfocada a desarrolladores | 24/7, empresarial | OxyCopilot AI, enorme pool de proxies, geoobjetivo |
| ScrapingBee | Web general, JS, CAPTCHA | $29/mes | 1k llamadas/mes | API simple | Email, foros | Chrome sin interfaz, proxies furtivos |
| Apify | Cualquier web, preconstruido/personalizado | Gratis/$39/mes | Gratis para siempre | Flexible, compleja | Comunidad, Discord | Marketplace de Actors, infraestructura en la nube, integraciones |
| Decodo | Web, SERP, e-commerce, social | $50/mes | 7 días/1k solicitudes | Fácil de usar | Chat en vivo 24/7 | API unificada, playground de código, gran valor |
| Octoparse | Cualquier web, no-code | Gratis/$119/mes | 14 días | Visual, no-code | Email, foro | Interfaz de apuntar y hacer clic, nube, Octoparse AI |
| Bright Data | Toda la web, conjuntos de datos | $1,05/1k solicitudes | Sí | Potente, compleja | 24/7, empresarial | Red de proxies más grande, IDE, conjuntos de datos listos |
| WebAutomation | Estructurados, e-commerce, bienes raíces | $74/mes | 14 días/10M filas | No-code, plantillas | Email, chat | Extractores preconstruidos, precio por fila |
| ScrapeHero | E-commerce, mapas, empleos, personalizado | $5/mes | Sí | No-code, gestionada | Email, tickets | Scrapers en la nube, proyectos a medida, entrega en Dropbox |
| Sequentum | Cualquier web, empresarial | $0/$199/mes | Crédito de $5 | Low-code, visual | Soporte cercano | Registros de auditoría, SOC-2, local/nube |
| Grepsr | Cualquier dato estructurado, gestionado | $350 único | Ejecución de muestra | Totalmente gestionada | Gestor dedicado | Configuración concierge, pago por dato, integraciones |
Elegir la herramienta de Web Scraping adecuada para tu negocio
Entonces, ¿qué herramienta deberías elegir? Así es como lo planteo para los equipos a los que asesoro:
-
Si quieres cero código, resultados inmediatos y limpieza de datos con IA:
Elige . Es la forma más rápida de pasar de “necesito datos” a “ya tengo los datos”, sin tener que estar pendiente de scripts o APIs.
-
Si eres desarrollador y te encanta el control y la flexibilidad:
Prueba Apify, ScrapingBee u Oxylabs. Te dan el máximo poder, pero tendrás que encargarte de algo de configuración y mantenimiento.
-
Si eres un usuario de negocio que quiere una herramienta visual:
WebAutomation es fantástica para el scraping de apuntar y hacer clic, especialmente para e-commerce y generación de leads.
-
Si necesitas cumplimiento, trazabilidad o funciones empresariales:
Sequentum está hecho para ti. Es más caro, pero merece la pena en sectores regulados.
-
Si solo quieres que otra persona se encargue de todo:
Grepsr o los servicios gestionados de ScrapeHero son el camino. Pagas un poco más, pero tu presión arterial lo agradecerá.
Y si todavía no lo tienes claro, la mayoría de estas plataformas ofrecen pruebas gratis, así que pruébalas.
Conclusiones clave
- Las APIs de web scraping ya son esenciales para los negocios basados en datos: se prevé que el mercado alcance .
- El scraping manual ha quedado atrás: entre la tecnología anti-bot, los proxies y los cambios en los sitios, las APIs y las herramientas de IA son la única forma de escalar.
- Cada API/plataforma tiene sus puntos fuertes:
- Oxylabs y Bright Data para escala y fiabilidad
- Apify para flexibilidad
- Decodo para valor
- WebAutomation para no-code
- Sequentum para cumplimiento
- Grepsr para datos gestionados sin complicaciones
- La automatización impulsada por IA, como Thunderbit, está cambiando las reglas del juego: ofrece mayores tasas de éxito, cero mantenimiento y procesamiento de datos integrado que las APIs tradicionales no pueden igualar.
- La mejor herramienta es la que encaja con tu flujo de trabajo, presupuesto y nivel técnico. ¡No tengas miedo de experimentar!
Si estás listo para dejar atrás los scripts rotos y el debugging interminable, prueba — o consulta más guías en el para profundizar en el scraping de Amazon, Google, PDFs y más.
Y recuerda: en el mundo de los datos web, lo único que cambia más rápido que los propios sitios es la tecnología que usamos para extraerlos. Mantén la curiosidad, mantén la automatización y que tus proxies nunca sean bloqueados.