
La web rebosa de datos y, seamos sinceros, nadie tiene tiempo de ir copiando y pegando mil fichas de producto o páginas de precios de la competencia una por una. Si usas Linux —como yo para buena parte de mi trabajo de automatización y desarrollo— ya sabes que esta plataforma es una auténtica potencia para equipos basados en datos. De hecho, y . Pero aquí está el reto: encontrar el Raspador Web adecuado para Linux que encaje de verdad con tu flujo de trabajo —ya seas un usuario de negocio sin perfil técnico o un programador experto— puede sentirse como buscar una aguja en un pajar.
Por eso he preparado este análisis en profundidad de las 18 mejores herramientas de raspado web para Linux en 2026. Desde soluciones sin código impulsadas por IA como (sí, la que hemos creado mi equipo y yo) hasta marcos clásicos para desarrolladores como Scrapy y Beautiful Soup, esta lista es tu atajo para elegir el mejor Raspador Web para Linux según tus necesidades, sin el quebradero de cabeza de probar a ciegas.
Por qué las herramientas de raspado web para Linux importan para los usuarios de negocio
Vamos a decirlo claro: recopilar datos a mano mata la productividad. Los estudios muestran que los equipos que dependen de copiar y pegar pierden horas cada semana y acumulan tasas de error cercanas al 5%; eso es una receta para errores costosos y oportunidades perdidas (). Linux, con su estabilidad, seguridad y flexibilidad, es la plataforma ideal para ejecutar raspadores que tienen que funcionar 24/7, ya sea en un escritorio, un servidor o en la nube.
Casos de uso habituales para herramientas de raspado web en Linux:
- Generación de leads: los equipos de ventas extraen nuevos contactos de directorios, redes sociales o sitios de reseñas, sin el trabajo manual de siempre ().
- Seguimiento de precios: los equipos de e-commerce recopilan automáticamente precios de la competencia y datos de stock para mantener sus tarifas competitivas y actualizadas.
- Investigación de la competencia: los equipos de marketing y operaciones siguen lanzamientos de producto, reseñas y palabras clave SEO; se acabó eso de ir a ciegas.
- Inteligencia de mercado: los analistas agregan noticias, foros y datos sociales para detectar tendencias en tiempo real.
- Automatización de flujos de trabajo: algunas herramientas —especialmente las impulsadas por IA— incluso pueden automatizar procesos web, como rellenar formularios o navegar por paneles, directamente desde tu máquina Linux.
¿Lo mejor? La herramienta de raspado web adecuada para Linux puede dar poder a los usuarios sin perfil técnico, no solo a los programadores, para acceder y aprovechar datos web y tomar decisiones empresariales más inteligentes y rápidas.
Cómo seleccionamos el mejor Raspador Web para Linux
No todos los raspadores son iguales, especialmente en Linux. Esto es lo que he tenido en cuenta:
- Compatibilidad con Linux: todas las herramientas de esta lista funcionan de forma nativa en Linux, vía navegador o con una solución sencilla, como Wine o acceso en la nube.
- Facilidad de uso: desde indicaciones de IA en lenguaje natural hasta interfaces visuales de apuntar y hacer clic, prioricé herramientas que permiten a los no programadores obtener resultados rápido, pero sin olvidar a quienes quieren control total.
- Potencia de extracción de datos: ¿puede manejar contenido dinámico, paginación, subpáginas y distintos tipos de datos? ¿Resiste trucos anti-raspado?
- Escalabilidad y automatización: programación, raspado en la nube, rastreo distribuido... imprescindibles para proyectos de datos serios.
- Integración y exportación: CSV, Excel, Google Sheets, APIs... si no puedes sacar tus datos, ¿de qué sirve?
- Precio y licencia: gratis, de código abierto o de pago; hay opciones para todos los presupuestos, desde fundadores en solitario hasta equipos empresariales.
- Comunidad y soporte: bases de usuarios activas, buena documentación y soporte ágil marcan una gran diferencia cuando surge un problema.
También he incluido opiniones reales de usuarios, reseñas del sector y mi propia experiencia práctica con estas herramientas. Vamos con la lista.
1. Thunderbit
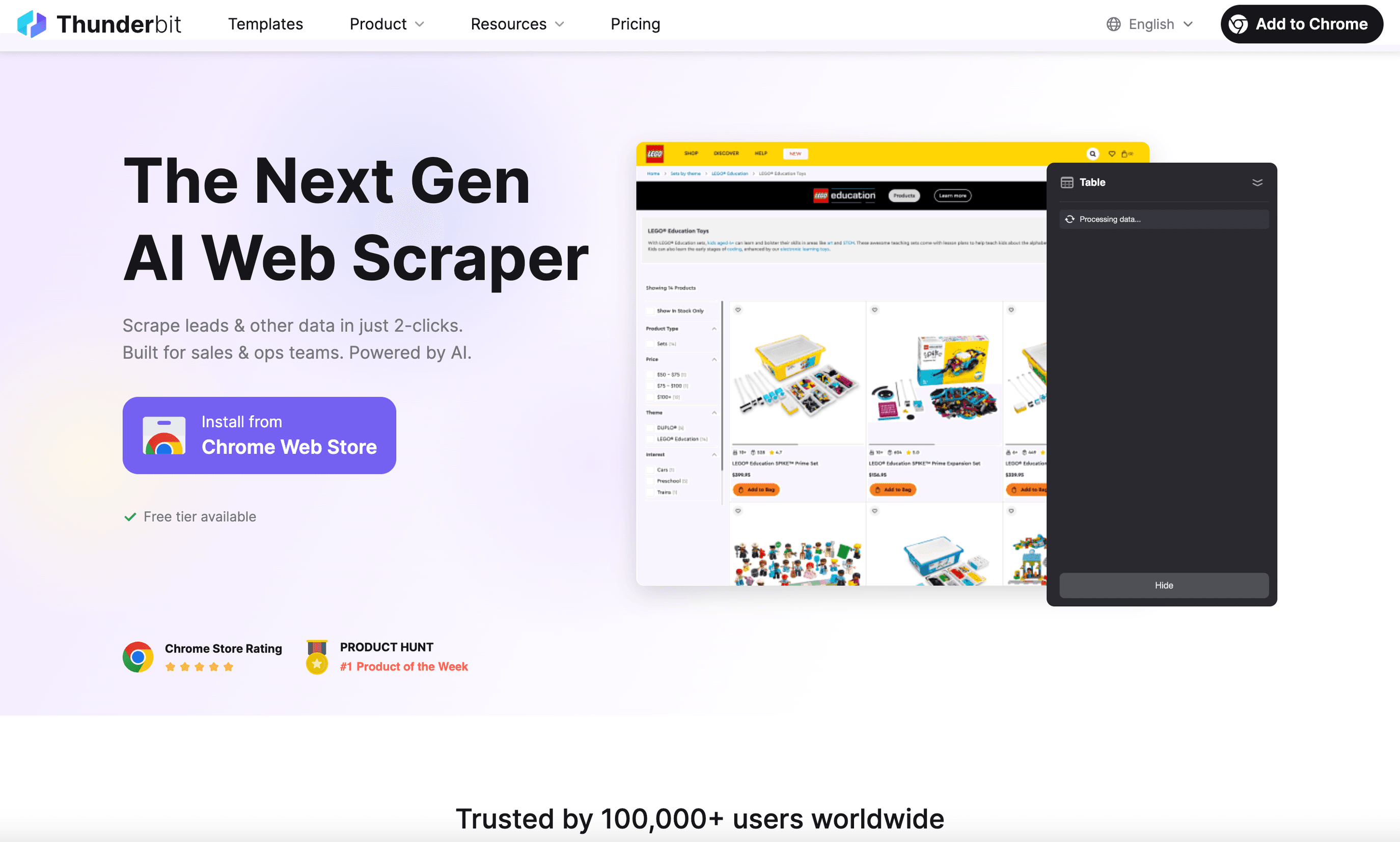 es mi primera opción para los usuarios de negocio que quieren un Raspador Web para Linux que de verdad sea fácil de usar. Como , funciona perfectamente en Linux (solo tienes que abrir Chrome o Chromium) y te permite extraer datos de cualquier sitio web en solo dos clics.
es mi primera opción para los usuarios de negocio que quieren un Raspador Web para Linux que de verdad sea fácil de usar. Como , funciona perfectamente en Linux (solo tienes que abrir Chrome o Chromium) y te permite extraer datos de cualquier sitio web en solo dos clics.
Lo que hace que Thunderbit destaque:
- Indicaciones en lenguaje natural: solo describe lo que quieres (“Extrae todos los nombres y precios de producto de esta página”) y la IA de Thunderbit se encarga del resto.
- Sugerencia de campos con IA: haces un clic y Thunderbit analiza la página, sugiriendo columnas y tipos de datos, sin selección manual de campos.
- Raspado de subpáginas y paginación: ¿necesitas más detalles? Thunderbit puede visitar cada subpágina (como las páginas de detalle de producto) y enriquecer tu tabla automáticamente.
- Raspado en la nube o local: extrae hasta 50 páginas a la vez en la nube, o usa el modo navegador para sitios que requieren inicio de sesión.
- Exportación instantánea: exporta con un clic a Excel, Google Sheets, Airtable, Notion, CSV o JSON, siempre gratis.
- Herramientas extra: extrae correos electrónicos, números de teléfono e imágenes con un solo clic. El autocompletado con IA incluso puede automatizar la entrada de formularios.
Precio: plan gratuito (raspado de 6 a 10 páginas); los planes de pago empiezan en 15 $/mes por 500 filas (). A los usuarios les encanta que “no tiene curva de aprendizaje” y que “convierte horas de trabajo en minutos” (). Para trabajos grandes, quizá tengas que dividirlos en ejecuciones más pequeñas, pero para la mayoría de casos de negocio es un enorme ahorro de tiempo.
Compatibilidad con Linux: 100%. Solo tienes que ejecutar Chrome/Chromium en tu escritorio o servidor Linux.
Ideal para: usuarios de negocio sin perfil técnico (ventas, marketing, operaciones) que quieren la configuración más rápida y sencilla.
2. Scrapy
 es el estándar de oro para los desarrolladores Python que quieren un Raspador Web flexible y escalable para Linux. Es de código abierto, rapidísimo (rastreo asíncrono) y puede con todo, desde extracciones simples hasta rastreos masivos distribuidos.
es el estándar de oro para los desarrolladores Python que quieren un Raspador Web flexible y escalable para Linux. Es de código abierto, rapidísimo (rastreo asíncrono) y puede con todo, desde extracciones simples hasta rastreos masivos distribuidos.
Características clave:
- Rastreo asíncrono y de alta velocidad, perfecto para extraer miles de páginas.
- Altamente extensible: complementos para proxies, CAPTCHAs y más.
- Se integra con el stack de datos de Python: salida a JSON, CSV, bases de datos o pandas.
- Gestiona cookies, sesiones y auto-throttling.
Precio: 100% gratis y de código abierto.
Compatibilidad con Linux: nativa (instalación mediante pip). Funciona muy bien en servidores y contenedores.
Ideal para: desarrolladores que crean raspadores personalizados a gran escala.
Ojo: para quienes no programan hay curva de aprendizaje, pero si sabes Python, Scrapy es difícil de superar.
3. Beautiful Soup
 es una biblioteca ligera de Python para analizar HTML y XML. Es la opción ideal para raspados rápidos y sencillos o para limpiar páginas web desordenadas.
es una biblioteca ligera de Python para analizar HTML y XML. Es la opción ideal para raspados rápidos y sencillos o para limpiar páginas web desordenadas.
Características clave:
- API simple y fácil de usar, ideal para principiantes.
- Funciona muy bien con requests para obtener páginas.
- Gestiona HTML roto con soltura.
Precio: gratis y de código abierto.
Compatibilidad con Linux: 100% (Python puro).
Ideal para: desarrolladores y científicos de datos que hacen tareas de raspado o análisis de pequeño a mediano tamaño.
Limitaciones: no maneja JavaScript ni contenido dinámico; combínalo con Selenium o Puppeteer si lo necesitas.
4. Selenium
 es el clásico marco de automatización de navegadores. Te permite controlar Chrome, Firefox u otros navegadores para raspar sitios dinámicos con mucho JavaScript.
es el clásico marco de automatización de navegadores. Te permite controlar Chrome, Firefox u otros navegadores para raspar sitios dinámicos con mucho JavaScript.
Características clave:
- Automatiza navegadores reales: puede iniciar sesión, hacer clic, desplazarse e interactuar como una persona.
- Compatible con Python, Java, C# y más.
- Modo headless para ejecutarlo en servidores Linux.
Precio: gratis y de código abierto.
Compatibilidad con Linux: compatibilidad total (solo tienes que instalar el controlador correcto del navegador).
Ideal para: ingenieros de QA, desarrolladores de scraping y cualquiera que necesite simular el comportamiento del usuario.
Ojo: consume muchos recursos y es más lento que los raspadores HTTP puros, pero a veces es la única forma de obtener los datos que necesitas.
5. Puppeteer
 es una biblioteca de Node.js de Google para controlar Chrome/Chromium en modo headless. Es parecido a Selenium, pero con una API moderna de JavaScript y una integración muy estrecha con las funciones de Chrome.
es una biblioteca de Node.js de Google para controlar Chrome/Chromium en modo headless. Es parecido a Selenium, pero con una API moderna de JavaScript y una integración muy estrecha con las funciones de Chrome.
Características clave:
- Ejecuta JavaScript, gestiona contenido dinámico y toma capturas de pantalla.
- Rápido, estable y fácil de usar para desarrolladores de Node.js.
- Intercepta solicitudes de red y bloquea recursos no deseados.
Precio: gratis y de código abierto.
Compatibilidad con Linux: instala Chromium automáticamente; funciona en modo headless por defecto.
Ideal para: desarrolladores que extraen datos de aplicaciones web modernas o sitios de una sola página.
6. Octoparse
 es un Raspador Web sin código con interfaz de arrastrar y soltar y un montón de plantillas prediseñadas. Aunque la aplicación de escritorio solo está disponible para Windows y Mac, los usuarios de Linux pueden acceder a la plataforma en la nube de Octoparse desde el navegador o ejecutar la app de Windows con Wine.
es un Raspador Web sin código con interfaz de arrastrar y soltar y un montón de plantillas prediseñadas. Aunque la aplicación de escritorio solo está disponible para Windows y Mac, los usuarios de Linux pueden acceder a la plataforma en la nube de Octoparse desde el navegador o ejecutar la app de Windows con Wine.
Características clave:
- Más de 100 plantillas listas para usar para sitios como Amazon, eBay, Zillow, etc.
- Diseñador visual de flujos de trabajo: apunta y haz clic para crear tu raspador.
- Raspado y programación en la nube: deja que los servidores de Octoparse hagan el trabajo pesado.
- Exporta a Excel, CSV, JSON y bases de datos.
Precio: plan gratuito (funciones limitadas), planes de pago desde 75–89 $/mes.
Compatibilidad con Linux: acceso en nube/web; app de escritorio mediante Wine.
Ideal para: usuarios sin código que necesiten datos de e-commerce o marketplaces rápidamente.
7. PhantomJS
 es un navegador WebKit en modo headless que en su día fue la opción preferida para automatización ligera de navegadores. Hoy está obsoleto, pero sigue funcionando en Linux para tareas heredadas o simples.
es un navegador WebKit en modo headless que en su día fue la opción preferida para automatización ligera de navegadores. Hoy está obsoleto, pero sigue funcionando en Linux para tareas heredadas o simples.
Características clave:
- Programable en JavaScript.
- Maneja JavaScript moderado y toma capturas de pantalla/PDF.
- No necesita interfaz gráfica.
Precio: gratis y de código abierto.
Compatibilidad con Linux: binario nativo.
Ideal para: proyectos heredados o entornos donde no sea posible instalar Chrome.
Advertencia: ya no tiene mantenimiento, así que los sitios modernos pueden no funcionar bien.
8. ParseHub
 es un Raspador Web visual y multiplataforma con una app nativa para Linux. Es ideal para quienes no programan y quieren extraer datos de sitios complejos y dinámicos.
es un Raspador Web visual y multiplataforma con una app nativa para Linux. Es ideal para quienes no programan y quieren extraer datos de sitios complejos y dinámicos.
Características clave:
- Interfaz de apuntar y hacer clic: selecciona elementos y construye flujos de trabajo visualmente.
- Gestiona contenido dinámico, mapas, scroll infinito y más.
- Ejecución y programación en la nube.
- Exporta a CSV, JSON o mediante API.
Precio: plan gratuito (5 proyectos), planes de pago desde 189 $/mes.
Compatibilidad con Linux: app nativa para Linux, Windows y Mac.
Ideal para: analistas y usuarios semitécnicos que quieren control sin programar.
9. Kimurai
 es un marco de raspado web en Ruby con compatibilidad nativa para Linux. Es como Scrapy, pero para desarrolladores Ruby.
es un marco de raspado web en Ruby con compatibilidad nativa para Linux. Es como Scrapy, pero para desarrolladores Ruby.
Características clave:
- Compatibilidad con varios navegadores: Headless Chrome, Firefox, PhantomJS o HTTP simple.
- Procesamiento asíncrono para alta concurrencia.
- DSL de Ruby limpio para escribir spiders.
Precio: gratis y de código abierto.
Compatibilidad con Linux: 100% (Ruby).
Ideal para: desarrolladores Ruby o equipos Rails que necesiten un raspado personalizado y de alta concurrencia.
10. Apify
 es una plataforma de raspado web en la nube con SDK de código abierto y un marketplace de “actors” listos para usar. Puedes ejecutar raspadores en tu máquina Linux o en la nube.
es una plataforma de raspado web en la nube con SDK de código abierto y un marketplace de “actors” listos para usar. Puedes ejecutar raspadores en tu máquina Linux o en la nube.
Características clave:
- SDK para Node.js, Python y más.
- Marketplace de raspadores preconstruidos.
- Ejecución en la nube, programación e integración con API.
Precio: plan gratuito, pago por uso en la nube.
Compatibilidad con Linux: CLI/SDK funciona en Linux; plataforma en la nube accesible desde el navegador.
Ideal para: desarrolladores que quieren combinar código personalizado con una infraestructura en la nube ya lista.
11. Colly
 es un marco de raspado web basado en Go creado para ofrecer velocidad y eficiencia. Si eres desarrollador Go, esta es tu herramienta.
es un marco de raspado web basado en Go creado para ofrecer velocidad y eficiencia. Si eres desarrollador Go, esta es tu herramienta.
Características clave:
- Raspado súper rápido y concurrente: más de 1.000 solicitudes/segundo en un solo núcleo.
- Rastreo respetuoso (cumple robots.txt), gestión de sesiones y cookies.
- Huella de memoria baja.
Precio: gratis y de código abierto.
Compatibilidad con Linux: binarios nativos de Go.
Ideal para: desarrolladores Go que necesitan raspado de alto rendimiento.
12. PySpider
 es un sistema de rastreo web en Python con interfaz web. Puedes gestionar, programar y supervisar los rastreos desde el navegador.
es un sistema de rastreo web en Python con interfaz web. Puedes gestionar, programar y supervisar los rastreos desde el navegador.
Características clave:
- Interfaz web para scripting y supervisión.
- Rastreo distribuido, programación e reintentos.
- Se integra con bases de datos y colas de mensajes.
Precio: gratis y de código abierto.
Compatibilidad con Linux: diseñado para despliegue en Linux.
Ideal para: equipos que gestionan varios proyectos de scraping desde una interfaz web.
13. WebHarvy
 es un Raspador visual de apuntar y hacer clic para Windows, aunque los usuarios de Linux pueden ejecutarlo con Wine. Es conocido por su detección de patrones y su modelo de compra única.
es un Raspador visual de apuntar y hacer clic para Windows, aunque los usuarios de Linux pueden ejecutarlo con Wine. Es conocido por su detección de patrones y su modelo de compra única.
Características clave:
- Explora y haz clic para seleccionar datos, sin programar.
- Detección automática de patrones para listas.
- Exporta a CSV, JSON, XML y SQL.
Precio: licencia única de unos 139 $.
Compatibilidad con Linux: funciona con Wine o en una máquina virtual.
Ideal para: principiantes o profesionales independientes que quieren un raspador rápido y visual.
14. OutWit Hub
 es una aplicación GUI nativa para Linux dedicada al raspado web. Reconoce automáticamente patrones de datos y ofrece potentes funciones de extracción y automatización.
es una aplicación GUI nativa para Linux dedicada al raspado web. Reconoce automáticamente patrones de datos y ofrece potentes funciones de extracción y automatización.
Características clave:
- Detecta automáticamente enlaces, imágenes, tablas, correos electrónicos y más.
- Editor de scripts para extracción personalizada.
- Automatización con macros y programación.
Precio: versión gratuita (limitada), licencia Pro de unos 50–100 $.
Compatibilidad con Linux: app nativa para Linux, Windows y Mac.
Ideal para: usuarios sin código con cierta inclinación técnica que quieren un raspador de escritorio con GUI.
15. Portia
 es un Raspador Web visual y de código abierto de Scrapinghub. Se ejecuta en el navegador y te permite anotar páginas para entrenar raspadores.
es un Raspador Web visual y de código abierto de Scrapinghub. Se ejecuta en el navegador y te permite anotar páginas para entrenar raspadores.
Características clave:
- Interfaz basada en navegador para extracción visual.
- Se integra con Scrapy para proyectos personalizados.
- De código abierto y extensible.
Precio: gratis y de código abierto.
Compatibilidad con Linux: basado en navegador; funciona en cualquier sistema operativo.
Ideal para: usuarios que quieren raspado visual de código abierto con integración de Scrapy.
16. Content Grabber
 es un Raspador visual de nivel empresarial para Windows, pero puede ejecutarse en Linux mediante Wine o virtualización.
es un Raspador visual de nivel empresarial para Windows, pero puede ejecutarse en Linux mediante Wine o virtualización.
Características clave:
- Editor visual más scripting en C# para lógica avanzada.
- Gestión de múltiples agentes y programación.
- Se integra con bases de datos, APIs y más.
Precio: licencias de miles de dólares; versión servidor desde 69 $/mes.
Compatibilidad con Linux: mediante Wine o máquina virtual.
Ideal para: agencias y equipos grandes que gestionan muchos proyectos de scraping.
17. Helium
 es una biblioteca de Python que simplifica la automatización con Selenium. Está pensada para que la automatización de navegadores resulte más humana y sencilla.
es una biblioteca de Python que simplifica la automatización con Selenium. Está pensada para que la automatización de navegadores resulte más humana y sencilla.
Características clave:
- Comandos intuitivos como
click("Login")owrite("email"). - Automatiza Chrome y Firefox.
- Genial para scripting rápido y tareas de automatización.
Precio: gratis y de código abierto.
Compatibilidad con Linux: funciona en Linux (basado en Selenium).
Ideal para: usuarios de Python que encuentran Selenium demasiado engorroso.
18. Dexi.io
 es una plataforma en la nube para extracción de datos y automatización. Se accede desde el navegador, así que los usuarios de Linux pueden usarla sin instalar nada.
es una plataforma en la nube para extracción de datos y automatización. Se accede desde el navegador, así que los usuarios de Linux pueden usarla sin instalar nada.
Características clave:
- Diseñador visual de flujos de trabajo para raspado y automatización.
- Programación, transformación de datos e integración con API.
- Escalabilidad y soporte de nivel empresarial.
Precio: desde 119 $/mes (Standard); planes superiores para mayor escala.
Compatibilidad con Linux: aplicación web: funciona en cualquier sistema operativo.
Ideal para: profesionales y empresas que necesitan extracción de datos web escalable e integrada.
Tabla comparativa rápida: herramientas de raspado web para Linux de un vistazo
| Herramienta | Tipo / Características clave | Ideal para | Precio | Compatibilidad con Linux |
|---|---|---|---|---|
| Thunderbit | Extensión de Chrome con IA, 2 clics, subpáginas, nube/local | Usuarios de negocio sin perfil técnico | Gratis, desde 15 $/mes | ✔ Chrome en Linux |
| Scrapy | Marco Python, asíncrono, CLI, muy extensible | Desarrolladores, raspadores personalizados a gran escala | Gratis | ✔ Nativo |
| Beautiful Soup | Biblioteca Python, análisis simple de HTML/XML | Desarrolladores, científicos de datos, tareas pequeñas | Gratis | ✔ Nativo |
| Selenium | Automatización de navegador, sitios con mucho JS | QA, desarrolladores, contenido dinámico | Gratis | ✔ Nativo |
| Puppeteer | Node.js, Chrome headless, renderizado JS | Desarrolladores Node, apps web modernas | Gratis | ✔ Nativo |
| Octoparse | Sin código, arrastrar y soltar, plantillas en la nube | Usuarios sin código, e-commerce | Gratis, desde 75 $/mes | ◐ Cloud/Wine |
| PhantomJS | WebKit headless, JavaScript programable | Proyectos heredados, ligero, sin Chrome | Gratis | ✔ Nativo |
| ParseHub | Visual, multiplataforma, apuntar y hacer clic | Analistas, usuarios semitécnicos | Gratis, desde 189 $/mes | ✔ Nativo |
| Kimurai | Marco Ruby, multibrowser, asíncrono | Desarrolladores Ruby, alta concurrencia | Gratis | ✔ Nativo |
| Apify | Plataforma en la nube, SDK, marketplace | Desarrolladores, híbrido personalizado/nube | Plan gratuito, pago por uso | ✔ Nativo/Nube |
| Colly | Marco Go, rápido, concurrente | Desarrolladores Go, alto rendimiento | Gratis | ✔ Nativo |
| PySpider | Python, interfaz web, programación, distribuido | Equipos, varios proyectos | Gratis | ✔ Nativo |
| WebHarvy | Visual, detección de patrones, licencia única | Principiantes, profesionales en solitario | ~139 $ pago único | ◐ Wine/VM |
| OutWit Hub | GUI nativa, detecta datos automáticamente, scripting | Usuarios sin código, GUI de escritorio | Gratis, Pro 50–100 $ | ✔ Nativo |
| Portia | De código abierto, visual, basado en navegador | Código abierto, integración con Scrapy | Gratis | ✔ Navegador |
| Content Grabber | Empresarial, visual, scripting, multiagente | Agencias, equipos grandes | $$$, desde 69 $/mes | ◐ Wine/VM |
| Helium | Python, Selenium simplificado, API intuitiva | Usuarios de Python, automatización rápida | Gratis | ✔ Nativo |
| Dexi.io | Nube, flujo visual, programación, API | Empresa, automatización escalable | Desde 119 $/mes | ✔ Navegador |
Cómo elegir el Raspador Web adecuado para Linux: factores clave
Elegir la herramienta correcta consiste en alinear tus necesidades con tus capacidades:
- Nivel técnico: quienes no programan deberían inclinarse por Thunderbit, ParseHub, Octoparse u OutWit Hub. Los desarrolladores pueden sacar más partido de Scrapy, Puppeteer, Colly o Kimurai.
- Complejidad de los datos: para páginas estáticas, Beautiful Soup o Colly son rápidos y sencillos. Para sitios dinámicos y con mucho JavaScript, necesitarás Selenium, Puppeteer o una herramienta visual que soporte JS.
- Escala y frecuencia: para trabajos puntuales, bastan herramientas sin código o raspadores en la nube. Para rastreos programados y a gran escala, elige Scrapy, PySpider o Apify.
- Necesidades de integración: ¿necesitas exportar a Excel, Sheets o una base de datos? Asegúrate de que la herramienta se adapte a tu flujo de trabajo.
- Presupuesto: abundan las opciones gratis y de código abierto para programadores. Para usuarios de negocio, Thunderbit y ParseHub ofrecen puntos de entrada asequibles, mientras que los equipos empresariales pueden invertir en Dexi.io o Content Grabber.
- Soporte y comunidad: las herramientas de código abierto tienen comunidades enormes; las comerciales ofrecen soporte dedicado.
Consejo profesional: no tengas miedo de combinar herramientas. Usa Thunderbit para prototipar e identificar patrones de datos, y luego pasa a Scrapy para rastreos a escala de producción. O usa Selenium para iniciar sesión y capturar cookies de sesión, y después delega en Colly o Scrapy para un raspado de alta velocidad.
Conclusión: encuentra tu mejor herramienta de raspado web para Linux en 2026
Los usuarios de Linux en 2026 tienen donde elegir. Tanto si quieres una herramienta sin código, impulsada por IA, que te dé resultados en minutos (Thunderbit), un sólido marco para desarrolladores (Scrapy, Colly) o una plataforma de nivel empresarial (Dexi.io), hay un Raspador Web para Linux que encaja con tus necesidades y tu flujo de trabajo.
Conclusiones clave:
- Linux es la base de la infraestructura de datos moderna: la mayoría de los mejores raspadores funcionan de forma nativa o vía navegador.
- Las herramientas de IA y sin código están democratizando el raspado web para usuarios de negocio.
- Los marcos para desarrolladores siguen dominando en flexibilidad, velocidad y escala.
- Pruébalo antes de comprar: la mayoría de las herramientas ofrece planes gratuitos o periodos de prueba.
¿Listo para empezar? o visita el para más guías sobre raspado web, automatización y crecimiento basado en datos.
Preguntas frecuentes
1. ¿Cuál es el Raspador Web más fácil para Linux si no sé programar?
es la mejor opción para usuarios sin perfil técnico. Funciona como extensión de Chrome en Linux, usa IA para automatizarlo todo y te permite extraer datos en solo dos clics.
2. ¿Qué raspador web para Linux es mejor para proyectos personalizados a gran escala?
es la opción preferida de los desarrolladores. Es rápido, escalable y muy personalizable, perfecto para rastreos grandes y recurrentes.
3. ¿Puedo raspar sitios con mucho JavaScript o dinámicos en Linux?
¡Sí! Usa o para controlar navegadores reales y extraer contenido dinámico. Las herramientas visuales como ParseHub y Thunderbit también admiten sitios dinámicos.
4. ¿Hay herramientas gratuitas de raspado web para Linux para uso empresarial?
Por supuesto. Scrapy, Beautiful Soup, Selenium, Colly, PySpider y Kimurai son gratuitas y de código abierto. Thunderbit y ParseHub ofrecen planes gratuitos para trabajos más pequeños.
5. ¿Cómo elijo entre raspadores para Linux sin código y basados en código?
Si quieres velocidad y simplicidad, elige sin código (Thunderbit, ParseHub, Octoparse). Si necesitas flexibilidad, automatización o integración con otros sistemas, las herramientas basadas en código (Scrapy, Puppeteer, Colly) son tu mejor apuesta.
¡Feliz raspado! Y que tus proyectos de datos sobre Linux funcionen más fluidos que una instalación recién hecha de Ubuntu. Si quieres ver más consejos de raspado web, visita el o suscríbete a nuestro para tutoriales prácticos.
Más información