

Temu ya llega a más de 416 millones de usuarios activos mensuales en más de 50 mercados. Su catálogo abarca desde utensilios de cocina hasta accesorios para mascotas y tiras LED. Si trabajas en ecommerce, dropshipping o inteligencia competitiva, seguro que alguna vez has querido llevar datos de Temu a una hoja de cálculo y luego has visto que Temu, la verdad, no pone nada fácil hacerlo.
He dedicado bastante tiempo a investigar y probar herramientas de scraping para sitios de ecommerce protegidos. Temu es uno de los objetivos más complicados que existen. La mayoría de las guías en línea o bien te dan un tutorial en Python que se rompe a la semana, o te mandan a APIs empresariales que cuestan más que tu presupuesto mensual de anuncios.
La realidad es que la mayoría de los usuarios de negocio —dropshippers, operadores en solitario, equipos de marketing— solo quieren una hoja de cálculo limpia con nombres de productos, precios, imágenes, valoraciones e información del vendedor. No quieren estar depurando scripts de Playwright a las 2 de la mañana.
Esta guía nace justo de esa necesidad: un desglose práctico, por niveles, de los mejores scrapers de Temu que de verdad funcionan en 2026, además de buenas prácticas para convertir un scrape puntual en inteligencia competitiva continua. Tanto si eres principiante total como si eres un desarrollador montando un canal de datos, aquí tienes una sección para ti.
Prueba Thunderbit para scrapear Temu
¿Por qué scrapear Temu? Principales casos de uso para equipos de negocio
Los datos de Temu no solo son interesantes: también tienen valor estratégico.
La plataforma se ha convertido en una referencia de precios en categorías de productos de ticket bajo y medio. Aunque no vendas en Temu, tus clientes comparan tus precios con lo que ven allí. Así es como usan los equipos los datos de Temu:
| Caso de uso | Datos necesarios | Por qué importa |
|---|---|---|
| Investigación de productos para dropshipping | Título, precio, imagen, valoración, número de reseñas, número de unidades vendidas, variantes | Encuentra productos de bajo coste con señales de demanda para compararlos en Amazon, Shopify, AliExpress y TikTok Shop |
| Precios competitivos | Precio actual, precio original, descuento %, moneda, envío, marca de tiempo | Sirve como base para la estrategia de precios y la planificación de promociones |
| Búsqueda de proveedores | Especificaciones, imágenes, variantes, vendedor/tienda, ID del artículo, categoría | Identifica tipos de producto y listados con perfil de proveedor que merecen una revisión más profunda |
| Análisis de tendencias de mercado | Palabra clave de búsqueda, categoría, número de ventas, número de reseñas, valoración | Muestra qué productos están ganando tracción en distintas categorías |
| Marketing e investigación creativa | Título, imagen, número de reseñas, valoración, descripciones, etiquetas de categoría | Revela mensajes, ganchos visuales, bundles y claims usados por los listados con más volumen |
| Seguimiento de stock y disponibilidad | URL del producto, disponibilidad, estimación de envío, precio, marca de tiempo | Detecta roturas de stock, cambios en almacenes locales y variaciones de precio a lo largo del tiempo |
Quienes buscan "los mejores scrapers de Temu" suelen dividirse en tres grupos. Los usuarios no técnicos quieren una extensión de Chrome que exporte a una hoja de cálculo. Los operadores semitécnicos quieren una herramienta visual con plantillas y programación. Los desarrolladores quieren una API, un script de Playwright y una estrategia de proxies.
Este artículo cubre los tres casos, pero empieza por el grupo más grande: personas que necesitan datos, no código.
Qué hace destacar a los mejores scrapers de Temu en 2026
Un scraper que funciona en Amazon o Shopify no necesariamente sobrevivirá en Temu. Los criterios de evaluación para este artículo son:
- Fiabilidad en Temu — ¿Devuelve realmente datos limpios o lo bloquean, saca filas vacías o se rompe tras un cambio de diseño?
- Facilidad de uso — ¿Puede empezar un usuario de negocio sin conocimientos técnicos sin escribir código?
- Completitud de los datos — ¿Admite enriquecimiento de subpáginas (visitar la página de detalle de cada producto para obtener especificaciones, variantes e información del vendedor)?
- Carga de mantenimiento — ¿Se adapta cuando Temu cambia la estructura de sus páginas?
- Programación y supervisión — ¿Puede ejecutar extracciones recurrentes y exportar a un destino de datos en vivo?
- Destinos de exportación — ¿CSV, Excel, Google Sheets, Airtable, Notion, JSON?
- Claridad de costes — ¿Cuánto cuesta realmente al mes un flujo de scraping de Temu?
Los informes de la comunidad en r/webscraping de Reddit describen de forma bastante consistente a Temu como uno de los sitios de ecommerce más difíciles de scrapear. Un usuario escribió que "ni siquiera puede obtener un precio como comprador", mientras que otro señaló que Temu y Shopee tienen equipos reforzando continuamente los mecanismos antibot. No existe una referencia pública de tasas de fallo específica para Temu, pero el Informe Bad Bot 2025 de Imperva descubrió que el tráfico automatizado superó al tráfico humano, con bots representando el 51% de todo el tráfico de Internet. Ese es el entorno del que Temu se está defendiendo.
Defensas antibot de Temu: por qué fallan la mayoría de los scrapers
La mayoría de los artículos sobre scraping de Temu dedican una frase a las medidas antibot: "Temu usa antibot". Eso no ayuda.
Si estás eligiendo una herramienta, necesitas saber qué defensas usa Temu y qué capacidades de la herramienta derrotan cada una. Este es el mapa práctico:
| Defensa de Temu | Qué hace | Capacidad necesaria en la herramienta | Ejemplos de herramientas |
|---|---|---|---|
| WAF de Cloudflare / comprobaciones del navegador | Bloquea agentes de usuario automatizados, identifica bots por huella digital y devuelve páginas de desafío | Infraestructura en la nube con IP residenciales rotativas y huellas de navegador reales | Thunderbit (scraping en la nube), Bright Data, Oxylabs, ScraperAPI |
| Renderizado intensivo con JavaScript | Los datos del producto se cargan mediante JS; el HTML sin procesar está vacío | Navegador sin interfaz o renderizado completo del navegador | Thunderbit (modo de scraping en navegador), Playwright, Selenium, ParseHub, actores de navegador de Apify |
| Selectores CSS dinámicos | Los nombres de clase cambian entre despliegues, rompiendo los scrapers basados en CSS | Detección de campos basada en IA (sin depender de selectores fijos) | Thunderbit (la IA lee la página desde cero cada vez), creador de scrapers con IA de Bright Data |
| Limitación de tasa | Reduce la velocidad de solicitudes secuenciales rápidas | Solicitudes concurrentes en la nube con limitación inteligente | Thunderbit (hasta 50 páginas a la vez mediante la nube), ScraperAPI, Bright Data |
| Desafíos CAPTCHA | Interrumpen las sesiones tras un comportamiento sospechoso | Resolución CAPTCHA integrada o una estrategia que dispare menos alertas | Bright Data, Oxylabs, ScraperAPI premium/ultra-premium |
| Scroll infinito / carga diferida | Solo aparecen los primeros productos sin interacción | Scroll inteligente, detección de paginación, automatización de interacciones | Paginación de Thunderbit, scroll inteligente de Apify, creador de flujos de Octoparse |
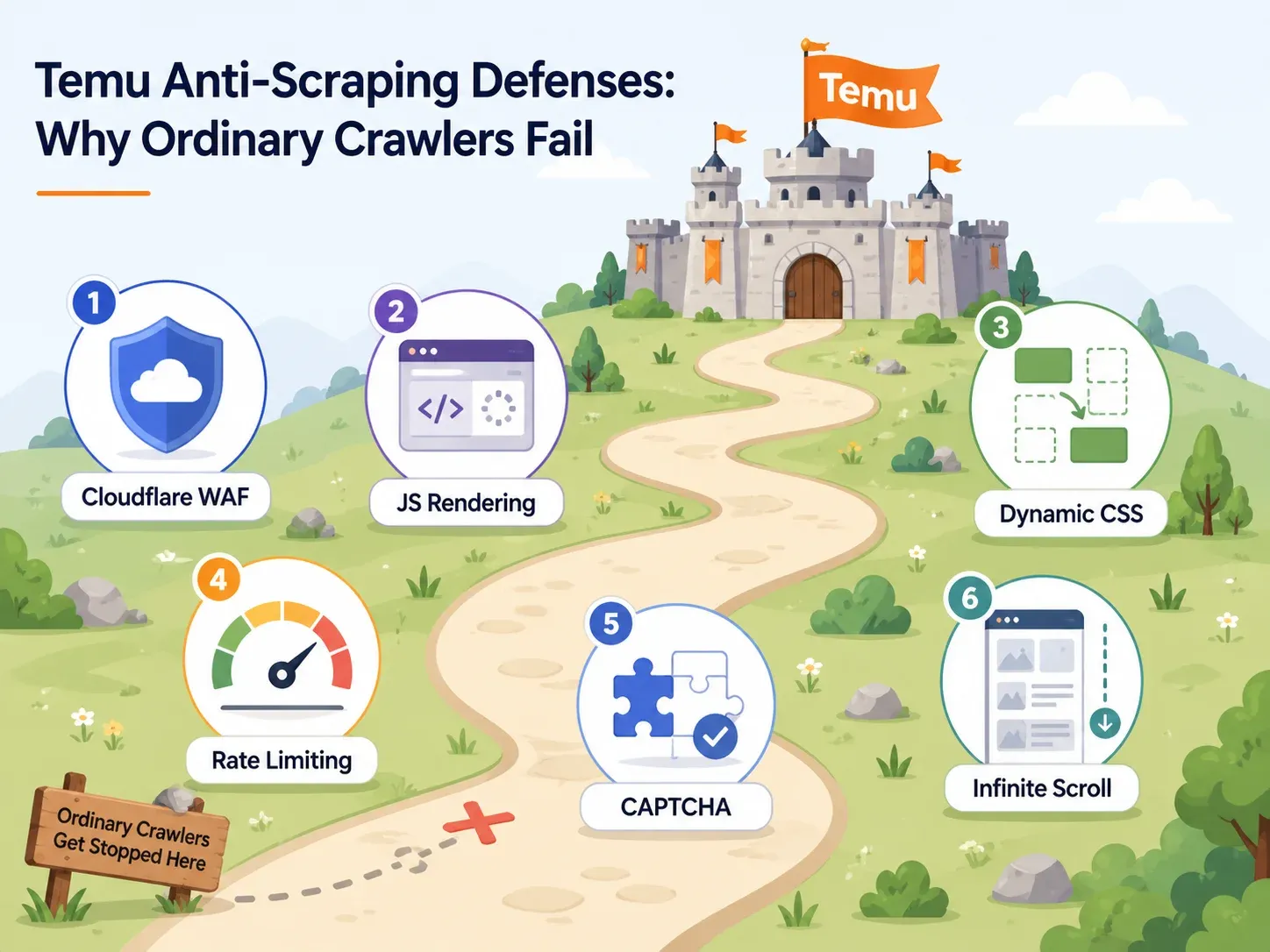
WAF de Cloudflare y bloqueo de IP
La puerta de entrada de Temu está protegida por comprobaciones de integridad del navegador al estilo de Cloudflare. Las solicitudes HTTP básicas —como las que hace una simple llamada requests.get() en Python— reciben un desafío, un 403 o datos incompletos.
Las herramientas que funcionan aquí necesitan IP residenciales o móviles rotativas y huellas de navegador reales. La revisión 2025 de Cloudflare Radar informó que los bots no basados en IA empezaron 2025 siendo responsables de aproximadamente la mitad de las solicitudes HTML de página. Esa es la escala de automatización contra la que se defienden plataformas como Temu.
Renderizado con JavaScript y selectores dinámicos
Aquí es donde fracasan en silencio la mayoría de los scrapers principiantes.
Si ves el código fuente de la página de Temu, a menudo encontrarás una carcasa vacía: las tarjetas de producto, los precios y las imágenes reales se inyectan con JavaScript después de que la página carga. Un scraper que solo lea HTML sin procesar no devolverá nada útil. Además, los nombres de clase CSS y las estructuras DOM de Temu cambian entre despliegues. Un scraper que dependa de un selector CSS fijo como .product-card__price funcionará hoy y devolverá columnas vacías mañana.
Los scrapers basados en IA (como Thunderbit) leen la página semánticamente cada vez, así que no dependen de que los nombres concretos de las clases sigan siendo los mismos.
Limitación de tasa y desafíos CAPTCHA
Si golpeas Temu demasiado rápido o demasiadas veces desde una sola IP, activarás límites de tasa o desafíos CAPTCHA. Algunas herramientas gestionan esto con limitación inteligente y resolución CAPTCHA integrada. Otras te lo dejan a ti, lo que para un usuario no técnico es básicamente un callejón sin salida.
Para el scraping en la nube, la clave son solicitudes concurrentes repartidas entre IP limpias con lógica automática de reintento.
Mejores scrapers de Temu por nivel de habilidad: desglose completo
Encuentra tu fila y ve a la sección que encaje:
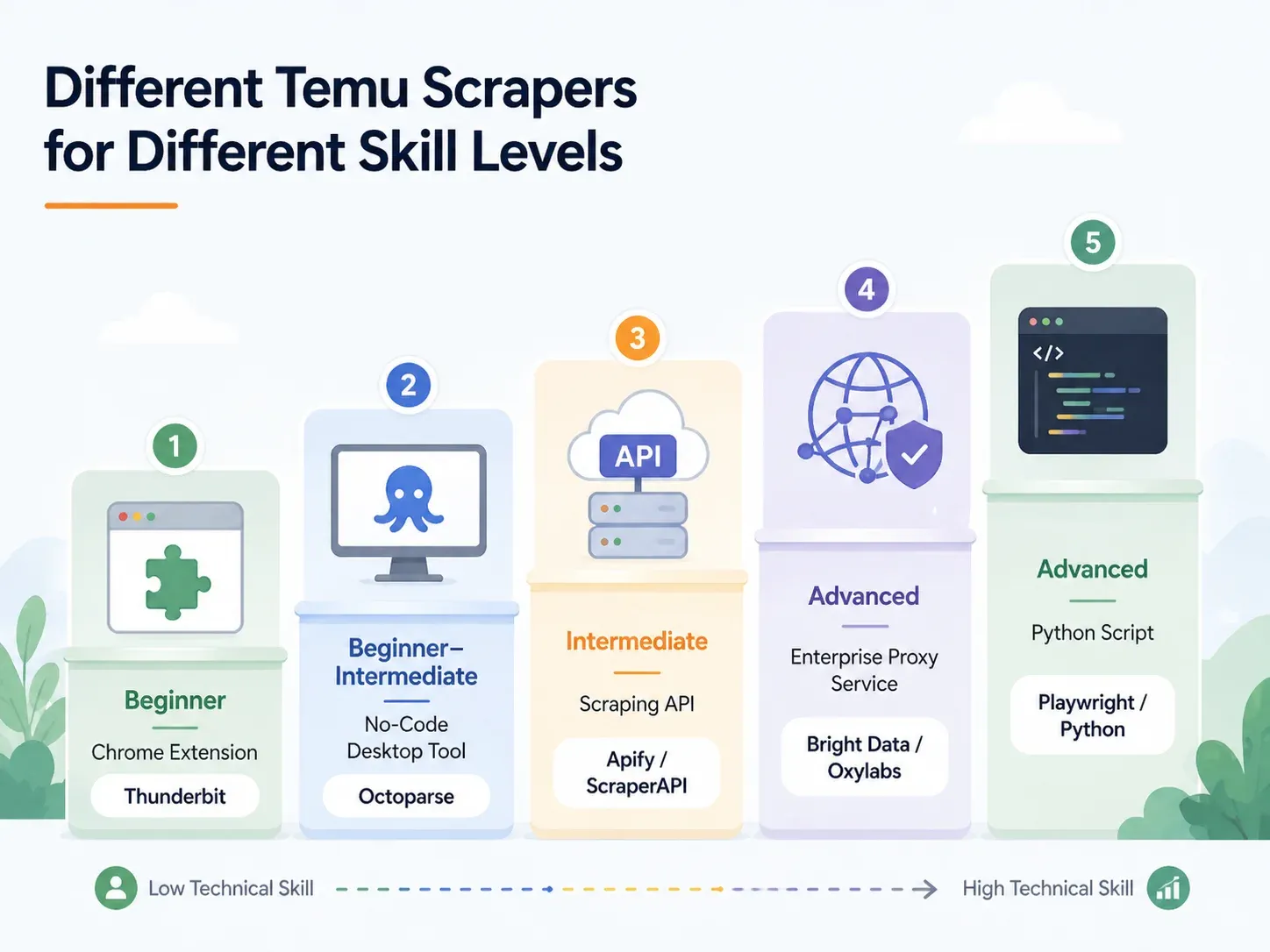
| Enfoque | Nivel de habilidad | Tiempo de configuración | Gestión antibot | Mejor para |
|---|---|---|---|---|
| Extensión Chrome con IA (p. ej., Thunderbit) | Principiante | < 2 min | Gestionada (nube o navegador) | Dropshippers, marketers, operaciones ecommerce |
| Herramienta de escritorio sin código (p. ej., Octoparse, ParseHub) | Principiante–intermedio | 10–60 min | Parcial (requiere configurar proxy) | Scraping habitual con plantillas |
| API/servicio de scraping (p. ej., ScraperAPI, Apify) | Intermedio | 15–45 min | Integrada | Desarrolladores que integran en pipelines |
| Proxy gestionado/empresarial (p. ej., Bright Data, Oxylabs) | Avanzado/empresarial | Horas–días | Infraestructura completa | Alto volumen, entrega a almacén de datos |
| Script personalizado en Python (Playwright/Selenium) | Avanzado | 1–4 h+ | Manual (configuración de proxy + CAPTCHA) | Control total, personalización para casos extremos |
Thunderbit: el mejor scraper de Temu para usuarios no técnicos
Thunderbit es una extensión de Chrome impulsada por IA, diseñada para usuarios de negocio —equipos de ventas, operaciones ecommerce, dropshippers, marketers— que necesitan datos estructurados de sitios web sin escribir código. Trabajo en el equipo de Thunderbit, así que conozco bien el producto. Seré directo sobre lo que hace y dónde encaja.
El flujo principal son dos clics: abres una página de Temu, haces clic en Sugerir campos con IA, revisas las columnas sugeridas (nombre del producto, precio, imagen, valoración, etc.) y luego haces clic en Scrapear.
La IA de Thunderbit lee la estructura de la página y propone automáticamente nombres de columnas y tipos de datos. No depende de selectores CSS fijos, así que cuando Temu cambia los nombres de clase o el diseño de las tarjetas, el scraper se adapta.
Funciones clave para Temu:
- Modo de scraping en la nube: Más rápido para páginas públicas, procesa hasta 50 páginas a la vez. Ideal para páginas de categorías, resultados de búsqueda y listados de productos que no requieren inicio de sesión.
- Modo de scraping en navegador: Usa tu sesión actual de Chrome, incluidas cookies, configuración regional y estado de inicio de sesión. Ideal cuando la región, los pop-ups o el contenido con sesión iniciada afectan a lo que muestra la página.
- Scrape Subpages: Después de scrapear una página de listado, haz clic en "Scrape Subpages" para visitar la página de detalle de cada producto y añadir columnas como descripción completa, variantes, información del vendedor, estimación de envío y especificaciones, sin configuración adicional.
- Prompts de IA para campos: Clasifica, traduce o reformatea datos durante el scrape. Por ejemplo: "Clasifica este producto en Utensilios de cocina, Pequeños electrodomésticos, Almacenamiento o Otros."
- Scraping programado: Configura una programación en lenguaje natural ("cada lunes a las 9am"), introduce URLs y Thunderbit ejecuta el scrape en la nube y exporta a Google Sheets, Airtable u otro destino.
- Exportaciones gratuitas: Excel, CSV, Google Sheets, Airtable, Notion, JSON — sin muro de pago para exportar. Las imágenes se exportan como adjuntos reales en Airtable y Notion.
Precio: plan gratuito con hasta 6 páginas (o 10 con un impulso de prueba); los planes de pago empiezan en torno a $15/mes (mensual) o $9/mes (anual) por 500 créditos, con 1 crédito = 1 fila de salida.
Scrapear datos de Temu con IA Get Started Free
Comparación directa: Thunderbit vs. un script de Python en la misma página de Temu
El contraste es enorme:
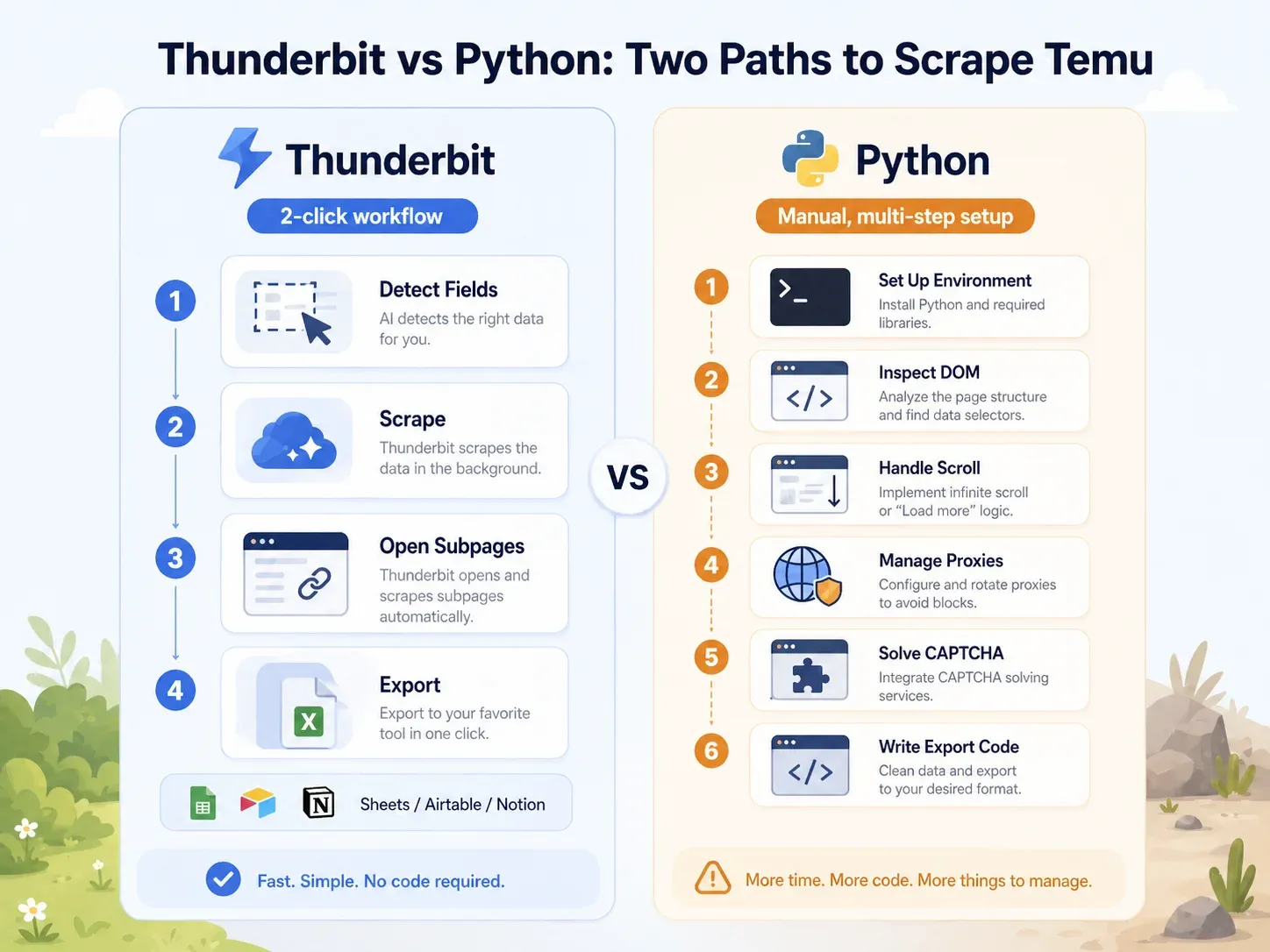
| Tarea | Thunderbit | Python (Playwright) |
|---|---|---|
| Abrir página de categoría de Temu | Abre la página en Chrome | Configura el entorno Python, instala Playwright, instala navegadores |
| Identificar campos | Haz clic en "Sugerir campos con IA" | Inspecciona el DOM, las llamadas de red y las cargas JSON |
| Manejar carga dinámica | Modo navegador/nube + paginación | Escribe lógica de scroll/espera, intercepta solicitudes |
| Manejar bloqueos | Prueba modo nube o modo navegador | Añade proxies, cabeceras, fingerprinting y reintentos, CAPTCHA |
| Extraer campos del listado | Haz clic en "Scrapear" | Escribe selectores o lógica de análisis de API |
| Enriquecer páginas de producto | Haz clic en "Scrape Subpages" | Crea un crawler PDP aparte |
| Exportar | Haz clic en Sheets/Airtable/Notion/Excel | Escribe código de integración CSV/JSON/Sheets |
| Configuración típica para un usuario de negocio | Menos de 2 minutos | 1–4 horas como mínimo; mantenimiento continuo |
Un prototipo mínimo en Playwright para Temu podría verse así (pseudocódigo, no listo para producción):
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.temu.com/search_result.html?search_key=kitchen+organizer")
page.wait_for_load_state("networkidle")
for _ in range(8):
page.mouse.wheel(0, 2000)
page.wait_for_timeout(1200)
cards = page.locator("[data-product-id], a[href*='goods.html']")
# El código de producción todavía necesita selectores, proxies, reintentos,
# gestión de CAPTCHA, rastreo PDP y lógica de exportación.
print(cards.count())
Eso son más de 10 líneas antes de haber extraído un solo campo, y aún no has tocado proxies, CAPTCHA, enriquecimiento de PDP ni exportación. Para un usuario no técnico, Thunderbit comprime todo ese flujo en un par de clics. Para un desarrollador, la ruta en Python ofrece más control, pero a costa de mucho más mantenimiento.
Octoparse y ParseHub: scrapers de Temu de escritorio sin código
Si quieres más control que una extensión de Chrome, pero no quieres escribir código, Octoparse y ParseHub son las opciones principales.
Octoparse tiene una plantilla pública Temu Details Scraper. Su salida de ejemplo incluye IDs de producto, títulos, precios, datos del vendedor/tienda, URLs de imágenes, descuentos, URLs de la tienda y especificaciones detalladas. Eso es una ventaja real: puedes empezar con una plantilla en lugar de construir un flujo desde cero. Octoparse también admite extracción en la nube, programación y creación visual de flujos de trabajo.
Las salvedades para Temu:
- Los complementos antibot (proxies residenciales a $3/GB, resolución de CAPTCHA a $1–$1.50 por mil) pueden disparar los costes con rapidez.
- Las plantillas pueden romperse cuando Temu cambia su diseño. Puede que tengas que actualizar selectores o esperar a que Octoparse mantenga la plantilla.
- La configuración tarda entre 10 y 60 minutos según la complejidad de la página.
Precios de Octoparse: plan gratuito con 10 tareas y 50K de exportación mensual de datos; Standard alrededor de $75/mes anual; Professional alrededor de $108/mes anual. Los complementos para proxies, CAPTCHA y servicios gestionados se cobran aparte.
ParseHub es un scraper visual de escritorio/web que maneja bien páginas dinámicas (ejecuta un navegador Chromium completo). Sin embargo, los planes de pago empiezan en $189/mes, lo cual es alto para un operador individual. No encontré una plantilla pública sólida específica para Temu en mi investigación. ParseHub encaja mejor con equipos que ya se sienten cómodos construyendo proyectos visuales de scraping.
| Herramienta | Fortalezas para Temu | Debilidades en Temu | Precio |
|---|---|---|---|
| Octoparse | Plantilla pública de Temu, flujo visual, extracción en la nube, programación | Mantenimiento de plantillas, los complementos antibot aumentan el coste | Gratis; ~75/mes anual Standard; ~108/mes anual Pro; complementos aparte |
| ParseHub | Manejo de páginas dinámicas, creador de flujos de proyecto, rotación de IP en planes de pago | Precio de entrada más alto, no se encontró plantilla pública de Temu | Planes de pago desde $189/mes |
APIs de scraping: ScraperAPI, Apify y Bright Data para Temu
Los servicios de scraping basados en API gestionan proxies, renderizado y lógica antibot, de modo que los desarrolladores pueden centrarse en analizar y almacenar datos. Encajan cuando estás creando un pipeline, no cuando haces una exportación puntual a una hoja de cálculo.
ScraperAPI es una API para desarrolladores de rotación de proxies y renderizado. Su página de precios indica una prueba de 7 días con 5,000 créditos, Hobby a $49/mes por 100,000 créditos y niveles superiores a partir de ahí. La trampa con Temu: el renderizado de JavaScript y los pools de proxies premium cuestan de 10 a 75 créditos por solicitud, según el nivel. Esa multiplicación de créditos significa que tu coste efectivo por fila puede ser mucho mayor que el precio de portada.
Apify es una plataforma con un marketplace de "actors" preconstruidos (scrapers). Existen varios actores para Temu. Un Temu Scraper mantenido por la comunidad muestra precios de pago por evento de alrededor de $5 por 1,000 productos en el nivel gratuito. Otro Temu Products Scraper lista $4 por 1,000 resultados. El riesgo: la calidad de los actores varía, el mantenimiento depende de la comunidad y algunos pueden quedar obsoletos o romperse cuando Temu se actualiza. Revisa siempre la fecha de "última modificación" y las valoraciones de usuarios antes de comprometerte.
Bright Data es la opción empresarial. Su página de scraper de Temu dice que los trabajos se ejecutan sobre la infraestructura de Bright Data con rotación de proxies, geotargeting, lógica de CAPTCHA/desbloqueo y autoscaling. Los formatos de salida incluyen JSON, CSV, Parquet y entrega directa a S3, GCS, Azure Blob, BigQuery y Snowflake. Las reseñas del sector indican que la API Web Scraper pay-as-you-go cuesta alrededor de $2.5 por 1,000 registros, con planes comprometidos que empiezan en torno a $499/mes. Potente, pero con precios pensados para equipos con presupuesto real.
Oxylabs también tiene una página dedicada a Temu Scraper API. Los planes empiezan en $49/mes, con una prueba gratuita de hasta 2,000 resultados. Es una alternativa sólida a Bright Data para equipos de desarrollo que quieren datos estructurados de Temu vía API.
| API/Plataforma | Evidencia específica para Temu | Fortaleza | Debilidad | Mejor para |
|---|---|---|---|---|
| ScraperAPI | No se encontró una página específica de Temu, pero sí funciones antibot para ecommerce | Endpoint simple, renderizado JS, proxies premium | Multiplicadores de créditos para funciones premium; el desarrollador debe analizar los datos | Pipelines de desarrollador |
| Apify | Varios actores de Temu en el marketplace | Ruta más rápida para desarrolladores si el actor encaja y se mantiene | La calidad de los actores varía; algunos están obsoletos | Desarrolladores que quieren marketplace de actores + programación |
| Bright Data | Página dedicada a scraper de Temu | Infraestructura empresarial, desbloqueo, entrega a almacén de datos | Caro; aún se requieren conceptos de web scraping | Equipos de datos a escala empresarial |
| Oxylabs | Página dedicada a Temu Scraper API | Precio claro por resultado, manejo de JS, promesas de IP/CAPTCHA | Flujo de trabajo de API para desarrolladores | Equipos de desarrollo que necesitan acceso a la API de Temu |
Scripts personalizados en Python (Playwright/Selenium): control total, mucho trabajo
Los scrapers personalizados en Python ofrecen la máxima flexibilidad: esa es la ventaja. Playwright suele ser un mejor punto de partida que Selenium para Temu por su modelo de autoespera y su mejor manejo de páginas pesadas en JavaScript.
Pero el intercambio es duro.
Un prototipo tarda de 1 a 4 horas. Un scraper de producción necesita rotación de proxies, huellas de navegador realistas, estrategia CAPTCHA, reintentos, validación de esquema, almacenamiento de salida, monitorización, alertas y revisión legal.
Y se rompe. Las comunidades de scraping en Reddit describen repetidamente el scraping moderno de ecommerce como inestable cuando los sitios usan Cloudflare, renderizado JavaScript y huellas antibot.
| Modo de fallo | Causa típica | Mitigación | |---|---|---|---| | HTML vacío / productos ausentes | JS carga las tarjetas de producto después del HTML inicial | Usa Playwright, espera a la red y al DOM | | Solo aparecen los primeros productos | Scroll infinito / carga diferida | Bucle de scroll, espera a red inactiva, umbrales de recuento de tarjetas | | Precios faltantes o incoherentes | Estado de región/sesión/moneda o respuesta antibot | Configura locale, cookies, proxy con geolocalización | | 403 / desafío / CAPTCHA | Reputación de IP, huella de navegador headless, ritmo de solicitudes | Proxies residenciales, navegador stealth, menor ritmo | | Ruptura de selectores | Cambios en DOM/clases, pruebas A/B | Extracción semántica o análisis de API si está disponible |
Los scripts personalizados no son la opción "gratis". Trasladan el coste de las suscripciones al tiempo de desarrollo, las facturas de proxies, los costes de CAPTCHA y el riesgo de mantenimiento. Si tienes un ingeniero de scraping en plantilla y necesitas lógica poco habitual, este es el camino correcto. Para todos los demás, en la práctica es la opción más cara.
Mejor práctica: scraping de subpáginas para obtener datos completos de producto en Temu
Esta es la mejor práctica con más impacto de todo el artículo, y casi ninguna otra guía la cubre.
Una página de categoría o búsqueda de Temu te muestra lo básico: título, miniatura, precio, valoración aproximada. Pero los campos que de verdad hacen que una fila sea accionable —descripciones detalladas, listas de variantes, recuento completo de reseñas, estimaciones de envío, nombres del vendedor, tablas de especificaciones— están en la página de detalle del producto (PDP).
Si solo haces scraping de la página de listado, trabajas con un conjunto de datos parcial.
El flujo de dos pasos:
- Paso 1 — Scrapear la página de listado (PLP): Extrae nombre del producto, precio, miniatura y valoración desde una página de búsqueda o categoría de Temu.
- Paso 2 — Enriquecer mediante scraping de subpáginas: Visita la PDP de cada producto y añade columnas como descripción completa, número de reseñas, opciones de variante, tiempo de envío e información del vendedor.
Así se ven los datos antes y después:
| Campo | Desde PLP (Paso 1) | Añadido desde PDP (Paso 2) |
|---|---|---|
| Título del producto | ✅ | — |
| Precio | ✅ | ✅ (verificado / % de descuento) |
| Miniatura | ✅ | — |
| Valoración con estrellas | ✅ | ✅ (con número de reseñas) |
| Descripción completa | ❌ | ✅ |
| Variantes (tallas, colores) | ❌ | ✅ |
| Nombre del vendedor | ❌ | ✅ |
| Estimación de envío | ❌ | ✅ |
| Especificaciones detalladas | ❌ | ✅ |
En Thunderbit, esto es un clic: después del scrape inicial, haz clic en "Scrape Subpages". La IA visita la URL de cada producto y añade las columnas adicionales, sin configuración extra, sin un spider aparte y sin mantenimiento de selectores. La plantilla Temu Details de Octoparse y el actor de Temu de Apify también admiten campos a nivel de PDP, pero con más configuración y mantenimiento. En Python, tendrías que construir un crawler PDP aparte, mantener sus selectores y gestionar la paginación dentro de las páginas de detalle, una inversión adicional considerable.
Mejor práctica: scraping programado de Temu para seguimiento continuo de precios y stock
Los scrapes puntuales son útiles para descubrir productos. La inteligencia competitiva exige observación repetida.
Los precios cambian, los productos se agotan, aparecen artículos nuevos a diario y la profundidad de los descuentos varía con las promociones. Un scrape semanal o diario crea una tabla histórica sobre la que tu equipo puede actuar.
Tres casos de uso que merece la pena automatizar:
- Monitorización de precios: Haz seguimiento semanal de los 50 SKU principales de un competidor en Temu. Obtén precios actualizados exportados automáticamente a Google Sheets para compararlos de un vistazo con tus propios precios.
- Monitorización de stock y disponibilidad: Detecta cuándo un producto en tendencia se agota, aparece una nueva variante o cambian las estimaciones de envío.
- Detección de nuevos productos/tendencias: Programa un scrape diario de "New Arrivals" de Temu o de una página de categoría prioritaria. Ordena por número de ventas o número de reseñas para detectar pronto los productos en ascenso.
En Thunderbit, lo configuras describiendo el intervalo en lenguaje natural ("cada lunes a las 9am"), introduciendo tus URLs objetivo y haciendo clic en "Schedule". El scrape se ejecuta en la nube y exporta al destino que elijas. Como la IA lee la página desde cero cada vez, los scrapes programados se adaptan automáticamente a los cambios de diseño de Temu: no necesitas actualizar selectores cuando Temu rediseña una tarjeta de producto.
La alternativa: configurar un cron job, mantener un script en Python, configurar rotación de proxies, construir un pipeline de salida y corregir selectores cada vez que Temu cambia su diseño. Para un equipo no técnico, eso no es viable. Para un desarrollador, es sobrecarga continua. Apify y Bright Data también admiten ejecuciones programadas, pero con más configuración técnica y costes mínimos más altos.
Mejor práctica: flujo de trabajo de datos de Temu de extremo a extremo (scrape → limpiar → exportar → actuar)
La mayoría de las guías de scraping terminan en "descargar CSV".
Pero los usuarios de negocio necesitan los datos dentro de las herramientas con las que realmente trabajan: Google Sheets para colaboración, Airtable para bases de productos, Notion para paneles de equipo. La verdadera mejor práctica es un flujo de trabajo de extremo a extremo:
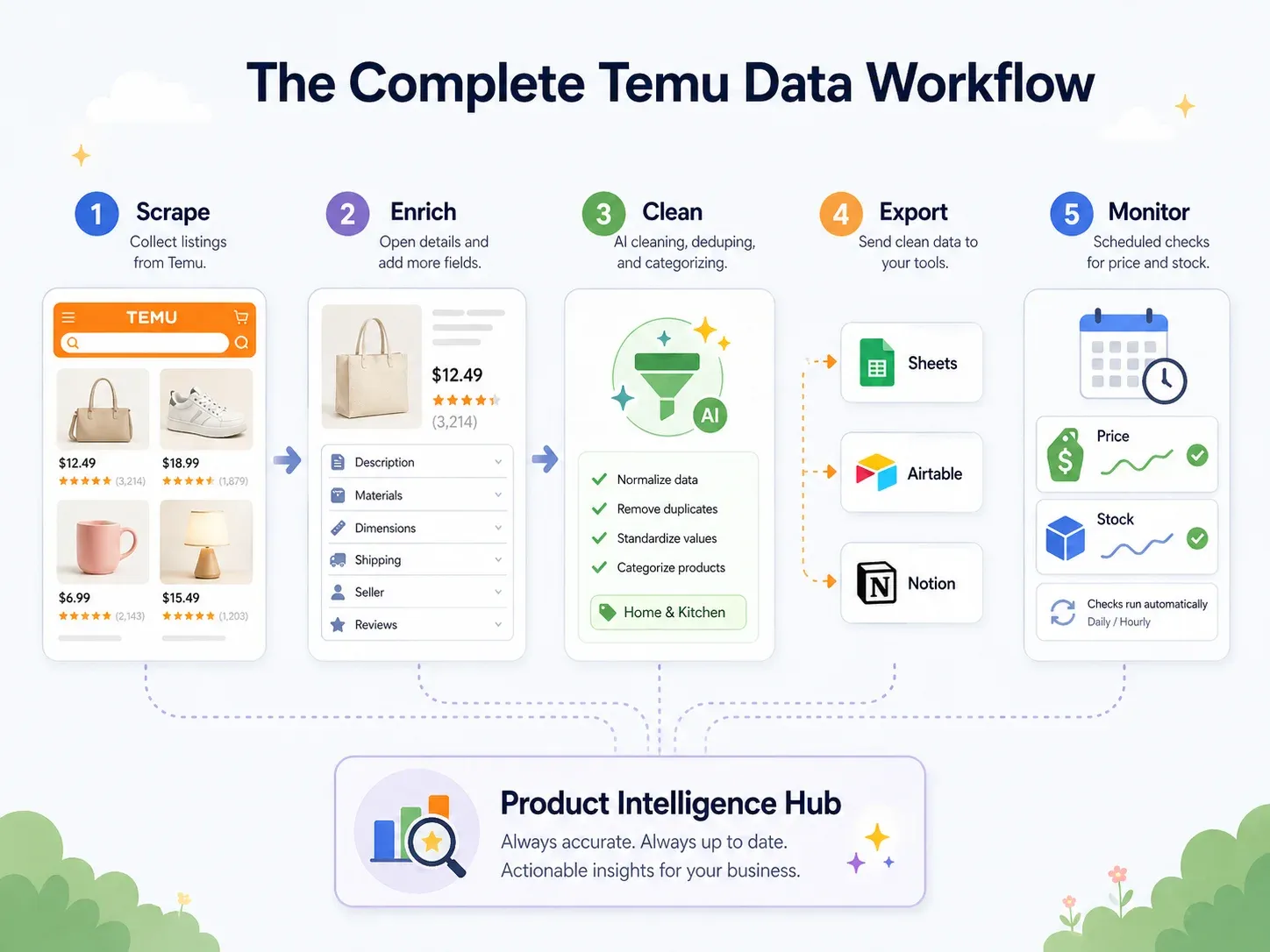
| Paso del flujo | Qué sucede | Capacidad de Thunderbit |
|---|---|---|
| Scrapear | Extraer datos de páginas de Temu | Sugerir campos con IA → Scrapear (2 clics) |
| Enriquecer | Visitar la página de detalle de cada producto | Scrape Subpages (1 clic) |
| Limpiar y etiquetar | Clasificar productos, normalizar precios, traducir títulos | Prompt de IA para campos: etiquetar, formatear y traducir durante el scrape |
| Exportar | Enviar datos a herramientas de negocio | Exportación gratuita a Excel, Google Sheets, Airtable, Notion; descarga CSV/JSON |
| Monitorizar | Seguir cambios a lo largo del tiempo | Scraper programado con intervalos en lenguaje natural |
Un ejemplo concreto: haces scraping de 200 productos de cocina de Temu. Durante el scrape, un Prompt de IA para campos clasifica automáticamente cada producto en "Utensilios / Pequeños electrodomésticos / Almacenamiento / Limpieza / Decoración". Los precios se normalizan a valores numéricos en USD. Los títulos de producto en chino se traducen al inglés. Los datos se exportan directamente a una base de Airtable con las imágenes de producto intactas (no solo URLs: adjuntos de imagen reales, como se describe en la guía de scraping de imágenes de Thunderbit). Un scrape programado actualiza los datos cada semana.
Algunas instrucciones útiles de Prompt de IA para datos de Temu:
- "Clasifica este producto en una de estas categorías: Utensilios de cocina, Pequeños electrodomésticos, Almacenamiento, Limpieza, Decoración, Otros. Devuelve solo la categoría."
- "Traduce el título del producto a un inglés conciso, preservando nombres de marca, cantidades, tamaños y números de modelo."
- "Normaliza el precio como un número sin símbolos de moneda."
- "Etiqueta la demanda como Alta, Media o Baja según la valoración, el número de reseñas y el número de ventas. Si falta algún dato, devuelve Desconocido."
Este flujo convierte un scrape bruto en una base de inteligencia de producto viva, sin que un desarrollador tenga que montar un pipeline ETL aparte.
Mejores scrapers de Temu comparados: tabla lado a lado
| Herramienta | Nivel de habilidad | Tiempo de configuración | Gestión antibot | Scraping de subpáginas | Programación | Opciones de exportación | Nivel de precio | Mejor para |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | Principiante | Minutos | Modo navegador, modo nube, detección de campos con IA | Sí (Scrape Subpages) | Sí (programaciones en lenguaje natural) | Excel, CSV, Google Sheets, Airtable, Notion, JSON | Gratis 6 páginas; de pago desde aprox. $9–15/mes por 500 créditos | Equipos ecommerce no técnicos, dropshippers |
| Octoparse | Principiante–intermedio | 10–60 min | Extracción en la nube, complementos de proxy/CAPTCHA | Sí (flujos de plantilla) | Sí (planes de pago/nube) | Excel, CSV, JSON, HTML, XML, base de datos, Google Sheets | Gratis; aprox. $75/mes anual Standard; complementos aparte | Operadores que quieren flujos visuales + plantilla de Temu |
| ParseHub | Principiante–intermedio | 30–60 min | Renderizado dinámico, rotación de IP en planes de pago | Sí (flujos de proyecto) | Planes de pago | CSV/JSON, Dropbox/S3 en planes de pago | Desde $189/mes | Equipos que construyen proyectos visuales para sitios dinámicos |
| ScraperAPI | Desarrollador | Horas | Rotación de proxies, renderizado JS, pools premium | Con código personalizado | DataPipeline/programador | HTML/JSON/CSV | Prueba 5K créditos; Hobby $49/mes; niveles superiores disponibles | Desarrolladores que crean pipelines personalizados para Temu |
| Apify | Intermedio | 10–30 min si el actor encaja | Lógica de navegador/proxy específica del actor | Depende del actor | Sí | JSON, CSV, Excel, API/datasets | Plataforma gratuita; actores de Temu aprox. $4–5/1K productos | Desarrolladores/operadores que pueden evaluar la calidad del actor |
| Bright Data | Avanzado/empresarial | Horas–días | Proxy completo, CAPTCHA, desbloqueo, autoscaling | Personalizado vía scraper/API | Sí | JSON, CSV, Parquet, S3, GCS, Azure, BigQuery, Snowflake | aprox. $2.5/1K registros PAYG; compromisos desde ~$499/mes | Equipos de datos empresariales, extracción de alto volumen |
| Oxylabs | Avanzado | Horas | Manejo de JS, promesas de IP/CAPTCHA | Personalizado vía API | Sí | JSON/salida de API | Desde $49/mes; prueba hasta 2K resultados | Equipos de desarrollo que necesitan acceso a la API de Temu |
| Python personalizado (Playwright) | Avanzado | 1–4 h+; mantenimiento continuo | Proxies manuales, CAPTCHA, huellas | Totalmente personalizado | Cron/cola/manual | Personalizado | Tiempo de desarrollo + costes de proxy/CAPTCHA/hosting | Casos extremos, equipos con ingenieros de scraping |
¿Qué scraper de Temu deberías elegir? Recomendaciones rápidas
- ¿Dropshipper que necesita investigación rápida de productos? Empieza con el plan gratuito de Thunderbit. Es la forma más rápida de pasar de "quiero datos de Temu" a "ya tengo una hoja de cálculo". Si funciona en tus páginas objetivo (y debería funcionar en la mayoría de páginas públicas de categorías y productos), listo.
- ¿Operador que quiere control visual y plantillas reutilizables? Octoparse tiene una plantilla pública Temu Details y un creador visual de flujos. Cuenta con 10–30 minutos de configuración y algo de ajuste de proxy/CAPTCHA.
- ¿Desarrollador que está construyendo un pipeline de datos o una herramienta interna? ScraperAPI o Apify te dan flujos de trabajo de API/actor que se integran con código y trabajos programados. Revisa los actores de Apify con cuidado: comprueba el estado de mantenimiento y las valoraciones de usuarios.
- ¿Equipo empresarial que necesita datos de Temu a gran volumen y entrega a almacén de datos? Bright Data es la apuesta de infraestructura. Es caro, pero maneja escala, desbloqueo y entrega a S3/BigQuery/Snowflake.
- ¿Ingeniero de scraping que necesita lógica poco habitual? Un Playwright/Selenium personalizado te da control total. Solo hay que presupuestar el mantenimiento continuo, los costes de proxy y la gestión de CAPTCHA.
Para la mayoría de los usuarios de negocio no técnicos, recomendaría probar primero el plan gratuito de Thunderbit. La pregunta inmediata siempre es "¿puedo obtener las filas que necesito de esta página exacta de Temu?" —y puedes responderla en menos de dos minutos sin gastar nada. Para desarrolladores, compara el coste por fila exitosa entre Apify, ScraperAPI y un pequeño prototipo en Playwright antes de comprometer presupuesto.
Prueba Thunderbit gratis para scrapear Temu
Preguntas frecuentes sobre scrapear Temu
¿Es legal scrapear Temu?
Depende de la jurisdicción, de los datos que recopiles, del método de acceso y de cómo uses los datos. Los Términos de uso de Temu restringen explícitamente el acceso automatizado, incluido rastrear, scrapear o hacer spidering de páginas o datos. Los tribunales de EE. UU. han ofrecido algunos precedentes favorables para acceder a datos disponibles públicamente (la decisión hiQ contra LinkedIn del Noveno Circuito), pero resoluciones posteriores también respaldaron reclamaciones por incumplimiento de contrato e invasión. La respuesta corta: scrapear datos de producto disponibles públicamente para investigación puede ser defendible en algunos contextos, pero los Términos de servicio, la ley de privacidad, el copyright y el uso que hagas de los datos importan. Esto no es asesoramiento legal: consulta con un abogado para usos comerciales.
¿Con qué frecuencia cambia Temu el diseño de su sitio?
No se ha documentado una cadencia pública. Los informes de la comunidad y el ecosistema de herramientas tratan a Temu como un objetivo dinámico, que se actualiza con frecuencia. Da por hecho que los selectores CSS pueden romperse en cualquier momento y prefiere extracción basada en IA/semántica o plantillas mantenidas activamente frente a selectores codificados a mano.
¿Puedo scrapear Temu sin que me bloqueen?
Para páginas públicas limitadas y con un ritmo responsable, sí, especialmente usando herramientas con renderizado real del navegador, soporte de sesión y limitación de ritmo. Ninguna herramienta debe considerarse una garantía universal. El scraping en la nube con IP rotativas funciona bien para páginas públicas de catálogo; el scraping en navegador con tu sesión actual funciona mejor cuando la región, el inicio de sesión o los pop-ups afectan a los datos.
¿Qué datos puedo extraer de las páginas de producto de Temu?
Los campos públicos habituales incluyen título del producto, URL, precio actual, precio original, porcentaje de descuento, URLs de imágenes, valoración con estrellas, número de reseñas, número de unidades vendidas, nombre del vendedor/tienda, información de envío, categoría, especificaciones del producto, variantes (colores, tallas) y marca de tiempo del scrape. Los campos exactos disponibles dependen del tipo de página (listado frente a detalle) y de la región.
¿Necesito proxies para scrapear Temu?
Para una extracción pequeña en modo navegador y estilo manual (unas pocas páginas a la vez), puede que no. Para recopilación en la nube, programada o de alto volumen, normalmente son necesarios proxies o una infraestructura gestionada antibloqueo. Herramientas como Thunderbit, Bright Data y ScraperAPI integran la gestión de proxies en sus plataformas para que no tengas que configurarla por separado.
Si quieres profundizar en temas relacionados, consulta nuestras guías sobre scraping web para comparación de precios, los mejores scrapers web para ecommerce, cómo scrapear datos de sitios web a Excel y cómo scrapear en Google Sheets. También puedes ver tutoriales en el canal de YouTube de Thunderbit.
Prueba Thunderbit para scrapear Temu Get Started Free
Más información




