La web se ha convertido en un terreno salvaje y en constante cambio: mejor pensar menos en una “biblioteca digital” y más en una “jungla de datos”. En 2025, si intentas extraer datos de sitios modernos, no te enfrentas solo a un muro de JavaScript: estás delante de una fortaleza. He visto de primera mano cómo las herramientas tradicionales de scraping se vienen abajo por el peso del contenido dinámico, el scroll infinito y los escudos antiboT. Por eso, el auge del navegador headless en Python no es solo una moda: es una auténtica revolución para cualquiera que necesite extracción de datos web fiable y escalable.
Y no es algo que interese solo a los perfiles técnicos. En 2025, , y más del . Ya trabajes en ventas, ecommerce u operaciones, elegir el navegador headless en Python adecuado marca la diferencia entre “los datos al alcance de la mano” y “los datos fuera de alcance”. Así que vamos al grano: he probado, comparado y usado estas herramientas, y aquí te presento los 10 mejores navegadores headless en Python para scraping moderno (con un foco especial en cómo la IA está cambiando las reglas del juego para quienes no programan).
¿Qué hace que un navegador headless en Python sea esencial para el scraping moderno?
Vamos a poner en claro la jerga: un navegador headless en Python no es más que un navegador web que controlas con código Python, pero sin la ventana aparatosa en pantalla. Carga páginas, ejecuta JavaScript, hace clic en botones, rellena formularios... todo de forma invisible, en segundo plano. Piensa en él como en un navegador fantasma que trabaja sin descanso mientras tú te tomas un café.
¿Por qué importa esto? Porque los sitios web modernos están pensados para usuarios, no para bots. Ocultan datos detrás de JavaScript, piden inicios de sesión y esperan que interactúes como una persona real. Los scrapers tradicionales, que solo descargan HTML, se quedan mirando cáscaras vacías. En cambio, los navegadores headless simulan el comportamiento real de un usuario: esperan las llamadas AJAX, hacen scroll por feeds infinitos y capturan el contenido exactamente como lo ves en Chrome o Firefox ().
Pero hay más:
- Velocidad y eficiencia: Los navegadores headless se saltan el renderizado visual, así que son más rápidos y consumen menos memoria, perfectos para scraping a gran escala ().
- Soporte para contenido dinámico: Ejecutan JavaScript, así que obtienes los datos reales ya renderizados, no solo el HTML en bruto.
- Superpoderes de automatización: ¿Necesitas iniciar sesión, paginar o gestionar ventanas emergentes? Los navegadores headless en Python pueden automatizarlo todo.
- Escalabilidad: Ejecuta cientos de instancias en la nube, extrae miles de páginas en paralelo y simplifica el proceso.
Para usuarios de negocio, esto significa que por fin puedes recopilar leads, vigilar a la competencia o rastrear precios, incluso si el sitio está construido como Fort Knox. Y con las últimas herramientas impulsadas por IA, ni siquiera necesitas saber programar para aprovecharlas.
Cómo elegimos los mejores navegadores headless en Python
No me limité a lanzar dardos sobre una lista de nombres de navegadores. Esto fue lo que evalué:
- Rendimiento y velocidad: ¿Puede manejar sitios modernos y cargados de JavaScript con rapidez y fiabilidad?
- Compatibilidad con navegadores: ¿Funciona con Chrome, Firefox, WebKit o incluso motores antiguos como IE?
- Facilidad de uso: ¿Es accesible para quienes no programan o exige un doctorado en Python?
- Funciones de IA y sin código: ¿Pueden los usuarios de negocio aprovechar la IA para automatizar el scraping sin escribir scripts?
- Comunidad y soporte: ¿Tiene una comunidad activa, buena documentación y desarrollo continuo?
- Funciones únicas: ¿Ofrece algo especial, como plantillas instantáneas, scraping en la nube o navegación entre subpáginas?
He visto equipos perder semanas peleándose con la configuración, solo para chocar contra un muro cuando cambiaba el diseño del sitio. Las mejores herramientas no solo funcionan: se adaptan, escalan y te facilitan la vida.
Los 10 mejores navegadores headless en Python para scraping moderno
Aquí tienes mi lista definitiva, con un análisis a fondo de lo que hace brillar —o tambalearse— a cada herramienta.
1. Thunderbit
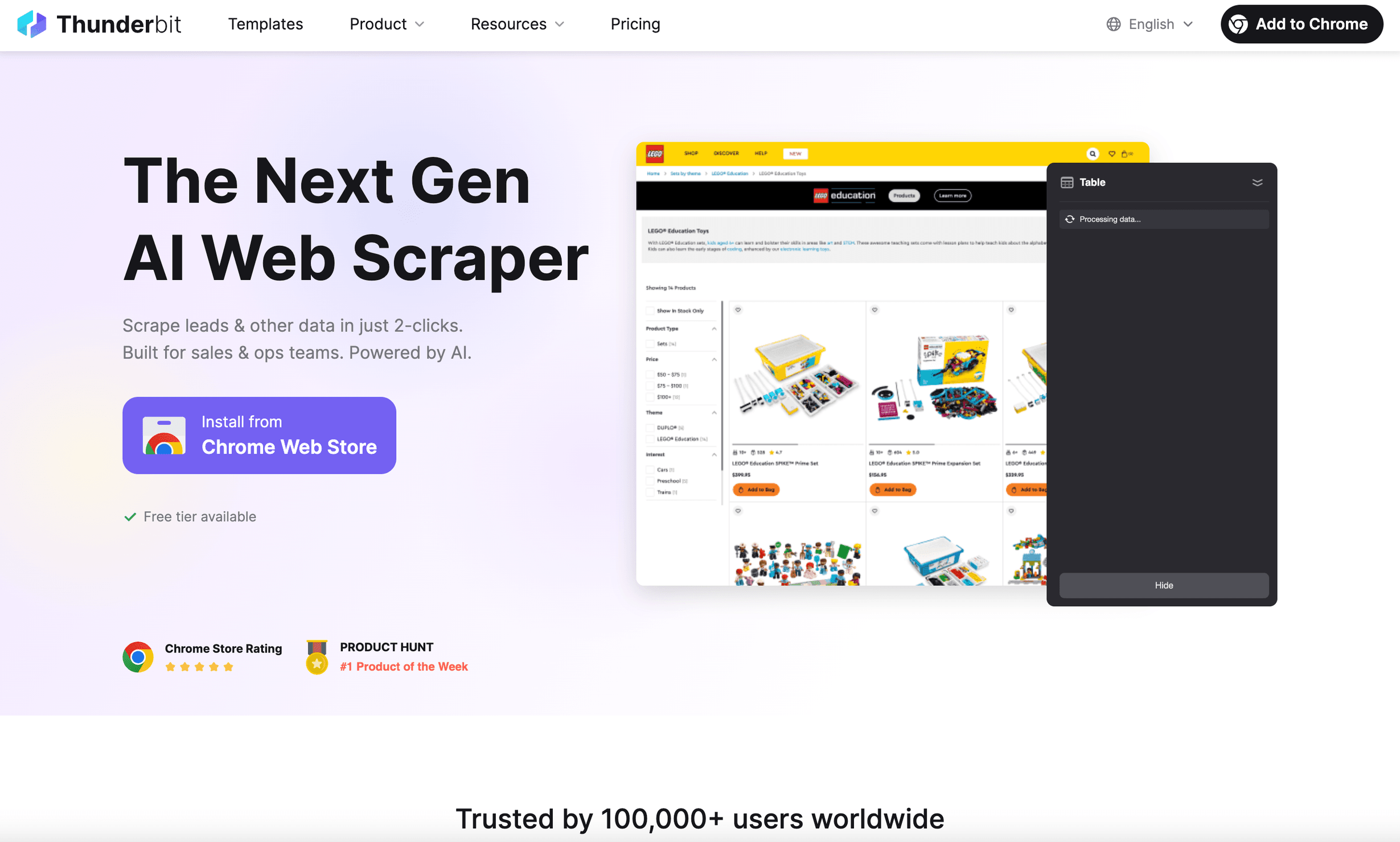 es el navegador headless en Python que ojalá hubiera tenido hace años. No es solo una herramienta de automatización de navegador: es una extensión de Chrome de Raspador Web IA creada para usuarios de negocio que buscan resultados, no dolores de cabeza.
es el navegador headless en Python que ojalá hubiera tenido hace años. No es solo una herramienta de automatización de navegador: es una extensión de Chrome de Raspador Web IA creada para usuarios de negocio que buscan resultados, no dolores de cabeza.
Por qué Thunderbit destaca:
- Sugerencia de campos con IA: Solo tienes que hacer clic en “Sugerir campos con IA” y la IA de Thunderbit leerá la página, recomendará qué datos extraer y configurará el raspador por ti ().
- Plantillas de datos instantáneas: Para sitios populares (Amazon, Zillow, LinkedIn, etc.), tienes plantillas de un clic, sin configuración.
- Scraping de subpáginas y paginación: Thunderbit puede ir subpágina por subpágina, gestionar el scroll infinito y combinar todos los datos en una sola tabla.
- Prompts en lenguaje natural: Describe lo que quieres en español sencillo; la IA de Thunderbit hace el resto.
- Scraping en la nube o en el navegador: Ejecuta extracciones de forma local o en la nube (hasta 50 páginas a la vez para ganar velocidad).
- No requiere programar: En serio: si puedes usar un navegador, puedes usar Thunderbit.
- Exportación de datos gratuita: Exporta a Excel, Google Sheets, Notion o Airtable con un solo clic.
He visto cómo Thunderbit ahorra horas a equipos de ventas y operaciones: extraen leads, supervisan precios o agregan datos de productos sin tocar una sola línea de código. Tiene la confianza de en todo el mundo, y el comentario se repite: “No puedo creer lo fácil que es”.
Ideal para: Usuarios no técnicos, equipos de negocio, cualquiera que quiera que la IA haga el trabajo pesado.
2. Selenium
 es el veterano de la automatización de navegadores. Si alguna vez has buscado en Google “python headless browser”, seguramente te has topado con Selenium WebDriver.
es el veterano de la automatización de navegadores. Si alguna vez has buscado en Google “python headless browser”, seguramente te has topado con Selenium WebDriver.
Ventajas:
- Compatible con todos los navegadores principales: Chrome, Firefox, Safari, Edge e incluso Internet Explorer (para los valientes).
- Comunidad enorme: Montones de tutoriales, plugins y respuestas en Stack Overflow.
- Muy flexible: Automatiza prácticamente todo lo que un usuario puede hacer: clics, formularios, navegación.
Desventajas:
- La configuración puede ser un dolor de cabeza: Tendrás que lidiar con drivers de navegador y mantener las versiones sincronizadas.
- Más lento que las herramientas modernas: El protocolo WebDriver añade sobrecarga, y escalar a cientos de navegadores resulta engorroso.
- API verbosa: Escribirás más código que con Playwright o Puppeteer.
Ideal para: Equipos con experiencia previa en Selenium, pruebas entre navegadores o flujos de automatización heredados.
3. Puppeteer
 es la librería de automatización de alto nivel de Google para Chrome/Chromium. Aunque es nativa de Node.js, los usuarios de Python pueden entrar en juego mediante Pyppeteer.
es la librería de automatización de alto nivel de Google para Chrome/Chromium. Aunque es nativa de Node.js, los usuarios de Python pueden entrar en juego mediante Pyppeteer.
Ventajas:
- Optimizado para Chrome: Rápido, eficiente y muy bien integrado con Chrome DevTools.
- API asíncrona: Ideal para sitios modernos con mucho JavaScript.
- Funciones completas: Capturas de pantalla, exportación a PDF, interceptación de red.
Desventajas:
- Solo Chromium: No tiene soporte para Firefox ni Safari.
- Nativo de Node.js: Los usuarios de Python deben usar Pyppeteer (que hoy ya no se mantiene; ver más abajo).
Ideal para: Desarrolladores que quieren automatización rápida y fiable en Chrome y no necesitan soporte multiplataforma.
4. Playwright
 es el nuevo talento del sector, desarrollado por Microsoft, y se ha convertido rápidamente en mi opción preferida para scraping avanzado.
es el nuevo talento del sector, desarrollado por Microsoft, y se ha convertido rápidamente en mi opción preferida para scraping avanzado.
Ventajas:
- Soporte multibrowser: Automatiza Chromium, Firefox y WebKit con una sola API.
- Espera automática: Se acabó adivinar cuándo una página está lista; Playwright espera por ti.
- Concurrencia: Ejecuta varios contextos de navegador en paralelo para una velocidad brutal.
- Pensado para Python: Enlaces nativos para Python, tanto asíncronos como síncronos.
Desventajas:
- Instalación más pesada: Incluye varios navegadores, así que la configuración es algo más pesada.
- Sigue requiriendo código: No es tan amigable para usuarios no técnicos como Thunderbit.
Ideal para: Desarrolladores que necesitan una automatización sólida y moderna, especialmente para aplicaciones web complejas y dinámicas.
5. Headless Chrome
 es el motor que impulsa muchas de las herramientas anteriores. Puedes controlarlo directamente mediante el Chrome DevTools Protocol (CDP) para lograr la máxima flexibilidad.
es el motor que impulsa muchas de las herramientas anteriores. Puedes controlarlo directamente mediante el Chrome DevTools Protocol (CDP) para lograr la máxima flexibilidad.
Ventajas:
- Compatibilidad web de vanguardia: Si funciona en Chrome, funciona en Headless Chrome.
- Control muy preciso: Accede a cada rincón del navegador.
Desventajas:
- Curva de aprendizaje pronunciada: Tendrás que hablar CDP o usar una librería envoltorio.
- Solo Chrome: No hay compatibilidad entre navegadores.
Ideal para: Expertos que construyen canalizaciones de automatización personalizadas o integran Chrome a bajo nivel.
6. Pyppeteer
 es la versión no oficial en Python de Puppeteer. Llevó la automatización asíncrona de Chrome a Python, pero... hay truco.
es la versión no oficial en Python de Puppeteer. Llevó la automatización asíncrona de Chrome a Python, pero... hay truco.
Ventajas:
- API al estilo Puppeteer: Si conoces Puppeteer, te sentirás como en casa.
- Automatización rápida en Chrome: Muy bueno para sitios dinámicos.
Desventajas:
- Sin mantenimiento: El proyecto original ya no se actualiza (los desarrolladores recomiendan pasarse a Playwright).
- Solo Chromium: No hay Firefox ni Safari.
Ideal para: Proyectos heredados que ya usan Pyppeteer. Para proyectos nuevos, usa Playwright.
7. Splash
 es un navegador headless ligero y programable con API HTTP, creado por el equipo de Scrapinghub (ahora Zyte).
es un navegador headless ligero y programable con API HTTP, creado por el equipo de Scrapinghub (ahora Zyte).
Ventajas:
- Ligero: Usa QtWebKit, así que consume menos recursos que Chrome.
- API HTTP: Puedes controlarlo desde cualquier lenguaje, no solo Python.
- Ideal para Scrapy: Se integra sin fricción con spiders de Scrapy para renderizado JavaScript.
Desventajas:
- Motor WebKit antiguo: Puede tener problemas con JavaScript de última generación.
- Requiere scripts en Lua: Para interacciones avanzadas, tendrás que aprender algo de Lua.
Ideal para: Usuarios de Scrapy que necesitan renderizado ocasional de JavaScript o tareas ligeras de renderizado del lado del servidor.
8. PhantomJS
 es el navegador headless programable original, construido sobre WebKit. Fue pionero, pero hoy está en gran medida obsoleto.
es el navegador headless programable original, construido sobre WebKit. Fue pionero, pero hoy está en gran medida obsoleto.
Ventajas:
- Scripting sencillo: Fácil de automatizar con JavaScript.
- Compatibilidad heredada: Sigue funcionando para sitios antiguos y estáticos.
Desventajas:
- Sin mantenimiento: No recibe actualizaciones desde 2016.
- Motor desfasado: No puede con sitios modernos cargados de JavaScript.
- Riesgos de seguridad: No tiene parches recientes.
Ideal para: Mantener scripts heredados. Para proyectos nuevos, migra a Playwright o Puppeteer.
9. HtmlUnit
 es un navegador headless basado en Java que simula el comportamiento del navegador. Es rápido y ligero, pero no es un motor de navegador real.
es un navegador headless basado en Java que simula el comportamiento del navegador. Es rápido y ligero, pero no es un motor de navegador real.
Ventajas:
- 100 % Java: Muy útil en entornos dominados por Java.
- Rápido para páginas estáticas: No hace falta arrancar un navegador completo.
Desventajas:
- Compatibilidad JS limitada: Tiene dificultades con sitios modernos y dinámicos.
- No es nativo de Python: Requiere capas de integración (por ejemplo, HtmlUnitDriver de Selenium).
Ideal para: Flujos basados en Java, pruebas de aplicaciones heredadas o scraping de páginas simples renderizadas en servidor.
10. TrifleJS
 es un navegador headless para Internet Explorer (IE), orientado a automatizar aplicaciones web heredadas en Windows.
es un navegador headless para Internet Explorer (IE), orientado a automatizar aplicaciones web heredadas en Windows.
Ventajas:
- Automatización de IE: Gestiona aplicaciones antiguas de intranet o sistemas que solo funcionan en IE.
- API similar a PhantomJS: Requiere cambios mínimos para scripts de PhantomJS.
Desventajas:
- Solo Windows: No hay soporte multiplataforma.
- Obsoleto: IE ya está retirado; TrifleJS es muy de nicho y rara vez recibe mantenimiento.
Ideal para: Flujos de trabajo heredados muy específicos donde todavía hace falta automatizar IE.
Tabla comparativa de funciones: navegadores headless en Python de un vistazo
| Herramienta | Compatibilidad con navegadores | Rendimiento y escala | Facilidad de uso | Funciones de IA/sin código | Comunidad y soporte | Ideal para |
|---|---|---|---|---|---|---|
| Thunderbit | Chrome (extensión/nube) | Alto (paralelismo en la nube) | El más fácil: sin código | Sí (IA, plantillas) | En crecimiento, activa | No programadores, ventas/operaciones, extracción rápida de datos |
| Selenium | Todos los navegadores principales | Moderado | Moderada (configuración) | No | Enorme, madura | Multibrowser, legado, automatización de pruebas |
| Puppeteer | Chromium/Chrome | Muy alto | Alta (para desarrolladores) | No | Amplia (Node.js) | Solo Chrome, desarrolladores, automatización rápida |
| Playwright | Chromium, Firefox, WebKit | Muy alto (multicontexto) | Alta (para desarrolladores) | No | Creciendo rápidamente | Scraping avanzado, multibrowser, moderno |
| Headless Chrome | Chrome/Edge | Muy alto | Baja (CDP manual) | No | N/D (base) | Personalizado, experto, control de bajo nivel |
| Pyppeteer | Chromium/Chrome | Alto | Moderada (asíncrono) | No | Pequeña, sin mantenimiento | Scripts heredados de Pyppeteer |
| Splash | QtWebKit | Moderado | Moderada (API/Lua) | No | De nicho (Scrapy/Zyte) | Usuarios de Scrapy, renderizado ligero de JS |
| PhantomJS | WebKit (antiguo) | Bajo (ya obsoleto) | Moderada (JS) | No | Desaparecida | Solo legado |
| HtmlUnit | Simulado (Java) | Moderado/alto (estático) | Baja (Java) | No | Pequeña, centrada en Java | Flujos de Java, páginas simples/estáticas |
| TrifleJS | Internet Explorer (Trident) | Bajo/Moderado | Moderada (JS, Win) | No | Muy pequeña, heredada | Automatización heredada solo para IE |
Cómo elegir el navegador headless en Python adecuado para tu negocio
Aquí tienes mi chuleta para elegir la herramienta adecuada:
- ¿Necesitas scraping rápido, sin código y con ayuda de IA? Elige . Es la forma más sencilla para que quienes no programan obtengan datos fiables, especialmente para equipos de ventas, ecommerce o investigación.
- ¿Quieres el máximo control y compatibilidad entre navegadores? es tu mejor opción. Es robusto, moderno y está pensado para escalar.
- ¿Ya invertiste en Selenium? Quédate con : sigue siendo el rey para flujos heredados y multiplataforma.
- ¿Construyes automatización solo para Chrome como desarrollador? (o Playwright) es rápido y potente.
- ¿Vas a scrapear páginas simples y estáticas en un entorno Java? es ligero y fácil de integrar.
- ¿Mantienes scripts heredados o aplicaciones solo para IE? y son tus amigos de último recurso.
Y recuerda: la mejor herramienta es la que encaja con tu flujo de trabajo, las habilidades de tu equipo y las necesidades de tu negocio. A veces eso significa combinar varias: usar Thunderbit para tareas rápidas, Playwright para el trabajo pesado y Selenium para sistemas heredados.
Preguntas frecuentes
1. ¿Qué es un navegador headless en Python y por qué lo necesito para hacer scraping?
Un navegador headless en Python es un navegador web que controlas con código Python, pero que se ejecuta de forma invisible (sin interfaz gráfica). Es esencial para scrapear sitios modernos con mucho JavaScript porque puede ejecutar scripts, gestionar interacciones de usuario y extraer contenido completamente renderizado, algo que los scrapers HTML tradicionales no pueden hacer.
2. ¿Cuál es el mejor navegador headless en Python para usuarios no técnicos?
es la mejor opción para quienes no programan. Usa IA para automatizar la configuración, ofrece plantillas instantáneas y te permite extraer datos en solo un par de clics, sin necesidad de programar.
3. ¿En qué se diferencian Playwright y Puppeteer para usuarios de Python?
Playwright admite varios navegadores (Chromium, Firefox y WebKit) y cuenta con enlaces sólidos para Python, lo que lo hace ideal para automatización avanzada. Puppeteer solo funciona con Chrome y es nativo de Node.js, aunque los usuarios de Python pueden usar Pyppeteer (aunque ya no se mantiene). Para proyectos nuevos en Python, Playwright es la mejor opción.
4. ¿Sigue siendo relevante Selenium para el scraping web moderno?
Sí: Selenium sigue usándose mucho, especialmente para pruebas entre navegadores y automatización heredada. Sin embargo, es más lento y más complejo de configurar que herramientas más nuevas como Playwright o Thunderbit, y resulta menos eficiente para scraping a gran escala.
5. ¿Cuándo debería usar herramientas heredadas como PhantomJS, HtmlUnit o TrifleJS?
Solo para mantener o migrar flujos de trabajo antiguos. PhantomJS y TrifleJS están obsoletos, y HtmlUnit es mejor para entornos Java con páginas sencillas. Para proyectos nuevos, conviene usar herramientas modernas y activamente mantenidas.
Si ya quieres ver cómo es el scraping moderno impulsado por IA, . Y para más análisis en profundidad sobre automatización web, visita el . ¡Feliz scraping! Que tus datos estén siempre frescos y tus navegadores sean eternamente headless.
Saber más