

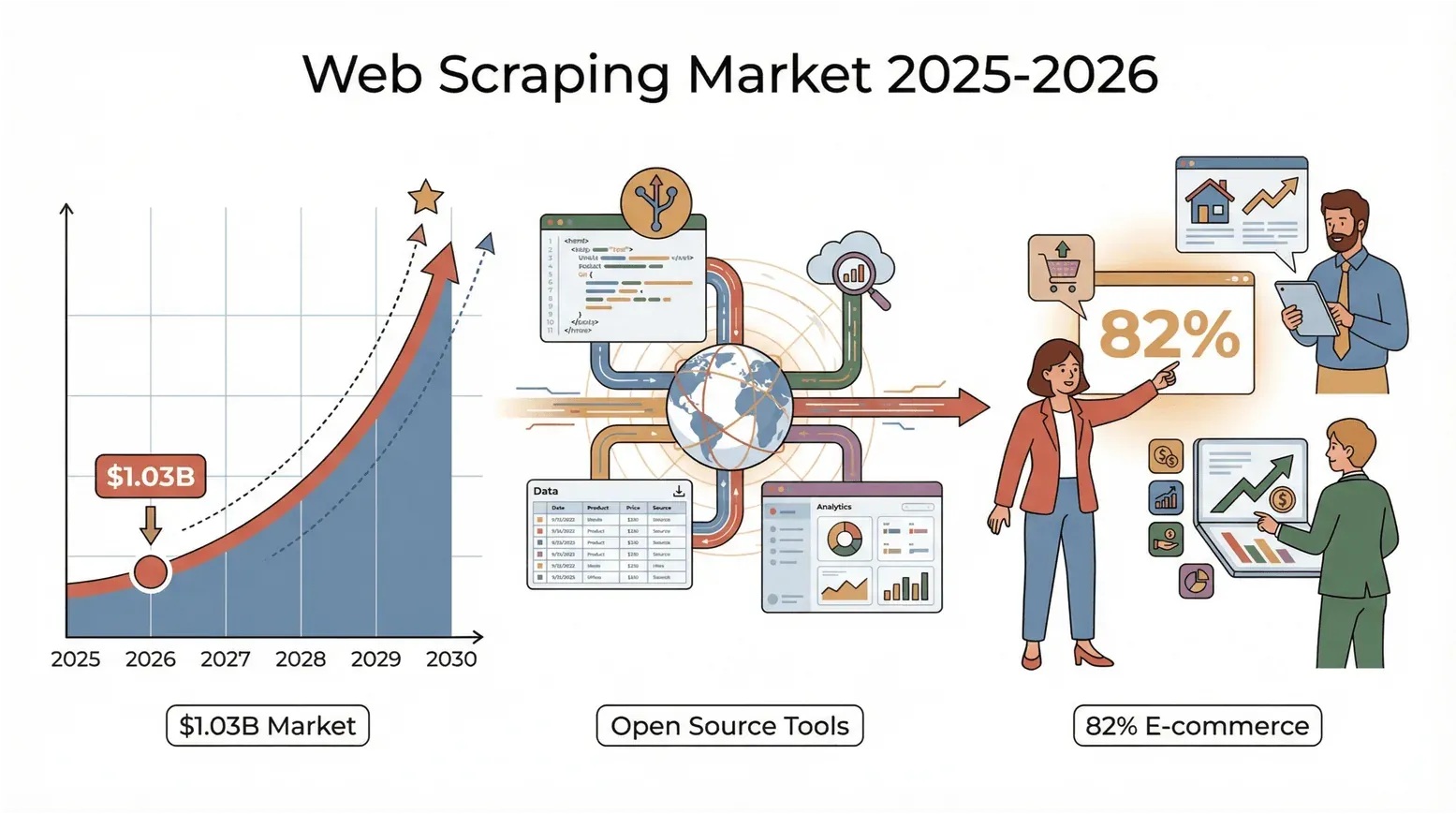
La web rebosa datos y, en 2026, la carrera por convertir ese caos en conocimiento es más intensa que nunca. Tanto si trabajas en ventas, e-commerce o bienes raíces, como si simplemente eres un fanático de los datos como yo, seguro que ya has comprobado que el viejo método de “copiar y pegar” se quedó corto hace tiempo. Aquí va un dato impactante: el mercado global de scraping web alcanzó 1,03 mil millones de dólares en 2025, según Mordor Intelligence (citado en el informe sobre el estado del web scraping 2026 de PromptCloud), y apunta a duplicarse casi por completo para 2030.
Y no son solo los gigantes tecnológicos: el 82 % de las empresas de e-commerce y más de un tercio de las firmas de inversión usan scraping web para conseguir leads, precios e investigación de mercado (Browsercat). La conclusión es clara: si no estás usando una herramienta de scraping web, probablemente estás dejando dinero —e ideas valiosas— sobre la mesa.
Pero aquí viene la buena noticia: las herramientas de código abierto para scraping web son más potentes, accesibles y impulsadas por la comunidad que nunca. Tanto si eres un experto en Python, un fanático de JavaScript o un usuario de negocio que solo quiere datos sin complicaciones, hay una herramienta para ti. Llevo años trabajando en SaaS y automatización, y he visto cómo ha evolucionado este ecosistema. Así que vamos a ver las 5 mejores herramientas de código abierto para scraping web que deberías explorar en 2026, además de cómo elegir la más adecuada para tus necesidades.
¿Por qué elegir herramientas de código abierto para scraping web?
Qué es el data scraping y cómo hacerlo en 2026 Get Started Free
Las herramientas de código abierto para scraping web son las navajas suizas del mundo de los datos. Son rentables (sin licencias), flexibles (puedes personalizarlo todo) y transparentes (puedes ver exactamente cómo funcionan). ¿La verdadera ventaja? La comunidad. Las herramientas de código abierto cuentan con el apoyo de miles de desarrolladores y usuarios que comparten complementos, tutoriales y correcciones, así que nunca te quedas solo (Oreate AI).
Frente a las herramientas comerciales, las opciones de código abierto te ponen al mando. No quedas atado a la hoja de ruta ni a los precios de un proveedor, y puedes adaptar tus scrapers a medida que cambian los sitios web. Además, muchos servicios comerciales de scraping se construyen, en realidad, sobre estos mismos motores de código abierto. Entonces, ¿por qué no ir directamente a la fuente?
Cómo seleccionamos las mejores herramientas de código abierto para scraping web
Con tantas opciones disponibles, me centré en algunos criterios clave:
- Facilidad de uso: ¿Pueden empezar rápido quienes no programan? ¿Hay opciones visuales o impulsadas por IA?
- Escalabilidad: ¿La herramienta puede manejar proyectos grandes o solo tareas puntuales?
- Compatibilidad con lenguajes y plataformas: Python, JavaScript, navegador, escritorio: algo para cada stack.
- Comunidad y mantenimiento: ¿La herramienta se actualiza activamente? ¿Hay foros, documentación y complementos?
- Funciones únicas: detección de campos con IA, scraping de subpáginas, programación, soporte en la nube y más.
También tuve en cuenta opiniones reales y casos de uso empresarial, porque la mejor herramienta es la que de verdad resuelve tu problema.
Las 5 mejores herramientas de código abierto para scraping web que debes explorar
Vamos con lo importante. Aquí va mi selección, desde la simplicidad impulsada por IA hasta auténticas potencias para desarrolladores.
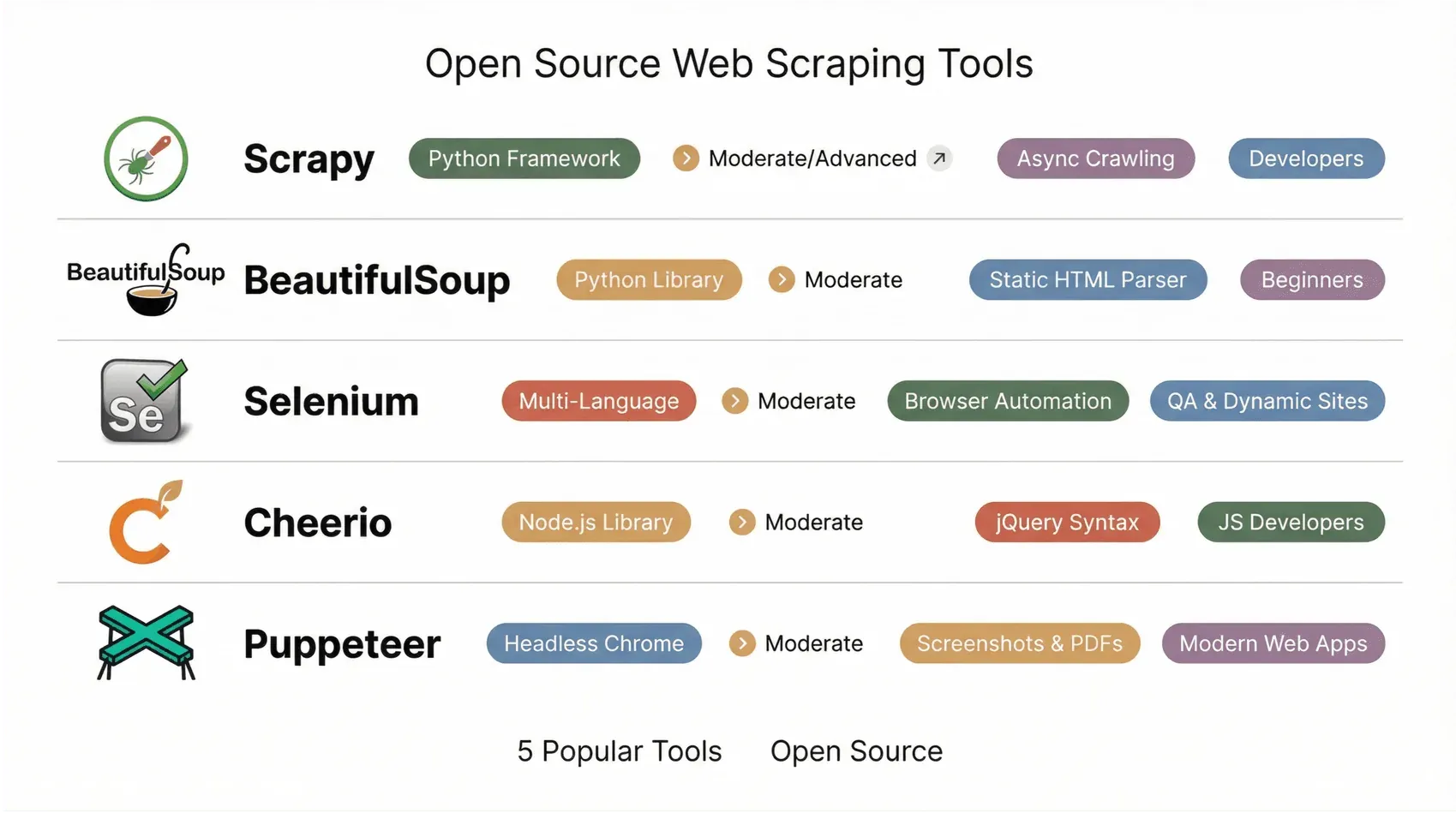
1. Scrapy
Scrapy es el sueño de cualquier desarrollador de Python. Es un framework de probada eficacia para crear crawlers y pipelines de datos escalables y personalizables. Tú defines “spiders” en Python y Scrapy se encarga de la cola, la limitación de velocidad y la exportación a JSON, CSV o XML. Desde la versión 2.14 (oct. de 2025) y el parche 2.14.1 (ene. de 2026), gran parte de la lógica interna basada en Twisted Deferred de Scrapy se reescribió como corutinas nativas de asyncio, con un nuevo punto de entrada AsyncCrawlerProcess que encaja mejor con el ecosistema moderno de Python asíncrono; ahora el reactor de asyncio es el predeterminado para los nuevos proyectos generados. Ojo: Scrapy 2.14+ requiere Python 3.10 o posterior.
El ecosistema de complementos es enorme, con middleware para proxies, cookies e incluso integración con navegadores sin interfaz para sitios dinámicos. Scrapy es el framework al que recurre la mayoría de los equipos cuando necesita rastrear catálogos completos de e-commerce o recopilar noticias a gran escala. La curva de aprendizaje es pronunciada para quienes no programan, pero si buscas potencia y flexibilidad, Scrapy cumple (Octoparse).
2. Beautiful Soup
Beautiful Soup es la biblioteca clásica de Python para analizar HTML de forma rápida y sin complicaciones. Tanto principiantes como expertos la valoran por su curva de aprendizaje amable y su parser tolerante (puede manejar incluso el HTML más desordenado). Haces una solicitud a una página (normalmente con requests), la cargas en Beautiful Soup y usas métodos sencillos para encontrar y extraer elementos.
Es perfecta para proyectos pequeños, prototipos y uso educativo. ¿La pega? Beautiful Soup no puede ejecutar JavaScript, así que solo funciona con HTML estático. Para sitios dinámicos, tendrás que combinarla con algo como Selenium o requests_html (ProsperaSoft).
3. Selenium
Selenium es la herramienta original de automatización de navegadores. Nació para pruebas, pero se ha convertido en una favorita para hacer scraping de sitios dinámicos y cargados de JavaScript. Selenium abre un navegador real (Chrome, Firefox, etc.) y simula acciones de usuario: clics, desplazamientos, inicios de sesión, lo que necesites. Si una persona puede verlo, Selenium puede extraerlo.
Es compatible con varios lenguajes (Python, Java, JS, C#) y va muy bien para hacer scraping detrás de inicios de sesión o flujos interactivos. Selenium 4 también ha ido integrando WebDriver BiDi, un protocolo bidireccional que permite que tu script se suscriba a eventos del navegador (peticiones de red, logs de consola, mutaciones del DOM) e intercepte llamadas de red, funciones que antes hacían que Puppeteer o Playwright fueran la opción más sencilla para scraping. Las versiones 4.40 (enero de 2026) y 4.41 (febrero de 2026) ampliaron el soporte de BiDi en Python, Java, .NET y Ruby. Siguen existiendo desventajas: Selenium es más lento y pesado que los scrapers HTTP puros, y gestionar los drivers del navegador sigue siendo engorroso. Pero para sitios complicados —y para equipos que ya usan Selenium como estándar en automatización de pruebas— sigue siendo una opción de scraping sólida en 2026 (ScrapeHero).
4. Cheerio
Cheerio es el jQuery del mundo de Node.js. Te permite analizar HTML en el servidor con una sintaxis familiar, muy parecida a jQuery. Es rapidísimo y perfecto para páginas estáticas: solo tienes que obtener el HTML (con Axios o Fetch), cargarlo en Cheerio y usar selectores para sacar lo que necesitas.
Cheerio no ejecuta JavaScript, así que es mejor para contenido estático. Pero se integra de maravilla con otras herramientas de Node.js y es una favorita entre los desarrolladores que quieren mantener todo en JavaScript (Cheerio Docs).
5. Puppeteer
Puppeteer es una biblioteca de Node.js para controlar Chrome o Chromium en modo sin interfaz. Es una opción muy popular para hacer scraping de aplicaciones web modernas y aplicaciones de una sola página que necesitan renderizado real del navegador: capturas de pantalla, generación de PDF e interceptación de red, todo con una API limpia de async/await. El equipo de Chrome en Google sigue manteniendo Puppeteer y lo mantiene alineado con cada nueva versión de Chrome y cada actualización del DevTools Protocol.
Un poco de contexto útil para 2026: el ritmo de lanzamientos de Puppeteer se ha centrado más en la compatibilidad con Chrome y en actualizaciones de dependencias que en nuevas capacidades, y el equipo original que construyó sus funciones más ambiciosas terminó creando Playwright en Microsoft. Si ya apostaste por Puppeteer y solo necesitas automatización de Chrome, sigue siendo una opción estable. Si empiezas desde cero y quieres soporte multiplataforma, un test runner integrado, localizadores con autoespera y un visor de trazas, la mayoría de los equipos en 2026 se inclina primero por Playwright (Firecrawl — Playwright vs Puppeteer, Autonoma — Playwright vs Puppeteer 2026).
Prueba gratis AI Web Scraper de Thunderbit
Tabla comparativa rápida: las mejores herramientas de código abierto para scraping web
| Herramienta | Facilidad de uso | Plataforma/Lenguaje | Contenido dinámico | Ideal para | Fortalezas únicas |
|---|---|---|---|---|---|
| Scrapy | Moderada/avanzada (código) | Framework de Python | Parcial | Desarrolladores, científicos de datos | Rastreo asíncrono, complementos, comunidad enorme |
| BeautifulSoup | Moderada (código simple) | Biblioteca de Python | No | Principiantes, análisis rápido | Parser tolerante, excelente para HTML estático |
| Selenium | Moderada (scripting) | Multilenguaje | Sí | QA, scraping de sitios dinámicos | Automatización real del navegador, maneja inicios de sesión y eventos de usuario |
| Cheerio | Moderada (código JS) | Biblioteca de Node.js | No | Desarrolladores JS, páginas estáticas | Sintaxis jQuery, análisis HTML rápido |
| Puppeteer | Moderada (código JS) | Node.js (Chrome sin interfaz) | Sí | Desarrolladores, apps web modernas | Capturas de pantalla, PDF, scraping de SPA, API async/await |
Cómo elegir la herramienta de código abierto para scraping web adecuada para ti
Cómo extraer datos de cualquier sitio web usando IA Get Started Free
Aquí tienes mi guía rápida para elegir la herramienta adecuada:
- Nivel técnico: ¿No programas? Empieza con Thunderbit, Octoparse, ParseHub o WebHarvy. ¿Eres desarrollador? Scrapy, Cheerio, Puppeteer o Apify.
- Escala del proyecto: ¿Tareas puntuales o pequeñas? Beautiful Soup, Cheerio, WebHarvy. ¿A gran escala o continuas? Scrapy, Apify, Thunderbit (con programación).
- Tipo de datos: ¿HTML estático? Usa Cheerio, Beautiful Soup o WebHarvy. ¿Dinámico o con mucho JavaScript? Puppeteer, Selenium, Thunderbit, Octoparse.
- Integración: ¿Necesitas exportar a Sheets, Notion o bases de datos? Thunderbit y Octoparse lo facilitan. ¿Necesitas APIs o pipelines personalizados? Scrapy y Apify son tus aliados.
- Comunidad y soporte: Busca foros activos, actualizaciones recientes y muchos tutoriales. Scrapy, Cheerio y Selenium tienen comunidades enormes; Thunderbit y Octoparse tienen bases de usuarios en crecimiento y muchas guías.
Prueba un par de herramientas en un proyecto pequeño y comprueba cuál encaja con tu flujo de trabajo y tu nivel de comodidad. Y no tengas miedo de combinar herramientas: a veces la solución más rápida es hacer un scraping rápido con una herramienta visual y luego un rastreo más profundo con un framework basado en código.
El valor de la comunidad y el soporte continuo en el scraping de código abierto
Una de las mayores ventajas del código abierto es la comunidad. Los foros activos, los repositorios de GitHub y las etiquetas de Stack Overflow significan que nunca estás solo. Si te atascas, lo más probable es que alguien ya haya resuelto el problema o te ayude a resolverlo. Las herramientas impulsadas por la comunidad reciben actualizaciones frecuentes y nuevas funciones, y encontrarás montones de tutoriales, complementos y buenas prácticas (Oreate AI).
Por eso, para herramientas visuales como Thunderbit y Octoparse, los foros de usuarios y el intercambio de plantillas son una mina de oro. Para herramientas para desarrolladores, las incidencias en GitHub y los grupos de Discord/Slack son donde ocurre la magia. Cuando eliges una herramienta de código abierto, te unes a una red global de personas que resuelven problemas, y eso no tiene precio.
Thunderbit:Una solución de scraping web sin código más fácil para todos
Sí, el código abierto está muy bien, pero a veces no quieres construir, ajustar y mantener un scraper solo para obtener datos útiles. Y no todos los problemas de scraping se resuelven con código abierto, y ahí es donde Thunderbit encaja perfectamente. Si has llegado hasta aquí pensando: “Estas herramientas son potentes, pero yo solo quiero los datos sin construir ni mantener scrapers”, Thunderbit es el siguiente paso natural.
Thunderbit es una extensión de Chrome impulsada por IA diseñada para usuarios de negocio a quienes les importan más los resultados que la infraestructura. En lugar de escribir selectores o scripts, empiezas haciendo clic en Sugerir campos con IA. La IA entiende la estructura de la página, propone columnas y haces el scraping con un segundo clic. La paginación, las subpáginas y los flujos de lista a detalle quedan resueltos por ti.
Una de las mayores fortalezas de Thunderbit es cómo conecta la intención humana con los datos estructurados. Puedes describir lo que quieres en lenguaje natural —por ejemplo, “recopila nombres de productos, precios y valoraciones”— y Thunderbit lo convierte en una tabla limpia. El scraping de subpáginas facilita extraer datos más completos visitando automáticamente las páginas de detalle. Las exportaciones a Excel, Google Sheets, Notion y Airtable vienen integradas, así que tus datos quedan listos para usar de inmediato.
Thunderbit es especialmente popular entre equipos de ventas, marketing, e-commerce y bienes raíces que necesitan datos fiables pero no quieren mantener pipelines de código abierto. Admite decenas de idiomas, funciona muy bien en sitios dinámicos y ofrece un plan gratuito generoso para empezar. Aunque no es de código abierto, complementa muy bien las herramientas open source: piénsalo como la forma más rápida de validar ideas o gestionar scrapes empresariales recurrentes sin sobrecarga de ingeniería.
Conclusión: desbloquear los datos de la web con las mejores herramientas de código abierto
El scraping web ya no es solo para programadores o grandes empresas. Con las herramientas de código abierto de hoy, cualquiera puede convertir la web en datos estructurados y accionables, ya sea para crear una lista de leads, monitorizar precios o impulsar tu próximo proyecto de IA. La clave está en alinear la herramienta con tus necesidades: herramientas visuales y con IA para velocidad y simplicidad; frameworks de código para potencia y escala.
Entonces, ¿qué sigue? Elige una herramienta de esta lista, pruébala en una tarea real y comprueba cuánto tiempo y esfuerzo te ahorras. Y si quieres una victoria rápida, descarga Thunderbit y descubre lo fácil que puede ser el scraping web. El mundo digital es tuyo: ve a por esas perlas de datos.
Para más análisis profundos y tutoriales, visita el blog de Thunderbit. ¡Feliz scraping!
Prueba gratis AI Web Scraper de Thunderbit Get Started Free
Preguntas frecuentes
1. ¿Cuál es la principal ventaja de las herramientas de código abierto para scraping web frente a las comerciales?
Las herramientas de código abierto son rentables, flexibles y cuentan con comunidades activas. Puedes personalizarlas, evitar el bloqueo con un proveedor y beneficiarte del conocimiento compartido y de actualizaciones frecuentes.
2. ¿Qué herramienta de código abierto es mejor para usuarios de negocio sin perfil técnico?
Thunderbit, Octoparse, ParseHub y WebHarvy son excelentes para quienes no programan. Thunderbit destaca por su flujo guiado por IA, de dos clics, y sus opciones de exportación directa.
3. ¿Las herramientas de código abierto pueden manejar sitios web dinámicos y con mucho JavaScript?
¡Sí! Herramientas como Thunderbit, Selenium, Puppeteer, Octoparse y ParseHub pueden extraer contenido dinámico renderizando las páginas en un navegador real o sin interfaz.
4. ¿Cómo sé si una herramienta se mantiene y se da soporte activamente?
Revisa GitHub para ver commits recientes, incidencias abiertas y actividad de colaboradores. Busca foros activos, publicaciones recientes en el blog y muchos complementos o plantillas aportados por usuarios.
5. ¿Cuál es la mejor forma de empezar con el scraping web si soy principiante?
Empieza con una herramienta visual o impulsada por IA como Thunderbit u Octoparse. Prueba a extraer un conjunto de datos pequeño, expórtalo a Excel o Sheets y experimenta. A medida que te sientas más cómodo, puedes explorar herramientas basadas en código para proyectos más avanzados.
¿Quieres ver Thunderbit en acción? Descarga la extensión de Chrome y únete a más de 30.000 usuarios que convierten la web en datos, sin necesidad de programar.
Saber más
- 7 herramientas de scraping web más populares para usar en 2026
- Las 5 mejores herramientas de software para extraer datos web en 2026
- Las 6 herramientas esenciales de scraping web para triunfar en 2025
- Las mejores herramientas y software para scraping web en 2025
- Las 17 mejores herramientas para extraer datos de sitios web en 2025




