

Enlaces rotos. Páginas huérfanas. Una página de “prueba” de 2019 que, por alguna razón, Google indexó. Si gestionas un sitio web, seguro conoces ese dolor.
Un buen crawler detecta todo eso —y además te muestra el mapa completo de tu sitio para que realmente puedas corregir los problemas. Pero mucha gente confunde “web crawler” con “web scraper”. No son lo mismo.
Probé 10 crawlers gratuitos en sitios reales. Algunos son excelentes para auditorías SEO. Otros funcionan mejor para extraer datos. Aquí te cuento cuáles sí valieron la pena —y cuáles no.
¿Qué es un crawler de sitios web? Conceptos básicos
Aclaremos algo primero: un website crawler no es lo mismo que un web scraper. Sí, los términos se usan como si fueran intercambiables, pero en realidad cumplen funciones distintas. Piensa en un crawler como el cartógrafo de tu sitio: recorre cada rincón, sigue todos los enlaces y construye un mapa de todas tus páginas. Su trabajo es descubrir URLs, entender la estructura del sitio e indexar contenido. Eso es justamente lo que hacen motores de búsqueda como Google con sus bots, y también lo que usan muchas herramientas SEO para revisar la salud de un sitio (Thunderbit Blog: What Is a Web Crawler?).
Un web scraper, en cambio, se dedica a extraer datos. No le interesa el mapa completo; solo quiere sacar la información valiosa: precios de productos, nombres de empresas, reseñas, correos electrónicos, lo que sea. Los scrapers extraen campos concretos de las páginas que los crawlers encuentran (Thunderbit Blog: How to Web Crawl a Site?).
Una analogía rápida:
- Crawler: La persona que recorre todos los pasillos de un supermercado y hace inventario de todos los productos.
- Scraper: La persona que va directo a la estantería del café y anota el precio de cada mezcla orgánica.
¿Por qué importa esto? Porque si lo que quieres es encontrar todas las páginas de tu sitio (por ejemplo, para una auditoría SEO), necesitas un crawler. Si quieres extraer todos los precios de productos de la web de tu competencia, necesitas un scraper —o, idealmente, una herramienta que haga ambas cosas.
¿Por qué usar un crawler web online? Beneficios clave para el negocio
Entonces, ¿por qué vale la pena usar un crawler? Porque la web no deja de crecer. De hecho, más del 54% de las marcas empresariales usan plataformas de crawling dedicadas para optimizar sus sitios, y algunas herramientas SEO rastrean 7 mil millones de páginas al día.
Esto es lo que los crawlers pueden hacer por ti:
- Auditorías SEO: detectan enlaces rotos, títulos faltantes, contenido duplicado, páginas huérfanas y más (SEO.ai).
- Revisión de enlaces y QA: encuentran errores 404 y bucles de redirección antes de que tus usuarios los vean (Screaming Frog).
- Generación de sitemaps: crean automáticamente sitemaps XML para buscadores y planificación (PowerMapper).
- Inventario de contenido: construyen un listado de todas tus páginas, su jerarquía y sus metadatos.
- Cumplimiento y accesibilidad: revisan cada página para comprobar WCAG, SEO y requisitos legales (SiteOne Crawler).
- Rendimiento y seguridad: señalan páginas lentas, imágenes demasiado pesadas o problemas de seguridad (SiteOne Crawler).
- Datos para IA y análisis: alimentan herramientas analíticas o de IA con datos rastreados (Thunderbit Blog: Crawl4AI Review).
Aquí tienes una tabla rápida con casos de uso y perfiles de negocio:
| Caso de uso | Ideal para | Beneficio / resultado |
|---|---|---|
| SEO y auditoría del sitio | Marketing, SEO, dueños de pequeños negocios | Detectar problemas técnicos, optimizar la estructura, mejorar el posicionamiento |
| Inventario de contenido y QA | Gestores de contenido, webmasters | Auditar o migrar contenido, detectar enlaces/imágenes rotos |
| Generación de leads (scraping) | Ventas, desarrollo de negocio | Automatizar prospección y alimentar el CRM con leads nuevos |
| Inteligencia competitiva | E-commerce, product managers | Seguir precios de la competencia, nuevos productos y cambios de stock |
| Clonado de sitemap y estructura | Desarrolladores, DevOps, consultores | Replicar la estructura del sitio para rediseños o copias de seguridad |
| Agregación de contenido | Investigadores, medios, analistas | Reunir datos de varios sitios para análisis o seguimiento de tendencias |
| Investigación de mercado | Analistas, equipos de entrenamiento de IA | Recopilar grandes conjuntos de datos para análisis o entrenamiento de modelos de IA |
(Thunderbit Blog: How to Web Crawl a Site?)
Cómo elegimos las mejores herramientas gratuitas de crawling web
He pasado bastantes noches en vela (y he bebido más café del que me gustaría admitir) revisando herramientas de crawling, leyendo documentación y ejecutando pruebas. Esto es lo que tenía en cuenta:
- Capacidad técnica: ¿puede con sitios modernos (JavaScript, accesos, contenido dinámico)?
- Facilidad de uso: ¿es amigable para usuarios no técnicos o exige dominar la línea de comandos?
- Límites del plan gratuito: ¿es realmente gratis o solo una versión de prueba?
- Acceso online: ¿es una herramienta en la nube, una app de escritorio o una librería de código?
- Funciones únicas: ¿ofrece algo especial, como extracción con IA, sitemaps visuales o crawling basado en eventos?
Probé cada herramienta, revisé opiniones de usuarios y comparé funciones una por una. Si una herramienta me hacía querer lanzar el portátil por la ventana, no entraba en la lista.
Tabla comparativa rápida: 10 mejores crawlers web gratuitos
| Herramienta y tipo | Funciones principales | Mejor caso de uso | Requisitos técnicos | Detalles del plan gratuito |
|---|---|---|---|---|
| BrightData (Cloud/API) | Crawling empresarial, proxies, renderizado JS, resolución de CAPTCHA | Recolección de datos a gran escala | Conviene algo de experiencia técnica | Prueba gratis: 3 scrapers, 100 registros cada uno (unos 300 en total) |
| Crawlbase (Cloud/API) | Crawling vía API, anti-bot, proxies, renderizado JS | Desarrolladores que necesitan infraestructura de crawling backend | Integración con API | Gratis: ~5.000 llamadas API durante 7 días, después 1.000/mes |
| ScraperAPI (Cloud/API) | Rotación de proxies, renderizado JS, crawling asíncrono, endpoints preconstruidos | Desarrolladores, monitorización de precios, datos SEO | Configuración mínima | Gratis: 5.000 llamadas API durante 7 días, después 1.000/mes |
| Diffbot Crawlbot (Cloud) | Crawling + extracción con IA, knowledge graph, renderizado JS | Datos estructurados a gran escala, IA/ML | Integración con API | Gratis: 10.000 créditos/mes (aprox. 10.000 páginas) |
| Screaming Frog (Desktop) | Auditoría SEO, análisis de enlaces/metadatos, sitemap, extracción personalizada | Auditorías SEO, gestores de sitios | App de escritorio, interfaz gráfica | Gratis: 500 URLs por rastreo, solo funciones básicas |
| SiteOne Crawler (Desktop) | SEO, rendimiento, accesibilidad, seguridad, exportación offline, Markdown | Desarrolladores, QA, migración, documentación | Escritorio/CLI, interfaz gráfica | Gratis y open source, 1.000 URLs en el informe GUI (configurable) |
| Crawljax (Java, OpenSrc) | Crawling basado en eventos para sitios con mucho JS, exportación estática | Desarrolladores, QA para apps web dinámicas | Java, CLI/configuración | Gratis y open source, sin límites |
| Apache Nutch (Java, OpenSrc) | Distribuido, basado en plugins, integración con Hadoop, búsqueda personalizada | Motores de búsqueda personalizados, crawling a gran escala | Java, línea de comandos | Gratis y open source, solo coste de infraestructura |
| YaCy (Java, OpenSrc) | Crawling y búsqueda peer-to-peer, privacidad, indexación web/intranet | Búsqueda privada, descentralización | Java, interfaz en navegador | Gratis y open source, sin límites |
| PowerMapper (Desktop/SaaS) | Sitemaps visuales, accesibilidad, QA, compatibilidad con navegadores | Agencias, QA, mapeo visual | GUI, fácil de usar | Prueba gratis: 30 días, 100 páginas (desktop) o 10 páginas (online) por análisis |
BrightData: crawler web en la nube de nivel empresarial

BrightData es el “tanque pesado” del crawling web. Es una plataforma en la nube con una red masiva de proxies, renderizado JavaScript, resolución de CAPTCHA y un IDE para crawls personalizados. Si trabajas con recolección de datos a gran escala —por ejemplo, monitorizando cientos de tiendas online para seguir precios—, su infraestructura es difícil de superar (aimultiple.com).
Puntos fuertes:
- Gestiona sitios complejos con protección anti-bot
- Escalable para necesidades empresariales
- Plantillas preconstruidas para sitios comunes
Limitaciones:
- No tiene un nivel gratuito permanente (solo prueba: 3 scrapers, 100 registros cada uno)
- Puede ser excesivo para auditorías sencillas
- Tiene cierta curva de aprendizaje para usuarios no técnicos
Si necesitas rastrear la web a gran escala, BrightData es como alquilar un coche de Fórmula 1. Solo no esperes que siga siendo gratis después de la prueba (BrightData Pricing).
Crawlbase: crawler web gratuito orientado a API para desarrolladores

Crawlbase (antes ProxyCrawl) está centrado en el crawling programático. Le envías una URL mediante su API y te devuelve el HTML, mientras gestiona proxies, geolocalización y CAPTCHAs por detrás (Capterra).
Puntos fuertes:
- Tasa de éxito muy alta (99%+)
- Compatible con sitios con mucho JavaScript
- Muy útil para integrarlo en tus propias apps o flujos de trabajo
Limitaciones:
- Requiere integrar API o SDK
- Plan gratuito: ~5.000 llamadas API durante 7 días, después 1.000/mes
Si eres desarrollador y quieres hacer crawling —y quizá scraping— a gran escala sin tener que gestionar proxies, Crawlbase es una opción sólida (Crawlbase Pricing).
ScraperAPI: simplifica el crawling web dinámico

ScraperAPI es la API de “búscamelo tú”. Le das una URL, se encarga de proxies, navegadores sin interfaz y medidas anti-bot, y te devuelve el HTML (o datos estructurados en algunos sitios). Es especialmente útil para páginas dinámicas y ofrece un plan gratuito bastante generoso (ScraperAPI Pricing).
Puntos fuertes:
- Muy fácil para desarrolladores (solo una llamada API)
- Maneja CAPTCHAs, bloqueos por IP y JavaScript
- Gratis: 5.000 llamadas API durante 7 días, después 1.000/mes
Limitaciones:
- No ofrece informes visuales de crawl
- Si quieres seguir enlaces, tendrás que programar la lógica de rastreo
Si quieres integrar crawling web en tu código en cuestión de minutos, ScraperAPI es una apuesta segura.
Diffbot Crawlbot: descubrimiento automatizado de la estructura de un sitio

Diffbot Crawlbot es donde las cosas se ponen inteligentes. No solo rastrea: usa IA para clasificar páginas y extraer datos estructurados (artículos, productos, eventos, etc.) en JSON. Es como tener un becario robot que realmente entiende lo que lee (Diffbot Free Plan).
Puntos fuertes:
- Extracción con IA, no solo crawling
- Compatible con JavaScript y contenido dinámico
- Gratis: 10.000 créditos/mes (unas 10.000 páginas)
Limitaciones:
- Enfocado a desarrolladores (integración por API)
- No es una herramienta visual de SEO; está más orientada a proyectos de datos
Si necesitas datos estructurados a gran escala, especialmente para IA o analítica, Diffbot es una auténtica potencia.
Screaming Frog: crawler SEO gratuito para escritorio

Screaming Frog es el crawler de escritorio clásico para auditorías SEO. Permite rastrear hasta 500 URLs por análisis en su versión gratuita y te da de todo: enlaces rotos, meta tags, contenido duplicado, sitemaps y más (Screaming Frog User Guide).
Puntos fuertes:
- Rápido, completo y muy reconocido en el mundo SEO
- No hace falta programar: solo introduces una URL y listo
- Gratis para hasta 500 URLs por rastreo
Limitaciones:
- Solo para escritorio (sin versión en la nube)
- Las funciones avanzadas (renderizado JS, programación) requieren licencia de pago
Si te tomas el SEO en serio, Screaming Frog es imprescindible —solo no esperes que rastree gratis un sitio de 10.000 páginas.
SiteOne Crawler: exportación de sitios estáticos y documentación

SiteOne Crawler es la navaja suiza de las auditorías técnicas. Es open source, multiplataforma y puede rastrear, auditar e incluso exportar tu sitio a Markdown para documentación o uso sin conexión (SiteOne Crawler).
Puntos fuertes:
- Cubre SEO, rendimiento, accesibilidad y seguridad
- Exporta sitios para archivado o migración
- Gratis y open source, sin límites de uso
Limitaciones:
- Más técnico que algunas herramientas con GUI
- El informe en la interfaz gráfica está limitado a 1.000 URLs por defecto (se puede configurar)
Si eres desarrollador, QA o consultor y quieres una visión profunda del sitio —y además te gusta el open source—, SiteOne es una joya poco conocida.
Crawljax: crawler web Java de código abierto para páginas dinámicas
Crawljax es una herramienta especializada: está diseñada para rastrear aplicaciones web modernas con mucho JavaScript simulando interacciones de usuario (clics, formularios, etc.). Es basada en eventos e incluso puede generar una versión estática de un sitio dinámico (Wikipedia: Crawljax).
Puntos fuertes:
- Excelente para rastrear SPA y sitios intensivos en AJAX
- Open source y ampliable
- Sin límites de uso
Limitaciones:
- Requiere Java y algo de programación/configuración
- No es para usuarios no técnicos
Si necesitas rastrear una app en React o Angular como si fueras un usuario real, Crawljax es tu aliado.
Apache Nutch: crawler web distribuido y escalable

Apache Nutch es el veterano de los crawlers open source. Está pensado para rastreos masivos y distribuidos —por ejemplo, crear tu propio motor de búsqueda o indexar millones de páginas (Martechvibe).
Puntos fuertes:
- Escala hasta miles de millones de páginas con Hadoop
- Muy configurable y extensible
- Gratis y open source
Limitaciones:
- Curva de aprendizaje pronunciada (Java, línea de comandos, configuraciones)
- No es ideal para sitios pequeños o usuarios casuales
Si quieres rastrear la web a gran escala y no te asusta la terminal, Nutch es tu herramienta.
YaCy: crawler web y motor de búsqueda peer-to-peer
YaCy es un crawler y motor de búsqueda descentralizado bastante singular. Cada instancia rastrea e indexa sitios, y puedes unirte a una red peer-to-peer para compartir índices con otros (TechRadar: YaCy).
Puntos fuertes:
- Enfocado en la privacidad, sin servidor central
- Muy útil para crear búsquedas privadas o internas
- Gratis y open source
Limitaciones:
- Los resultados dependen de la cobertura de la red
- Requiere cierta configuración (Java, interfaz en navegador)
Si te interesa la descentralización o quieres montar tu propio motor de búsqueda, YaCy es una opción muy interesante.
PowerMapper: generador visual de sitemaps para UX y QA

PowerMapper se centra en visualizar la estructura de tu sitio. Rastrea tu web y genera sitemaps interactivos; además, revisa accesibilidad, compatibilidad entre navegadores y aspectos básicos de SEO (Slickplan Review).
Puntos fuertes:
- Los sitemaps visuales son ideales para agencias y diseñadores
- Comprueba accesibilidad y cumplimiento
- Interfaz sencilla, sin necesidad de conocimientos técnicos
Limitaciones:
- Solo ofrece prueba gratuita (30 días, 100 páginas en desktop / 10 páginas online por análisis)
- La versión completa es de pago
Si necesitas presentar un sitemap a clientes o revisar cumplimiento, PowerMapper es muy práctico.
Cómo elegir el crawler web gratuito adecuado para ti
Con tantas opciones, ¿cómo decidir? Aquí va mi guía rápida:
- Para auditorías SEO: Screaming Frog (sitios pequeños), PowerMapper (visual), SiteOne (auditorías profundas)
- Para aplicaciones web dinámicas: Crawljax
- Para crawling a gran escala o búsqueda personalizada: Apache Nutch, YaCy
- Para desarrolladores que necesitan acceso por API: Crawlbase, ScraperAPI, Diffbot
- Para documentación o archivado: SiteOne Crawler
- Para uso empresarial con prueba gratuita: BrightData, Diffbot
Factores clave a considerar:
- Escalabilidad: ¿Qué tan grande es tu sitio o tu tarea de crawling?
- Facilidad de uso: ¿Te sientes cómodo con código o prefieres una interfaz de clics?
- Exportación de datos: ¿Necesitas CSV, JSON o integración con otras herramientas?
- Soporte: ¿Hay comunidad o documentación si te atascas?
Cuando el crawling web se combina con el scraping: por qué Thunderbit es una opción más inteligente
Extrae datos de cualquier sitio web usando IA Get Started Free
La realidad es esta: la mayoría de las personas no rastrea sitios solo para hacer mapas bonitos. El objetivo real suele ser obtener datos estructurados: listas de productos, información de contacto o inventarios de contenido. Ahí es donde entra Thunderbit.
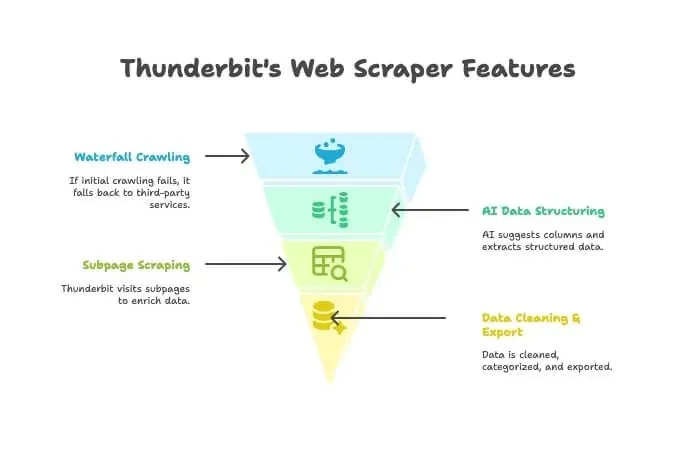
Thunderbit no es solo un crawler ni solo un scraper: es una extensión de Chrome impulsada por IA que combina ambos. Funciona así:
- Crawler con IA: Thunderbit explora el sitio, igual que un crawler.
- Crawling en cascada: si el motor propio de Thunderbit no logra acceder a la página —quizá por una barrera anti-bot complicada—, cambia automáticamente a servicios de crawling de terceros, sin que tengas que configurar nada.
- Estructuración de datos con IA: una vez obtiene el HTML, la IA de Thunderbit sugiere las columnas correctas y extrae datos estructurados (nombres, precios, correos, etc.) sin que escribas un solo selector.
- Scraping de subpáginas: si necesitas detalles de cada página de producto, Thunderbit puede visitar automáticamente cada subpágina y enriquecer tu tabla.
- Limpieza y exportación de datos: puede resumir, categorizar, traducir y exportar tus datos a Excel, Google Sheets, Airtable o Notion con un solo clic.
- Simplicidad sin código: si sabes usar un navegador, puedes usar Thunderbit. Sin programar, sin proxies y sin dolores de cabeza.
¿Cuándo conviene usar Thunderbit en lugar de un crawler tradicional?
- Cuando tu objetivo final es una hoja de cálculo limpia y útil, no solo una lista de URLs.
- Cuando quieres automatizar todo el proceso —crawling, extracción, limpieza y exportación— en un solo lugar.
- Cuando valoras tu tiempo y tu tranquilidad.
Puedes descargar la extensión de Chrome de Thunderbit aquí y comprobar por ti mismo por qué tantos usuarios de negocio están cambiando.
Probar Thunderbit gratis – AI Web Scraper
Conclusión: cómo sacar el máximo partido a los crawlers web gratuitos
Qué es el data scraping y cómo hacerlo Get Started Free
Los crawlers web han evolucionado muchísimo. Tanto si eres marketer, desarrollador o simplemente alguien que quiere mantener su sitio en buen estado, hay una herramienta gratuita —o al menos de prueba gratuita— para ti. Desde plataformas de nivel empresarial como BrightData y Diffbot, hasta joyas open source como SiteOne y Crawljax, pasando por mapeadores visuales como PowerMapper, hoy las opciones son más variadas que nunca.
Pero si buscas una forma más inteligente e integrada de pasar de “necesito estos datos” a “aquí está mi hoja de cálculo”, prueba Thunderbit. Está pensado para usuarios de negocio que quieren resultados, no solo informes.
¿Listo para empezar a rastrear? Descarga una herramienta, ejecuta un análisis y descubre lo que te estabas perdiendo. Y si quieres pasar de crawling a datos accionables en dos clics, echa un vistazo a Thunderbit.
Para más análisis en profundidad y guías prácticas, visita el Thunderbit Blog.
Extrae datos de sitios web con IA en 2 clics
Probar AI Web Scraper Get Started Free
FAQ
¿Cuál es la diferencia entre un website crawler y un web scraper?
Un crawler descubre y mapea todas las páginas de un sitio (piensa en crear un índice o tabla de contenidos). Un scraper extrae campos concretos de esas páginas (como precios, correos o reseñas). Los crawlers encuentran; los scrapers extraen (Thunderbit Blog: What Is a Web Crawler?).
¿Qué crawler web gratuito es mejor para usuarios no técnicos?
Para sitios pequeños y auditorías SEO, Screaming Frog es bastante fácil de usar. Para mapeo visual, PowerMapper es excelente durante la prueba. Thunderbit es la opción más sencilla si lo que buscas son datos estructurados y quieres una experiencia sin código desde el navegador.
¿Hay sitios web que bloquean crawlers?
Sí. Algunos sitios usan archivos robots.txt o medidas anti-bot, como CAPTCHAs o bloqueos por IP, para frenar crawlers. Herramientas como ScraperAPI, Crawlbase y Thunderbit (con crawling en cascada) suelen poder sortear estos obstáculos, pero siempre conviene rastrear con responsabilidad y respetar las normas del sitio (BrightData Pricing).
¿Los crawlers gratuitos tienen límites de páginas o funciones?
La mayoría sí. Por ejemplo, la versión gratuita de Screaming Frog está limitada a 500 URLs por rastreo; la prueba de PowerMapper es de 100 páginas. Las herramientas basadas en API suelen tener límites mensuales de créditos. Las herramientas open source como SiteOne o Crawljax, por lo general, no tienen límites estrictos, aunque dependes del hardware que uses.
¿Usar un crawler web es legal y cumple con la privacidad?
En general, rastrear páginas públicas es legal, pero siempre conviene revisar los términos de servicio y el archivo robots.txt. Nunca rastrees datos privados o protegidos por contraseña sin permiso, y ten en cuenta las leyes de privacidad si vas a extraer datos personales (Crawlbase Guide).




