

Los datos web son la base para ventas, marketing y operaciones. Si todavía copias y pegas todo a mano, ya vas tarde.
Pero aquí está el problema con las herramientas “gratis” para raspado web: la mayoría no son realmente gratis. Son pruebas con límites muy apretados o esconden las funciones que de verdad necesitas detrás de un muro de pago.
Evalué 12 herramientas para ver cuáles sí permiten hacer trabajo real en el plan gratuito. Probé listas de Google Maps, páginas dinámicas detrás de inicios de sesión y PDFs. Algunas sí cumplieron. Otras me hicieron perder la tarde.
Aquí va el análisis honesto, empezando por las que sí recomendaría.
Por qué los raspadores gratis importan más que nunca
Seamos claros: en 2026, el raspado web ya no es solo cosa de hackers o científicos de datos. Se ha vuelto una herramienta básica para las empresas modernas, y los números lo respaldan. El mercado del software de raspado web alcanzó 1,01 mil millones de dólares en 2024 y apunta a más que duplicarse para 2032. ¿Por qué? Porque desde equipos de ventas hasta agentes inmobiliarios están usando datos web para ganar ventaja.
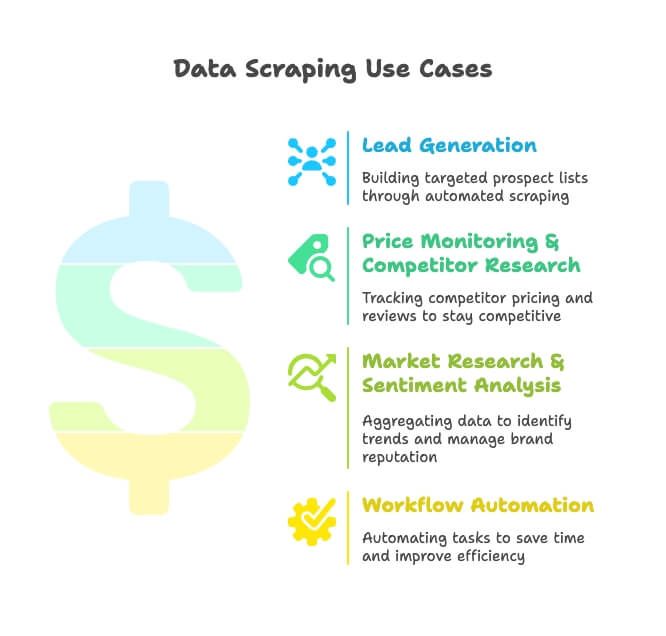
- Generación de leads: los equipos comerciales rastrean directorios, Google Maps y redes sociales para armar listas de prospectos bien segmentadas; ya no hace falta buscar a mano.
- Seguimiento de precios e investigación de la competencia: equipos de ecommerce y retail monitorizan SKUs, precios y reseñas de la competencia para seguir siendo competitivos (y sí, el 82% de las empresas de comercio electrónico lo hace por esa misma razón).
- Investigación de mercado y análisis de sentimiento: marketing recopila reseñas, noticias y conversaciones en redes para detectar tendencias y cuidar la reputación de la marca.
- Automatización de flujos de trabajo: operaciones automatiza desde revisiones de inventario hasta reportes programados, ahorrando horas cada semana.
Y aquí va un dato interesante: las empresas que usan raspadores web con IA ahorran entre un 30% y un 40% de tiempo frente a los métodos manuales. No hablamos de ahorrar un poco de tiempo: hablamos de la diferencia entre salir a las 6 p. m. o a las 9 p. m.
Cómo seleccionamos las mejores herramientas gratuitas de raspado de datos
He visto muchas listas de “mejores raspadores web” que solo repiten texto de marketing. Aquí no. Para esta lista, revisé:
- Usabilidad real del plan gratis: ¿el nivel gratuito sirve de verdad o solo es una demo?
- Facilidad de uso: ¿una persona sin programar puede obtener resultados en minutos o hace falta un doctorado en Regex?
- Tipos de sitios compatibles: páginas estáticas, dinámicas, paginadas, con login, PDFs, redes sociales… ¿la herramienta resuelve casos reales?
- Opciones de exportación: ¿puedes llevar los datos a Excel, Google Sheets, Notion o Airtable sin complicarte?
- Funciones extra: extracción con IA, programación, plantillas, postprocesado, integraciones.
- Tipo de usuario ideal: ¿está pensada para usuarios de negocio, analistas o desarrolladores?
También revisé la documentación de cada herramienta, probé el onboarding y comparé los límites de los planes gratuitos, porque “gratis” no siempre significa lo que parece.
De un vistazo: comparación de 12 raspadores de datos gratis
Aquí tienes una vista comparativa para ayudarte a identificar rápido la herramienta adecuada para ti.
| Herramienta | Plataforma | Limitaciones del plan gratis | Ideal para | Formatos de exportación | Funciones destacadas |
|---|---|---|---|---|---|
| Thunderbit | Extensión de Chrome | 6 páginas/mes | Personas sin código, negocios | Excel, CSV | Prompts con IA, raspado de PDF/imagen, rastreo de subpáginas |
| Browse AI | Nube | 50 créditos/mes | Usuarios sin código | CSV, Sheets | Robots con clics, programación |
| Octoparse | Escritorio | 10 tareas, 50k filas/mes | No-code, usuarios semi técnicos | CSV, Excel, JSON | Flujo visual, soporte para sitios dinámicos |
| ParseHub | Escritorio | 5 proyectos, 200 páginas/ejecución | No-code, usuarios semi técnicos | CSV, Excel, JSON | Visual, soporte para sitios dinámicos |
| Webscraper.io | Extensión de Chrome | Uso local ilimitado | No-code, tareas simples | CSV, XLSX | Basado en sitemap, plantillas de la comunidad |
| Apify | Nube | 5 USD en créditos/mes | Equipos, usuarios semi técnicos, devs | CSV, JSON, Sheets | Marketplace de actores, programación, API |
| Scrapy | Librería de Python | Ilimitado (código abierto) | Desarrolladores | CSV, JSON, DB | Control total por código, escalable |
| Puppeteer | Librería de Node.js | Ilimitado (código abierto) | Desarrolladores | Personalizado (código) | Navegador sin interfaz, soporte para JS dinámico |
| Selenium | Multilenguaje | Ilimitado (código abierto) | Desarrolladores | Personalizado (código) | Automatización del navegador, soporte mult navegador |
| Zyte | Nube | 1 spider, 1 h/trabajo, retención de 7 días | Devs, equipos de operaciones | CSV, JSON | Scrapy alojado, gestión de proxies |
| SerpAPI | API | 100 búsquedas/mes | Devs, analistas | JSON | APIs de buscadores, anti bloqueo |
| Diffbot | API | 10,000 créditos/mes | Devs, proyectos de IA | JSON | Extracción con IA, grafo de conocimiento |
Thunderbit: mi elección principal para raspado de datos con IA y fácil de usar
Extrae datos de cualquier sitio web usando IA Get Started Free
Hablemos de por qué Thunderbit encabeza mi lista. Y no lo digo solo porque formo parte del equipo: de verdad creo que Thunderbit es lo más parecido a tener un becario con IA que sí escucha (y no pide café cada dos horas).
Thunderbit no se siente como la típica experiencia de “aprende la herramienta y luego raspa”. Es más como darle instrucciones a un asistente inteligente: describes lo que quieres (“extrae todos los nombres de productos, precios y enlaces de esta página”) y la IA de Thunderbit se encarga del resto. Sin XPath, sin selectores CSS, sin dolores de cabeza con Regex. Y si quieres raspar subpáginas, como fichas de producto o enlaces de contacto de empresas, Thunderbit puede entrar automáticamente y enriquecer tu tabla; otra vez, con solo pulsar un botón.
Pero lo que de verdad marca la diferencia en Thunderbit es lo que pasa después de extraer los datos. ¿Necesitas resumir, traducir, categorizar o limpiar la información? El posprocesado con IA integrado de Thunderbit se encarga de eso. No obtienes solo datos en bruto: obtienes información estructurada y útil, lista para tu CRM, tu hoja de cálculo o tu próximo proyecto.
Plan gratis: la prueba gratuita de Thunderbit permite raspar hasta 6 páginas (o 10 con el impulso de prueba), incluidos PDFs, imágenes e incluso plantillas para redes sociales. Puedes exportar gratis a Excel o CSV, y probar funciones como extracción de emails, teléfonos e imágenes. Para proyectos más grandes, los planes de pago desbloquean más páginas, exportación directa a Google Sheets/Notion/Airtable, raspado programado y plantillas instantáneas para sitios populares como Amazon, Google Maps e Instagram.
Si quieres ver Thunderbit en acción, prueba la extensión de Chrome de Thunderbit o visita nuestro canal de YouTube para ver videos de inicio rápido.
Funciones destacadas de Thunderbit
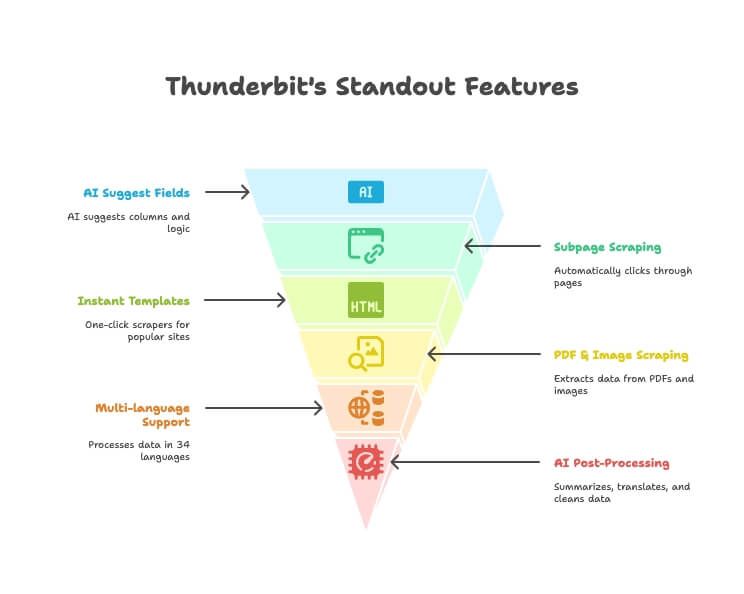
- Campos sugeridos por IA: solo describe los datos que necesitas y la IA de Thunderbit te propone las columnas y la lógica de extracción correctas.
- Raspado de subpáginas: entra automáticamente en páginas de detalle o enlaces y enriquece tu tabla principal, sin configuración manual.
- Plantillas instantáneas: raspadores con un clic para Amazon, Google Maps, Instagram y más.
- Raspado de PDF e imágenes: extrae tablas y datos de PDFs e imágenes con IA, sin herramientas extra.
- Soporte multilingüe: raspa y procesa datos en 34 idiomas.
- Exportación directa: envía tus datos directamente a Excel, Google Sheets, Notion o Airtable (planes de pago).
- Posprocesado con IA: resume, traduce, categoriza y limpia los datos mientras raspas.
- Extracción gratis de email/teléfono/imagen: captura información de contacto o imágenes de cualquier sitio con un clic.
Thunderbit salva la distancia entre “solo extraer datos” y “obtener datos que realmente puedas usar”. Es lo más parecido que he visto a un asistente de datos con IA para usuarios de negocio.
El resto del top 12: revisión de herramientas gratuitas de raspado de datos
Veamos el resto del grupo, organizado según para quién encaja mejor.
Para usuarios sin código y de negocio
Thunderbit
Ya cubierto arriba. La forma más fácil de empezar para quienes no programan, con funciones de IA y plantillas instantáneas.
Webscraper.io
- Plataforma: Extensión de Chrome
- Ideal para: sitios simples y estáticos; personas sin código que no les importe probar y ajustar.
- Funciones clave: raspado basado en sitemap, admite paginación, exportación a CSV/XLSX.
- Plan gratis: uso local ilimitado, pero sin ejecuciones en la nube ni programación. Solo operación manual.
- Limitaciones: no trae manejo nativo de inicios de sesión, PDFs ni contenido dinámico complejo. Solo soporte de la comunidad.
ParseHub
- Plataforma: aplicación de escritorio (Windows, Mac, Linux)
- Ideal para: personas sin código y usuarios semi técnicos que estén dispuestos a invertir tiempo en aprender.
- Funciones clave: constructor visual de flujos, compatible con sitios dinámicos, AJAX, inicios de sesión y paginación.
- Plan gratis: 5 proyectos públicos, 200 páginas por ejecución, solo ejecuciones manuales.
- Limitaciones: los proyectos son públicos en el plan gratis (ojo con datos sensibles), sin programación y con velocidades de extracción más lentas.
Octoparse
- Plataforma: aplicación de escritorio (Windows/Mac), nube (de pago)
- Ideal para: usuarios sin código y analistas que buscan potencia y flexibilidad.
- Funciones clave: interfaz visual de clic y selección, soporte para contenido dinámico, plantillas para sitios populares.
- Plan gratis: 10 tareas, hasta 50,000 filas/mes, solo escritorio (sin nube ni programación).
- Limitaciones: sin API, rotación de IP ni programación en el plan gratuito. La curva de aprendizaje puede ser dura para sitios complejos.
Browse AI
- Plataforma: nube
- Ideal para: usuarios sin código que quieren automatizar raspados y monitoreo sencillos.
- Funciones clave: grabador de robots con clics, programación e integraciones (Sheets, Zapier).
- Plan gratis: 50 créditos/mes, 1 sitio web, hasta 5 robots.
- Limitaciones: volumen limitado y cierta curva inicial para sitios complejos.
Para desarrolladores y usuarios técnicos
Scrapy
- Plataforma: librería de Python (código abierto)
- Ideal para: desarrolladores que quieren control total y escalabilidad.
- Funciones clave: altamente personalizable, admite rastreos grandes, middleware y pipelines.
- Plan gratis: ilimitado (código abierto).
- Limitaciones: no tiene interfaz gráfica y requiere programar en Python. No es para personas sin código.
Puppeteer
- Plataforma: librería de Node.js (código abierto)
- Ideal para: desarrolladores que raspan sitios dinámicos con mucho JavaScript.
- Funciones clave: automatización de navegador sin interfaz, control total sobre navegación y extracción.
- Plan gratis: ilimitado (código abierto).
- Limitaciones: requiere programar en JavaScript y no tiene GUI.
Selenium
- Plataforma: multilenguaje (Python, Java, etc.), código abierto
- Ideal para: desarrolladores que automatizan navegadores para raspado o testing.
- Funciones clave: soporte mult navegador, automatiza clics, scroll e inicios de sesión.
- Plan gratis: ilimitado (código abierto).
- Limitaciones: más lento que las librerías headless y exige scripting.
Zyte (Scrapy Cloud)
- Plataforma: nube
- Ideal para: desarrolladores y equipos de operaciones que despliegan spiders de Scrapy a escala.
- Funciones clave: Scrapy alojado, gestión de proxies y programación de trabajos.
- Plan gratis: 1 spider concurrente, 1 hora por trabajo, retención de datos durante 7 días.
- Limitaciones: sin programación avanzada en el plan gratis, requiere conocer Scrapy.
Para equipos y uso empresarial
Apify
- Plataforma: nube
- Ideal para: equipos, usuarios semi técnicos y desarrolladores que quieren scrapers listos para usar o personalizados.
- Funciones clave: marketplace de actores (bots preconstruidos), programación, API e integraciones.
- Plan gratis: 5 USD en créditos al mes (suficiente para tareas pequeñas), retención de datos de 7 días.
- Limitaciones: cierta curva de aprendizaje y uso limitado por créditos.
SerpAPI
- Plataforma: API
- Ideal para: desarrolladores y analistas que necesitan datos de buscadores (Google, Bing, YouTube).
- Funciones clave: APIs de búsqueda, anti bloqueo y salida JSON estructurada.
- Plan gratis: 100 búsquedas al mes.
- Limitaciones: no sirve para sitios web arbitrarios, solo uso vía API.
Diffbot
- Plataforma: API
- Ideal para: desarrolladores, equipos de IA/ML y empresas que necesitan datos web estructurados a escala.
- Funciones clave: extracción con IA, grafo de conocimiento y APIs para artículos/productos.
- Plan gratis: 10,000 créditos al mes.
- Limitaciones: solo API, requiere habilidades técnicas y tiene limitación de tasa.
Límites del plan gratis: qué significa realmente “gratis” en cada raspador de datos
Seamos sinceros: “gratis” puede significar desde “ilimitado para aficionados” hasta “apenas suficiente para engancharte”. Aquí va el desglose de lo que realmente obtienes:
| Herramienta | Páginas/filas al mes | Formatos de exportación | Programación | Acceso a API | Límites gratis destacados |
|---|---|---|---|---|---|
| Thunderbit | 6 páginas | Excel, CSV | No | No | Campos sugeridos por IA limitados, sin exportación directa a Sheets/Notion en gratis |
| Browse AI | 50 créditos | CSV, Sheets | Sí | Sí | 1 sitio web, 5 robots, retención de 15 días |
| Octoparse | 50,000 filas | CSV, Excel, JSON | No | No | Solo escritorio, sin nube ni programación |
| ParseHub | 200 páginas/ejecución | CSV, Excel, JSON | No | No | 5 proyectos públicos, velocidad lenta |
| Webscraper.io | Uso local ilimitado | CSV, XLSX | No | No | Ejecuciones manuales, sin nube |
| Apify | 5 USD en créditos (~poco) | CSV, JSON, Sheets | Sí | Sí | Retención de 7 días, tope por créditos |
| Scrapy | Ilimitado | CSV, JSON, DB | No | N/A | Requiere programar |
| Puppeteer | Ilimitado | Personalizado (código) | No | N/A | Requiere programar |
| Selenium | Ilimitado | Personalizado (código) | No | N/A | Requiere programar |
| Zyte | 1 spider, 1 h/trabajo | CSV, JSON | Limitada | Sí | Retención de 7 días, 1 trabajo concurrente |
| SerpAPI | 100 búsquedas | JSON | No | Sí | Solo APIs de búsqueda |
| Diffbot | 10,000 créditos | JSON | No | Sí | Solo API, con límite de tasa |
En resumen: para proyectos reales, Thunderbit, Browse AI y Apify ofrecen las pruebas gratuitas más útiles para usuarios de negocio. Para raspado continuo o a gran escala, pronto vas a chocar con los límites y tendrás que actualizar o pasar a soluciones de código abierto.
¿Qué herramienta de raspado de datos es mejor para ti? (guía por tipo de usuario)
Aquí tienes una guía rápida para elegir la herramienta correcta según tu rol y tu nivel técnico:
| Tipo de usuario | Mejores herramientas gratis | Por qué |
|---|---|---|
| No programador (ventas/marketing) | Thunderbit, Browse AI, Webscraper.io | Más rápidas de aprender, clic y selección, ayuda con IA |
| Semitécnico (operaciones/analista) | Octoparse, ParseHub, Apify, Zyte | Más potencia, manejan sitios complejos, algo de scripting posible |
| Desarrollador/ingeniero | Scrapy, Puppeteer, Selenium, Diffbot, SerpAPI | Control total, ilimitadas, enfoque API-first |
| Equipo/empresa | Apify, Zyte | Colaboración, programación, integraciones |
Escenarios reales de raspado web: comparación de adaptabilidad de herramientas
Veamos cómo se comportan estas herramientas en cinco escenarios comunes:
| Escenario | Thunderbit | Browse AI | Octoparse | ParseHub | Webscraper.io | Apify | Scrapy | Puppeteer | Selenium | Zyte | SerpAPI | Diffbot |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Listados paginados | Fácil | Fácil | Medio | Medio | Medio | Fácil | Fácil | Fácil | Fácil | Fácil | N/A | Medio |
| Listados de Google Maps | Fácil* | Difícil | Medio | Medio | Difícil | Fácil | Difícil | Difícil | Difícil | Difícil | Fácil | N/A |
| Páginas que requieren login | Fácil | Medio | Medio | Medio | Manual | Medio | Fácil | Fácil | Fácil | Fácil | N/A | N/A |
| Extracción de datos de PDFs | Fácil | No | No | No | No | Medio | Difícil | Difícil | Difícil | Difícil | No | Limitado |
| Contenido de redes sociales | Fácil* | Parcial | Difícil | Difícil | Difícil | Fácil | Difícil | Difícil | Difícil | Difícil | YouTube | Limitado |
- Thunderbit y Apify ofrecen plantillas/actores preconstruidos para Google Maps y raspado de redes sociales, lo que hace estos casos mucho más fáciles para usuarios no técnicos.
Extensión vs. escritorio vs. nube: ¿cuál ofrece la mejor experiencia de raspado web?
- Extensiones de Chrome (Thunderbit, Webscraper.io):
- Ventajas: rápidas de empezar, funcionan en el navegador y requieren poca configuración.
- Desventajas: operación manual, pueden verse afectadas por cambios en el sitio y tienen automatización limitada.
- Ventaja de Thunderbit: la IA gestiona cambios de estructura, navegación entre subpáginas e incluso raspado de PDFs e imágenes, así que es mucho más robusto que las extensiones tradicionales.
- Aplicaciones de escritorio (Octoparse, ParseHub):
- Ventajas: potentes, flujos visuales y manejo de sitios dinámicos e inicios de sesión.
- Desventajas: curva de aprendizaje más alta, sin automatización en la nube en los planes gratis y dependientes del sistema operativo.
- Plataformas en la nube (Browse AI, Apify, Zyte):
- Ventajas: programación, colaboración en equipo, escalabilidad e integraciones.
- Desventajas: los planes gratis suelen estar limitados por créditos, requieren cierta configuración y a veces conocer APIs.
- Librerías de código abierto (Scrapy, Puppeteer, Selenium):
- Ventajas: ilimitadas, personalizables e ideales para desarrolladores.
- Desventajas: requieren programar, no son para usuarios de negocio.
Tendencias de raspado web en 2026: qué hace diferentes a las herramientas modernas
El raspado web en 2026 gira en torno a IA, automatización e integración. Esto es lo nuevo:
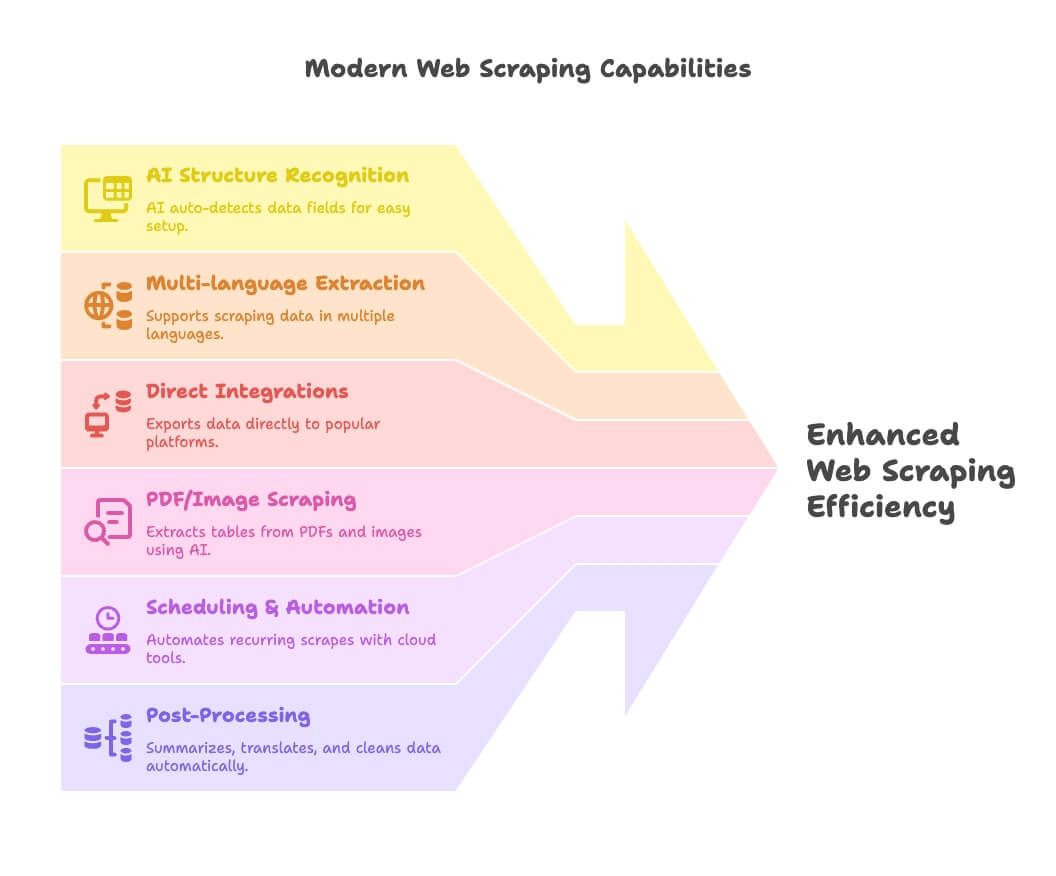
- Reconocimiento de estructura con IA: herramientas como Thunderbit usan IA para detectar automáticamente campos de datos, haciendo la configuración mucho más fácil para quienes no programan.
- Extracción multilingüe: Thunderbit y otras herramientas permiten raspar y procesar datos en decenas de idiomas.
- Integraciones directas: exporta los datos extraídos directamente a Google Sheets, Notion o Airtable; ya no hace falta pelear con CSVs.
- Raspado de PDF e imágenes: Thunderbit lidera en esto, permitiendo extraer tablas desde PDFs e imágenes con IA.
- Programación y automatización: las herramientas en la nube (Apify, Browse AI) te permiten configurar raspados recurrentes y olvidarte.
- Posprocesado: resume, traduce, categoriza y limpia datos mientras raspas; se acabaron las hojas de cálculo desordenadas.
Thunderbit, Apify y SerpAPI están a la vanguardia de estas tendencias, pero Thunderbit destaca por hacer que el raspado con IA sea accesible para todos, no solo para desarrolladores.
Más allá del raspado: procesamiento de datos y funciones de valor añadido
No se trata solo de capturar datos, sino de hacer que sirvan. Así se comparan las mejores herramientas en posprocesado:
| Herramienta | Limpieza | Traducción | Categorización | Resumen | Notas |
|---|---|---|---|---|---|
| Thunderbit | Sí | Sí | Sí | Sí | Posprocesado con IA integrado |
| Apify | Parcial | Parcial | Parcial | Parcial | Depende del actor utilizado |
| Browse AI | No | No | No | No | Solo datos en bruto |
| Octoparse | Parcial | No | Parcial | No | Algo de procesamiento de campos |
| ParseHub | Parcial | No | Parcial | No | Algo de procesamiento de campos |
| Webscraper.io | No | No | No | No | Solo datos en bruto |
| Scrapy | Sí* | Sí* | Sí* | Sí* | Si lo programa un desarrollador |
| Puppeteer | Sí* | Sí* | Sí* | Sí* | Si lo programa un desarrollador |
| Selenium | Sí* | Sí* | Sí* | Sí* | Si lo programa un desarrollador |
| Zyte | Parcial | No | Parcial | No | Algunas funciones de autoextracción |
| SerpAPI | No | No | No | No | Solo datos estructurados de búsqueda |
| Diffbot | Sí | Sí | Sí | Sí | Con IA, pero solo vía API |
- El desarrollador debe implementar la lógica de procesamiento.
Thunderbit es la única herramienta que permite a usuarios sin perfil técnico pasar de datos web en bruto a insights estructurados y accionables, todo en un solo flujo de trabajo.
Comunidad, soporte y recursos de aprendizaje: cómo ponerse al día
La documentación y el onboarding importan, y mucho. Así se comparan estas herramientas:
| Herramienta | Documentación y tutoriales | Comunidad | Plantillas | Curva de aprendizaje |
|---|---|---|---|---|
| Thunderbit | Excelente | En crecimiento | Sí | Muy baja |
| Browse AI | Buena | Buena | Sí | Baja |
| Octoparse | Excelente | Grande | Sí | Media |
| ParseHub | Excelente | Grande | Sí | Media |
| Webscraper.io | Buena | Foro | Sí | Media |
| Apify | Excelente | Grande | Sí | Media-alta |
| Scrapy | Excelente | Enorme | N/A | Alta |
| Puppeteer | Buena | Grande | N/A | Alta |
| Selenium | Buena | Enorme | N/A | Alta |
| Zyte | Buena | Grande | Sí | Media-alta |
| SerpAPI | Buena | Media | N/A | Alta |
| Diffbot | Buena | Media | N/A | Alta |
Thunderbit y Browse AI son las más fáciles para principiantes. Octoparse y ParseHub tienen buenos recursos, pero requieren más paciencia. Apify y las herramientas para desarrolladores tienen curvas de aprendizaje más empinadas, aunque están bien documentadas.
Conclusión: cómo elegir el raspador de datos gratis adecuado en 2026
Mira las mejores herramientas de raspado web en 2026 Get Started Free
La idea clave es esta: no todas las herramientas gratuitas de raspado de datos son igual de útiles, y tu elección debe depender de tu rol, tu comodidad técnica y tus necesidades reales.
- Si eres usuario de negocio o no programador y quieres obtener datos rápido —sobre todo de sitios difíciles, PDFs o imágenes—, Thunderbit es el mejor punto de partida. Su enfoque basado en IA, los prompts en lenguaje natural y sus funciones de posprocesado lo convierten en lo más parecido a un asistente de datos con IA de verdad. Prueba gratis la extensión de Chrome de Thunderbit y comprueba lo rápido que puedes pasar de “necesito estos datos” a “aquí está mi hoja de cálculo”.
- Si eres desarrollador o necesitas raspado ilimitado y personalizable, herramientas de código abierto como Scrapy, Puppeteer y Selenium son tu mejor opción.
- Para equipos y usuarios semi técnicos, Apify y Zyte ofrecen soluciones escalables y colaborativas con planes gratuitos generosos para trabajos pequeños.
Sea cual sea tu flujo de trabajo, empieza con la herramienta que encaje con tus habilidades y necesidades. Y recuerda: en 2026 no necesitas ser programador para aprovechar el poder de los datos web; solo necesitas el asistente adecuado (y quizá un poco de humor cuando los robots te ganen por velocidad).
¿Quieres profundizar más? Consulta más guías y comparativas en el blog de Thunderbit, incluyendo:
- Qué es el raspado de datos y cómo hacerlo en 2026
- Cómo raspar datos de sitios web a Excel usando IA
- Las mejores herramientas y software de raspado web en 2026
Empezar a raspar con Thunderbit
Probar AI Web Scraper Get Started Free




