
En 2015, extraer datos significaba rogarle a un desarrollador que te hiciera un script en Python o pasar un fin de semana aprendiendo XPath. En 2026, escribes «obtén todos los nombres y precios de los productos» y la IA hace el resto.
Ese cambio llegó a toda velocidad. Más de 2 millones de empresas ya dependen del raspado web. El mercado superó los $1.000 millones en 2024 y apunta a duplicarse para 2030.
¿El mayor motor? Los web crawlers con IA. Se adaptan a cambios en el diseño, entienden el contenido de la página y no solo las etiquetas HTML. Y funcionan incluso para personas que nunca han escrito una sola línea de código.
He pasado meses probando 15 de ellos. Esto fue lo que encontré, incluida la razón por la que Thunderbit (sí, la empresa que cofundé) se llevó el primer puesto.
Por qué la IA está transformando el raspado de páginas web: la nueva era de las herramientas de raspado web
Extrae datos de cualquier sitio web con IA Get Started Free
Seamos claros: el raspado web tradicional nunca se diseñó para el usuario empresarial medio. Todo giraba en torno al código, los selectores y a rezar para que tu script no se rompiera la próxima vez que un sitio cambiara su diseño. Pero la IA y los LLM han cambiado por completo el panorama.
Así es como cambia todo:
- Instrucciones en lenguaje natural: En lugar de pelearte con el código, solo le dices a la IA lo que quieres. Herramientas como Thunderbit interpretan tus instrucciones en inglés sencillo y configuran la extracción por ti (fuente).
- Aprendizaje adaptativo: Los raspadores con IA pueden adaptarse a cambios de diseño en los sitios web, lo que reduce los dolores de cabeza por mantenimiento.
- Gestión de contenido dinámico: Los sitios modernos adoran JavaScript y el scroll infinito. Las herramientas impulsadas por IA interactúan con estos elementos y capturan datos que los raspadores de antes pasarían por alto.
- Salida estructurada con análisis de IA: Los raspadores basados en LLM realmente entienden el contenido de la página y generan datos limpios y estructurados.
- Evasión automática de bots: Los raspadores con IA pueden eludir medidas anti-scraping y usar proxies/navegadores headless para evitar bloqueos de IP.
- Flujos de trabajo de datos integrados: Las mejores herramientas no solo extraen datos: te los entregan donde los necesitas, con exportación de un clic a Google Sheets, Airtable, Notion y más (fuente).
¿El resultado? El raspado web ahora es una experiencia de apuntar y hacer clic (o incluso de conversación), abriendo la puerta para que equipos de ventas, marketing y operaciones —no solo desarrolladores— aprovechen los datos web directamente.
15 web crawlers con IA que vale la pena conocer en 2026
Vamos a repasar los 15 mejores web crawlers con IA, empezando por Thunderbit. Te contaré lo esencial de cada herramienta: sus funciones principales, usuarios objetivo, precios y qué la hace destacar. Y sí, seré sincero sobre en qué brilla cada una y en qué quizá no.
1. Thunderbit: el Raspador Web IA para todos
Obviamente aquí tengo algo de sesgo, pero Thunderbit es el raspador web con IA que me habría encantado tener hace años. Estas son las razones por las que ocupa el puesto #1 en esta lista:
- Extracción en lenguaje natural: «Chateas» con Thunderbit. Solo describe los datos que quieres —«extrae todos los nombres y precios de los productos de esta página»— y la IA hace el resto (fuente). Sin código, sin selectores, sin dolor de cabeza.
- Raspado de subpáginas y multinivel: Thunderbit puede seguir enlaces y extraer subpáginas. Por ejemplo, extrae una lista de productos y luego entra en cada producto para ver los detalles, todo de una vez.
- Salida estructurada instantánea: La IA da formato y limpia los datos al vuelo, sugiere campos relevantes, normaliza formatos e incluso resume o categoriza texto.
- Amplio soporte de fuentes: Thunderbit no sirve solo para HTML: también puede extraer datos de PDF e imágenes usando OCR integrado e IA de visión (fuente).
- Integraciones empresariales: Exportación con un clic a Google Sheets, Airtable, Notion o Excel (fuente). Programa extracciones y envía los datos directamente al flujo de trabajo de tu equipo.
- Plantillas predefinidas: Para sitios como Amazon, LinkedIn, Zillow, etc., Thunderbit ofrece recetas de extracción ya preparadas para extraer datos con un clic.
- Fácil de usar y accesible: La interfaz es de apuntar y hacer clic, con un asistente intuitivo. Los usuarios cuentan que empiezan a usarlo en minutos.

Thunderbit cuenta con la confianza de más de 30.000 usuarios en todo el mundo, incluidos equipos de Accenture, Grammarly y Puma. Los equipos de ventas lo usan para crear listas de leads, los agentes inmobiliarios agrupan anuncios de propiedades y los especialistas en marketing monitorizan a la competencia, todo sin escribir una sola línea de código.
Precio: Hay un plan gratuito (extrae hasta 100 pasos al mes), con planes de pago desde 14,99 $/mes. Incluso los planes profesionales son asequibles para particulares y equipos pequeños.
Thunderbit es lo más parecido que he visto a «convertir la web en una base de datos», y está hecho para todos, no solo para ingenieros.
Probar la extensión de Chrome de Thunderbit
2. Crawl4AI
Para quién es: Desarrolladores y equipos técnicos que crean pipelines personalizados.
Crawl4AI es un framework de código abierto basado en Python, optimizado para velocidad y crawling a gran escala, con la integración de LLM en mente. Es rapidísimo, admite navegadores headless para contenido dinámico y puede estructurar los datos extraídos para enviarlos fácilmente a flujos de trabajo de IA.
- Lo mejor para: Desarrolladores que necesitan un motor de crawling potente y personalizable.
- Precio: Gratis (licencia MIT). Tendrás que alojarlo y ejecutarlo por tu cuenta.
3. ScrapeGraphAI
Para quién es: Desarrolladores y analistas que crean agentes de IA o pipelines de datos complejos.
ScrapeGraphAI es una biblioteca de Python de código abierto, guiada por prompts, que convierte sitios web en “grafos” de datos estructurados usando LLM. Puedes escribir prompts como «Extrae todos los nombres, precios y valoraciones de producto de las primeras 5 páginas», y la herramienta construye el flujo de trabajo de scraping por ti (fuente).
- Lo mejor para: Usuarios técnicos que quieren un scraping flexible basado en prompts.
- Precio: Gratis para la biblioteca de código abierto; la API en la nube empieza en 20 $/mes.
4. Firecrawl
Para quién es: Desarrolladores que crean agentes de IA o pipelines de datos a gran escala.
Firecrawl es una plataforma y API de crawling centrada en IA que convierte sitios web completos en datos “listos para LLM” (fuente). Devuelve Markdown o JSON, maneja contenido dinámico e integra con frameworks como LangChain y LlamaIndex.
- Lo mejor para: Desarrolladores que necesitan alimentar datos web en vivo a modelos de IA.
- Precio: El núcleo de código abierto es gratis; los planes en la nube empiezan en 19 $/mes.
5. Browse AI
Para quién es: Usuarios empresariales, growth hackers y analistas.
Browse AI es una plataforma sin código con una interfaz de apuntar y hacer clic. «Entrenas» un robot haciendo clic en los datos que quieres, y la IA generaliza el patrón para extracciones futuras. Gestiona inicios de sesión, scroll infinito y puede supervisar sitios para detectar cambios.
- Lo mejor para: Usuarios no técnicos que quieren automatizar la recopilación y supervisión de datos.
- Precio: Plan gratuito (50 créditos al mes); los planes de pago empiezan en 19 $/mes.
6. LLM Scraper
Para quién es: Desarrolladores que quieren que la IA haga el análisis.
LLM Scraper es una biblioteca de JavaScript/TypeScript de código abierto que te permite definir un esquema de datos y hacer que un LLM extraiga esos datos de cualquier página web. Está construido sobre Playwright, admite varios proveedores de LLM e incluso puede generar código reutilizable.
- Lo mejor para: Desarrolladores que quieren convertir cualquier página web en datos estructurados usando LLM.
- Precio: Gratis (licencia MIT).
7. Reader (Jina Reader)
Para quién es: Desarrolladores que crean aplicaciones de LLM, chatbots o resumidores.
Jina Reader es una API que extrae texto limpio y datos estructurados de páginas web (e incluso de PDF/imágenes), y devuelve Markdown o JSON listos para LLM. Está impulsado por un modelo de IA personalizado e incluso puede generar descripciones de imágenes.
- Lo mejor para: Obtener contenido limpio y legible para LLM o sistemas de preguntas y respuestas.
- Precio: API gratuita (no hace falta clave para el uso básico).
8. Bright Data
Para quién es: Empresas y usuarios profesionales que necesitan escala, cumplimiento y fiabilidad.
Bright Data es un gigante de la industria de los datos web, con una enorme red de proxies y herramientas de scraping impulsadas por IA. Ofrece raspadores listos para usar, una API general de Web Scraper y flujos de datos “listos para LLM”.
- Lo mejor para: Organizaciones que necesitan datos web fiables a gran escala.
- Precio: Basado en uso, premium. Hay pruebas gratuitas disponibles.
9. Octoparse
Para quién es: Usuarios de nivel no técnico a semitécnico.
Octoparse es una herramienta consolidada sin código, con un diseñador visual de flujos de trabajo y detección automática impulsada por IA. Gestiona inicios de sesión, scroll infinito y puede exportar datos en varios formatos.
- Lo mejor para: Analistas, dueños de pequeñas empresas o investigadores.
- Precio: Hay plan gratuito; los planes de pago empiezan en 119 $/mes.
10. Apify
Para quién es: Desarrolladores y equipos técnicos que necesitan scraping/automatización personalizada.
Apify es una plataforma en la nube para ejecutar scripts de scraping (“actors”) y ofrece una tienda de actores preconstruidos. Es escalable, se integra con IA y admite gestión de proxies.
- Lo mejor para: Desarrolladores que quieren ejecutar scripts personalizados en la nube.
- Precio: Plan gratuito; los planes de pago por uso empiezan en 49 $/mes.
11. Zyte (Scrapy Cloud)
Para quién es: Desarrolladores y empresas que necesitan scraping de nivel empresarial.
Zyte es la empresa detrás de Scrapy y ofrece una plataforma en la nube y extracción automática impulsada por IA. Gestiona la programación, los proxies y proyectos a gran escala.
- Lo mejor para: Equipos de desarrollo que ejecutan proyectos de scraping a largo plazo.
- Precio: Pruebas gratuitas y planes empresariales personalizados.
12. Webscraper.io
Para quién es: Principiantes, periodistas e investigadores.
Webscraper.io es una extensión popular de Chrome para extraer datos con apuntar y hacer clic. Es sencilla, gratuita para uso local y ofrece un servicio en la nube para trabajos más grandes.
- Lo mejor para: Tareas de scraping rápidas y puntuales.
- Precio: Extensión gratuita; los planes en la nube empiezan en unos 50 $/mes.
13. ParseHub
Para quién es: Usuarios no técnicos que necesitan más potencia que las herramientas básicas.
ParseHub es una aplicación de escritorio con un flujo de trabajo visual para extraer contenido dinámico, incluidos mapas y formularios. Puede ejecutar proyectos en la nube y ofrece una API.
- Lo mejor para: Especialistas en marketing digital, analistas y periodistas.
- Precio: Plan gratuito (200 páginas por ejecución); los planes de pago empiezan en 189 $/mes.
14. Diffbot
Para quién es: Empresas y compañías de IA que necesitan datos web estructurados a gran escala.
Diffbot usa visión por computador y NLP para extraer datos automáticamente de cualquier página web, y ofrece APIs para artículos, productos y un enorme grafo de conocimiento.
- Lo mejor para: Inteligencia de mercado, finanzas y datos de entrenamiento para IA.
- Precio: Premium, desde unos 299 $/mes.
15. DataMiner
Para quién es: Usuarios no técnicos, especialmente en ventas, marketing y periodismo.
DataMiner es una extensión de Chrome para extraer datos web rápidamente con apuntar y hacer clic. Tiene una biblioteca de “recetas” preconstruidas y puede exportar directamente a Google Sheets.
- Lo mejor para: Tareas rápidas como exportar tablas o listas a hojas de cálculo.
- Precio: Plan gratuito (500 páginas al día); Pro empieza en unos 19 $/mes.
Comparativa de las mejores herramientas de Raspador Web IA: ¿cuál se adapta a tus necesidades?
Aquí tienes una comparativa general para ayudarte a encontrar la tuya:
| Herramienta | Uso de IA/LLM | Facilidad de uso | Salida/Integración | Ideal para | Precio |
|---|---|---|---|---|---|
| Thunderbit | Interfaz en lenguaje natural; la IA sugiere campos | La más fácil (chat sin código) | Exportación a Sheets, Airtable, Notion | Equipos no técnicos | Plan gratuito; Pro ~30 $/mes |
| Crawl4AI | Crawling listo para IA; integración con LLM | Difícil (código Python) | Biblioteca/CLI; integración mediante código | Desarrolladores que necesitan pipelines de datos rápidos para IA | Gratis |
| ScrapeGraphAI | Pipelines de prompts LLM para scraping | Media (algo de código o API) | API/SDK; salida JSON | Desarrolladores/analistas que crean agentes de IA | Gratis OSS; API desde 20 $/mes |
| Firecrawl | Crawling a Markdown/JSON listo para LLM | Media (uso de API/SDK) | SDKs (Py, Node, etc.); integración con LangChain | Desarrolladores que integran datos web en vivo con IA | Gratis + nube de pago |
| Browse AI | IA asistida con apuntar y hacer clic | Fácil (sin código) | Más de 7000 integraciones de apps (Zapier) | Usuarios no técnicos que automatizan la supervisión web | 50 ejecuciones gratis; de pago desde 19 $/mes |
| LLM Scraper | Usa LLM para analizar la página según un esquema | Difícil (código TS/JS) | Biblioteca de código; salida JSON | Desarrolladores que quieren que la IA haga el análisis | Gratis (usa tu propia API de LLM) |
| Reader (Jina) | El modelo de IA extrae texto/JSON | Fácil (llamada API sencilla) | API REST que devuelve Markdown/JSON | Desarrolladores que añaden búsqueda/contenido web a LLM | API gratuita |
| Bright Data | API de scraping mejoradas con IA; gran red de proxies | Difícil (API, técnico) | APIs/SDKs; flujos de datos o conjuntos de datos | Escala empresarial | Según uso |
| Octoparse | Detección automática de listas con IA | Moderada (app sin código) | CSV/Excel, API para resultados | Usuarios semitécnicos | Gratis limitado; 59–166 $/mes |
| Apify | Algunas funciones de IA (Actors, tutoriales de IA) | Difícil (scripts de código) | API integral; integración con LangChain | Desarrolladores que necesitan scraping personalizado en la nube | Plan gratuito; pago por uso |
| Zyte (Scrapy) | Extracción automática basada en ML; framework Scrapy | Difícil (código Python) | API, interfaz de Scrapy Cloud; JSON/CSV | Equipos de desarrollo, proyectos a largo plazo | Precios personalizados |
| Webscraper.io | Sin IA (plantillas manuales) | Fácil (extensión del navegador) | Descarga CSV, API en la nube | Principiantes, extracciones puntuales rápidas | Extensión gratuita; nube ~50 $/mes |
| ParseHub | Sin LLM explícito; creador visual | Moderada (app sin código) | JSON/CSV; API para ejecuciones en la nube | Usuarios sin perfil técnico que extraen sitios complejos | 200 páginas gratis; de pago desde 189 $/mes |
| Diffbot | Visión e NLP de IA para cualquier página; grafo de conocimiento | Fácil (solo llamadas API) | APIs (Artículo/Producto/...) + consulta al Grafo de Conocimiento | Empresa, datos web estructurados | Desde ~299 $/mes |
| DataMiner | Sin LLM; recetas de la comunidad | La más fácil (interfaz del navegador) | Exportación a Excel/CSV; Google Sheets | Usuarios no técnicos que extraen datos a hojas de cálculo | Gratis limitado; Pro ~19 $/mes |
Categorías de herramientas: desde gigantes para desarrolladores hasta raspadores web pensados para negocios
Para darle sentido a esta lista, conviene agrupar las herramientas en unas pocas categorías:
1. Potencias para desarrolladores y código abierto
- Ejemplos: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Fortalezas: Mucha flexibilidad, escala y personalización. Ideales para crear pipelines propios o integrarlos con modelos de IA.
- Compromisos: Requieren conocimientos de código y más configuración.
- Casos de uso: Crear un pipeline de datos personalizado, extraer sitios complejos o integrarse con sistemas internos.
2. Agentes de extracción integrados con IA
- Ejemplos: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Fortalezas: Reducen la distancia entre extraer datos y entenderlos. Las interfaces en lenguaje natural los hacen accesibles.
- Compromisos: Algunos siguen evolucionando; puede que no ofrezcan control granular.
- Casos de uso: Respuestas rápidas o conjuntos de datos, creación de agentes autónomos o alimentación de datos en vivo a LLM.
3. Raspadores sin código o de poco código pensados para negocios
- Ejemplos: Thunderbit, Browse AI, Octoparse, ParseHub, Webscraper.io, DataMiner
- Fortalezas: Fáciles de usar, requieren poco o nada de código, y son buenos para tareas empresariales habituales.
- Compromisos: Pueden sufrir con sitios muy complejos o con escalas enormes.
- Casos de uso: Generación de leads, supervisión de la competencia, proyectos de investigación y extracciones puntuales.
4. Plataformas y servicios empresariales de datos
- Ejemplos: Bright Data, Diffbot, Zyte
- Fortalezas: Soluciones completas, servicios gestionados, cumplimiento y fiabilidad a escala.
- Compromisos: Mayor coste, más trabajo de implementación.
- Casos de uso: Pipelines de datos siempre activos y a gran escala, inteligencia de mercado y datos de entrenamiento para IA.
Cómo elegir el web crawler con IA adecuado para tus necesidades de raspado de páginas web
Qué es el data scraping y cómo hacerlo Get Started Free
Elegir la herramienta correcta puede resultar abrumador, así que aquí va mi guía paso a paso:
- Define tus objetivos y requisitos de datos: ¿Qué sitios y qué datos necesitas? ¿Con qué frecuencia? ¿Cuánto volumen? ¿Qué harás con ellos?
- Evalúa tu capacidad técnica: ¿No programas? Prueba Thunderbit, Browse AI u Octoparse. ¿Tienes algo de scripting? LLM Scraper o DataMiner. ¿Eres fuerte en desarrollo? Crawl4AI, Apify o Zyte.
- Considera la frecuencia y la escala: ¿Es algo puntual? Usa herramientas gratis. ¿Se repite? Busca funciones de programación. ¿A gran escala? Herramientas empresariales o código abierto a escala.
- Presupuesto y modelo de precios: Los planes gratuitos son excelentes para probar. Suscripción vs. pago por uso depende de tus necesidades.
- Prueba y prueba de concepto: Pon a prueba unas cuantas herramientas con tus datos reales. La mayoría tiene planes gratuitos.
- Mantenimiento y soporte: ¿Quién arreglará las cosas si el sitio cambia? Las herramientas sin código con IA pueden corregir automáticamente cambios menores; el código abierto depende de ti o de la comunidad.
- Relaciona herramientas con escenarios: ¿Un equipo de ventas extrayendo leads? Thunderbit o Browse AI. ¿Un investigador recopilando tweets? DataMiner o Webscraper.io. ¿Un modelo de IA que necesita artículos de noticias? Jina Reader o Zyte. ¿Construyendo un sitio de comparativas? Apify o Zyte.
- Ten un plan de respaldo: A veces una herramienta no funciona para un sitio concreto. Ten una alternativa.
La herramienta “correcta” es la que te da los datos que necesitas con la menor fricción y dentro de tu presupuesto. A veces, es una combinación.
Thunderbit frente a las herramientas tradicionales de raspado web: ¿qué lo hace destacar?
Vamos a concretar por qué Thunderbit es distinto:
- Interfaz en lenguaje natural: Sin código, sin acrobacias de apuntar y hacer clic. Solo describe lo que quieres (fuente).
- Configuración cero y sugerencias de plantillas: Thunderbit detecta automáticamente la paginación, las subpáginas e incluso sugiere plantillas para sitios comunes (fuente).
- Limpieza y enriquecimiento de datos impulsados por IA: Resume, categoriza, traduce y enriquece datos mientras los extraes (fuente).
- Menos dolores de cabeza por mantenimiento: La IA de Thunderbit resiste pequeños cambios en los sitios, reduciendo roturas.
- Integración con herramientas empresariales: Exportación directa a Google Sheets, Airtable y Notion; se acabó pelearse con CSV (fuente).
- Velocidad para aportar valor: Pasa de una idea a datos en minutos, no en días.
- Curva de aprendizaje: Si puedes navegar por la web y describir lo que necesitas, puedes usar Thunderbit.
- Adaptabilidad: Extrae datos de sitios web, PDF, imágenes y más, todo con la misma herramienta.
Thunderbit no es solo un raspador: es un asistente de datos que encaja en tu flujo de trabajo, ya estés en ventas, marketing, ecommerce o inmobiliario.
Probar el Raspador Web IA de Thunderbit
Buenas prácticas de raspado de páginas web con herramientas de Raspador Web IA
Para sacar el máximo partido a los raspadores web con IA, estos son mis mejores consejos:
- Define con claridad tus necesidades de datos: Ten claro qué campos quieres, cuántas páginas y en qué formato los necesitas.
- Aprovecha las sugerencias de IA: Usa la detección de campos y las sugerencias de las herramientas para captar datos importantes que podrías pasar por alto (fuente).
- Empieza poco a poco y valida: Prueba con una muestra pequeña, revisa la salida y ajusta lo necesario.
- Gestiona el contenido dinámico: Asegúrate de que tu herramienta admite contenido dinámico e interacciones (paginación, scroll infinito, etc.).
- Respeta las políticas del sitio web: Revisa robots.txt, evita extraer datos sensibles y respeta los límites de ritmo.
- Integra para automatizar: Usa las funciones de exportación y los webhooks para conectar los datos extraídos directamente con tu flujo de trabajo.
- Mantén la calidad de los datos: Haz comprobaciones básicas, usa posprocesamiento y supervisa errores.
- Sé conciso con los prompts: Al usar herramientas impulsadas por IA, unas instrucciones claras y específicas dan mejores resultados.
- Aprende de la comunidad: Únete a foros y comunidades para encontrar consejos y resolver problemas.
- Mantente al día: Las herramientas de IA evolucionan rápido; vigila las nuevas funciones y mejoras.
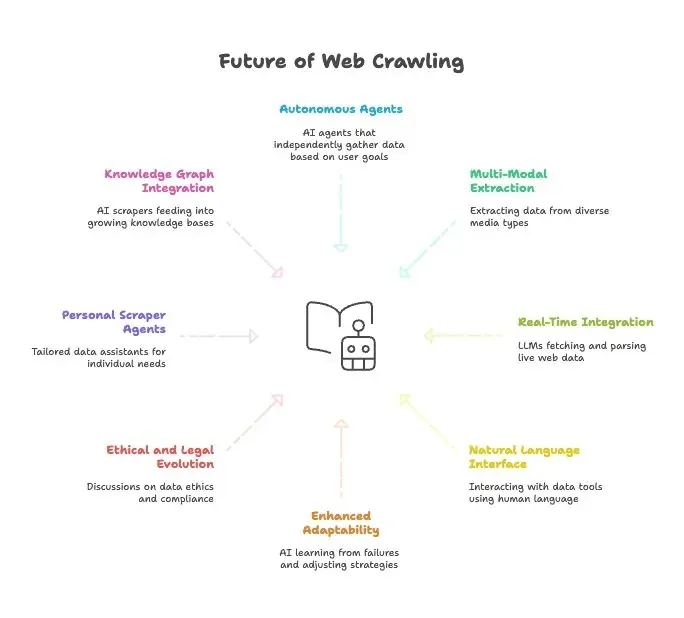
El futuro del raspado web: IA, LLM y el auge de los agentes de raspado web en lenguaje natural
De cara al futuro, la convergencia entre la IA y el raspado web no hace más que acelerarse:
- Agentes de scraping totalmente autónomos: Pronto solo le dirás a un agente de IA cuál es tu objetivo final y él averiguará cómo conseguir los datos.
- Extracción de datos multimodal: Los raspadores sacarán datos de texto, imágenes, PDF e incluso vídeos.
- Integración en tiempo real con modelos de IA: Los LLM tendrán módulos integrados para buscar y analizar datos web en vivo.
- Todo en lenguaje natural: Hablaremos con nuestras herramientas de datos como hablamos con las personas, haciendo que la recopilación y transformación de datos sea accesible para todos.
- Mayor adaptabilidad: Los raspadores con IA aprenderán de los fallos y adaptarán sus estrategias automáticamente.
- Evolución ética y legal: Veremos más conversación sobre ética de los datos, cumplimiento y uso justo.
- Agentes personales de scraping: Imagina un asistente personal de datos que reúna noticias, ofertas de empleo y más, ajustado a tus necesidades.
- Integración con grafos de conocimiento: Los raspadores con IA alimentarán de forma continua bases de conocimiento cada vez más grandes, potenciando una IA más inteligente.
En resumen: el futuro del raspado web está entrelazado con el futuro de la IA. Las herramientas son cada día más inteligentes, más autónomas y más accesibles.
Conclusión: desbloquear valor empresarial con el web crawler con IA adecuado
El raspado web ha pasado de ser una habilidad técnica de nicho a una capacidad empresarial clave, gracias a la IA. Las 15 herramientas que he cubierto aquí representan lo mejor de lo posible en 2026, desde potencias para desarrolladores hasta asistentes pensados para negocios.
¿El verdadero secreto? Elegir la herramienta adecuada puede multiplicar de forma dramática el valor que obtienes de los datos web. Para equipos no técnicos, Thunderbit es la forma más sencilla de convertir la web en una base de datos estructurada y lista para análisis: sin código, sin complicaciones, solo resultados.
Así que, tanto si estás reuniendo leads, vigilando a la competencia o alimentando tu próximo modelo de IA, tómate el tiempo para evaluar tus necesidades, prueba algunas herramientas y descubre cuál te funciona. Y si quieres vivir hoy el futuro del raspado web, prueba Thunderbit. La información que necesitas está a solo un prompt de distancia.
¿Quieres saber más? Consulta el blog de Thunderbit para leer análisis en profundidad, tutoriales y lo último en extracción de datos impulsada por IA.
Lecturas adicionales:
- Qué es el data scraping y cómo hacerlo en 2026
- Cómo extraer datos de sitios web a Excel usando IA
- Las mejores herramientas y software de raspado web en 2026
Probar Raspador Web IA Get Started Free
Preguntas frecuentes
1. ¿Qué es un web crawler con IA y en qué se diferencia de los raspadores web tradicionales?
Un web crawler con IA usa procesamiento del lenguaje natural y aprendizaje automático para entender, extraer y estructurar datos web. A diferencia de los raspadores tradicionales, que requieren programación manual y selectores XPath, las herramientas con IA pueden gestionar contenido dinámico, adaptarse a cambios de diseño e interpretar instrucciones del usuario en inglés sencillo.
2. ¿Quién debería usar herramientas de raspado web con IA como Thunderbit?
Thunderbit está diseñado tanto para usuarios no técnicos como técnicos. Es ideal para profesionales de ventas, marketing, operaciones, investigación y ecommerce que quieren extraer datos estructurados de sitios web, PDF o imágenes, sin escribir código.
3. ¿Qué funciones hacen que Thunderbit destaque frente a otros web crawlers con IA?
Thunderbit ofrece una interfaz en lenguaje natural, crawling multinivel, estructuración automática de datos, soporte OCR y exportaciones fluidas a plataformas como Google Sheets y Airtable. También incluye sugerencias de campos impulsadas por IA y plantillas predefinidas para sitios populares.
4. ¿Hay opciones gratuitas para el raspado web con IA en 2026?
Sí. Muchas herramientas como Thunderbit, Browse AI y DataMiner ofrecen planes gratuitos con uso limitado. Para desarrolladores, opciones de código abierto como Crawl4AI y ScrapeGraphAI ofrecen funcionalidad completa sin coste, aunque requieren configuración técnica.
5. ¿Cómo elijo el web crawler con IA adecuado para mis necesidades?
Empieza por identificar tus objetivos de datos, tu capacidad técnica, tu presupuesto y tus requisitos de escala. Si quieres una solución sin código y fácil de usar, Thunderbit o Browse AI son excelentes opciones. Para necesidades personalizadas o a gran escala, herramientas como Apify o Bright Data encajan mejor.




