Déjame contarte cómo fueron mis primeros pasos en el mundo del raspado web. Imagina la escena: año 2015, en un piso pequeño de Nueva Jersey, con tres cafés encima y peleando con un script de Python que se rompía cada vez que la web objetivo cambiaba su diseño. ¿Mis armas en ese entonces? Beautiful Soup y Selenium. Avancemos hasta 2025 y el debate sobre “beautiful soup vs selenium” sigue vivo, pero el panorama ha cambiado por completo gracias a la inteligencia artificial, de formas que ni soñaba en aquel entonces. Hoy, las herramientas no solo leen HTML: entienden el contenido, navegan enlaces como si fueran personas, extraen datos estructurados con instrucciones en lenguaje natural e incluso pueden limpiar, resumir o traducir la información al instante.

Hoy el raspado web ya no es solo cosa de programadores. Es una tarea clave para equipos de ventas, marketing, ecommerce y operaciones que necesitan datos frescos y bien organizados, ¡para ayer! Con el mercado de software de scraping superando los y nuevas herramientas con IA como revolucionando el sector, la pregunta ya no es solo “¿Qué scraper de Python uso?”, sino “¿Cómo consigo los datos que necesito con el menor esfuerzo, sin líos técnicos ni estar todo el día manteniendo scripts?” Vamos a meternos de lleno en la comparativa beautiful soup vs selenium y ver cómo la IA está cambiando las reglas del juego.
Beautiful Soup vs Selenium: ¿En qué se diferencian?
Si alguna vez buscaste “python web scraper” en Google, seguro que te topaste con y . Pero, ¿qué los hace distintos?
Imagina a Beautiful Soup como ese bibliotecario que te encuentra lo que buscas en un abrir y cerrar de ojos. Es una librería de Python pensada para analizar y extraer datos de archivos HTML o XML estáticos. Si la información que necesitas ya está en el código fuente de la página, Beautiful Soup la localiza, la organiza y te la entrega lista para usar. Es rápido, ligero y no necesita “ver” la página como lo haría una persona: simplemente lee el HTML.
Selenium, en cambio, es como un robot que puede usar un navegador real. Automatiza acciones en el navegador: hacer clic en botones, rellenar formularios, iniciar sesión, desplazarse y esperar a que cargue el JavaScript. Selenium es ideal cuando los datos solo aparecen tras alguna interacción o cuando la página se construye dinámicamente con JavaScript.
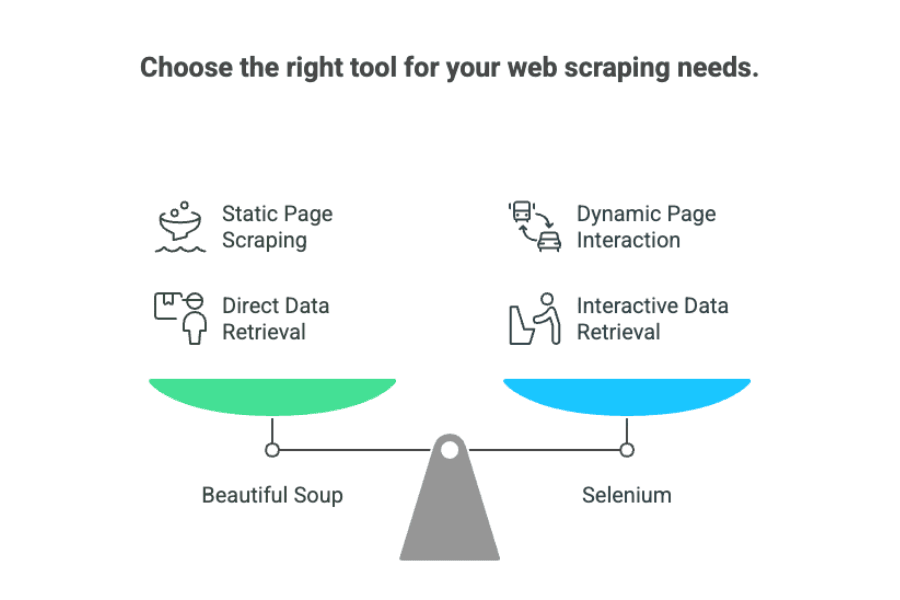
Así que, en el debate “beautiful soup vs selenium”, la clave es:
- Beautiful Soup: Perfecto para páginas estáticas donde los datos están en el HTML.
- Selenium: Mejor para sitios dinámicos que requieren interacción o esperar a que cargue el contenido.
Si eres usuario de negocio, aquí va una comparación sencilla:
- Beautiful Soup es como copiar información de un catálogo impreso.
- Selenium es como mandar a alguien a la tienda para hojear el catálogo, pulsar algunos botones y conseguir los precios más recientes.
Retos Comunes: Limitaciones de Beautiful Soup y Selenium
Ahora, hablemos de los problemas reales. Después de pasar más horas de las que quisiera arreglando scrapers rotos, estos son los principales desafíos de Beautiful Soup y Selenium:
1. Fragilidad ante Cambios en la Web
Ambas herramientas son muy sensibles a los cambios en la estructura de las páginas. Si el dueño de la web cambia una clase o mueve un div, tu scraper puede dejar de funcionar de la noche a la mañana. Como , “el mantenimiento puede costar diez veces más que el desarrollo”. Duele, ¿verdad?
2. Velocidad (o la falta de ella)
- Beautiful Soup es rápido para analizar, pero si raspas miles de páginas una a una, puede llevar tiempo.
- Selenium es mucho más lento: cada página requiere abrir un navegador, esperar scripts y simular interacciones. Escalar Selenium implica abrir muchos navegadores, lo que consume CPU y memoria.
3. Poca Reutilización de Código
Cada web es diferente. Eso significa que tienes que escribir lógica personalizada para cada sitio, y si la web cambia, vuelta a empezar. No hay un script universal.
4. Complejidad Técnica
Ambas requieren conocimientos de Python, selectores HTML/CSS y (en Selenium) saber manejar drivers de navegador. Para quienes no son desarrolladores, la curva de aprendizaje es empinada.
5. Mantenimiento Constante
Mantener los scrapers funcionando es un trabajo sin fin. Las webs cambian, las medidas anti-bots se endurecen y hay que estar actualizando scripts. Para usuarios de negocio, esto significa depender de desarrolladores o subcontratar el scraping.
Más Allá de los Scrapers Tradicionales en Python: El Auge de las Soluciones con IA
Aquí es donde la cosa se pone interesante. En los últimos años han surgido raspadores web con IA: herramientas que usan modelos de lenguaje (como GPT) para “leer” y extraer datos de webs, sin necesidad de programar.
Llega Thunderbit: Raspador Web IA para Usuarios de Negocio
es una extensión de Chrome que te permite extraer datos de cualquier web en solo dos clics. Sin Python, sin código, sin pelear con drivers. Solo apuntas, haces clic y dejas que la IA haga el trabajo pesado.
Por Qué los Raspadores IA como Thunderbit Son un Cambio de Juego
- Sin código, sin esfuerzo: Thunderbit va más allá del “no code”: es “sin esfuerzo”. No tienes que configurar nada. Instala la , navega a la página objetivo y deja que la IA sugiera los campos a extraer.
- Maneja contenido dinámico: Al funcionar en el navegador, Thunderbit ve todo lo que tú ves, incluidos datos cargados por JavaScript, tras clics o detrás de inicios de sesión.
- Rápido y preciso: La IA de Thunderbit puede extraer datos de varias páginas a la vez, y está diseñada para ser ágil y exacta, especialmente en casos de negocio como generación de leads, ecommerce o inmobiliaria.
- Sin mantenimiento: Piensa en Thunderbit como un asistente IA que nunca se cansa. Si la web cambia, la IA se adapta. Olvídate de reescribir código cada vez que se mueve un div.
- Limpieza y enriquecimiento de datos: Thunderbit no solo extrae datos en bruto: puede etiquetar, formatear, traducir e incluso resumir la información mientras la recopila. Es como darle 10,000 páginas web a ChatGPT y pedirle una hoja de cálculo limpia y estructurada.
¿El resultado? Los usuarios de negocio pueden obtener los datos que necesitan sin depender de IT ni aprender Python.
Thunderbit vs Beautiful Soup vs Selenium: Comparativa Rápida
Así se comparan estas herramientas para usuarios de negocio:
| Criterio | Beautiful Soup | Selenium | Thunderbit (Raspador Web IA) |
|---|---|---|---|
| Instalación | Instalación simple en Python | Compleja (drivers de navegador) | Extensión de Chrome, sin configuración |
| Facilidad de uso | Fácil para programadores | Más difícil, requiere código | Sin código, amigable para negocio |
| Velocidad | Rápido en páginas estáticas | Lento (por el navegador) | Rápido en trabajos pequeños/medios, no para millones |
| Contenido dinámico | No puede con JS | Maneja todo lo dinámico | Maneja todo lo dinámico |
| Mantenimiento | Alto (se rompe con cambios) | Alto (se rompe, drivers) | Bajo (la IA se adapta a cambios) |
| Escalabilidad | Bien en estáticas, requiere infraestructura | Difícil de escalar, consume recursos | Mejor para trabajos pequeños/medios, no scraping masivo |
| Limpieza de datos | Manual, post-procesado | Manual, post-procesado | Integrado: etiqueta, formatea, traduce, resume |
| Integraciones | Código personalizado | Código personalizado | 1 clic a Excel, Sheets, Airtable, Notion |
| Conocimientos técnicos | Requiere Python | Python + navegador | No se necesita ninguno |
Funciones Avanzadas: Cómo Thunderbit Revoluciona el Web Scraping para Empresas
Veamos qué hace que Thunderbit sea un salto adelante para usuarios de negocio:
1. Extracción de Datos con IA
Thunderbit utiliza IA para “leer” páginas web y sugerir los mejores campos a extraer. Solo tienes que hacer clic en “Sugerir campos IA”, revisar las columnas y pulsar “Extraer”. Sin escribir selectores ni analizar HTML.
2. Raspado de Subpáginas
¿Necesitas datos de una lista de productos y luego detalles de cada uno? Thunderbit puede visitar automáticamente cada subpágina y enriquecer tu tabla de datos, sin configuraciones extra.
3. Limpieza, Etiquetado y Traducción de Datos
La IA de Thunderbit puede:
- Etiquetar datos: Añadir categorías o etiquetas mientras extrae.
- Formatear datos: Estandarizar teléfonos, fechas o precios.
- Traducir: Traducir al instante el contenido extraído al idioma que prefieras.
- Resumir: Generar resúmenes o puntos clave de textos largos.
Es como tener un analista de datos integrado en tu scraper.
4. Integraciones Sin Fricción
Exporta tus datos directamente a Excel, Google Sheets, Airtable o Notion con un solo clic. Olvídate de pelear con archivos CSV.
5. Sin Código, Sin Mantenimiento
Thunderbit está pensado para usuarios de negocio, no para desarrolladores. No necesitas saber Python ni preocuparte por el mantenimiento. La IA se adapta a los cambios y tus flujos siguen funcionando.
Para más detalles sobre Thunderbit, revisa .
¿Qué Herramienta Elegir? Consejos Prácticos para Empresas
Entonces, ¿cómo decidir entre Beautiful Soup, Selenium y Thunderbit? Aquí tienes mis recomendaciones tras años raspando (y rompiendo) webs:
1. ¿Cuántos Datos Necesitas?
- Trabajos pequeños o medianos (cientos o miles de páginas): Thunderbit es ideal: configuración rápida, sin código y limpieza de datos integrada.
- Scraping a gran escala (decenas de miles o millones de páginas): Beautiful Soup (con frameworks como Scrapy) o soluciones empresariales. Thunderbit aún no está pensado para scraping masivo.
2. ¿Tienes Recursos de Programación?
- Tienes desarrolladores: Beautiful Soup y Selenium te dan control total.
- No tienes desarrolladores o necesitas rapidez: Thunderbit u otra herramienta con IA.
3. ¿Con Qué Frecuencia Cambia la Web?
- Cambios frecuentes: La IA de Thunderbit se adapta sola, ahorrando dolores de cabeza.
- Cambios raros: Beautiful Soup o Selenium pueden servir, pero prepárate para actualizar scripts.
4. ¿Necesitas Limpieza o Enriquecimiento de Datos?
- Sí: Thunderbit puede etiquetar, formatear, traducir y resumir mientras extrae.
- No, solo datos en bruto: Beautiful Soup o Selenium.
Lista de Decisión
| Pregunta | Mejor Herramienta |
|---|---|
| No tienes desarrollador, necesitas datos ya | Thunderbit |
| Necesitas limpieza/traducción de datos al extraer | Thunderbit |
| Escala masiva, pipeline personalizado | Beautiful Soup/Scrapy |
| Cambios frecuentes en la web, quieres bajo mantenimiento | Thunderbit |
Conclusión: El Futuro de los Scrapers en Python
El raspado web ha evolucionado mucho desde mis inicios peleando con scripts frágiles en Python. En 2025, el debate “beautiful soup vs selenium” sigue siendo relevante, pero la llegada de herramientas con IA como Thunderbit está cambiando el panorama para los usuarios de negocio.
Beautiful Soup sigue siendo el rey para analizar HTML estático: rápido, ligero y perfecto para tareas sencillas. Selenium es la opción para automatizar navegadores y extraer datos de sitios dinámicos, aunque requiere más configuración y mantenimiento.
Pero si quieres olvidarte del código, evitar problemas de mantenimiento y obtener datos limpios y estructurados con el mínimo esfuerzo, los raspadores web IA como Thunderbit son el nuevo estándar. No solo son “sin código”, son “sin esfuerzo”. Y para equipos de ventas, ecommerce y operaciones que necesitan datos ya (no después de una semana de arreglos), es una gran ventaja.
¿Mi consejo? Revisa tus flujos actuales de scraping. Si estás cansado de scripts rotos, mantenimiento interminable o de esperar a los desarrolladores, prueba Thunderbit. El futuro del raspado web es más inteligente, rápido y accesible que nunca, y personalmente, tengo muchas ganas de ver hasta dónde llega.
¿Quieres ver Thunderbit en acción? o explora más guías en el . Y si te interesa extraer datos de sitios específicos (Amazon, Twitter, PDFs y más), aquí tienes recursos:
¡Feliz scraping! Que tus datos siempre sean estructurados, frescos y sin dolores de cabeza.