

Imagina la siguiente escena: te encuentras frente a una página web repleta de miles de productos y tu jefe (o tu yo más curioso por los datos) quiere todos esos precios, nombres y reseñas en una hoja de cálculo... para ayer. Podrías pasarte horas copiando y pegando, o dejar que Python haga el trabajo duro por ti. Aquí es donde entra el raspado web, y créeme, no es solo cosa de frikis con sudadera o ingenieros de Silicon Valley. Hoy en día, el raspado web se ha vuelto una habilidad clave para equipos de ventas, agentes inmobiliarios, analistas de mercado y muchos más. El mercado global de software de raspado web ya supera los $1.000 millones y se espera que más que se duplique para 2032. Eso son muchísimos datos... y un montón de oportunidades.
Como cofundador de Thunderbit, llevo años ayudando a empresas a automatizar la recolección de datos. Pero antes de que los raspadores con IA como Thunderbit hicieran la extracción de datos web tan fácil como dar dos clics, aprendí con el stack clásico de Python: beautiful soup, requests y mucha prueba y error. En esta guía te cuento qué es beautiful soup, cómo instalarlo y usarlo, y por qué sigue siendo una herramienta fundamental. Después, te mostraré cómo soluciones con IA como Thunderbit están revolucionando el sector (y ahorrando muchos dolores de cabeza). Así que, tanto si eres novato en Python, usuario de negocio o simplemente tienes curiosidad por el scraping, acompáñame.
¿Qué es BeautifulSoup? Descubre el poder del raspado web en Python
Vamos a lo básico. beautiful soup (o BS4) es una librería de Python para extraer datos de archivos HTML y XML. Imagínala como tu detective personal de HTML: le das un código web caótico y lo transforma en una estructura ordenada y fácil de recorrer. De repente, conseguir el nombre de un producto, un precio o una reseña es tan sencillo como pedirlo por etiqueta o clase.
beautiful soup no descarga páginas web por sí sola (para eso están librerías como requests), pero una vez tienes el HTML, buscar, filtrar y extraer los datos que necesitas es pan comido. No es casualidad que, según una encuesta reciente, más del 43% de los desarrolladores elijan beautiful soup como su herramienta de raspado web favorita, por encima de cualquier otra.
beautiful soup se usa en todo tipo de proyectos: desde investigaciones académicas hasta análisis de e-commerce o generación de leads. He visto equipos de marketing crear listas de influencers, reclutadores extraer ofertas de empleo y periodistas automatizar investigaciones. Es flexible, tolerante a errores y, si sabes un poco de Python, bastante accesible.
¿Por qué usar BeautifulSoup? Ventajas y ejemplos reales
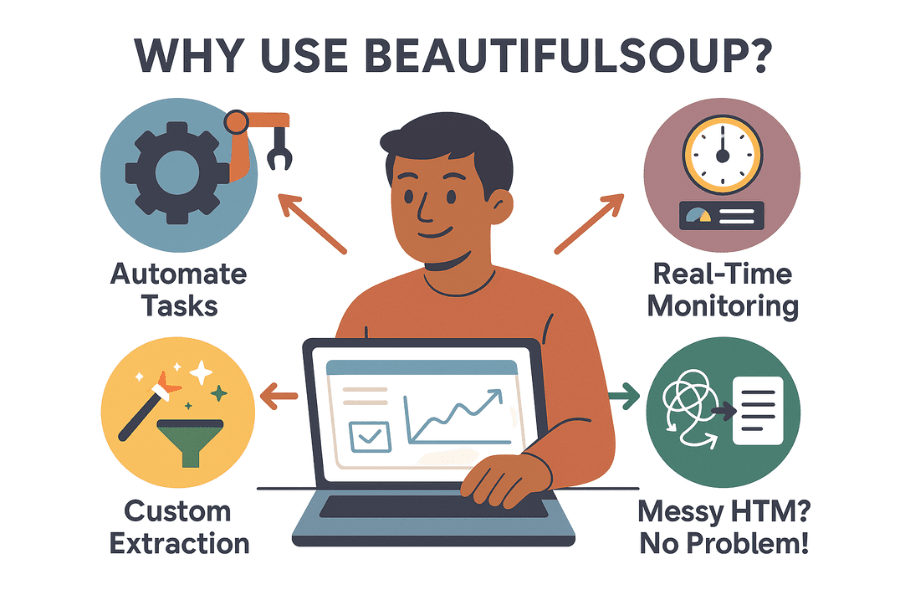
Entonces, ¿por qué tantos profesionales y amantes de los datos apuestan por beautiful soup? Aquí tienes algunas de sus ventajas principales:
- Automatiza tareas repetitivas: ¿Para qué copiar y pegar si puedes dejar que un script lo haga por ti? beautiful soup puede recopilar miles de datos en minutos, liberando a tu equipo para tareas más importantes.
- Monitorización en tiempo real: Configura scripts para vigilar precios de la competencia, inventarios o titulares de noticias de forma automática. Si tu rival baja precios, lo sabrás antes de terminar el café.
- Extracción personalizada: ¿Necesitas los 10 productos más populares con valoraciones y reseñas? beautiful soup te da control total sobre qué datos recoges y cómo los procesas.
- Soporta HTML desordenado: Aunque el código de una web sea un caos, beautiful soup suele ser capaz de interpretarlo.
Aquí tienes algunos ejemplos prácticos:
| Caso de uso | Descripción | Resultado |
|---|---|---|
| Generación de leads | Extrae emails y teléfonos de directorios o LinkedIn | Crea listas de ventas segmentadas |
| Monitorización de precios | Vigila precios de la competencia en tiendas online | Ajusta tus precios en tiempo real |
| Investigación de mercado | Recoge reseñas, valoraciones o detalles de productos | Detecta tendencias y mejora productos |
| Datos inmobiliarios | Agrupa anuncios de portales como Zillow o Realtor.com | Analiza tendencias de precios o inversiones |
| Agregación de contenido | Reúne noticias, blogs o menciones en redes sociales | Alimenta newsletters o análisis de sentimiento |
¿Y el retorno? Un minorista británico usó el scraping para vigilar a la competencia y aumentó sus ventas un 4%. ASOS duplicó sus ventas internacionales ajustando su marketing según los precios locales extraídos. En resumen: los datos extraídos impulsan decisiones reales de negocio.
Primeros pasos: Cómo instalar BeautifulSoup en Python
¿Listo para ponerte manos a la obra? Así puedes instalar beautiful soup:
Paso 1: Instala beautiful soup (la versión correcta)
Asegúrate de instalar la última versión: beautiful soup 4 (bs4). ¡No te confundas con el nombre antiguo!
pip install beautifulsoup4
Si usas macOS o Linux, puede que necesites pip3 o añadir sudo:
sudo pip3 install beautifulsoup4
Consejo: Si ejecutas pip install beautifulsoup (sin el “4”), instalarás una versión antigua e incompatible. Me ha pasado, y no es nada divertido de arreglar.
Paso 2: Instala un parser (opcional, pero recomendable)
beautiful soup puede usar el parser HTML integrado de Python, pero para mayor velocidad y fiabilidad, instala lxml y html5lib:
pip install lxml html5lib
Paso 3: Instala Requests (para descargar páginas web)
beautiful soup analiza HTML, pero primero tienes que conseguirlo. La librería requests es la más utilizada:
pip install requests
Paso 4: Verifica tu entorno de Python
Asegúrate de usar Python 3. Si trabajas en un IDE (PyCharm, VS Code), revisa el intérprete. Si ves errores de importación, puede que estés instalando paquetes en el entorno equivocado. En Windows, py -m pip install beautifulsoup4 ayuda a instalar en la versión correcta.
Paso 5: Prueba tu instalación
Haz una prueba rápida:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
Si ves la etiqueta <title>, todo está listo.
Fundamentos de BeautifulSoup: conceptos y sintaxis clave
Vamos a repasar los objetos y conceptos principales de beautiful soup:
- Objeto BeautifulSoup: Es la raíz del árbol HTML analizado. Se crea con
BeautifulSoup(html, parser). - Tag: Representa una etiqueta HTML o XML (como
<div>,<p>,<span>). Puedes acceder a atributos, hijos y texto. - NavigableString: Es el texto dentro de una etiqueta.
Entendiendo el árbol de análisis
Imagina tu HTML como un árbol genealógico: la etiqueta <html> es el ancestro, <head> y <body> son sus hijos, y así sucesivamente. beautiful soup te permite recorrer este árbol con sintaxis de Python.
Ejemplo:
html = """
<html>
<head><title>Mi página de prueba</title></head>
<body>
<p class="story">Érase una vez <b>tres hermanas pequeñas</b>...</p>
</body>
</html>
"""
soup = BeautifulSoup(html, "html.parser")
# Acceder a la etiqueta title
print(soup.title) # <title>Mi página de prueba</title>
print(soup.title.string) # Mi página de prueba
# Acceder al primer <p> y su clase
p_tag = soup.find('p', class_='story')
print(p_tag['class']) # ['story']
# Obtener todo el texto dentro de <p>
print(p_tag.get_text()) # Érase una vez tres hermanas pequeñas...
Navegación y búsqueda
- Accesores de elementos:
soup.head,soup.body,tag.parent,tag.children - find() / find_all(): Busca etiquetas por nombre o atributos.
- select(): Usa selectores CSS para consultas más complejas.
Ejemplo:
# Encontrar todos los enlaces
for link in soup.find_all('a'):
print(link.get('href'))
# Ejemplo con selector CSS
for item in soup.select('div.product > span.price'):
print(item.get_text())
Práctica: tu primer raspador web con BeautifulSoup
Vamos a lo práctico. Supón que quieres extraer títulos y precios de productos en una página de resultados de e-commerce (por ejemplo, Etsy). Así lo harías:
Paso 1: Descarga la página web
import requests
from bs4 import BeautifulSoup
url = "https://www.etsy.com/search?q=clothes"
headers = {"User-Agent": "Mozilla/5.0"} # Algunos sitios requieren user-agent
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, 'html.parser')
Paso 2: Analiza y extrae los datos
Supón que cada producto está en un <li class="wt-list-unstyled">, el título en <h3 class="v2-listing-card__title"> y el precio en <span class="currency-value">.
items = []
for item in soup.find_all('li', class_='wt-list-unstyled'):
title_tag = item.find('h3', class_='v2-listing-card__title')
price_tag = item.find('span', class_='currency-value')
if title_tag and price_tag:
title = title_tag.get_text(strip=True)
price = price_tag.get_text(strip=True)
items.append((title, price))
Paso 3: Guarda en CSV o Excel
Con el módulo csv de Python:
import csv
with open("etsy_products.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["Título del producto", "Precio"])
writer.writerows(items)
O con pandas:
import pandas as pd
df = pd.DataFrame(items, columns=["Título del producto", "Precio"])
df.to_csv("etsy_products.csv", index=False)
¡Y ya tienes una hoja de cálculo lista para analizar, reportar o presumir!
Retos de BeautifulSoup: mantenimiento, anti-bots y limitaciones
Aquí va la parte sincera: aunque beautiful soup me encanta, tiene sus retos, sobre todo si quieres escalar o mantener tus scripts a largo plazo.
1. Frágil ante cambios en la web
Las webs cambian su diseño, nombres de clases o el orden de los elementos constantemente. Tu script de beautiful soup solo funciona mientras los selectores sigan igual. Si la web cambia el HTML, tu script puede romperse... y a veces ni te enteras. Si raspas decenas (o cientos) de sitios, mantenerlos actualizados puede ser una pesadilla.
2. Medidas anti-scraping
Hoy en día, muchas webs usan defensas como CAPTCHAs, bloqueos de IP, límites de velocidad o contenido dinámico con JavaScript. beautiful soup no puede con esto por sí solo. Necesitarás proxies, navegadores sin cabeza o incluso servicios externos para resolver CAPTCHAs. Es como un juego del gato y el ratón con los administradores de la web.
3. Escalabilidad y rendimiento
beautiful soup es ideal para scripts puntuales o extracciones moderadas. Pero si necesitas raspar millones de páginas o ejecutar procesos en paralelo, tendrás que programar manejo de errores, concurrencia e infraestructura extra. Es posible, pero requiere mucho trabajo.
4. Barrera técnica
Seamos sinceros: si no te manejas con Python, HTML y depuración, beautiful soup puede intimidar. Incluso para desarrolladores experimentados, el scraping suele ser un ciclo de inspeccionar, programar, ejecutar, ajustar y repetir.
5. Aspectos legales y éticos
El scraping puede rozar zonas grises legales, sobre todo si ignoras el robots.txt o los términos de uso. Con código, eres responsable de respetar las normas del sitio, limitar la frecuencia y tratar los datos de forma ética.
Más allá de BeautifulSoup: cómo herramientas con IA como Thunderbit facilitan el scraping
Extrae datos de cualquier web usando IA Get Started Free
Aquí es donde la cosa se pone interesante. Con la llegada de la IA, herramientas como Thunderbit han democratizado el raspado web: ya no es solo para programadores.
Thunderbit es una extensión de Chrome con IA que te permite extraer datos de cualquier web en dos clics. Sin Python, sin selectores, sin dolores de cabeza de mantenimiento. Solo abre la página, haz clic en “AI Suggest Fields” y la IA de Thunderbit detecta automáticamente los datos que probablemente quieras (nombres de productos, precios, reseñas, emails, teléfonos, etc.). Luego, haz clic en “Scrape” y listo.
Thunderbit vs. BeautifulSoup: comparación directa
| Funcionalidad | BeautifulSoup (con código) | Thunderbit (IA sin código) |
|---|---|---|
| Dificultad de configuración | Requiere programar en Python, saber HTML y depurar | Sin código—la IA detecta los campos, interfaz intuitiva |
| Velocidad para obtener datos | Horas (escribiendo y probando código) | Minutos (2–3 clics) |
| Adaptabilidad a cambios | Se rompe si cambia el HTML; hay que actualizar manualmente | La IA se adapta a muchos cambios; plantillas para sitios populares |
| Paginación/subpáginas | Hay que programar bucles y peticiones para cada página | Paginación y subpáginas integradas—solo activa una opción |
| Gestión anti-bots | Hay que añadir proxies, resolver CAPTCHAs, simular navegador | Muchos bloqueos se evitan automáticamente; el contexto del navegador ayuda |
| Procesamiento de datos | Control total en el código, pero hay que programarlo | IA integrada para resumir, categorizar, traducir y limpiar datos |
| Opciones de exportación | Código personalizado para CSV, Excel, bases de datos, etc. | Exportación con un clic a CSV, Excel, Google Sheets, Airtable, Notion |
| Escalabilidad | Ilimitada si montas la infraestructura; gestionas errores y escalado | Alta—la nube/extensión gestiona cargas paralelas, programación y grandes volúmenes (según plan/créditos) |
| Coste | Gratis (open-source), pero consume tiempo y mantenimiento | Freemium (gratis para tareas pequeñas, planes de pago para más volumen), pero ahorra mucho tiempo y esfuerzo |
| Flexibilidad | Máxima—el código puede hacer lo que quieras, si lo programas | Cubre la mayoría de casos estándar; algunos casos complejos requieren código |
Si quieres profundizar, visita el blog de Thunderbit y la documentación de funciones.
Paso a paso: scraping con Thunderbit vs. BeautifulSoup
Comparemos los flujos de trabajo extrayendo datos de productos en una tienda online.
Con BeautifulSoup
- Inspecciona la estructura HTML de la web con las herramientas del navegador.
- Escribe código Python para descargar la página (
requests), analizarla (beautiful soup) y extraer los campos deseados. - Ajusta los selectores (clases, rutas de etiquetas) hasta obtener los datos correctos.
- Programa la paginación con bucles para seguir los enlaces “Siguiente”.
- Exporta los datos a CSV o Excel con código adicional.
- Si la web cambia, repite los pasos 1–5.
Tiempo estimado: 1–2 horas por sitio nuevo (más si hay bloqueos anti-bot).
Con Thunderbit
- Abre la web objetivo en Chrome.
- Haz clic en la extensión Thunderbit.
- Haz clic en “AI Suggest Fields”—la IA propone columnas como Nombre de producto, Precio, etc.
- Ajusta las columnas si lo necesitas y haz clic en “Scrape”.
- Activa la paginación o subpáginas con un interruptor si hace falta.
- Previsualiza los datos en una tabla y expórtalos al formato que prefieras.
Tiempo estimado: 2–5 minutos. Sin código, sin depuración, sin mantenimiento.
Extra: Thunderbit también puede extraer emails, teléfonos, imágenes e incluso rellenar formularios automáticamente. Es como tener un becario ultrarrápido que nunca se queja de tareas repetitivas.
Prueba Thunderbit AI Web Scraper gratis
Conclusión y puntos clave
Qué es el data scraping y cómo hacerlo en 2025 Get Started Free
El raspado web ha pasado de ser un truco de hackers a una herramienta esencial para empresas, desde la generación de leads hasta la investigación de mercados. beautiful soup sigue siendo una excelente puerta de entrada para quienes saben algo de Python, ofreciendo flexibilidad y control para proyectos a medida. Pero a medida que las webs se vuelven más complejas—y los usuarios de negocio exigen resultados más rápidos y sencillos—herramientas con IA como Thunderbit están cambiando las reglas del juego.

Si te gusta programar y quieres algo totalmente personalizado, beautiful soup sigue siendo tu mejor opción. Pero si prefieres evitar el código, olvidarte del mantenimiento y obtener resultados en minutos, Thunderbit es el camino. ¿Por qué invertir horas programando si puedes resolverlo con IA?
¿Listo para probarlo? Descarga la extensión de Chrome de Thunderbit, o explora más tutoriales en el blog de Thunderbit. Y si te sigue picando la curiosidad por Python, sigue experimentando con beautiful soup—pero no olvides estirar las muñecas después de tanto teclear.
¡Feliz scraping!
Prueba Thunderbit AI Web Scraper Get Started Free
Lecturas recomendadas:
- Documentación oficial de Beautiful Soup
- Qué es el data scraping y cómo hacerlo en 2025
- Cómo extraer datos de una web a Excel usando IA
- Canal de YouTube de Thunderbit
Si tienes dudas, anécdotas o quieres compartir tus batallas de scraping, deja un comentario o contáctame. Te aseguro que he roto más raspadores de los que la mayoría ha escrito.




