

Pongámonos serios un momento: Amazon es, a la vez, el centro comercial, el supermercado y la tienda de electrónica de medio internet. Si te dedicas a ventas, e-commerce u operaciones, ya intuyes que lo que pasa dentro de Amazon no se queda dentro de Amazon: te toca los precios, te condiciona el inventario y hasta marca cuál será el próximo producto estrella. El problema es que todos esos datos jugosos —productos, precios, valoraciones, reseñas— viven encerrados tras una interfaz pensada para que la gente compre, no para que tu equipo se nutra de información. Así que la pregunta es: ¿cómo sacas esa información sin gastar el fin de semana copiando y pegando como si siguiéramos en 1999?
Para eso está el web scraping. En esta guía te enseño dos caminos para extraer datos de productos de Amazon: el clásico de «arremángate y prográmalo en Python» y la vía moderna de «que la IA cargue con lo pesado» a través de un raspador web sin código como Thunderbit. Pasaremos por código Python de verdad (con sus trucos y sus parches), y después te muestro cómo Thunderbit te da esos mismos datos en un par de clics, sin tocar una línea de código. Da igual si eres desarrollador, analista de negocio o simplemente alguien harto de meter datos a mano: aquí hay algo para ti.
¿Por qué extraer datos de productos de Amazon? (amazon scraper python, web scraping with python)
Amazon no solo es el minorista online más grande del mundo: también es el mayor mercadillo a cielo abierto para la inteligencia competitiva. Con más de 600 millones de productos publicados y casi 2 millones de vendedores activos, es una mina de oro para quien quiera:

- Vigilar precios (y ajustar los tuyos al momento)
- Estudiar a la competencia (seguirle los lanzamientos, las valoraciones y las reseñas)
- Generar leads (localizar vendedores, proveedores o incluso posibles socios)
- Anticipar la demanda (mirando niveles de stock y posiciones de ventas)
- Captar tendencias de mercado (analizando reseñas y resultados de búsqueda)
Y no es palabrería: hay empresas reales sacándole un retorno tangible. Sin ir más lejos, un minorista de electrónica usó datos de precios de Amazon para subir sus márgenes de beneficio un 15%, y otra marca consiguió un 4% más de ventas y un 30% menos de tiempo de analista tras automatizar el seguimiento de precios de sus rivales.
Aquí tienes una tabla rápida con casos de uso y el tipo de retorno que cabe esperar:
| Caso de uso | Quién lo usa | ROI / beneficio típico |
|---|---|---|
| Supervisión de precios | E-commerce, operaciones | Aumento del margen de beneficio de 15%+, +4% en ventas, 30% menos tiempo de analista |
| Análisis de la competencia | Ventas, producto, operaciones | Ajustes de precio más rápidos, mayor competitividad |
| Investigación de mercado (reseñas) | Producto, marketing | Iteración de producto más rápida, mejores textos publicitarios, insights SEO |
| Generación de leads | Ventas | Más de 3.000 leads/mes, 8+ horas ahorradas por representante a la semana |
| Inventario y previsión de demanda | Operaciones, cadena de suministro | Reducción del 20% en sobreinventario, menos roturas de stock |
| Detección de tendencias | Marketing, directivos | Detección temprana de productos y categorías en auge |
Y ahora el dato que lo remata: más del 90% de las organizaciones ya reconoce un valor medible en la analítica de datos. Si no estás extrayendo datos de Amazon, estás dejando insights —y dinero— encima de la mesa.
Resumen: Amazon Scraper Python frente a herramientas de raspador web sin código
Hay dos vías principales para sacar los datos de Amazon del navegador y volcarlos en tus hojas de cálculo o paneles:
-
Amazon Scraper Python (web scraping with python):
Escribes tu propio script apoyándote en bibliotecas de Python como Requests y BeautifulSoup. Tienes control absoluto, sí, pero a cambio toca saber programar, lidiar con las defensas anti-bot y mantener el script cada vez que Amazon retoque su web.
-
Herramientas de raspador web sin código (como Thunderbit):
Usas una herramienta donde señalas, haces clic y extraes datos, sin escribir nada. Las opciones modernas como Thunderbit hasta tiran de IA para adivinar qué datos extraer, resolver subpáginas y paginación, y exportar directo a Excel o Google Sheets.
Así quedan frente a frente:
| Criterio | Raspador Python | Sin código (Thunderbit) |
|---|---|---|
| Tiempo de configuración | Alto (instalar, programar, depurar) | Bajo (instalar extensión) |
| Conocimientos necesarios | Se requiere programar | Ninguno (apuntar y hacer clic) |
| Flexibilidad | Ilimitada | Alta para casos de uso comunes |
| Mantenimiento | Tú corriges el código | La herramienta se actualiza sola |
| Gestión anti-bot | Tú gestionas proxies y cabeceras | Integrado, gestionado por ti |
| Escalabilidad | Manual (hilos, proxies) | Raspado en la nube, en paralelo |
| Exportación de datos | Personalizada (CSV, Excel, BD) | Un clic para Excel y Sheets |
| Coste | Gratis (tu tiempo + proxies) | Freemium, pagas al escalar |
En lo que sigue te llevo por los dos caminos: primero, cómo montar un raspador de Amazon en Python (con código real) y luego cómo lograr lo mismo con el raspador web con IA de Thunderbit.
Empezar con Amazon Scraper Python: requisitos previos y configuración
Antes de pelearnos con el código, dejemos el entorno a punto.
Vas a necesitar:
- Python 3.x (descárgalo desde python.org)
- Un editor de código (yo tiro de VS Code, pero vale cualquiera)
- Estas bibliotecas:
requests(para las solicitudes HTTP)beautifulsoup4(para analizar el HTML)lxml(analizador HTML rápido)pandas(para tablas de datos y exportación)re(expresiones regulares, ya viene de serie)
Instala las bibliotecas:
pip install requests beautifulsoup4 lxml pandas
Configuración del proyecto:
- Crea una carpeta nueva para tu proyecto.
- Abre el editor y crea un archivo de Python (por ejemplo,
amazon_scraper.py). - ¡Listo, ya lo tienes todo a mano!
Paso a paso: web scraping con Python para datos de productos de Amazon
Veamos cómo extraer una sola ficha de producto de Amazon. (Tranquilo, enseguida pasamos a raspar varios productos y varias páginas.)
1. Enviar solicitudes y obtener HTML
Lo primero, recuperar el HTML de una ficha de producto. (Cambia la URL por la de cualquier producto de Amazon.)
import requests
url = "<https://www.amazon.com/dp/B0ExampleASIN>"
response = requests.get(url)
html_content = response.text
print(response.status_code)
Aviso: lo más probable es que Amazon te bloquee esta solicitud tan básica. En lugar de la ficha del producto, igual te encuentras un error 503 o un CAPTCHA. ¿El motivo? Amazon sabe perfectamente que no eres un navegador de verdad.
Cómo manejar las medidas anti-bot de Amazon
A Amazon no le hacen ninguna gracia los bots. Para esquivar los bloqueos, te tocará:
- Configurar una cabecera User-Agent (pasar por Chrome o Firefox)
- Rotar los User-Agents (no repetir siempre el mismo)
- Espaciar las solicitudes (meter retrasos aleatorios)
- Usar proxies (para raspados a gran escala)
Así se montan las cabeceras:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
}
response = requests.get(url, headers=headers)
¿Quieres apretar un poco más? Arma una lista de User-Agents y ve rotándolos en cada solicitud. Para trabajos grandes lo suyo es un servicio de proxy (hay donde elegir), pero para raspados pequeños, con cabeceras y retrasos suele bastar.
Extraer campos clave del producto
Una vez tengas el HTML, toca analizarlo con BeautifulSoup.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, "lxml")
Vamos ahora a por lo importante:
Título del producto
title_elem = soup.find(id="productTitle")
product_title = title_elem.get_text(strip=True) if title_elem else None
Precio
El precio de Amazon puede asomar en varios sitios. Prueba con esto:
price = None
price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
if price_elem:
price = price_elem.get_text(strip=True)
else:
price_whole = soup.find("span", {"class": "a-price-whole"})
price_frac = soup.find("span", {"class": "a-price-fraction"})
if price_whole and price_frac:
price = price_whole.text + price_frac.text
Valoración y número de reseñas
rating_elem = soup.find("span", {"class": "a-icon-alt"})
rating = rating_elem.get_text(strip=True) if rating_elem else None
review_count_elem = soup.find(id="acrCustomerReviewText")
reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
reviews_count = reviews_text.split()[0] # por ejemplo, "1,554 ratings"
URL de la imagen principal
A veces Amazon esconde las imágenes en alta resolución dentro de un JSON metido en el HTML. Aquí va un apaño rápido con regex:
import re
match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
main_image_url = match.group(1) if match else None
O bien, saca directamente la etiqueta principal de la imagen:
img_tag = soup.find("img", {"id": "landingImage"})
img_url = img_tag['src'] if img_tag else None
Detalles del producto
Las especificaciones —marca, peso, dimensiones— suelen venir en una tabla:
details = {}
rows = soup.select("#productDetails_techSpec_section_1 tr")
for row in rows:
header = row.find("th").get_text(strip=True)
value = row.find("td").get_text(strip=True)
details[header] = value
O, si Amazon tira del formato «detailBullets»:
bullets = soup.select("#detailBullets_feature_div li")
for li in bullets:
txt = li.get_text(" ", strip=True)
if ":" in txt:
key, val = txt.split(":", 1)
details[key.strip()] = val.strip()
Imprime los resultados:
print("Título:", product_title)
print("Precio:", price)
print("Valoración:", rating, "basada en", reviews_count, "reseñas")
print("URL de la imagen principal:", main_image_url)
print("Detalles:", details)
Raspado de varios productos y manejo de paginación
Un producto está muy bien, pero lo normal es que quieras la lista entera. Así raspas resultados de búsqueda y varias páginas seguidas.
Obtener enlaces de producto desde una página de búsqueda
search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
res = requests.get(search_url, headers=headers)
soup = BeautifulSoup(res.text, "lxml")
product_links = []
for a in soup.select("h2 a.a-link-normal"):
href = a['href']
full_url = "<https://www.amazon.com>" + href
product_links.append(full_url)
Manejar la paginación
Las URL de búsqueda de Amazon usan &page=2, &page=3, etc.
for page in range(1, 6): # raspa las primeras 5 páginas
search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
res = requests.get(search_url, headers=headers)
if res.status_code != 200:
break
soup = BeautifulSoup(res.text, "lxml")
# ... extraer enlaces de producto como arriba ...
Recorrer las páginas de producto y exportar a CSV
Guarda los datos de cada producto en una lista de diccionarios y luego deja que pandas haga el resto:
import pandas as pd
df = pd.DataFrame(product_data_list) # lista de diccionarios
df.to_csv("amazon_products.csv", index=False)
O a Excel:
df.to_excel("amazon_products.xlsx", index=False)
Buenas prácticas para proyectos de Amazon Scraper Python
No nos contemos cuentos: Amazon retoca su web sin parar y persigue a los raspadores. Así mantienes tu proyecto en pie:
- Rota cabeceras y User-Agents (apóyate en una biblioteca como
fake-useragent) - Usa proxies para raspados a gran escala
- Espacia las solicitudes (mete
time.sleep()aleatorios entre peticiones) - Maneja los errores con cabeza (reintenta ante un 503, baja el ritmo si te bloquean)
- Escribe una lógica de análisis flexible (prueba varios selectores por campo)
- Vigila los cambios en el HTML (si de pronto el script devuelve
Noneen todo, revisa la página) - Respeta robots.txt (Amazon prohíbe raspar muchas secciones; hazlo con responsabilidad)
- Limpia los datos sobre la marcha (quita símbolos de moneda, comas y espacios)
- No te aísles de la comunidad (foros, Stack Overflow, el r/webscraping de Reddit)
Lista de comprobación para mantener tu raspador:
- Rotar User-Agents y cabeceras
- Usar proxies si raspas a gran escala
- Añadir retrasos aleatorios
- Modularizar el código para facilitar actualizaciones
- Vigilar bloqueos o CAPTCHAs
- Exportar datos con regularidad
- Documentar los selectores y la lógica
Si quieres ir más a fondo, échale un ojo a mi guía de web scraping con Python.
La alternativa sin código: raspar Amazon con Thunderbit AI Web Scraper
Raspa datos de productos de Amazon con IA Get Started Free
Vale, ya conoces la opción con Python. ¿Pero qué hacemos si no te apetece programar, o sencillamente quieres los datos en dos clics y seguir con tu día? Para eso está Thunderbit.
Thunderbit es una extensión de Chrome de raspado web con IA que te deja extraer datos de productos de Amazon —y de prácticamente cualquier web— sin escribir una línea. Estas son las razones por las que me convence:
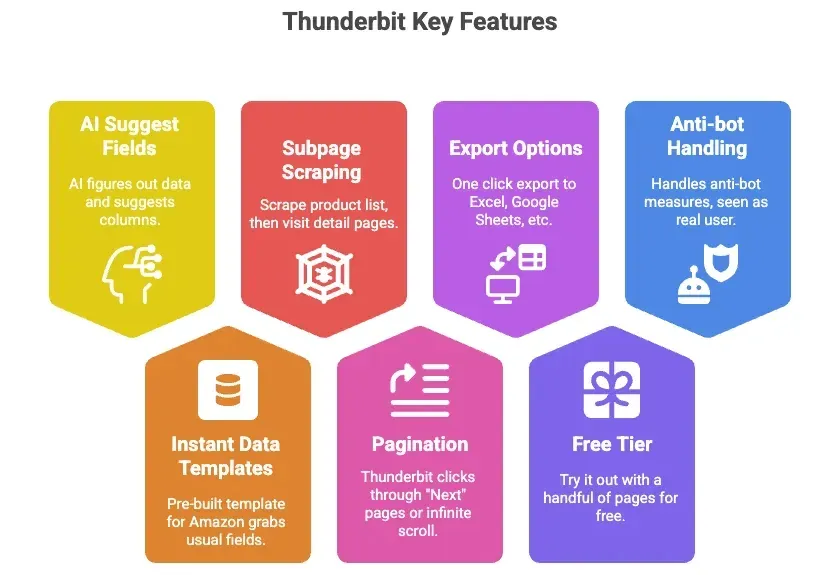
- Sugerencia de campos con IA: un clic y la IA de Thunderbit reconoce qué datos hay en la página y te propone columnas (Título, Precio, Valoración, etc.).
- Plantillas de datos al instante: para Amazon hay una plantilla lista que saca todos los campos habituales, sin configurar nada.
- Raspado de subpáginas: raspa un listado de productos y deja que Thunderbit entre en cada ficha de detalle para extraer más información de forma automática.
- Paginación: Thunderbit pulsa por ti los botones de «Siguiente» o resuelve el scroll infinito.
- Exportación a Excel, Google Sheets, Airtable y Notion: un clic y tus datos quedan listos para usar.
- Plan gratuito: pruébalo sin pagar con unas cuantas páginas.
- Gestiona lo anti-bot por ti: como trabaja en tu navegador (o en la nube), Amazon lo ve como un usuario real.
Paso a paso: usar Thunderbit para raspar datos de productos de Amazon
Así de sencillo es:
-
Instala Thunderbit:
Descarga la extensión de Chrome de Thunderbit e inicia sesión.
-
Abre Amazon:
Ve a la página de Amazon que quieras raspar (resultados de búsqueda, ficha de producto, lo que sea).
-
Haz clic en «AI Suggest Fields» o usa una plantilla:
Thunderbit te propondrá las columnas a extraer (o eliges la plantilla de Amazon Product).
-
Revisa las columnas:
Ajústalas a tu gusto (añade o quita campos, cámbiales el nombre, etc.).
-
Haz clic en «Scrape»:
Thunderbit extrae los datos de la página y te los presenta en una tabla.
-
Gestiona subpáginas y paginación:
Si raspaste un listado, pulsa «Scrape Subpages» para entrar en cada ficha de producto y sacar más datos. Thunderbit también pasa solo a las páginas de «Next».
-
Exporta tus datos:
Haz clic en «Export to Excel» o «Export to Google Sheets». Y ya está.
-
(Opcional) Programa el raspado:
¿Necesitas estos datos cada día? Usa el programador de Thunderbit y olvídate.
Eso es todo. Sin código, sin depurar, sin proxies, sin dolores de cabeza. Si prefieres verlo en vídeo, pásate por el canal de YouTube de Thunderbit o por la página de la plantilla Amazon Product Scraper.
Prueba la plantilla Amazon Product Scraper
Amazon Scraper Python frente a raspador web sin código: comparación lado a lado
Juntemos todas las piezas:
| Criterio | Raspador Python | Thunderbit (sin código) |
|---|---|---|
| Tiempo de configuración | Alto (instalar, programar, depurar) | Bajo (instalar extensión) |
| Conocimientos necesarios | Se requiere programar | Ninguno (apuntar y hacer clic) |
| Flexibilidad | Ilimitada | Alta para casos de uso comunes |
| Mantenimiento | Tú corriges el código | La herramienta se actualiza sola |
| Gestión anti-bot | Tú gestionas proxies y cabeceras | Integrado, gestionado por ti |
| Escalabilidad | Manual (hilos, proxies) | Raspado en la nube, en paralelo |
| Exportación de datos | Personalizada (CSV, Excel, BD) | Un clic para Excel y Sheets |
| Coste | Gratis (tu tiempo + proxies) | Freemium, pagas al escalar |
| Ideal para | Desarrolladores, necesidades personalizadas | Usuarios de negocio, resultados rápidos |
Si eres desarrollador, te gusta trastear y necesitas algo muy a medida, Python es tu compañero. Si lo que buscas es rapidez, sencillez y cero código, tu camino es Thunderbit.
Cuándo elegir Python, sin código o un raspador web con IA para datos de Amazon
Elige Python si:
- Necesitas lógica a medida o quieres engancharlo a tus sistemas backend
- Vas a raspar a gran escala (decenas de miles de productos)
- Te apetece entender cómo funciona el scraping por dentro
Elige Thunderbit (sin código, raspador web con IA) si:
- Quieres los datos rápido y sin programar
- Eres usuario de negocio, analista o profesional de marketing
- Necesitas que tu equipo consiga los datos por su cuenta
- Prefieres ahorrarte el lío de proxies, defensas anti-bot y mantenimiento
Usa ambos si:
- Quieres prototipar rápido con Thunderbit y después montar una solución Python a medida para producción
- Quieres recoger los datos con Thunderbit y limpiarlos y analizarlos con Python
Para la mayoría de perfiles de negocio, Thunderbit cubre el 90% de lo que necesitas raspar en Amazon en una fracción del tiempo. Para el 10% restante —lo muy a medida, lo masivo o lo profundamente integrado— Python sigue llevando la corona.
Conclusión y conclusiones clave
Cómo raspar productos y reseñas de Amazon en 2025 con IA Get Started Free
Extraer datos de productos de Amazon es casi un superpoder para cualquier equipo de ventas, e-commerce u operaciones. Tanto si vigilas precios, como si estudias a la competencia o solo quieres ahorrarle a tu gente horas eternas de copiar y pegar, hay una vía que te encaja.
- El raspado con Python te da control total, pero arrastra una curva de aprendizaje y un mantenimiento que no se acaba nunca.
- Los raspadores web sin código como Thunderbit ponen la extracción de datos de Amazon al alcance de cualquiera: sin programar, sin quebraderos de cabeza, solo resultados.
- ¿La mejor jugada? Quédate con la herramienta que case con tus habilidades, tu agenda y tus objetivos de negocio.
Si te pica la curiosidad, prueba Thunderbit: empezar es gratis y te va a sorprender lo rápido que tienes en la mano los datos que necesitas. Y si eres desarrollador, no le tengas miedo a mezclar enfoques: a veces, la forma más rápida de construir es dejar que la IA se ocupe de las partes aburridas.
Obtén la extensión de Chrome de Thunderbit
Preguntas frecuentes
1. ¿Por qué querría una empresa extraer datos de productos de Amazon?
Sacar datos de Amazon le permite a una empresa vigilar precios, estudiar a la competencia, recopilar reseñas para investigar productos, anticipar la demanda y generar leads de ventas. Con más de 600 millones de productos y casi 2 millones de vendedores, Amazon es una fuente riquísima de inteligencia competitiva.
2. ¿Cuáles son las principales diferencias entre usar Python y herramientas sin código como Thunderbit para raspar Amazon?
Los raspadores en Python brindan la máxima flexibilidad, pero exigen saber programar, tiempo de configuración y un mantenimiento que no para. Thunderbit, un raspador web con IA sin código, te deja extraer datos de Amazon al instante desde una extensión de Chrome, sin programar, con gestión anti-bot integrada y exportación a Excel o Sheets.
3. ¿Es legal raspar datos de Amazon?
Los términos de servicio de Amazon prohíben el scraping por norma general, y además la plataforma despliega activamente defensas anti-bot. Aun así, muchas empresas siguen extrayendo datos públicos cuidando hacerlo con responsabilidad: respetando los límites de velocidad y evitando un exceso de solicitudes.
4. ¿Qué tipo de datos puedo extraer de Amazon con herramientas de web scraping?
Los campos más habituales son títulos de producto, precios, valoraciones, número de reseñas, imágenes, especificaciones, disponibilidad e incluso información del vendedor. Thunderbit, además, admite el raspado de subpáginas y la paginación para reunir datos de varios listados y páginas.
5. ¿Cuándo debería elegir el raspado con Python en lugar de una herramienta como Thunderbit, o al revés?
Quédate con Python si necesitas control total, lógica a medida o vas a integrar el scraping en sistemas backend. Apuesta por Thunderbit si quieres resultados rápidos sin programar, necesitas escalar sin complicarte o eres un usuario de negocio que busca una solución de bajo mantenimiento.
¿Quieres profundizar más? Mira estos recursos:
- Blog de Thunderbit
- Qué es el data scraping y cómo hacerlo en 2025
- Cómo raspar productos y reseñas de Amazon en 2025 con IA
- Guía de web scraping con Python
Feliz raspado, y que tus hojas de cálculo no se queden nunca desactualizadas.
Prueba el raspador web con IA de Thunderbit para Amazon Get Started Free




