
Todo AI web scraper parece brillante en su demo de producto. Luego lo pones frente a un sitio real con protección de Cloudflare y te devuelve una página de desafío mientras, con total seguridad, te dice que encontró 47 listados de productos.
He pasado los últimos meses evaluando herramientas de scraping para nuestro equipo en Thunderbit. La brecha entre lo que enseñan en la demo y lo que de verdad aguanta en producción es, casi siempre, la mayor fuente de frustración que veo en las comunidades. Un usuario de Reddit lo resumió a la perfección: Con solo en la categoría de web scraping, además de decenas de extensiones de Chrome, proveedores de API y marketplaces de actores, el problema de la sobrecarga de opciones es real. Así que probé 12.
Este artículo evalúa 12 herramientas AI web scraper según criterios de producción: manejo anti-bot, escalabilidad, calidad del output estructurado, eficiencia de coste, compatibilidad con sitios dinámicos y flexibilidad para desarrolladores. Sin listas de funciones. Sin capturas de marketing. Solo lo que realmente funciona cuando termina la demo.
Por qué la mayoría de los AI Web Scrapers fracasan más allá de la demo
El patrón es predecible. El sitio de marketing de una herramienta muestra cómo extrae columnas limpias de una página sencilla de productos. La instalas, la pruebas en un sitio de e-commerce protegido y obtienes una de estas tres cosas:
- Una respuesta
200 OKque contiene una página de desafío de Cloudflare en lugar de los datos reales - Resultados limpios en las primeras 5 páginas, y después fallos silenciosos o filas inventadas
- Extracción perfecta hoy, selectores rotos la semana siguiente tras un pequeño cambio en el diseño
No son casos extremos. Son la norma.
Como dijo un profesional : "El scraper devuelve un 200 con una página de desafío de Cloudflare, tu agente intenta razonar sobre eso, alucina, y no tienes idea de por qué."
El problema de raíz es arquitectónico. La mayoría de las demos muestran la capa de parsing en páginas públicas limpias, mientras que el trabajo real falla en la capa de fetching. Los sitios en producción añaden protección anti-bot, renderizado dinámico, páginas internas anidadas, scroll infinito, estado de inicio de sesión, variaciones por locale y cambios de layout.
Una herramienta puede lucir genial en una demo y aun así colapsar en el primer flujo de trabajo serio de un cliente.
Por eso este artículo evalúa cada herramienta desde la óptica de la preparación para producción, y no como una simple lista de funciones. Los seis criterios que utilicé:
| Criterio | Por qué importa |
|---|---|
| Manejo anti-bot/CAPTCHA | Los sitios protegidos fallan antes de que la calidad de la extracción importe |
| Escalabilidad más allá de la demo | Los lotes y las ejecuciones paralelas revelan los límites operativos |
| Calidad del output estructurado | Los usuarios necesitan JSON/CSV limpios, no HTML en bruto que requiera limpieza manual |
| Eficiencia de tokens/coste | La extracción con IA puede salir más cara que el propio scraping |
| Compatibilidad con sitios dinámicos/pesados en JS | Las páginas modernas requieren DOM renderizado, no HTML estático |
| Flexibilidad no-code frente a API | Los equipos de ventas y los ingenieros de datos tienen necesidades distintas |
Si quieres una visión rápida del mercado sobre cómo cambió el web scraping en los últimos dos años, esta charla de Browserless es un buen punto de partida antes de comparar las herramientas una por una.
Dónde realmente ayuda la IA en un pipeline de scraping (y dónde no)
Un mito persistente en este mercado es que "AI web scraper" significa que la IA se encarga de todo de principio a fin. El consenso de la comunidad es sorprendentemente claro: . La postura tajante de un usuario: "Usas IA para leer una captura de pantalla de una página web. No usas IA para programar el scraper en sí."
El pipeline de scraping tiene tres capas distintas, y el valor de la IA cambia muchísimo entre ellas:
Rastreo y fetching: la capa de infraestructura
Aquí es donde se hacen las peticiones: proxies, navegadores sin interfaz, gestión de sesiones, resolución de CAPTCHA, reintentos. La IA aporta casi nada útil aquí. Sigues necesitando pools de proxies, fingerprinting del navegador e infraestructura de desbloqueo. Aquí es donde la mayoría de las herramientas falla primero en producción.
Parsing y extracción: donde la IA brilla
Una vez que tienes contenido limpio de la página, la IA destaca convirtiendo HTML no estructurado en campos estructurados. La extracción basada en esquemas, la detección adaptativa de campos y el manejo de variaciones de layout sin selectores XPath frágiles son el punto fuerte de la IA en scraping.
Postprocesado: etiquetar, traducir, categorizar
Después de la extracción, la IA aporta valor clasificando productos, traduciendo texto, normalizando números de teléfono o resumiendo descripciones. Es un gran encaje, pero solo si los datos extraídos ya son correctos.
Así es como se reparten las 12 herramientas entre esas capas:
| Herramienta | Rastreo/Fetching | Parsing/Extracción | Postprocesado | Mejor descripción |
|---|---|---|---|---|
| Thunderbit | Fuerte | Fuerte | Fuerte | AI scraper integral sin código |
| Octoparse | Fuerte | Medio | Bajo | Scraper visual basado en reglas con infraestructura cloud |
| Browse AI | Medio | Medio | Medio | Plataforma de robots en la nube centrada en el monitoreo |
| Firecrawl | Medio | Fuerte | Bajo-Medio | API de extracción para desarrolladores |
| Apify | Fuerte | Medio-Fuerte | Medio | Marketplace de actores y orquestación |
| Gumloop | Medio | Medio | Fuerte | Automatización de flujos con nodos de scraping |
| Bright Data | Muy fuerte | Medio | Bajo-Medio | Stack de infraestructura empresarial |
| Bardeen | Medio | Medio | Fuerte | Automatización del navegador para flujos de GTM |
| Diffbot | Bajo-Medio | Muy fuerte | Medio | Extracción preentrenada más grafo de conocimiento |
| ScrapingBee | Fuerte | Bajo-Medio | Bajo | API de fetching y desbloqueo |
| Instant Data Scraper | Bajo | Medio (páginas simples) | Bajo | Scraper rápido heurístico en el navegador |
| ParseHub | Medio | Medio | Bajo | Scraper visual de escritorio para interacciones complejas |
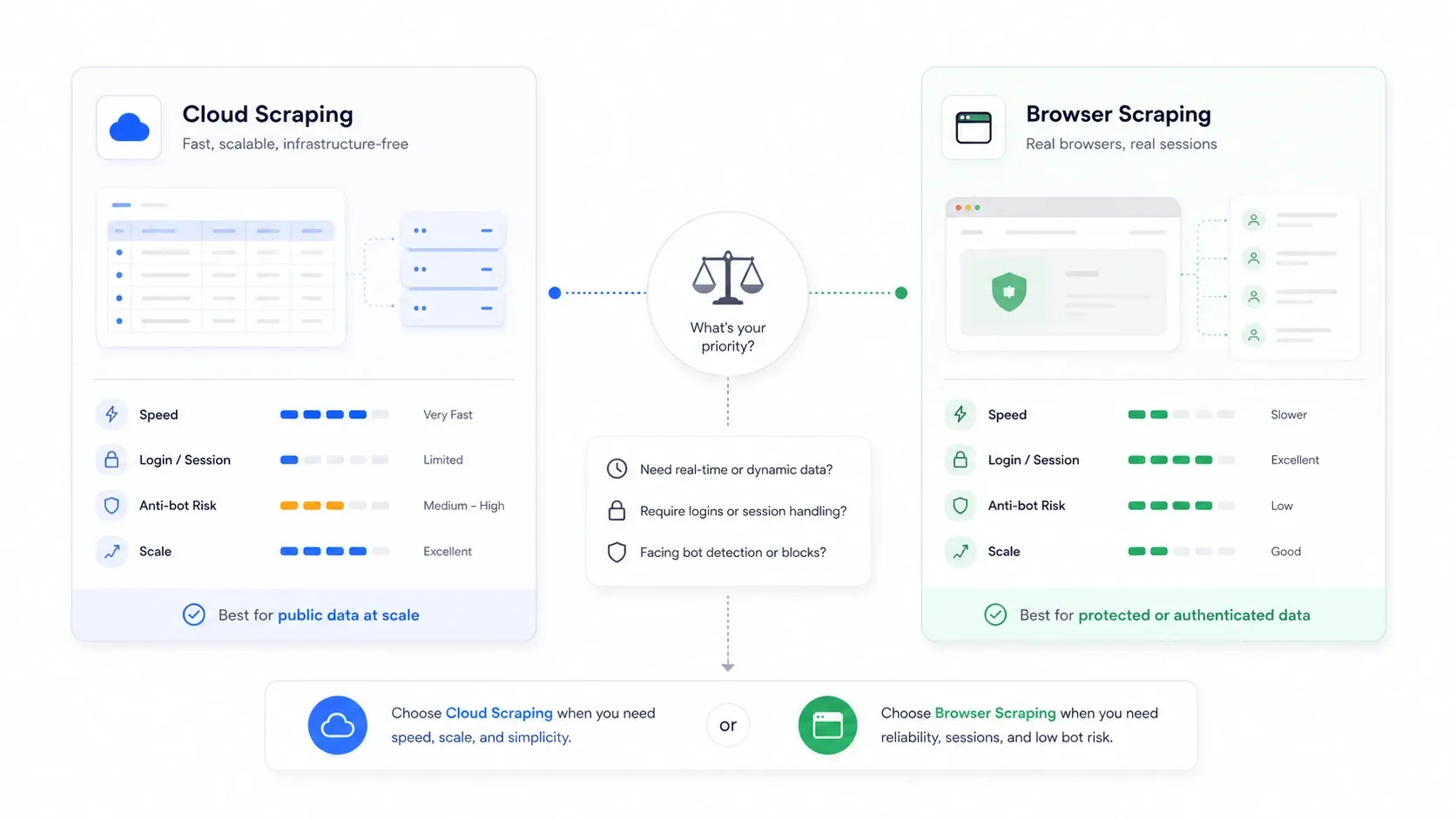
Scraping en la nube vs scraping en navegador: la decisión que nadie explica
Esta es la decisión arquitectónica que la mayoría de los artículos recopilatorios ignora por completo, y a menudo es más importante que la herramienta que elijas.
Scraping en la nube significa que servidores remotos hacen las solicitudes por ti. Scraping en navegador significa que la extracción ocurre en tu propia sesión del navegador, usando tus cookies, tu IP y tu estado autenticado.
| Escenario | Mejor modo | Por qué |
|---|---|---|
| Sitios de e-commerce y listados públicos a gran volumen | Nube | Más paralelismo y sin cuello de botella de la máquina local |
| Sitios que requieren inicio de sesión o autenticación | Navegador | Reutiliza las cookies reales de tu sesión |
| Sitios que castigan IPs de centros de datos | Navegador | Parece tráfico normal de usuario |
| Tareas grandes y recurrentes de monitoreo | Nube | Más fácil de programar y mantener continuidad |
| Tareas puntuales, frágiles y sensibles al anti-bot | Navegador | Más fácil inspeccionar lo que el sitio realmente renderizó |
Esto también importa económicamente. El informe State of Web Scraping 2026 de Apify encontró que año tras año, y reportó un mayor gasto en infraestructura. El anti-bot no es solo un problema técnico. Es un problema de presupuesto.
La mayoría de las herramientas solo ofrece un modo. Aquí va el desglose:
| Herramienta | Nube | Navegador | Ambos |
|---|---|---|---|
| Thunderbit | ✅ | ✅ | ✅ |
| Octoparse | ✅ | ✅ (local) | ✅ |
| Browse AI | ✅ | Solo configuración | — |
| Firecrawl | ✅ | API para interacción | — |
| Apify | ✅ | ✅ (a través de actors) | ✅ |
| Gumloop | ✅ | ✅ (Web Agent) | ✅ |
| Bright Data | ✅ | ✅ | ✅ |
| Bardeen | Limitado (páginas públicas) | ✅ | Parcial |
| Diffbot | ✅ | — | — |
| ScrapingBee | ✅ | — | — |
| Instant Data Scraper | — | ✅ | — |
| ParseHub | ✅ (de pago) | ✅ (escritorio) | ✅ |
Las 12 herramientas AI Web Scraper de un vistazo
Aquí tienes la comparación general de las 12 herramientas:
| Herramienta | Mejor para | Plan gratis | Nube/Navegador | Acceso API | Scraping programado | Manejo anti-bot |
|---|---|---|---|---|---|---|
| Thunderbit | Equipos no técnicos | ✅ (6 páginas) | Ambos | ✅ | ✅ | Fuerte |
| Octoparse | Scraping con muchas plantillas | ✅ (limitado) | Ambos | ✅ | ✅ | Moderado-Fuerte |
| Browse AI | Monitoreo de cambios | ✅ (limitado) | Principalmente nube | ✅ | ✅ | Moderado |
| Firecrawl | Pipelines de extracción para desarrolladores | ✅ (1.000 créditos/mes) | Nube más API de navegador | ✅ | No | Moderado |
| Apify | Equipos de desarrollo más marketplace | ✅ (5 $ de uso gratis) | Ambos | ✅ | ✅ | Fuerte con complementos |
| Gumloop | Automatización de flujos | ✅ (5.000 créditos/mes) | Ambos | ✅ | ✅ | Medio |
| Bright Data | Acceso empresarial a datos | Prueba / créditos | Ambos | ✅ | Externo | Muy fuerte |
| Bardeen | Automatización del navegador para ventas y operaciones | ✅ (100 créditos) | Primero navegador | Limitado | ✅ | Medio-Bajo |
| Diffbot | APIs de extracción estructurada | ✅ (10.000 créditos) | Nube | ✅ | No | Bajo en fetching / alto en extracción |
| ScrapingBee | Fetching y desbloqueo para desarrolladores | ✅ (1.000 créditos) | Nube | ✅ | No | Fuerte |
| Instant Data Scraper | Scrapes gratuitos puntuales | ✅ (totalmente gratis) | Solo navegador | No | No | Bajo |
| ParseHub | Flujos visuales complejos | ✅ (5 proyectos) | Escritorio más nube | ✅ | ✅ (de pago) | Medio |
1. Thunderbit
es el AI web scraper que creamos específicamente para equipos no técnicos que necesitan datos de calidad de producción sin escribir código ni gestionar infraestructura. El flujo principal es realmente de dos clics: AI Suggest Fields lee la página y propone columnas, y luego Scrape ejecuta la extracción en modo nube o navegador.
Lo que lo diferencia de otros scrapers no-code es la arquitectura. Thunderbit separa las preocupaciones de rastreo, como la infraestructura cloud, la rotación de proxies, el manejo anti-bot y el renderizado de JavaScript, de la extracción con IA que lee el HTML y produce columnas estructuradas. Eso encaja con el patrón recomendado por expertos de "scraper primero, LLM después", pero empaquetado en un flujo de extensión de Chrome que sí pueden usar comerciales y responsables de operaciones.
Principales fortalezas
- Scraping en nube y en navegador en una sola interfaz. Cambia de modo según si el sitio es público o requiere tu sesión autenticada. El modo cloud gestiona hasta 50 páginas en paralelo.
- La IA vuelve a leer la estructura de la página cada vez. Sin mantenimiento de XPath. Cuando un sitio cambia su layout, Thunderbit se adapta automáticamente en la siguiente ejecución.
- Scraping de subpáginas. La IA visita páginas de detalle enlazadas y enriquece la tabla principal sin configuración manual.
- Field AI Prompts. Etiquetado, traducción y categorización personalizados durante la extracción, en lugar de como un paso aparte de postprocesado.
- Exportaciones gratis a Google Sheets, Excel, Airtable y Notion.
- Plantillas de scraper instantáneas para sitios populares como Amazon, Zillow y LinkedIn.
- Programación en lenguaje natural. Dile "extrae cada lunes a las 9am" y lo convierte en una programación recurrente.
- API abierta con endpoints Distill y Extract, procesamiento por lotes de hasta 100 URLs y concurrencia publicada de 2 en gratis a 50 en Pro 1.
Lo que podría mejorar
- El plan gratis es intencionadamente pequeño.
- La experiencia no-code está centrada en la extensión de Chrome. Quienes quieran flujos solo con API tienen que usar la Open API por separado.
- No es la herramienta adecuada si tu necesidad principal es infraestructura pura de proxies sin extracción.
Precios
Hay plan gratis. Los planes no-code empiezan desde 9 $/mes facturado anualmente o 15 $/mes en Starter. El precio de la API va por separado: 600 unidades de un solo uso gratis, luego 16 $/mes anual para Starter API y 40 $/mes anual para Pro 1 API. Consulta y .
Ideal para: equipos de ventas, e-commerce y operaciones que necesitan datos web estructurados sin apoyo de ingeniería.
2. Octoparse
es un constructor visual de flujos de trabajo para web scraping con una gran biblioteca de plantillas preconstruidas. Lleva suficiente tiempo en el mercado como para contar con una infraestructura cloud madura, y maneja bien la paginación en sitios estructurados y previsibles.
Principales fortalezas
- Amplias plantillas de scraping preconstruidas para sitios populares
- Extracción en la nube con ejecuciones programadas
- Rotación de IP y resolución de CAPTCHA como complementos de pago
- Acceso API en planes superiores
Lo que podría mejorar
- Las capacidades de IA son más ligeras que las de herramientas nativas de LLM. La sugerencia de campos sigue dependiendo más de plantillas que de lectura adaptativa.
- Los diseños complejos o inusuales requieren bastante ajuste manual en el editor visual.
- La curva de aprendizaje se empina cuando necesitas lógica condicional o soluciones contra bloqueos.
Precios
Hay plan gratis para siempre. El centro de ayuda oficial apunta actualmente a Standard desde 75 $/mes facturados anualmente y Professional desde 208 $/mes facturados anualmente, aunque algunas páginas localizadas y rutas de actualización muestran equivalentes mensuales más altos. Lo importante es que los precios de Octoparse ahora mezclan suscripciones con complementos de pago como proxies residenciales y resolución de CAPTCHA.
Ideal para: analistas y equipos de operaciones que extraen sitios estructurados, amigables para plantillas, a escala moderada.
3. Browse AI
es una plataforma no-code basada en la nube, diseñada principalmente para monitorear cambios en sitios web a lo largo del tiempo, como precios de la competencia, disponibilidad de stock y actualizaciones de contenido. El scraping forma parte del producto, pero el verdadero diferenciador es el sistema recurrente de monitoreo y alertas.
Principales fortalezas
- Detección de cambios y alertas integradas
- Grabador de robots no-code con configuración de apuntar y hacer clic
- Robots preconstruidos para sitios populares
- Soporte premium de proxies en planes superiores
Lo que podría mejorar
- El precio basado en créditos se encarece rápido cuando monitorizas páginas de detalle a escala
- Menos atractivo para extracción masiva puntual que las herramientas API-first
- Manejo anti-bot moderado; algunos sitios siguen requiriendo proxies premium o soluciones alternativas
Precios
Hay cuenta gratuita. Los planes de pago empiezan alrededor de 19 $/mes facturados anualmente para Starter, con niveles superiores de créditos y monitoreo por encima de eso.
Ideal para: equipos que necesitan monitorización continua de precios de la competencia, cambios de contenido o niveles de stock, más que extracción masiva de una sola vez.
4. Firecrawl
es una API orientada a desarrolladores que convierte páginas web en Markdown limpio o JSON estructurado. Se sitúa principalmente en la capa de extracción y es excelente para equipos que construyen pipelines RAG o alimentan contenido web a LLMs.
Principales fortalezas
- Excelente calidad de salida en Markdown para flujos LLM posteriores
- API limpia con funciones de scrape, crawl, map, search, extract y acciones de navegador
- Soporte para procesamiento por lotes
- Concurrencia de 2 en gratis a 100 en Growth
Lo que podría mejorar
- No tiene interfaz no-code y requiere habilidades de desarrollo
- Existe ayuda integrada con proxies y anti-bot, pero Firecrawl no se posiciona como un proveedor de desbloqueo dedicado
- No tiene programador propio para tareas recurrentes
- No resulta rentable para no desarrolladores que solo quieren una hoja de cálculo con datos
Precios
El plan gratis incluye 1.000 créditos al mes. Los planes de pago empiezan en 16 $/mes anual para Hobby y escalan con más créditos, concurrencia y uso del navegador. Las sesiones de navegador se cobran aparte en créditos.
Ideal para: desarrolladores que crean pipelines LLM, sistemas RAG o flujos de extracción personalizados y necesitan Markdown o JSON limpios desde páginas web.
5. Apify
es una plataforma con un marketplace de actors de scraping preconstruidos, además de herramientas para construir los propios. Piénsalo como una capa de orquestación en la que eliges o construyes scrapers especializados para sitios concretos y luego los programas y gestionas a través de una API unificada.
Principales fortalezas
- Marketplace enorme de actors con scrapers creados por la comunidad para cientos de sitios
- API y SDK potentes para desarrolladores
- Gestión de proxies y programación integradas
- Se integra con muchas herramientas posteriores
Lo que podría mejorar
- Lo de "no-code" solo es parcialmente cierto una vez sales del marketplace y necesitas lógica personalizada
- La fiabilidad de los actors depende del mantenimiento de la comunidad
- El precio puede dispararse porque se suman computación, coste del actor y proxies
Precios
El plan gratis incluye 5 $ en créditos mensuales de plataforma. Los planes de pago empiezan en 39 $/mes para Starter, con niveles superiores orientados a escala.
Ideal para: equipos de desarrollo que quieren flujos de scraping reutilizables y programables con un gran ecosistema de soluciones preconstruidas.
6. Gumloop
es una plataforma no-code de automatización de flujos que incluye un nodo de web scraping. El valor real no está en el scraping por sí solo. Está en conectar la extracción con LLMs, Google Sheets, CRMs y otras herramientas en un mismo lienzo visual.
Principales fortalezas
- Constructor visual de flujos con drag and drop
- Integra scraping con LLMs y herramientas de negocio posteriores en un solo flujo
- El plan gratis actualmente se anuncia con 5.000 créditos/mes
- Programación basada en tiempo para flujos recurrentes
- Los modos de scraping básico y Web Agent interactivo cubren tanto flujos simples como más completos
Lo que podría mejorar
- El motor de scraping es menos robusto que el de herramientas AI web scraper dedicadas
- Menor profundidad en anti-bot y proxies que la de proveedores especializados
- Los límites de concurrencia y triggers son más ajustados en el plan gratis
- No es ideal como caso de uso principal para scraping a gran escala y alto volumen
Precios
Hay plan gratis. Gumloop unificó a finales de 2025 su antigua estructura Solo y Team en un plan Pro, y desde entonces su comunicación pública se centra más en créditos gratis más generosos y niveles de pago consolidados que en precios pensados para scraping primero.
Ideal para: equipos que quieren usar el scraping como un paso dentro de un flujo automatizado más amplio: extraer, analizar y enviar a herramientas de negocio.
Si quieres ver cómo se siente en la práctica un flujo de extracción nativo de IA antes de seguir con el resto de la lista, este tutorial de Thunderbit es la demo de producto más relevante para equipos no técnicos.
7. Bright Data
es el stack de infraestructura de nivel empresarial de esta lista. Si tu problema es "no consigo pasar la protección anti-bot de este sitio haga lo que haga", Bright Data probablemente sea la respuesta, pero viene con la complejidad y el precio propios de una solución enterprise.
Principales fortalezas
- Red de proxies líder en el sector con IPs residenciales, de centros de datos y móviles
- Web Unlocker para anti-bot y bypass de CAPTCHA
- Scraping Browser con desbloqueo integrado
- Datasets prerecopilados disponibles para compra
- Control programático completo mediante API y SDK
Lo que podría mejorar
- No está diseñado para usuarios no técnicos
- El precio refleja su posicionamiento empresarial
- La extracción con IA no es el motivo principal para comprar la plataforma
Precios
Browser API empieza en 8 $/GB bajo modalidad pay as you go, con tarifas por GB más bajas en compromisos mensuales mayores. Otros productos de Bright Data, como Unlocker, Scraper APIs, datasets y pools de proxies, usan unidades de precio distintas.
Ideal para: equipos de datos empresariales que necesitan extraer sitios muy protegidos a gran escala y cuentan con personal técnico para gestionar la infraestructura.
8. Bardeen
es una herramienta de automatización del navegador centrada en clics, rellenado de formularios y scraping, con extracción de datos impulsada por IA superpuesta. Se entiende mejor como una herramienta de flujos GTM que también hace scraping, no como una herramienta de scraping que además hace GTM.
Principales fortalezas
- Automatización intuitiva tipo playbook con scraping como un paso más
- Scrapers oficiales mantenidos por el equipo de Bardeen para sitios populares
- Integraciones sólidas con CRM, Google Sheets, Slack y otras herramientas de negocio
- Útil para scraping de leads, enriquecimiento y flujos de exportación a CRM
Lo que podría mejorar
- La arquitectura centrada primero en navegador limita el scraping sin supervisión a alto volumen
- El scraping en la nube solo funciona en páginas públicas, no en páginas restringidas
- El manejo anti-bot depende en gran medida de lo que ya permita tu sesión del navegador
- La extracción con IA puede tener problemas con diseños complejos o no estándar
Precios
El plan gratis incluye 100 créditos mensuales. La documentación pública de soporte hace referencia a un precio heredado de 15 $/mes Pro para usuarios existentes, mientras que el empaquetado comercial actual de Bardeen está más orientado a enterprise y a flujos de trabajo que a la clásica tarificación de scraper barato.
Ideal para: equipos de ventas y operaciones que necesitan el scraping como parte de un flujo más amplio de automatización del navegador.
9. Diffbot
usa visión por computadora y NLP para leer páginas web como lo haría una persona, y devuelve datos estructurados de artículos, productos, discusiones y organizaciones. Es una de las APIs de extracción de mayor calidad disponibles si tus páginas encajan con sus modelos preentrenados.
Principales fortalezas
- Modelos de extracción preentrenados para artículos, productos, discusiones y más
- Knowledge Graph con miles de millones de entidades para enriquecer datos
- Calidad muy alta en el output estructurado en los tipos de página compatibles
- API clara para desarrolladores con límites de uso publicados
Lo que podría mejorar
- No tiene interfaz no-code
- No incluye crawling, gestión de proxies ni manejo anti-bot integrados
- Es caro para equipos pequeños
- Menos flexible en tipos de página no estándar que los extractores basados en schema prompts
Precios
El plan gratis incluye 10.000 créditos. Startup cuesta 299 $/mes por 250.000 créditos, y Plus cuesta 899 $/mes por 1.000.000 de créditos.
Ideal para: equipos de desarrollo que necesitan extracción estructurada de alta precisión en tipos de página estándar y están dispuestos a gestionar el fetching por separado.
10. ScrapingBee
es una API de web scraping centrada en la capa de fetching y desbloqueo. Tú le envías una URL, ella gestiona proxies, renderizado con navegador sin interfaz y defensas anti-bot, y devuelve HTML o, opcionalmente, datos extraídos.
Principales fortalezas
- Rotación de proxies y manejo anti-bot integrados
- Soporte para renderizado de JavaScript
- API REST sencilla
- Endpoint de scraping de Google Search
- Concurrencia publicada por plan
Lo que podría mejorar
- Las funciones de extracción con IA son limitadas
- No tiene interfaz no-code
- No incluye programación ni monitoreo integrados
- Una respuesta
200con una página bloqueada aún puede contar como solicitud exitosa
Precios
El plan gratis incluye 1.000 créditos de API. Los planes de pago empiezan en 49 $/mes y escalan con más concurrencia y volumen de solicitudes.
Ideal para: desarrolladores que principalmente necesitan fetching fiable por encima de defensas anti-bot y que harán la extracción con su propio código o con otra herramienta.
11. Instant Data Scraper
es una extensión gratuita de Chrome con más de 1.000.000 de usuarios que detecta automáticamente patrones de datos en una página y te permite exportar a CSV o Excel. No hay sugerencia de campos con IA en el sentido de LLM. Usa detección heurística de patrones.
Principales fortalezas
- Totalmente gratis, sin necesidad de cuenta
- Detección de datos con un clic en muchas páginas de listados y tablas
- Maneja paginación en algunos sitios
- Barrera de entrada extremadamente baja
- Sigue mantenida, con actualizaciones en la Chrome Web Store en 2026
Lo que podría mejorar
- No tiene sugerencia de campos ni etiquetado de datos impulsados por IA
- No hay scraping en la nube, programación ni API
- Tiene problemas con layouts complejos, contenido dinámico y sitios pesados en JS
- No ofrece manejo anti-bot más allá de lo que tu navegador ya pueda cargar
- La exportación se limita a CSV y Excel
Precios
Gratis. Para siempre.
Ideal para: cualquiera que necesite un scraping rápido y puntual de una página simple de listado y no quiera crear una cuenta ni pagar nada.
12. ParseHub
es una aplicación de escritorio con una interfaz visual de apuntar y hacer clic para construir proyectos de scraping. Puede manejar datos complejos anidados, contenido cargado por AJAX, scroll infinito e interacciones con menús desplegables que muchas extensiones sencillas suelen pasar por alto.
Principales fortalezas
- Interfaz visual de selectores para definir reglas de extracción
- Maneja datos anidados, menús desplegables, scroll infinito y contenido AJAX
- Plan gratis con hasta 5 proyectos
- Exporta a JSON, CSV y Excel
- Programación en la nube y rotación de IP en planes de pago
Lo que podría mejorar
- Flujo solo de escritorio, sin la comodidad de una extensión de navegador
- Velocidad de ejecución más lenta que la de herramientas nativas en la nube
- Los proyectos se rompen cuando cambian los layouts porque no existe una capa de relectura con IA
- Capacidades de IA limitadas y una sensación más heredada de scraper visual clásico
Precios
Hay plan gratis con 5 proyectos y 200 páginas por ejecución. Los planes de pago empiezan en 189 $/mes con programación, rotación de IP y límites más altos.
Ideal para: usuarios no técnicos que necesitan extraer sitios interactivos complejos y están dispuestos a invertir tiempo en configurar flujos visuales.
Cómo empezar con un AI Web Scraper en 5 pasos
Cada herramienta de esta lista tiene un flujo de incorporación distinto. Usaré Thunderbit como ejemplo concreto porque es el que mejor encaja con la intención de búsqueda de "solo necesito que esto funcione en una página real".
Paso 1: Instala y navega
Instala la y ve a la página que quieres extraer: un listado de productos, un directorio o un portal inmobiliario.
Paso 2: deja que la IA sugiera tus campos de datos
Haz clic en AI Suggest Fields. La IA lee la página actual y propone nombres de columnas y tipos de datos. En una página de producto, podría sugerir Nombre del producto, Precio, Valoración, URL de la imagen y Descripción.
Paso 3: personaliza los campos con Field AI Prompts
Ajusta las columnas si los valores por defecto no son del todo correctos. Añade Field AI Prompts para transformaciones personalizadas como "traduce la descripción al español", "clasifica como Electrónica, Hogar o Moda" o "extrae solo el precio numérico".
Paso 4: elige modo nube o navegador y extrae
Selecciona scraping en la nube para sitios públicos o scraping en navegador para objetivos autenticados o muy protegidos. Luego haz clic en Scrape.
Paso 5: exporta tus datos donde quieras
Exporta los resultados a Google Sheets, Excel, Airtable o Notion. Las exportaciones son gratis.
¿Y si cambia el layout del sitio?
Esa es la ventaja clave de producción de los extractores nativos con IA frente a las herramientas basadas en reglas. Los scrapers tradicionales como ParseHub y los flujos antiguos de Octoparse dependen de selectores XPath o rutas CSS. Cuando un sitio actualiza su estructura HTML, esos selectores se rompen y vuelves a reconfigurar todo manualmente.
Los extractores con IA como Thunderbit vuelven a leer la estructura de la página cada vez. Eso significa sin mantenimiento de XPath y sin selectores frágiles. La IA se adapta automáticamente a los cambios de layout en la siguiente ejecución.
Scraping programado y acceso API: las funciones avanzadas que nadie reseña
Los scrapes puntuales están bien para investigación. Los casos de uso en producción, como el monitoreo de precios, la actualización de listas de leads y el seguimiento de stock, requieren extracción recurrente y acceso programático. Estas funciones separan los juguetes de las herramientas.
Soporte de programación
| Herramienta | Programación nativa | Notas |
|---|---|---|
| Thunderbit | ✅ | Configuración en lenguaje natural |
| Octoparse | ✅ | Ejecuciones programadas en la nube |
| Browse AI | ✅ | Función central del producto |
| Firecrawl | ❌ | Usa cron externo |
| Apify | ✅ | Expresiones cron completas |
| Gumloop | ✅ | Triggers de flujo basados en tiempo |
| Bright Data | Externo | Normalmente se orquesta a través de los sistemas del cliente |
| Bardeen | ✅ | Programación de playbooks |
| Diffbot | ❌ | Primero API, orquestación externa |
| ScrapingBee | ❌ | Solo API |
| Instant Data Scraper | ❌ | Herramienta manual de navegador |
| ParseHub | ✅ (de pago) | Función premium |
Comparación de API para desarrolladores
| Herramienta | Señal de concurrencia o tasa | Modelo de precios |
|---|---|---|
| Thunderbit | 2 → 50 concurrentes | Basado en créditos |
| Firecrawl | 2 → 100 concurrentes | Basado en créditos |
| Apify | Depende del plan | Unidades de cómputo |
| Gumloop | Concurrencia de flujo limitada por plan | Basado en créditos |
| Diffbot | 5 llamadas/min → 25 llamadas/seg | Basado en créditos |
| ScrapingBee | 10 → 200 concurrentes | Créditos de API |
| Bright Data | La Browser API anuncia solicitudes concurrentes ilimitadas | Basado en GB |
Si tu caso de uso es más técnico y estás intentando decidir cuánta infraestructura quieres asumir, este tutorial de Firecrawl es un complemento útil y orientado a la ejecución frente a las comparaciones de producto anteriores.
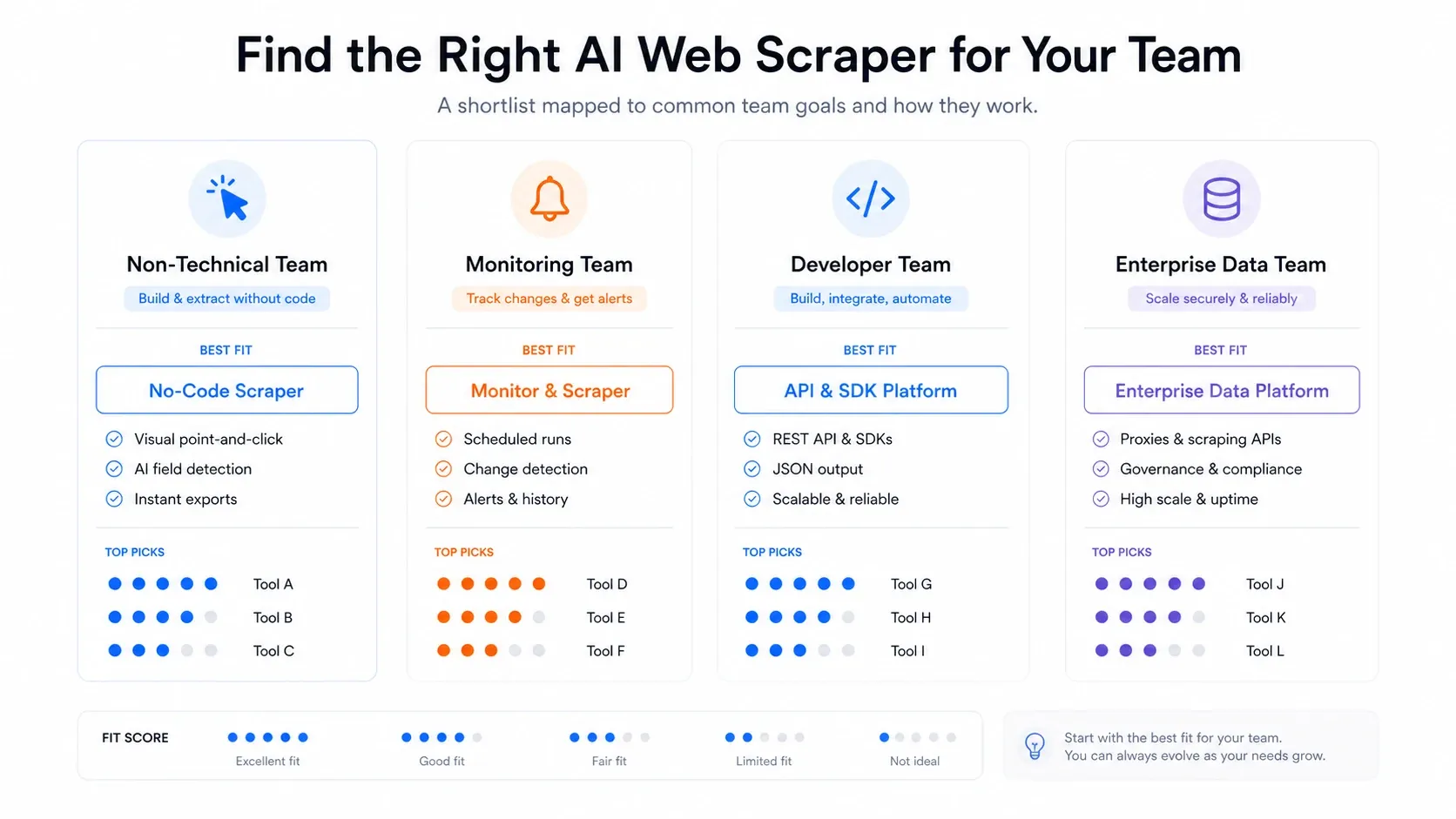
Cómo elegir el AI Web Scraper adecuado
Después de probar las 12 herramientas, así es como yo decidiría:
- Equipo no técnico que necesita datos rápido: empieza con Thunderbit. El flujo de dos clics, las exportaciones gratis y el cambio entre navegador y nube cubren la mayoría de necesidades de scraping de negocio sin apoyo de ingeniería.
- Necesitas monitoreo continuo y alertas: Browse AI está hecho para eso. No es el extractor más potente de una sola vez, pero su detección de cambios es una función de primera clase.
- Desarrollador que construye un pipeline LLM: Firecrawl para extracción en Markdown o JSON, o Diffbot para extracción estructurada preentrenada. Combina cualquiera de los dos con ScrapingBee o Bright Data si necesitas un manejo anti-bot serio en la capa de fetching.
- Necesitas un marketplace de scrapers preconstruidos: Apify tiene el ecosistema de actors más grande. Solo prepárate para hacer mantenimiento cuando fallen.
- Objetivos a escala enterprise y muy protegidos: Bright Data. Nada más se le acerca en infraestructura de proxies, pero el presupuesto y el personal técnico deben estar a la altura.
- Quieres que el scraping sea parte de una automatización más amplia: Gumloop o Bardeen, según si automatizas flujos de trabajo o tareas GTM basadas en navegador.
- Solo necesitas un scraping gratis y rápido: Instant Data Scraper. Cero configuración, cero coste, cero complejidad, pero también cero programación, cero IA y cero nube.
- Sitios interactivos complejos con menús desplegables y AJAX: ParseHub todavía los maneja mejor que la mayoría de extensiones, aunque la carga de mantenimiento es real.
Conclusión
El mercado de AI web scraper en 2026 está lleno de herramientas que impresionan en las demos y decepcionan en producción. La distancia entre "funciona en una captura de marketing" y "funciona en un sitio de e-commerce protegido a las 3 de la mañana y en horario programado" es donde la mayoría de compradores pierde tiempo y dinero.
La conclusión clave tras evaluar las 12 herramientas es sencilla: la capa de fetching sigue siendo la parte difícil. La IA sobresale en la extracción y el postprocesado, pero no sustituye la infraestructura de proxies, el manejo anti-bot ni la gestión de sesiones. Las mejores herramientas resuelven ambas capas, como Thunderbit y Bright Data, o son honestas sobre qué capa cubren, como Firecrawl para extracción y ScrapingBee para fetching.
Si quieres ver cómo luce un AI web scraper listo para producción sin escribir código, . El plan gratis basta para probar el flujo completo en páginas reales. Si tus necesidades son más orientadas a desarrollo, combina una API de extracción con un servicio de fetching dedicado y ahórrate la frustración de esperar que una sola herramienta lo haga todo.
Preguntas frecuentes
¿Por qué la mayoría de los AI web scrapers fallan en sitios reales después de funcionar bien en demos?
Las demos suelen mostrar extracción en páginas limpias y sin protección. Los sitios reales añaden protección de Cloudflare, renderizado dinámico de JavaScript, paginación, requisitos de inicio de sesión y layouts que cambian con frecuencia. La mayoría de las herramientas manejan bien la capa de parsing y extracción, pero carecen de una infraestructura robusta para la capa de fetching.
¿Cuál es la diferencia entre scraping en la nube y scraping en navegador, y cuándo debería usar cada uno?
El scraping en la nube usa servidores remotos para hacer las solicitudes, lo que es más rápido, paralelo y escalable. El scraping en navegador se ejecuta en tu propia sesión del navegador y es mejor para sitios autenticados o con detección agresiva de bots. Thunderbit es una de las pocas herramientas que ofrece ambos modos en la misma interfaz.
¿Puedo usar un AI web scraper para tareas recurrentes como el monitoreo de precios?
Sí, pero solo si la herramienta admite scraping programado. Thunderbit, Octoparse, Browse AI, Apify, Gumloop, Bardeen y ParseHub en planes de pago ofrecen programación.
¿Qué AI web scraper es mejor si no sé programar?
Thunderbit ofrece la ruta más rápida hacia datos utilizables para usuarios no técnicos. Instant Data Scraper es totalmente gratis, pero se limita a páginas simples. Browse AI y Octoparse ofrecen interfaces visuales con más configuración. ParseHub es potente para sitios interactivos complejos, pero tiene una curva de aprendizaje más pronunciada.
¿Cuánto cuesta realmente el AI web scraping de nivel de producción?
El rango es amplio. Instant Data Scraper es gratis. Thunderbit, Firecrawl y Browse AI ofrecen puntos de entrada gratuitos con planes de pago de bajo coste. Herramientas de gama media como Octoparse, ParseHub y ScrapingBee pueden costar entre unos 49 y 189 dólares al mes. Soluciones empresariales como Bright Data y Diffbot empiezan mucho más alto.