Resumen ejecutivo
Analizamos el archivo robots.txt de cada dominio de la lista Tranco top 10,000 de los sitios web con más tráfico del mundo. Después procesamos cada uno con un analizador compatible con RFC 9309, clasificamos el archivo según la política de bots de IA que hubiera adoptado el sitio, si es que tenía alguna, y contamos cuántos de los sitios más visitados del mundo intentan realmente bloquear a ChatGPT, Claude, Perplexity, Gemini, Common Crawl, Bytespider, Apple Intelligence y otros rastreadores que entrenan y sirven grandes modelos de lenguaje en 2026.
Las cifras principales, sobre una muestra de 7,248 sitios cuyos robots.txt pudimos leer sin problemas:
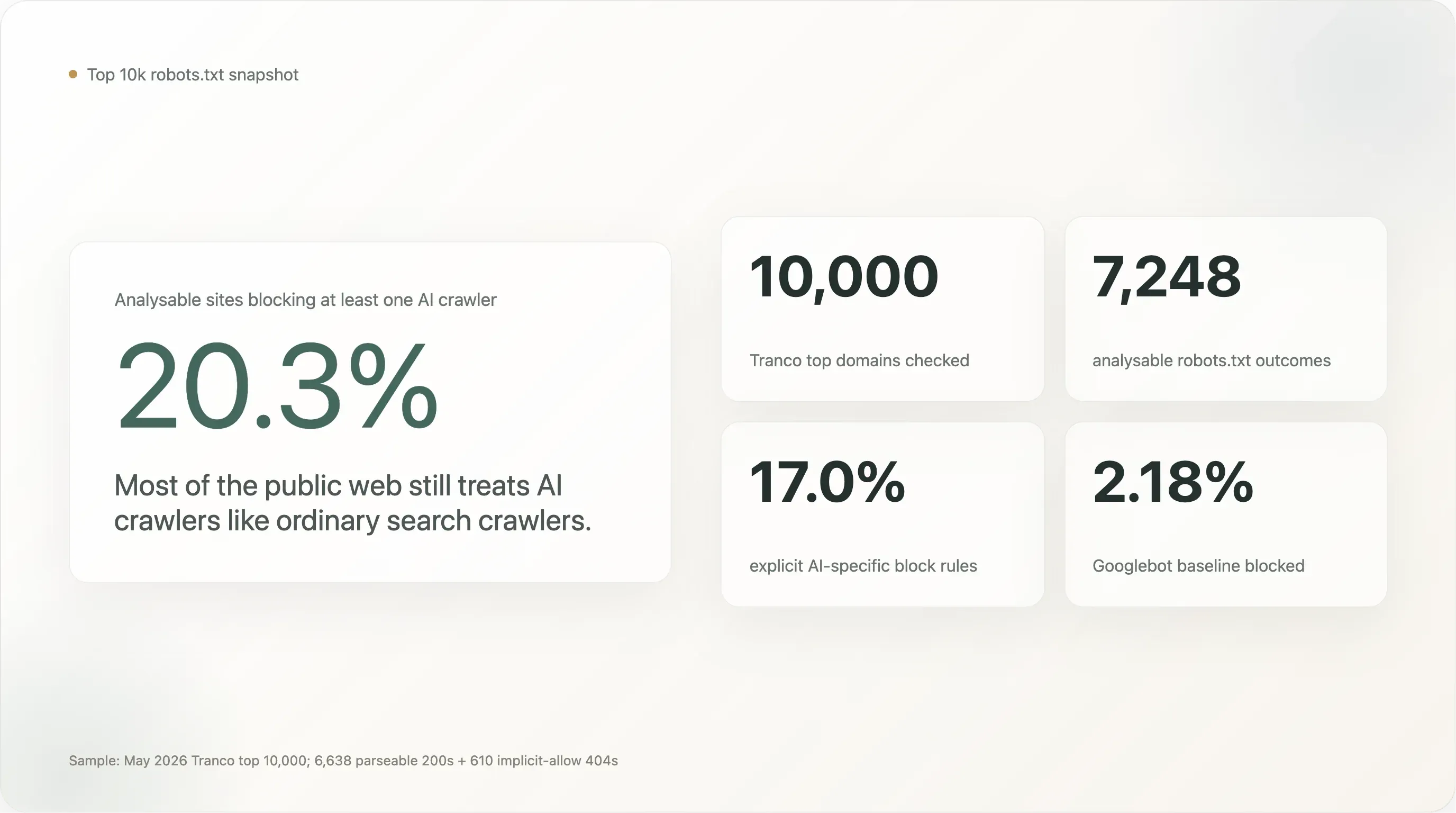
El 20.3% de los 10,000 sitios principales del mundo bloquea al menos un bot de IA. El 17.0% tiene una regla explícita y específica para IA a propósito. El 80% restante deja a los bots de IA tan bienvenidos como a Googlebot.
Seis hallazgos que cambian la forma de entender la historia:
- Los medios están en el 47% de bloqueo — la cifra más alta de cualquier sector. Alemania lidera con 88%, Francia con 80%, Rusia con 0%. El régimen legal, no la tecnología ni la economía del sector, es el principal factor.
CCBot(Common Crawl) es el bot más bloqueado, con 16.3% — por delante deGPTBot(15.8%) yBytespider(14.9%). Los editores apuntan al corpus de entrenamiento, no a la marca del modelo. La regla selectiva más adoptada es «bloquearCCBot, permitirGooglebot» (14.1% de los sitios).- Francia lidera todos los países con 50.6% de bloqueo de IA en sitios
.fr; el bloque de la UE supera en 16 puntos la media global. 275 archivosrobots.txtcitan explícitamente la Directiva 2019/790 de la UE. El artículo 4 es el único régimen legal que mueve las cifras de forma visible. - El 17.8% escribió sus propias reglas de IA; el 4.5% usa la plantilla gestionada de Cloudflare; el 75.7% no dice nada. Los sitios grandes redactan sus propias reglas; la cola larga usa el interruptor. The Atlantic y
cloudflare.comestán en la lista gestionada por Cloudflare. - 108 sitios permiten explícitamente
GPTBot— WordPress.org, Kaspersky, Norton, Avast, Sophos, The Verge, The Atlantic, NBA.com, The Sun, Branch.io. Los sectores de seguridad y herramientas para desarrolladores están sobrerrepresentados. - La política de IA no se vuelve más agresiva en la parte alta de la curva. Top 100, 101–1000, 1001–5000 y 5001–10000 se mueven todos entre 19% y 23%. La cifra principal es una propiedad de la web pública en 2026, no una señal del tamaño de un sitio concreto.
La historia ya no trata de si la web se está «defendiendo». Trata de qué industrias, qué países, qué regímenes legales y qué proveedores de IA son el objetivo de una política activa — y cuáles no.
I. Contexto: cómo robots.txt se convirtió en un artefacto de política de IA
Tres fuerzas han redefinido lo que significa robots.txt desde que OpenAI lanzó GPTBot en agosto de 2023.
Los proveedores de IA se multiplicaron. Después llegaron Google-Extended de Google, ClaudeBot de Anthropic, Bytespider de ByteDance, Applebot-Extended de Apple, Amazonbot de Amazon y Meta-ExternalAgent de Meta. El CCBot ya existente de Common Crawl pasó a ser el objetivo de bloqueo con mayor palanca, porque su archivo alimenta a la mayoría de los modelos de pesos abiertos. También aparecieron bots que no pertenecen a proveedores: AI2Bot, cohere-ai, PerplexityBot, YouBot, DuckAssistBot, Diffbot, Omgili. En 2026, una lista de bloqueo completa ronda los ~25 nombres.
El artículo 4 de la Directiva de la UE 2019/790 sobre derechos de autor creó una excepción legal para la minería de textos y datos que no aplica si el titular de derechos ha «reservado expresamente» sus derechos de una forma «legible por máquina». Durante 2024–2025, editores de la UE y sus abogados coincidieron en que robots.txt era la forma canónica de expresar esa reserva. Nuestro conjunto de datos muestra que 275 sitios citan explícitamente la Directiva 2019/790 y 87 mencionan «TDM» — concentrados en sitios europeos de noticias, donde aparece como un preámbulo legal de 4 a 8 líneas.
Cloudflare convirtió el interruptor en producto. En 2024–2025, Cloudflare lanzó un panel de «AI Audit», un interruptor «Block AI Bots» y una plantilla gestionada de robots.txt con la sintaxis Content-Signal: search=yes,ai-train=no y texto base sobre la Directiva 2019/790 de la UE. Para mayo de 2026, esa plantilla ya funcionaba en el 4.5% del top 10k analizable. La hoja de ruta pública de Cloudflare habla de activar por defecto el interruptor para cuentas nuevas, lo que movería la tasa global de bloqueo entre 5 y 8 puntos sin que ningún editor individual tome una decisión.
robots.txt en 2026 ya no es el archivo de configuración anodino que era en 2022. Es un mecanismo de reserva de derechos de autor con respaldo en tratados en la UE, un artefacto de política moldeado por proveedores en la cola larga y la primera línea de una negociación lenta entre quienes gestionan sitios web y quienes entrenan modelos.
II. Metodología
Intentamos que esto fuera lo más aburrido y reproducible posible. El flujo completo (scripts Python, CSV procesados, archivo bruto de robots.txt, gráficos) se publica junto con este informe.
Muestra
Partimos de la lista Tranco de mayo de 2026, descargada como top-1m.csv.zip, y tomamos las primeras 10,000 filas. Tranco agrega cuatro rankings de origen (Cisco Umbrella, Majestic, Farsight y Cloudflare Radar), filtra por estabilidad en una ventana de 30 días y elimina el ruido obvio de rastreadores/CDN. La lista que produce es lo más parecido a un «top 10k global del tráfico web» canónico que existe en abierto, y es la muestra estándar para la investigación académica de la web (usada en más de 600 artículos revisados por pares desde su lanzamiento por KU Leuven en 2018).
La lista incluye una mezcla de (a) sitios principales que la gente visita, (b) dominios de infraestructura / API / DNS / CDN que no sirven ningún /, y (c) dominios usados internamente por grandes plataformas (por ejemplo, gvt1.com, apple-dns.net, googleusercontent.com). En lugar de filtrarlos de antemano, los mantuvimos todos y los etiquetamos como categoría infrastructure en la capa de análisis. Desaparecen de forma natural cuando restringimos el análisis a «sitios que devolvieron un robots.txt analizable».
Obtención
Para cada uno de los 10,000 dominios enviamos un GET /robots.txt asíncrono por HTTPS, con fallback a HTTP, redirecciones seguidas hasta cuatro saltos, un timeout total de 12 segundos, un límite de cuerpo de 500 KB y un User-Agent de navegador real con Accept-Language: en-US. La concurrencia se mantuvo en 80 solicitudes simultáneas. El trabajo se ejecutó desde una sola IP residencial en San Francisco.
Resultado de la obtención:
| Estado | Cantidad | Interpretación |
|---|---|---|
200 OK | 6,638 | Se devolvió el cuerpo de robots.txt y era analizable. |
404 Not Found | 610 | No existe robots.txt. RFC 9309 define esto como un «permitir todo» implícito. |
403 Forbidden | 563 | El origen rechaza activamente las solicitudes a robots.txt. Excluido del análisis. |
429 Too Many Requests | 7 | Casi no hay limitación a nivel de CDN en este tramo del ranking. |
fetch_failed (error TLS / DNS / TCP) | 2,065 | Mayoritariamente dominios apex de CDN (akamai.net, cloudfront.net, fastly.net, gtld-servers.net, apple-dns.net) que no ejecutan un servidor web en /. No están «bloqueados» — simplemente no tienen ningún robots.txt que servir. |
| Otros 4xx/5xx | 117 | Casos mixtos: errores del servidor, geobloqueo, respuestas malformadas. |
Esto nos da 7,248 sitios en la muestra analizable (6,638 200 + 610 404). Los 2,065 fetch_failed son dominios reales, pero son puntos apex de CDN/DNS, no sitios que la gente visite, y tratarlos como si tuvieran una «política de IA» no tiene sentido. Permanecen en el conjunto de datos como una estadística aparte de accesibilidad.
Análisis sintáctico
Cada cuerpo 200 se procesó con protego, una implementación en Python de RFC 9309 usada en producción por Scrapy. Para cada par (sitio, bot) calculamos tres cosas:
can_fetch_root— si el bot puede acceder a/, con la semántica estándar de grupos de registros, la precedencia de la regla de coincidencia más larga y la anulación deUser-agent: *por un bot específico cuando ambos existen.has_specific_rule— si el archivo contiene una líneaUser-agent:que nombra exactamente a ese bot (sin distinguir mayúsculas y minúsculas).disallow_count— cuántas directivasDisallow:hay en el bloque coincidente, usado para distinguir prohibiciones completas del sitio de restricciones por ruta.
La combinación importa porque una tasa general de «bloqueo» oculta dos fenómenos distintos: marcas que escribieron intencionadamente User-agent: GPTBot \n Disallow: / porque decidieron oponerse, y marcas cuyo bloqueo genérico User-agent: * \n Disallow: / (configurado años atrás por motivos de staging o mantenimiento) termina también prohibiendo a cualquier bot de IA que no existiera cuando se redactó la plantilla. A lo largo de este informe, la cifra de «cualquier bloqueo de IA» incluye ambos casos; la cifra de «bloqueo explícito de IA» es el subconjunto deliberado.
Bots incluidos
Seguimos 25 bots, agrupados en tres categorías:
- Rastreadores de entrenamiento de IA (16):
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Meta-ExternalAgent,Bytespider,Applebot-Extended,Diffbot,Amazonbot,ImagesiftBot,FacebookBot,cohere-ai,AI2Bot,Omgili,Omgilibot. - Bots de inferencia / recuperación en vivo de IA (7):
PerplexityBot,Perplexity-User,ChatGPT-User,OAI-SearchBot,ClaudeBot(que sirve tanto para entrenamiento como para inferencia),YouBot,DuckAssistBot. - Base de búsqueda (6):
Googlebot,Bingbot,DuckDuckBot,Slurp(Yahoo),Baiduspider,YandexBot.
Algunos bots se sitúan a ambos lados de la línea entre entrenamiento e inferencia. ClaudeBot es el caso más destacado: Anthropic retiró el antiguo User-Agent anthropic-ai en 2024 y ahora usa ClaudeBot tanto para entrenamiento como para recuperación en vivo, así que una regla Disallow: ClaudeBot ya no se traduce de forma limpia como «bloquear entrenamiento pero mantener visibilidad». Hemos dejado la asignación tal como está y señalamos más adelante la consecuencia.
Clasificación por industria
Clasificamos cada dominio en una de 16 categorías sectoriales (news, social, streaming, ecommerce, search, finance, infrastructure, saas, academia, dev, gov, adult, gambling, travel, telecom, unknown) mediante un enfoque por capas:
- Diccionario de dominios conocidos — un mapa curado a mano de ~500 dominios de alto tráfico por industria.
- Patrones de TLD / sufijo —
.gov→gov,.eduy.ac.*→academia, sufijos CDN reconocidos →infrastructure. - Palabras clave en el nombre del dominio — news, post, shop, bank, porn, casino, etc. como señales de respaldo.
- Rastreo de la página principal — para los sitios que las tres primeras capas no pudieron clasificar y que devolvieron un
robots.txt200, recuperamos el HTML de la página principal, extraímos<title>,<meta name="description">,<meta property="og:type">y ejecutamos una puntuación por palabras clave frente a pistas de categorías al estilo de modelos de lenguaje.
Esto produjo 3,407 sitios (34%) con etiquetas de industria confiables y 6,593 que quedaron como unknown. La categoría unknown está dominada por portales regionales no anglófonos, sitios de marca .com corporativos que no encajan en ninguna sola categoría y editores tradicionales de mercados lingüísticos pequeños para los que no teníamos entradas en el diccionario. Cuando este informe cita un porcentaje por industria, el denominador es la muestra clasificada de esa industria, no los 10,000 completos.
III. Hallazgos
Hallazgo 1 — Uno de cada cinco sitios de mayor tráfico bloquea al menos un bot de IA
Entre los 7,248 sitios analizados, 1,472 (20.31%) bloquean al menos un bot de IA. 1,230 (16.97%) tienen una regla deliberada específica para IA. La base de Googlebot es 2.18% (158 sitios: la mayoría bloquea todo como valor predeterminado de mantenimiento o, en tres casos, son motores de búsqueda bloqueando a competidores).
Ese 20% principal es 9 veces la base de Googlebot. Es una señal real — los sitios con más tráfico tienen una probabilidad un orden de magnitud mayor de bloquear un rastreador de IA que un rastreador de búsqueda —, pero también es una cifra bastante menor que la narrativa de «el bloqueo de IA está alcanzando una adopción universal» que lleva circulando en la prensa desde 2024. Incluso en los 10,000 sitios más visitados de la web, la mayoría de cinco sextos no dice nada sobre IA.
La división entre «cualquier bloqueo de IA» (20.3%) y «bloqueo explícito de IA» (17.0%) es pequeña en términos absolutos, pero importante conceptualmente. La diferencia de 3.3 puntos es la proporción de sitios que bloquean bots de IA solo porque su regla existente User-agent: * \n Disallow: / atrapa todo lo que pasa, incluidos bots que no existían cuando se escribió la regla. La cifra deliberada de 17.0% es la lectura más limpia de «cuántos de los sitios más grandes del mundo han tomado una decisión específica sobre IA».
Comparado con la literatura previa:
| Fuente | Fecha | Muestra | Tasa de bloqueo |
|---|---|---|---|
| Originality.ai | Mar 2025 | 1,000 noticias más populares (inglés) | 35.7% bloquea GPTBot |
| Palewire | Ago 2024 | 1,500 organizaciones de noticias | 36.0% cualquier rastreador de IA |
| Reuters Institute | Primavera 2025 | 50 marcas de noticias líderes, 10 países | 78% cualquier rastreador de IA |
| WIRED / NYT | Finales de 2023 | Top 50 noticias de EE. UU. | 26% bloquea GPTBot |
| Este informe (Thunderbit) | Mayo 2026 | Tranco top 10,000 (todos los sectores) | 20.3% / 17.0% explícito |
Nuestro 17.0% explícito es más bajo que todos los estudios centrados solo en noticias porque dos tercios de nuestra muestra no son noticias. Si nos limitamos a los 650 sitios de noticias, obtenemos 47% — dentro del mismo rango que los estudios anteriores una vez que se tiene en cuenta la composición de la muestra. La imagen estructural es consistente: el cohorte de noticias bloquea IA a una tasa 3–4 veces superior a la del resto de la web.
Hallazgo 2 — Profundización sectorial: una diferencia de 12× entre noticias y telecom
El hallazgo más citado en dos años de cobertura sobre «scraping con IA» ha sido el dato de 80% de los medios bloquean GPTBot de Originality.ai y Palewire. Nuestro corte da una cifra menor pero igualmente distintiva: el 47.2% de los sitios de noticias del top 10,000 bloquea al menos un bot de IA, y el 45.2% escribe una regla explícita para IA.
Pero «noticias vs. todo lo demás» es demasiado grueso. El desglose completo (sectores con n ≥ 10 en la muestra) cuenta una historia mucho más rica:
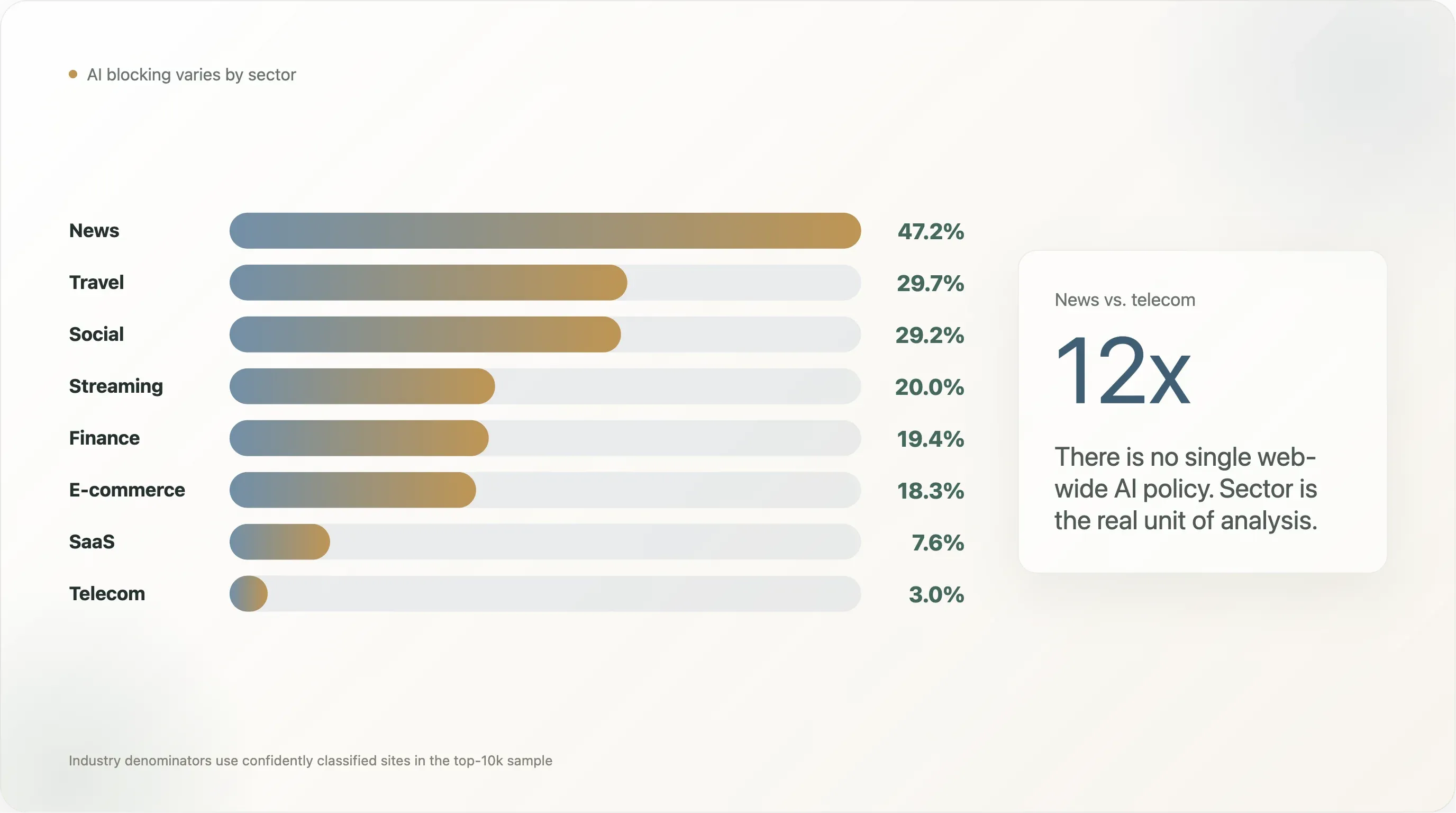
| Sector | n | Cualquier bloqueo de IA | Explícito | Googlebot bloqueado | Reglas propias | Cloudflare Managed | Silencio |
|---|---|---|---|---|---|---|---|
| Noticias | 650 | 47.2% | 45.2% | 1.5% | 46.9% | 1.5% | 48.5% |
| Viajes | 64 | 29.7% | 29.7% | 0.0% | 35.9% | 3.1% | 54.7% |
| Social | 65 | 29.2% | 23.1% | 4.6% | 23.1% | 6.2% | 66.2% |
| Streaming | 440 | 20.0% | 17.7% | 0.7% | 16.8% | 3.6% | 75.5% |
| Finanzas | 129 | 19.4% | 12.4% | 0.8% | 14.7% | 2.3% | 75.2% |
| Comercio electrónico | 224 | 18.3% | 17.4% | 0.4% | 24.1% | 1.3% | 66.1% |
| Adulto | 254 | 17.3% | 14.6% | 0.4% | 10.2% | 7.9% | 79.5% |
| Búsqueda | 12 | 16.7% | 0.0% | 0.0% | 0.0% | 0.0% | 100.0% |
| Academia | 268 | 14.6% | 13.8% | 0.4% | 13.4% | 3.4% | 77.2% |
| Apuestas | 100 | 14.0% | 13.0% | 0.0% | 18.0% | 4.0% | 77.0% |
| Herramientas para desarrolladores | 129 | 10.1% | 7.8% | 0.0% | 8.5% | 5.4% | 77.5% |
| SaaS | 369 | 7.6% | 6.2% | 0.3% | 9.5% | 0.8% | 87.5% |
| Gobierno | 172 | 5.2% | 3.5% | 0.0% | 4.1% | 0.6% | 83.1% |
| Infraestructura | 47 | 4.3% | 0.0% | 0.0% | 4.3% | 2.1% | 72.3% |
| Telecom | 33 | 3.0% | 3.0% | 0.0% | 12.1% | 0.0% | 78.8% |
La diferencia de 12× entre noticias y telecom es lo que hace que «la política de IA de la web» sea la unidad equivocada de análisis. No hay una sola cifra; hay cifras sectoriales que divergen por un orden de magnitud. A continuación repasamos los cuatro hallazgos más distintivos.
Noticias: 47% de bloqueo, 47% de reglas propias. Noticias es el cohorte que escribió el manual. Cloudflare Managed apenas alcanza el 1.5% en noticias — estos editores no externalizan la regla. El texto es inusualmente rico: el NYT abre con un preámbulo legal de 14 líneas citando «Art. 4 of the EU Directive»; la BBC con «Please use our site like a human, not a robot... TL;DR: Browse, read, watch, enjoy — like a human.»; The Sun con «The Sun does not permit the unlicensed use of our content for large language models.» Esto es robots.txt como declaración de política, no como configuración.
Viajes al 30% — la sorpresa. Booking, Expedia, TripAdvisor, Kayak y las grandes aerolíneas bloquean a dos tercios de la tasa de noticias. El patrón selectivo es consistente: el bloqueador medio de viajes deniega 5–7 UAs de entrenamiento pero deja intactos los UAs de inferencia (PerplexityBot, ChatGPT-User, OAI-SearchBot). Los datos agregados de precios y reseñas son el foso defensivo; las citas que vuelven al sitio son la ventaja. Este es el patrón más limpio de «sacar el entrenamiento, permitir la inferencia» dentro de una sola industria.
Adulto al 17% — también sorpresa. Muestras anteriores más pequeñas mostraban 0%. Los datos de la muestra completa indican que 1 de cada 6 sitios adultos prohíbe al menos un bot de IA, con la tasa más alta de Cloudflare Managed de cualquier sector (7.9%). Más de la mitad de los bloqueos de IA en sitios adultos provienen del interruptor de Cloudflare, no de una decisión del editor. El entrenamiento para generación de imágenes es la amenaza implícita: modelos de clase Stable Diffusion aprenden estilo visual más rápido de lo que los modelos de texto aprenden estilo de escritura.
SaaS al 7.6% es contraintuitivo. Los proveedores de software son el segmento más ruidoso en el discurso sobre política de IA, pero su robots.txt está muy abierto. La lectura correcta: los equipos de marketing de SaaS han identificado correctamente la búsqueda con IA como un canal de distribución. Los proveedores que realmente lo han pensado están optando por incluirse, no por excluirse: la lista explícita de Allow-GPTBot (Hallazgo 12) está dominada por seguridad y SaaS de herramientas para desarrolladores.
Gobierno 5.2%, telecom 3.0%, infraestructura 4.3%, desarrollo 10.1%. Las obligaciones de archivo público hacen que Disallow: / sea jurídicamente delicado en .gov. Los sitios de marketing de telecom quieren ser descubiertos. Los dominios apex de CDN no tienen nada que proteger. Las herramientas para desarrolladores se incluyen explícitamente (su contenido gana valor cuando los LLM lo citan).
La conclusión: no existe una única cifra de «la web bloquea / no bloquea IA» que no pierda más de lo que transmite. La única forma honesta de discutir estos datos es por sector.
Hallazgo 3 — Por proveedor de IA: ¿a quién se bloquea más?
El otro corte natural de los datos es por empresa de IA, no por bot. Varios proveedores operan varios bots (OpenAI opera tres: GPTBot, ChatGPT-User, OAI-SearchBot; Anthropic opera dos: ClaudeBot, anthropic-ai; Meta opera dos: Meta-ExternalAgent, FacebookBot). Agregar a nivel de proveedor es lo más cerca que podemos llegar a responder «¿qué piensa la web pública de cada empresa de IA?».
| Proveedor de IA | Bots agregados | Sitios que bloquean ≥ 1 bot | % de la muestra analizable |
|---|---|---|---|
| Common Crawl | CCBot | 1,178 | 16.25% |
| OpenAI | GPTBot, ChatGPT-User, OAI-SearchBot | 1,172 | 16.17% |
| Anthropic | ClaudeBot, anthropic-ai | 1,111 | 15.33% |
| ByteDance | Bytespider | 1,082 | 14.93% |
| Meta | Meta-ExternalAgent, FacebookBot | 989 | 13.65% |
Google-Extended | 970 | 13.38% | |
| Amazon | Amazonbot | 877 | 12.10% |
| Apple | Applebot-Extended | 859 | 11.85% |
| Webz.io (Omgili) | Omgili, Omgilibot | 731 | 10.09% |
| Cohere | cohere-ai | 717 | 9.89% |
| Perplexity | PerplexityBot, Perplexity-User | 715 | 9.86% |
| Diffbot | Diffbot | 684 | 9.44% |
| You.com | YouBot | 563 | 7.77% |
| AI2 (Allen AI) | AI2Bot | 487 | 6.72% |
| DuckDuckGo | DuckAssistBot | 482 | 6.65% |
Common Crawl es la entidad más señalada aunque es un archivo web sin ánimo de lucro, no un operador de LLM. La razón es la palanca: CCBot alimenta casi todos los modelos de pesos abiertos y una parte importante de los cerrados. Bloquear primero CCBot es la regla de mayor cobertura que un editor puede escribir.
OpenAI, Anthropic y ByteDance se agrupan entre 14–16%. La ventaja de OpenAI se debe en parte a un artefacto de conteo (tres bots de OpenAI frente a un único bot de ByteDance). El 14.9% de Bytespider es el efecto «comportamiento de Bytespider» — se ha documentado que ignora robots.txt desde 2024, y los editores lo bloquean como señal pública, no porque teman a TikTok.
Meta, Google, Amazon y Apple, entre 12–14% son la segunda franja — reglas redactadas de forma defensiva, no como declaración de posición. Los proveedores menores (Webz.io, Cohere, Perplexity, Diffbot, You.com, AI2, DuckDuckGo) en 6–10% están empujados sobre todo por el piso general del 3.8%; sus reglas explícitas están en el rango del 1–4%.
xAI (Grok), Mistral y la mayoría de los laboratorios europeos o chinos no aparecen en la tabla — no han publicado User-Agents de rastreo de entrenamiento documentados. El ecosistema actual de robots.txt es un diálogo entre proveedores estadounidenses/chinos que publicaron UAs y editores estadounidenses/europeos que escribieron reglas; los proveedores que no publicaron son invisibles para la negociación.
Hallazgo 4 — CCBot es el nuevo punto de fricción, no GPTBot
El orden de los bots en el top-10k se ve así:
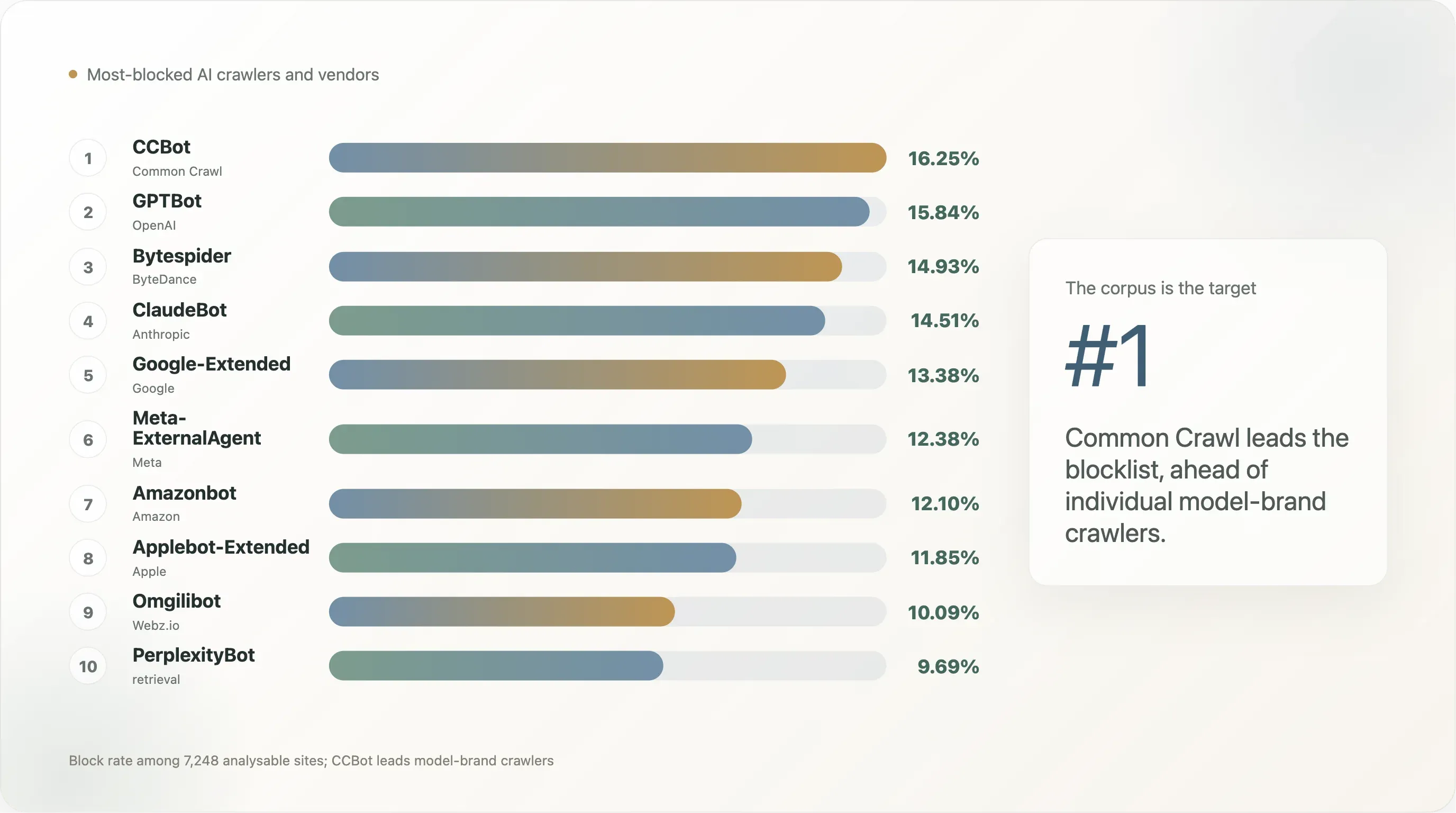
| Posición | Bot | Tasa de bloqueo | Tasa de regla explícita |
|---|---|---|---|
| 1 | CCBot (Common Crawl) | 16.25% | 12.90% |
| 2 | GPTBot (OpenAI) | 15.84% | 12.72% |
| 3 | Bytespider (ByteDance) | 14.93% | 11.35% |
| 4 | ClaudeBot (Anthropic) | 14.51% | 11.13% |
| 5 | Google-Extended | 13.38% | 10.18% |
| 6 | Meta-ExternalAgent | 12.38% | 8.95% |
| 7 | Amazonbot | 12.10% | 8.66% |
| 8 | Applebot-Extended | 11.85% | 8.72% |
| 9 | Omgilibot | 10.09% | 5.31% |
| 10 | anthropic-ai (obsoleto) | 9.99% | 6.55% |
| 11 | cohere-ai | 9.89% | 6.42% |
| 12 | PerplexityBot | 9.69% | 6.40% |
| 13 | Diffbot | 9.44% | 5.95% |
| 14 | ChatGPT-User (inferencia) | 8.90% | 5.73% |
| 15 | YouBot (inferencia) | 7.77% | 4.29% |
| 16 | OAI-SearchBot (inferencia) | 6.83% | 3.66% |
| base | Googlebot | 2.18% | — |
| base | Bingbot | 2.27% | — |
Lo que muestra esta tabla es que el bot que la web pública bloquea primero no es la marca del modelo — es el corpus. El archivo de Common Crawl de 250 mil millones de páginas ha sido la entrada de entrenamiento individual más grande para GPT-3, GPT-4, Llama 1 / 2 / 3, Falcon, Mistral, BLOOM y la mayoría de los modelos de pesos abiertos lanzados desde 2020. Un sitio que quiera salirse de «estar dentro del próximo modelo frontera» se optimiza bloqueando primero CCBot — una vez que no estás en Common Crawl, quedas prácticamente excluido del pipeline de entrenamiento de código abierto de forma gratuita. GPTBot y ClaudeBot van después porque son la cara visible de dos productos comerciales concretos; el User-Agent a nivel de corpus es el objetivo estructural.
Los bots de IA peor posicionados en la tabla también son informativos. Omgilibot con 10% es inusualmente alto para un bot del que la mayoría de los lectores no habrá oído hablar — lo opera Webz.io, un intermediario de datos de contenido que vende archivos web a operadores de LLM, y un grupo considerable de medios ha empezado a nombrarlo explícitamente en sus archivos. AI2Bot con 6.7% (y una regla correspondiente Ai2Bot-Dolma en sitios Squarespace) sugiere que la comunidad académica de LLM también está siendo señalada por editores que no necesariamente distinguen entre «rastreador de investigación sin fines de lucro» y «rastreador comercial».
El grupo de inferencia — ChatGPT-User, OAI-SearchBot, YouBot, Perplexity-User — se sitúa entre 4 y 8 puntos porcentuales por debajo del grupo de entrenamiento. Esa diferencia responde a una larga cuestión de política: sí, los sitios con más tráfico distinguen entre un bot que recopila datos para entrenar modelos futuros y un bot que hace recuperación en vivo para responder ahora mismo a la pregunta de un usuario. No siempre hacen esa distinción (las reglas genéricas no lo hacen), pero una parte significativa escribe reglas que apuntan específicamente al lado del entrenamiento.
Hallazgo 5 — El 14% bloquea CCBot mientras mantiene bienvenido a Googlebot — el patrón «bloquear el corpus, mantener la búsqueda»
La regla selectiva con más adopción en el top-10k:
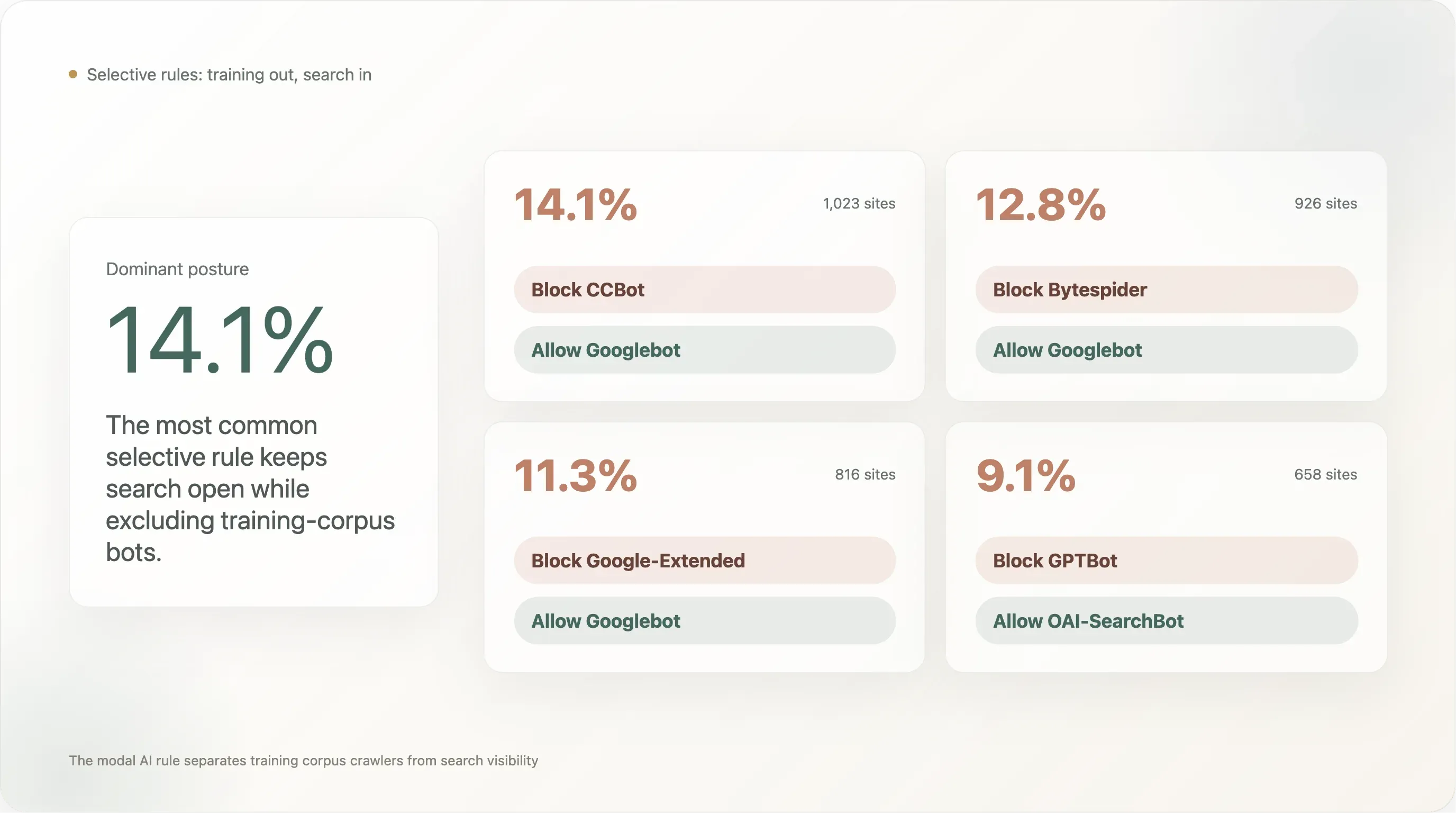
| Patrón de regla | Sitios | % de la muestra analizable |
|---|---|---|
Bloquear CCBot, permitir Googlebot | 1,023 | 14.11% |
Bloquear Bytespider, permitir Googlebot | 926 | 12.78% |
Bloquear Google-Extended, permitir Googlebot | 816 | 11.26% |
Bloquear GPTBot, permitir OAI-SearchBot | 658 | 9.08% |
Bloquear GPTBot, permitir ChatGPT-User | 525 | 7.24% |
Bloquear CCBot, permitir PerplexityBot | 519 | 7.16% |
Bloquear anthropic-ai, permitir ClaudeBot | 59 | 0.81% |
El patrón más adoptado (14.1%) es «bloquear Common Crawl, mantener la visibilidad en Google Search». El segundo (12.8%) es «bloquear Bytespider, mantener la visibilidad en Google Search», es decir, bloquear el rastreador de ByteDance señalado por reputación sin tocar la base legítima de búsqueda. El tercero (11.3%) es «bloquear el UA de entrenamiento de IA de Google mientras se mantiene el UA de búsqueda de Google», que es exactamente la separación para la que Google diseñó Google-Extended: el editor opta por no participar en el entrenamiento de Bard / Gemini sin perder posicionamiento en búsqueda.
Estos tres números juntos describen la postura política dominante en la web top-10k: denegar los bots del corpus de entrenamiento, dejar intactos los bots de búsqueda e inferencia. El patrón minoritario de «denegar entrenamiento pero permitir el UA específico de recuperación en vivo de este LLM» — GPTBot ✗ / ChatGPT-User ✓ con 7.2% — existe, pero es menor que los recortes a nivel de corpus.
La fila anthropic-ai / ClaudeBot con 0.81% refleja la retirada del UA por parte de Anthropic en 2024: ClaudeBot ahora sirve tanto para entrenamiento como para inferencia, eliminando la expresión clara de «bloquear entrenamiento, permitir citación» para Claude que sí permitía el antiguo UA anthropic-ai. Esta es la decisión de diseño de UA más poco discutida de 2024–2025 — eliminó toda una clase de expresión de política de robots.txt.
Hallazgo 6 — Noticias en detalle: por país y por idioma
Cuando separamos la categoría de noticias por dominio de código de país — teniendo en cuenta que esto significa .de para noticias alemanas, .fr para francesas, etc., no el idioma servido — la variación dentro de noticias es mayor que la variación entre noticias y el resto:
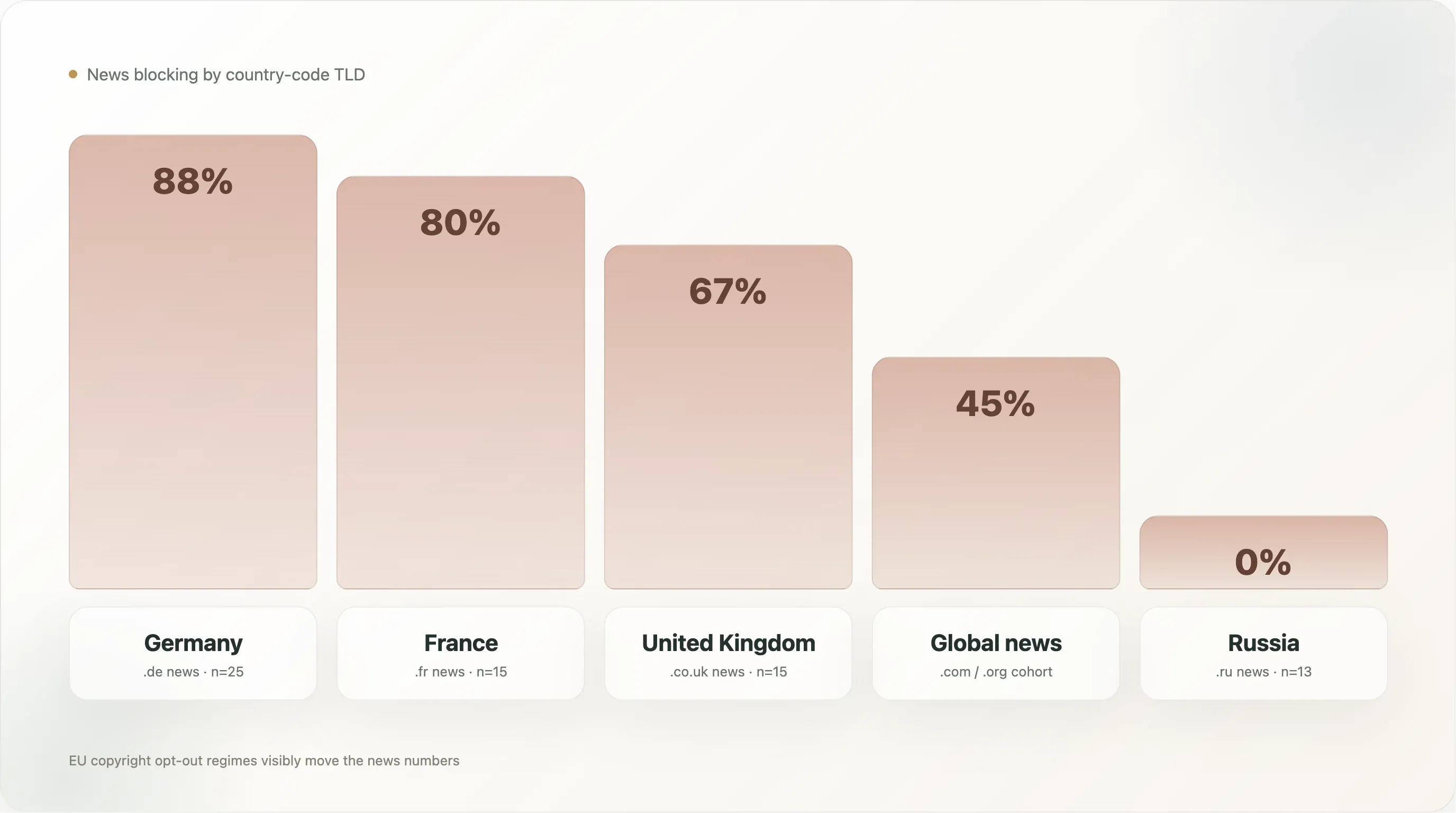
| País (solo noticias) | n | Cualquier bloqueo de IA | Explícito |
|---|---|---|---|
🇩🇪 Alemania (.de) | 25 | 88.0% | 88.0% |
🇫🇷 Francia (.fr) | 15 | 80.0% | 80.0% |
🇬🇧 Reino Unido (.co.uk) | 15 | 66.7% | 53.3% |
🇪🇸 España (.es) | 5 | 60.0% | 60.0% |
🇮🇹 Italia (.it) | 13 | 53.8% | 53.8% |
Noticias globales (.com/.org/etc.) | 500 | 45.0% | 42.8% |
🇵🇱 Polonia (.pl) | 7 | 42.9% | 42.9% |
🇯🇵 Japón (.jp) | 12 | 25.0% | 25.0% |
🇷🇺 Rusia (.ru) | 13 | 0.0% | 0.0% |
🇬🇷 Grecia (.gr) | 6 | 0.0% | 0.0% |
Las noticias alemanas son el subsegmento con mayor bloqueo de todo el conjunto, con 88%, y además es 88% explícito — prácticamente no hay ningún sitio de noticias alemán del top 10k que permita a los rastreadores de entrenamiento de IA acceder a su archivo. El cohorte está liderado por Spiegel, Bild, Welt, Zeit, FAZ, Süddeutsche, Heise, Golem, Stern, Focus — todo el establishment editorial alemán, además de editores tecnológicos que escribieron sus reglas de forma independiente. La infraestructura política que hay detrás es densa: VG Media, la organización colectiva de derechos de los editores alemanes, ha sido el cohorte demandante más agresivo en la litigación europea sobre derechos de autor e IA, y el artículo 4 de la Directiva de la UE se implementa en la ley alemana como §44b UrhG con lenguaje explícito de exclusión legible por máquina. Cuando llegaron los proveedores de IA, los editores alemanes eran el cohorte nacional mejor preparado para traducir esa postura legal en reglas robots.txt.
Las noticias francesas con 80% van justo por debajo. El entorno legal francés es similar (la Directiva 2019/790 transpuso a la ley francesa), y el comportamiento del cohorte también: lemonde.fr, lefigaro.fr, liberation.fr, lequipe.fr, 20minutes.fr, ouest-france.fr bloquean, y el archivo de Le Monde además cita el droit du producteur de base de données francés (artículo L 342-1 del Código de la Propiedad Intelectual) como base jurídica nacional paralela. Francia añade además la particularidad de una sentencia de 2024 del tribunal de comercio de París que considera suficientes los opt-outs basados en robots.txt como aviso bajo el artículo 4; esto proporciona un respaldo jurisprudencial directo que ninguna otra jurisdicción ha igualado aún.
El Reino Unido con 67% es más bajo, y la razón es que varios grandes editores británicos (thesun.co.uk, dailymail.co.uk, mirror.co.uk) usan bloqueos User-agent: * de denegar todo en lugar de reglas específicas para IA, lo que tira la cifra explícita hacia abajo hasta 53%. El efecto agregado es el mismo — estos sitios no permiten rastreo de IA —, pero la política se expresa como «ningún bot salvo esta lista concreta de motores de búsqueda permitidos» en lugar de como denegaciones nombradas por bot. La estructura jurídica también es más débil: tras el Brexit, el Reino Unido heredó la lógica del artículo 4, pero la jurisprudencia doméstica correspondiente es más escasa.
Las noticias rusas con 0% son la fila más sorprendente. Trece sitios de noticias de dominios rusos en la muestra (dzen.ru, rbc.ru, ria.ru, kommersant.ru, tass.ru, lenta.ru, gazeta.ru, interfax.ru, kp.ru, tass.com, etc.) — ninguno bloquea ningún rastreador de IA. La explicación probable: el entrenamiento de LLM en ruso está dominado por los propios modelos tipo GPT de Yandex (que usan rastreadores internos de Yandex, no Common Crawl), el entorno ruso de derechos de autor no ha adoptado un equivalente al artículo 4, y los grandes editores rusos ven a los LLM occidentales como un asunto menor (los controles de exportación de EE. UU. ya limitan OpenAI/Anthropic en Rusia) y a Yandex como un actor doméstico más que como un adversario. La postura política es simplemente distinta.
Las noticias japonesas con 25% muestran un tercer patrón. Japón tiene excepciones explícitas para la minería de textos y datos en su ley nacional de derechos de autor (artículo 30-4 de la Ley de Derecho de Autor japonesa, enmendada en 2018) que son más permisivas que el artículo 4 de la Directiva de la UE — permiten TDM con fines de «no disfrute», incluido el entrenamiento de IA, sin requerir el consentimiento del titular. Los editores japoneses tienen menos base jurídica para el opt-out y, por eso, las tasas correspondientes de robots.txt son más bajas. El 25% que sí bloquea corresponde sobre todo a los editores más grandes y cosmopolitas (asahi.com, nikkei.com), posicionados como internacionales más que domésticos.
Los datos de noticias por país son la evidencia más clara del informe de que el régimen legal, no la tecnología ni la economía del sector, es el principal motor del bloqueo de IA. Los cohortes de noticias de la UE se agrupan entre 54% y 88%; los cohortes de noticias fuera de la UE (Rusia, Japón, el cohorte global .com) van de 0% a 45%. El máximo de 88% está en el país con la implementación más desarrollada del artículo 4; el mínimo de 0% está en el país con prácticamente ninguna ley de política de IA.
Hallazgo 7 — UE frente al resto: una brecha de 16 puntos
Si elevamos la lente de país un nivel, la división amplia entre la UE y el resto es nítida:
| Región | n | Cualquier bloqueo de IA | Explícito |
|---|---|---|---|
ccTLD de la UE (.fr, .de, .es, .it, .nl, .pl, .se, .dk, .fi, .be, .at, .cz, .hu, .ro, .gr, .pt, .ie, .sk, .bg) | 617 | 35.2% | 33.9% |
ccTLD nacionales no UE (.uk, .jp, .kr, .cn, .ru, .br, .in, .au, .mx, .ca, .tr, .ar, .cl, .co, .pe) | 897 | 17.2% | 13.6% |
Global (.com, .net, .org, etc.) | 5,734 | 19.2% | 15.7% |
Los sitios ccTLD de la UE bloquean IA al doble de la tasa del cohorte nacional no UE y casi al doble de la tasa de la base global .com. La diferencia es consistente entre los Estados miembros de la UE (no hay un solo país que arrastre la media) y consistente entre industrias (.de noticias al 88%, .de SaaS en torno al 12%, .de comercio electrónico alrededor del 25% — todos por encima de sus equivalentes globales).
Encontramos 275 archivos robots.txt en el top-10k que citan explícitamente la Directiva 2019/790 en sus comentarios — alrededor del 3.8% de la muestra analizable. El cohorte está dominado por editores de la UE, pero va más allá de ellos: varias marcas estadounidenses de noticias (sobre todo NYT, que cita directamente «Art. 4 of the EU Directive»), algunos sitios británicos y un puñado de grandes destinos europeos de comercio electrónico reproducen el lenguaje legal. 87 archivos mencionan «TDM» o «text and data mining» por su nombre. 460 archivos contienen alguna forma de lenguaje de reserva de derechos de autor («expresamente se excluye», «todos los derechos reservados», «sin uso comercial», «sin machine learning») incluso cuando no citan una ley concreta.
Dos observaciones más granulares de este corte:
El efecto UE no se limita a noticias. Cuando mantenemos constantes las noticias, los sitios no noticiosos de la UE siguen bloqueando IA a tasas más altas que los no noticiosos fuera de la UE (aproximadamente 28% frente a 14%). Una pequeña pero real parte de SaaS, comercio electrónico y academia de la UE ha interiorizado el marco del artículo 4 para sus propios sectores.
El lenguaje con sabor a la UE se está convirtiendo en una plantilla de facto incluso fuera de la UE. La plantilla robots.txt gestionada por Cloudflare — adoptada globalmente — cita explícitamente «ARTICLE 4 OF THE EUROPEAN UNION DIRECTIVE 2019/790» en su texto base. Un sitio estadounidense que activa el ajuste «Block AI Bots» de Cloudflare está, sin saberlo necesariamente, afirmando una reserva de derechos estatutaria de la UE. Este es uno de los artefactos de deriva de política más interesantes que encontramos: un concepto jurídico europeo se está globalizando a través de la interfaz de producto de un proveedor de infraestructura estadounidense.
Hallazgo 8 — Plantillas y orígenes de plantillas
El desglose de origen de plantilla de los 6,638 sitios que devolvieron un robots.txt analizable:
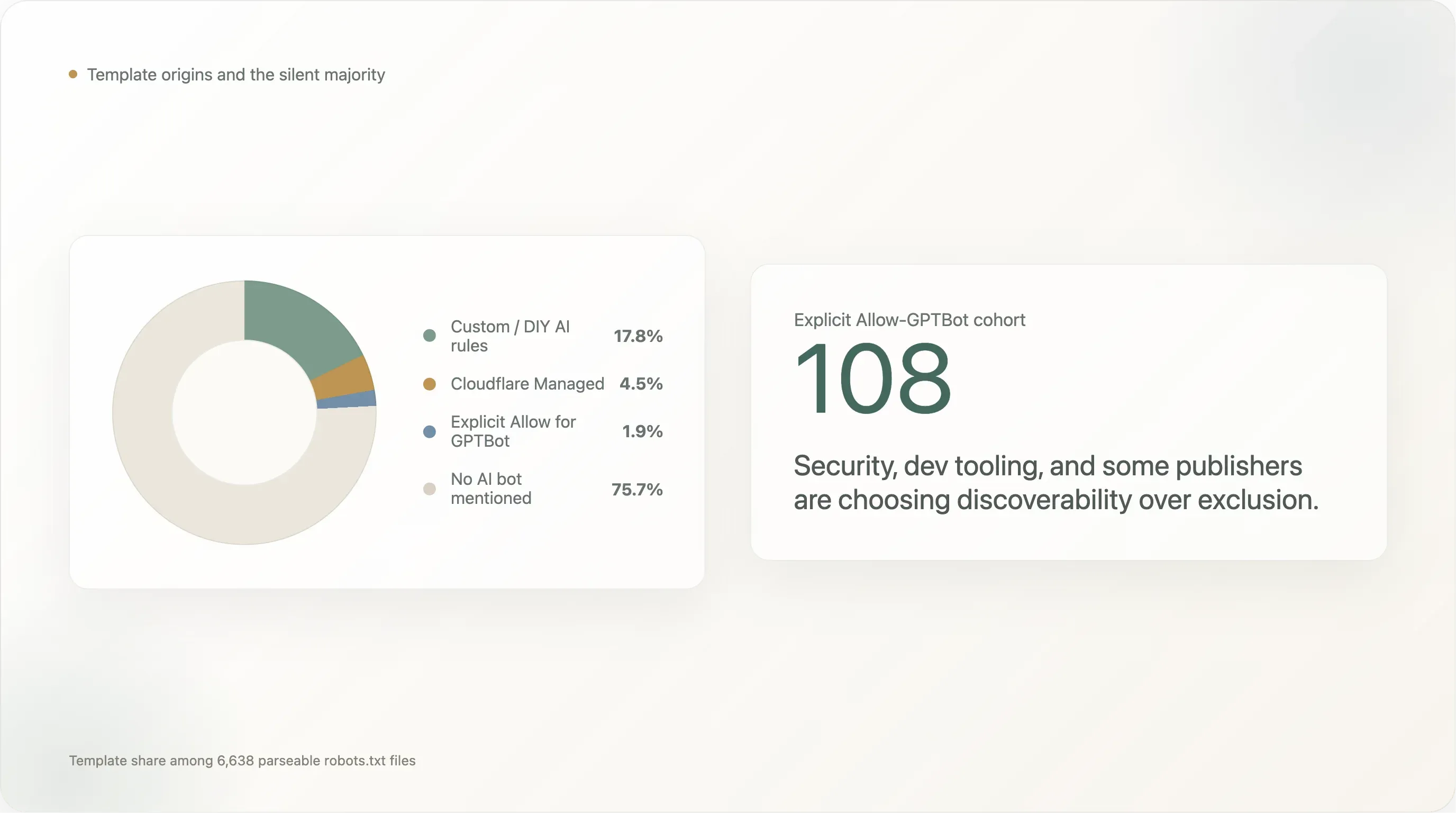
| Plantilla | Sitios | Participación |
|---|---|---|
| No se menciona ningún bot de IA (valor por defecto tipo Shopify, Yoast, o escrito a mano sin considerar IA) | 5,024 | 75.7% |
| Reglas de IA personalizadas / DIY | 1,183 | 17.8% |
Cloudflare Managed (Content-Signal: search=yes,ai-train=no) | 302 | 4.5% |
Allow: / explícito para GPTBot | 124 | 1.9% |
| Valor por defecto de Squarespace (28 UAs de IA en el bloque restringido por ruta) | 5 | 0.1% |
Las reglas DIY dominan con 17.8%. El cohorte de bloqueadores redactados internamente está liderado por todas las plataformas de redes sociales (facebook.com, twitter.com, linkedin.com, whatsapp.com, tiktok.com, snapchat.com, pinterest.com, x.com, chatgpt.com), los destinos de comercio electrónico más grandes (amazon.com, amazonvideo.com), las grandes marcas de noticias (nytimes.com, cnn.com, bbc.com, theguardian.com, forbes.com, reuters.com, bbc.co.uk, t-online.de, weather.com), streaming / medios clave (netflix.com, vimeo.com, soundcloud.com, imdb.com) y una larga cola de sitios de servicios profesionales (canva.com, medium.com).
Cloudflare Managed se sitúa en 4.5% — bastante más alto que la penetración de esa misma plantilla en la parte altísima de la curva y más bajo que su penetración en la cola larga fuera de la ventana de este informe. La plantilla se adopta sobre todo en el tramo rank 1001–10000 (4–5%) y prácticamente no aparece en la parte superior de la curva (Top 100: 1 sitio la usa; Top 101–1000: 5 sitios). Las grandes propiedades globales redactan sus propias reglas; la cola larga usa el interruptor.
Algunos sitios concretos con Cloudflare Managed que merecen mención. cloudflare.com usa la plantilla — lo que es coherente (Cloudflare prueba su propio producto en su propio dominio). theatlantic.com usa la plantilla — la única gran marca de noticias estadounidense que encontramos que no escribió una regla personalizada. spankbang.com usa la plantilla — el sitio adulto mejor posicionado que adoptó un bloqueo de IA inyectado por Cloudflare. linktr.ee usa la plantilla, bloqueando el entrenamiento de IA en toda la economía de creadores alojada en Linktree con una sola decisión del proveedor. launchpad.net, nexusmods.com, vinted.fr, cookielaw.org, rustdesk.com y una larga lista de propiedades mediáticas más pequeñas completan el cohorte visible de Cloudflare Managed.
El patrón de adopción de Cloudflare es la evidencia más concreta que hemos visto de que una parte importante de «la política de IA de la web» la están decidiendo los proveedores de infraestructura. La participación absoluta es pequeña (4.5%), pero estructuralmente importante: la plantilla es la que Cloudflare envía por defecto, y la trayectoria de activación por defecto para los próximos 12 meses apunta al alza. Si Cloudflare activa el bloqueo de bots de IA por defecto para cuentas nuevas, la tasa global de bloqueo sube de forma material sin que ningún editor individual tome una decisión.
El valor por defecto de Squarespace (5 sitios en el top-10k, pero un cohorte mucho mayor fuera de nuestra muestra) es otro patrón distinto: Squarespace publica un robots.txt que nombra 28 bots de IA en un solo bloque, pero esos bots heredan las restricciones de ruta de User-agent: * en lugar de recibir una prohibición de todo el sitio. Los rastreadores de IA pueden acceder a /, a la página principal, a las páginas de producto y al blog. Simplemente no pueden acceder a /config o /account. Ya habíamos señalado esto como fuente de falsos positivos de «bloqueo de IA» en escaneos de terceros de sitios Squarespace; la misma advertencia aplica aquí.
Hallazgo 9 — La política de IA es uniforme a lo largo de la distribución de ranking
La intuición convencional para este tipo de estudio es que los sitios más visitados tendrían la política de IA más agresiva — tienen más que perder por el desplazamiento del entrenamiento, más capacidad legal y más escrutinio público. Los datos no respaldan esa intuición.
| Tramo de ranking | n | Cualquier bloqueo de IA | Explícito | Cloudflare Managed |
|---|---|---|---|---|
| Top 100 | 67 | 22.4% | 17.9% | 1 sitio |
| Top 101–1,000 | 598 | 22.9% | 19.2% | 5 sitios |
| Top 1,001–5,000 | 2,810 | 19.0% | 15.3% | 99 sitios |
| Top 5,001–10,000 | 3,773 | 20.8% | 17.8% | 197 sitios |
Los cuatro tramos se mueven entre 19% y 23%. El Top 100 no es más agresivo que la cola larga del 5001 al 10000. La cifra principal parece ser una propiedad de la web pública en 2026, no una señal del tamaño o la prominencia de un sitio individual.
Hay dos factores que contribuyen. Primero, la cabeza de la curva está dominada por dominios de infraestructura / SaaS / búsqueda / portal (Microsoft, Apple, Google, etc.) que, por sí mismos, presentan bajas tasas de bloqueo de IA. Segundo, la cola larga incluye una proporción alta de editores de noticias regionales y sitios bajo jurisdicción de la UE que — como mostraron los Hallazgos 6 y 7 — bloquean IA con más agresividad que la media global. Ambos efectos se cancelan aproximadamente, y el resultado es una cifra principal uniforme.
La columna Cloudflare Managed sí cambia a lo largo de la curva. El Top 1000 tiene 6 sitios gestionados por Cloudflare (1.0%); el Top 1001–10000 tiene 296 (5.7%). Los sitios grandes redactan sus propias reglas; la cola larga usa el interruptor del proveedor. Esta es la única señal realmente dependiente del ranking en el conjunto de datos, y sugiere que a medida que bajas por la curva de tráfico desde la parte alta de la web hacia la cola larga, la proporción de política de IA establecida por proveedores y no por editores aumenta de forma constante. Esperamos que este gradiente continúe más allá del top 10k hacia el top 100k y después.
Hallazgo 10 — Cinco anatomías: cómo se ve robots.txt cuando de verdad es una política
Las cifras describen la forma del conjunto de datos; el carácter real de la «política de IA en la web pública» se ve mejor leyendo archivos concretos. Aquí van cinco que merecen atención, elegidos para abarcar todo el espacio de políticas.
Anatomía 1 — The New York Times (nytimes.com)
Las primeras 14 líneas de nytimes.com/robots.txt:
1# New York Times content is made available for your personal, non-commercial
2# use subject to our Terms of Service here:
3# https://help.nytimes.com/hc/en-us/articles/115014893428-Terms-of-Service.
4# Use of any device, tool, or process designed to data mine or scrape the content
5# using automated means is prohibited without prior written permission from
6# The New York Times Company. Prohibited uses include but are not limited to:
7# (1) text and data mining activities under Art. 4 of the EU Directive on Copyright in
8# the Digital Single Market;
9# (2) the development of any software, machine learning, artificial intelligence (AI),
10# and/or large language models (LLMs);
11# (3) creating or providing archived or cached data sets containing our content to others; and/or
12# (4) any commercial purposes.
13# Contact https://nytlicensing.com/contact/ for assistance.Esto es robots.txt como prueba legal. El archivo está estructurado para ser admisible como evidencia en el litigio NYT v. OpenAI en el que participa. Las referencias a «Art. 4 of the EU Directive» — de una editorial estadounidense — ilustran la observación del Hallazgo 7 de que los marcos legales de la UE se están filtrando al discurso global. La prohibición explícita de «crear o proporcionar conjuntos de datos archivados o en caché» apunta directamente a Common Crawl. El archivo supera las 60 líneas y tiene bloques User-agent nombrados para GPTBot, OAI-SearchBot, ChatGPT-User, anthropic-ai, ClaudeBot, CCBot, Google-Extended, Applebot-Extended, Bytespider, Diffbot, Meta-ExternalAgent, Amazonbot, Omgili, Omgilibot y media docena más — cada bot nombrado tiene su propio Disallow: /.
Anatomía 2 — Der Spiegel (spiegel.de) — permiso de IA a nivel de sección
Der Spiegel es el robots.txt más sofisticado operacionalmente que encontramos en todo el conjunto de datos. El bloque relevante:
1# TLP-6507: Testweise Freischaltung der OpenAI-Suchcrawler fuer ausgewaehlte Bereiche
2User-agent: OAI-SearchBot
3Allow: /ausland/
4Allow: /partnerschaft/
5Allow: /gesundheit/
6Allow: /familie/
7Allow: /reise/
8Allow: /psychologie/
9Allow: /stil/
10Disallow: /
11User-agent: ChatGPT-User
12Allow: /ausland/
13Allow: /partnerschaft/
14Allow: /gesundheit/
15Allow: /familie/
16Allow: /reise/
17Allow: /psychologie/
18Allow: /stil/
19Disallow: /El comentario se traduce como «Activación de prueba de los rastreadores de búsqueda de OpenAI para secciones seleccionadas». Spiegel ha permitido siete categorías de contenido concretas — noticias internacionales, relaciones, salud, familia, viajes, psicología y estilo de vida — para los UAs de inferencia de OpenAI mientras bloquea todo lo demás. Las secciones políticas, las noticias nacionales alemanas y la cobertura de investigación quedan explícitamente excluidas. Common Crawl, Bytespider, Cohere, Webzio-Extended y otros UAs de entrenamiento reciben un Disallow: / completo más abajo en el archivo.
Esto es robots.txt como política editorial a nivel de sección. La teoría implícita es que el contenido de estilo de vida presenta menos riesgo de desplazamiento en entrenamiento y mayor ventaja de citación en inferencia, así que Spiegel permite que la IA muestre esas secciones; la política y la investigación son el foso defensivo, así que la IA queda excluida. No hemos visto este patrón en otros sitios. Implica un nivel de coordinación interna entre redacción, legal e infraestructura que la mayoría de las salas de redacción no ha alcanzado. Esperamos que este tipo de expresión granular de política a nivel de sección se extienda durante 2026–2027 — el archivo de Spiegel es, en esencia, un indicador adelantado.
Anatomía 3 — BBC (bbc.com) — la forma de declaración de política
El robots.txt de BBC comienza con:
1# version: ec59bd036e5138eb4831a9ed44447b1ff310e235
2# The BBC's Terms of Use: https://www.bbc.co.uk/terms
3# - Explain the rules for using our services
4# - Tell you what you can do with our content
5#
6# In short: Please use our site like a human, not a robot.
7# That means:
8# - No scraping, crawling, or systematic extraction of content
9# - No use of BBC content for training or fine-tuning AI models, including LLMs
10# - No retrieval-augmented generation (RAG), AI-powered search, agentic AI or
11# grounding using BBC content
12# - No creating datasets from BBC content
13# - No text and data mining (TDM) under Article 4 of the EU Directive on Copyright
14# - No using BBC content to create summaries for your own use
15# - No business use without permission
16# - The BBC reserves all rights in its content and expressly opts out of any
17# statutory exceptions in any jurisdiction for text and data mining,
18# as permitted by law
19#
20# TL;DR: Browse, read, watch, enjoy - like a human.La BBC versiona su robots.txt (el # version: ec59bd... es un hash de commit de git), prohíbe los ocho tipos concretos de uso de IA que sus abogados siguen de cerca y termina con un resumen de una línea en la voz en prosa sobre la que se construye la marca BBC. La frase «expressly opts out of any statutory exceptions in any jurisdiction» es una reserva global deliberada — está diciendo no confiamos en que ningún régimen jurídico individual nos dé la protección que queremos, así que afirmamos la exclusión en todas partes a la vez. Es el robots.txt más trabajado del conjunto y se lee más como una nota de prensa que como un archivo de configuración.
Anatomía 4 — WordPress.org — la bienvenida explícita
Comparemos todo lo anterior con wordpress.org:
1User-agent: GPTBot
2Allow: /
3User-agent: ClaudeBot
4Allow: /
5User-agent: anthropic-ai
6Allow: /
7User-agent: Google-Extended
8Allow: /
9User-agent: Applebot-Extended
10Allow: /
11User-agent: PerplexityBot
12Allow: /
13User-agent: Bytespider
14Allow: /
15User-agent: CCBot
16Allow: /
17User-agent: Copilot
18Allow: /WordPress.org opta explícitamente por nueve rastreadores de entrenamiento de IA, incluidos los tres (Bytespider, CCBot, anthropic-ai) que más a menudo se bloquean en otros sitios. La teoría implícita es que la documentación y el ecosistema de plugins de WordPress son un bien público cuyo valor aumenta cuando los asistentes de IA pueden responder preguntas sobre él. Cada vez que alguien pregunta a Claude «¿cómo configuro los enlaces permanentes en WordPress?» y Claude ha sido entrenado con wordpress.org/documentation/, la misión de WordPress se ha visto beneficiada. La Fundación parece haber decidido que estar dentro del corpus de entrenamiento de todos los modelos es una ventaja estratégica, y ha usado la gramática expresiva del archivo para decirlo así.
Anatomía 5 — The Verge (theverge.com) — el híbrido patrocinado
Otro patrón que vale la pena mostrar. The Verge estructura sus reglas de IA como Disallow: / \ Allow: /sp/:
1User-agent: GPTBot
2Allow: /
3User-agent: Applebot
4Allow: /
5User-agent: Google-Extended
6Disallow: /
7Allow: /sp/
8User-agent: anthropic-ai
9Disallow: /
10Allow: /sp/
11User-agent: Bytespider
12Disallow: /
13Allow: /sp/
14User-agent: CCBot
15Disallow: /
16Allow: /sp/
17User-agent: ChatGPT-User
18Disallow: /
19Allow: /sp/
20User-agent: ClaudeBot
21Disallow: /
22Allow: /sp/La ruta /sp/ es la sección de contenido patrocinado / de socios de The Verge. El contenido editorial queda bloqueado para el entrenamiento de IA; el contenido patrocinado sí se permite. La lógica económica es clara: los patrocinadores pagan para que su contenido sea descubrible, incluso a través de IA; el escaparate editorial es el foso defensivo. GPTBot está completamente abierto (presumiblemente por una relación directa con OpenAI), Applebot también está completamente abierto como base de búsqueda, y el resto recibe un tratamiento híbrido. Esta es la única estructura de «acceso escalonado a la IA» de este tipo que encontramos.
Estos cinco archivos describen el rango actual de la política de IA en robots.txt. La mayoría de los archivos del top 10k no se parecen a ninguno de ellos — o bien están en silencio, o usan una plantilla de proveedor. Los que sí se parecen a uno de estos fueron escritos por personas que decidieron que el archivo merecía leerse con atención.
Una nota sobre la escala de los archivos: el cuerpo mediano de robots.txt en nuestra muestra es de 858 bytes — demasiado pequeño para codificar una política de IA significativa. La cola derecha es donde viven las reglas: 1,005 sitios (15.3%) tienen un archivo de más de 5 KB, 273 superan los 20 KB y el máximo fue de 248 KB. 460 archivos contienen lenguaje de reserva de derechos de autor; 275 citan la Directiva 2019/790 de la UE por su nombre. En 2026, robots.txt es cada vez más un documento versionado y revisado por abogados, no una línea de configuración.
Hallazgo 11 — 108 sitios dan la bienvenida explícitamente a GPTBot
Un cohorte pequeño pero visible escribe una regla User-agent: GPTBot \n Allow: / — el inverso del más discutido «Disallow GPTBot». La cifra total en nuestra muestra es de 108 sitios con un Allow explícito para GPTBot en la ruta raíz. Los primeros 25 por ranking de Tranco:
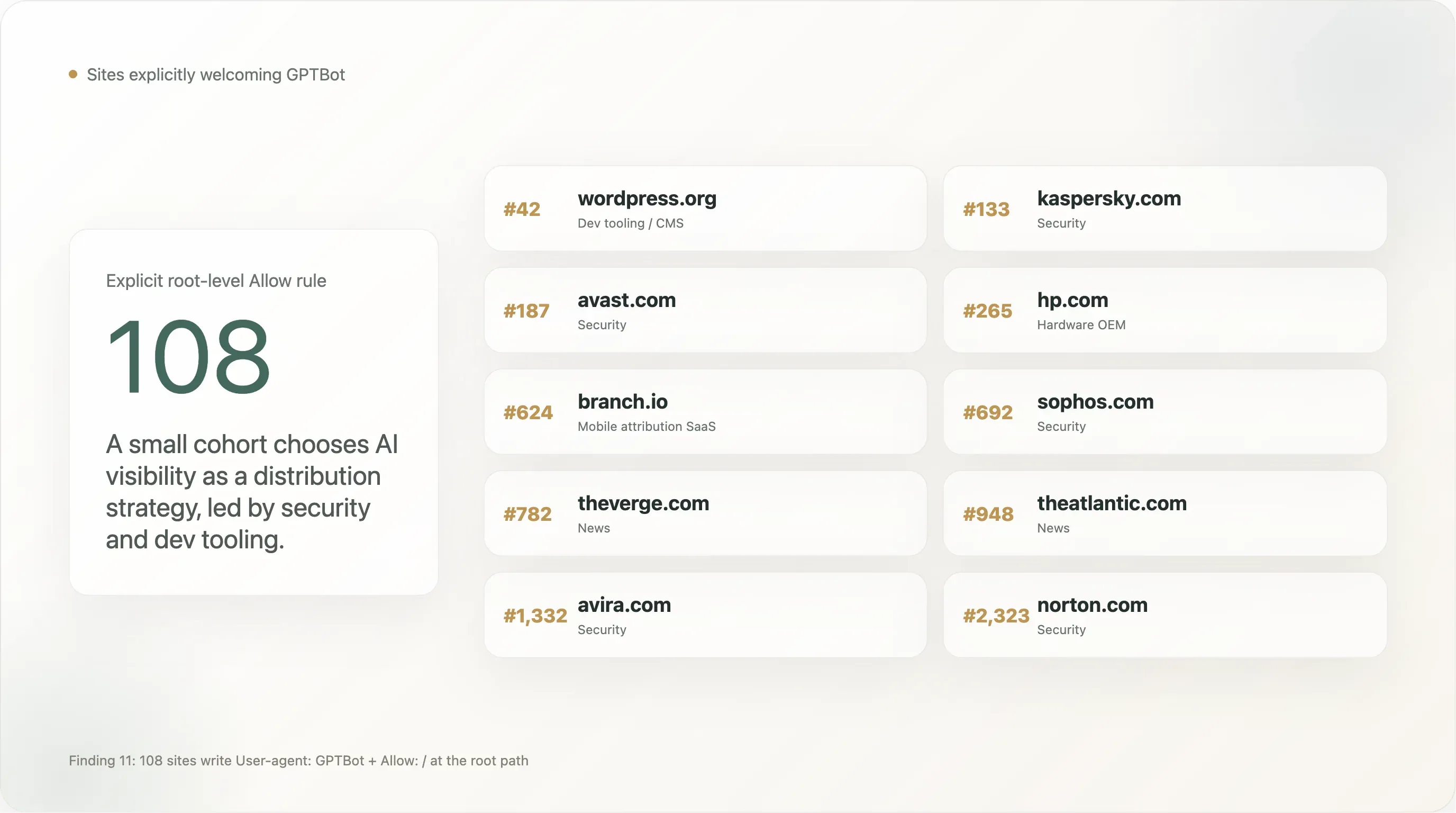
| Posición | Dominio | Sector |
|---|---|---|
| 42 | wordpress.org | Herramientas para desarrolladores / CMS |
| 133 | kaspersky.com | Seguridad |
| 187 | avast.com | Seguridad |
| 265 | hp.com | Fabricante de hardware |
| 624 | branch.io | SaaS de atribución móvil |
| 692 | sophos.com | Seguridad |
| 782 | theverge.com | Noticias |
| 905 | rambler.ru | Portal ruso |
| 945 | kleinanzeigen.de | Marketplace alemán |
| 948 | theatlantic.com | Noticias |
| 1,092 | lge.com | LG Electronics |
| 1,300 | justdial.com | Búsqueda local en India |
| 1,332 | avira.com | Seguridad |
| 1,412 | youm7.com | Noticias de Egipto |
| 1,530 | goodreturns.in | Finanzas en India |
| 1,621 | publi24.ro | Clasificados rumanos |
| 1,807 | geocomply.com | SaaS de cumplimiento |
| 1,908 | nba.com | Deportes |
| 1,956 | oneindia.com | Noticias de India |
| 1,974 | mindbox.ru | SaaS ruso |
| 2,009 | thesun.co.uk | Noticias |
| 2,126 | vox.com | Noticias |
| 2,140 | mgid.com | Publicidad nativa |
| 2,314 | ninjarmm.com | SaaS de gestión de TI |
| 2,323 | norton.com | Seguridad |
Algunos patrones:
Las empresas de seguridad están claramente sobrerrepresentadas. Kaspersky, Avast, Sophos, Avira, Norton, NinjaRMM permiten explícitamente a GPTBot. Esto es una estrategia de distribución deliberada: cuando un usuario pregunta a ChatGPT «¿cuál es el mejor antivirus para mi portátil con Windows?», tener la marca dentro del corpus de entrenamiento del modelo afecta directamente a la recomendación. La seguridad es una de las pocas categorías de producto B2C donde la búsqueda con IA ya está sustituyendo al SEO como canal principal de adquisición, y estas marcas se movieron primero. Esperamos que el resto del sector de seguridad siga en los próximos 12 meses.
Algunas grandes marcas de noticias están en esta lista, no en la lista de bloqueo. The Verge, The Atlantic, Vox, The Sun, NBA.com. Esto no es una contradicción — parece que estos editores han decidido que ser citables dentro de la búsqueda de ChatGPT es más valioso que protegerse del entrenamiento, y escribieron la regla Allow explícita para defenderse de futuros sobrebloqueos por parte de su CDN o CMS. Compáralo con la postura de NYT / Reuters / BBC / Forbes / Guardian de Disallow explícito. Ambas posiciones son defendibles; la industria de noticias no es monolítica.
La presencia de The Sun es notable porque el mismo sitio usa en otra parte de su archivo un bloqueo general User-agent: * de denegar todo. La política de The Sun se lee mejor como «el entrenamiento de IA está prohibido, la búsqueda con IA está permitida y hemos incluido explícitamente a GPTBot como excepción al denegar todo para asegurarnos de que ChatGPT pueda responder preguntas citando a The Sun». Esta es la más sofisticada jurídicamente de las reglas Allow-GPTBot — es una exclusión más una inclusión de un solo proveedor.
La presencia de WordPress.org es la entrada individual más importante de la lista. Una parte no trivial del ecosistema global de CMS de código abierto apunta a WordPress.org para documentación o aloja plugins procedentes de allí. Al permitir explícitamente GPTBot en wordpress.org/robots.txt, la Fundación WordPress ha dicho, en la práctica, que el ecosistema de documentación de WordPress está abierto para entrenamiento — lo que tiene efectos de arrastre en lo bien que Claude, Gemini y ChatGPT pueden responder preguntas del tipo «¿cómo hago…?» sobre WordPress.
Los otros 83 sitios de la lista completa de Allow-GPTBot son una larga cola de noticias regionales, proveedores de seguridad más pequeños, plataformas de clasificados en mercados no anglófonos y SaaS B2B. Hasta donde podemos ver, no existe ninguna coordinación sectorial equivalente de «Allow-GPTBot» — la regla se adopta sitio por sitio, por operadores que han decidido que estar en el corpus es la posición estratégica.
Hallazgo 12 — llms.txt es poco menos que un rumor a esta escala
llms.txt, el formato alternativo propuesto para el descubrimiento de contenido amigable con LLMs (impulsado por Mintlify, Anthropic, Vercel y unos pocos proveedores de herramientas para desarrolladores desde finales de 2024), apenas tiene adopción visible en nuestra muestra.
De los 6,638 sitios que devolvieron un robots.txt analizable, 83 (1.15%) mencionan llms.txt — normalmente como una línea Sitemap: https://example.com/llms.txt. Eso es dos órdenes de magnitud menos que la misma métrica medida en muestras de comercio con fuerte presencia de herramientas para desarrolladores, donde los valores por defecto de Vercel y Mintlify inflan la adopción.
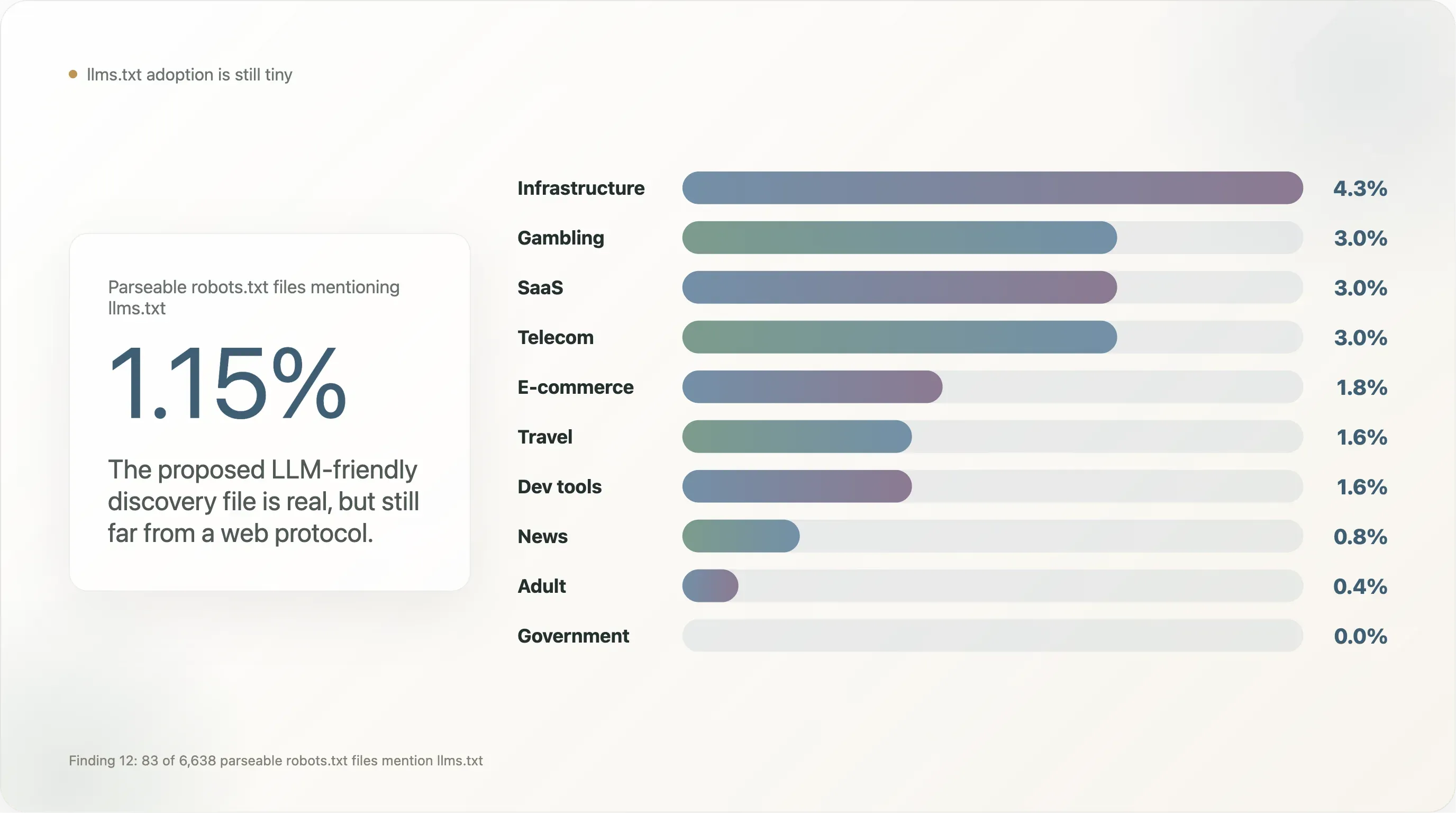
El desglose por categoría:
| Sector | n | % que menciona llms.txt |
|---|---|---|
| Infraestructura | 47 | 4.3% |
| Apuestas | 100 | 3.0% |
| SaaS | 369 | 3.0% |
| Telecom | 33 | 3.0% |
| Comercio electrónico | 224 | 1.8% |
| Viajes | 64 | 1.6% |
| Herramientas para desarrolladores | 129 | 1.6% |
| Noticias | 650 | 0.8% |
| Adulto | 254 | 0.4% |
| Gobierno | 172 | 0.0% |
| Academia | 268 | 0.0% |
| Búsqueda | 12 | 0.0% |
llms.txt se concentra en SaaS cercano a herramientas de desarrollo, apuestas (que adopta funciones nuevas de robots.txt con vocabulario más rápido que otras industrias reguladas porque cuenta con equipos de cumplimiento acostumbrados a añadir metadatos extra) y comercio electrónico B2B. Brilla por su ausencia en noticias y gobierno — los dos segmentos más implicados en la política de IA y cuya adopción sería necesaria para que el estándar pasara de «experimento de proveedor» a «protocolo web». Hasta entonces, llms.txt es real pero pequeño, y una auditoría de seguimiento a finales de 2026 será una buena prueba de repetición.
El problema estructural al que se enfrenta llms.txt es que no está estandarizado por ningún proceso del IETF y los grandes proveedores de IA no se han comprometido a respetarlo. Una regla de robots.txt cuenta con 30 años de infraestructura de rastreo alrededor; una de llms.txt no tiene nada. Hasta que al menos un gran proveedor (OpenAI, Anthropic, Google, Cloudflare) declare apoyo formal, el archivo es esencialmente un artefacto de marketing del ecosistema Mintlify / Vercel. No esperamos que eso cambie en 2026.
Hallazgo 13 — Accesibilidad: robots.txt sigue siendo legible para dos tercios de la web principal
Una observación lateral que no debía ser un hallazgo: el 66% de los 10,000 sitios principales devolvió un robots.txt analizable a una única IP de investigación, y solo 7 de 10,000 (0.07%) devolvieron 429 Too Many Requests. Esto es una buena noticia para robots.txt como protocolo público.
A modo de comparación, el mismo flujo ejecutado dos meses antes sobre una muestra de comercio de mercado medio de 1,008 dominios recibió 429 del 52% de los dominios resueltos — Shopify y CDNs de Cloudflare limitando de forma agresiva cualquier UA que no fuera un gran motor de búsqueda. La web de mayor tráfico es mucho más amable: es más probable que los sitios principales tengan o bien (a) niveles de gestión de bots menos agresivos, o bien (b) listas de permitidos explícitas para rastreadores de investigación conocidos, o ambas cosas.
La tasa de fetch_failed del 21% en el top-10k está dominada por dominios apex de CDN (akamai.net, cloudfront.net, fastly.net, apple-dns.net, gtld-servers.net) que no ejecutan un servidor web en /. No nos están bloqueando; simplemente no tienen nada que servir. Excluyéndolos, la tasa real de fallos de «intentó leerse pero no se pudo» está en los dígitos bajos.
Esto significa que futuras iteraciones de este informe — capturas trimestrales, comparaciones interanuales — pueden ejecutarse de forma barata y reproducible en una sola máquina. La ventana de auditoría sigue abierta en la parte alta de la curva. El caso asimétrico es la cola larga y el segmento de comercio, donde la limitación a nivel de CDN ya ha privatizado efectivamente robots.txt. Esperamos que esta divergencia se amplíe: los sitios principales seguirán siendo legibles porque los indexan motores de búsqueda que exigen legibilidad; el comercio de cola larga será menos legible a medida que las capas de lucha contra bots de Cloudflare se desplieguen con más agresividad. La auditabilidad pública de robots.txt se está bifurcando siguiendo la misma línea que separa «la web visible» de «la web protegida operativamente».
IV. Qué significa todo esto
Cuatro afirmaciones, en orden de cuán sólidamente las respalda el dato.
1. Internet tiene una política de IA por sector, no una política global. La diferencia de 12× entre noticias y telecom domina cualquier cifra agregada. Informar de «X% de la web bloquea IA» sin un corte sectorial sobrestima SaaS/gobierno/desarrollo y subestima noticias/viajes/social. Hacerlo sector por sector es la única forma honesta de presentar estos datos.
2. El artículo 4 de la Directiva de Derechos de Autor de la UE es el único régimen legal que mueve las cifras de forma visible. Los sitios ccTLD de la UE bloquean al 35% frente a la base global del 19%. La litigación en EE. UU. (NYT contra OpenAI, informe de enero de 2025 de la Oficina de Derechos de Autor) ha movido al cohorte de noticias estadounidense, pero no a la web estadounidense más amplia. El marco de la UE también se está filtrando globalmente a través de la plantilla de Cloudflare, que cita la Directiva 2019/790 en su texto base sin importar la jurisdicción del cliente.
3. Se están expresando dos «políticas de IA» paralelas y no coinciden entre sí. La política deliberada y escrita a mano (17.8%, sobre todo noticias/social/viajes/comercio electrónico) y la política heredada gestionada por Cloudflare (4.5%) se solapan en el fondo, pero difieren en legitimidad. En un mundo donde los operadores de IA buscan cobertura legal para ignorar robots.txt, la defensa de «lo escribimos y lo revisamos» es estructuralmente más fuerte que «solo lo activé con un interruptor». El incentivo litigioso es llevar la política de la segunda categoría a la primera.
4. Lo que los editores están bloqueando es el corpus, no el modelo. CCBot con 16.3% — por encima de cualquier bot de marca de modelo — es la declaración más clara de esto. Denegar OpenAI no saca a un editor del entrenamiento; denegar CCBot sí. El 14.1% de la web top-10k bloquea CCBot mientras mantiene bienvenido a Googlebot. El patrón «bloquear entrenamiento, mantener búsqueda» es la regla modal de IA en 2026.
Para los sitios que están pensando en su propia postura: la postura media es el silencio — el 80% del top 10k no dice nada sobre IA. El 17% que escribe reglas se concentra en Disallow, pero un cohorte pequeño y creciente (la lista explícita de Allow-GPTBot, 1.5%, liderada por proveedores de seguridad) está eligiendo públicamente la postura inversa. No hay consenso sectorial y no lo habrá en los próximos doce meses.
Para los operadores de IA: seguir sosteniendo que robots.txt es un protocolo heredado con semántica ambigua se vuelve cada vez más difícil de defender cuando el 17% de los sitios más grandes del mundo ha escrito reglas deliberadas explícitas nombrando bots a mano, y el 3.8% de los archivos cita una ley concreta de la UE por número de artículo. Si hay que respetar esas reglas o no, es una decisión empresarial; el hecho de que existan ya es una realidad empírica.
V. Perspectiva: lo que esperamos para finales de 2026
Tres trayectorias visibles en el conjunto de datos:
Cloudflare Managed duplicará con creces su participación, y plausiblemente alcanzará el 10%+ del top-10k analizable. La hoja de ruta de Cloudflare discute públicamente activar por defecto el bloqueo de bots de IA para cuentas nuevas. Si el interruptor se lanza activado por defecto, la tasa global de bloqueo subirá 5–8 puntos porcentuales sin que ningún editor haga nada. Sabremos que esto está ocurriendo cuando la participación de Cloudflare Managed en el tramo 5001–10000 supere su actual 5.7%.
Las políticas de IA a nivel de sección (estilo Spiegel) se extenderán entre las grandes cabeceras de noticias. La lógica económica — dejar que la IA cite el contenido de bajo riesgo, proteger el contenido-foso — es lo bastante convincente como para esperar que al menos 10 cabeceras de peso implementen reglas por sección antes de terminar 2026. Vigilen primero la prensa alemana y francesa de segundo nivel; el marco legal premia allí la experimentación.
El cohorte de Allow-GPTBot explícito crecerá, liderado por SaaS B2B y herramientas para desarrolladores. Cuando la búsqueda con IA se convierta en un canal de adquisición medible para los proveedores de software (como ya lo es en seguridad), el CMO marginal escribirá User-agent: GPTBot \n Allow: / para inmunizarse contra bloqueos accidentales excesivos. Esperamos que la lista de 108 sitios se aproxime al doble a fin de año.
Lo que no esperamos: un cambio significativo en la cuota de la mayoría silenciosa. El 80% de la web que no dice nada sobre IA incluye sectores (gobierno, telecom, infraestructura, SaaS B2B) sin razón económica para escribir una regla y sin presión legal para hacerlo. La política universal de IA no llegará.
VI. Limitaciones
- Sesgo de una sola captura. Las obtenciones se realizaron en una ventana de 36 horas a principios de mayo de 2026. El archivo cambia a diario en el Top 100; cabe esperar una deriva de 1–2 puntos porcentuales por trimestre en las cifras principales.
- Lagunas de clasificación por industria. 6,593 de 10,000 sitios siguieron como
unknowndespués del clasificador de cuatro capas. Los porcentajes por industria son sólidos donde n es grande (noticias: 650, streaming: 440, saas: 369, academia: 268, adulto: 254, comercio electrónico: 224, gobierno: 172, finanzas: 129, desarrollo: 129) y más ruidosos por debajo de n=30. El corte de noticias por país también es limitado: DE/FR/UK tienen n≥15, mientras que Corea/Suecia/República Checa se apoyan en n=20–25. robots.txtes voluntario. UnDisallowes una solicitud, no una barrera.Bytespider,PerplexityBoty otros han sido documentados ignorando reglas. Medimos declaraciones de política, no su aplicación.- Auditoría de IP única basada en EE. UU. No pudimos leer el 21% de los dominios resueltos. La mayoría son puntos apex de CDN sin servidor web; una pequeña parte son sitios cuyo CDN nos bloqueó antes de llegar al origen. Esto sesga ligeramente la muestra hacia infraestructuras más antiguas y contra sitios geobloqueados por país de origen.
- Semántica de la lista Tranco. Tranco filtra por estabilidad; no es un ranking verdadero de comportamiento del usuario. Las cifras agregadas son robustas frente a la elección de la lista; las posiciones de ranking concretas no lo son.
- No hay datos de tráfico. Medimos la política de
robots.txt, no el rendimiento real de los bots de IA. La política y el tráfico no siempre coinciden.
VII. Reproducir esto
Todo lo usado para producir este informe está en la carpeta de entrega.
- tranco_top10k.csv — lista de entrada
- out/sites.csv — dominio × ranking × industria × idioma × estado de robots.txt (10,000 filas)
- out/fetch_meta.csv — resultado de obtención por dominio (estado, esquema, bytes, error)
- out/bot_status.csv — cuadrícula dominio × bot (250,000 filas: bloqueado, tiene_regla, fetch_status)
- out/site_meta.csv — un registro analítico por sitio (plantilla, booleanos resumidos)
- out/analysis.json — cada métrica citada en el informe
- 01_fetch_robots.py, 02_classify.py, 03_parse_and_analyze.py — flujo completo en Python
Las correcciones de metodología, incidencias del conjunto de datos y análisis de seguimiento son bienvenidos en support@thunderbit.com. Este informe se publica de forma independiente de cualquier posición comercial que Thunderbit tenga; construimos un raspador web IA y tenemos un interés estructural en que robots.txt siga siendo un contrato legible por máquina y significativo en la web pública. Los datos de este informe se sostienen por sí mismos. — El equipo de investigación de Thunderbit, mayo de 2026.