

La demanda de datos etiquetados de alta calidad en machine learning nunca ha sido tan alta. Cada vez que hablo con equipos que están creando nuevos modelos de IA —ya sea para previsión de ventas, recomendaciones de productos o análisis de sentimiento de clientes— aparecen siempre los mismos puntos de dolor: etiquetar datos a mano es lento, caro y, francamente, un poco agotador para el alma. He visto proyectos estancarse durante semanas (o meses) mientras esperan suficientes ejemplos etiquetados para entrenar un modelo decente. ¿Y cuando las etiquetas no son consistentes? Bueno, digamos que las predicciones de tu modelo pueden acabar siendo tan fiables como mis intentos de aparcar en paralelo.
Pero aquí va la buena noticia: la etiquetación automatizada de datos con machine learning está cambiando las reglas del juego. Al dejar que la IA haga el trabajo pesado, las empresas no solo están acelerando el proceso de etiquetado, sino también mejorando la precisión y la consistencia, dos cosas que pueden hacer que tu proyecto de ML triunfe o fracase. En esta guía, te explicaré cómo funciona la etiquetación automatizada de datos, por qué es tan crítica para construir modelos robustos y cómo puedes usar herramientas como Thunderbit para montar tu propio flujo de trabajo de etiquetado automatizado, sin necesidad de programar.
¿Qué es la etiquetación automatizada de datos con machine learning?
Vamos a desglosarlo. La etiquetación automatizada de datos con machine learning significa usar algoritmos y herramientas de IA para asignar etiquetas —como “spam” o “no spam”, “gato” o “perro”, “positivo” o “negativo”— a tus datos en bruto, sin que una persona tenga que revisar cada ejemplo uno por uno. Piensa en ello como la diferencia entre etiquetar miles de fotos de vacaciones a mano o usar reconocimiento facial para organizarlas automáticamente por persona, lugar o incluso estado de ánimo.
La etiquetación manual tradicional es exactamente lo que suena: personas revisando los datos uno por uno y asignando la etiqueta correcta. Es precisa (a veces), pero lenta, costosa y difícil de escalar. La etiquetación automatizada, en cambio, usa modelos de machine learning —entrenados con un conjunto más pequeño de datos etiquetados manualmente— para predecir etiquetas para el resto del conjunto de datos. ¿El resultado? Etiquetado más rápido, más consistente y más escalable (GeeksforGeeks).
Para los usuarios de negocio, esto significa que puedes crear mejores modelos, más rápido y con mucho menos trabajo manual pesado. Y en el mundo actual impulsado por los datos, eso supone una ventaja competitiva importante.
Automatiza la etiquetación de datos con Thunderbit Usa el raspador web con IA de Thunderbit para automatizar tu flujo de etiquetado de datos, sin necesidad de programar. Get Started Free
Por qué la etiquetación automatizada de datos es clave para modelos de machine learning de alta calidad
La cuestión es esta: la calidad de tus datos etiquetados influye directamente en el rendimiento de tus modelos de machine learning. Como dice el refrán: “basura entra, basura sale”. Si tus etiquetas son inconsistentes o incorrectas, tu modelo aprenderá patrones equivocados y tus predicciones se resentirán (DataCamp).
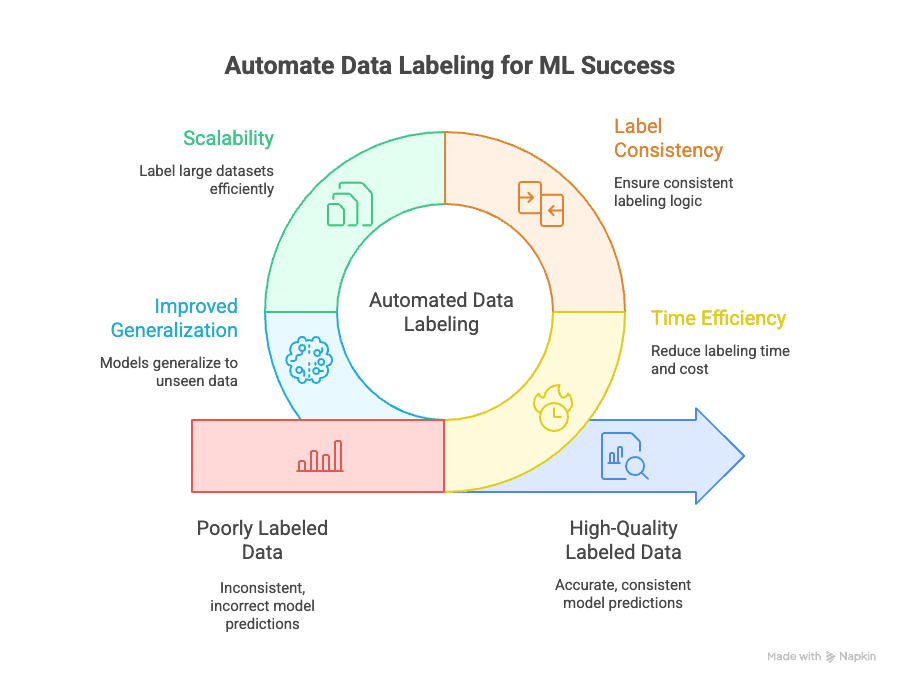
La etiquetación automatizada de datos aborda varios desafíos clave:
- Eficiencia de tiempo: La etiquetación manual puede consumir el 70 % del tiempo y del coste total de un proyecto de ML. La automatización reduce eso a una fracción, permitiéndote iterar y desplegar modelos más rápido.
- Consistencia de etiquetas: Las máquinas no se cansan ni se distraen. La etiquetación automatizada garantiza que cada punto de datos se etiquete con la misma lógica, reduciendo el error humano y el sesgo (GeeksforGeeks).
- Escalabilidad: ¿Necesitas etiquetar 10.000, 100.000 o incluso un millón de puntos de datos? La automatización lo hace posible, sin contratar a todo un ejército de anotadores (Keylabs).
- Mejor generalización: Las etiquetas coherentes y de alta calidad ayudan a que tus modelos generalicen mejor a datos nuevos y no vistos, que es el objetivo final en machine learning (Kili Technology).
Y el impacto en el negocio es real: Keylabs informa de que los flujos híbridos que combinan etiquetado asistido por IA con revisión humana pueden mejorar la precisión del etiquetado hasta en un 80 % frente a los flujos puramente manuales, lo que se traduce directamente en iteraciones de modelo más rápidas y predicciones posteriores más fiables.
Comparación entre etiquetación manual y automatizada de datos
Veámoslo lado a lado:
| Factor | Etiquetado manual | Etiquetado automatizado con ML |
|---|---|---|
| Velocidad | Lento (semanas/meses para conjuntos de datos grandes) | Rápido (minutos/horas para conjuntos de datos grandes) |
| Precisión | Alta, pero propensa al error humano y a la inconsistencia | Alta, con lógica consistente y menos errores |
| Escalabilidad | Limitada por los recursos humanos | Escala fácilmente a millones de puntos de datos |
| Coste | Alto (intensivo en mano de obra) | Menores costes a largo plazo (Keylabs) |
| Ideal para | Conjuntos de datos pequeños, complejos o ambiguos | Conjuntos de datos grandes, repetitivos o bien definidos |
La etiquetación manual sigue teniendo su lugar, sobre todo para casos límite o datos ambiguos, pero para la mayoría de aplicaciones empresariales, la automatización es el camino a seguir.
Los pasos básicos de la etiquetación automatizada de datos con machine learning
Entonces, ¿cómo funciona realmente la etiquetación automatizada de datos? Este es el flujo de trabajo de principio a fin que recomiendo (y que yo mismo uso):
- Recopilación y preprocesamiento de datos
- Extracción y preparación de características
- Etiquetado automatizado mediante machine learning
- Garantía de calidad y revisión humana
Veamos cada paso.
Paso 1: Recopilación y preprocesamiento de datos
Antes de poder etiquetar nada, necesitas recopilar y limpiar tus datos. Esto puede significar extraer listados de productos de sitios web, exportar reseñas de clientes o recopilar imágenes de bases de datos internas. La clave aquí es la calidad: datos malos generan etiquetas malas, y eso acaba en modelos malos (Snorkel AI).
Buenas prácticas:
- Elimina duplicados y entradas irrelevantes
- Estandariza formatos (fechas, monedas, etc.)
- Gestiona los datos faltantes o incompletos
Paso 2: Extracción y preparación de características
Después, identificas las características que importan para tu tarea de etiquetado. Por ejemplo, si estás etiquetando listados de productos, podrías extraer atributos como precio, marca, categoría y descripción. En ventas o marketing, esto podría significar sacar nombres de empresas, información de contacto o sentimiento de correos electrónicos.
Ejemplo de negocio: Con Thunderbit, puedes extraer datos estructurados de páginas web —como especificaciones de productos, reseñas o datos de contacto— sin escribir ni una sola línea de código.
Paso 3: Etiquetado automatizado mediante machine learning
Aquí es donde ocurre la magia. Usas modelos de machine learning —entrenados con un conjunto de datos más pequeño etiquetado manualmente— para predecir etiquetas para el resto de tus datos. Las técnicas más comunes incluyen:
- Modelos supervisados: entrenas un clasificador con ejemplos etiquetados y luego lo usas para etiquetar nuevos datos.
- Etiquetado basado en reglas: usas reglas predefinidas (por ejemplo, “si el precio es > 1000 $, etiquetar como ‘premium’”) para casos simples.
- Aprendizaje activo: el modelo pide intervención humana en los casos dudosos, mejorando con el tiempo (GeeksforGeeks).
- Aprendizaje por transferencia: usas modelos preentrenados para acelerar el etiquetado en nuevos dominios (GeeksforGeeks).
¿El resultado? Etiquetas coherentes y de alta calidad, a escala.
Paso 4: Garantía de calidad y revisión humana
Incluso los mejores modelos necesitan una revisión de cordura. La revisión humana periódica ayuda a detectar casos límite, datos ambiguos o deriva del modelo. Algunos pasos prácticos de QA incluyen:
- Tomar muestras aleatorias de datos etiquetados para revisión manual
- Comparar las etiquetas automáticas con un conjunto de referencia “gold standard”
- Usar métricas de acuerdo entre anotadores para medir la consistencia (Kili Technology)
Cómo usar Thunderbit para la etiquetación automatizada de datos con machine learning
Ahora vamos a la parte práctica. Thunderbit es un raspador web con IA y una herramienta de etiquetado de datos diseñada para usuarios de negocio, sin necesidad de programar. Así puedes usarlo para automatizar tu flujo de trabajo de etiquetado de datos:
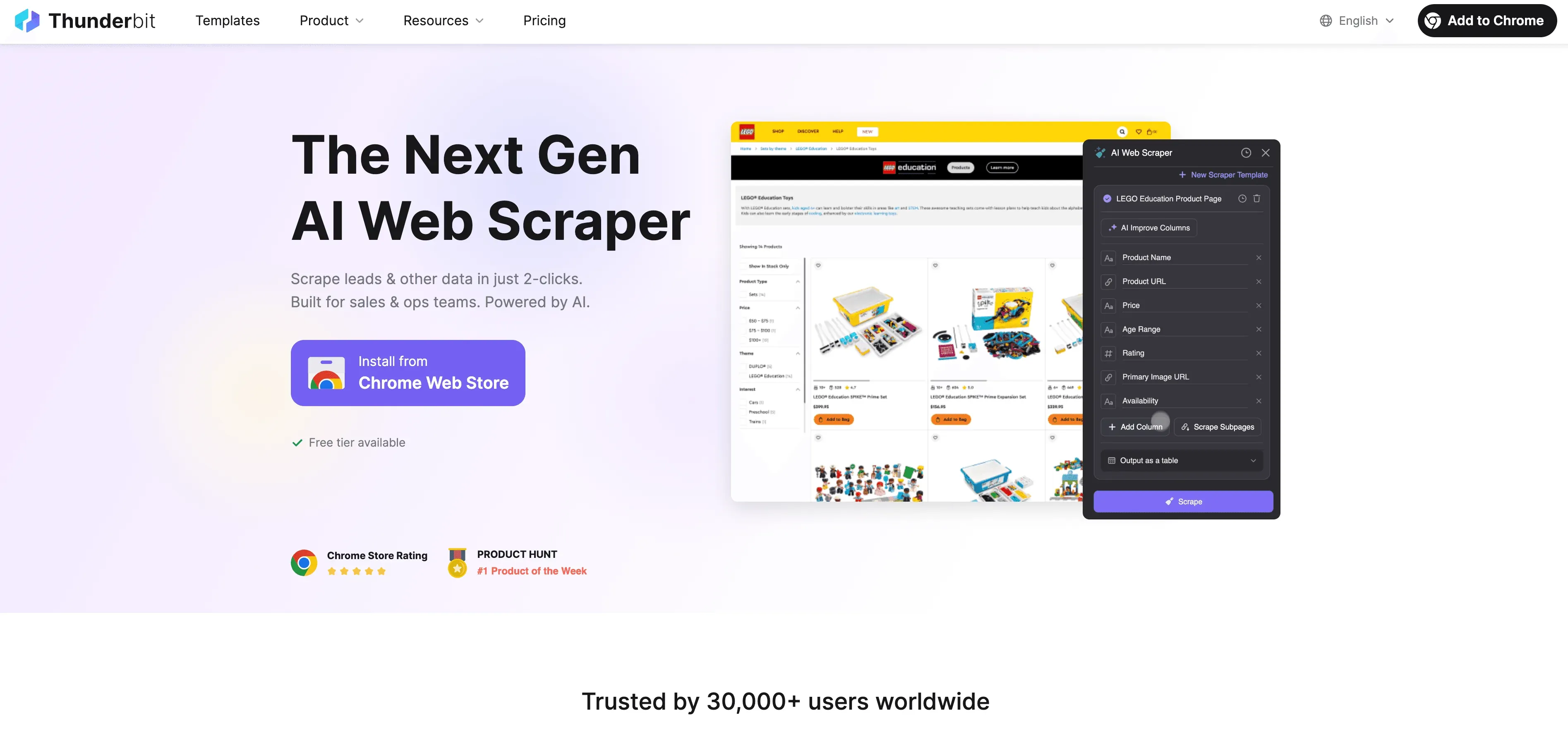
Guía paso a paso
- Extrae datos de sitios web: Usa la extensión de Chrome de Thunderbit para recopilar datos estructurados de cualquier sitio web. Solo tienes que abrir la extensión, seleccionar tu fuente de datos y dejar que la IA de Thunderbit sugiera los mejores campos para extraer.
- Define las instrucciones de etiquetado: Usa las indicaciones en lenguaje natural de Thunderbit para decirle a la IA cómo etiquetar tus datos. Por ejemplo: “Etiqueta todos los productos de más de 500 $ como ‘premium’” o “Marca las reseñas con sentimiento positivo”.
- Aplica la etiquetación automatizada: La función Field AI Prompt de Thunderbit te permite personalizar y refinar cómo se asignan las etiquetas, ideal para tareas de etiquetado complejas o con múltiples campos.
- Exporta los datos etiquetados: Una vez etiquetados, exporta los datos directamente a Excel, Google Sheets, Airtable o Notion, listos para entrenar el modelo o analizarlos.
¿Y lo mejor? Thunderbit está pensado para usuarios no técnicos de ventas, marketing, operaciones y más. No necesitas escribir una sola línea de código ni pelearte con plantillas complejas.
Prueba Thunderbit para la etiquetación automatizada de datos
Prompts en lenguaje natural y funciones Field AI de Thunderbit
Una de mis funciones favoritas es poder definir la lógica de etiquetado en lenguaje sencillo. ¿Quieres categorizar leads por región, etiquetar productos por categoría o marcar correos con lenguaje urgente? Solo describe lo que quieres y la IA de Thunderbit se encargará del resto.
Ejemplos de prompts:
- “Etiqueta todos los contactos con correo ‘.edu’ como segmento de ‘Educación’.”
- “Si la reseña menciona ‘envío rápido’, etiqueta como ‘Experiencia de envío positiva’.”
- “Agrupa los productos por marca y rango de precio.”
La función Field AI Prompt de Thunderbit te permite ir todavía más al detalle, personalizando la lógica de etiquetado para cada columna, combinando reglas o incluso traduciendo las etiquetas a varios idiomas.
Raspado de subpáginas y etiquetado de múltiples campos
¿Estructuras de datos complejas? No hay problema. La función de raspado de subpáginas de Thunderbit te permite extraer y etiquetar datos de páginas anidadas —como detalles de productos o biografías de autores— y combinarlo todo en una sola tabla estructurada. Puedes etiquetar varios campos de una sola vez, ahorrando aún más tiempo.
Caso de uso real: extraer listados de productos de un sitio de ecommerce, luego seguir el enlace de cada producto para extraer y etiquetar especificaciones, reseñas e información del vendedor, todo en un solo flujo de trabajo.
Integrar varias herramientas de etiquetado de datos para lograr mayor precisión y eficiencia
Aunque Thunderbit cubre muchísimas necesidades, a veces necesitas herramientas especializadas para ciertos tipos de datos, como anotación de imágenes o etiquetado de vídeo. Ahí es donde entran plataformas como Label Studio o Supervisely.
Consejo profesional: usa Thunderbit para encargarte de la extracción de datos web y el etiquetado inicial, y luego exporta tus datos a Label Studio o Supervisely para anotaciones avanzadas (como cajas delimitadoras en imágenes o etiquetas de vídeo fotograma a fotograma). Este enfoque multiherramienta te permite aprovechar los puntos fuertes de cada plataforma, mejorando tanto la precisión como la eficiencia (GeeksforGeeks).
Cuándo usar herramientas especializadas junto con Thunderbit
- Anotación de imágenes: para tareas como detección de objetos o segmentación, usa Supervisely o Label Studio.
- Etiquetado de vídeo: las herramientas especializadas para vídeo gestionan la anotación y el seguimiento fotograma a fotograma.
- Tareas complejas con múltiples etiquetas: combina la extracción de datos estructurados de Thunderbit con herramientas de anotación avanzada para obtener los mejores resultados.
Mejor práctica: empieza con Thunderbit para un etiquetado rápido y escalable de datos estructurados y semiestructurados, y luego incorpora herramientas especializadas según lo necesites para anotaciones más profundas.
Cómo extraer datos de PDF usando IA Aprende a extraer y etiquetar datos de PDFs usando las herramientas con IA de Thunderbit. Get Started Free
Mejores prácticas para la etiquetación automatizada de datos con machine learning
¿Quieres sacar el máximo partido a tu flujo de etiquetado automatizado? Estos son mis mejores consejos:
- Define directrices claras para las etiquetas: las etiquetas ambiguas generan datos inconsistentes; sé específico sobre lo que significa cada etiqueta.
- Empieza con un conjunto semilla de alta calidad: etiqueta manualmente una muestra pequeña y representativa para entrenar tu modelo inicial.
- Itera y mejora: usa aprendizaje activo para refinar tu modelo con el tiempo, centrando la revisión humana en los casos más difíciles.
- Valida con regularidad: revisa periódicamente una muestra aleatoria de datos etiquetados para detectar errores o deriva.
- Integra y automatiza: usa herramientas como Thunderbit para conectar recopilación de datos, etiquetado y exportación en un único flujo de trabajo.
Desafíos comunes y cómo superarlos
La etiquetación automatizada de datos no está exenta de obstáculos. Así puedes abordar los más comunes:
- Datos ambiguos: usa definiciones claras y detalladas de las etiquetas y proporciona ejemplos para los casos límite.
- Deriva del modelo: reentrena tu modelo de etiquetado con regularidad usando nuevos datos revisados manualmente.
- Casos límite: establece un proceso de revisión humana para puntos de datos inciertos o novedosos.
- Problemas de integración: elige herramientas (como Thunderbit) que ofrezcan exportación sencilla a tus plataformas preferidas.
Conclusión y puntos clave
La etiquetación automatizada de datos con machine learning es el ingrediente secreto detrás de los modelos de IA más eficaces de hoy en día. Ahorra tiempo, reduce costes y, lo más importante, entrega las etiquetas coherentes y de alta calidad que tus modelos necesitan para rendir al máximo. Al combinar herramientas como Thunderbit con plataformas especializadas de anotación, puedes construir un flujo de etiquetado rápido, preciso y escalable, independientemente de tu nivel técnico.
¿Listo para comprobar la diferencia por ti mismo? Descarga Thunderbit, prueba la etiquetación automatizada en tu próximo proyecto y verás cómo tus modelos de machine learning se vuelven más inteligentes y más rápidos. Y si quieres más consejos y buenas prácticas, echa un vistazo al blog de Thunderbit para guías en profundidad y tutoriales.
Automatiza la etiquetación de datos con Thunderbit
Preguntas frecuentes
1. ¿Qué es la etiquetación automatizada de datos con machine learning?
Es el proceso de usar modelos de IA y ML para asignar etiquetas a los datos automáticamente, en lugar de hacerlo manualmente. Este enfoque acelera el etiquetado, mejora la consistencia y escala a conjuntos de datos grandes.
2. ¿Por qué importa la calidad del etiquetado para machine learning?
Los modelos solo aprenden los patrones que codifican sus etiquetas, así que unas etiquetas inconsistentes o erróneas enseñan al modelo lo incorrecto. Informes del sector de proveedores de etiquetado como Keylabs señalan que los flujos híbridos de IA más humanos pueden aumentar la precisión del etiquetado hasta en un 80 % frente a los puramente manuales, y esa mejora se refleja directamente en el rendimiento del modelo.
3. ¿Cómo ayuda Thunderbit con la etiquetación automatizada de datos?
Thunderbit te permite extraer y etiquetar datos web usando IA, con prompts en lenguaje natural y lógica de campos personalizable, sin necesidad de programar. Es ideal para usuarios de negocio en ventas, marketing y operaciones.
4. ¿Puedo combinar Thunderbit con otras herramientas de etiquetado?
Por supuesto. Usa Thunderbit para la extracción de datos estructurados y el etiquetado inicial, y luego exporta a herramientas como Label Studio o Supervisely para anotación avanzada de imágenes o vídeo.
5. ¿Cuáles son las mejores prácticas para la etiquetación automatizada de datos?
Define directrices claras para las etiquetas, empieza con un conjunto semilla de calidad, itera con aprendizaje activo, valida con regularidad y usa herramientas integradas para agilizar tu flujo de trabajo.
¿Listo para automatizar tu etiquetado de datos y potenciar tus proyectos de machine learning? Prueba Thunderbit y comprueba cuánto tiempo —y frustración— puedes ahorrarte.
Más información:
- Cómo extraer datos de PDF usando IA
- Qué es el data scraping y cómo hacerlo en 2025
- Qué es el list crawling y cómo hacerlo usando IA
- Cómo extraer cualquier sitio web usando IA
Prueba el Raspador Web IA para la etiquetación automatizada de datos Get Started Free




