Εξαγωγέας Substack














Ξεκλειδώστε τα δεδομένα του Substack με το Thunderbit
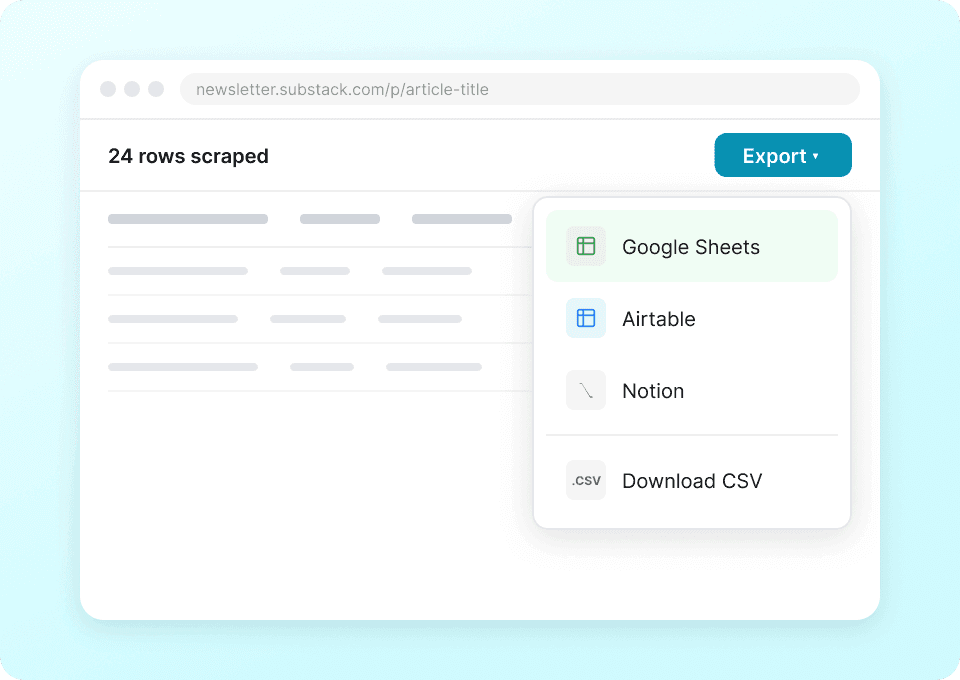
Στείλτε τα δεδομένα του Substack απευθείας στις εφαρμογές σας
Σταματήστε να κάνετε χειροκίνητο copy-paste στα στοιχεία δημοσιεύσεων του Substack, όπως ονόματα συγγραφέων, τίτλους άρθρων και αριθμούς συνδρομητών. Με το Thunderbit, ένα μόνο κλικ στέλνει τα εξαγόμενα δεδομένα σας απευθείας σε Google Sheets, Notion ή Airtable — ώστε να αναλύετε τάσεις δημοσιεύσεων και την απόδοση περιεχομένου χωρίς την κουραστική χειροκίνητη εργασία.
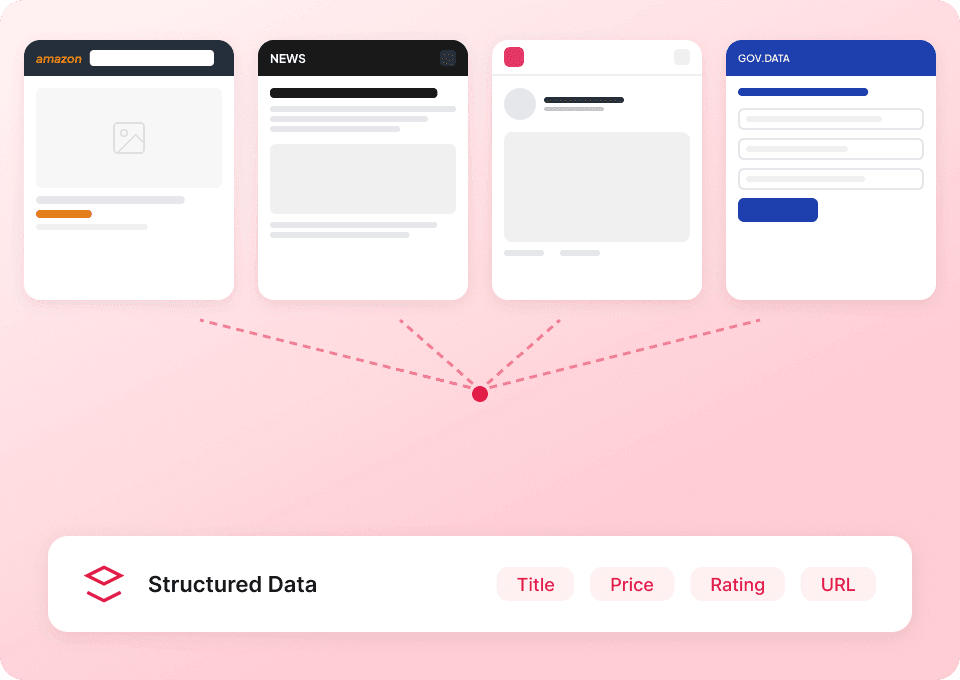
Ένας scraper για το Substack και όχι μόνο
Δεν χρειάζεται να αλλάζετε εργαλείο για κάθε ιστοσελίδα. Το Thunderbit λειτουργεί στο Substack αμέσως, χωρίς ρυθμίσεις, και περιλαμβάνει πάνω από 50 έτοιμα templates για άλλες δημοφιλείς πλατφόρμες. Εξάγετε περιγραφές δημοσιεύσεων, περιεχόμενο άρθρων και πολλά ακόμη — και μετά χρησιμοποιήστε το ίδιο εργαλείο για να συλλέξετε δεδομένα από οπουδήποτε στο web.
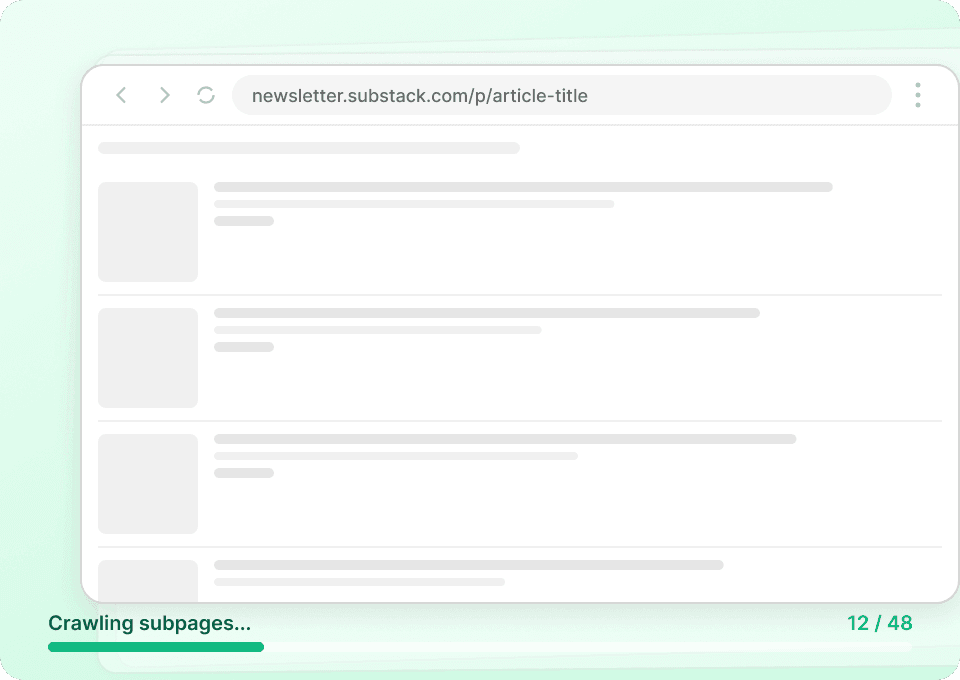
Δείτε ολόκληρη την εικόνα του Substack
Οι σελίδες λίστας του Substack εμφανίζουν μόνο σύνοψη. Το Thunderbit επισκέπτεται αυτόματα κάθε υποσελίδα άρθρου για να τραβήξει το πλήρες περιεχόμενο, δίνοντάς σας ένα ολοκληρωμένο dataset σε μία μόνο διαδικασία. Συλλέξτε τίτλους άρθρων, ονόματα συγγραφέων, ονόματα δημοσιεύσεων και το πλήρες κείμενο των άρθρων — χωρίς να ανοίξετε ούτε μία σελίδα χειροκίνητα.
Δυσκολεύεστε να κάνετε αποτελεσματικά scraping στο Substack;
Δείτε γιατί το Thunderbit ξεπερνά τους παραδοσιακούς scrapers για δεδομένα Substack.
Παραδοσιακοί scrapers
Ο παλιός τρόπος δουλειάςThunderbit
Η πιο έξυπνη προσέγγισηΜην το παίρνεις μόνο από εμάς
Δες τι λένε οι χρήστες μας για το Thunderbit.








Συχνές ερωτήσεις
Σχετικά χρήσεις
Εξερεύνησε περισσότερες χρήσεις του web scraper του Thunderbit.

PubMed Scraper
Το Thunderbit’s PubMed Scraper σάς βοηθά να εξάγετε δομημένα δεδομένα από τα αποτελέσματα αναζήτησης και τις σελίδες άρθρων του PubMed με τη βοήθεια AI. Συλλέξτε επίκαιρη ιατρική έρευνα, αποδείξεις από κλινικές μελέτες, περιλήψεις, συγγραφείς, ιδρύματα/φορείς, ημερομηνίες δημοσίευσης και συνδέσμους και εξαγάγετέ τα σε Excel, Google Sheets, Airtable ή Notion.
Μάθε περισσότερα ->
Carousell 爬虫
Εξάγετε καταχωρίσεις Carousell — τίτλους, περιγραφές, τιμές και στοιχεία πωλητή — με 2 κλικ και κάντε εξαγωγή απευθείας σε Excel, Google Sheets ή Notion. Χωρίς κώδικα ή περίπλοκη ρύθμιση.
Μάθε περισσότερα ->
Coupang scraper
Εξαγάγετε ονόματα προϊόντων, τιμές και ποσοστά έκπτωσης από το Coupang σε 2 κλικ — και εξάγετε αμέσως τα δεδομένα σε Excel, Google Sheets ή Notion. Δεν απαιτείται κώδικας.
Μάθε περισσότερα ->
MUJI Scraper
Εξάγετε ονόματα προϊόντων Muji, τιμές, μεγέθη και περιγραφές — και στη συνέχεια εξάγετε τα σε Excel, Google Sheets ή Notion με 2 κλικ. Η τεχνητή νοημοσύνη του Thunderbit διαβάζει τη σελίδα για εσάς, χωρίς καμία ρύθμιση.
Μάθε περισσότερα ->Εργαλείο Συλλογής Δεδομένων Βίντεο
Το Video Scraper της Thunderbit σάς επιτρέπει να εξάγετε δεδομένα για βίντεο και δημιουργούς με τη βοήθεια AI, μέσα σε λίγα κλικ. Συλλέξτε λίστες βίντεο, δείκτες απόδοσης και στοιχεία προφίλ και έπειτα εξαγάγετε σε Excel, Google Sheets, Airtable ή Notion για παρακολούθηση και έρευνα influencers.
Μάθε περισσότερα ->
Sports Direct Scraper
Εξάγετε ονόματα προϊόντων, τιμές και ποσοστά έκπτωσης από το Sports Direct σε 2 κλικ με το AI του Thunderbit — και μετά εξάγετε τα δεδομένα σας άμεσα σε Excel, Google Sheets ή Notion. Δεν απαιτείται κώδικας ή καμία ρύθμιση.
Μάθε περισσότερα ->Έτοιμος να απογειώσεις την εξαγωγή δεδομένων σου;
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Η δωρεάν δοκιμή προσφέρει απεριόριστα credits για 8 ιστοσελίδες.



