Scraper Ειδήσεων

Το εμπιστεύονται επαγγελματίες σε κορυφαίες εταιρείες














Δεδομένα ειδήσεων, συλλεγμένα πιο γρήγορα
Τράβηξε καθαρά δεδομένα ειδήσεων από άρθρα, λίστες και πηγές χωρίς τη χειροκίνητη ταλαιπωρία.
Πάρε όλες τις λεπτομέρειες του άρθρου
Οι σελίδες λίστας ειδήσεων σου δίνουν μόνο ένα teaser. Η Thunderbit επισκέπτεται κάθε υποσελίδα άρθρου και επιστρέφει την πλήρη εικόνα, συμπεριλαμβανομένων τίτλου, περίληψης άρθρου, συντάκτη, ημερομηνίας δημοσίευσης, πηγής ειδήσεων και ενότητας. Έτσι, μπορείς να περάσεις από μια απλή λίστα ιστοριών σε ένα πλήρες σύνολο δεδομένων με λιγότερα βήματα.
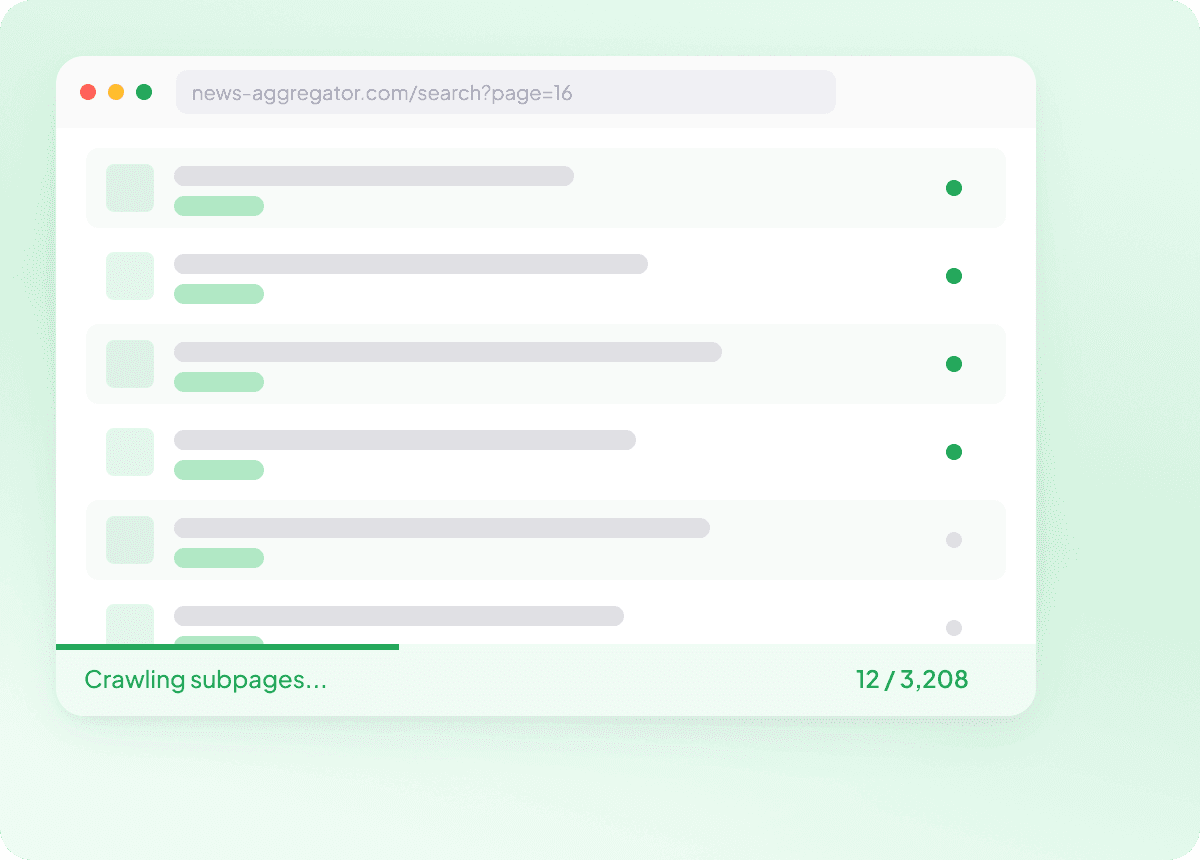
Μαζικό scraping λιστών URL ειδήσεων
Το να κάνεις scraping ειδήσεων μία σελίδα τη φορά γίνεται γρήγορα αργό. Με την Thunderbit, μπορείς να της δώσεις μια λίστα από URLs άρθρων και να κάνεις μαζικό scraping εκατοντάδων σελίδων με μία κίνηση, ώστε κάθε ιστορία να καταγράφεται με τα πεδία που χρειάζεσαι. Είναι ένας πρακτικός τρόπος να συλλέγεις μεγάλα σύνολα δεδομένων ειδήσεων χωρίς να επαναλαμβάνεις την ίδια δουλειά.

Κράτησε τα δεδομένα ειδήσεων φρέσκα
Οι ειδήσεις αλλάζουν καθημερινά και τα παλιά δεδομένα δεν χρησιμεύουν. Ρύθμισε προγραμματισμένο scraping ώστε η Thunderbit να λειτουργεί αυτόματα και να κρατά το spreadsheet σου ενημερωμένο με νέους τίτλους, περιλήψεις, συντάκτες, ημερομηνίες δημοσίευσης, πηγές ειδήσεων και ενότητες. Παίρνεις επαναλαμβανόμενες ενημερώσεις χωρίς να χρειάζεται να το θυμάσαι εσύ.
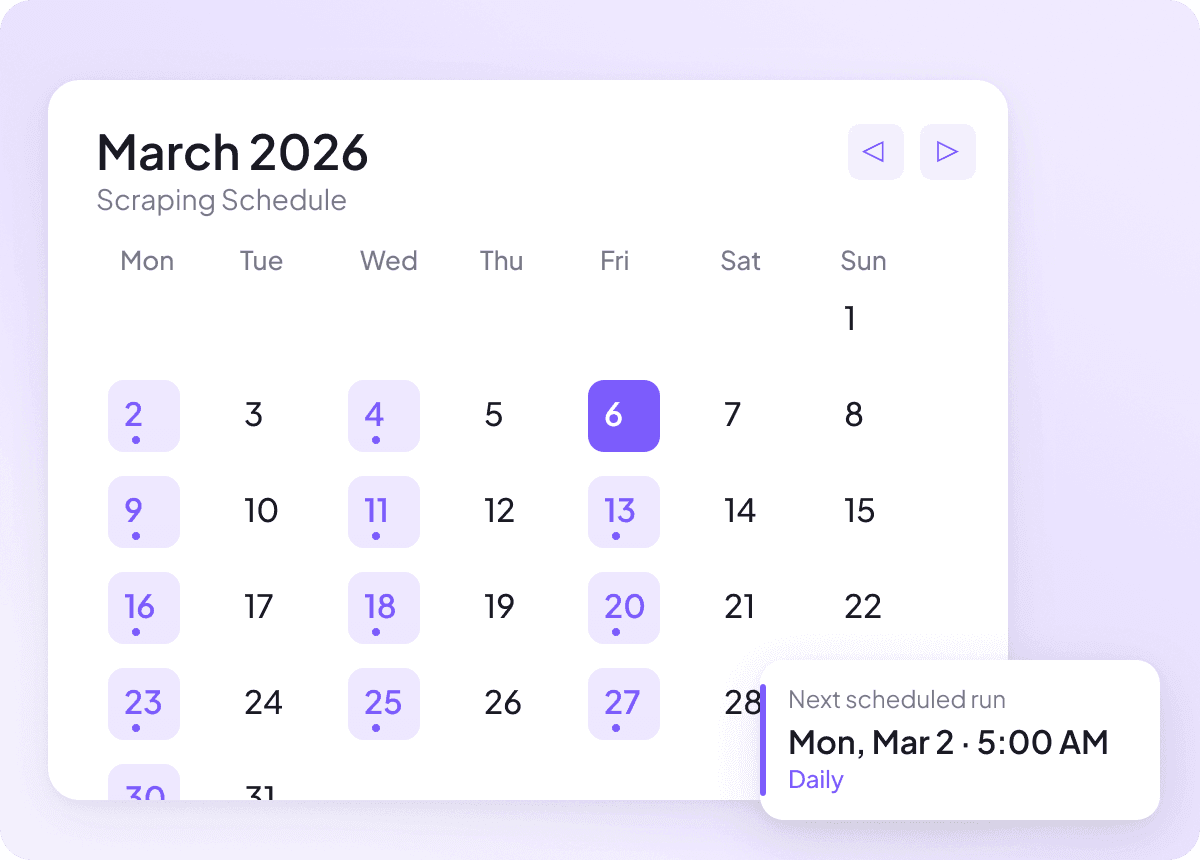
Γιατί η Thunderbit είναι διαφορετική από τα παραδοσιακά news scrapers;
Ένας πιο γρήγορος τρόπος να συλλέγεις ακατάστατα δεδομένα ειδήσεων χωρίς συνεχείς βλάβες.
Παραδοσιακά scrapers
Ο παλιός τρόπος να γίνονται τα πράγματαThunderbit AI
Η πιο έξυπνη προσέγγισηΜην το πάρεις μόνο από εμάς
Δες τι λένε οι χρήστες μας για το Thunderbit.






Συχνές ερωτήσεις
Σχετικά χρήσεις
Ανακάλυψε περισσότερες χρήσεις του web scraper του Thunderbit.
Amazon price scraper
Φέρτε τιμές, αξιολογήσεις και ASIN από το Amazon στο Google Sheets με scraping με σημείο και κλικ — χωρίς περίπλοκη ρύθμιση.
Μάθε περισσότερα ->Elgiganten Scraper
Συγκεντρώστε ονόματα προϊόντων, τιμές και διαθεσιμότητα από το Elgiganten σε μόλις δύο κλικ — το AI του Thunderbit αναλαμβάνει τα δύσκολα.
Μάθε περισσότερα ->
PubMed Scraper
Το PubMed Scraper της Thunderbit σάς βοηθά να εξάγετε δομημένα δεδομένα από τα αποτελέσματα αναζήτησης και τις σελίδες άρθρων του PubMed με τη βοήθεια AI. Συλλέξτε δημοφιλή ιατρική έρευνα, στοιχεία κλινικών δοκιμών, περιλήψεις, συγγραφείς, ιδρύματα/συσχετίσεις, ημερομηνίες δημοσίευσης και συνδέσμους και έπειτα εξαγάγετε σε Excel, Google Sheets, Airtable ή Notion.
Μάθε περισσότερα ->
Trivago scraper
Εξαγάγετε ονόματα ξενοδοχείων, τιμές και αξιολογήσεις από το Trivago με λίγα μόνο κλικ — χωρίς κώδικα ή ρύθμιση.
Μάθε περισσότερα ->
Spokeo Scraper
Σταμάτα να αντιγράφεις χειροκίνητα δεδομένα από το Spokeo — χρησιμοποίησε το Thunderbit για να τραβάς ονόματα, ηλικίες, διευθύνσεις και πολλά άλλα με μόλις λίγα κλικ.
Μάθε περισσότερα ->
United Airlines Scraper
Δείξε και κάνε κλικ για να συλλέξεις δεδομένα πτήσεων της United Airlines, όπως αριθμό πτήσης, ώρα άφιξης και αεροδρόμιο αναχώρησης — το Thunderbit AI αναλαμβάνει τα υπόλοιπα.
Μάθε περισσότερα ->Έτοιμος να απογειώσεις την εξαγωγή δεδομένων σου;
Γίνε μέλος των 100,000+ επαγγελματιών που ήδη χρησιμοποιούν το Thunderbit για να αυτοματοποιούν τις web scraping ροές εργασίας τους.
Η δωρεάν δοκιμή προσφέρει απεριόριστα credits για 8 webpages.